ChatGPT 有哪些 “激动人心的时刻“?以及自己的一些思考
文章目录
- 一、前言
- 二、主要内容
- 三、一些思考
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、前言
近日,英伟达创始人兼 CEO 黄仁勋与 OpenAI 联合创始人及首席科学家伊尔亚-苏茨克维 (Ilya Sutskever) 展开了一次 “炉边谈话”。
黄仁勋认为,ChatGPT 是 “AI 界的 iPhone 时刻”,但这一时刻的到来并非一蹴而就,OpenAI 联合创始人早在十年前便开始关注神经网络,在探索生成式 AI 的过程中也经历了神经网络如何兼具深度和规模的探索、让机器不受监督的学习能力的突破。到如今,ChatGPT 成为了一款全球关注的 “网红工具”。站在当下回顾它的迭代和发展历程,创意似乎是在创始人和团队的一个个 “灵感” 之中蹦出,看似理所当然的创新背后究竟有哪些 “激动人心的时刻”?

原文链接和视频: 腾讯科技 编辑整理:李海丹、周小燕 | 关于 ChatGPT,黄仁勋和 OpenAI 联合创始人进行了一场 “炉边谈话”
二、主要内容
黄仁勋:最近 ChatGPT 的热潮使人工智能又站在了世界的 “风口浪尖”,OpenAI 公司也受到行业的重点关注,你也成为了整个行业最为引入注目的年轻工程师、最为顶尖的科学家。我的第一个问题是,你最初关注和聚焦人工智能领域的出发点是什么?有想过会取得目前如此巨大的成功吗?
伊尔亚-苏茨克维:非常感谢对我的盛情邀请。人工智能通过不断的深度学习,给我们的世界带来了巨大的变化。对于我个人来说,其实主要是两方面:
- 首先,我关注在人工智能深度学习方面的初心,是我们人类对于各种问题,都有一定的直觉性的理解。对于人类意识的定义,以及我们人类的智力是如何完成这样的预判,这是我特别感兴趣的地方。
- 第二,在 2002 年到 2003 年期间,当时的我认为 “学习” 这件事,是只有人类才能完成的任务,计算机是无法做到的。所以我当时冒出一个想法:如果能够让计算机去不断学习,或许会带来人工智能行业的改变。
- 并且很幸运的是,当时我正在上大学,我研究的专业刚好是研究神经网络学习方向。神经网络是在 AI 方面的一个非常重要的进步,我们关注如何通过神经网络去研究深度学习,以及神经网络如何像人类的大脑那样工作,这样的逻辑如何反映在计算机的工作方式上。当时的我其实并不清楚研究这个领域会带来怎样的职业工作路径,只是觉得这会是一个长期而言比较有前景的行业。
黄仁勋:在您最开始接触神经网络研究方向时,那个时候的神经网络的规模是多大?
伊尔亚-苏茨克维:其实那个时候神经网络还没有讨论到规模的概念,只有几百个神经单元,甚至当时的我都没想过,居然能发展到现在如此之多的神经单元、以及如此多的 CPU 的单位。当时我们启动了一个数学实验室,基于经费预算有限,我们先开始只做了各种各样不同的实验,并收集了各种不同的问题去测试准确度。我们都从一点一滴很小的积累,去训练神经网络。这也是最开始实现的第一个生成式 AI 模式的雏形。
黄仁勋:早在 2012 年之前,你就在神经网络领域有所建树,你是在什么时间点开始觉得计算机视觉以及神经网络和人工智能是未来很有前景的方向的?
伊尔亚-苏茨克维:在 2012 年之前大概两年左右,我逐渐意识到深度学习会获得很多关注,这不仅仅是我的直觉,其背后有一套非常扎实的理论基础。如果计算机的神经网络足够深、规模足够大,它就能够解决一些深层次的硬核内容问题,关键是需要神经网络兼备深度和规模,这意味着我们必须有足够大的数据库和算力。我们在优化数据模型上付出很多努力,我们的一个同事基于 “秒” 做出了神经网络的 馈,用户可以不断训练神经网络,这能让神经网络的规模更大、获得更多数据。有的人觉得这样的数据集大到不可想象,如果当时的算力能够处理这么大的数据,那么一定能触发一场革命。
黄仁勋:我们第一次相遇的时候,也是我们对未来的展望真正有所交集的时候。你当时告诉我说,GPU 会影响接下来几代人的生活,你的直觉认为 GPU 可能会对深度学习的训练有所帮助。能不能告诉我,你是在什么时候意识到这一点的?
伊尔亚-苏茨克维:我们在多伦多实验室中第一次尝试使用 GPU 训练深度学习的时候,并不清楚到底如何使用 GPU、如何让 GPU 获得真正的关注。随着我们获得越来越多的数据集,我们也越来越清楚传统的模型会带来的优势。我们希望能够加速数据处理的过程,训练过去科学家从来没有训练过的内容。
黄仁勋:我们看到 ChatGPT 和 OpenAI 目前已经打破了过去计算机编辑图像的模式。
伊尔亚-苏茨克维:我觉得不只是打破了计算机图像的编辑,而是用另外一种说法去形容,是 “超越式” 的。大部分人都是用传统的思维模式去处理数据集,但我们的处理方式更先进。当时我们也认为这是一件艰难的事情,如果我们能做好,就是帮助人们跨越了一大步。
黄仁勋:放在当下来看,当时你去硅谷到 Open AI 上班、担任 Open AI 的首席科学家,你认为最重要的工作时什么?我觉得 Open AI 在不同的时间点有不同的工作关注焦点,ChatGPT 是 “AI 界的 iPhone 时刻”,你是如何达到这样的转变时刻的?
伊尔亚-苏茨克维:最开始我们也不太清楚如何开展整个项目,而且,我们现在所得出的结论,和当时使用的逻辑完全不同。用户现在已经有这么好用的 ChatGPT 工具,来帮助大家创造出非常好的艺术效果和文本效果。但在 2015 年、2016 年的时候,我们还不敢想象能达到当下的程度。当时我们大部分同事来自谷歌的 DeepMind,他们有从业经验,但相对而言思想比较狭窄、受到束缚,当时我们内部做了 100 多次不同的实验和对比。
- 那时我想出一个特别令自己激动的想法,就是让机器具备一种不受监督的学习能力,虽然今天我们认为这是理所当然的,你可以用自然语言模型训练所有内容。但在 2016 年,不受监督的学习能力仍旧是没有被解决的问题,也没有任何科学家有过相关的经验和洞见。我觉得 “数据压缩” 是技术上的瓶颈,这个词并不常见,但实际上 ChatGPT 确实压缩了我们的训练数据集。但最后我们还是找到了数学模型,通过不断训练让我们压缩数据,这其实是对数据集的挑战。这是令我感动特别激动的一个想法,这个想法在 GPT 上获得了成果。
- 其实这样一些成果,可能并不会在机器学习之外深受欢迎,但是我想说的是,我工作取得的成果是训练了神经网络。我们希望能够去训练神经网络预测下一个单词。我认为下一个神经元的单位会和我们的整个视觉神经网络密切相关的,这个很有趣,这个和我们验证的方法是一致的。它再次重新证明了,下一个字符的预测、下一个数据的预测能够帮助我们去发掘现有数据的逻辑,这个就是 ChatGPT 训练的逻辑。
黄仁勋:扩大数据规模是帮助我们提高 AI 能力的表现,更多的数据、更大的数据集能够帮助生成式 AI 获得更好的结果。您觉得 GPT-1、GPT-2、GPT-3 的演变过程,是否符合摩尔定律?
伊尔亚-苏茨克维:OpenAI 的目标之一是解决扩大数据集的问题,但我们刚开始面临的问题,如何提升数据的高精准度,让模型能够实现精准预测非常重要。我们当时在做 Open AI 项目的时候,希望它能实时做一些策略性游戏,比如竞争性的体育游戏,它必须足够快、足够聪明,还要和其它队竞赛。作为一个 AI 模型,它其实不断重复这样一个基于人类反馈的强化学习过程。
黄仁勋:你是如何精准调控给予人类反馈的强化学习的?是不是有其它附属系统,给 ChatGPT 一定的知识背景来支持 ChatGPT 的表现?
伊尔亚-苏茨克维:我可以给大家解释一下,我们的工作原理是不断训练神经网络架构,让神经网络去预测下一个单词。基于过去我们收集的文本,ChatGPT 不仅仅是表面上的自监督学习,我们希望它能够在当下预测的单词和过去的单词之间达成一定的逻辑上的一致。过去的文本,其实是用于投射到接下来的单词的预测上。从神经网络来看,它更像是根据世界的不同方面,根据人们的希望、梦想和动机得出一个结论。但我们的模型还没有达到预期的效果,比如我们从网上随便摘几个句子做前言,在此基础上,不需要做额外的训练就能让 ChatGPT 写出一篇符合逻辑的论文。我们不是简单地根据人类经验完成 AI 学习,而是要根据人类反馈进行强化学习。人类的反馈很重要,越多的反馈能使 AI 更可靠。
黄仁勋:你可以给 AI 指示,让 AI 做某些事情,但是你能不能让 AI 不做某些事情?比如说告诉 AI 界限在哪里?
伊尔亚-苏茨克维:可以的。我觉得第二个阶段的训练序列,就是和 AI、神经网络去进行交流,我们对 AI 训练得越多,AI 的精准度越高,就会越来越符合我们的意图。我们不断地提高 AI 的忠诚度和准确度,它就会变得越来越可靠,越来越精准,而且越来越符合人类社会的逻辑。
黄仁勋:ChatGPT 在几个月之前就面世了,并且也是人类历史上增长最为迅速的软件和应用。很多人都会给出各种不同的解释,有人会说它是目前为止使用方式最简单的应用。比如说它的交互模式非常简单,它超越了所有人的预期。人们也不需要去学习如何使用 ChatGPT,只要给 ChatGPT 下命令,提出各种不同的提示就可以。如果你的提示不够清楚的话,ChatGPT 也会进一步把你的提示做得比较清晰,然后回顾并且问你是不是想要这个?这样一个深度学习的过程让我特别惊艳。我们在几天之前看到了 GPT-4 的表现,它在很多领域的表现非常让人震惊,它能够通过 SAT 考试、律师协会的律师执业资格考试,而且能够达到很高的人类水平。我想问的就是,GPT-4 有什么样的改善?并且你认为接下来它会帮助人们在哪些方面、领域有更多的改善?
伊尔亚-苏茨克维:GPT-4 基于过去 ChatGPT 的性能,做了很多改善。我们对 GPT-4 的训练大概是从 6-8 个月之前开始的,GPT -4 和之前版本 GPT 最重要的区别,就是 GPT-4 是基于更精确的精准度去预测下一个单词的,因为有更好的神经网络帮助预测。比如说你自己在读一篇推理小说,小说中有各种不同的人物和情节,有密室、有谜团,你在读推理小说的过程中完全不清楚接下来会发生什么。通过小说不同的人物和情节,你预测凶手有几种可能性,GPT-4 所做的内容就像一本推理小说一样。
黄仁勋:很多人都会说深度学习会带来推理,但是深度学习并不会带来学习。语言模型是如何学习到推理和逻辑的?有一些任务,ChatGPT 和 GPT-3 不够擅长,而 GPT-4 更擅长。GPT-4 现在还有什么样缺陷,可以在接下来的版本上更进一巩固吗?
伊尔亚-苏茨克维:现在的 ChatGPT 可以更精准地的定义逻辑和推理,通过更好的逻辑和推理在接下来的解密的过程中获得更好的答案。神经网络或许会面临一些挑战,比如让神经网络去打破固有的思维模式,这就意味着我们要思考神经网络到底可以走多远,简而言之,神经网络的潜力有多大。我们认为 GPT 的推理确实还没有达到我们之前预期的水平,如果我们更进一步扩大数据库,保持过去的商业运转模型,它的推理的能力会进一步提高,我对这个比较有信心。
黄仁勋:还有一点特别有意思,就是你去问 ChatGPT 一个问题,它会基于过去的知识和经验告诉你这个问题的答案,这个也是基于它对过去知识和数据库的总结,以及基于对你的了解提供的答案,并且展现一定的逻辑性。我觉得 ChatGPT 有一种自然而然的属性,它能够不断去理解。
伊尔亚-苏茨克维:是的,神经网络确实有这些能力,但是有时候不太靠谱,这也是神经网络接下来面临的最大障碍。在很多情况下,神经网络会比较夸张、会出很多的错误,甚至出一些人类根本做不出来的错误。现在我们需要更多的研究来解决这些 “不可靠性“。现在 GPT-4 的模型已经被公开发布了,它其实没有追踪数据模型的能力,它的能力是基于文本去预测下一个单词,所以是有局限性的。我觉得有些人可能会让 GPT-4 去找出某些数据的来源,然后会对数据来源做更深入地调查。总体而言,尽管 GPT-4 并不支持内部的数据收集,它肯定会在持续的数据深入挖掘之中变得更加精准。GPT-4 已经能够从图片中进行学习,并且根据图片和内容的输入进行反馈。
黄仁勋:多模态学习如何加深 GPT-4 对于世界的理解?为什么多模态学习定义了 GPT 和 OpenAI?
伊尔亚-苏茨克维:多模态非常有意思。
- 第一,多模态在视觉和图像识别上特别有用。因为整个世界是由图片形成的,人们也是视觉动物,动物也是视觉动物,人脑 1/31/31/3 的灰质都是用来处理图像的,GPT-4 现在也能够去理解这些图像。
- 第二,通过图片或文字对世界的理解是一样的,这也是我们的一个论证。对于一个人而言,我们作为一个人可能一生之中只会说 10 亿个词。
黄仁勋:我脑海中闪过 10 亿个词的画面,居然有这么多词?
伊尔亚-苏茨克维:是的,我们可以计算一下人一生的时间有多久,以及一秒能处理多少词,如果再减去这个人生命中睡觉的时间,就能算出一生处理了多少单词。人和神经网络不同之处,就是有些过去对于文本而言的话,如果我们有一个十亿级的词汇无法理解的话,可以用万亿级的词汇来理解。我们对于世界的知识和信息,可以通过文本慢慢渗透给 AI 的神经网络。如你加上视觉图片等更多的元素,神经网络可以更精准地学习。
黄仁勋:对于文本和图片方面的深度学习,如果我们想要人工智能智能去理解其背后的逻辑,甚至夸张的说,是理解这个世界的基本原理——比如我们人类日常一句话的表达方式,比如说有一个词其实有两种含义,声音的高低变化,其实都代表着两种不同的语气。在说话的语言和语调方面,会不会对 AI 去理解文本有一定帮助呢?
伊尔亚-苏茨克维:是的,你说的这类场景非常重要。对于语音和语调,包括声音的大小和语气,都非常重要的信息来源。
黄仁勋:GPT-4 在哪些内容上比 GPT-3 做出了更多的进步,可以举个例子吗?
伊尔亚-苏茨克维:比如说在一些数学竞赛上(像高中数学竞赛),很多问题是需要图表来解答的。GPT-3.5 对于图表的解读做得特别差,而 GPT-4 只需要文本就可以解读,准确率有很大的提升。
黄仁勋:你之前提到,AI 能够生成各种不同的文本来去训练另外一个 AI。比如说,在所有的语言之中一共有 20 万亿不同的语言计数单位去训练语言模型,那么这个语言模型的训练到底是什么样的?AI 是否可生成出只属于 AI 的数据来去自我学习?这样的形式看起来是一个闭环的模型,就像我们人类通过自己不断地去学习外部的世界、通过自我反思、通过解决问题来去训练我们自己的大脑。你怎么看这样一个合成生成过程,以及 AI 的自我学习和自我培训呢?
伊尔亚-苏茨克维:我不会低估这个部分已经存在的数据,甚至我认为这里面存在的数据要比我们意识到的数据更多。
黄仁勋:是的,这也是我们在不断展望的未来中去思考的事情,相信总有一天,AI 能够自己去生成内容、进行自我学习,并且可以自我改善。你是否可以总结一下我们现在处于什么样的发展阶段?以及在不远的将来,我们的生成式 AI 能够达到什么样的情况?对于大语言模型,它的未来是什么?
伊尔亚-苏茨克维:对我来说,预测未来是很困难的。我们能做的就是把这件事,持续做下去,我们将会让大家看到更多令人感到惊艳版本的系统。我们希望能够去提高数据的可靠度,让系统真正能够获得人们的信任。如果让生成式的 AI 去总结某一些文本,然后得出一个结论。目前 AI 在解读这个文本过程中,还没有完全去验证文本的真实性以及文本所说的信息的来源,这一点是很重要的。接下来我们对于未来的展望,就是让神经网络必须要意识到所有数据来源的真实性,让神经网络意识到用户每一步的需求。
黄仁勋:这种技术希望能够展现给人们更多的可靠性。我还有最后一个问题,你觉得第一次使用ChatGPT-4的时候,有哪些性能让你觉得是很令人惊艳和震惊的?
伊尔亚-苏茨克维:对比之前的 ChatGPT 版本,神经网络只会回答问题,有的时候也会误解问题,回答上很不理想。但是 GPT-4 基本没有再误解问题,会以更快的方式去解决难题,能够去处理复杂的艰难的任务,这个对我来说特别有意义。举例子来看,很多人意识到 ChatGPT 能够写诗,比如说它可以写押头韵的诗,也能够写押尾韵的诗。并且它能够去解释笑话,能明白这个笑话背后到底是什么样的意义。其实简而言之,就是它的可靠性更好了。我在这个行业从业差不多二十多年了,让我认为 “惊艳” 的特点,就是它本身存在的意义,是可以给人类带来帮助的。它从最开始毫不起眼的工作领域慢慢成长,变得越来越强。同样的一个神经网络,通过两种不同的方式来训练,能够变得越来越强大。我也经常会发出疑问和感叹:这些神经网络是如何去成长如此之迅速的?我们是不是需要更多的训练?它是不是会像人脑一样不断成长?这让我感觉到它的伟大,或者说让人感到特别惊讶的方面。
黄仁勋:回想过去我们也认识很长的时间了,你将整个职业生涯都奉献给了这个事业,祝贺你在 GPT 和 AI 方面有所建树。今天跟你交流让我更清楚地了解了 ChatGPT 工作的逻辑,这是对于 ChatGPT 和 OpenAI 最为深入、最为艺术的一种解释。今天很高兴能够再次跟你交流,谢谢!
三、一些思考
ChatGPT 这波浪潮下,微软和英伟达其实成为了最大的赢家。
最近的热点词:ChatGPT、GPT-4、类 ChatGPT 产品
很多人没有意识到 GPT 其实是一场意识形态的战争。就像 Tiktok 对米果宣传机器的降维打击一样。参加听证会的 Tiktok CEO 周受资火了,但他这幅东方面孔和他所服务的来自东方的这款社交 APP,让某国会的议员们愈发五味杂陈,似乎注定了 Tiktok 命运的多舛。
在过去的几年里,这个世界涌现了不少新的技术,像区块链、元宇宙、强化学习等,但似乎都没有这次的 ChatGPT 如此普世近人:学生、老板、科学家、老百姓,谁都可以玩,谁都玩的嗨。很多年以前,那时候我们还是落后国家,总感觉技不如人,西方的东西就是好。如今在前人工智能时代,在 Al 算法领域,我们起码走在很多国家前列,数学家成了香饽饽。与此同时,算法只能解决算法的问题,GPT 依赖的或者吃的是网络世界的各种信息知识,由此引发了一个大大的问题就是:英文语料自带科学 & 逻辑属性,而来自中文世界的语料大部分都是二手货甚至是垃圾 (懂得都懂 emmm)。
人工智能时代,算法和算力固然重要,有效、优质的信息数据的获取和整合才是未来十年的新基建,比如中文知识图谱的构建。而这需要的是一步一个脚印,互相协作。这方面,我们差的还很多 … 当下及未来的一段时间里,大数据是一种新型战略资源。GPT-4 的强大很多人还没有来得及领略,GPT-5、GPT-6 已然在路上。国产的文心一言还在追赶中 … 百度大佬说:搞这个是因为企业有需 (钱) 求 (挣) …
2023 年 3 月 25 日,在中国发展高层论坛 2023 年年会上,黄奇帆表示,当下特别要重视的是第四次工业革命的核心技术转化出来的最终产品。言外之意:他对当下历史方位的判断是第四次工业革命。
最后,一点个人看法:真正的生产力不是 “类 GPT 产品” 帮老板们挣了多少钱,省了多少人力物力,而是能自主孕育出真正推动人类文明进步的土壤。
📚️ 参考链接:
- 关于 ChatGPT,黄仁勋和 OpenAI 联合创始人进行了一场 “炉边谈话”
- 不论谁赢了 ChatGPT 大战,英伟达都是最后的赢家
- 英伟达再现 AI「iPhone 时刻」,CEO 称生成式 AI 正颠覆全球企业
相关文章:
ChatGPT 有哪些 “激动人心的时刻“?以及自己的一些思考
文章目录一、前言二、主要内容三、一些思考🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 近日,英伟达创始人兼 CEO 黄仁勋与 OpenAI 联合创始人及首席科学家伊尔亚-苏茨克维 (Ilya Sutskever) 展开了一次 “炉边谈话”。 黄仁…...
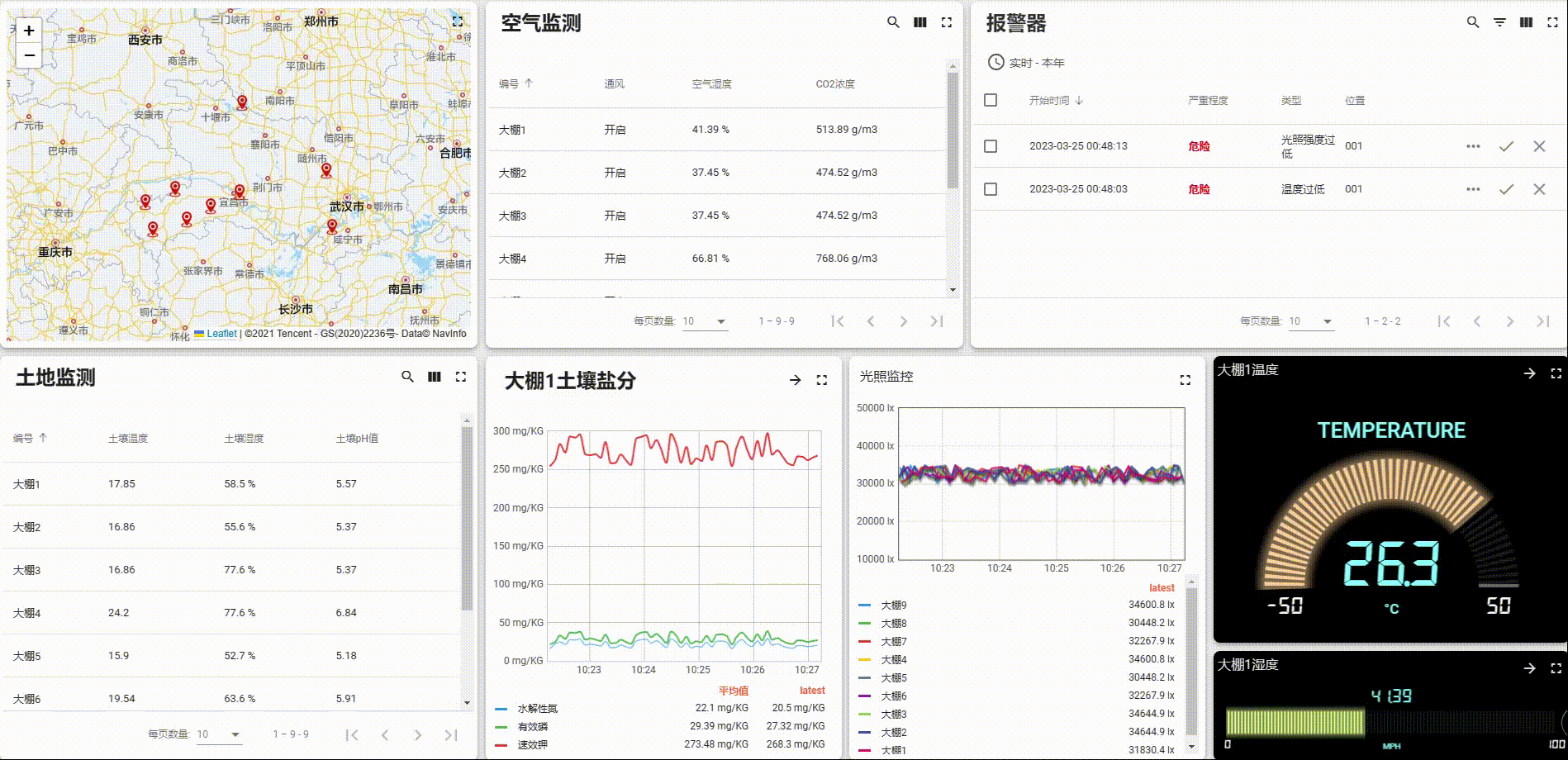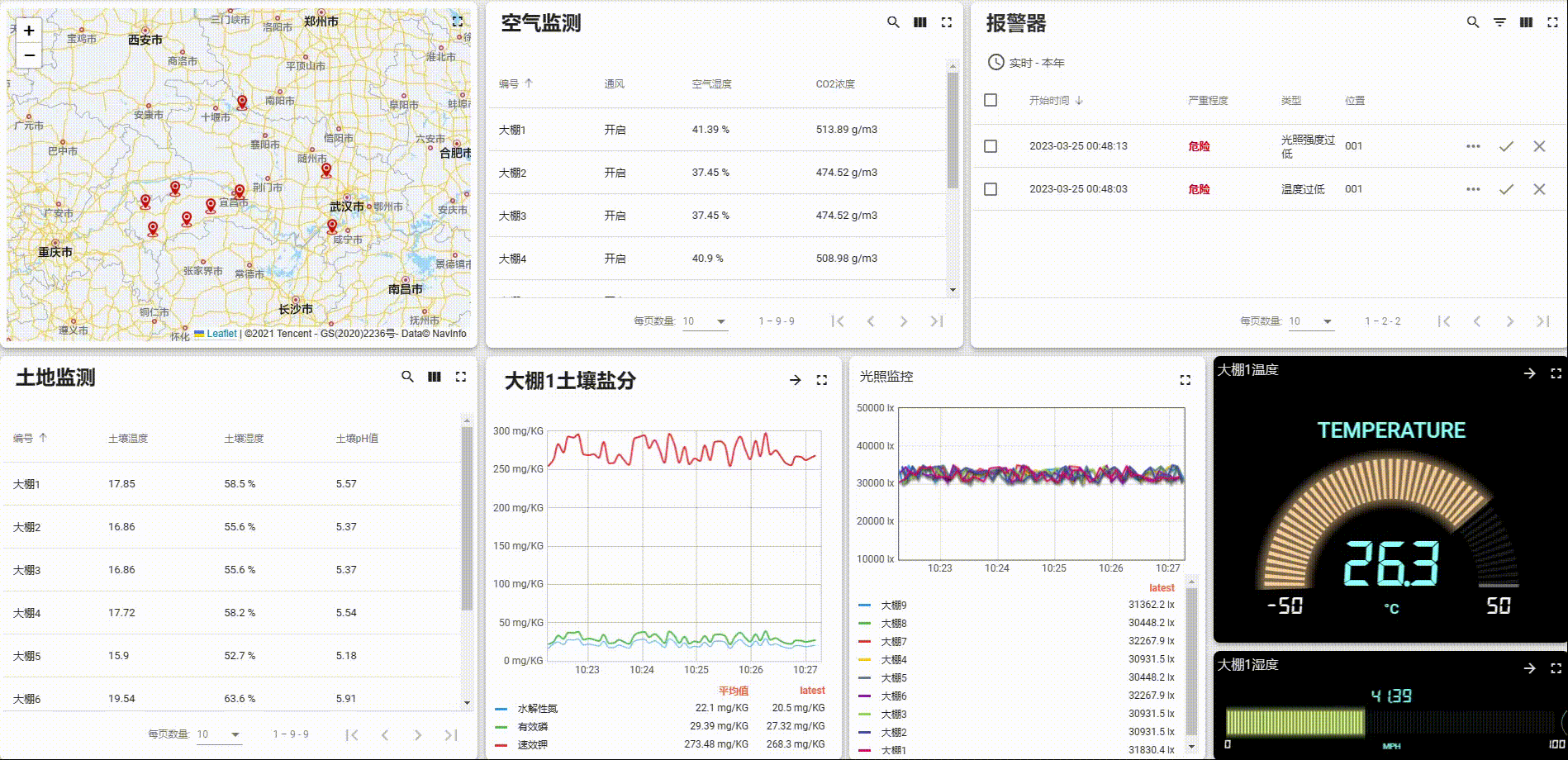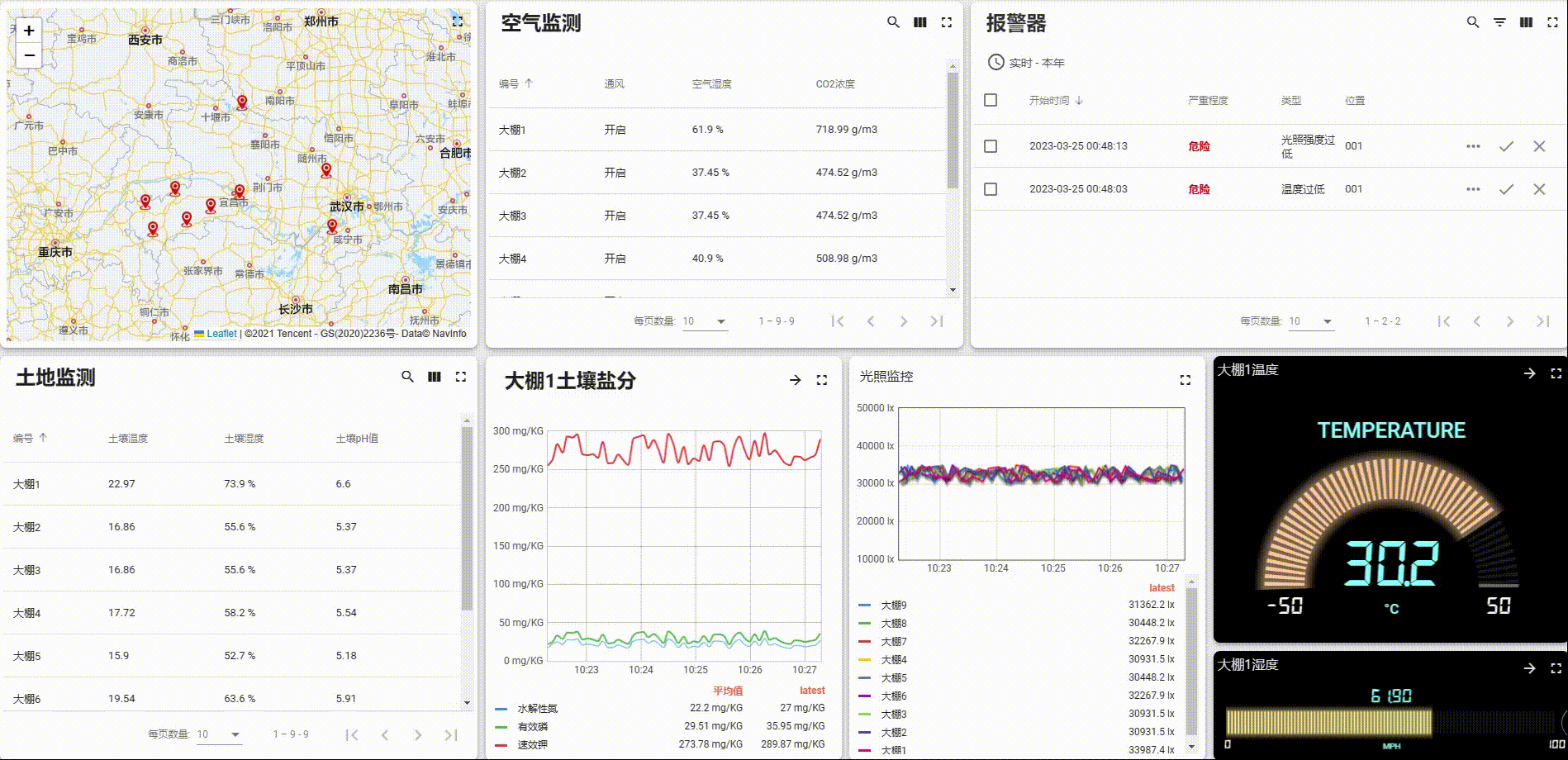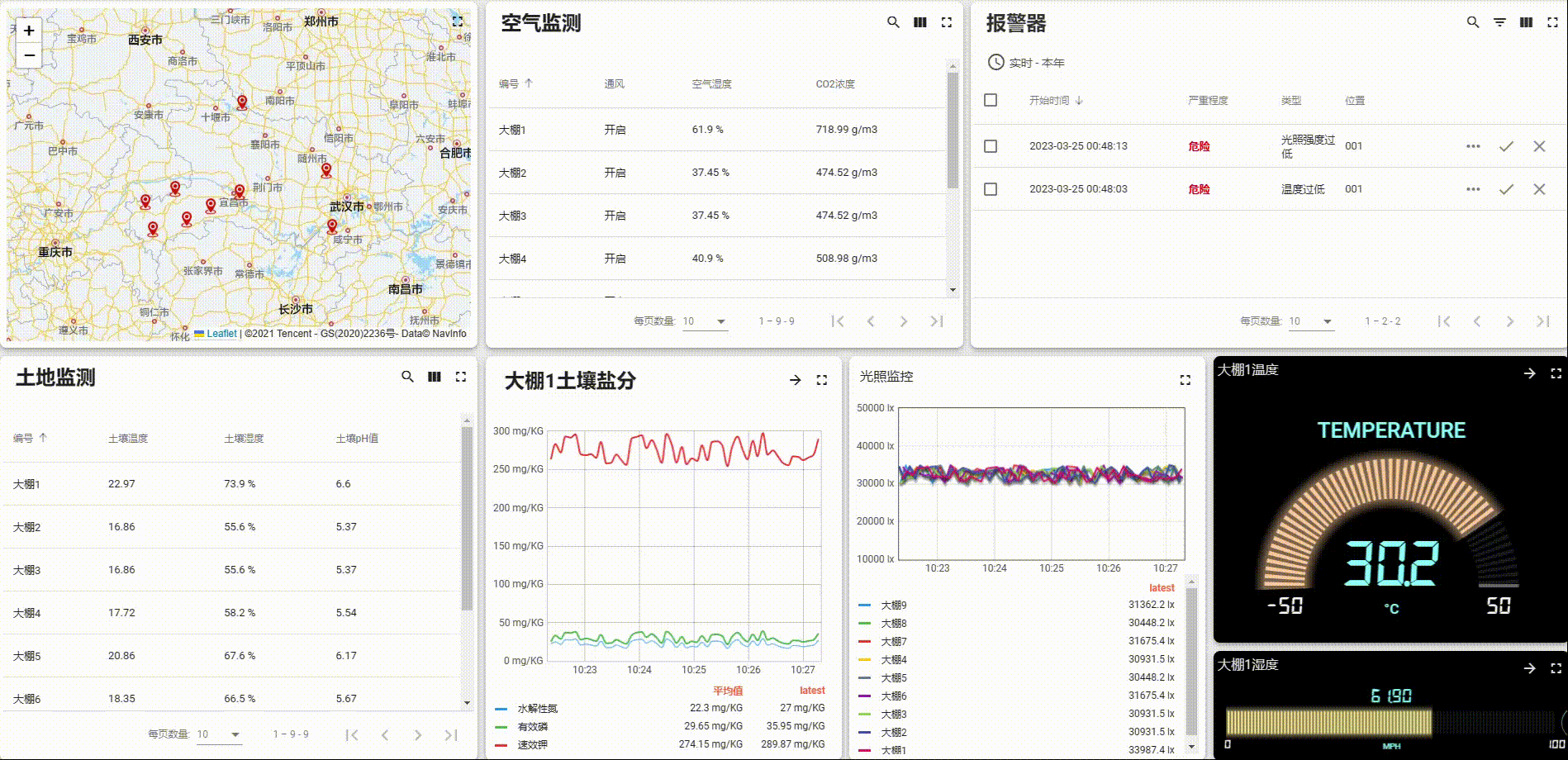
Thingsboard开源物联网平台智慧农业实例快速部署教程(二)【手把手部署UI与动态数据】
Thingsboard开源物联网平台智慧农业实例快速部署教程(二)【部署UI与动态数据】 文章目录Thingsboard开源物联网平台智慧农业实例快速部署教程(二)【部署UI与动态数据】1. 页面总览2. 设备2.1 数据字段定义2.2 设备映射关系2.3 添加…...
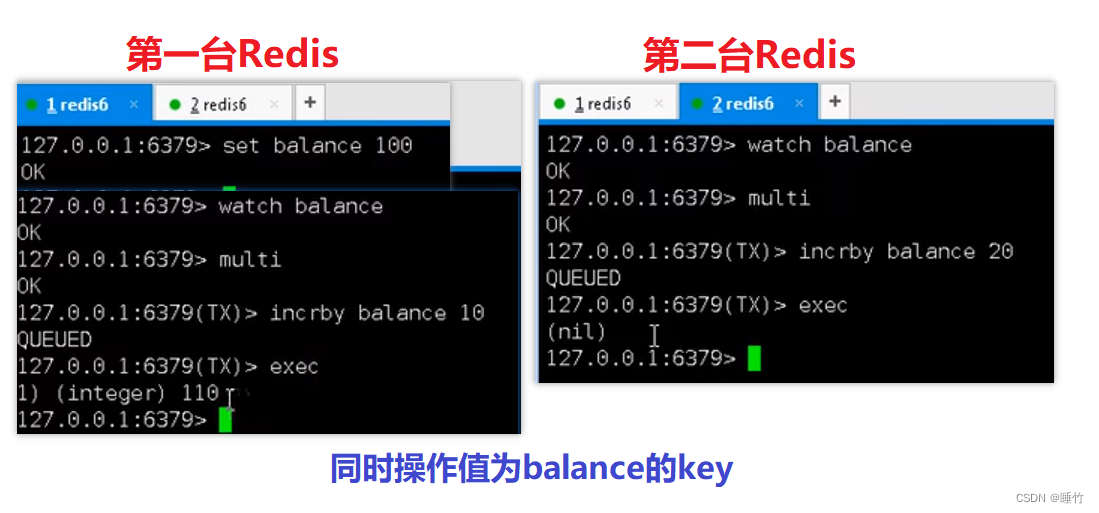
Redis事务
1、事务概要 Redis事务是一个单独的隔离操作: 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。 Redis事务的主要作用 串联多个命令,防止别的命令插队。 事务的3个命令 MultiExe…...
【蛤蟆先生去看心理医生】
第一章 整个人都不太好 人物性格描述蛤蟆热情、时尚、爱冒险,现在抑郁,不能自拔獾智慧、威严河鼠关心朋友,有点絮叨鼹鼠体贴善良 第二章 擎友前来相助 讲诉了鼹鼠和河鼠对蛤蟆情况的担忧和讨论。鼹鼠回忆起过去蛤蟆时髦的打扮和充满活力的生…...

JAVA开发与运维(云安全产品)
在现在的开发和运维中,云生态组件的使用率非常高,很少公司自己维护自己的物理机,网络流量 ,监控,第三方中间件,除了少数涉密程度高的部分和公司外,大多数的企业都在使用云生态。比如我们正在开发…...
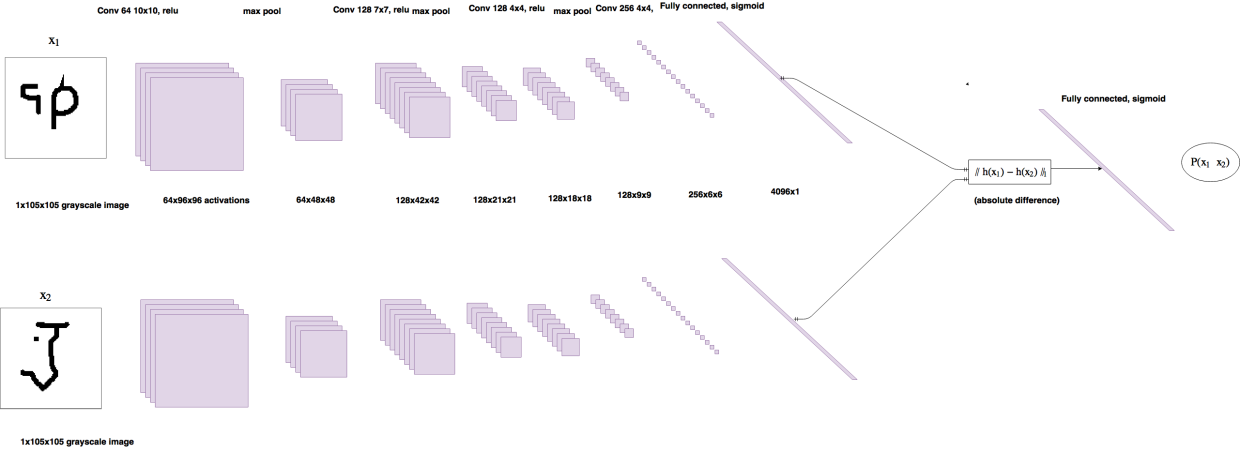
[Few-shot learning] Siamese neural networks
这篇文章主要介绍的是Siamese Neural Network经典论文: Gregory Koch, et al., Siamese Neural Networks for One-shot Image Recognition. ICML 2015。 神经网络能够取得非常好的效果得益于使用大量的带标签数据进行有监督学习训练。但是这样的训练方法面临两个难题…...

利用qiankun框架在自己项目中集成拖拽式低代码数据可视化开发平台
目前微前端已经是很成熟的技术了,各大公司都推出了自己的微前端框架,比如蚂蚁的qiankun,京东的micro-app,如果你的子应用不使用vite构建的话,我会更加推荐后者,micro-app使用更加简单,micro-app…...

【spring boot】在Java中操作缓存:
文章目录一、Jedis二、Spring Data Redis(常用)【1】pom.xml【2】application.yml【3】RedisConfig【4】RuiJiWaiMaiApplicationTests三、Spring Cache【1】常用注解:【2】使用案例【3】底层不使用redis,重启服务,内存…...
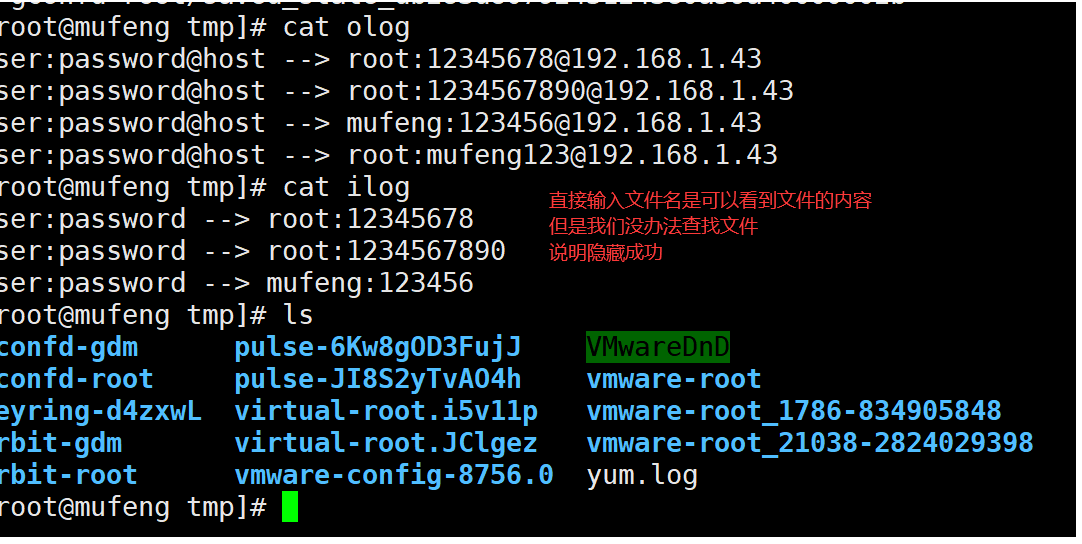
擂台赛-安全攻防之使用openssh后门获取root密码实战
前言 大家好,我是沐风晓月,我们开始组队学习了,介绍下我们的情况: 这几天跟队员 迎月,虹月,心月,古月打擂台,我和心月一组,相互攻占对方服务器。 终于在今早凌晨三点拿…...
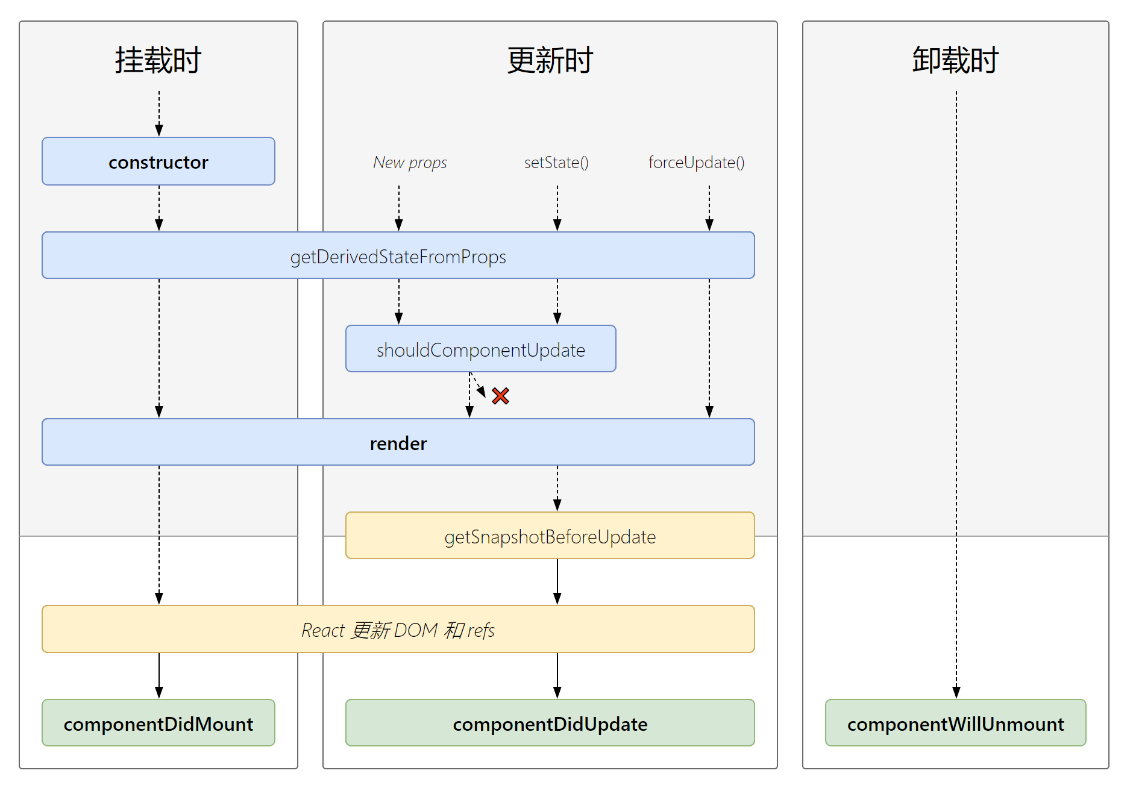
关于React入门基础从哪学起?
文章目录前言一、React简介1. React是什么2. react 与 vue 最大的区别就是:3. React特点4. React介绍描述5. React高效的原因6.React强大之处二、React基础格式1.什么是虚拟dom?2.为什么要创建虚拟dom?三、React也分为俩种创建方式1. 使用js的方式来创建…...
python玄阶斗技--tkinter库
目录 一.tkinter库介绍 二.功能实现 1.窗口创建 2.Button 按钮 3.Entry 文本输入域 4.text 文本框 5.Listbox 多选下拉框 6.Radiobutton 多选项按钮 7.Checkbutton 多选按钮 8.Scale 滑块(拉动条) 9.Scroolbar 滚动条 10.Menu 菜单栏 11. messagebox 消息框 12…...
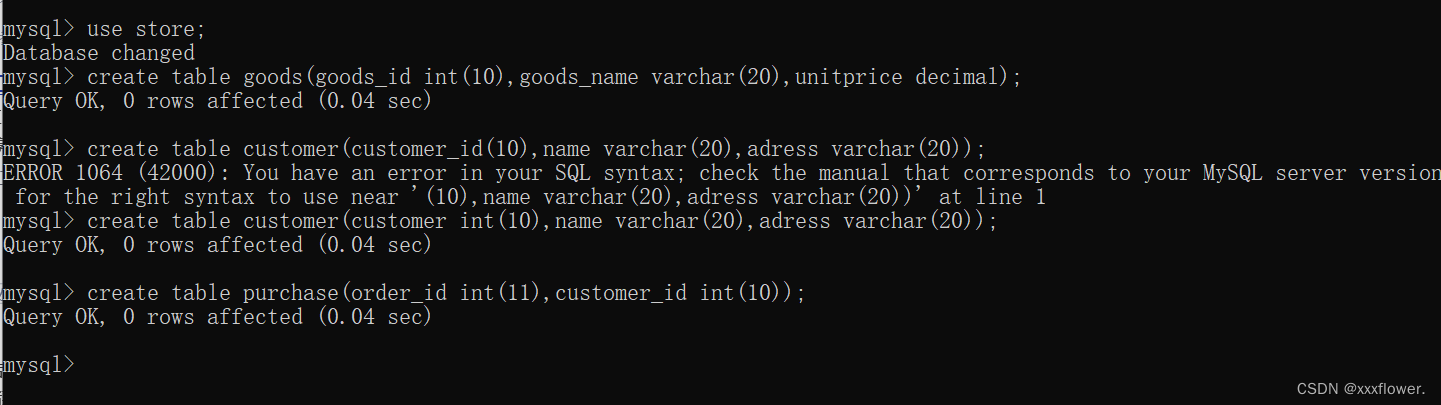
【MySQL】MySQL的介绍MySQL数据库及MySQL表的基本操作
文章目录数据库的介绍什么是数据库数据库分类MySQL的介绍数据库的基本操作数据库的操作创建数据库查看所有数据库选中指定的数据库删除数据库常用数据类型数值类型字符串类型日期类型表的操作创建表查看指定数据库下的所有表查看指定表的结构删除表小练习数据库的介绍 什么是数…...
)
【每日随笔】社会上层与中层的博弈 ( 技术无关、没事别点进来看 | 社会上层 | 上层与中层的保护层 | 推荐学习的知识 )
文章目录一、社会上层二、上层与中层的保护层三、推荐学习的知识一、社会上层 社会上层 掌握着 生产资料 和 权利 ; 社会中层 是 小企业主 和 中产打工人 ; 上层 名额有限 生产资料所有者 : 垄断巨头 , 独角兽 , 大型企业主 , 大型企业股东 , 数量有限 ;权利所有者 : 高级别的…...
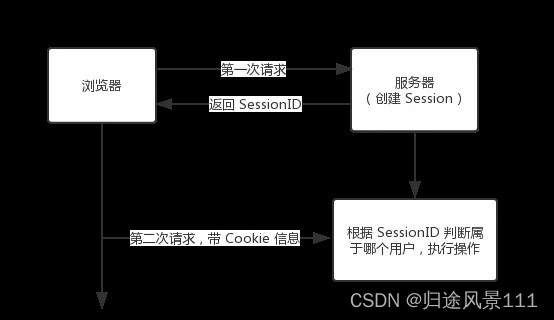
Cookie 和 Session的区别
文章目录时间:2023年3月23日第一:什么是 Cookie 和 Session ?什么是 Cookie什么是 Session第二:Cookie 和 Session 有什么不同?第三:为什么需要 Cookie 和 Session,他们有什么关联?第四&#x…...
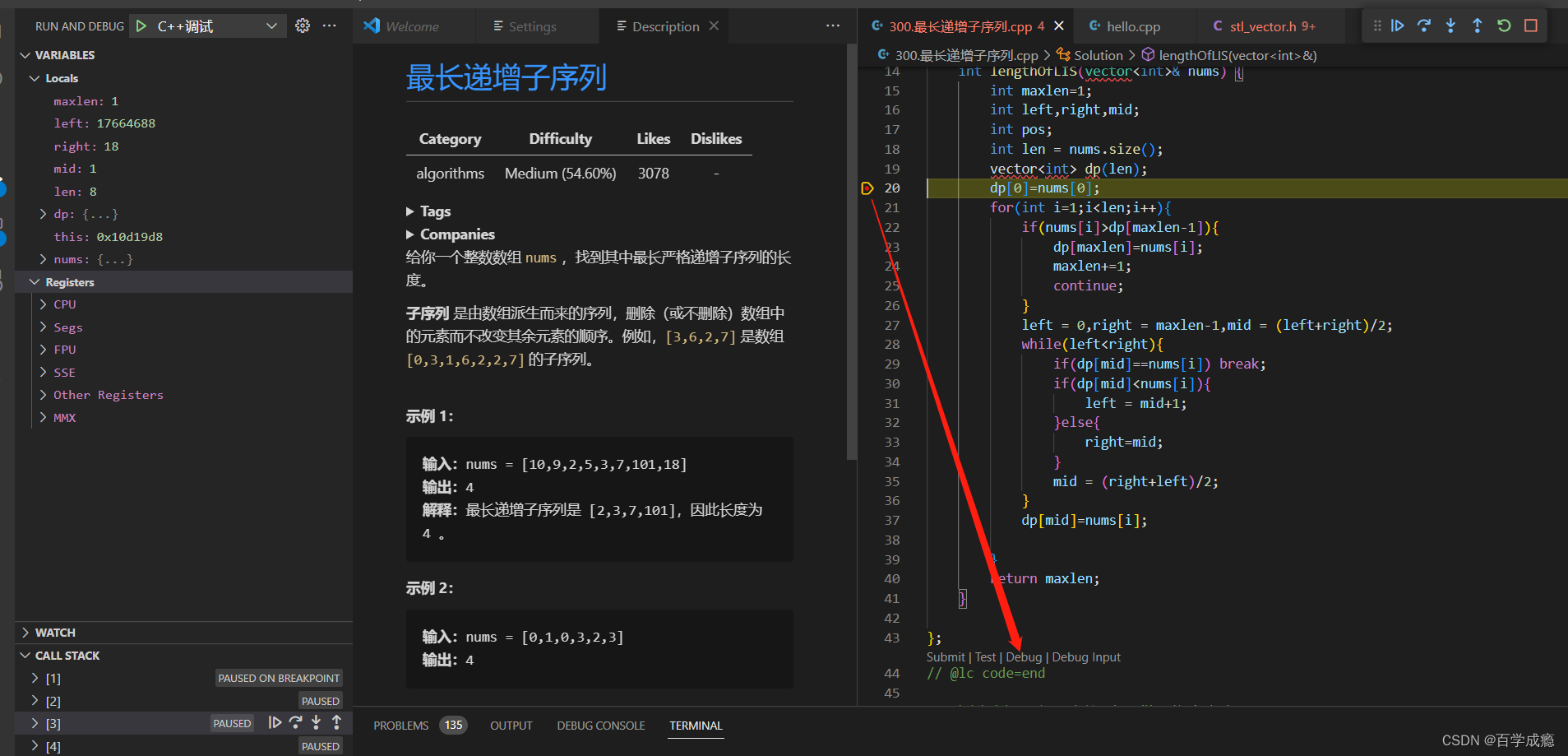
leetcode使用vscode调试C++代码
leetcode使用vscode调试C代码 这里记录一下大体思路吧,关于细节配置放上别的博主的链接,他们讲的更好 vscode只是编辑器,相当于记事本,需要下载minGW提供的编译器和调试器 官方介绍: C/C拓展不包括编译器或调试器&…...

树莓派Linux源码配置,树莓派Linux内核编译,树莓派Linux内核更换
目录 一 树莓派Linux的源码配置 ① 内核源码下载说明 ② 三种方法配置源码 二 树莓派Linux内核编译 ① 内核编译 ② 编译时报错及解决方案(亲测) 三 更换树莓派Linux内核 操作步骤说明 ● dmesg报错及解决方案(亲测࿰…...

【C语言】深度讲解 atoi函数 使用方法与模拟实现
文章目录atoi使用方法:atoi模拟实现atoi 功能:转化字符串到整数 头文件: #include <stdlib.h> int atoi (const char * str); 参数 str:要转换为整数的字符串 返回值 如果转换成功,函数将转换后的整数作为int值…...
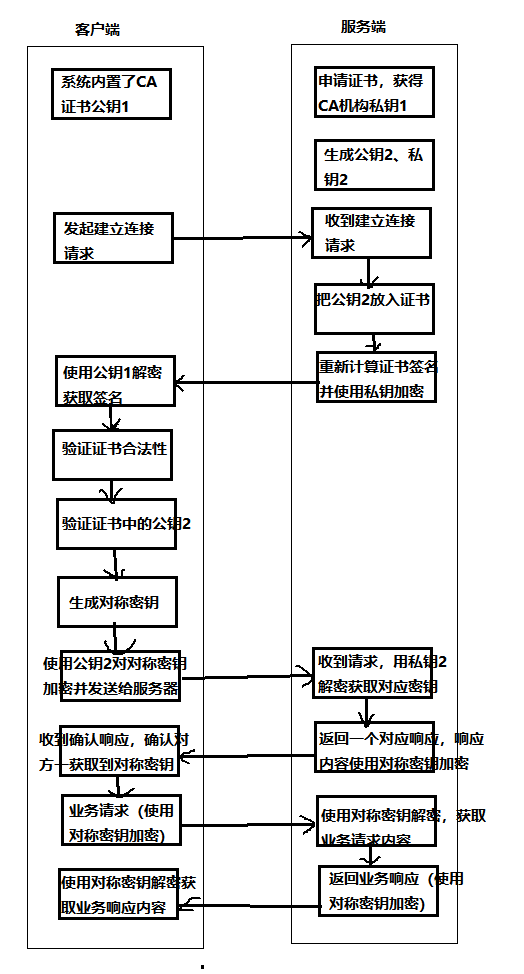
HTTPS的加密流程
1、概念HTTPS 是一个应用层协议,是在 HTTP 协议的基础上引入了一个加密层。HTTP 协议内容都是按照文本的方式明文传输的,这就导致在传输过程中出现一些被篡改的情况。HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协…...
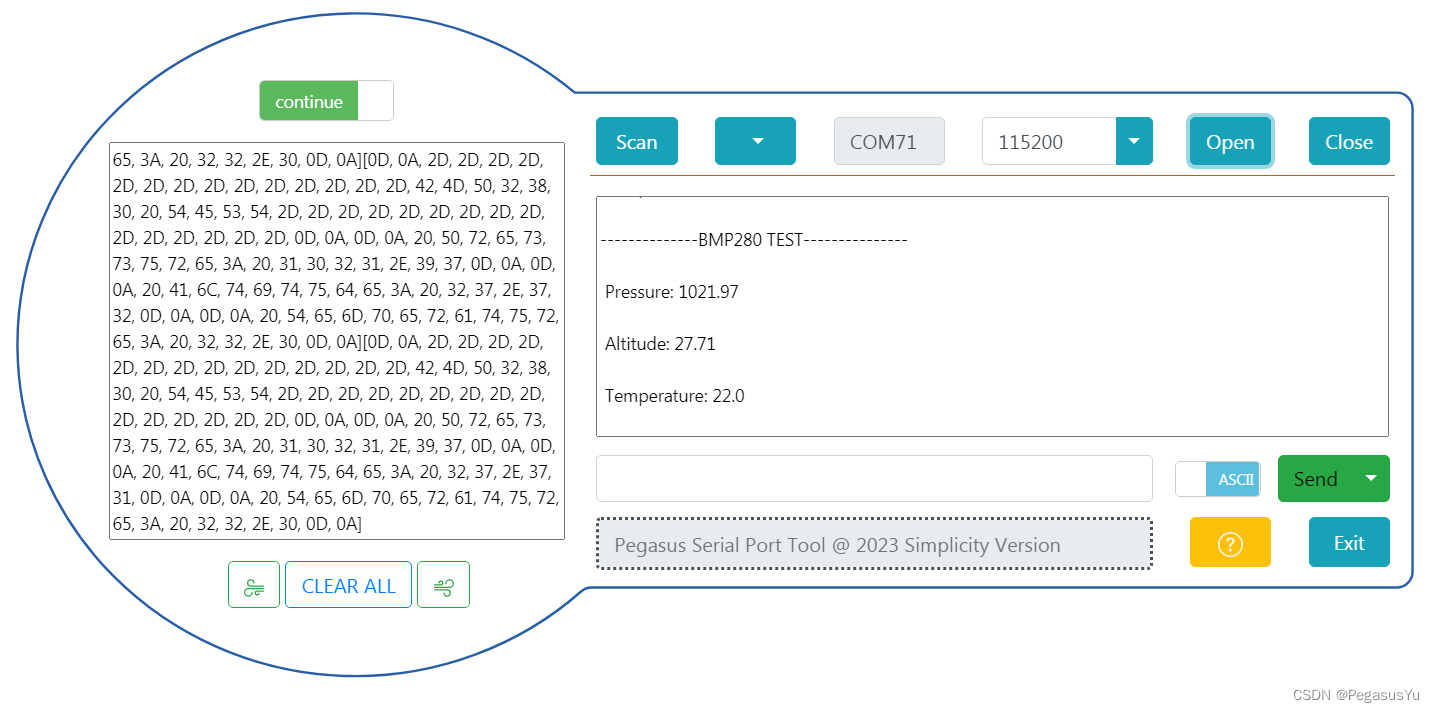
STM32配置读取BMP280气压传感器数据
STM32配置读取BMP280气压传感器数据 BMP280是在BMP180基础上增强的绝对气压传感器,在飞控领域的高度识别方面应用也比较多。 BMP280和BMP180的区别: 市面上也有一些模块: 这里介绍STM32芯片和BMP280的连接和数据读取。 电路连接 BMP28…...
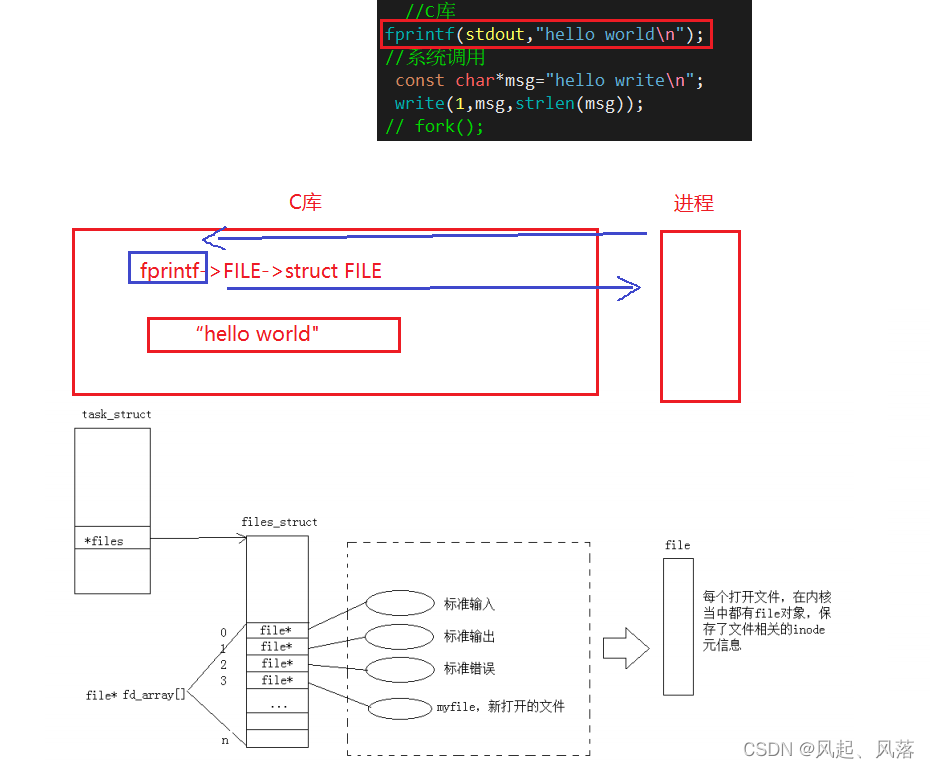
【Linux】 基础IO——文件(中)
文章目录1. 文件描述符为什么从3开始使用?2. 文件描述符本质理解3. 如何理解Linux下的一切皆文件?4. FILE是什么,谁提供?和内核的struct有关系么?证明struct FILE结构体中存在文件描述符fd5. 重定向的本质输出重定向输…...

Verilog时钟分频:从原理到工程实践,避坑指南与最佳方案
1. 项目概述:为什么时钟分频是数字设计的基石在数字电路和FPGA设计里,时钟信号就像是整个系统的心跳。它驱动着寄存器、状态机和数据流,确保所有操作在正确的节拍下同步进行。但现实情况是,我们手头的时钟源往往只有一个固定的频率…...
)
STM32 I2C驱动AT24C02 EEPROM:手把手教你搞定页边界对齐与连续读写(附完整代码)
STM32 I2C驱动AT24C02 EEPROM:页边界对齐与连续读写实战指南 在嵌入式开发中,EEPROM因其非易失性存储特性成为参数保存的首选方案。而AT24C02作为经典的I2C接口EEPROM,其页写入机制却暗藏玄机——许多开发者第一次遭遇"写入数据丢失&quo…...

FanControl深度技术解析:构建精准智能的风扇控制体系
FanControl深度技术解析:构建精准智能的风扇控制体系 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...
详情页开发避坑指南:路由配置与参数传递详解)
告别弹窗!若依框架(Ruoyi)详情页开发避坑指南:路由配置与参数传递详解
若依框架详情页开发实战:从路由配置到参数传递的深度解析 在若依框架的实际开发中,详情页的实现往往成为开发者遇到的"拦路虎"。明明按照文档操作,却频繁遭遇页面空白、参数丢失或控制台报错等问题。本文将深入剖析若依框架中前端路…...

Ren`Py 引擎初探:从零搭建你的Python视觉小说项目
1. 为什么选择RenPy开发视觉小说? 第一次听说RenPy是在三年前,当时我正在寻找能用Python开发的游戏引擎。试过Unity、Unreal这些主流引擎后,发现它们要么需要学习C#,要么对2D支持不够友好。直到偶然在论坛看到有人用RenPy做文字冒…...

Uncle小说阅读器:桌面级智能小说聚合与个性化阅读方案
Uncle小说阅读器:桌面级智能小说聚合与个性化阅读方案 【免费下载链接】uncle-novel 📖 Uncle小说,PC版,一个全网小说下载器及阅读器,目录解析与书源结合,支持有声小说与文本小说,可下载mobi、e…...

ARM Cortex-A72 GICv3中断处理机制与优化实践
1. ARM Cortex-A72 GIC CPU接口架构概述在ARMv8-A架构中,通用中断控制器(GIC)作为中断管理的核心组件,其CPU接口承担着处理器核心与中断源之间的桥梁作用。Cortex-A72处理器实现了GICv3架构规范,相较于前代GICv2,主要引入了以下关…...

诺和诺德牵手OpenAI,能否夺回“药王”之位?
01 诺和诺德牵手OpenAI就在最近,诺和诺德(Novo Nordisk)宣布与OpenAI合作,消息发布后,诺和诺德股价短线上涨近4%。很多人或许不知道“诺和诺德”,但“司美格鲁肽”却广为人知,诺和诺德正是研发出…...

从“芯”出发:RK3588与树莓派5的硬件博弈与开发者抉择
1. 芯片架构的硬核对决 当RK3588遇上树莓派5,这场硬件较量就像两位武林高手过招。RK3588用的是台积电8nm工艺,四核Cortex-A76加四核Cortex-A55的big.LITTLE设计,主频最高2.4GHz。实测跑分时,A76大核单核性能比树莓派5的Cortex-A76…...

K210实战:从环境适配到动态阈值,打造鲁棒的矩形识别系统
1. K210矩形识别系统概述 第一次接触K210的矩形识别功能时,我被它小巧的体积和强大的视觉处理能力惊艳到了。这款国产AI芯片虽然只有指甲盖大小,却能实时处理图像识别任务,特别适合嵌入式视觉应用。在实际电赛项目中,我们经常需要…...