机器学习(五) -- 监督学习(8) --神经网络2
机器学习系列文章目录及序言
深度学习系列文章目录及序言
上篇:机器学习(五) -- 监督学习(8) --神经网络1
下篇:
前言
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
tips:本篇文章按照神经网络训练过程编排:
激活函数 -> (数据预处理、权值初始化 )前向传播 -> 损失计算(损失函数,正则化方法) -> 反向传播 -> 参数更新(梯度下降法)
三、神经网络原理
前面我们说了神经网络的训练过程主要包括前向传播(forward propagation),损失计算(loss calculation),反向传播(backpropagation)和参数更新(parameter update)。

- 前向传播:输入层数据从前向后,数据逐步传递至输出层
- 损失函数:衡量神经网络的输出与实际结果之间的差异,Loss=f(y^,y)
- 反向传播:损失函数开始从后向前,梯度逐步传递至第一层,用于权重更新,使网络输出更接近标签
- 反向传播原理:微积分中的链式求导法则

1、超参数
1.1、超参数定义
超参数(Hyperparameters)是机器学习和深度学习模型中的参数,但与模型的权重和偏差不同,超参数是在训练模型之前设置的,而不是通过训练过程学习的。超参数对于模型的性能和行为起着关键作用,因此选择合适的超参数对于获得良好的模型性能至关重要
常见超参数:
- 学习率(Learning Rate):学习率控制了模型在每次迭代中更新权重的幅度。太大的学习率可能导致模型不稳定,而太小的学习率可能导致模型收敛速度过慢。
- 批量大小(Batch Size):批量大小定义了模型在每次迭代中使用的训练样本数量。合适的批量大小可以影响模型的训练速度和性能。
- 迭代次数(Epochs):迭代次数表示整个训练数据集被模型用于训练的次数。它影响模型的收敛速度。
- 正则化参数(Regularization Parameter):正则化参数用于控制模型的复杂度,以防止过拟合。常见的正则化方法包括L1正则化和L2正则化。
- 隐藏层的数量和单元数(Number of Hidden Layers and Units):对于神经网络等深度学习模型,超参数还包括了隐藏层的数量和每个隐藏层中神经元的数量。
- 优化算法(Optimization Algorithm):优化算法用于更新模型的权重,常见的包括随机梯度下降(SGD)、Adam等。
- 激活函数(Activation Function):激活函数用于每个神经元的输出,常见的有ReLU、Sigmoid、Tanh等。
选择合适的超参数通常需要经验和试验,可以使用交叉验证等技术来评估不同超参数组合的性能。超参数调优是调整机器学习模型以获得最佳性能的重要步骤之一。不同的超参数选择可能会导致完全不同的模型行为和性能。
1.2、超参数调优
寻找超参数的最优值通常需要尝试不同的超参数组合,并评估它们在模型性能上的影响。以下是一些常见的方法和策略,用于帮助你找到最佳的超参数值:
- 网格搜索(Grid Search):网格搜索是一种简单而直观的方法,它涉及指定超参数的一组可能值,然后对所有可能的组合进行训练和评估。通过交叉验证来评估不同组合的性能,最终选择在验证集上表现最好的组合。
- 随机搜索(Random Search):随机搜索是一种更高效的方法,它在超参数空间内随机选择超参数组合进行训练和评估。与网格搜索相比,随机搜索通常可以在相同的计算资源下探索更多的超参数组合。
- 贝叶斯优化(Bayesian Optimization):贝叶斯优化是一种更智能的方法,它使用贝叶斯模型来估计超参数空间内的性能,并选择最有可能改善性能的超参数组合。这可以在相对较少的试验中找到良好的超参数值。
- 自动调参工具:有一些自动调参工具和平台,如Hyperopt、Optuna和Keras Tuner,可以帮助你自动化超参数搜索过程。它们使用不同的算法和策略来寻找最佳超参数。
- 学习曲线(Learning Curves):绘制学习曲线可以帮助你理解不同超参数对模型性能的影响。学习曲线显示了模型性能随着训练数据量或迭代次数的增加而变化,有助于识别模型是否过拟合或欠拟合。
- 交叉验证:使用交叉验证来评估不同超参数组合的性能,以避免模型在特定验证集上表现良好但在未见数据上表现糟糕的情况。
- 自适应调整(Adaptive Tuning):有些超参数调整算法可以在训练过程中自动调整超参数,以适应模型性能的变化。例如,学习率衰减算法可以自动降低学习率以改善模型的收敛。
最佳的超参数值取决于你的具体问题和数据集,因此需要灵活性和实验来找到最佳的组合。通常,通过在小规模数据集上进行初步搜索,然后在更大的数据集上验证获得的超参数组合,可以更快地找到适合你的模型的最佳超参数。
2、激活函数
激活函数最终决定了要发射给下一个神经元的内容,不使用激活函数的话,神经网络的每层都只是做线性变换,多层输入叠加后也还是线性变换。因为线性模型的表达能力通常不够,所以激活函数可以引入非线性因素。
2.1、作用
- 让多层感知机成为真正的多层,否则等价于一层
- 引入非线性,使网络可以逼近任意非线性函数(万能逼近定理)
无激活函数,多层网络会退化成单层网络(矩阵乘法理解):所以加入激活函数才能避免网格退化,退化效果:

2.2、性质
- 连续并可导(允许在少数点上不可导)便于利用数值优化的方法来学习网络参数.
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率
- 激活函数的导函数的值域要在合适区间内,不能太大也不能太小,否则会影响训练的效率和稳定性
2.3、常见激活函数
2.3.0、分类
激活函数能分成两类——饱和激活函数和非饱和激活函数。
饱和:
右饱和:当x趋近于正无穷时,函数的导数趋近于0;(饱和区,下面会提到)
左饱和:当x趋近于负无穷时,函数的导数趋近于0;
饱和函数和非饱和函数:当一个函数既满足右饱和又满足左饱和,则为饱和函数,否则为非饱和函数。
eg:
- 饱和函数:Sigmoid函数,tanh函数等
- 非饱和函数:ReLu、ELU、Leaky ReLU、PReLU、RReLU等
2.3.1、阶跃函数
理想情况下,激活函数的形式应为阶跃函数。其函数与导函数图像如下图所示:


即输出有0或1两种,0 表示神经元不兴奋,1 则表示神经元兴奋。但阶跃函数不光滑且不连续,因此对于激活函数的选择通常会选择Sigmoid 函数(Sigmoid Function)。
2.3.2、Sigmoid函数
Sigmoid函数函数与导函数图像如下图所示:

如图所示,在其左右两边导函数值接近0,被称为饱和区,神经元大量落入饱和区导致梯度接近0,将无法在向后传播梯度进而更新参数,导致模型训练困难(梯度消失)
- 优点
- 实数映射到 [ 0 , 1 ] 区间,常用作二分类输出层,(在循环神经网络中作为各种门控单元的激活函数,用来控制信息是保留还是遗忘,接近0就是遗忘,接近1就是保留)
- 能将输入值映射到概率值,在分类任务中非常有用。
- 缺点
- 计算量大,易出现梯度消失,影响模型的训练速度。
- 输出数据不是0均值(zero-centered),可能导致后续层神经元输入偏移,影响训练效果。
梯度消失(gradient vanishing)与梯度爆炸(Gradient Explosion):
梯度消失:随着网络层数的增多,从高层逐层反向传递的梯度信息可能会越来越弱,以至于传到底层时梯度几乎为零,从而造成底层参数无法得到更新,导致网络无法收敛;
梯度爆炸:也有可能在反向传递时,大于1的梯度值不断相乘,导致梯度值越来越大,使得网络处于震荡状态而无法收敛。
梯度消失详解:优化神经网络的方法是Back Propagation,即导数的反向传播:先计算输出层对应的 loss,然后将 loss 以导数的形式不断向上一层网络传递,修正相应的参数,达到降低loss的目的。Sigmoid函数在深度网络中常常会导致导数逐渐变为0,使得参数无法被更新,神经网络无法被优化。
原因在于两点:
- 当参数x的值较大或较小时,导数接近与0,而反向传播的数学依据是微积分求导的链式法则,当前层的导数需要之前各层导数的乘积,几个小数的相乘,结果会更接近0。
- Sigmoid导数的最大值是0.25,这意味着导数在每一层至少会被压缩为原来的1/4,通过两层后被变为1/16,…,通过10层后为1/1048576。请注意这里是“至少”,导数达到最大值这种情况还是很少见的。
0均值(zero-centered):
Sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。
如果数据分布不是zero-centered的,就会导致后一层的神经元接受的输入都为正或都为负,梯度的方向也是要么为正要么为负,这会导致对于该层的所有w参数,梯度的符号都是一样的,在一次更新中,该层的w参数要么一起增大,要么一起减小。这会导致如下图红色箭头所示的阶梯式更新。

通常训练是按batch训练的,所以每个batch的信息不同,在一定程度上能缓解非0均值带来的影响,所以尽管ReLU不是0均值的,但仍然是主流激活函数。
2.3.3、tanh函数(双曲正切)
tanh函数与导函数图像如下图所示:

- 优点
-
实数映射到 [ -1 , 1 ] 区间,处理正负值数据更有效,常用在RNN中
-
输出数据是0均值的,有助于数据中心化,加速训练过程。
-
- 缺点
- 同样易出现梯度消失
在实际应用中,Tanh函数常用于神经网络的隐藏层,因为它能够提供更好的梯度信息,从而加速训练过程;然而,在输出层,特别是二分类问题中,Sigmoid函数仍然是一个更自然的选择,因为其输出范围在0到1之间,更适合表示概率值。
2.3.4、ReLU(修正线性单元)
ReLU(Rectified Linear Unit)函数是目前最常用的激活函数之一。


- 优点:
- 线性运算,计算上非常高效,能够有效缓解梯度消失问题。
- 梯度在正输入值时始终为1,反向传播过程中梯度不会消失,加速训练过程。
- 缺点:
- 存在“死亡ReLU”问题(Dead ReLU Problem),负输入值时输出为零,可能导致某些神经元永远不被激活,失去学习能力。
Dead ReLU Problem:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
这是由于函数导致负梯度在经过该ReLU单元时被置为0, 且在之后也不被任何数据激活, 即流经该神经元的梯度永远为0, 不对任何数据产生响应。 当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题。有两个主要原因可能导致这种情况产生:
(1) 非常不幸的参数初始化,这种情况比较少见;
(2) learning rate太高导致在训练过程中参数更新太大,会导致超过一定比例的神经元不可逆死亡, 进而参数梯度无法更新, 整个训练过程失败。
2.3.4.1、Leaky ReLU
为了解决Dead ReLU Problem,将ReLU的前半段设为0.01x而非0。


与ReLU函数不同,Leaky ReLU函数在输入值为负时不会直接输出零,而是输出一个较小的负值(通常是输入值的0.01倍)。
- 优点:
- 能有效缓解“死亡ReLU”问题,提高神经网络的训练效果。
- 负输入值时输出较小的负值,神经元仍能接收梯度信息,继续学习。
- 缺点:
- 需要调优负斜率(如0.01),不同任务可能需要不同的负斜率。
- 在某些任务中表现优异,但在其他任务中可能不如ReLU有效。
2.3.4.2、PReLU(Parametric ReLU)

函数与导函数图像基本同上
参数α通常为 0 到 1 之间的数字,并且通常相对较小。
在负值域,PReLU 的斜率较小,这也可以避免 Dead ReLU 问题。
2.3.5、softmax函数
各个输出节点的输出值范围映射到[0, 1],并且约束各个输出节点的输出值的和为1的函数。
Softmax函数通常用于神经网络的输出层,特别是在多分类问题中

Softmax操作原理
- 取指数,实现非负(同时放大差异)
- 除以指数之和,实现之和为1
如下

将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点 。计算如下:

- 优点:
- 输出是概率分布,输出值总和为1,适合多分类问题的概率预测。
- 可微分,可用于反向传播过程,优化神经网络参数。
- 缺点:
- 当类别数量较多时,计算复杂度较高,影响训练速度。
- 处理类别不平衡问题时可能表现不佳,倾向于将概率分布集中在少数几个类别上。
2.4、激活函数的应用
在实际应用中,选择合适的激活函数需要根据具体问题和网络结构来决定;以下是一些常见的应用场景及其推荐的激活函数:
-
回归问题:对于回归问题,输出层通常使用线性激活函数(y=x,恒等映射),因为我们希望输出值可以在任意范围内变化。
-
二分类问题:在二分类问题中,输出层通常使用Sigmoid激活函数,因为它能将输出值限制在 0 和 1 之间,便于解释为概率。
-
多分类问题:对于多分类问题,输出层使用Softmax激活函数是首选,它能将输出值转换为概率分布,确保所有类别的概率之和为 1。
-
多标签分类问题:在多标签分类问题中,输出层通常使用Sigmoid激活函数,因为每个标签的预测是独立的,且需要输出概率值。
-
隐藏层:对于隐藏层,ReLU是默认的选择,因为它简单高效,能加速学习过程;对于一些特定问题,Tanh或Leaky ReLU也可能表现更好。
此外,ReLU激活函数通过输出输入值本身或零,有效缓解了梯度消失问题,适用于大多数深度神经网络;Tanh函数将输入映射到-1到1之间,适合处理具有正负值的数据;Leaky ReLU通过在负值输入时引入小的正斜率,解决了ReLU的“死亡”问题。
在选择激活函数时,还需考虑其他因素,如隐藏单元的数量,权重初始化和其他超参数;通过测试不同的激活函数并评估其性能,可以优化神经网络的架构,提高其效果。激活函数的选择没有一成不变的答案,需要根据具体问题和网络结构进行实验和调整;通过不断尝试和评估,可以找到最适合的激活函数,提升神经网络的性能。
3、前向传播
3.1、数据预处理


3.2、权值初始化
训练前对权值参数赋值,良好的权值初始化有利于模型训练
3.2.1、随机初始化法
高斯分布随机初始化,从高斯分布N~(μ,σ^2)中随机采样,对权重进行赋值,比如N~(0,0.01)。
3σ准则:数值分布在(µ-3σ, µ+3σ)中的概率为99.73%

正态分布图像中,μ 决定了正态分布的位置,σ 决定了分布的幅度,例如在Sigmoid函数中权重的值过大或者过小会落入饱和区,可能导致梯度消失,影响模型训练,所以我们可以通过控制σ来控制权重的大小,标准差选择方式通常采用:自适应标准差(自适应方法随机分布中的标准差。)。
Xavier初始化:为一种自适应标准差方法,用一个均匀分布(![]() )来控制正态分布的均值和方差(让这个均匀分布的均值和标准差做正态分布的均值和标准差)。
)来控制正态分布的均值和方差(让这个均匀分布的均值和标准差做正态分布的均值和标准差)。
在这个均匀分布中,a为输入神经元个数,b为输出神经元个数。正态分布的期望(均值)和标准差为: 。所以正态分布的均值和标准差为:
。所以正态分布的均值和标准差为:![]()
即所用正态分布为:![]()
高斯分布为: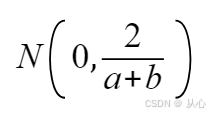
Xavier初始化,出自这篇论文:![]()
还有Kaiming初始化(MSRA),出自这篇论文:
3.3、前向传播
前向传播就是从输入层到输出层,计算每一层每一个神经元的激活值。也就是先随机初始化每一层的参数矩阵,然后从输入层开始,依次计算下一层每个神经元的激活值,一直到最后计算输出层神经元的激活值。

前向传播计算过程(其实前面算过了,这里再简单举例,y_1这样表示是可能存在多个输出神经元):
step1:随机初始化参数矩阵w^(1)和w^(2)

step1:计算隐藏层的每个神经元激活值(g(x)为激活函数)

step1:计算输出层的每个神经元激活值(因为偏置以权重形式表示,所以需要在上一层产生的输出矩阵中加入偏置的表示x_0)

4、损失函数
前向传播的之后需要计算损失,而损失函数是衡量神经网络的输出与实际结果之间的差异
MSE(均方误差,Mean Squared Error)和CE(交叉熵,Cross Entropy)是神经网络两种常见损失函数
4.1、损失函数、代价函数、目标函数辨析
损失函数(Loss Function):
代价函数(Cost Function):
目标函数(Objective Function):![]()
损失函数描述单样本差异值(代码中以一个batch计算),代价函数描述总体平均差异值,目标函数强调整个训练过程,及要求模型输出与标签更接近,也要求模型参数不能太复杂(正则项控制模型复杂度,让模型不要太复杂,防止过拟合)
4.2、MSE(均方误差,Mean Squared Error)
在回归模型评估中机器学习(四) -- 模型评估(3)_机器学习讲过,这里简要概述。
输出值和实际结果之差的平方和的均值,常用在回归任务中,公式如下:

4.3、CE(交叉熵,Cross Entropy)
4.3.1、信息量和熵
交叉熵源于信息论,关于信息量和熵的知识,详情请看机器学习(五) -- 监督学习(3) -- 决策树中的【信息论基础】部分
4.3.2、相对熵(KL散度)
如果对于同一个随机变量X有两个单独的概率分布 P(x) 和 Q(x) ,则我们可以使用KL散度来衡量这两个概率分布之间的差异。
公式为

在机器学习中,常常使用 P(x) 来表示样本的真实分布, Q(x) 来表示模型所预测的分布,比如在一个三分类任务中(例如,猫狗马分类器), x_1,x_2,x_3 分别代表猫,狗,马,例如一张猫的图片真实分布 P(X)=[1,0,0],预测分布 Q(X)=[0.7,0.2,0.1],计算KL散度:

KL散度越小,表示 P(x) 与 Q(x) 的分布更加接近,可以通过反复训练 Q(x) 来使 Q(x) 的分布逼近 P(x)。
4.3.3、交叉熵
交叉熵用于衡量两个分布的差异,常用于分类任务中,首先将KL散度公式拆开:

前者H(p(x))表示信息熵,后者即为交叉熵,KL散度 = 交叉熵 - 信息熵。交叉熵计算公式如下:

在机器学习训练网络时,输入数据与标签常常已经确定,那么真实概率分布 P(x) 也就确定下来了,所以信息熵在这里就是一个常量。由于KL散度的值表示真实概率分布 P(x) 与预测概率分布 Q(x) 之间的差异,值越小表示预测的结果越好,所以需要最小化KL散度,而交叉熵等于KL散度加上一个常量(信息熵),且公式相比KL散度更加容易计算,所以在机器学习中常常使用交叉熵损失函数来计算loss就行了。优化交叉熵 == 优化相对熵。
4.3.4、栗子
| 猫 | 狗 | 马 | |
|---|---|---|---|
| Label | 0 | 1 | 0 |
| Pred | 0.2 | 0.7 | 0.1 |
loss=-(0*log_2(0.2)+1*log_2(0.7)+0*log_2(0.1)) =0.15
机器学习中一个batch的loss为(m为样本个数):

交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。
- 概率两性质:
- 概率值非负
- 概率之和等于1
- Softmax操作
- 取指数,实现非负(同时放大差异)
- 除以指数之和,实现之和为1
没有一个适合所有任务的损失函数,损失函数设计会涉及算法类型、求导是否容易、数据中异常值的分布等问题 。
更多损失函数可到PyTorch网站torch.nn — PyTorch 2.4 documentation
4.4、正则化方法
正则化(Regularization):减小方差的策略,通俗理解为减轻过拟合的策略
过拟合现象:方差过大,在训练集表现良好,在测试集表现糟糕
误差=偏差+方差+噪声
- 偏差:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
- 噪声:则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界
4.4.1、加入正则项
L1正则化(Lasso Regression): ,赋0,删除这个特征的影响
,赋0,删除这个特征的影响
L2正则化(Ridge Regression): ,削弱某个特征的影响(weight decay,权重衰减)
,削弱某个特征的影响(weight decay,权重衰减)

其实在线性回归时已经简要讲过正则项相关要点,详情可看机器学习(五) -- 监督学习(5) -- 线性回归1
例如加入L2正则项后,用梯度下降法更新权重,产生的影响(省略学习率):
通常0<λ<1,用于权衡Loss和正则项的比例(更关注哪一个的影响)

w_i(1-λ)<w_i,相当于加入正则项后使得权重减小,效果如下

4.4.2、随机失活(Dropout)
随机失活在神经网络中常用 ,随机选中(随机)神经元使其权重为0(失活),可以避免过度依赖某个神经元, 实现减轻过拟合,如下为不使用和使用的结构对比:

采用代码实现Dropout时,训练和测试两个阶段的数据尺度变化,测试时神经元输出值需要乘以概率p。如上图左侧为测试阶段(所有神经元都会使用),右边为训练阶段(使用部分神经元)。
4.4.3、其他正则化方法
- Batch normalization:《Batch Normalization: Accelerating Deep NetworkTraining by Reducing Internal Covariate Shift》
- Layer Normalization:《Layer Normalization》
- Instance Normalization:《Instance Normalization: The Missing Ingredient forFast Stylization》
- Group Normalization:《 Group Normalization》
5、误差逆传播算法(反向传播,BP)
这里知道损失函数基本形式为 Loss=f(y^,y) 即可
误差逆传播算法(Error back propagation algorithm,反向传播算法,简称BP算法) :反向传播就是根据前向传播计算出来的激活值,来计算每一层参数的梯度,并从后往前进行参数的更新。
(为了方便理解,上面的神经网络结构画成如下的计算图,乘法和激活函数运算其实可以合并,但为了便于理解,还是将它们拆开写的)
(计算图简要来讲就是一种有向无环图,包含节点和边,节点表示数据或操作(方框、圆圈),边表示数据流或计算依赖关系,每条边通常表示从一个操作的输出到另一个操作的输入。)

下图左边是前向传播的矩阵表示,右边是参数矩阵的维度

(这里涉及到矩阵求导的知识,详情请看:线性代数 -- 矩阵求导,主要涉及标量对向量求导的分子布局 )
)
利用反向传播(链式求导法则)可以算出最终的损失Loss对隐藏层w^(2)以及x^(2)和输入层w^(1)以及x^(1)的表示如下:

同时我们看到 最终的损失Loss对输入层w^(1)以及x^(1)求导用到了Loss对隐藏层x^(2)求导的结果,也就是梯度反向传播的体现
6、参数更新(梯度下降算法)
参数更新,也就是神经网络的优化算法,通过调整模型参数来最小化损失函数的过程,我们主要用到梯度下降法(GD,Gradient Descent)。
梯度下降法:权重沿着梯度负方向更新,使得函数值减小,以下为3个数学基本概念。
- 导数:函数在指定坐标轴上的变化率
- 方向导数:指定方向上的变化率
- 梯度:一个向量,方向为方向导数取得最大值的方向
具体可看机器学习(五) -- 监督学习(5) -- 线性回归1-CSDN博客的梯度下降部分
参数更新公式为(学习率n:控制更新步长):

其他一些优化算法:
- 批量梯度下降(BGD,Batch/Navie Gradient Descent)
- 随机梯度下降(SGD,Stochastic Gradient Descent)
- 动量随机梯度下降(SGD with momentum)
- 自适应梯度(AdaGrad)优化
- 均方根传播(RMSProp)优化
- Adam(Adaptive Moment Estimation)优化
7、深度学习简述
7.1、定义
深度学习是指训练多层神经网络(强调深度的重要性,逐层抽象),它是基于人工神经网络的机器学习的一个子集,“深度”指的是这些神经网络中的多层;传统的机器学习算法仅限于相对简单的分析,深度学习可以从图像,文本和音频等大型复杂数据集中提取更丰富,更抽象的表示。
深度神经网络的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。
深度学习是当今计算机视觉,语音识别,自然语言处理和人工智能等领域快速发展的基础。
7.2、传统机器学习和深度学习的区别
传统机器学习的特征提取主要依赖人工,针对特定简单任务的时候人工提取特征会简单有效,但是并不能通用。
深度学习的特征提取并不依靠人工,而是机器自动提取的。这也是为什么大家都说深度学习的可解释性很差,因为有时候深度学习虽然能有好的表现,但是我们并不知道他的原理是什么。
7.3、深度学习优缺点
优点
- 学习能力强,表现非常好
- 覆盖范围广、适应性好,理论上可以映射到任意函数,所以能解决很复杂的问题。
- 数据驱动、上限高,数据量越大,他的表现就越好。
- 可移植性好,有很多框架可以使用,可以兼容很多平台。
缺点:
- 计算量大、便携性差
- 硬件需求高
- 模型设计复杂
- 深度学习依赖数据,并且可解释性不高。
7.3、应用
计算机视觉与图像识别:
- 人脸识别:广泛应用于安全监控、手机解锁、支付验证等场景。
- 图像分类:整幅图像的分类或识别
- 物体检测:检测图像中物体的位置进而识别物体
- 图像分割:对图像中的特定物体按边缘进行分割
- 图像回归:预测图像中物体组成部分的坐标
自然语言处理(NLP):
- 语音识别:将语音识别为文字
- 声纹识别:识别是哪个人的声音
- 语音合成:根据文字合成特定人的语音
- 语言模型:根据之前词预测下一个单词。
- 情感分析:分析文本体现的情感(正负向、正负中或多态度类型)。
- 神经机器翻译:基于统计语言模型的多语种互译。
- 神经自动摘要:根据文本自动生成摘要。
- 机器阅读理解:通过阅读文本回答问题、完成选择题或完型填空。
- 自然语言推理:根据一句话(前提)推理出另一句话(结论)。
购物与推荐系统:
- 用户行为分析:分析用户的购物习惯、偏好等信息,为电商平台提供精准营销支持。
- 商品推荐:根据用户的历史行为和喜好,为用户提供个性化的商品推荐服务。
综合应用
- 图像描述:根据图像给出图像的描述句子
- 可视问答:根据图像或视频回答问题
- 图像生成:根据文本描述生成图像
- 视频生成:根据故事自动生成视频
还可以用于金融、医疗、自动驾驶、游戏开发等等。
旧梦可以重温,且看:机器学习(五) -- 监督学习(8) --神经网络1
欲知后事如何,且看:
相关文章:
机器学习(五) -- 监督学习(8) --神经网络2
机器学习系列文章目录及序言深度学习系列文章目录及序言 上篇:机器学习(五) -- 监督学习(8) --神经网络1 下篇: 前言 tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看…...

物联网之PWM呼吸灯、脉冲、LEDC
MENU 前言原理硬件电路设计软件程序设计analogWrite()函数实现呼吸灯效果LEDC输出PWM信号 前言 学习制作呼吸灯,通过LED灯的亮度变化来验证PWM不同电压的输出。呼吸灯是指灯光在单片机的控制之下完成由亮到暗的逐渐变化,感觉好像是人在呼吸。 原理 脉冲宽…...

Python利用pyecharts实现数据可视化
小编会持续更新知识笔记,如果感兴趣可以三连支持。闲来无事,水文一篇,不过上手实践一下倒还是挺好玩的,这一块知识说不定以后真可以尝试拿来做数据库的报表显示。 有梦别怕苦,想赢别喊累。 目录 前言 JSON数据格式的…...

网恋照妖镜源码搭建教程
文章目录 前言创建网站1.打开网站设置 配置ssl2.要打开强制HTTPS,用宝塔免费的ssl证书即可,也可以使用其他证书,必须是与域名匹配的3.上传文件至根目录进行解压4.解压后,修改文件 sc.php 里面的内容5.其余探索 前言 前俩年很火的…...

STM32
(以下操作环境为Keil5和proteus8.9) 八种输入输出模式及他们的工作模式 分析如下 总线:总线提供了数据在不同组件(如处理器、内存、输入输出设备等)之间传输的路径,使数据能够快速、准确地在系统内流动。 …...

用手机做抢答器 低预算知识竞赛活动的选择
使用手机作为抢答器是低预算竞赛活动的一个理想选择。随着智能手机的普及,传统抢答器已经被手机抢答器所替代,这种转变不仅降低了成本,而且提供了更大的灵活性和便利性。通过手机扫码登录竞赛软件,参赛者可以直接在手机上进行抢答…...

ELK学习笔记(二)——使用K8S部署Kibana8.15.0
上篇文章我们完成了,ES的集群部署,如果还没有看过上篇文章的兄弟,可以去看看。 ELK学习笔记(一)——使用K8S部署ElasticSearch8.15.0集群 话不多说,接下来直接进入kibana的搭建 一、下载镜像 #1、下载官方…...

报错:CPU指令集的问题
bug描述 我在运行CMAQ中的icon时,遇到bug: Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, POPCNT and AVX instructions.解决办法 经过查询&a…...

Type-C接口诱骗取电快充方案
Type-C XSP08Q 快充协议芯片是一种新型电源管理芯片,主要负责控制充电电流和电压等相关参数,从而实现快速充电功能。Type-C XSP08Q快充协议是在Type-C接口基础上,加入了XSP08Q协议芯片的支持,很大程度上提升了充电速度。 正常情况…...

图像白平衡
目录 效果 背景 什么是白平衡? 实现原理 将指定图色调调整为参考图色调主要流程 示例代码 效果 将图一效果转换为图二效果色调: 调整后,可实现色调对换 背景 现有两张图像,色调不一致,对于模型重建会有影响。因…...

SAP Business One 与无锡哲讯:携手共创企业数字化未来
在当今快速发展的商业世界中,企业的数字化转型已成为提升竞争力的关键。在众多的数字化解决方案中,SAP Business One 以其强大的功能和灵活性脱颖而出。与此同时,无锡哲讯智能科技有限公司作为专业的 SAP 系统服务提供商,为企业带…...

Unity Adressables 使用说明(五)在运行时使用 Addressables(Use Addressables at Runtime)
一旦你将 Addressable assets 组织到 groups 并构建到 AssetBundles 中,就需要在运行时加载、实例化和释放它们。 Addressables 使用引用计数系统来确保 assets 只在需要时保留在内存中。 Addressables 初始化 Addressables 系统在运行时第一次加载 Addressable …...

什么是死锁,如何解决?
什么是死锁? 在并发编程中,死锁是指两个或多个进程在竞争资源时,互相等待无法继续执行的状态。这种情况发生时,每个进程都在等待其他进程释放它们所需要的资源,但同时又不释放自己占有的资源,导致所有进程…...

借助ChatGPT三步,完成课题申报书中研究价值部分写作全攻略指南
大家好,感谢关注。我是七哥,一个在高校里不务正业,折腾学术科研AI实操的学术人。关于使用ChatGPT等AI学术科研的相关问题可以和作者七哥(yida985)交流,多多交流,相互成就,共同进步,为大家带来最酷最有效的智能AI学术科研写作攻略。 撰写申请书中的“本课题的学术价值…...

IDEA取消自动选择光标所在行
今天出现了一个怪事: 当我使用IDEA编写代码的时候,单击下一行或者上一行的时候,莫名其妙它会自己选中一行,导致我要么是回车代码直接没了,要么是代码直接给我搞错位了,还得按ctrlz返回,十分的恶…...

VUE2.0 elementUI el-input-number 数据更新,视图不更新——基础积累
今天遇到一个问题,是关于el-input-number组件的,发现数据明明已经更改了,但是页面上组件输入框中还是之前的值。 比如上方输入框中,我输入120.5,就会出现下面的诡异现象 回显此值是120.779,但是页面上输入…...

JS中this指向问题
首先,this的绑定和定义的位置无关,它的指向只和调用方式有关,this只有在运行时才知道指向谁。 一,默认绑定 默认绑定,也可以说是独立函数调用,这时this指向window。 function foo() {console.log(this) …...
)
大厂面试:小米嵌入式面试题大全及参考答案(130+道 12万长文)
Flink 架构介绍 Flink 是一个分布式流处理和批处理框架,具有高吞吐、低延迟、高可靠等特点。其架构主要由以下几个部分组成: 客户端(Client):负责将作业提交到集群,并与作业管理器进行交互,获取作业的状态信息。客户端可以是命令行工具、IDE 插件或者自定义的应用程序。…...

React 更新界面
文章目录 发现宝藏引入 useState声明和使用状态多个组件的状态管理解析代码 状态的局部性和性能优化结论 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。 在 React 中ÿ…...

JavaSE-易错题集-001
1. AccessViolationException异常触发后,下列程序的输出结果为( ) 1 2 3 4 5 6 7 8 9 10 11 12 13 static void Main(string[] args) { try { throw new AccessViolationException(); Console.Write…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

Godot 4.2 + C# 避坑指南:手把手教你打包发布你的第一个2D游戏到Steam
Godot 4.2 C# 避坑指南:从开发到Steam发布的完整实战手册当你终于完成心爱的2D游戏开发,准备向全世界展示你的作品时,打包发布这个看似简单的环节往往会成为独立开发者最大的噩梦。特别是使用Godot 4.2搭配C#的项目,从导出设置到…...

实测对比,使用Taotoken聚合接口后Agent任务延迟与稳定性观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测记录:使用 Taotoken 聚合接口后 Agent 任务延迟与稳定性观感 效果展示类,记录将原有基于单一 API 的 A…...

计算机视觉的实战项目:从0到1搭建属于自己的图像识别系统
作为软件测试从业者,我们每天都在和各类功能验证、兼容性测试、自动化测试框架打交道,对AI领域的实战项目往往觉得“门槛高”“和日常工作不沾边”。但随着AI技术在互联网产品中的落地越来越深入,图像识别功能已经成为很多APP、智能硬件的核心…...