CENet及多模态情感计算实战(论文复现)
CENet及多模态情感计算实战(论文复现)
本文所涉及所有资源均在传知代码平台可获取
文章目录
- CENet及多模态情感计算实战(论文复现)
- 概述
- 研究背景
- 主要贡献
- 论文思路
- 主要内容和网络架构
- 数据集介绍
- 性能对比
- 复现过程(重要)
- 演示结果
概述
本文对 “Cross-Modal Enhancement Network for Multimodal Sentiment Analysis” 论文进行讲解和手把手复现教学,解决当下热门的多模态情感计算问题,并展示在MOSI和MOSEI两个数据集上的效果
研究背景
情感分析在人工智能向情感智能发展中起着重要作用。早期的情感分析研究主要集中在分析单模态数据上,包括文本情感分析、图像情感分析、音频情感分析等。然而,人类的情感是通过人体的多种感官来传达的。因此,单模态情感分析忽略了人类情感的多维性。相比之下,多模态情感分析通过结合文本、视觉和音频等多模态数据来推断一个人的情感状态。与单模态情感分析相比,多模态数据包含多样化的情感信息,具有更高的预测精度。目前,多模态情感分析已被广泛应用于视频理解、人机交互、政治活动等领域。近年来,随着互联网和各种多媒体平台的快速发展,通过互联网表达情感的载体和方式也变得越来越多样化。这导致了多媒体数据的快速增长,为多模态情感分析提供了大量的数据源。下图展示了多模态在情感计算任务中的优势。

主要贡献
- 提出了一种跨模态增强网络,通过融入长范围非文本情感语境来增强预训练语言模型中的文本表示;
- 提出一种特征转换策略,通过减小文本模态和非文本模态的初始表示之间的分布差异,促进了不同模态的融合;
- 融合了新的预训练语言模型SentiLARE来提高模型对情感词的提取效率,从而提升对情感计算的准确性。
论文思路
作者提出的跨模态增强网络(CENet)模型通过将视觉和声学信息集成到语言模型中来增强文本表示。在基于transformer的预训练语言模型中嵌入跨模态增强(CE)模块,根据非对齐非文本数据中隐含的长程情感线索增强每个单词的表示。此外,针对声学模态和视觉模态,提出了一种特征转换策略,以减少语言模态和非语言模态的初始表示之间的分布差异,从而促进不同模态的融合。
主要内容和网络架构

通过该图,我们可以看出该模型主要有以下几部分组成:
- 非文本模态特征转化
- 跨模态增强
- 预训练语言模型输出
- 非文本模态转换
针对预训练语言模型,初始文本表示是基于词汇表的单词索引序列,而视觉和听觉的表示则是实值向量序列。为了缩小这些异质模态之间的初始分布差异,进而减少在融合过程中非文本特征和文本特征之间的分布差距,本文提出了一种将非文本向量转换为索引的特征转换策略。这种策略有助于促进文本表征与非文本情感语境的有机融合。
具体而言,特征转换策略利用无监督聚类算法分别构建了“声学词汇表”和“视觉词汇表”。通过查询这些非语言词汇表,可以将原始的非语言特征序列转换为索引序列。下图展示了特征转换过程的具体步骤。考虑到k-means方法具有计算复杂度低和实现简单等优点,作者选择使用k-means算法来学习非语言模态的词汇。

- 跨模态增强模块
本文提出的CE模块旨在将长程视觉和声学信息集成到预训练语言模型中,以增强文本的表示能力。CE模块的核心组件是跨模态嵌入单元,其结构如下图所示。该单元利用跨模态注意力机制捕捉长程非文本情感信息,并生成基于文本的非语言嵌入。嵌入层的参数可学习,用于将经过特征转换策略处理后得到的非文本索引向量映射到高维空间,然后生成文本模态对非文本模态的注意力权重矩阵。

在初始训练阶段,由于语言表征和非语言表征处于不同的特征空间,它们之间的相关性通常较低。因此,注意力权重矩阵中的元素可能较小。为了更有效地学习模型参数,研究者在应用softmax之前使用超参数来缩放这些注意力权重矩阵。
基于注意力权重矩阵,可以生成基于文本的非语言向量。将基于文本的声学嵌入和基于文本的视觉嵌入结合起来,形成非语言增强嵌入。最后,通过整合非语言增强嵌入来更新文本的表示。因此,CE模块的提出旨在为文本提供非语言上下文信息,通过增加非语言增强嵌入来调整文本表示,从而使其在语义上更加准确和丰富。
- 预训练语言模型输出
作者采用SentiLARE作为语言模型,其利用包括词性和单词情感极性在内的语言知识来学习情感感知的语言表示。CE模块被集成到预训练语言模型的第i层中。值得注意的是,任何基于Transformer的预训练语言模型都可以与CE模块集成。下面是作者根据SentiLARE的设置进行的步骤:
- 给定一个单词序列,首先通过Stanford Log-Linear词性(POS)标记器学习其词性序列,并通过SentiwordNet学习单词级情感极性序列。
- 然后,使用预训练语言模型的分词器获取词标索引序列。这个序列作为输入,产生一个初步的增强语言知识表示。
- 更新后的文本表示将作为第(i+1)层的输入,并通过SentiLARE中的剩余层进行处理。
- 每一层的输出将是具有视觉和听觉信息的文本主导的高级情感表示。
- 最后,将这些文本表示输入到分类头中,以获取情感强度。
因此,CE模块通过将非语言增强嵌入集成到预训练语言模型中,有助于生成更富有情感感知的语言表示。这种方法能够在文本表示中有效地整合视觉和听觉信息,从而提升情感分析等任务的性能。
数据集介绍
1. CMU-MOSI: 它是一个多模态数据集,包括文本、视觉和声学模态。它来自Youtube上的93个电影评论视频。这些视频被剪辑成2199个片段。每个片段都标注了[-3,3]范围内的情感强度。该数据集分为三个部分,训练集(1,284段)、验证集(229段)和测试集(686段)。
2. CMU-MOSEI: 它类似于CMU-MOSI,但规模更大。它包含了来自在线视频网站的23,453个注释视频片段,涵盖了250个不同的主题和1000个不同的演讲者。CMU-MOSEI中的样本被标记为[-3,3]范围内的情感强度和6种基本情绪。因此,CMU-MOSEI可用于情感分析和情感识别任务。
性能对比
有下图可以观察到,该论文提出的CENet与其他SOTA模型对比性能有明显提升:

复现过程(重要)
1. 数据集准备
下载MOSI和MOSEI数据集已提取好的特征文件(.pkl)。把它放在"./dataset”目录。2. 下载预训练语言模型
下载SentiLARE语言模型文件,然后将它们放入"/pretrained-model / sentilare_model”目录。3. 下载需要的包
pip install -r requirements.txt4. 搭建CENet模块
利用pytorch框架对CENet模块进行搭建:class CE(nn.Module):def __init__(self, beta_shift_a=0.5, beta_shift_v=0.5, dropout_prob=0.2):super(CE, self).__init__()self.visual_embedding = nn.Embedding(label_size + 1, TEXT_DIM, padding_idx=label_size)self.acoustic_embedding = nn.Embedding(label_size + 1, TEXT_DIM, padding_idx=label_size)self.hv = SelfAttention(TEXT_DIM)self.ha = SelfAttention(TEXT_DIM)self.cat_connect = nn.Linear(2 * TEXT_DIM, TEXT_DIM)def forward(self, text_embedding, visual=None, acoustic=None, visual_ids=None, acoustic_ids=None):visual_ = self.visual_embedding(visual_ids)acoustic_ = self.acoustic_embedding(acoustic_ids)visual_ = self.hv(text_embedding, visual_)acoustic_ = self.ha(text_embedding, acoustic_) visual_acoustic = torch.cat((visual_, acoustic_), dim=-1)shift = self.cat_connect(visual_acoustic)embedding_shift = shift + text_embeddingreturn embedding_shift5. 将CE模块与预训练语言模型融合
class BertEncoder(nn.Module):def __init__(self, config):super(BertEncoder, self).__init__()self.output_attentions = config.output_attentionsself.output_hidden_states = config.output_hidden_statesself.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])self.CE = CE()def forward(self, hidden_states, visual=None, acoustic=None, visual_ids=None, acoustic_ids=None, attention_mask=None, head_mask=None):all_hidden_states = ()all_attentions = ()for i, layer_module in enumerate(self.layer):if self.output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)if i == ROBERTA_INJECTION_INDEX:hidden_states = self.CE(hidden_states, visual=visual, acoustic=acoustic, visual_ids=visual_ids, acoustic_ids=acoustic_ids)6. 训练代码编写
定义一个整体的训练过程 train()函数,它负责训练模型多个 epoch,并在每个 epoch 结束后评估模型在验证集和测试集上的性能,并记录相关的指标和损失;并在训练最后一轮输出所有测试集id,true label 和 predicted label。
def train(args,model,train_dataloader,validation_dataloader,test_data_loader,optimizer,scheduler, ):valid_losses = []test_accuracies = []for epoch_i in range(int(args.n_epochs)):train_loss, train_pre, train_label = train_epoch(args, model, train_dataloader, optimizer, scheduler)valid_loss, valid_pre, valid_label = evaluate_epoch(args, model, validation_dataloader)test_loss, test_pre, test_label = evaluate_epoch(args, model, test_data_loader)train_acc, train_mae, train_corr, train_f_score = score_model(train_pre, train_label)test_acc, test_mae, test_corr, test_f_score = score_model(test_pre, test_label)non0_test_acc, _, _, non0_test_f_score = score_model(test_pre, test_label, use_zero=True)valid_acc, valid_mae, valid_corr, valid_f_score = score_model(valid_pre, valid_label)print("epoch:{}, train_loss:{}, train_acc:{}, valid_loss:{}, valid_acc:{}, test_loss:{}, test_acc:{}".format(epoch_i, train_loss, train_acc, valid_loss, valid_acc, test_loss, test_acc))valid_losses.append(valid_loss)test_accuracies.append(test_acc)wandb.log(({"train_loss": train_loss,"valid_loss": valid_loss,"train_acc": train_acc,"train_corr": train_corr,"valid_acc": valid_acc,"valid_corr": valid_corr,"test_loss": test_loss,"test_acc": test_acc,"test_mae": test_mae,"test_corr": test_corr,"test_f_score": test_f_score,"non0_test_acc": non0_test_acc,"non0_test_f_score": non0_test_f_score,"best_valid_loss": min(valid_losses),"best_test_acc": max(test_accuracies),}))# 输出测试集的 id、真实标签和预测标签with torch.no_grad():for step, batch in enumerate(test_data_loader):batch = tuple(t.to(DEVICE) for t in batch)input_ids, visual_ids, acoustic_ids, pos_ids, senti_ids, polarity_ids, visual, acoustic, input_mask, segment_ids, label_ids = batchvisual = torch.squeeze(visual, 1)outputs = model(input_ids,visual,acoustic,visual_ids,acoustic_ids,pos_ids, senti_ids, polarity_ids,token_type_ids=segment_ids,attention_mask=input_mask,labels=None,)logits = outputs[0]logits = logits.detach().cpu().numpy()label_ids = label_ids.detach().cpu().numpy()logits = np.squeeze(logits).tolist()label_ids = np.squeeze(label_ids).tolist()# 假设您从 label_ids 中获取 idsids = [f"sample_{idx}" for idx in range(len(label_ids))] # 这里是示例,您可以根据实际情况生成合适的 ids# 输出所有测试样本的 id、真实标签和预测标签值for i in range(len(ids)):print(f"id: {ids[i]}, true label: {label_ids[i]}, predicted label: {logits[i]}")6. 开始训练+测试
python train.py7. 输出结果
此外,为了方便直观地查看模型性能,我在最后一层训练结束后将所有测试集视频的clip id、真实标签和预测标签依次进行输出;并且结合wandb库自动保存结果可视化;结果在后续章节展示。
演示结果
训练过程

模型性能结果

接下来是我们自己补充的每个测试集的真实标签和预测标签

可视化
文章代码资源点击附件获取
相关文章:

CENet及多模态情感计算实战(论文复现)
CENet及多模态情感计算实战(论文复现) 本文所涉及所有资源均在传知代码平台可获取 文章目录 CENet及多模态情感计算实战(论文复现)概述研究背景主要贡献论文思路主要内容和网络架构数据集介绍性能对比复现过程(重要&am…...
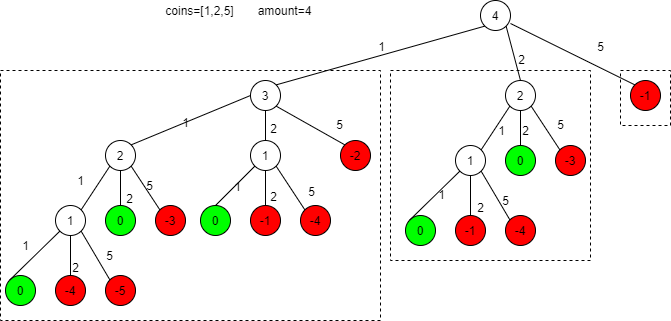
备战秋招60天算法挑战,Day34
题目链接: https://leetcode.cn/problems/coin-change/ 视频题解: https://www.bilibili.com/video/BV1qsvDeHEkg/ LeetCode 322.零钱兑换 题目描述 给你一个整数数组coins,表示不同面额的硬币;以及一个整数amount,表…...

vue实现评论滚动效果
vue插件实现滚动效果 一、安装组件 官网地址:https://chenxuan0000.github.io/vue-seamless-scroll/ 1、vue2安装 npm install vue-seamless-scroll --savevue3安装 npm install vue3-seamless-scroll --save二、组件引入 <template><div v-if"…...

iphone13 不升级IOS使用广电卡
iPhone13的信号📶,15系统刷高版本iPCC,本帖以后不再更新!!! 自从知道可以通过刷iPCC的方式改善信号(不更新iOS大版本的情况下),尝试了各种版本。 我自己用下来总结 - 移动联通48、49、50 &…...
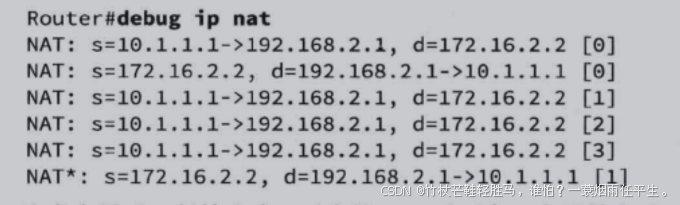
网络地址转换
文章目录 1. NAT使用环境2. NAT的优缺点3. NAT的三种类型4. NAT工作原理5. 配置示例6. 常用排错命令 1. NAT使用环境 需要连接到互联网,但主机没有全局唯一的IP地址;更换的ISP的要求对网络进行重新编址;需要合并两个使用相同编址方案的内联网…...

【python】 @property属性详解 and mysql的sqlalchemy的原生sql
【python】 property属性详解 一文搞懂python中常用的装饰器(classmethod、property、staticmethod、abstractmethod…) sqlalchemy的原生sql from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker# 数据库连接字符串 DATAB…...

西门子WinCC开发笔记(一):winCC西门子组态软件介绍、安装
文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/142060535 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、Op…...

如何在5个步骤中编写更好的ChatGPT提示
ChatGPT是一个风靡全球的生成式人工智能 (AI) 工具。虽然它有可能编造一些东西,但是通过精心设计提示,可以确保获得最佳结果。在这篇文章中,我们将探讨如何做到这一点。 在本文中,我将向你展示如何编写提示,激励驱动C…...

最小堆最大堆
文章目录 最小堆、最大堆最小堆(Min-Heap)最大堆(Max-Heap)堆的主要操作及时间复杂度堆的常见应用堆的数组表示大根堆--堆排序 最小堆、最大堆 最小堆(Min-Heap)和最大堆(Max-Heap)…...

华为 HCIP-Datacom H12-821 题库 (10)
有需要题库的可以看主页置顶 V群进行学习交流 1.缺省情况下,BGP 对等体邻接关系的保持时间是多少秒? A、120 秒 B、60 秒 C、10 秒 D、180 秒 答案:D 解析: BGP 存活消息每隔 60 秒发一次,保持时间“180 秒” 2.缺省…...

如何利用命令模式实现一个手游后端架构?
命令模式的原理解读 命令模式的英文翻译是 Command Design Pattern。在 GoF 的《设计模式》一书中,它是这么定义的: The command pattern encapsulates a request as an object, thereby letting us parameterize other objects with different reques…...

ThreadLocal 释放的方式有哪些
ThreadLocal基础概念:IT-BLOG-CN ThreadLocal是Java中用于在同一个线程中存储和隔离变量的一种机制。通常情况下,我们使用ThreadLocal来存储线程独有的变量,并在任务完成后通过remove方法清理这些变量,以防止内存泄漏。然而&…...

监控-zabbix
1运维监控 是指对计算机系统、网络、服务器等关键IT基础设施进行实时监控,以确保系统的稳定运行和及时发现潜在问题 2老监控框架(不会用但需要知道) Cacti: Cacti是一款基于PHP、MySQL开发的网络流量监测图形分析工具。主要监…...

设计模式 解释器模式(Interpreter Pattern)
文章目录 解释器模式简绍解释器模式的结构优缺点UML图具体代码实现Context 数据实体类,可以包含一些方法Abstract Expression 创建接口方法Terminal Expression 对数据简单处理Non-Terminal Expression 同样实现抽象接口方法Client(客户端) 调…...

Linux echo命令讲解及与重定向符搭配使用方法,tail命令及日志监听方式详解
echo echo具有回声,回响的意思,在linux系统中echo一般可以输出指定字符或用于命令执行 echo命令的用法为 echo 输出字符串 或 echo 命令 若参数为字符串则进行字符串输出,注意若字符串中含空格最好将其用引号括起,防止echo命…...

Linux网络:总结协议拓展
1. TCP/IP四层模型总结 2. 网络协议拓展 DNS协议(地址解析协议) TCP/IP使用IP地址和端口号来确定网络中一台主机的一个程序。 但是这样标定不方便记忆,于是开始引出主机名(字符串),使用hosts文件来描述…...

去除恢复出厂设置中UI文字显示
文章目录 需求场景 一、代码跟踪与分析在线文字搜索RK平台本地源码搜索实际测试验证代码推理 二、实现方案三、延伸知识四、知识总结 需求 需求:去除恢复出厂设置中UI文字显示 场景 Android 相关产品各种方向旋转、强制横竖屏等需求,导致在恢复出厂设…...

《高校教育管理》
《高校教育管理》为中文社会科学引文索引(CSSCI)来源期刊、北大中文核心期刊、RCCSE中国核心学术期刊、人大“复印报刊资料”重要转载来源期刊,是江苏大学主办,中国高等教育管理研究会协办的全国性高等教育管理专业期刊。 ISSN 1…...

全国计算机二级考试C语言篇4——选择题
运算符与表达式 1.赋值的正确写法 赋值操作是一个很常见的操作,但是赋值操作也有一些需要注意的地方。赋值操作是将一个表达式的值赋给一个变量的过程。在C语言中,赋值操作符是""。结合性从右到左,不控制求值顺序。 下面是几种C语言…...

数据结构————哈希表
哈希表(Hash table),也被称为散列表,是一种根据关键值(Key value)而直接进行访问的数据结构。它通过把关键值映射到表中的一个位置来访问记录,从而加快查找的速度。这个映射函数被称为散列函数或…...

混合基FFT,matlab实现
参考数字信号处理教程第四版(程佩青著)第四章FFT这里直接给出matlab函数,性能不保证最优注意,此函数只能处理混合基fft,即输入信号x的长度不能是素数,不能是2次幂整数function X mixedRadixFFT(x)% multiB…...

抖音无水印下载终极解决方案:免费高效获取高清视频的实战秘籍
抖音无水印下载终极解决方案:免费高效获取高清视频的实战秘籍 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

JMeter接口测试实战:从鉴权验证到故障注入的工程化落地
1. 为什么接口测试不能只靠“点点点”——JMeter不是高级版Postman,而是工程化验证的起点很多人第一次接触JMeter,是在开发甩来一个接口文档后,下意识打开Postman填URL、选Method、点Send,看到返回200就松一口气:“通了…...

APT32F110开发板串口printf重定向与动态文本显示实战
1. 项目概述:从“Hello World”到“花式表白”的嵌入式浪漫作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我调试过的开发板、写过的“Hello World”程序,估计能绕办公室好几圈。大多数时候,我们的工作就是和数据手册、寄存器、…...

深入理解Android网络开发:以OkHttp为核心的全面指南
引言 在移动应用开发中,网络通信是核心功能之一。Android平台提供了丰富的网络库和工具,但开发者常面临挑战,如性能优化、安全配置和弱网环境处理。OkHttp作为Android生态中最流行的HTTP客户端库,由Square公司开发,以其高效、灵活和易扩展的特性成为行业标准。它支持同步…...

量子计算入门:从量子比特到量子退火的核心原理与实践
1. 项目概述:推开量子世界的大门最近几年,量子计算这个词的热度是越来越高,从科技新闻到投资风口,似乎无处不在。但说实话,很多朋友一听到“量子叠加”、“量子纠缠”这些词,第一反应可能就是“不明觉厉”&…...

HarmonyOS ArkUI实战:从零构建购物社交应用UI界面
1. 项目概述与核心价值如果你正在学习HarmonyOS应用开发,或者已经从其他移动端框架(如Android、Flutter)转过来,那么构建一个美观、交互流畅的UI界面,往往是上手实践的第一步,也是最直观检验学习成果的一步…...

AI时代管理者必备的10项核心能力地图
1. 项目概述:这不是一份“领导力清单”,而是一张AI时代管理者的生存地图“10 Essential Skills for AI Leaders”——看到这个标题,很多人第一反应是点开、收藏、转发到“管理者必读”群,然后继续用Excel做季度复盘、用PPT讲战略愿…...

大数据搬运工 · Sqoop
🚛 在「关系型数据库」与「Hadoop 大仓库」之间 | 批量、高效、并行运输数据💡 生活比喻: 想象你的学校图书馆(关系型数据库)有一大堆超重的图书,而学校新建的“超级储藏大楼”(Hado…...

代码优化的10个技巧:让你的代码既高效又优雅
对于软件测试从业者而言,编写高质量的测试代码是保障测试效率、提升测试可靠性的核心基础。无论是自动化测试脚本、测试工具开发还是测试框架搭建,臃肿、低效、可读性差的代码不仅会拖慢测试执行速度,还会增加缺陷排查的难度,提升…...