[Few-shot learning] Siamese neural networks
这篇文章主要介绍的是Siamese Neural Network经典论文: Gregory Koch, et al., Siamese Neural Networks for One-shot Image Recognition. ICML 2015。
神经网络能够取得非常好的效果得益于使用大量的带标签数据进行有监督学习训练。但是这样的训练方法面临两个难题:
- 有些情况下我们无法采集到大量数据;
- 给数据打标签需要消耗大量人力财力。
当我们只有少量带标签的数据时如何训练出一个泛化性很好的模型呢?因此,few-shot learning问题应用而生。Few-shot learning仅需要每个类别含有少量带标签数据就可以对样本进行分类。
Gregory Koch等人提出了一种新的机器学习框架,当每个待测类别仅有1个样本的时候也能取得超过90%的识别准确率。
1. Omniglot数据集
《Siamese Neural Networks for One-shot Image Recognition》论文中使用了Omniglot数据集。Omniglot数据集是Few-shot Learning中常用的数据集,它采集了来自50个字母表的1623个手写字符。每一个字符仅仅包含20个样本,每一个样本都是来自于不同人的手写笔迹。样本图片的分辨率为105x105。
这面展示几个手写字符:
 | |
 | |
 | |
 |
Omniglot数据集的下载方法:
git clone https://github.com/brendenlake/omniglot.git
cd omniglot/python
unzip images_evaluation.zip
unzip images_background.zip
cd ../..
# setup directory for saving models
mkdir models
Omniglot数据集通常被划分为30个训练字母表(background),20个测试字母表(evaluation)。这30个训练样本和20个测试样本是完全没有交际的,也就是说测试样本集中的类别完全是一个新的类别。这也是few-shot learning和传统的supervised learning不同的地方。
2. A one-shot learning baseline / 1 nearest neighbor
对于nnn-way 111-shot问题,由于我们手中只有一个样本,所以没有办法训练得到一个泛化性很好的神经网络模型。最简单的方法是K-nearest neighbours,只需计算测试样本到训练样本的欧式距离,然后选择最近的一个作为预测标签:
C(x^)=argmin∣∣x^−xc∣∣C(\hat{x})=\text{argmin}||\hat{x}-x_c|| C(x^)=argmin∣∣x^−xc∣∣
论文中显示,1-nn在202020-way 111-shot任务上的准确率为28%,而盲猜的正确率只有5%。因此,1-nn对于解决one-shot问题还是有用的,但是效果并不理想,但可以作为一个baseline。
3. Siamese Neural Networks
由于训练样本太少,用它来训练网络肯定会造成过拟合,所以我们不能像传统的有监督学习那样其训练分类模型,而是要让模型如何区分不同。
Siamese Networks即孪生网络,他们共享一部分网络结构。将两张图片输入到网络中得到两个特在向量。我们用向量的绝对差值度量两张图片的相似性。Siamese网络的结构图如下所示:
[图片上传失败…(image-275fb8-1679970385410)]
Siamese网络使用相同的特征提取网络提取特在得到两个向量,然后训练步骤为:
- 将两个样本分别输入到两个网络中,得到两个特征向量
x1和x2; - 计算向量的L1距离,
dis = np.abs(x1 - x2); - 将距离
dis输入到一个全连接网络中,全连接网络的神经元个数是1; - 经过Sigmoid函数得到预测输出,介于0-1之间。0表示两个样本属于不同类别,1表示两个样本属于同一类别。
- 使用二元交叉熵损失函数计算loss,反向传播更新参数。
对于kkk-way 111-shot问题,我们需要比较querry set样本与kkk个support sample的score,选择score最大的support sample作为标签。例如下图的252525-way 111-shot问题,相似度越高,Siamese 网络的输出值越大,因此可以确定query sample 的类别。
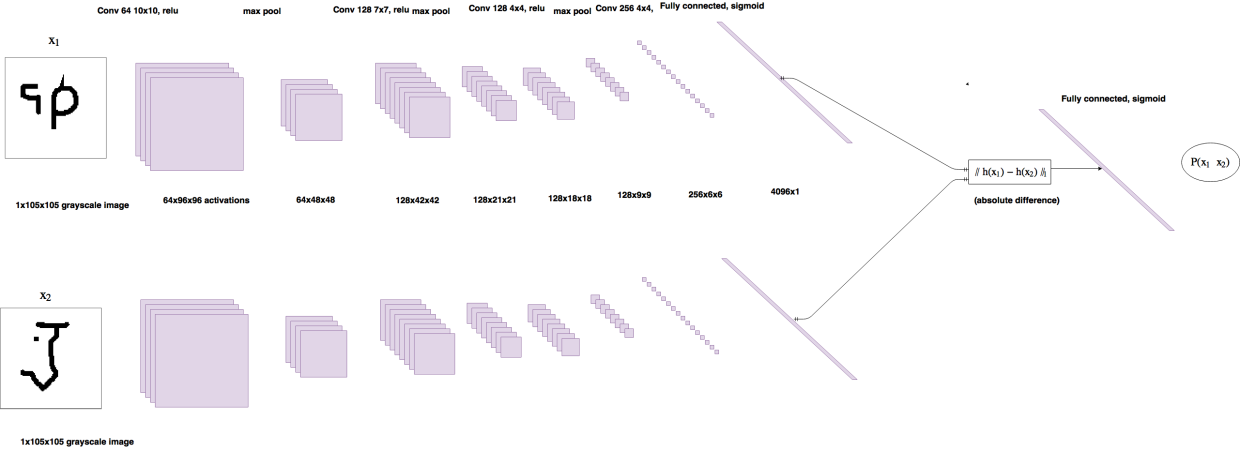
论文中模型的一般部署方法在Pytorch中的实现如下(参考4):
import torch.nn as nn
class Siamese(nn.Module):def __init__(self):super(Siamese, self).__init__()self.conv = nn.Sequential(nn.Conv2d(1, 64, 10), # 64@96*96nn.ReLU(inplace=True),nn.MaxPool2d(2), # 64@48*48nn.Conv2d(64, 128, 7),nn.ReLU(), # 128@42*42nn.MaxPool2d(2), # 128@21*21nn.Conv2d(128, 128, 4),nn.ReLU(), # 128@18*18nn.MaxPool2d(2), # 128@9*9nn.Conv2d(128, 256, 4),nn.ReLU(), # 256@6*6)self.liner = nn.Sequential(nn.Linear(9216, 4096), nn.Sigmoid())self.out = nn.Linear(4096, 1)def forward_one(self, x):x = self.conv(x)x = x.view(x.size()[0], -1)x = self.liner(x)return xdef forward(self, x1, x2):out1 = self.forward_one(x1)out2 = self.forward_one(x2)dis = torch.abs(out1 - out2)out = self.out(dis)return out
损失函数使用torch.nn.BCEWithLogitsLoss(size_average=True)函数。torch.nn.BCELoss函数,如果输出经过了nn.Sigmoid(),则损失函数就用torch.nn.BCELoss。
loss_fn = torch.nn.BCEWithLogitsLoss(size_average=True)
net = Siamese()
optimizer.zero_grad()
output = net.forward(img1, img2)
loss = loss_fn(output, label)
loss_val += loss.item()
loss.backward()
optimizer.step()
4. Few-shot task
4.1 Training tasks
Few-shot learnig的难点在于如何生成training tasks和test tasks, 这里我参考文献4的方法:
class OmniglotTrain(Dataset):def __init__(self, dataPath, transform=None):super(OmniglotTrain, self).__init__()np.random.seed(0)# self.dataset = datasetself.transform = transformself.datas, self.num_classes = self.loadToMem(dataPath)def loadToMem(self, dataPath):print("begin loading training dataset to memory")datas = {}agrees = [0, 90, 180, 270]idx = 0for agree in agrees:for alphaPath in os.listdir(dataPath):for charPath in os.listdir(os.path.join(dataPath, alphaPath)):datas[idx] = []for samplePath in os.listdir(os.path.join(dataPath, alphaPath, charPath)):filePath = os.path.join(dataPath, alphaPath, charPath, samplePath)datas[idx].append(Image.open(filePath).rotate(agree).convert('L'))idx += 1print("finish loading training dataset to memory")return datas,idxdef __len__(self):return 21000000def __getitem__(self, index):# image1 = random.choice(self.dataset.imgs)label = Noneimg1 = Noneimg2 = None# get image from same classif index % 2 == 1: # odd numberlabel = 1.0idx1 = random.randint(0, self.num_classes - 1)image1 = random.choice(self.datas[idx1])image2 = random.choice(self.datas[idx1])# get image from different classelse: # even numberlabel = 0.0idx1 = random.randint(0, self.num_classes - 1)idx2 = random.randint(0, self.num_classes - 1)while idx1 == idx2:idx2 = random.randint(0, self.num_classes - 1)image1 = random.choice(self.datas[idx1])image2 = random.choice(self.datas[idx2])if self.transform:image1 = self.transform(image1)image2 = self.transform(image2)return image1, image2, torch.from_numpy(np.array([label], dtype=np.float32))
这个方法方法比较常规,就是随即产生image pair,属于统一个字符标签为1,不属于标签为0。
然后使用
trainSet = OmniglotTrain(train_path, transform=data_transforms)
trainLoader = DataLoader(trainSet, batch_size=batch_size, shuffle=False, num_workers=workers)
调用即可。
4.2 Test tasks
需要着重注意的是测试集任务:
class OmniglotTest(Dataset):def __init__(self, dataPath, transform=None, times=200, way=20):np.random.seed(1)super(OmniglotTest, self).__init__()self.transform = transformself.times = times # number of samples, 参与测试的样本数量self.way = wayself.img1 = Noneself.c1 = Noneself.datas, self.num_classes = self.loadToMem(dataPath)def loadToMem(self, dataPath):print("begin loading test dataset to memory")datas = {}idx = 0for alphaPath in os.listdir(dataPath):for charPath in os.listdir(os.path.join(dataPath, alphaPath)):datas[idx] = []for samplePath in os.listdir(os.path.join(dataPath, alphaPath, charPath)):filePath = os.path.join(dataPath, alphaPath, charPath, samplePath)datas[idx].append(Image.open(filePath).convert('L'))idx += 1print("finish loading test dataset to memory")return datas, idxdef __len__(self):return self.times * self.waydef __getitem__(self, index):idx = index % self.waylabel = None# generate image pair from same classif idx == 0:self.c1 = random.randint(0, self.num_classes - 1)self.img1 = random.choice(self.datas[self.c1])img2 = random.choice(self.datas[self.c1])# generate image pair from different classelse:c2 = random.randint(0, self.num_classes - 1)while self.c1 == c2:c2 = random.randint(0, self.num_classes - 1)img2 = random.choice(self.datas[c2]) if self.transform:img1 = self.transform(self.img1)img2 = self.transform(img2)return img1, img2
这里需要提前了解到的一个前提是:
testSet = OmniglotTest(Flags.test_path, transform=transforms.ToTensor(), times = times, way = way)
testLoader = DataLoader(testSet, batch_size=way, shuffle=False, num_workers=workers)
这里loadToMem函数是往每一个character的往容器中存放数据,而每一个character有20个样本,所以self.datas中每20个样本为一个character,整个测试集evaluation数据集有659个character,每个chatacter共有20个样本,所以共有659*20=13180个样本。
这里要注意的是testLoader的shuffle的参数False,也就是说测试集是从第0个索引开始一个一个读取的。所以每一个epoch刚好是读取了一个类别的20个样本,也就是每次只判断一个类别预测结果的对错。
好了,现在我们来看看__getitem__函数。由于索引是从0开始,一次20个,所以第一个batch的索引为0-20,从0开始一次读取image。因此,必然会经过if idx == 0判断条件。运行步骤为:
- index = 0
- idx = index % 20 = 0
- if idx == 0成立,从所有类别中随即选择一个类别,在该类别下随机选择两张图片img1, img2
- index = 1,2,3,4,…,19
- idx = index % 20 = 1,2,3,4,…,19
- if idx == 0不成立,进入else语句,随即选择两个不同类别的图片img1, img2
- 第一个batch完成,判断batch是否读取完成,若是则退出循环,否则index+1,返回步骤2
这里测试的代码为:
for _, (test1, test2) in enumerate(testLoader, 1):test1, test2 = test1.cuda(), test2.cuda()test1, test2 = Variable(test1), Variable(test2)output = net.forward(test1, test2).data.cpu().numpy()pred = np.argmax(output)if pred == 0:right += 1else: error += 1
因为每个batch只有第一个img pair是相同的,如果预测正确,np.argmax(output)是0
本文原载于我的简书
Reference
- One Shot Learning and Siamese Networks in Keras
- Github - One-Shot-Learning-with-Siamese-Networks (Keras)
- Github - Pokemon: Siamese-Network-with-Contrastive-loss
- Github - Siamese Networks for One-Shot Learning (pytorch)
相关文章:
[Few-shot learning] Siamese neural networks
这篇文章主要介绍的是Siamese Neural Network经典论文: Gregory Koch, et al., Siamese Neural Networks for One-shot Image Recognition. ICML 2015。 神经网络能够取得非常好的效果得益于使用大量的带标签数据进行有监督学习训练。但是这样的训练方法面临两个难题…...

利用qiankun框架在自己项目中集成拖拽式低代码数据可视化开发平台
目前微前端已经是很成熟的技术了,各大公司都推出了自己的微前端框架,比如蚂蚁的qiankun,京东的micro-app,如果你的子应用不使用vite构建的话,我会更加推荐后者,micro-app使用更加简单,micro-app…...

【spring boot】在Java中操作缓存:
文章目录一、Jedis二、Spring Data Redis(常用)【1】pom.xml【2】application.yml【3】RedisConfig【4】RuiJiWaiMaiApplicationTests三、Spring Cache【1】常用注解:【2】使用案例【3】底层不使用redis,重启服务,内存…...
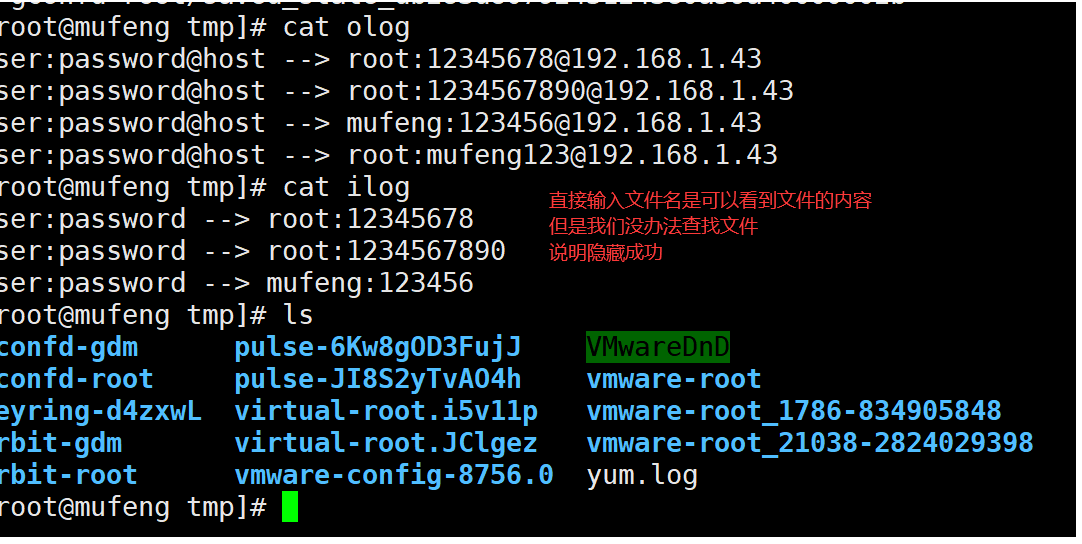
擂台赛-安全攻防之使用openssh后门获取root密码实战
前言 大家好,我是沐风晓月,我们开始组队学习了,介绍下我们的情况: 这几天跟队员 迎月,虹月,心月,古月打擂台,我和心月一组,相互攻占对方服务器。 终于在今早凌晨三点拿…...
关于React入门基础从哪学起?
文章目录前言一、React简介1. React是什么2. react 与 vue 最大的区别就是:3. React特点4. React介绍描述5. React高效的原因6.React强大之处二、React基础格式1.什么是虚拟dom?2.为什么要创建虚拟dom?三、React也分为俩种创建方式1. 使用js的方式来创建…...
python玄阶斗技--tkinter库
目录 一.tkinter库介绍 二.功能实现 1.窗口创建 2.Button 按钮 3.Entry 文本输入域 4.text 文本框 5.Listbox 多选下拉框 6.Radiobutton 多选项按钮 7.Checkbutton 多选按钮 8.Scale 滑块(拉动条) 9.Scroolbar 滚动条 10.Menu 菜单栏 11. messagebox 消息框 12…...
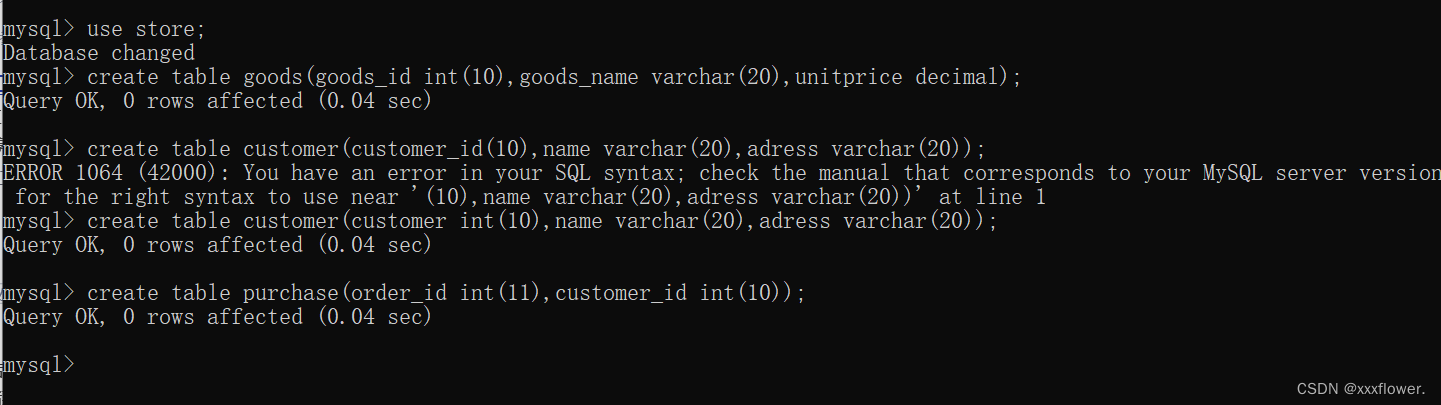
【MySQL】MySQL的介绍MySQL数据库及MySQL表的基本操作
文章目录数据库的介绍什么是数据库数据库分类MySQL的介绍数据库的基本操作数据库的操作创建数据库查看所有数据库选中指定的数据库删除数据库常用数据类型数值类型字符串类型日期类型表的操作创建表查看指定数据库下的所有表查看指定表的结构删除表小练习数据库的介绍 什么是数…...
)
【每日随笔】社会上层与中层的博弈 ( 技术无关、没事别点进来看 | 社会上层 | 上层与中层的保护层 | 推荐学习的知识 )
文章目录一、社会上层二、上层与中层的保护层三、推荐学习的知识一、社会上层 社会上层 掌握着 生产资料 和 权利 ; 社会中层 是 小企业主 和 中产打工人 ; 上层 名额有限 生产资料所有者 : 垄断巨头 , 独角兽 , 大型企业主 , 大型企业股东 , 数量有限 ;权利所有者 : 高级别的…...
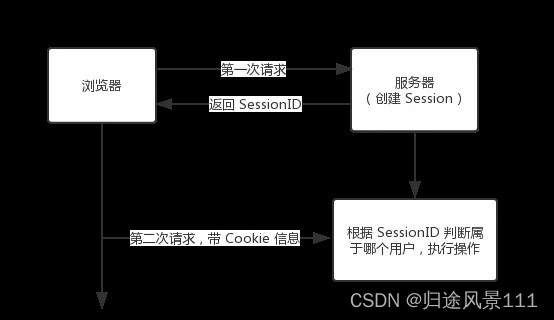
Cookie 和 Session的区别
文章目录时间:2023年3月23日第一:什么是 Cookie 和 Session ?什么是 Cookie什么是 Session第二:Cookie 和 Session 有什么不同?第三:为什么需要 Cookie 和 Session,他们有什么关联?第四&#x…...
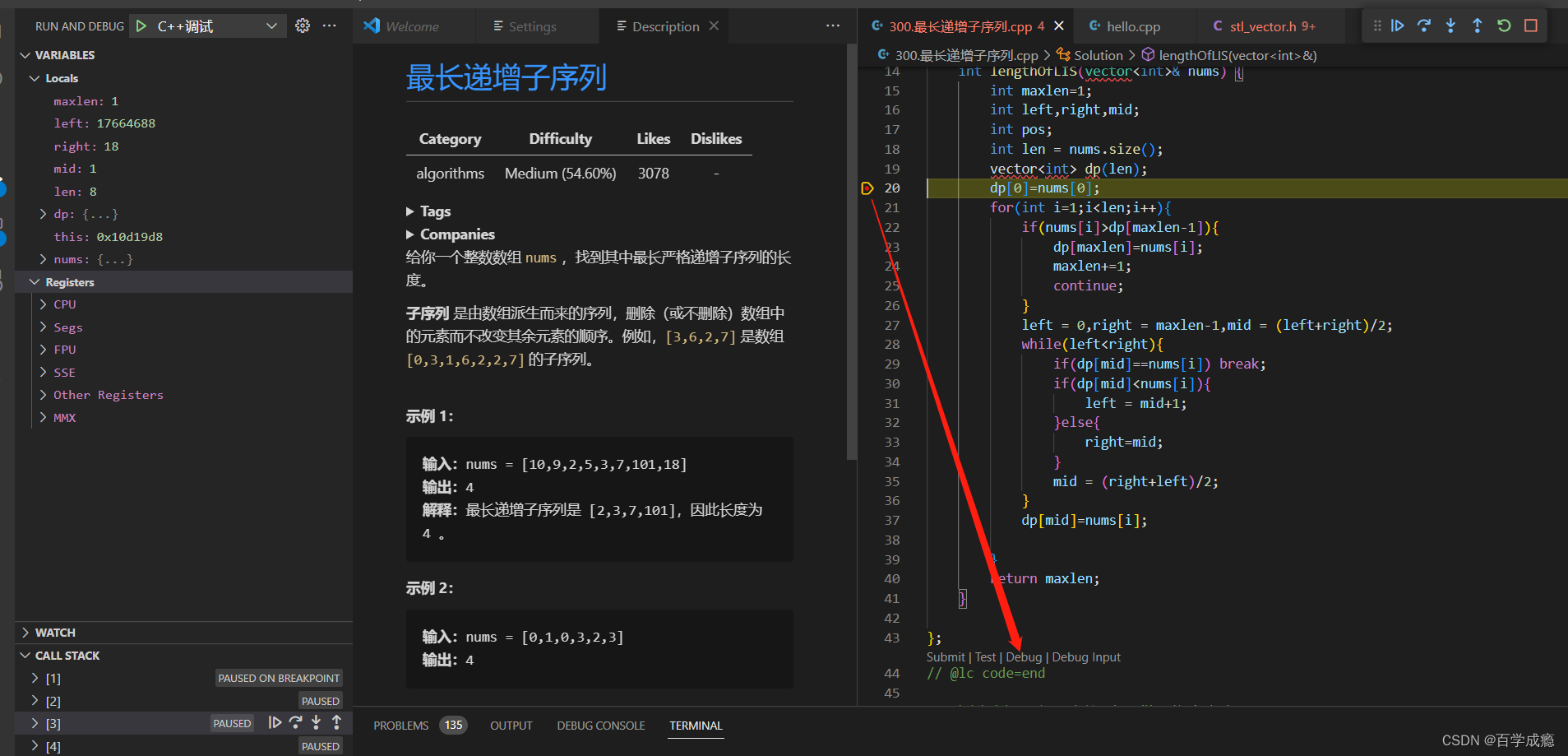
leetcode使用vscode调试C++代码
leetcode使用vscode调试C代码 这里记录一下大体思路吧,关于细节配置放上别的博主的链接,他们讲的更好 vscode只是编辑器,相当于记事本,需要下载minGW提供的编译器和调试器 官方介绍: C/C拓展不包括编译器或调试器&…...

树莓派Linux源码配置,树莓派Linux内核编译,树莓派Linux内核更换
目录 一 树莓派Linux的源码配置 ① 内核源码下载说明 ② 三种方法配置源码 二 树莓派Linux内核编译 ① 内核编译 ② 编译时报错及解决方案(亲测) 三 更换树莓派Linux内核 操作步骤说明 ● dmesg报错及解决方案(亲测࿰…...

【C语言】深度讲解 atoi函数 使用方法与模拟实现
文章目录atoi使用方法:atoi模拟实现atoi 功能:转化字符串到整数 头文件: #include <stdlib.h> int atoi (const char * str); 参数 str:要转换为整数的字符串 返回值 如果转换成功,函数将转换后的整数作为int值…...
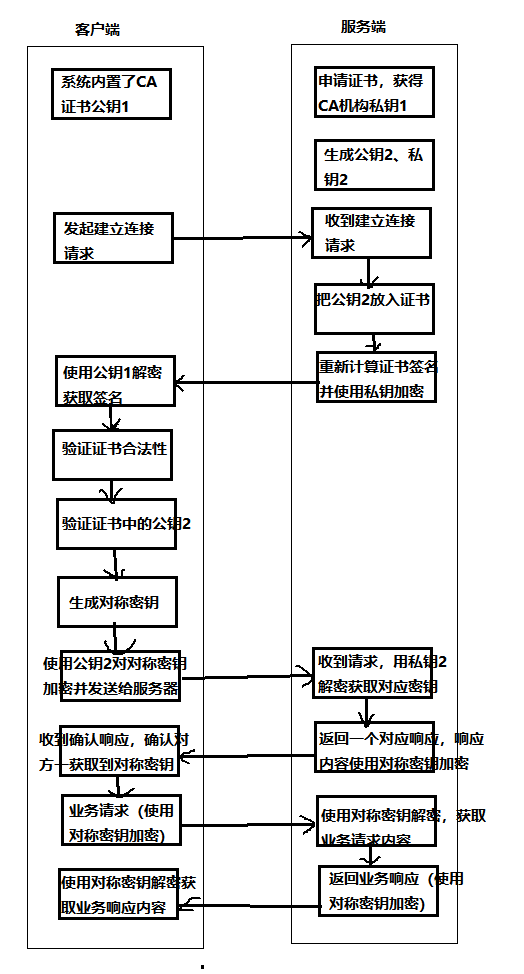
HTTPS的加密流程
1、概念HTTPS 是一个应用层协议,是在 HTTP 协议的基础上引入了一个加密层。HTTP 协议内容都是按照文本的方式明文传输的,这就导致在传输过程中出现一些被篡改的情况。HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协…...
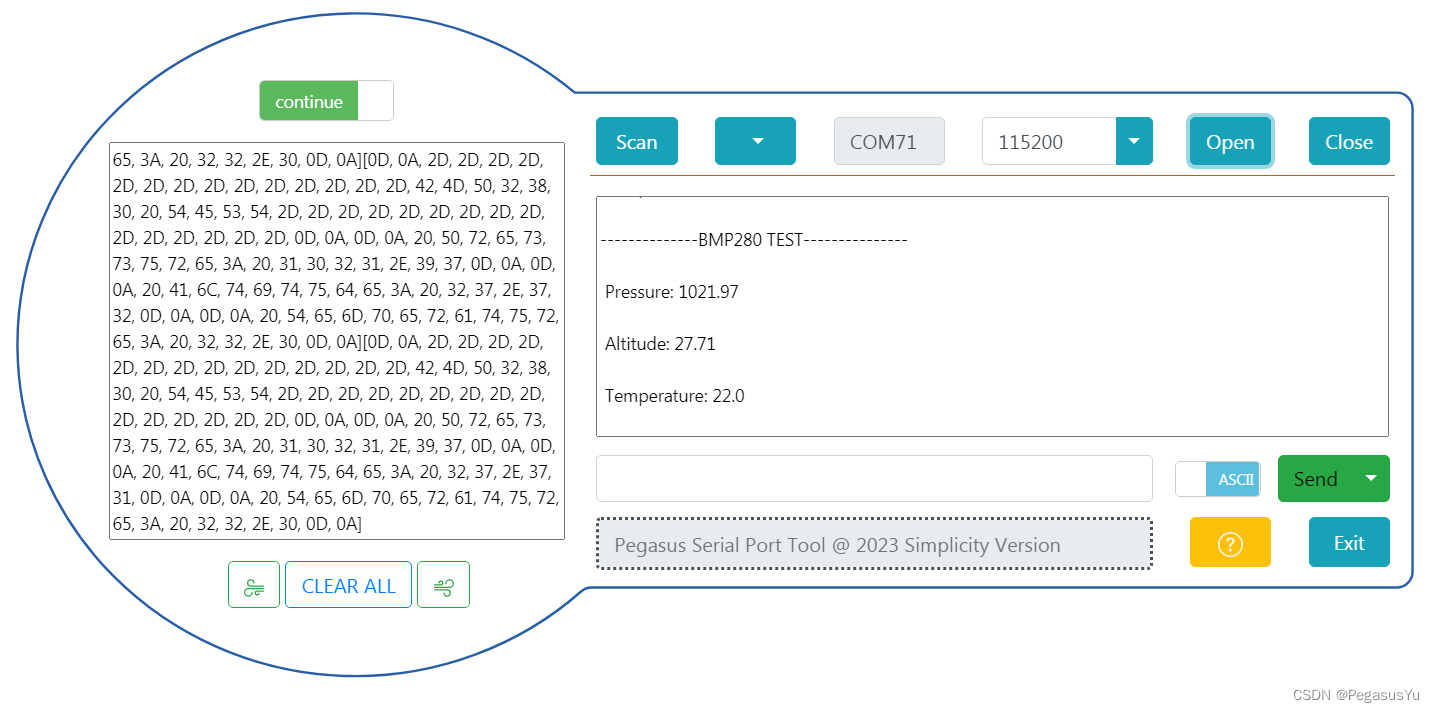
STM32配置读取BMP280气压传感器数据
STM32配置读取BMP280气压传感器数据 BMP280是在BMP180基础上增强的绝对气压传感器,在飞控领域的高度识别方面应用也比较多。 BMP280和BMP180的区别: 市面上也有一些模块: 这里介绍STM32芯片和BMP280的连接和数据读取。 电路连接 BMP28…...
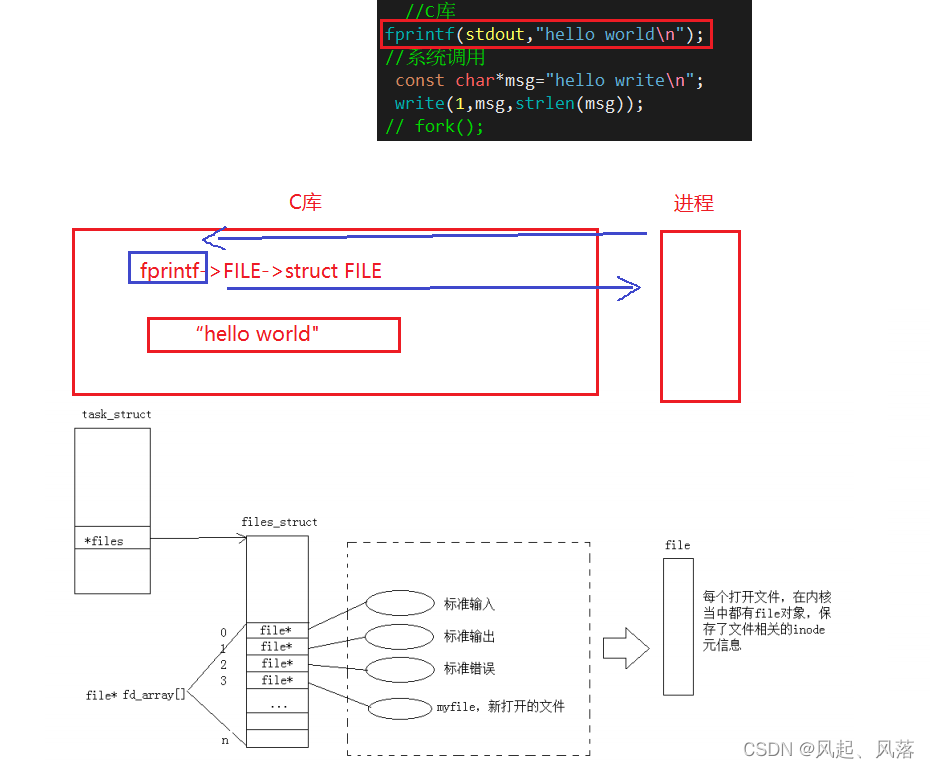
【Linux】 基础IO——文件(中)
文章目录1. 文件描述符为什么从3开始使用?2. 文件描述符本质理解3. 如何理解Linux下的一切皆文件?4. FILE是什么,谁提供?和内核的struct有关系么?证明struct FILE结构体中存在文件描述符fd5. 重定向的本质输出重定向输…...

蓝桥杯刷题冲刺 | 倒计时13天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录1.母牛的故事2.魔板1.母牛的故事 题目 链接: [递归]母牛的故事 - C语言网 (dotcpp.c…...
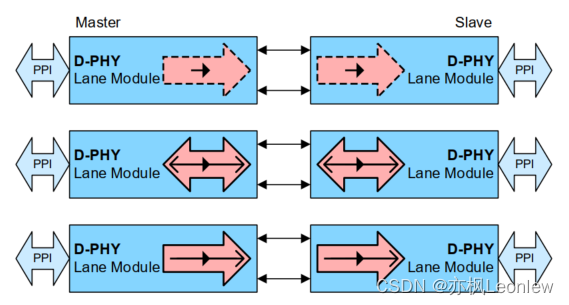
MIPI D-PHYv2.5笔记(5) -- 不同的PHY配置方式
声明:作者是做嵌入式软件开发的,并非专业的硬件设计人员,笔记内容根据自己的经验和对协议的理解输出,肯定存在有些理解和翻译不到位的地方,有疑问请参考原始规范看 规范5.7章节列举了一些常见的PHY配置,但实…...

【周末闲谈】文心一言,模仿还是超越?
个人主页:【😊个人主页】 系列专栏:【❤️周末闲谈】 周末闲谈 ✨第一周 二进制VS三进制 文章目录周末闲谈前言一、背景环境二、文心一言?(_)?三、文心一言的优势?😗😗😗四、文心一…...

《一“企”谈》 | 「佛山市政」:携手企企通,让采购业务数智化
近日,国家施工总承包壹级企业「佛山市市政建设工程有限公司」(以下简称“佛山市政”)正积极布局数字化建设工作,基于采购业务数智化,携手企企通打造了SaaS采购云平台。 01、岭南建筑强企 匠心铸造精品 …...
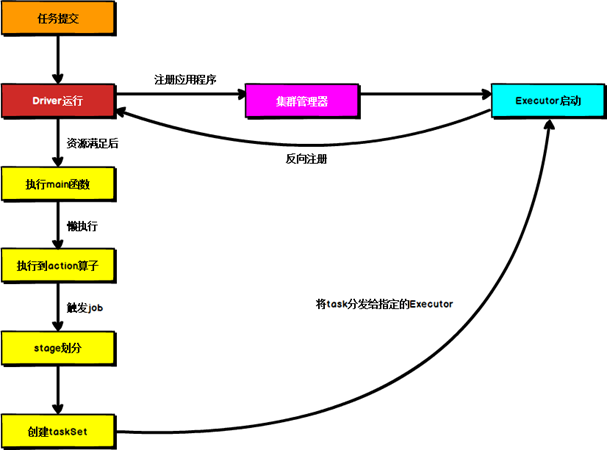
Spark运行架构
目录 1 运行架构 2 核心组件 2.1 Driver 2.2 Executor 2.3 Master & Worker 2.4 ApplicationMaster 3 核心概念 3.1 Executor 与 Core 3.2 并行度( Parallelism) 3.3 有向无环图( DAG) 4 提交流程 …...

终极指南:如何使用webSpoon快速构建企业级数据集成平台
终极指南:如何使用webSpoon快速构建企业级数据集成平台 【免费下载链接】pentaho-kettle webSpoon is a web-based graphical designer for Pentaho Data Integration with the same look & feel as Spoon 项目地址: https://gitcode.com/gh_mirrors/pen/pent…...

Taotoken用量看板如何帮助团队管理大模型API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队管理大模型API成本 作为团队的技术负责人,在引入大模型能力支持多个项目时,一…...

缠论自动化分析终极指南:ChanlunX让复杂技术分析变得简单
缠论自动化分析终极指南:ChanlunX让复杂技术分析变得简单 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 你是否曾经面对复杂的K线图感到迷茫?是否想要掌握缠论分析却苦于手工绘制…...

解密Ryujinx:5个核心技术原理让你理解现代游戏模拟器的设计哲学
解密Ryujinx:5个核心技术原理让你理解现代游戏模拟器的设计哲学 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx作为一款基于C#开发的Nintendo Switch模拟器&#x…...

容器化自动化数据抓取平台OpenClaw-Compose部署与实战指南
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一个自动化数据抓取和处理的项目,发现了一个挺有意思的GitHub仓库:alexleach/openclaw-compose。乍一看标题,你可能会觉得这又是一个普通的Docker Compose编排文件集合…...

Ubuntu Apache WebDAV 服务部署与多用户自动化管理
1. WebDAV服务基础认知与场景价值 第一次听说WebDAV这个词时,我也是一头雾水——这串字母组合看起来像某种神秘协议。直到有次团队需要共享设计素材库,才发现这个1996年就诞生的老协议,在云存储时代依然散发着独特魅力。简单来说,…...

LTC3305铅酸电池平衡器与PTC限流方案设计
1. LTC3305铅酸电池平衡器工作原理 LTC3305是Linear Technology(现属ADI)推出的一款专用于铅酸电池组的主动平衡控制器。其核心功能是通过一个辅助电池(AUX)在串联电池组间进行电荷转移,实现电压均衡。这种架构特别适合…...

在高校科研项目中采用 Taotoken 实现多模型对比实验的便捷方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在高校科研项目中采用 Taotoken 实现多模型对比实验的便捷方案 高校科研团队在进行大模型相关的对比实验时,常常面临一…...

ARM RAS架构中ERR<n>FR寄存器解析与应用
1. ARM RAS架构与错误记录机制概述 在服务器和关键任务计算领域,硬件可靠性直接决定了系统的可用性水平。ARMv8/v9架构中的RAS(Reliability, Availability, Serviceability)扩展提供了一套完整的硬件错误处理机制,其核心是通过一组专用寄存器实现错误检测…...

如何构建工业级智能预测性维护系统:基于LSTM的5大实战策略
如何构建工业级智能预测性维护系统:基于LSTM的5大实战策略 【免费下载链接】Predictive-Maintenance-using-LSTM Example of Multiple Multivariate Time Series Prediction with LSTM Recurrent Neural Networks in Python with Keras. 项目地址: https://gitcod…...