Mybatis【分页插件,缓存,一级缓存,二级缓存,常见缓存面试题】
文章目录
- MyBatis缓存
- 分页
- 延迟加载和立即加载
- 什么是立即加载?
- 什么是延迟加载?
- 延迟加载/懒加载的配置
- 缓存
- 什么是缓存?
- 缓存的术语
- 什么是MyBatis 缓存?
- 缓存的适用性
- 缓存的分类
- 一级缓存
- 引入案例
- 一级缓存的配置
- 一级缓存的工作流程
- 一级缓存失效的情况
- 二级缓存
- XML实现
- 注解实现
- 二级缓存的缺点
- 自定义缓存的分类
- 总结(面试题汇总):
MyBatis缓存
分页
在Mybatis的配置文件中进行声明该插件:
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><properties resource="jdbc.properties"></properties><typeAliases><!-- 给单个类起别名 --><!-- <typeAlias alias="Student" type="bean.Student"/> --><!-- 批量别名定义,包扫描,别名为类名,扫描整个包下的类 --><package name="bean" /></typeAliases><!-- 分页插件 --><plugins><plugin interceptor="com.github.pagehelper.PageInterceptor"></plugin></plugins><environments default="development"><environment id="development"><transactionManager type="JDBC" /><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}" /><property name="url" value="${jdbc.url}" /><property name="username" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" /></dataSource></environment></environments><mappers><!-- 注册sqlmapper文件 --><!-- 1.同包 接口和sqlMapper 2.同名 接口和sqlMapper 3.sqlMapper的namespace指向接口的类路径 --><!-- <mapper resource="mapper/StudentMapper.xml" /> --><!-- <mapper class="mapper.StudentMapper"/> --><package name="mapper" /></mappers>
</configuration>
// 逻辑分页,减少对磁盘的读取,但是占用内存空间大@Select("select * from student")public List<Student> findStudentRowBounds(RowBounds rb);// 分页插件(推荐)@Select("select * from student")public List<Student> findStudentPageHelper();
方式1: 使用Map集合来保存分页需要数据,来进行分页
package mapper;
public interface StudentMapper {// 物理分页,多次读取磁盘,占用内存小@Select("select * from student limit #{cpage},#{size}")public List<Student> selectLimit(@Param("cpage") int cpage, @Param("size") int size);
}package test;
public class Test01 {public static void main(String[] args) {SqlSession sqlSession = DaoUtil.getSqlSession();StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);List<Student> list = studentMapper.selectLimit((1 - 1) * 3, 3);list.forEach(System.out::println);DaoUtil.closeSqlSession(sqlSession);}
}
方式2: 使用RowBounds集合来保存分页需要数据,来进行分页
package mapper;
public interface StudentMapper {// 逻辑分页,减少对磁盘的读取,但是占用内存空间大@Select("select * from student")public List<Student> findStudentRowBounds(RowBounds rb);
}
package test;
public class Test01 {public static void main(String[] args) {SqlSession sqlSession = DaoUtil.getSqlSession();StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);RowBounds rb = new RowBounds((1 - 1) * 3, 3);List<Student> list = studentMapper.findStudentRowBounds(rb);list.forEach(System.out::println);DaoUtil.closeSqlSession(sqlSession);}
}
方式3: 使用分页插件来进行分页【推荐】
package mapper;
public interface StudentMapper {// 分页插件(推荐)@Select("select * from student")public List<Student> findStudentPageHelper();
}
package test;
public class Test01 {public static void main(String[] args) {SqlSession sqlSession = DaoUtil.getSqlSession();StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);// PageHelper分页插件// (页码,每页多少个)// 分页第一页少做一次计算,sql语句也不同Page<Object> page = PageHelper.startPage(10, 1);// 获取page对象System.out.println(page);List<Student> list = studentMapper.findStudentPageHelper();// 详细分页对象PageInfo<Student> pageinfo = new PageInfo<Student>(list, 10);System.out.println(pageinfo);list.forEach(System.out::println);DaoUtil.closeSqlSession(sqlSession);}
}

延迟加载和立即加载
什么是立即加载?
立即加载是: 不管用不用信息,只要调用,马上发起查询并进行加载
比如: 当我们查询学生信息时,就需要知道学生在哪个班级中,所以就需要立马去查询班级的信息
通常:当 一对一或者 多对一 的时候需要立即加载
什么是延迟加载?
延迟加载是: 在真正使用数据时才发起查询,不用的时候不查询,按需加载(也叫 懒加载)
比如: 在查询班级信息,每个班级都会有很多的学生(假如每个班有100个学生),如果我们只是查看 班级信息,但是学生对象也会加载到内存中,会造成浪费。 所以我门需要进行懒加载,当确实需要查看班级中的学生信息,我门在进行加载班级中的学生信息。
通常: 一对多,或者多对多的是需要使用延迟加载
延迟加载/懒加载的配置

如果设置 lazyLoadingEnabled = false,则禁用延迟加载,会级联加载所有关联对象的数据
如果设置 lazyLoadingEnabled = true,默认情况下mybatis 是按层级延时加载的。
aggressiveLazyLoading = true,mybatis 是按层级延时加载 aggressiveLazyLoading = false,mybatis 按需求加载。
延迟加载的sqlmap

实现:
StudentMapper
@Results({ @Result(column = "classid", property = "classid"),@Result(column = "classid", property = "clazz", one = @One(select = "mapper.ClazzMapper.selectAll")) })@Select("select * from student")public List<Student> findStudentAndClassid();
测试类
public class Test02 {public static void main(String[] args) {SqlSession sqlSession = DaoUtil.getSqlSession();StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);List<Student> list = studentMapper.findStudentAndClassid();Student stu = list.get(0);System.out.println(stu);
// list.forEach(System.out::println);DaoUtil.closeSqlSession(sqlSession);}
}
发现这里执行了多条sql,但是我只需要List集合中第一个学生的所有数据

这里就需要进行懒加载!
将上面的StudentMapper改为:
// mybatis底层默认立即加载// FetchType.DEFAULT 从配置文件进行读取加载// FetchType.EAGER 立即加载// FetchType.LAZY 延迟加载,懒加载@Results({ @Result(column = "classid", property = "classid"),@Result(column = "classid", property = "clazz", one = @One(select = "mapper.ClazzMapper.selectAll", fetchType = FetchType.LAZY)) })@Select("select * from student")public List<Student> findStudentAndClassid();

就解决了查询一个Student而执行了多条SQL的问题
缓存
什么是缓存?
缓存(cache),数据交换的缓冲区,当应用程序需要读取数据时,先从数据库中将数据取出,放置在缓冲区中,应用程序从缓冲区读取数据。

特点:数据库取出的数据保存在内存中,具备快速读取和使用。
限制:读取时无需再从数据库获取,数据可能不是最新的;导致数据不一致性。
缓存的术语
针对缓存数据:
命中 需要的数据在缓存中找到结果。
未命中 需要的数据在缓存中未找到,重新获取。

什么是MyBatis 缓存?
功能 减少Java Application 与数 据库的交互次数,从而提升程 序的运行效率;
方式 通过配置和定制。
缓存的适用性
适合使用缓存: 经常查询并且不经常改变的 数据的正确与否对最终结果影响不大的 比如:一个公司的介绍,新闻等
不适合用于缓存: 经常改变的数据 数据的正确与否对最终结果影响很大 比如商品的库存,股市的牌价等
缓存的分类

一级缓存
将数据放在SqlSession对象中,一般默认开启一级缓存

引入案例
StudentMapper
@Select("select * from student where sid=#{v}")public Student findStudentBySid(int sid);
测试类
情况1:
SqlSession sqlSession = DaoUtil.getSqlSession();
StudentMapper stuMapper = sqlSession.getMapper(StudentMapper.class);
Student s1 = stuMapper.findStudentBySid(10);
System.out.println(s1);
System.out.println();
Student s2 = stuMapper.findStudentBySid(10);
System.out.println(s1 == s2);//true
DaoUtil.closeSqlSession(sqlSession);

从同一个SqlSession的一级缓存中拿的Student是同一个对象
情况2:从两个SqlSession的一级缓存中查询同一个对象,返回的不是同一个Student对象
【发生了一级缓存失效】
SqlSession sqlSession1 = DaoUtil.getSqlSession();
StudentMapper stuMapper1 = sqlSession1.getMapper(StudentMapper.class);
Student s1 = stuMapper1.findStudentBySid(10);
System.out.println(s1);
for (int i = 0; i < 100; i++) {System.out.print(".");
}
System.out.println();
SqlSession sqlSession2 = DaoUtil.getSqlSession();
StudentMapper stuMapper2 = sqlSession2.getMapper(StudentMapper.class);Student s2 = stuMapper2.findStudentBySid(10);
System.out.println(s2);System.out.println(s1 == s2);// false

情况3:
清空SQLSession后,查询的不是同一个Student对象
【发生了一级缓存失效】
SqlSession sqlSession = DaoUtil.getSqlSession();
StudentMapper stuMapper = sqlSession.getMapper(StudentMapper.class);
Student s1 = stuMapper.findStudentBySid(10);
System.out.println(s1);
for (int i = 0; i < 100; i++) {System.out.print(".");
}
System.out.println();
sqlSession.clearCache();//清空SqlSession()
Student s2 = stuMapper.findStudentBySid(10);
System.out.println(s2);
System.out.println(s1 == s2);// false
DaoUtil.closeSqlSession(sqlSession);

关闭sqlsession 或者清空sqlsession缓存都可以实现
注意:当调用sqlsession的修改,添加,删除,commit(),close() 等方法时, 就会清空一级缓存
一级缓存的配置

一级缓存的工作流程


一级缓存失效的情况
1.不同SqlSession对应不同的一级缓存
2.同一个SqlSession单查询条件不同
3.同一个SqlSession两次查询期间执行了任何一次增删改操作
4.同一个SqlSession两次查询期间手动清空了缓存
案例:
MappertStudent
@Insert("insert into student(sname) values (#{sname})")
public int addStudent(Student s);
@Select("select * from student where sid=#{v}")
public Student findStudentBySid(int sid);
package test;import java.util.List;import org.apache.ibatis.session.SqlSession;import bean.Student;
import dao.DaoUtil;
import mapper.StudentMapper;public class Test03 {public static void main(String[] args) {SqlSession sqlSession = DaoUtil.getSqlSession();StudentMapper stuMapper = sqlSession.getMapper(StudentMapper.class);Student s1 = stuMapper.findStudentBySid(10);System.out.println(s1);for (int i = 0; i < 100; i++) {System.out.print(".");}stuMapper.addStudent(new Student());System.out.println();
// sqlSession.clearCache();//清空SqlSession()Student s2 = stuMapper.findStudentBySid(10);System.out.println(s2);System.out.println(s1 == s2);// false}
}

这里在两个查询之间进行了插入insert数据操作,就使一级缓存失效了,第二次查询的数据不是从缓存中拿,而是从数据库中去查询。
二级缓存


二级缓存就是在SqlSessionFactory,然后通过同一个Factory工厂,去获得相同的Cache,通过namespace去拿到对应的Student对象
XML实现
在mybatis中进行配置的参数说明:

<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><properties resource="jdbc.properties"></properties><settings><!-- 全局启用或者禁用延迟加载<setting name=" lazyLoadingEnabled" value="true" />当启用时有延迟加载属性的对象会在被调用时按需进行加载,如果设置为false,会按层级进行延迟加载,默认为true<setting name=" aggressiveLazyLoading" value="true" /> --><setting name="cacheEnabled" value="true"/></settings><typeAliases><!-- 给单个类起别名 --><!-- <typeAlias alias="Student" type="bean.Student"/> --><!-- 批量别名定义,包扫描,别名为类名,扫描整个包下的类 --><package name="bean" /></typeAliases><environments default="development"><environment id="development"><transactionManager type="JDBC" /><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}" /><property name="url" value="${jdbc.url}" /><property name="username" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" /></dataSource></environment></environments><mappers><!-- 注册sqlmapper文件 --><!-- 1.同包 接口和sqlMapper 2.同名 接口和sqlMapper 3.sqlMapper的namespace指向接口的类路径 --><!-- <mapper resource="mapper/StudentMapper.xml" /> --><!-- <mapper class="mapper.StudentMapper"/> --><package name="mapper" /></mappers>
</configuration>
step1:
设置为true
<settings><!-- 全局启用或者禁用延迟加载<setting name=" lazyLoadingEnabled" value="true" />当启用时有延迟加载属性的对象会在被调用时按需进行加载,如果设置为false,会按层级进行延迟加载,默认为true<setting name=" aggressiveLazyLoading" value="true" /> --><setting name="cacheEnabled" value="true"/></settings>
step2:
表明这个映射文件开启了二级缓存
<cache/>
step3:
useCache="true"表明这条查询用到了二级缓存
<select id="findStudent" parameterType="int"resultType="student" useCache="true">select * from student where sid = #{value}</select>

注解实现

step1:
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><properties resource="jdbc.properties"></properties><settings><!-- 全局启用或者禁用延迟加载<setting name=" lazyLoadingEnabled" value="true" /><setting name=" aggressiveLazyLoading" value="true" /> --><setting name="cacheEnabled" value="true"/></settings><typeAliases><!-- 给单个类起别名 --><!-- <typeAlias alias="Student" type="bean.Student"/> --><!-- 批量别名定义,包扫描,别名为类名,扫描整个包下的类 --><package name="bean" /></typeAliases><environments default="development"><environment id="development"><transactionManager type="JDBC" /><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}" /><property name="url" value="${jdbc.url}" /><property name="username" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" /></dataSource></environment></environments><mappers><!-- 注册sqlmapper文件 --><!-- 1.同包 接口和sqlMapper 2.同名 接口和sqlMapper 3.sqlMapper的namespace指向接口的类路径 --><!-- <mapper resource="mapper/StudentMapper.xml" /> --><!-- <mapper class="mapper.StudentMapper"/> --><package name="mapper" /></mappers>
</configuration>
step2:
在接口前面加上@CacheNamespace(blocking = true),表示这个接口中的所有查询都是二级缓存
package mapper;
//让此处的所有内容都为二级缓存
@CacheNamespace(blocking = true)
public interface StudentMapper {@Select("select * from student where sid=#{v}")public Student findStudentBySid(int sid);
}
案例:
说明使用到了二级缓存,需要实体类实现序列化接口


序列化后的两个student对象不是同一个对象,二级缓存的数据存在磁盘上。

二级缓存的缺点
当数据库服务器和客户端是通过网络传输的,这里用二级缓存是为了减少由于网络环境不好加载时间。主要是为了解决数据库不在本机,且网络不稳定带来的问题,但是现在不推荐使用
1.Mybatis 的二级缓存相对于一级缓存来说, 实现了缓存数据的共享,可控性也更强;
2.极大可能会出现错误数据,有设计上的缺陷, 安全使用的条件比较苛刻;
3.分布式环境下,必然会出现读取到错误 数据,所以不推荐使用。
分布式就是同一个数据库连接多台服务器,给多个用户服务。二级缓存在分布式情况下必然会出错,二级缓存绝对不可能用。

但是现在基本不用,弊端如下:

案例完整代码:
bean.Student实体类
package bean;import java.io.Serializable;
import java.util.Date;public class Student implements Serializable{private int sid;private String sname;private Date birthday;private String Ssex;private int classid;private Clazz clazz;public int getSid() {return sid;}public void setSid(int sid) {this.sid = sid;}public String getSname() {return sname;}public void setSname(String sname) {this.sname = sname;}public Date getBirthday() {return birthday;}public void setBirthday(Date birthday) {this.birthday = birthday;}public String getSsex() {return Ssex;}public void setSsex(String ssex) {Ssex = ssex;}public int getClassid() {return classid;}public void setClassid(int classid) {this.classid = classid;}public Clazz getClazz() {return clazz;}public void setClazz(Clazz clazz) {this.clazz = clazz;}public Student(int sid, String sname, Date birthday, String ssex, int classid, Clazz clazz) {super();this.sid = sid;this.sname = sname;this.birthday = birthday;Ssex = ssex;this.classid = classid;this.clazz = clazz;}public Student() {super();}@Overridepublic String toString() {return "Student [sid=" + sid + ", sname=" + sname + ", birthday=" + birthday + ", Ssex=" + Ssex + ", classid="+ classid + ", clazz=" + clazz + "]";}
}
Daoutil工具类
package dao;import java.io.IOException;
import java.io.InputStream;import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;public class DaoUtil {static SqlSessionFactory factory = null;static {try {// 1.读取配置文件InputStream is = Resources.getResourceAsStream("mybatis-config.xml");// 2.生产sqlSession的工厂factory = new SqlSessionFactoryBuilder().build(is);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public static SqlSession getSqlSession() {// 3.返回sqlSession对象return factory.openSession();}public static void closeSqlSession(SqlSession sqlSession) {// 4.释放资源sqlSession.close();}
}
StudentMapper
package mapper;import java.util.List;
import java.util.Map;import org.apache.ibatis.annotations.CacheNamespace;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.DeleteProvider;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.InsertProvider;
import org.apache.ibatis.annotations.One;
import org.apache.ibatis.annotations.Options;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Result;
import org.apache.ibatis.annotations.Results;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.SelectProvider;
import org.apache.ibatis.annotations.Update;
import org.apache.ibatis.annotations.UpdateProvider;
import org.apache.ibatis.jdbc.SQL;
import org.apache.ibatis.mapping.FetchType;
import org.apache.ibatis.session.RowBounds;import bean.Student;//让此处的所有内容都为二级缓存
@CacheNamespace(blocking = true)
public interface StudentMapper {@Insert("insert into student(sname) values (#{sname})")public int addStudent(Student s);// 物理分页,多次读取磁盘,占用内存小@Select("select * from student limit #{cpage},#{size}")public List<Student> selectLimit(@Param("cpage") int cpage, @Param("size") int size);// 逻辑分页,减少对磁盘的读取,但是占用内存空间大@Select("select * from student")public List<Student> findStudentRowBounds(RowBounds rb);// 分页插件(推荐)@Select("select * from student")public List<Student> findStudentPageHelper();// mybatis底层默认立即加载// FetchType.DEFAULT 从配置文件进行读取加载// FetchType.EAGER 立即加载// FetchType.LAZY 延迟加载,懒加载@Results({ @Result(column = "classid", property = "classid"),@Result(column = "classid", property = "clazz", one = @One(select = "mapper.ClazzMapper.selectAll", fetchType = FetchType.LAZY)) })@Select("select * from student")public List<Student> findStudentAndClassid();@Select("select * from student where sid=#{v}")public Student findStudentBySid(int sid);
}测试类
package test;import org.apache.ibatis.session.SqlSession;import bean.Student;
import dao.DaoUtil;
import mapper.StudentMapper;public class Test04 {public static void main(String[] args) {SqlSession sqlSession1 = DaoUtil.getSqlSession();StudentMapper stuMapper1 = sqlSession1.getMapper(StudentMapper.class);Student s1 = stuMapper1.findStudentBySid(10);System.out.println(s1);DaoUtil.closeSqlSession(sqlSession1);SqlSession sqlSession2 = DaoUtil.getSqlSession();StudentMapper stuMapper2 = sqlSession2.getMapper(StudentMapper.class);Student s2 = stuMapper2.findStudentBySid(10);System.out.println(s1);DaoUtil.closeSqlSession(sqlSession2);}
}
自定义缓存的分类

总结(面试题汇总):
一级缓存和二级缓存的区别:
一级缓存指的是一个对象存到了SqlSession里面了,它是内存式的缓存,写在内存上的
二级缓存指的是缓存在SqlSessionFactory里面了,它是写在磁盘上的
二级缓存不用的原因:
分布式环境下,必然会出现读取到错误 数据,所以不推荐使用。
分页查询
• 什么是缓存
• 数据交换的缓冲区,当应用程序需要读取数据时,先从数据库中将数据取出,放置在缓冲区中,应用程序从缓冲区读取数据;
• 什么是一级缓存
• 相对同一个 SqlSession 对象而言的缓存;
• 什么是二级缓存
• 一个 namespace 下的所有操作语句,都影响着同一个Cache;
• 自定义缓存的方式
• 实现 org. apache. ibatis. cache. Cache 接口自定义缓存;
• 引入 Redis 等第三方内存库作为 MyBatis 缓存。
补充:
缓存击穿、雪崩、穿透
缓存击穿、雪崩、穿透
相关文章:
Mybatis【分页插件,缓存,一级缓存,二级缓存,常见缓存面试题】
文章目录 MyBatis缓存分页延迟加载和立即加载什么是立即加载?什么是延迟加载?延迟加载/懒加载的配置 缓存什么是缓存?缓存的术语什么是MyBatis 缓存?缓存的适用性缓存的分类一级缓存引入案例一级缓存的配置一级缓存的工作流程一级…...

【Qt开发】QT6.5.3安装方法(使用国内源)亲测可行!!!
目录 🌕下载在线安装包🌕 把安装包放到系统盘🌕开始安装🌕参考文章 🌕下载在线安装包 https://mirrors.nju.edu.cn/qt/official_releases/online_installers/ 🌕 把安装包放到系统盘 我的系统盘是G盘&…...
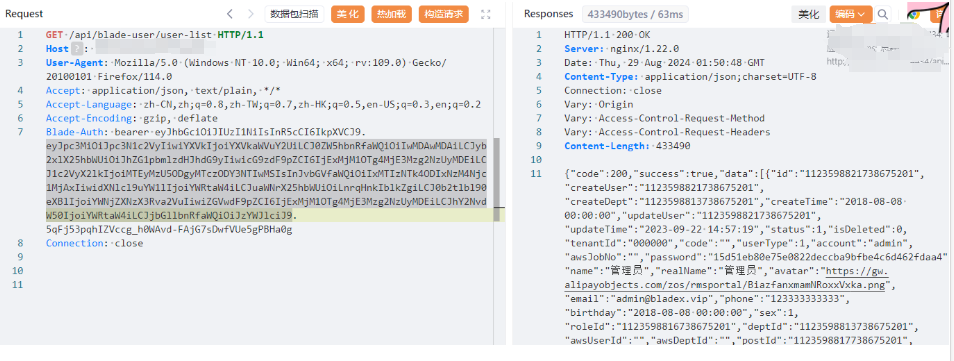
springblade-JWT认证缺陷漏洞CVE-2021-44910
漏洞成因 SpringBlade前端通过webpack打包发布的,可以从其中找到app.js获取大量接口 然后直接访问接口:api/blade-log/api/list 直接搜索“请求未授权”,定位到认证文件:springblade/gateway/filter/AuthFilter.java 后面的代码…...

Chapter 12 Vue CLI脚手架组件化开发
欢迎大家订阅【Vue2Vue3】入门到实践 专栏,开启你的 Vue 学习之旅! 文章目录 前言一、项目目录结构二、组件化开发1. 组件化2. Vue 组件的基本结构3. 依赖包less & less-loader 前言 组件化开发是Vue.js的核心理念之一,Vue CLI为开发者提…...
Ubuntu: 配置OpenCV环境
从从Ubuntu系统安装opencv_ubuntu安装opencv-CSDN博客文章浏览阅读2.3k次,点赞4次,收藏14次。开源计算机视觉(OpenCV)是一个主要针对实时计算机视觉的编程函数库。OpenCV的应用领域包括:2D和3D功能工具包、运动估计、面部识别系统、手势识别、人机交互、…...
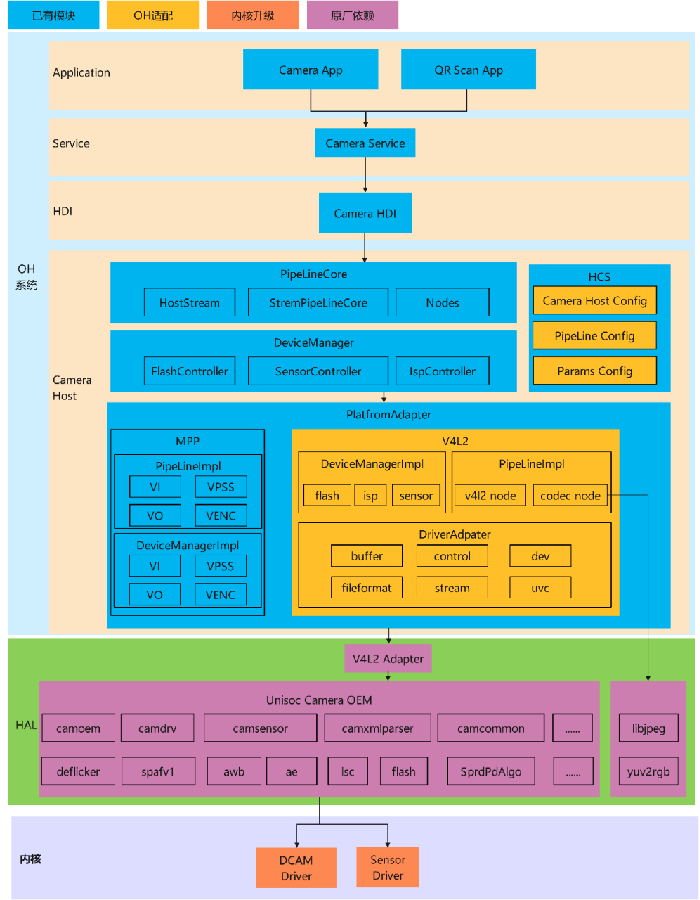
芯片解决方案--SL8541e-OpenHarmony适配方案
摘要 本文描述8541E芯片适配OpenHarmony的整体方案。 本文描述的整体方案,不止适用于8541e,也适用于该芯片厂家的其他芯片,如7863、7885,少部分子系统会略有差异。 整体方案架构 整体方案架构如下图,遵循OpenHarmo…...

Spring Boot之数据访问集成入门
Spring Boot中的数据访问和集成支持功能是其核心功能之一,通过提供大量的自动配置和依赖管理,极大地简化了数据访问层的开发。Spring Boot支持多种数据库,包括关系型数据库(如MySQL、Oracle等)和非关系型数据库&#x…...

Learn ComputeShader 09 Night version lenses
这次将要制作一个类似夜视仪的效果 第一步就是要降低图像的分辨率, 这只需要将id.xy除上一个数字然后再乘上这个数字 可以根据下图理解,很明显通过这个操作在多个像素显示了相同的颜色,并且很多像素颜色被丢失了,自然就会有降低分…...

Java学习第七天
成员方法分类: 静态成员方法(有static修饰 属于类)建议用类名访问,也可以用对象访问 实例成员方法(无static修饰 属于对象)只能用对象出发访问 使用static来定义一些工具类 工具类直接使用类名.方法调用即…...

深入剖析 Redis 基础及其在 Java 应用中的实战演练
引言 在现代分布式系统和高并发应用中,缓存系统是不可或缺的一环,而 Redis 作为一种高性能的内存数据存储以其丰富的数据结构和快速的读写性能,成为了众多开发者的首选。本篇博客将详细介绍 Redis 的基础知识,并通过 Java 代码演…...

Why I‘m getting 404 Resource Not Found to my newly Azure OpenAI deployment?
题意:为什么我新部署的Azure OpenAI服务会出现404资源未找到的错误? 问题背景: Ive gone through this quickstart and I created my Azure OpenAI resource created a model deployment which is in state succeedded. I also playaround …...

【word导出带图片】使用docxtemplater导出word,通知书形式的word
一、demo-导出的的 二、代码操作 1、页面呈现 项目要求,所以页面和导出来的word模版一致 2、js代码【直接展示点击导出的js代码】 使用插件【先下载这五个插件,然后页面引入插件】 import docxtemplater from docxtemplater import PizZip from pizzip …...

微信小程序路由跳转之间的区别
navigateTo: 功能描述: navigateTo用于保留当前页面,跳转到应用内的某个页面。但是不能跳到 tabbar 页面。 页面栈变化: 当使用navigateTo进行页面跳转时,当前页面会被推入页面栈中,但不会被销毁࿰…...

centos安装docker并配置加速器
docker安装与卸载: 1、检查当前是否安装docker yum list installed | grep docker2、卸载docker 根据yum list installed | grep docker查询出来的内容,逐个进行删除 yum remove docker.x86 64 -y3、启动与关闭docker 4、删除/etc/docker文件夹 如果…...

【软件测试】设计测试用例
目录 📕引言 🍀测试用例 🚩概念 🚩设计测试用例的万能公式 🏀常规思考逆向思维发散性思维 🏀万能公式 🎄设计测试用例的方法 🚩基于需求的设计方法 🏀明确需求中…...

Kafka【十三】消费者消费消息的偏移量
偏移量offset是消费者消费数据的一个非常重要的属性。默认情况下,消费者如果不指定消费主题数据的偏移量,那么消费者启动消费时,无论当前主题之前存储了多少历史数据,消费者只能从连接成功后当前主题最新的数据偏移位置读取&#…...
)
Python 的语法元素(容易忘记的)
文章目录 同步赋值同步赋值的相关操作同步赋值的原理 同步赋值 同步赋值是 Python 语言的一个强大功能,它让代码更加紧凑和高效,尤其是在处理多个变量时。 同步赋值的相关操作 简单同步赋值: 如果你想同时初始化多个变量到不同的值&#x…...

找到字符串中所有字母异位词问题
欢迎跳转我的主页:羑悻的小杀马特-CSDN博客 目录: 一题目简述: 二思路汇总: 三解答代码: 一题目简述: leetcode题目链接:. - 力扣(LeetCode) 二思路汇总: …...

QEMU用户模式测试AARCH64程序
QEMU的两种模式 QEMU(快速模拟器)是一个开源的机器模拟器和虚拟化器,它能够模拟多种处理器架构,并且可以在不同平台上运行。QEMU 支持两种模式:用户模式和系统模式。 用户模式(User Mode)&…...

机器学习(五) -- 监督学习(8) --神经网络2
机器学习系列文章目录及序言深度学习系列文章目录及序言 上篇:机器学习(五) -- 监督学习(8) --神经网络1 下篇: 前言 tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程
中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 掌握中兴光猫的设备管理和权限获取能力是网络管理员和技术爱好者…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...