Spark2.x 入门: KMeans 聚类算法
一 KMeans简介
KMeans 是一个迭代求解的聚类算法,其属于 划分(Partitioning) 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量。
ML包下的KMeans方法位于org.apache.spark.ml.clustering包下,其过程大致如下:
1.根据给定的k值,选取k个样本点作为初始划分中心;
2.计算所有样本点到每一个划分中心的距离,并将所有样本点划分到距离最近的划分中心;
3.计算每个划分中样本点的平均值,将其作为新的中心;
循环进行2~3步直至达到最大迭代次数,或划分中心的变化小于某一预定义阈值
显然,初始划分中心的选取在很大程度上决定了最终聚类的质量,和MLlib包一样,ML包内置的KMeans类也提供了名为 KMeans|| 的初始划分中心选择方法,它是著名的 KMeans++ 方法的并行化版本,其思想是令初始聚类中心尽可能的互相远离,具体实现细节可以参见斯坦福大学的B Bahmani在PVLDB上的论文Scalable K-Means++,这里不再赘述。
二 实战
与MLlib版本的Kmeans教程相同,本文亦使用UCI数据集中的鸢尾花数据Iris进行实验,它可以在iris获取,Iris数据的样本容量为150,有四个实数值的特征,分别代表花朵四个部位的尺寸,以及该样本对应鸢尾花的亚种类型(共有3种亚种类型),如下所示:
5.1,3.5,1.4,0.2,setosa
...
5.4,3.0,4.5,1.5,versicolor
...
7.1,3.0,5.9,2.1,virginica
...
在使用前,引入需要的包:
import org.apache.spark.ml.clustering.{KMeans,KMeansModel}
import org.apache.spark.ml.linalg.{Vector,Vectors}
开启RDD的隐式转换:
import spark.implicits._
下文中,我们默认名为spark的SparkSession已经创建。
为了便于生成相应的DataFrame,这里定义一个名为model_instance的case class作为DataFrame每一行(一个数据样本)的数据类型。
注:因为是非监督学习,所以不需要数据中的label,只需要使用特征向量数据就可以。
scala> case class model_instance(features: org.apache.spark.ml.linalg.Vector)
defined class model_instance
在定义数据类型完成后,即可将数据读入RDD[model_instance]的结构中,并通过RDD的隐式转换.toDF()方法完成RDD到DataFrame的转换:
val rawData = sc.textFile("file:///root/data/iris.txt")
rawData: org.apache.spark.rdd.RDD[String] = file:///root/data/iris.txt MapPartitionsRDD[220] at textFile at <console>:56scala> val df = rawData.map(line =>{ model_instance( Vectors.dense(line.split(",").filter(p => p.matches("\\d*(\\.?)\\d*")).map(_.toDouble)) )}).toDF()
df: org.apache.spark.sql.DataFrame = [features: vector]
与MLlib版的教程类似,我们使用了filter算子,过滤掉类标签,正则表达式\\d*(\\.?)\\d*可以用于匹配实数类型的数字,\\d*使用了*限定符,表示匹配0次或多次的数字字符,\\.?使用了?限定符,表示匹配0次或1次的小数点。
在得到数据后,我们即可通过ML包的固有流程:创建Estimator并调用其fit()方法来生成相应的Transformer对象,很显然,在这里KMeans类是Estimator,而用于保存训练后模型的KMeansModel类则属于Transformer:
scala> val kmeansmodel = new KMeans().setK(3).setFeaturesCol("features").setPredictionCol("prediction").fit(df)
kmeansmodel: org.apache.spark.ml.clustering.KMeansModel = kmeans_bdadcf53b52e
与MLlib版本类似,ML包下的KMeans方法也有Seed(随机数种子)、Tol(收敛阈值)、K(簇个数)、MaxIter(最大迭代次数)、initMode(初始化方式)、initStep(KMeans||方法的步数)等参数可供设置,和其他的ML框架算法一样,用户可以通过相应的setXXX()方法来进行设置,或以ParamMap的形式传入参数,这里为了简介期间,使用setXXX()方法设置了参数K,其余参数均采用默认值
与MLlib中的实现不同,KMeansModel作为一个Transformer,不再提供predict()样式的方法,而是提供了一致性的transform()方法,用于将存储在DataFrame中的给定数据集进行整体处理,生成带有预测簇标签的数据集:
scala> val results = kmeansmodel.transform(df)
results: org.apache.spark.sql.DataFrame = [features: vector, prediction: int]
为了方便观察,我们可以使用collect()方法,该方法将DataFrame中所有的数据组织成一个Array对象进行返回:
scala> results.collect().foreach(row => {println( row(0) + " is predicted as cluster " + row(1))})
[5.1,3.5,1.4,0.2] is predicted as cluster 2
...
[6.3,3.3,6.0,2.5] is predicted as cluster 1
...
[5.8,2.7,5.1,1.9] is predicted as cluster 0
...scala> results.show()
+-----------------+----------+
| features|prediction|
+-----------------+----------+
|[5.1,3.5,1.4,0.2]| 0|
|[4.9,3.0,1.4,0.2]| 0|
|[4.7,3.2,1.3,0.2]| 0|
|[4.6,3.1,1.5,0.2]| 0|
|[5.0,3.6,1.4,0.2]| 0|
|[5.4,3.9,1.7,0.4]| 0|
|[4.6,3.4,1.4,0.3]| 0|
|[5.0,3.4,1.5,0.2]| 0|
|[4.4,2.9,1.4,0.2]| 0|
|[4.9,3.1,1.5,0.1]| 0|
|[5.4,3.7,1.5,0.2]| 0|
|[4.8,3.4,1.6,0.2]| 0|
|[4.8,3.0,1.4,0.1]| 0|
|[4.3,3.0,1.1,0.1]| 0|
|[5.8,4.0,1.2,0.2]| 0|
|[5.7,4.4,1.5,0.4]| 0|
|[5.4,3.9,1.3,0.4]| 0|
|[5.1,3.5,1.4,0.3]| 0|
|[5.7,3.8,1.7,0.3]| 0|
|[5.1,3.8,1.5,0.3]| 0|
+-----------------+----------+
only showing top 20 rows
也可以通过KMeansModel类自带的clusterCenters属性获取到模型的所有聚类中心情况:
scala> kmeansmodel.clusterCenters.foreach(center => {println("Clustering Center:"+center)})
Clustering Center:[5.005999999999999,3.4180000000000006,1.4640000000000002,0.2439999999999999]
Clustering Center:[5.901612903225806,2.7483870967741932,4.393548387096774,1.433870967741935]
Clustering Center:[6.85,3.0736842105263147,5.742105263157893,2.071052631578947]
与MLlib下的实现相同,KMeansModel类也提供了计算 集合内误差平方和(Within Set Sum of Squared Error, WSSSE) 的方法来度量聚类的有效性,在真实K值未知的情况下,该值的变化可以作为选取合适K值的一个重要参考:
scala> kmeansmodel.computeCost(df)
res30: Double = 78.94084142614622
相关文章:

Spark2.x 入门: KMeans 聚类算法
一 KMeans简介 KMeans 是一个迭代求解的聚类算法,其属于 划分(Partitioning) 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量。 ML包下的KMeans方法位于org.apach…...

如何快速练习键盘盲打
盲打是指在不看键盘的情况下进行打字,这样可以显著提高打字速度和效率。以下是一些练习盲打的方法: 熟悉键盘布局:首先,你需要熟悉键盘上的字母和符号的位置。可以通过键盘图或者键盘贴纸来帮助记忆。 使用在线打字练习工具&…...

Flask中实现WebSocket需要什么组件
在Flask中实现WebSocket功能,通常不会直接使用Flask本身,因为Flask是一个轻量级的Web框架,主要设计用于处理HTTP请求。然而,你可以通过集成一些第三方库来在Flask应用中支持WebSocket。WebSocket是一种在单个TCP连接上进行全双工通…...

java8 Stream流详解
前言 Java 8引入了一种新的处理集合的方式——Stream API。它提供了一种高级迭代方式,支持函数式编程风格,使得集合操作更加简洁、清晰。本文将详细介绍Java 8 Stream API的核心概念、操作和使用技巧。 Stream API 简介 Stream API是Java 8中的一大亮…...
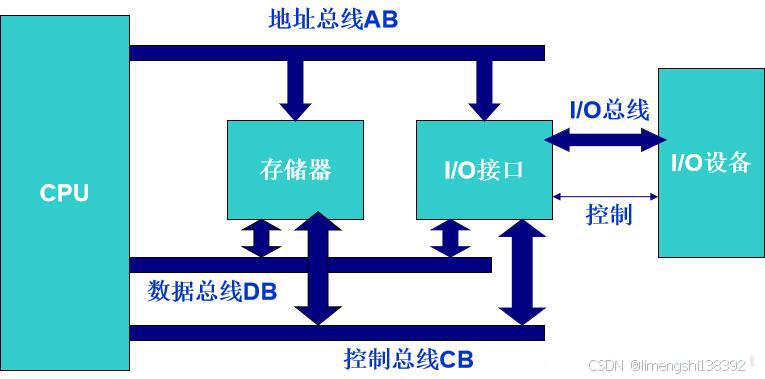
通信工程学习:什么是AB地址总线、DB数据总线、CD控制总线
AB地址总线、DB数据总线、CD控制总线 在计算机体系结构中,总线(Bus)是一种用于在计算机内部各个组件之间传输信息的物理通道。其中,AB地址总线、DB数据总线和CD控制总线是计算机总线系统中非常重要的三个组成部分,它们…...
(更新中……))
CP AUTOSAR标准之EthernetInterface(AUTOSAR_SWS_EthernetInterface)(更新中……)
1 简介和功能概述 该规范指定了AUTOSAR基础软件模块以太网接口的功能、API和配置。 在AUTOSAR分层软件架构[1]中,以太网接口属于ECU抽象层,或者更准确地说,属于通信硬件抽象。 这表明了以太网接口的主要任务: 为上层提供独立于硬件的以太网通信系统接口,该系统…...

Windows系统离线安装使用pm2 管理进程
目录 1. 安装 Node.js 和 npm 2. 创建一个项目目录 3. 初始化 npm 项目 4. 下载 pm2 及其所有依赖 5. 打包 pm2 及其依赖 6. 将打包文件传输到内网服务器 7. 在内网服务器上解压并安装 8. 使用 pm2 总结 在联网的机器上,使用 npm(Node.js 包管理…...
)
4-4.Andorid Camera 之简化编码模板(获取摄像头 ID、选择最优预览尺寸)
一、Camera 简化思路 在 Camera 的开发中,其实我们通常只关注打开相机、图像预览和关闭相机,其他的步骤我们不应该花费太多的精力 为此,应该提供一个工具类,它有处理相机的一些基本工具方法,包括获取摄像头 ID、选择最…...
【深度学习】向量化
1. 什么是向量化 向量化通常是消除代码中显示for循环语句的技巧,在深度学习实际应用中,可能会遇到大量的训练数据,因为深度学习算法往往在这种情况下表现更好,所以代码的运行速度非常重要,否则如果它运行在一个大的数据…...
基于canal的Redis缓存双写
canal地址:alibaba/canal: 阿里巴巴 MySQL binlog 增量订阅&消费组件 (github.com)https://github.com/alibaba/canal 1. 准备 1.1 MySQL 查看主机二进制日志 show master status 查看binlog是否开启 show variables like log_bin 授权canal连接MySQL账号 …...

以太网交换机工作原理学习笔记
在网络中传输数据时需要遵循一些标准,以太网协议定义了数据帧在以太网上的传输标准,了解以太网协议是充分理解数据链路层通信的基础。以太网交换机是实现数据链路层通信的主要设备,了解以太网交换机的工作原理也是十分必要的。 1、以太网协议…...

ECCV`24 | 蚂蚁集团开源风格控制新SOTA!StyleTokenizer:零样本精确控制图像生成
文章链接:https://arxiv.org/pdf/2409.02543 代码&数据集链接: https://github.com/alipay/style-tokenizer 亮点直击 介绍了一种名为StyleTokenizer的新方法,用于在扩散模型中进行风格控制。这种方法允许通过一个任意参考图像实现对生成…...

Flutter的升级和降级步骤
升级 1.版本升级 // 升级到指定版本 flutter upgrade 版本号 // 升级到最新版本 flutter upgrade 2. 更新开发配置 启动 Android Studio。 打开 Settings 对话框,查看 SDK Manager。 如果你已经打开了一个项目,请打开 Tools > SDK Manager。 如果…...

计算机网络与Internet应用
一、计算机网络 1.计算机网络的定义 网络定义:计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享…...

[建模已更新]2024数学建模国赛高教社杯A题:“板凳龙” 闹元宵 思路代码文章助攻手把手保姆级
本系列专栏将包括两大块内容 第一块赛前真题和模型教学,包括至少8次真题实战教学,每期教学专栏的最底部会提供完整的资料百度网盘包括:真题、数据、可复现代码以及文章. 第二块包括赛中详细思路建模、代码的参考助攻, 会提供2024年高教社国赛A的全套参考内容(一般36h内更新完毕…...

Spring Boot-自定义banner
在 Spring Boot 应用中,你可以自定义启动时显示的 banner。这些 banner 可以包括图形、文字或者其他形式的标识。如图所示: 1. 使用 banner.txt 文件 默认情况下,Spring Boot 使用项目的 banner.txt 文件中的内容作为启动时的 banner。你可以…...

2158. 直播获奖(live)
代码 #include<bits/stdc.h> using namespace std; int main() {int n,w,a[100000],cnt[601]{0},i,j,s;cin>>n>>w;for(i0;i<n;i){scanf("%d",&a[i]);cnt[a[i]];int x(i1)*w/100;if(!x) x1;for(j600,s0;j>0;j--){scnt[j];if(s>x){cou…...

python---爬取QQ音乐
如Cookie为非vip,仅能获取非vip歌曲 1.下载包 pip install jsonpath 2.代码 import os import time import requests from jsonpath import jsonpathdef search_and_download_qq_music(query_text):headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; …...

tomato靶场攻略
1.使用nmap扫描同网段的端口,发现靶机地址 2.访问到主页面,只能看到一个大西红柿 3.再来使用dirb扫面以下有那些目录,发现有一个antibot_image 4.访问我们扫到的地址 ,点金目录里看看有些什么文件 5.看到info.php很熟悉࿰…...

Django+Vue3前后端分离学习(一)(项目开始时settings.py里的设置)
一、创建django项目 二、修改settings.py里的配置: 1、修改语言和时区: # 语言编码 LANGUAGE_CODE zh-hansTIME_ZONE UTCUSE_I18N True# 不用时区 USE_TZ False 2、配置数据库: DATABASES {default: {ENGINE: django.db.backends.m…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

AI Agent 为什么必须有“记忆系统”?
导语:大模型不是没有智商,而是经常没有“记性”。真正能长期干活的 Agent,不是靠无限拉长上下文,而是靠一套会压缩、会检索、会遗忘、会治理的外置记忆系统。一、先给结论:Agent 的记忆系统,本质是“上下文…...