ChatGPT原理解析
文章目录
- Transformer
- 模型结构
- 构成组件
- 整体流程
- GPT
- 预训练
- 微调模型
- GPT2
- GPT3
- 局限性
- GPT4
- 相关论文
Transformer
Transformer,这是一种仅依赖于注意力机制而不使用循环或卷积的简单模型,它简单而有效,并且在性能方面表现出色。
在时序模型中,2017年最常用的模型是循环神经网络(RNN),RNN是一种序列模型,通过将之前的信息存储在隐藏状态中,使得它能够有效地处理时序信息。然而,由于RNN是按照时间步骤逐个计算的,因此它不易并行化,导致它在计算性能上存在缺陷。
Transformer模型完全基于注意力机制,而不再使用循环神经网络。由于注意力机制可以并行化,因此Transformer具有更好的并行性能和更好的实验结果。
模型结构
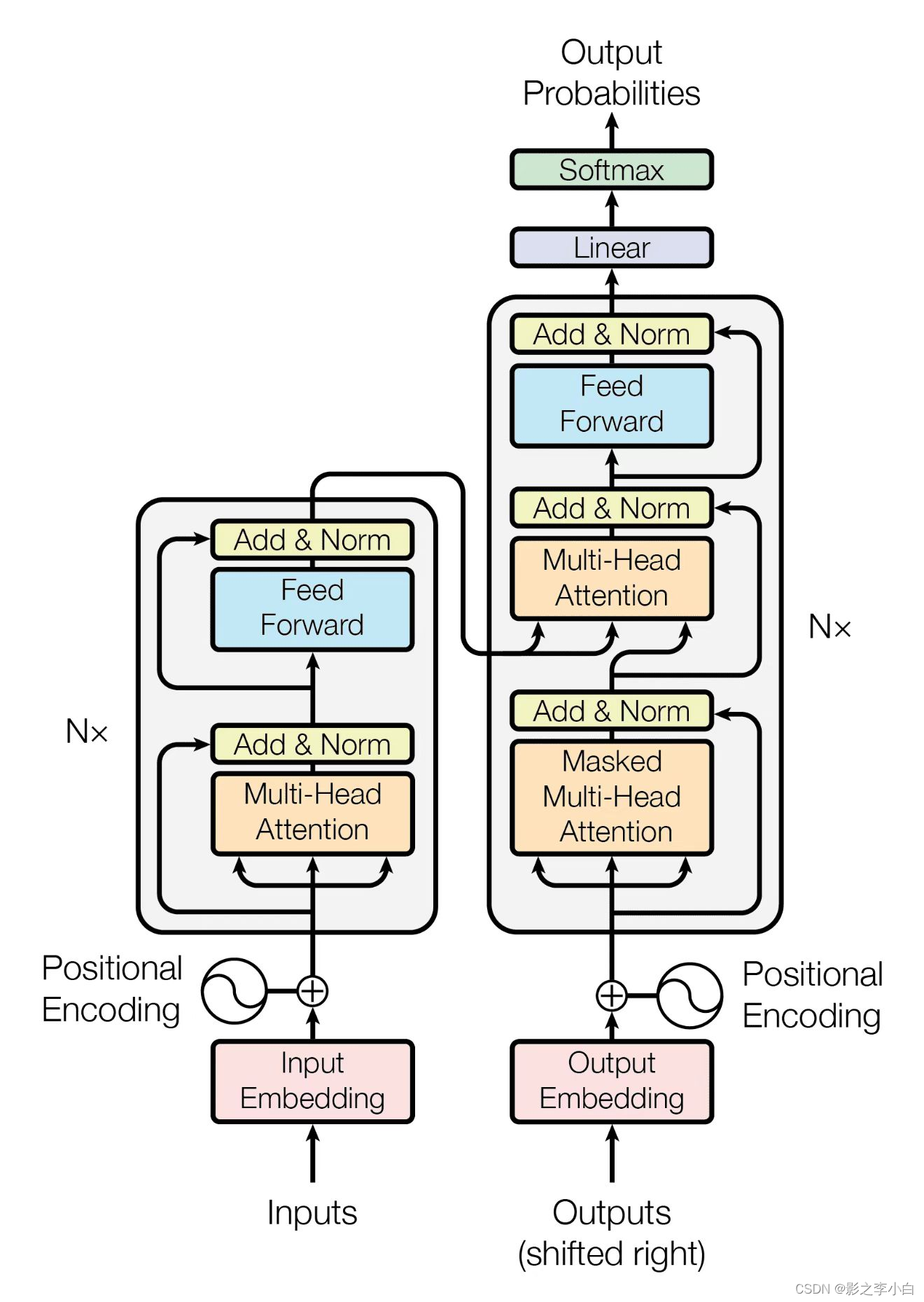
构成组件
- 编码器和解码器:图中左侧为编码器,右侧为解码器。
- 注意力机制:注意力函数是将一个query和一系列key-value映射成一个output的函数,这里的query、key、value、output都是一些向量。权重是由value对应的key和query的compatibility function(相似度)计算得来的,Transformer里面用的注意力算法是“Scaled Dot-Product Attention”。
- 多头注意力(Multi-Head Attention):把query、key、value投影到一个低维,投影h次,然后再做h次的注意力函数,将每个函数的输出并在一起,再投影回来,得到最终的输出。
- 带掩码自注意力层(Masked Multi-Head Attention): 因为在解码器中,算第n个query对应的输出的时候,是不能看到后面内容的值的,所以后面所有内容的权重要通过这种方式设置成0。
- 前馈网络(fully connected feed-forward network):可以理解为一个MLP(多层感知器),会利用它来进行语义空间的转换;Attention层用于抓取整个序列的信息并进行汇聚。
- Embeddings:输入是一个个的词,或者叫词源(token),需要把它映射成一个个向量。Embeddings就是给定任何一个词,用长为d的一个向量来表示它。
- Positional Encoding:Attention机制缺乏时序信息。Positional Encoding可以将每个词在句子中的位置信息加入到嵌入层中,从而为Attention机制提供了时序信息。
整体流程
- 输入数据生成词的嵌入式向量表示(Embedding),生成位置编码(Positional
Encoding,简称PE)。 - 进入Encoders部分。先进入多头注意力层(Multi-Head Attention),是自注意力处理,然后进入全连接层(又叫前馈神经网络层),每层都有ResNet、Add &Norm。
- 每一个Encoder的输入,都来自前一个Encoder的输出,但是第一个Encoder的输入就是 Embedding+ PE。
- 进入Decoders部分。先进入第一个多头注意力层(是Masked自注意力层),再进入第二个多头注意力层(是 Encoder-Decoder 注意力层),每层都有ResNet、Add&Norm。
- 每一个Decoder 都有两部分输入。
Decoder的第一层(Maksed多头自注意力层)的输入,都来自前一个Decoder的输出但是第一个Decoder是不经过第一层的(因为经过算出来也是0)。
Decoder 的第二层(Encoder-Decoder 注意力层)的输入,Query都来自该Decoder的第一层,且每个Decoder的这一层的Key、Value都是一样的,均来自最后一个Encoder。 - 最后经过 Linear、Softmax归一化。
GPT
论文作者取了标题中“generative pre-training”,将模型命名为GPT。
在自然语言理解中,存在许多不同的任务,但标记数据相对较少。因此,针对这个问题,一种解决方法是在没有标注的数据上训练一个预训练模型,然后在有标记的数据上进行微调。
GPT模型基于Transformer架构。与循环神经网络(RNN)相比,Transformer在迁移学习方面更加稳健,因为它具有更结构化的记忆,可以处理更长的文本,并从句子和段落层面提取更好的语义信息。
预训练
该模型从输入的K个单词和模型参数中预测下一个单词的出现概率。将每个单词的预测概率加起来,就得到了目标函数。目标就是通过训练模型,使其能够输出与给定文本类似的文章。
微调模型
在微调任务中有两个目标函数。一个是预测下一个单词,另一个是预测给定完整序列的标签。通过对它们的加权平均来平衡这两个目标函数。
自然语言处理任务的多样性也导致了需要为每个任务构建不同的模型,GPT采用的解决方案是改变输入的形式而不是改变模型本身。
NLP中四种常见的用户任务:
- “分类”(classification),例如对一段文本进行情感分类,判断其是正面还是负面。
- “蕴含”(entailment),即判断一段文本是否蕴含某种假设。
- “相似”(similarity),即判断两段文本的相似程度。
- “多选题”(multiple choice),即从多个答案中选择正确的答案。
在GPT模型中,它们都可以表示为一个序列和对应的标签。
GPT2
在进行下游任务时,使用一个称为“zero shot”的设置。也就是说,在进行下游任务时,不需要下游任务的任何标注信息,也不需要再次训练模型,然后得到了差不多的结果。这种方法的好处是只需训练一个模型,便可以在任何地方使用。
GPT3
GPT3是为了解决GPT2的有效性而设计的。因此,它回到了GPT一开始考虑的few-shot学习的设置,即不再追求太过极致的性能表现,而是在有限的样本上提供有用的信息。
few-shot是指通过提供一些样例来学习,而不是像传统的训练方式那样需要大规模的数据集进行训练。
这样做的好处在于,无需耗费大量的时间和成本来收集和标注数据集,而且模型可以更加关注于样例之间的共性,从而提高模型的泛化能力。
在GPT3的微调设置里,他是要求不做梯度更新的。
在 Meta Learning 中,模型不仅要学习如何解决特定的任务,还要学习如何快速适应新的任务。这样的训练方法有助于提高模型的泛化能力,使得模型在新的领域中表现更好。
in-context learning 是另一种训练模型的方法。它指的是在给定一个任务的上下文中,让模型从少量样本中学习如何解决这个任务。in-context learning 只会对给定的任务产生影响,不会改变模型的权重。
局限性
- 在人类语言中,有些词是必须要记住的,而有些则不是。但GPT3无法区分它们的重要性。
- 由于训练数据来自整个网络上的文章,其有效性可能不高。对于人类来说,这种方式可能不可靠。
- 像许多深度学习模型一样,GPT3无法解释。
GPT4
主要是功能性描述介绍。
- GPT-4是一个大型多模型,它在某些困难的专业和学术基准测试中具有人类水平的表现。
- GPT-4 的一个重点是构建可预测扩展的深度学习堆栈。
- OpenAI在GPT-4的开发和部署过程中实施了各种安全措施和流程,减少了它产生有害内容的能力。
相关论文
《Attention is all you need》[J]. Advances in neural information processing systems, 2017.
《Improving language understanding by generative pre-training》[J]. 2018.
《Language models are unsupervised multitask learners》[J]. OpenAI blog, 2019.
《Language models are few-shot learners》[J]. Advances in neural information processing systems, 2020
《GPT-4 Technical Report》
《GPT-4 System Card》
相关文章:
ChatGPT原理解析
文章目录Transformer模型结构构成组件整体流程GPT预训练微调模型GPT2GPT3局限性GPT4相关论文Transformer Transformer,这是一种仅依赖于注意力机制而不使用循环或卷积的简单模型,它简单而有效,并且在性能方面表现出色。 在时序模型中&#…...

常用算法实现【必会】:sort/bfs/dfs
文章目录常用排序算法实现(Go版本)BFS 广度优先遍历,利用queueDFS 深度优先遍历,利用stack前序遍历(根 左 右)中序遍历(左根右)后序遍历(左 右 根)BFS/DFS 总…...
瑟瑟发抖吧——用了这款软件,我的开发效率提升了50%
一、前言 开发中,一直听到有人讨论是否需要重复造轮子,我觉得有能力的人,轮子得造。但是往往开发周期短,用轮子所节省的时间去更好的理解业务,应用到业务中,也能清晰发现轮子的利弊,一定意义上…...

笔记本只使用Linux是什么体验?
个人主页:董哥聊技术我是董哥,嵌入式领域新星创作者创作理念:专注分享高质量嵌入式文章,让大家读有所得!近期,也有朋友问我,笔记本只安装Linux怎么样,刚好我也借此来表达一下我的感受…...

pipeline业务发布
业务环境介绍公司当前业务上线流程首先是通过nginx灰度,dubbo-admin操作禁用,然后发布上线主机,发布成功后,dubbo-admin启用,nginx启用主机;之前是通过手动操作,很不方便,本次优化为…...

【巨人的肩膀】JAVA面试总结(七)
💪MyBatis 1、谈谈你对MyBatis的理解 Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,加载驱动、创建连接、创建statement等繁杂的过程,开发者开发时只需要关注如何编写SQL语句,可以…...

Python满屏表白代码
目录 前言 爱心界面 无限弹窗 前言 人生苦短,我用Python!又是新的一周啦,本期博主给大家带来了一个全新的作品:满屏表白代码,无限弹窗版!快快收藏起来送给她吧~ 爱心界面 def Heart(): roottk.Tk…...
Spring学习流程介绍
Spring学习流程介绍 Spring技术是JavaEE开发必备技能,企业开发技术选型命中率>90%; Spring有下面两大优势: 简化开发: 降低企业级开发的复杂性 框架整合: 高效整合其他技术,提高企业级应用开发与运行效率 Spring官网: https://spring.io/ Spring发展…...
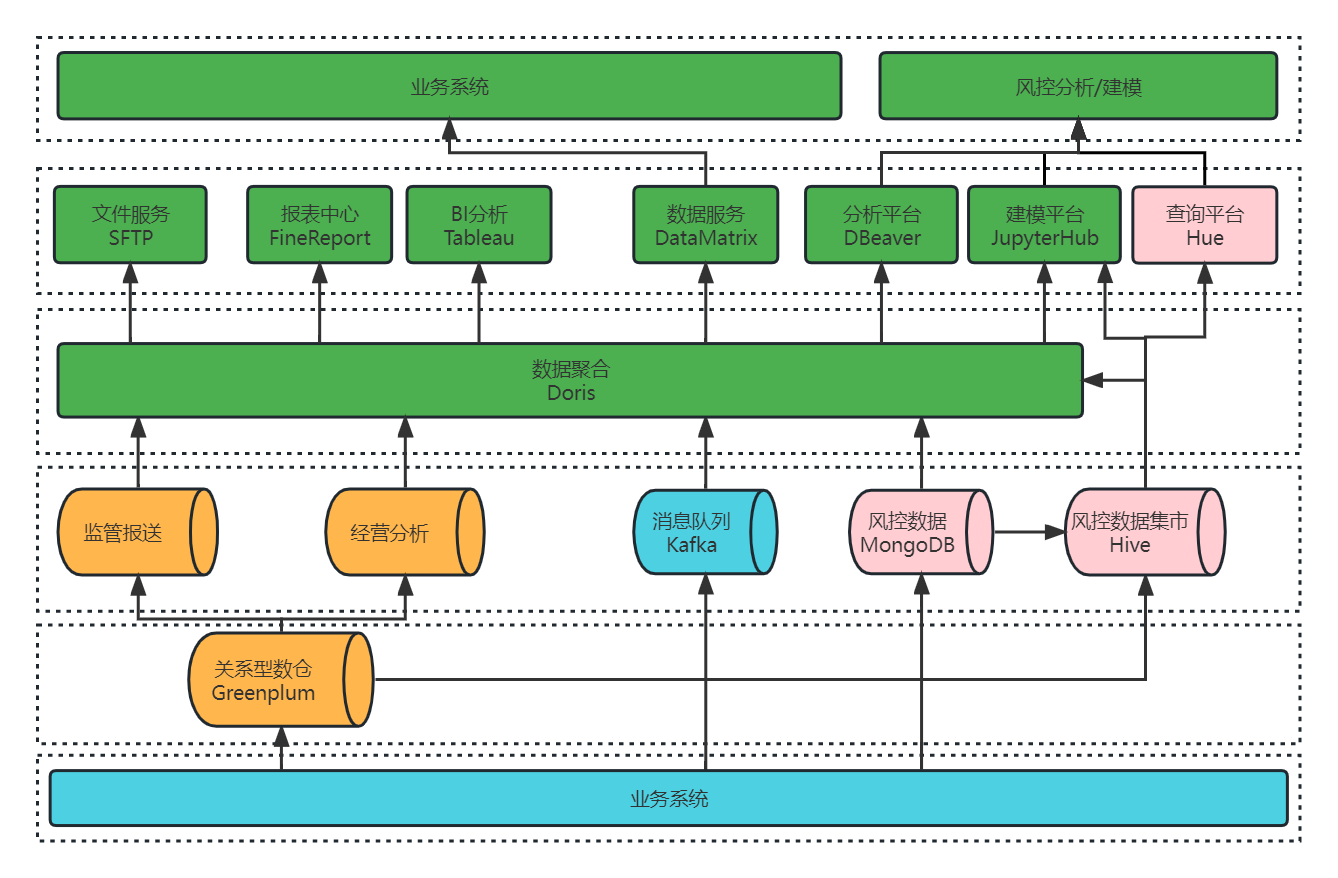
杭银消金基于 Apache Doris 的统一数据查询网关改造
导读: 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风…...
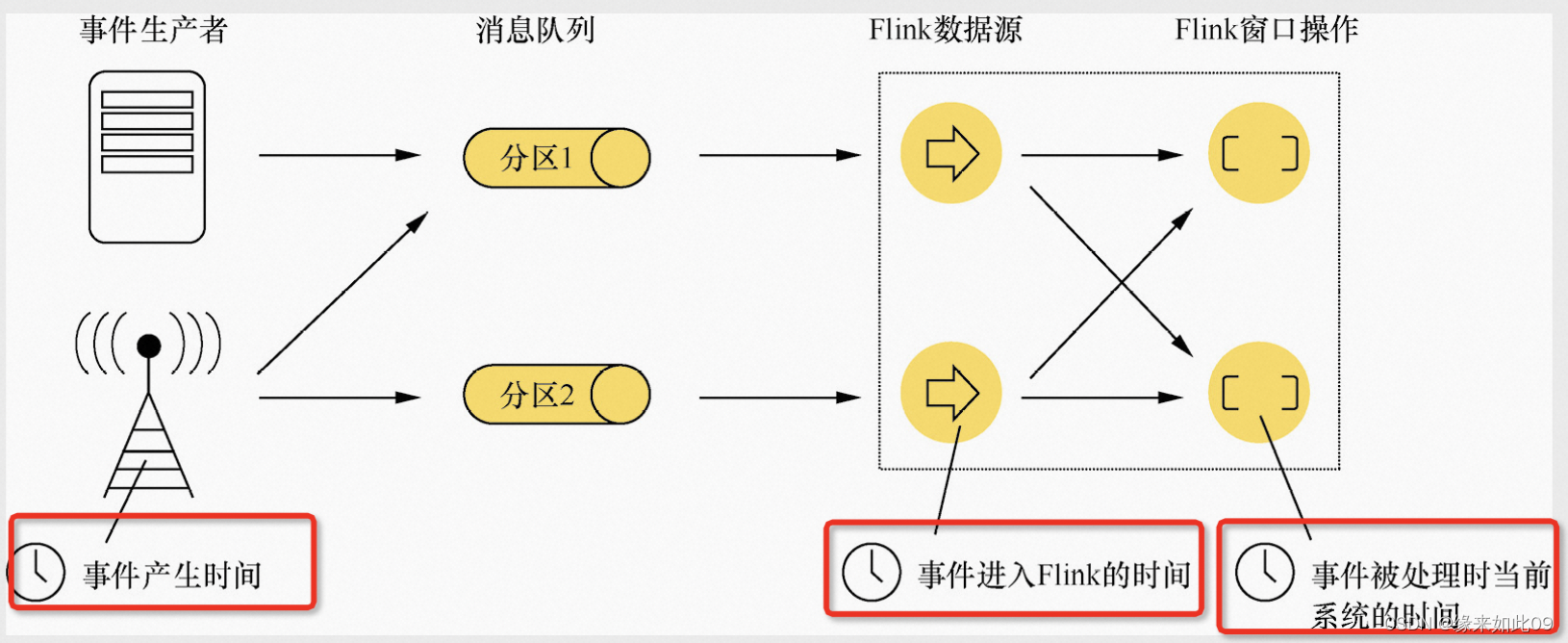
Flink学习笔记(六)Time详解
一、Flink中Time的三种类型: Stream数据中的Time(时间)分为以下3种: 1.Event Time(事件产生的时间): 事件的时间戳,通常是生成事件的时间。Event time 是事件本身的时间,…...

「Vue面试题」在项目中你是如何解决跨域的?
文章目录一、跨域是什么二、如何解决CORSProxy一、跨域是什么 跨域本质是浏览器基于同源策略的一种安全手段 同源策略(Sameoriginpolicy),是一种约定,它是浏览器最核心也最基本的安全功能 所谓同源(即指在同一个域&…...
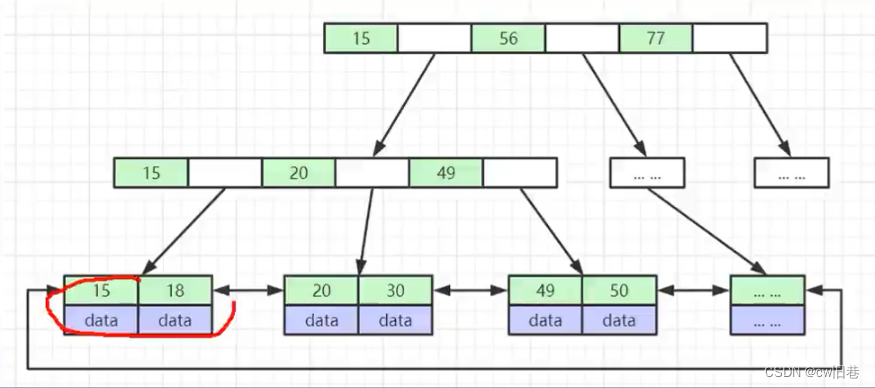
java八股文--数据库
数据库1.索引的基本原理2.聚簇和非聚簇索引的区别3.mysql索引的数据结构以及各自的优劣4.索引的设计原则5.事务的基本特性和隔离级别6.mysql主从同步原理7.简述MyISAM和InnoDB的区别8.简述mysql中索引类型及对数据库性能的影响9.Explain语句结果中各个字段分别表示什么10.索引覆…...

vue中名词解释
No名称略写作用应用场景其他1 单页面应用 (Single-page application) SPA 1,控制整个页面 2,抓取更新数据 3,无需加载,进行页面切换 丰富的交互,复杂的业务逻辑的web前端一般要求后端提供api数据…...

基于Java+SSM+Vue的旅游资源网站设计与实现【源码(完整源码请私聊)+论文+演示视频+包运行成功】
博主介绍:专注于Java技术领域和毕业项目实战 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟 Java项目精品实战案例(200套) 目录 一、效果演示 二、…...
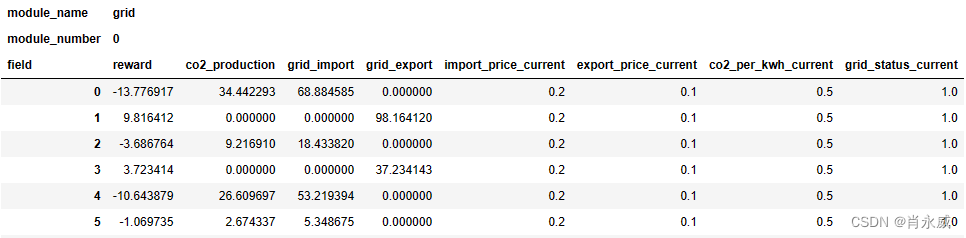
用于人工智能研究的开源Python微电网模拟器pymgrid(入门篇)
pymgrid是一个开源Python库,用于模拟微型电网的三级控制,允许用户创建或自行选择的微电网。并可以使用自定义的算法或pymgrid中包含的控制算法之一来控制这些微电网(基于规则的控制和模型预测控制)。 pymgrid还提供了与OpenAI Gy…...
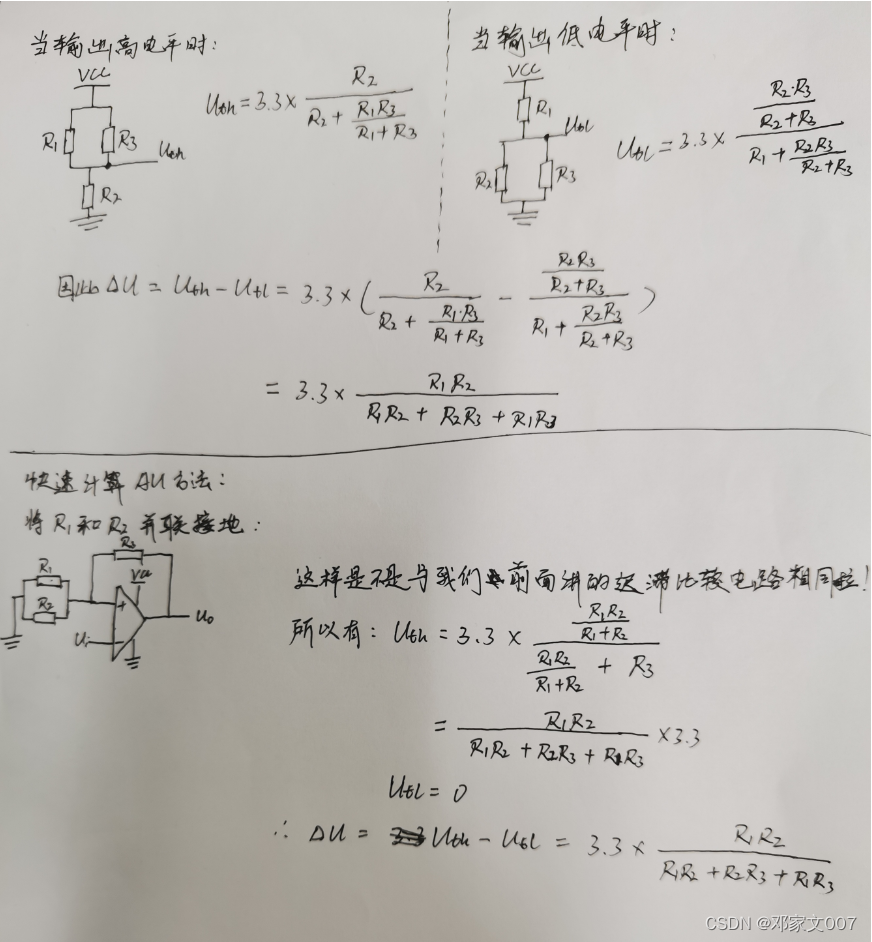
运算放大器:电压比较器、电压跟随器、同相比例放大器
目录一、单限电压比较器二、滞回电压比较器三、窗口电压比较器四、正点原子直流电机驱动器电路分析实战1、电压采集电路2、电流采集电路3、过流检测电路Ⅰ、采用分压后的输入电压:Ⅱ、采用理想电压源的输入电压:Ⅲ、同相输入电压采用的是非理想电压源&am…...

Vector - CAPL - 实时时间on *(续2)
继续继续。。。四、键盘事件这个键盘事件是我个人起的名字,为了方便与其他事件进行区分,为什么要把这一个单独拉出来说呢,因为它的用处实在是太广泛了,基本只要是使用CANoe做一些基本的自动化测试小工具,都会用到它&am…...

数据质量管理的四个阶段
然而,我们需要按照什么流程来对数据质量进行有效的管控,从而提升数据质量,释放数据价值?一般来讲,数据质量控制流程分为4个阶段:启动、执行、检查、处理。在管控过程中这4个阶段需不断循环,螺旋…...
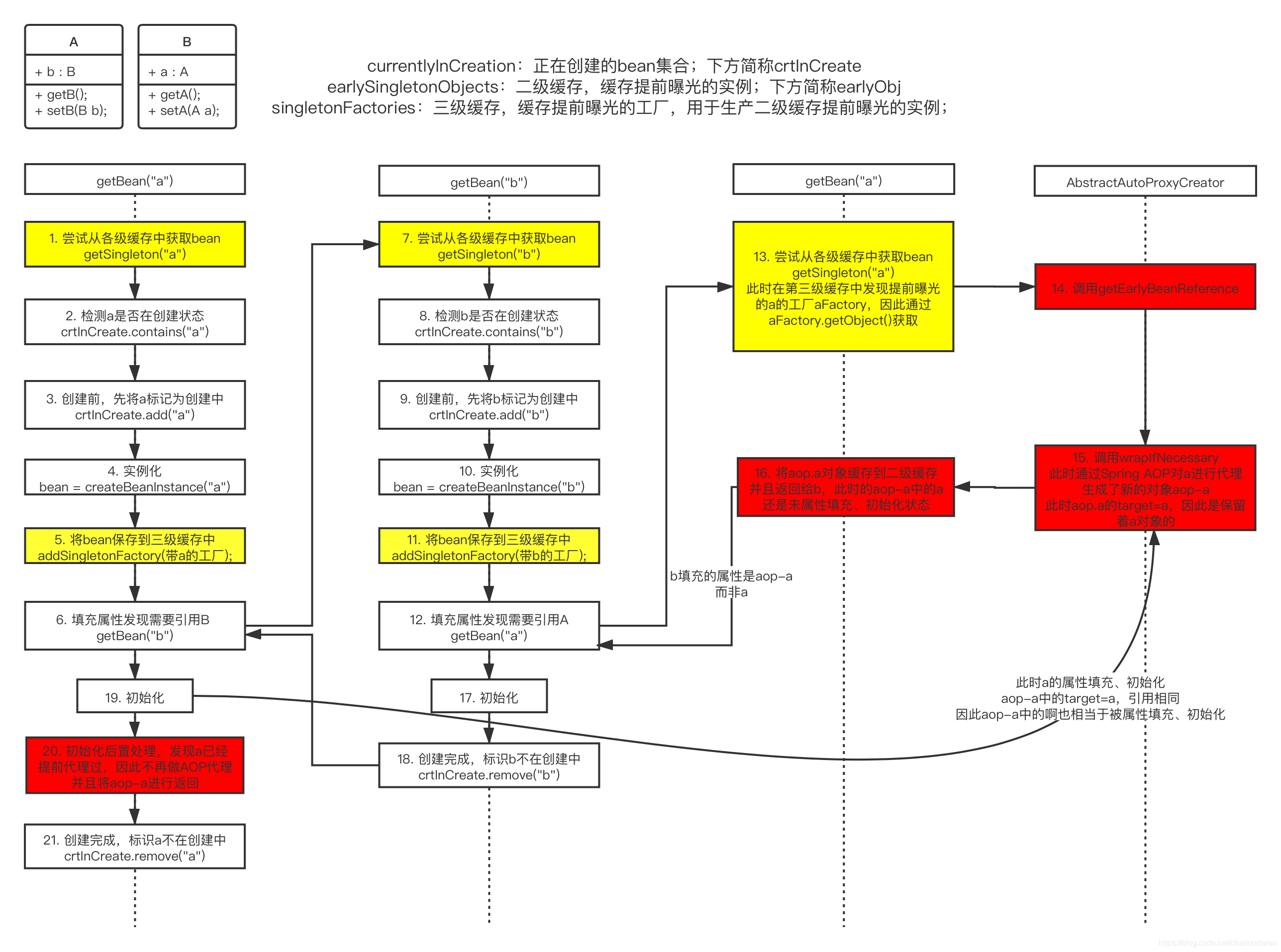
Spring源码面试最难问题——循环依赖
前言 问:Spring 如何解决循环依赖? 答:Spring 通过提前曝光机制,利用三级缓存解决循环依赖(这原理还是挺简单的,参考:三级缓存、图解循环依赖原理) 再问:Spring 通过提前…...
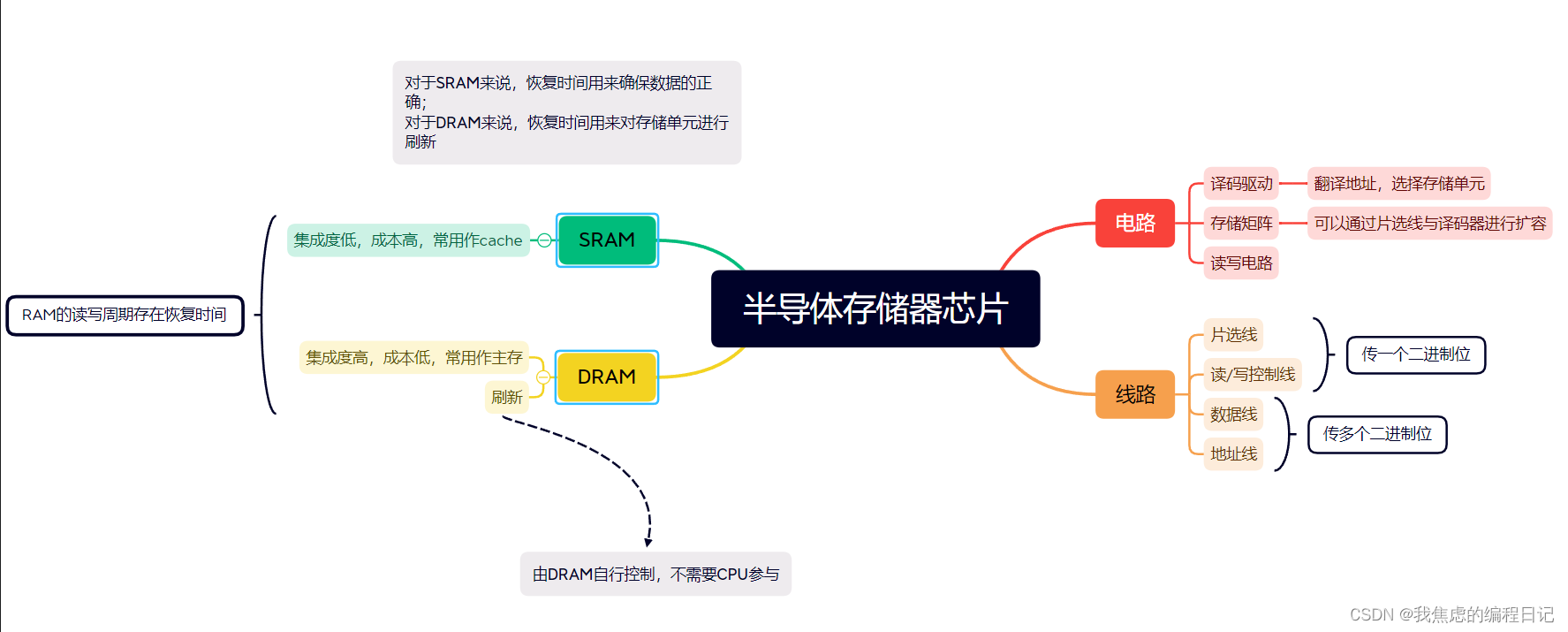
【计组】RAM的深入理解
一、存储机理 RAM的实现逻辑有种,分别是触发器和电容。 SRAM(Static)DRAM(Dynamic)存储方式触发器电容破坏性读出否(触发器具有稳态,能够锁住0或1两种状态)是(电容需要…...

seo网络推广专员有哪些发展前景
SEO网络推广专员的职业发展前景分析 在当今数字经济时代,网络推广已经成为企业营销的核心手段之一。而在网络推广的诸多角色中,SEO网络推广专员(Search Engine Optimization网络推广专员)无疑是其中最为关键的一环。作为一个SEO网…...

从零到一:阿里云天池街景符号识别Baseline实战指南
从零到一:阿里云天池街景符号识别Baseline实战指南 街景符号识别是计算机视觉领域一项极具挑战性的任务,它要求模型能够准确识别并理解街道场景中的各类符号信息。对于刚接触深度学习实战的开发者来说,如何从零开始构建一个完整的识别系统往往…...

MusePublic助力Java开发者:SpringBoot集成指南
MusePublic助力Java开发者:SpringBoot集成指南 1. 为什么Java团队需要MusePublic能力 最近帮一家电商公司做推荐系统升级时,技术负责人跟我聊起一个现实问题:他们用传统协同过滤算法生成的商品推荐列表,点击率已经连续三个季度停…...

突破百度网盘限速瓶颈:BaiduPCS-Go命令行客户端完全指南
突破百度网盘限速瓶颈:BaiduPCS-Go命令行客户端完全指南 【免费下载链接】BaiduPCS-Go iikira/BaiduPCS-Go原版基础上集成了分享链接/秒传链接转存功能 项目地址: https://gitcode.com/GitHub_Trending/ba/BaiduPCS-Go 你是否厌倦了百度网盘那令人抓狂的下载…...

附链小程序测评:支持Word/PDF/PPT/EXCEL/压缩包上传,解决公众号文件嵌入难题
公众号运营中,文件分发存在明确痛点:推文无法直接嵌入附件,第三方链接常出现跳转繁琐、广告弹窗、文件过期等问题,增加运营成本且影响用户体验。附链小程序为微信生态原生工具,核心解决上述痛点,支持公众号…...

【Java外部函数性能优化黄金法则】:20年JVM专家亲授JNI/FFM调优的7大致命误区与3步极速修复方案
第一章:Java外部函数优化的演进脉络与性能本质Java平台对外部函数调用(Foreign Function & Memory API,即JEP 454/464/471/472)的演进,标志着JVM从“纯Java世界”迈向系统级互操作的新纪元。其性能本质并非单纯降低…...

当相机位姿已知:利用COLMAP从稀疏到稠密重建的实战指南
1. 环境准备与数据格式转换 在开始COLMAP重建之前,我们需要确保环境配置正确,并完成相机位姿数据的格式转换。COLMAP支持Windows、Linux和macOS系统,但为了获得最佳性能,建议使用配备NVIDIA显卡的机器,并安装CUDA加速版…...
Pixelorama:从像素小白到艺术大师的完整指南
Pixelorama:从像素小白到艺术大师的完整指南 【免费下载链接】Pixelorama Unleash your creativity with Pixelorama, a powerful and accessible open-source pixel art multitool. Whether you want to create sprites, tiles, animations, or just express yours…...

ModTheSpire模组加载器全攻略:解锁杀戮尖塔无限可能
ModTheSpire模组加载器全攻略:解锁杀戮尖塔无限可能 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 副标题:从零开始的模组探索之旅——让你的游戏体验突破边界…...

【深度剖析】从libgomp TLS内存分配冲突到scikit-learn在ARM平台的兼容性优化
1. ARM架构下TLS内存分配的底层原理 当你在ARM服务器上跑scikit-learn模型时,突然蹦出"cannot allocate memory in static TLS block"错误,这背后其实是线程本地存储(TLS)在作祟。想象每个线程都有自己专属的储物柜&…...