Spark运行架构
目录
1 运行架构
2 核心组件
2.1 Driver
2.2 Executor
2.3 Master & Worker
2.4 ApplicationMaster
3 核心概念
3.1 Executor 与 Core
3.2 并行度( Parallelism)
3.3 有向无环图( DAG)
4 提交流程
4.1 Yarn Client模式
4.2 Yarn Cluster模式
1 运行架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的Driver 表示 master,
负责管理整个集群中的作业任务调度。图形中的Executor 则是 slave,负责实际执行任务。

2 核心组件
由上图可以看出,对于 Spark 框架有两个核心组件:
2.1 Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在Spark 作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在 Executor 之间调度任务(task)
- 跟踪Executor 的执行情况
- 通过UI 展示查询运行情况
实际上,我们无法准确地描述Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为Driver 类。
2.2 Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
2.3 Master & Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
2.4 ApplicationMaster
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和Driver(计算)之间的解耦合靠的就是ApplicationMaster。
3 核心概念
3.1 Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
应用程序相关启动参数如下:
| 名称 | 说明 |
| --num-executors | 配置 Executor 的数量 |
| --executor-memory | 配置每个 Executor 的内存大小 |
| --executor-cores | 配置每个 Executor 的虚拟 CPU core 数量 |
3.2 并行度( Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
3.3 有向无环图( DAG)

大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop 所承载的 MapReduce,它将计算分为两个阶段,分别为 Map 阶段 和 Reduce 阶段。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由 Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观, 更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
4 提交流程
所谓的提交流程,其实就是我们开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,我们这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以本课程中的提交流程是基于 Yarn 环境的
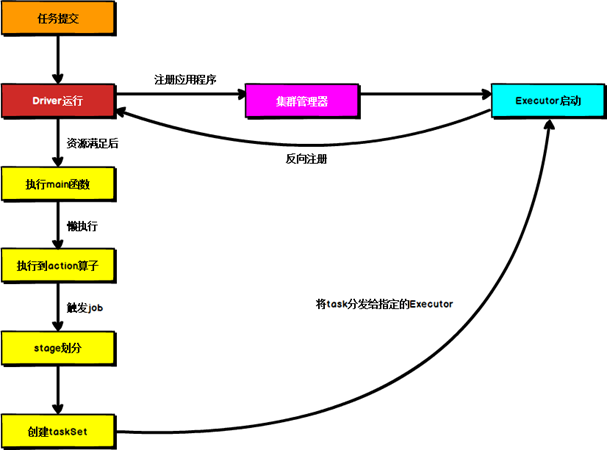
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client 和 Cluster。两种模式主要区别在于:Driver 程序的运行节点位置。
4.1 Yarn Client模式
Client 模式将用于监控和调度的Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
- Driver 在任务提交的本地机器上运行
- Driver 启动后会和ResourceManager 通讯申请启动ApplicationMaster
- ResourceManager 分配 container,在合适的NodeManager 上启动ApplicationMaster,负责向ResourceManager 申请 Executor 内存
- ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的NodeManager 上启动 Executor 进程
- Executor 进程启动后会向Driver 反向注册,Executor 全部注册完成后Driver 开始执行main 函数
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个stage 生成对应的TaskSet,之后将 task 分发到各个Executor 上执行。
4.2 Yarn Cluster模式
Cluster 模式将用于监控和调度的 Driver 模块启动在Yarn 集群资源中执行。一般应用于实际生产环境。
- 在 YARN Cluster 模式下,任务提交后会和ResourceManager 通讯申请启动ApplicationMaster,
- 随后ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是Driver。
- Driver 启动后向 ResourceManager 申请Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配container,然后在合适的NodeManager 上启动Executor 进程
- Executor 进程启动后会向Driver 反向注册,Executor 全部注册完成后Driver 开始执行
main 函数,
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个stage 生成对应的TaskSet,之后将 task 分发到各个Executor 上执行。
相关文章:
Spark运行架构
目录 1 运行架构 2 核心组件 2.1 Driver 2.2 Executor 2.3 Master & Worker 2.4 ApplicationMaster 3 核心概念 3.1 Executor 与 Core 3.2 并行度( Parallelism) 3.3 有向无环图( DAG) 4 提交流程 …...
基于卷积神经网络CNN的水果分类预测,卷积神经网络水果等级识别
目录 背影 卷积神经网络CNN的原理 卷积神经网络CNN的定义 卷积神经网络CNN的神经元 卷积神经网络CNN的激活函数 卷积神经网络CNN的传递函数 卷积神经网络CNN水果分类预测 基本结构 主要参数 MATALB代码 结果图 展望 背影 现在生活,为节能减排,减少电能…...

Spring Boot 框架总结
Spring Boot 框架总结 1. springboot的引言 Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化Spring应用的 初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不 再需要定义样板化的配置。通过这种方式࿰…...
【数据结构】第五站:带头双向循环链表
目录 一、链表的八种结构 二、带头双向循环链表的实现 1.链表的定义 2.链表的接口定义 3.接口的具体实现 三、带头双向循环链表的完整代码 四、顺序表和链表的区别 一、链表的八种结构 我们已经知道链表可以有以下三种分法 而这三种结构又可以排列组合,形成八…...

Springboot生成二维码
Springboot生成二维码整合 我们使用两种方式,去生成二维码,但是其实,二维码的生成基础,都是zxing包,这是Google开源的一个包,第一种是使用原始的zxing方式去实现,第二种是使用hutool来实现&…...

“独裁者”何小鹏,再造小鹏汽车
文丨智能相对论 作者丨沈浪 如果没有何小鹏,小鹏汽车将失去灵魂。 2014年,夏珩、何涛等人在广州组建小鹏汽车(当时还叫“橙子汽车”),何小鹏还只是股权投资人。 夏珩、何涛原任职于广汽,负责新能源汽车…...

数据结构 | 泛型 | 擦除机制| 泛型的上界
目录 编辑 1.泛型 1.1Object类引出泛型概念 2.泛型语法 2.1泛型编写代码 3.泛型的机制 3.1擦除机制 4.泛型的上界 4.1泛型上界的语法 4.2泛型上界的使用 5.泛型方法 5.1泛型方法语法 5.2泛型方法的使用 1.泛型 一般的类和方法中,只能使用具体的代码…...
详解)
C++拷贝构造函数(复制构造函数)详解
拷贝和复制是一个意思,对应的英文单词都是copy。对于计算机来说,拷贝是指用一份原有的、已经存在的数据创建出一份新的数据,最终的结果是多了一份相同的数据。例如,将 Word 文档拷贝到U盘去复印店打印,将 D 盘的图片拷…...

python学习——多线程
python学习——多线程概念python中线程的开发线程的启动线程的退出和传参threading的属性和方法threading实例的属性和方法多线程daemon线程和non-demone线程daemon线程的应用场景线程的jointhreading.local类线程的延迟执行:Timer线程同步Event 事件Lock ——锁加锁…...
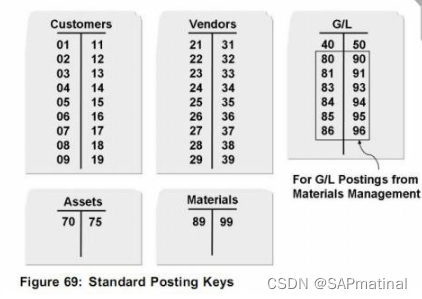
SAP 系统中过账码or记账码
SAP中过账码和记账码是指同一个事物。 在实际业务中,记账码就是只有“借”和“贷”, 而SAP中Posting Code肩负着更多的任务: 1)界定科目类型, 2)借贷方向, 3)凭证输入时画面上的字…...

【FreeRTOS(一)】FreeRTOS新手入门——初识FreeRTOS
初识FreeRTOS一、实时操作系统概述1、概念2、RTOS的必要性3、RTOS与裸机的区别4、FreeRTOS的特点二、FreeRTOS的架构三、FreeRTOS的代码架构一、实时操作系统概述 1、概念 RTOS:根据各个任务的要求,进行资源(包括存储器、外设等)…...

Python中 __init__的通俗解释是什么?
__init__是Python中的一个特殊方法,用于在创建对象时初始化对象的属性。通俗来讲,它就像是一个构造函数,当我们创建一个类的实例时,__init__方法会被自动调用,用于初始化对象的属性。 举个例子,如果我们定义…...

网友真实面试总结出的自动化测试面试题库
目录 常规问题 手工测试部 自动化测试 自动化测试面试题2:selenium篇 常规问题 1、如何快速深入的了解移动互联网领域的应用 (答案:看http协议 restful api知识 json加1分) 2、对xx应用自己会花多久可以在业务上从入门到精通&…...

2023 年最佳 C++ IDE
文章目录前言1. Visual Studio2. Code::Blocks3. CLion4. Eclipse CDT(C/C 开发工具)5. CodeLite6. Apache NetBeans7. Qt Creator8. Dev C9. C Builder10. Xcode11. GNAT Programming Studio12. Kite总结前言 要跟踪极佳 IDE(集成开发环境&…...

在Ubuntu上使用VSCode编译MySQL Connector/C连接库
首先下载并解压MySQL Connector/C源码,然后执行以下步骤: 1、安装MySQL Connector/C依赖:在终端中输入以下命令来安装MySQL Connector/C的依赖项: sudo apt-get install build-essential cmake 2、下载并解压MySQL Connector/C源…...
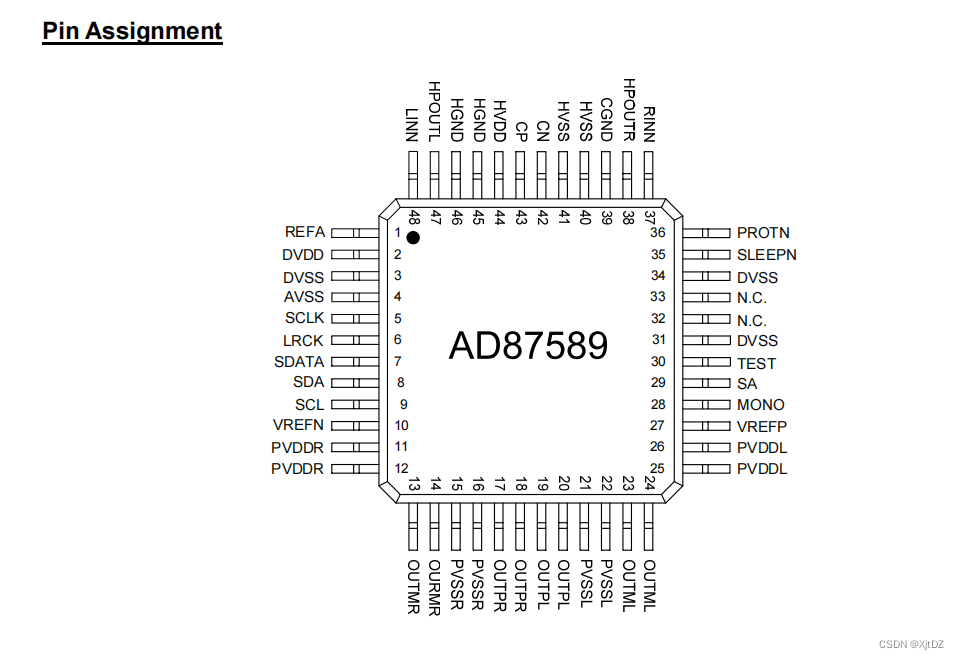
单声道数字音频放大器AD87589
AD87589是一种集成音频系统解决方案,嵌入数字音频处理、功率级放大器和立体声2Vrms线路驱动器。 AD87589具有可编程转换速率控制的输出缓冲器,可直接驱动一个(单声道)或两个(立体声)扬声器。此外࿰…...

网络的UDP协议和TCP协议
协议:数据在网络中的传输规则,常见的协议有 UDP协议和TCP协议 协议:计算机网络中,连接和通信的规则被称为网络通信协议 UDP协议:用户数据报协议,是面向无连接通信协议,速度快,有大小…...

【JaveEE】多线程之阻塞队列(BlockingQueue)
目录 1.了解阻塞队列 2.生产者消费者模型又是什么? 2.1生产者消费者模型的优点 2.1.1降低服务器与服务器之间耦合度 2.1.2“削峰填谷”平衡消费者和生产的处理能力 3.标准库中的阻塞队列(BlockingQueue) 3.1基于标准库(Bloc…...
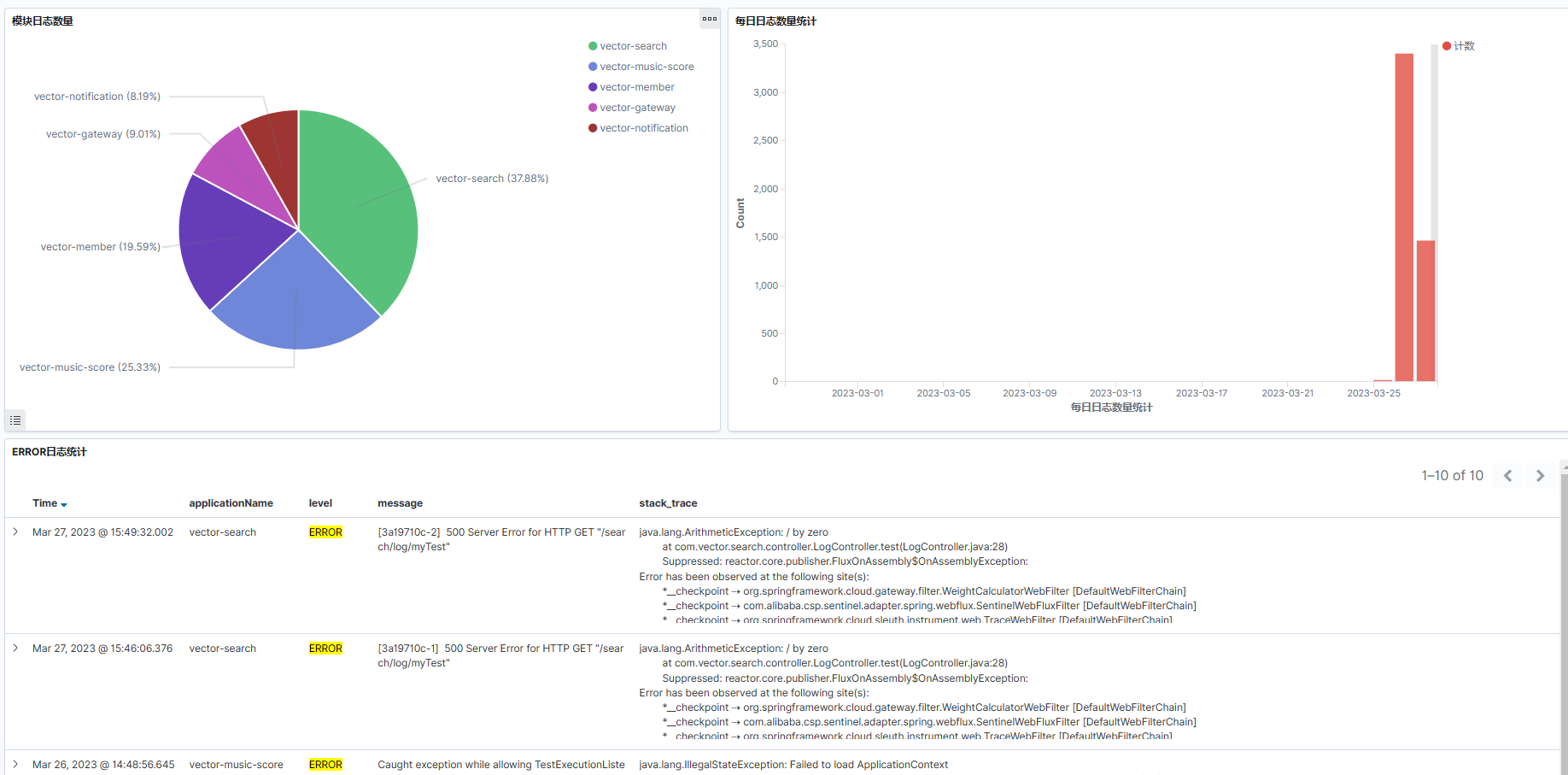
分布式ELK日志监控系统环境搭建
文章目录1.1为什么需要监控项目日志1.2ELK日志监控系统介绍1.3ELK的工作流程1.4ELK环境搭建1.4.1Elasticsearch的安装1.4.2Kibana的安装1.4.3Logstash的安装1.4.4数据源配置1.4.5日志监测测试1.4.6日志数据可视化展示1.1为什么需要监控项目日志 项目日志是记录项目运行过程中产…...
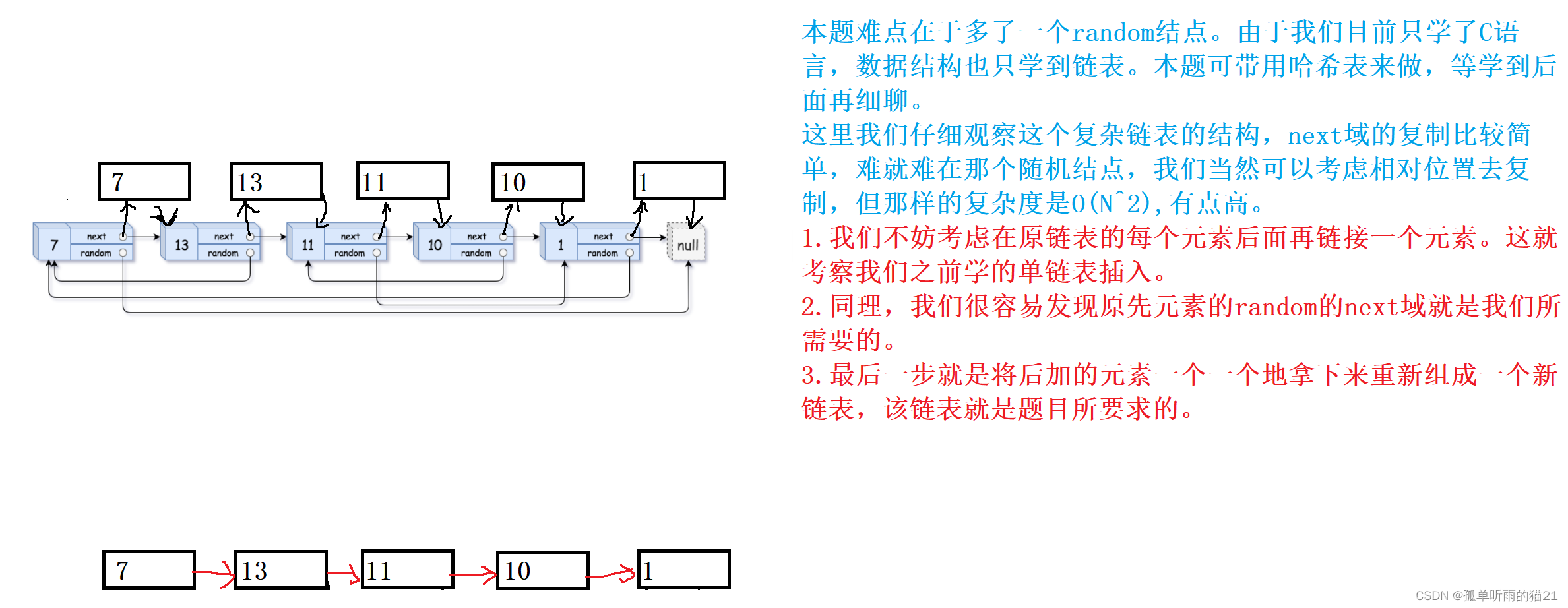
【数据结构刷题集】链表经典习题
😽PREFACE🎁欢迎各位→点赞👍 收藏⭐ 评论📝📢系列专栏:数据结构刷题集🔊本专栏涉及到题目是数据结构专栏的补充与应用,只更新相关题目,旨在帮助提高代码熟练度&#x…...

在wsl中利用快马平台五分钟搭建flask博客后端原型
最近在Windows系统下折腾WSL(Windows Subsystem for Linux)时,发现结合InsCode(快马)平台可以快速搭建项目原型,特别适合需要Linux环境特性的开发验证。就拿搭建一个Flask博客后端来说,传统方式从零开始配置环境、编写…...
飞速发展的今天,传统云)
**雾计算中的边缘智能:基于Python的轻量级任务调度系统设计与实现**在物联网(IoT)飞速发展的今天,传统云
雾计算中的边缘智能:基于Python的轻量级任务调度系统设计与实现 在物联网(IoT)飞速发展的今天,传统云计算模式已难以满足低延迟、高带宽和实时响应的需求。**雾计算(Fog Computing)**作为云与终端设备之间的…...

Qwen3-14B开源模型实战:跨境电商多平台产品文案批量生成
Qwen3-14B开源模型实战:跨境电商多平台产品文案批量生成 1. 跨境电商文案生成的痛点与解决方案 跨境电商运营面临的最大挑战之一,就是需要为同一款产品在不同平台(亚马逊、eBay、速卖通等)生成符合各自规范的优质文案。传统人工…...

效率提升秘籍:使用快马AI一键生成动漫视频批量处理与格式转换工具
效率提升秘籍:使用快马AI一键生成动漫视频批量处理与格式转换工具 最近接手了一个动漫视频处理的项目,需要将大量不同格式的动漫视频统一转换为高清MP4格式,并生成预览缩略图。手动处理不仅耗时耗力,还容易出错。于是我开始寻找自…...

KOReader终极指南:如何打造你的完美电子墨水屏阅读体验
KOReader终极指南:如何打造你的完美电子墨水屏阅读体验 【免费下载链接】koreader An ebook reader application supporting PDF, DjVu, EPUB, FB2 and many more formats, running on Cervantes, Kindle, Kobo, PocketBook and Android devices 项目地址: https:…...

避开这些坑!Mapbox图层管理实战:动态加载GeoJSON数据的正确姿势
Mapbox高级图层管理实战:GeoJSON动态加载与性能优化全解析 当处理省级以上GIS数据可视化时,Mapbox的图层管理能力直接决定了应用的流畅度和用户体验。许多开发者在使用GeoJSON数据源时,常遇到内存泄漏、渲染卡顿、交互延迟等问题。本文将深入…...

ESXI系统安装全流程详解:从U盘启动到网络配置
1. 制作ESXI系统U盘启动盘 准备一个容量至少8GB的U盘,建议使用USB3.0接口的高速U盘,这样写入速度会快很多。我实测过,用USB2.0的U盘写入一个ESXI镜像可能需要20分钟,而USB3.0通常5分钟就能搞定。 首先需要下载两个关键文件&#x…...
)
SpringBoot集成TTL实现Feign与线程池的TraceId无缝传递(实战优化版)
1. 问题背景与核心挑战 在分布式系统中,日志链路追踪是排查问题的关键手段。想象一下这样的场景:用户请求从网关进入,经过多个微服务处理,每个服务又可能调用其他服务或使用线程池异步处理。当出现问题时,如何快速定位…...

深度学习优化算法详解:从 SGD 到 AdamW
深度学习优化算法详解:从 SGD 到 AdamW 1. 背景与动机 优化算法是深度学习训练的核心,选择合适的优化器直接影响模型的收敛速度和最终性能。本文深入分析主流优化算法的原理和适用场景。 2. 梯度下降家族 2.1 SGD import torch import torch.nn as nnopt…...

终极指南:PrivateGPT增量文档处理策略与动态更新解决方案
终极指南:PrivateGPT增量文档处理策略与动态更新解决方案 【免费下载链接】privateGPT 利用GPT的强大功能与你的文档进行互动,确保100%的隐私保护,无数据泄露风险 项目地址: https://gitcode.com/GitHub_Trending/pr/privateGPT Priva…...