数学建模笔记——熵权法(客观赋权法)
数学建模笔记——熵权法[客观赋权法]
- 熵权法(客观赋权法)
- 1. 基本概念
- 2. 基本步骤
- 3. 典型例题
- 3.1 正向化矩阵
- 3.2 对正向化矩阵进行矩阵标准化
- 3.3 计算概率矩阵P
- 3.4 计算熵权
- 3.5 计算得分
- 4. python代码实现
熵权法(客观赋权法)
1. 基本概念
熵权法,物理学名词,按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量;根据信息熵的定义,对于某项指标,可以用熵值来判断某个指标的离散程度,其信息熵值越小,指标的离散程度越大,该指标对综合评价的影响(即权重)就越大,如果某项指标的值全部相等,则该指标在综合评价中不起作用。因此,可利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
- 熵权法是一种客观的赋权方法,它可以靠数据本身得出权重。
- 依据的原理:指标的变异程度越小,所反映的信息量也越少,其对应的权值也应该越低。
另一种表述:越有可能发生的事情,信息量越少。越不可能发生的事情,信息量就越多。其中我们认为 概率 就是衡量事情发生的可能性大小的指标。
那么把 信息量 用字母 I I I表示,概率用 P P P表示,那么我们可以将它们建立一个函数关系:
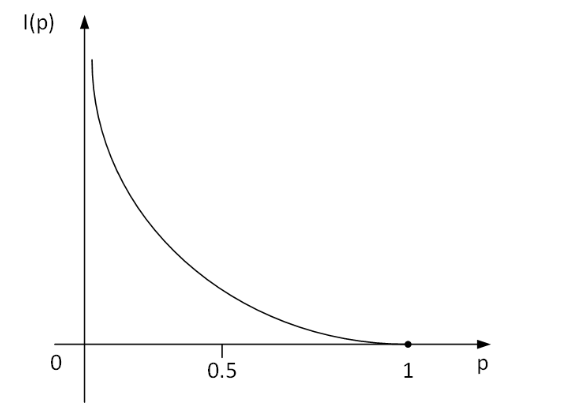
那么,假设 x 表示事件 X 可能发生的某种情况,p(x)表示这种情况发生的概率情况如上图所示,该图像可以用对数函数进行拟合,那
么最终我们可以定义: I ( x ) = − ln ( p ( x ) ) I(x)=-\ln(p(x)) I(x)=−ln(p(x)),因为 0 ≤ p ( x ) ≤ 1 0\leq p(x)\leq1 0≤p(x)≤1,所以 I ( x ) ≥ 0 I(x)\geq0 I(x)≥0。
信息熵的定义
假设 x 表示事件 X 可能发生的某种情况,p(x) 表示这种情况发生的概率我们可以定义: I ( x ) = − ln ( p ( x ) ) I(x)=-\ln(p(x)) I(x)=−ln(p(x)) ,因为 0 ≤ p ( x ) ≤ 1 0\leq p(x)\leq1 0≤p(x)≤1 ,
所以 I ( x ) ≥ 0 I(x)\geq0 I(x)≥0。如果事件 X 可能发生的情况分别为: x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn ,那么我们可以定义事件 X X X 的信息熵为:
H ( X ) = ∑ i = 1 n [ p ( x i ) I ( x i ) ] = − ∑ i = 1 n [ p ( x i ) ln ( p ( x i ) ) ] H(X)=\sum_{i=1}^n\left[p(x_i)I(x_i)\right]=-\sum_{i=1}^n\left[p(x_i)\ln(p(x_i))\right] H(X)=i=1∑n[p(xi)I(xi)]=−i=1∑n[p(xi)ln(p(xi))]
那么从上面的公式可以看出,信息上的本质就是对信息量的期望值。
可以证明的是: p ( x 1 ) = p ( x 1 ) = ⋯ = p ( x n ) = 1 / n p(x_1)=p(x_1)=\cdots=p(x_n)=1/n p(x1)=p(x1)=⋯=p(xn)=1/n时, H ( x ) H(x) H(x)取最大值,此时 H ( x ) = ln ( n ) H(x)=\ln(n) H(x)=ln(n)。(n表示事件发生情况的总数)
2. 基本步骤
熵权法的计算步骤大致分为以下三步:
-
数据标准化
假设有 n n n个要评价的对象, m m m个评价指标(已经正向化了)构成的正向化矩阵如下:
X = [ x 11 x 12 ⋯ x 1 m x 21 x 22 ⋯ x 2 m ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n m ] X=\begin{bmatrix}x_{11}&x_{12}&\cdots&x_{1m}\\x_{21}&x_{22}&\cdots&x_{2m}\\\vdots&\vdots&\ddots&\vdots\\x_{n1}&x_{n2}&\cdots&x_{nm}\end{bmatrix} X= x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1mx2m⋮xnm
设标准化矩阵为 Z Z Z , Z Z Z中元素记为 z i j : z_{ij}: zij:
z i j = x i j ∑ i = 1 n x i j 2 z_{ij}=\frac{x_{ij}}{\sqrt{\sum_{i=1}^nx_{ij}^2}} zij=∑i=1nxij2xij
判断 Z Z Z矩阵中是否存在着负数,如果存在的话,需要对 X X X使用另一种标准化方法对矩阵 X X X进行一次标准化得到 Z Z Z矩阵,其标准化的公式为:
z i j = x i j − m i n { x 1 j , x 2 j , ⋯ , x n j } m a x { x 1 j , x 2 j , ⋯ , x n j } − m i n { x 1 j , x 2 j , ⋯ , x n j } z_{ij}=\frac{x_{ij}-min\{x_{1j},x_{2j},\cdots,x_{nj}\}}{max\{x_{1j},x_{2j},\cdots,x_{nj}\}-min\{x_{1j},x_{2j},\cdots,x_{nj}\}} zij=max{x1j,x2j,⋯,xnj}−min{x1j,x2j,⋯,xnj}xij−min{x1j,x2j,⋯,xnj}这样可以保证 z i j z_{ij} zij在 [0,1] 区间,没有负数。
-
计算概率矩阵P
假设有 n n n个要评价的对象, m m m个评价指标,且经过了上一步处理得到的非负矩阵为:
Z = [ z 11 z 12 ⋯ z 1 m z 21 z 22 ⋯ z 2 m ⋮ ⋮ ⋱ ⋮ z n 1 z n 2 ⋯ z n m ] Z=\begin{bmatrix}z_{11}&z_{12}&\cdots&z_{1m}\\z_{21}&z_{22}&\cdots&z_{2m}\\\vdots&\vdots&\ddots&\vdots\\z_{n1}&z_{n2}&\cdots&z_{nm}\end{bmatrix} Z= z11z21⋮zn1z12z22⋮zn2⋯⋯⋱⋯z1mz2m⋮znm
计算概率矩阵 P P P,其中 P P P中每一个元素 p i j p_{ij} pij,的计算公式如下:
p i j = z i j ∑ i = 1 n z i j p_{ij}\:=\:\frac{z_{ij}}{\sum_{i=1}^nz_{ij}} pij=∑i=1nzijzij保证每一列的加和为1,即每个指标所对应的概率和为1。
-
计算熵权
信息熵的计算:
对于第 j j j个指标而言,其信息嫡的计算公式为:
e j = − 1 ln n ∑ i = 1 n p i j ln ( p i j ) , ( j = 1 , 2 , ⋯ , m ) e_j=-\frac{1}{\ln n}\sum_{i=1}^np_{ij}\ln(p_{ij}),\quad(j=1,2,\cdots,m) ej=−lnn1i=1∑npijln(pij),(j=1,2,⋯,m)
注意:这里如果说 p i j p_{ij} pij为0,那么就需要指定 l n ( 0 ) = 0 ln(0)=0 ln(0)=0 。信息效用值的定义:
d j = 1 − e j d_j=1-e_j dj=1−ej那么信息效用值越大,其对应的信息就越多。
将信息效用值进行归一化,我们就能够得到每个指标的 熵权:
ω j = d j ∑ j = 1 m d j , ( j = 1 , 2 , 3 , ⋯ , m ) \begin{aligned}\omega_{j}&=\frac{d_j}{\sum_{j=1}^md_j},\quad(j=1,2,3,\cdots,m)\end{aligned} ωj=∑j=1mdjdj,(j=1,2,3,⋯,m)
3. 典型例题
明星Kun想找一个对象,但喜欢他的人太多,不知道怎么选,经过层层考察,留下三个候选人。他认为身高165是最好的,体重在90-100斤是最好的。
候选人 颜值 牌气(争吵次数) 身高 体重 A 9 10 165 120 B 8 7 166 80 C 6 3 164 90
-
观察候选人的数据我们可以发现,A,B,C三人的身高是极为接近的,那么对于找对象来说这个指标是不是就不重要了呢?
-
对于体重这个指标来说,三人相差较大,那么找对象是不是就多考虑这个指标?
3.1 正向化矩阵
| 候选人 | 颜值 | 脾气(争吵次数) | 身高 | 体重 |
|---|---|---|---|---|
| A | 9 | 0 | 0 | 0 |
| B | 8 | 3 | 0.9 | 0.5 |
| C | 6 | 7 | 0.2 | 1 |
3.2 对正向化矩阵进行矩阵标准化
因为指标中没有负数,采用 z i j = x i j ∑ i = 1 n x i j 2 z_{ij}=\frac{x_{ij}}{\sqrt{\sum_{i=1}^nx_{ij}^2}} zij=∑i=1nxij2xij进行标准化
| 候选人 | 颜值 | 牌气(争吵次数) | 身高 | 体重 |
|---|---|---|---|---|
| A | 0.669 | 0 | 0 | 0 |
| B | 0.595 | 0.394 | 0.976 | 0.447 |
| C | 0.446 | 0.919 | 0.217 | 0.894 |
3.3 计算概率矩阵P
计算标准化矩阵第 j j j项指标下第 i i i个样本所占的比重 p i j = z i j ∑ i = 1 n z i j p_{ij}\:=\:\frac{z_{ij}}{\sum_{i=1}^nz_{ij}} pij=∑i=1nzijzij
| 候选人 | 颜值 | 脾气(争吵次数) | 身高 | 体重 |
|---|---|---|---|---|
| A | 0.391 | 0 | 0 | 0 |
| B | 0.348 | 0.300 | 0.818 | 0.333 |
| C | 0.261 | 0.700 | 0.182 | 0.667 |
3.4 计算熵权
| 颜值 | 脾气(争吵次数) | 身高 | 体重 |
|---|---|---|---|
| 0.0085 | 0.3072 | 0.3931 | 0.2912 |
3.5 计算得分
| 候选人 | 得分 |
|---|---|
| A | 0.0044 |
| B | 0.5009 |
| C | 0.4946 |
4. python代码实现
import numpy as np
# 定义一个自定义的对数函数,用于处理输入数组中的零元素def mylog(p):n = len(p)lnp = np.zeros(n)for i in range(n):if p[i] == 0:lnp[i] = 0else:lnp[i] = np.log(p[i])return lnp# 定义一个指标矩阵
X = np.array([[9, 0, 0, 0], [8, 3, 0.9, 0.5], [6, 7, 0.2, 1]])# 对矩阵X的每一列进行标准化处理
Z = X/np.sqrt(np.sum(X**2, axis=0))
print("标准化后的矩阵为:\n{}".format(Z))# 计算熵权所需的变量和矩阵初始化
n, m = Z.shape
D = np.zeros(m)# 计算每个指标的信息效用值
for i in range(m):x = Z[:, i]p = x/np.sum(x)e = -np.sum(p*mylog(p))/np.log(n)D[i] = 1-e# 根据信息效用值计算各指标权重
W = D/np.sum(D)
print("各指标权重为:\n{}".format(W))输出:
标准化后的矩阵为:
[[0.66896473 0. 0. 0. ][0.59463532 0.3939193 0.97618706 0.4472136 ][0.44597649 0.91914503 0.21693046 0.89442719]]
各指标权重为:
[0.00856537 0.30716152 0.39326471 0.2910084 ]
相关文章:
数学建模笔记——熵权法(客观赋权法)
数学建模笔记——熵权法[客观赋权法] 熵权法(客观赋权法)1. 基本概念2. 基本步骤3. 典型例题3.1 正向化矩阵3.2 对正向化矩阵进行矩阵标准化3.3 计算概率矩阵P3.4 计算熵权3.5 计算得分 4. python代码实现 熵权法(客观赋权法) 1. 基本概念 熵权法,物理学名词,按照信息论基本原…...

XGBoost算法-确定树的结构
我们在求解上面的w和obj的过程中,都是假定我们的树结构是确定的,因为当我们改变树中划分条件的时候,每个叶子节点对应的样本有可能是不一样的,我们的G和H也是不一样的,得到的最优w和最优obj肯定也是不一样的。 到底哪一…...

concurrentHashMap线程安全实现的原理
1. Segment 数组 ConcurrentHashMap 内部维护一个 Segment 数组,每个 Segment 都是一个小型的 HashMap。Segment 继承自 ReentrantLock,因此每个 Segment 都是一个可重入锁。 2. 并发级别 ConcurrentHashMap 在构造时可以指定并发级别(con…...

域名证书,泛域名证书,sni
文章目录 前言一、证书1.全域名证书2.泛域名证书 二、域名证书的使用1、浏览器请求域名证书流程对全域名证书的请求流程对泛域名证书的请求流程ssl client-hello携带server name 报文 2、浏览器对证书的验证流程 三、域名证书和sni 前言 本文介绍了泛域名证书和全域名证书的区别…...

Pytest夹具autouse参数使用。True表示会自动在测试中使用,而无需显式指定
1. 全局conftest文件日志记录功能 # 当前路径(使用 abspath 方法可通过dos窗口执行) current_path os.path.dirname(os.path.abspath(__file__)) # 上上级目录 ffather_path os.path.abspath(os.path.join(current_path,"../"))LOG_FILE_PATH f{ffather_path}/lo…...

Linux:归档及压缩
tar命令 • tar 集成备份工具 – -c:创建归档 – -x:释放归档 – -f:指定归档文件名称,必须在所有选项的最后 – -z、-j、-J:调用 .gz、.bz2、.xz 格式工具进行处理 – -t:显示归档中的文件清单 – -C:指定…...

jenkins 安装
jenkins安装 jenkins官网 中文网址 安装设置 所有jenkins版本 内存512M以上,10Gb磁盘;安装jdk,需要java8以上下载较新的版本,否则安装插件时可能报错版本过低 # 搜索java yum search java | grep -iE "jdk"# 安装jd…...
)
mysql学习教程,从入门到精通,MySQL 删除数据库教程(6)
1、MySQL 删除数据库 使用普通用户登陆 MySQL 服务器,你可能需要特定的权限来创建或者删除 MySQL 数据库,所以我们这边使用 root 用户登录,root 用户拥有最高权限。 在删除数据库过程中,务必要十分谨慎,因为在执行删除…...
)
C语言:刷题日志(2)
一.币值转换 输入一个整数(位数不超过9位)代表一个人民币值(单位为元),请转换成财务要求的大写中文格式。如23108元,转换后变成“贰万叁仟壹百零捌”元。为了简化输出,用小写英文字母a-j顺序代…...

微带结环行器仿真分析+HFSS工程文件
微带结环行器仿真分析HFSS工程文件 工程下载:微带结环行器仿真分析HFSS工程文件 我使用HFSS版本的是HFSS 2024 R2 参考书籍《微波铁氧体器件HFSS设计原理》和视频微带结环行器HFSS仿真 1、环形器简介 环行器是一个有单向传输特性的三端口器件,它表明…...

怎么仿同款小程序的开发制作方法介绍
很多老板想要仿小程序系统,就是想要做个和别人界面功能类似的同款小程序系统,咨询瀚林问该怎么开发制作?本次瀚林就为大家介绍一下仿制同款小程序系统的方法。 1、确认功能需求 想要模仿同款小程序系统,那么首先需要找到自己想要…...

音视频入门基础:WAV专题(10)——FFmpeg源码中计算WAV音频文件每个packet的pts、dts的实现
一、引言 从文章《音视频入门基础:WAV专题(6)——通过FFprobe显示WAV音频文件每个数据包的信息》中我们可以知道,通过FFprobe命令可以打印WAV音频文件每个packet(也称为数据包或多媒体包)的信息࿰…...

0.91寸OLED屏幕大小的音频频谱,炫酷
(后文有详细介绍) 频谱扫描: 迷你音频频谱——频率扫描 音乐律动: 迷你音频频谱——频率扫描 迷你音频频谱——音乐2 迷你音频频谱——音乐3 一、简介 音频频谱在最小0.91寸OLED 屏幕上显示,小巧玲珑 二、应用场景 本…...

6. LinkedList与链表
一、ArrayList的缺陷 通过源码知道,ArrayList底层使用数组来存储元素,由于其底层是一段连续空间,当在ArrayList任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后搬移,时间复杂度为O(n),效率比…...

Statcounter Global Stats 提供全球统计数据信息
Statcounter Global Stats 提供全球统计数据信息 1. Statcounter Global Stats2. Mobile & Tablet Android Version Market Share WorldwideReferences Statcounter Global Stats https://gs.statcounter.com/ Statcounter Global Stats are brought to you by Statcounte…...

Linux kernel中的dts dtsi dtb dtc dtb.img dtbo.img
1、问题 kernel与hsm会设置一些gpio,但是某些gpio会在kernel与hsm侧共同设置,导致最终的设置结果失败,将kernel侧在dts文件中设置的gpio注释掉之后,发现hsm设置gpio时还是失败 2、问题原因 因为dts文件不仅仅会影响kernel镜像&…...

微信小程序页面制作——个人信息
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

使用C++11的`std::async`执行异步任务:实战指南
使用C11的std::async执行异步任务:实战指南 在现代软件开发中,异步编程是提高应用程序性能和响应速度的重要手段。C11引入了std::async,使得编写异步任务变得更加简单和直观。本文将详细介绍如何使用std::async执行异步任务,并提…...

【高阶数据结构】B树、B+树、B*树
B树、B树、B*树 1. 常见的搜索结构2. B树概念3. B树的插入分析4. B树的插入实现4.1 B树的节点设计4.2 B树的部分插入实现14.3 B树的查找4.4 B树的部分插入实现24.5 插入key的过程4.7 B树的插入完整代码4.8 B树的简单验证4.9 B树的删除4.10 B树的性能分析 5. B树6. B*树7. 总结8…...

HBuilderx中vue页面引用scss样式
scss为css样式的预编译器,引入了变量、嵌入、混合、集成、引入等功能,相对于css样式,实现了样式的编程,具有更灵活的样式编写模式。 那么在HBuilderx中,“.vue”格式页面如何调用scss样式呢?详细如下&#…...
)
用ChatGPT写投资人邮件:72小时内获3家TS的实测框架(含Prompt工程+合规校验清单)
更多请点击: https://codechina.net 第一章:用ChatGPT写投资人邮件:72小时内获3家TS的实测框架(含Prompt工程合规校验清单) 在融资关键期,一封精准、可信、有温度的投资人邮件,往往比BP更早决定…...

高效拦截微信撤回消息:WeChatIntercept一站式解决方案
高效拦截微信撤回消息:WeChatIntercept一站式解决方案 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微信聊天…...

基于SpringBoot的校园心理健康匿名互助社区毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的校园心理健康匿名互助社区系统以解决当前高校心理健康服务中存在的信息传播效率低下、公众参与度不足以及资源利用…...

如何用NightX Client彻底改变你的Minecraft 1.8.9游戏体验?终极功能解析
如何用NightX Client彻底改变你的Minecraft 1.8.9游戏体验?终极功能解析 【免费下载链接】NightX-Client Minecraft Forge 1.8.9 hacked client, Based on LiquidBounce 项目地址: https://gitcode.com/gh_mirrors/ni/NightX-Client 想要在Minecraft 1.8.9中…...

AI代理实战能力评估:MLE-Bench基准测试深度解析与工程启示
1. 项目概述与核心价值最近在跟进AI代理(AI Agent)领域的发展,特别是它们在自动化复杂工作流方面的潜力。作为一个在机器学习工程一线摸爬滚打了十来年的从业者,我深知从数据清洗、特征工程、模型调优到实验管理的全流程ÿ…...

OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如
OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时间控制而烦恼吗?OBS Advanced Timer计时器插件是你的直播时间管理…...

慕课助手:让在线学习效率提升300%的开源浏览器插件
慕课助手:让在线学习效率提升300%的开源浏览器插件 【免费下载链接】mooc-assistant 慕课助手 浏览器插件(Chrome/Firefox/Opera) 项目地址: https://gitcode.com/gh_mirrors/mo/mooc-assistant 你是否曾因网课平台的机械重复操作浪费宝贵时间?根…...

具身智能的发展趋势对就业市场的影响的时间线是怎样的?
一、时间线为什么是 2026–2027 / 2028–2029 / 2030?1)2026–2027:阵痛期(工业 / 物流先替代)核心依据:量产节奏 成本拐点 机构一致判断出货量预测:多家机构(IFR、高盛、麦肯锡&a…...

JMeter WebSocket测试实战:协议原理与PD插件全生命周期压测
1. 为什么 WebSocket 接口不能用 HTTP Sampler 硬套?——从协议本质讲清测试前提你是不是也试过,在 JMeter 里把 WebSocket 的 URL 直接粘进 HTTP Request Sampler,填上 Host、Path、Method,点运行,结果 Response Code…...

yuzu模拟器完全指南:在PC上免费畅玩Switch游戏的终极教程
yuzu模拟器完全指南:在PC上免费畅玩Switch游戏的终极教程 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu yuzu模拟器是一款开源的任天堂Switch模拟器,让你能够在Windows、Linux和Android设备…...