第 6 章图像聚类
本章将介绍几种聚类方法,并展示如何利用它们对图像进行聚类,从而寻找相似的图像组。聚类可以用于识别、划分图像数据集,组织与导航。此外,我们还会对聚类后的图像进行相似性可视化。
6.1 K-means聚类
K-means 是一种将输入数据划分成 k 个簇的简单的聚类算法。K-means 反复提炼初
始评估的类中心,步骤如下:
(1) 以随机或猜测的方式初始化类中心 ui ,i=1…k;
(2) 将每个数据点归并到离它距离最近的类中心所属的类 ci ;
(3) 对所有属于该类的数据点求平均,将平均值作为新的类中心;
(4) 重复步骤(2)和步骤(3)直到收敛。

K-means 算法最大的缺陷是必须预先设定聚类数 k,如果选择不恰当则会导致聚类出来的结果很差。其优点是容易实现,可以并行计算,并且对于很多别的问题不需要任何调整就能够直接使用。
6.1.1 SciPy聚类包
尽管 K-means 算法很容易实现,但我们没有必要自己实现它。SciPy 矢量量化包scipy.cluster.vq 中有 K-means 的实现,下面是使用方法。为便于说明,我们先生成简单的二维数据:
from scipy.cluster.vq import *
class1 = 1.5 * randn(100,2)
class2 = randn(100,2) + array([5,5])
features = vstack((class1,class2))
上面的代码生成两类二维正态分布数据。用 k=2 对这些数据进行聚类:
centroids,variance = kmeans(features,2)
由于 SciPy 中实现的 K-means 会计算若干次(默认为 20 次),并为我们选择方差最小的结果,所以这里返回的方差并不是我们真正需要的。现在,你可以用 SciPy 包中的矢量量化函数对每个数据点进行归类:
code,distance = vq(features,centroids)
通过上面得到的 code,我们可以检查是否有归类错误。为了将其可视化,我们可以画出这些数据点及最终的聚类中心:
figure()
ndx = where(code==0)[0]
plot(features[ndx,0],features[ndx,1],'*')
ndx = where(code==1)[0]
plot(features[ndx,0],features[ndx,1],'r.')
plot(centroids[:,0],centroids[:,1],'go')
axis('off')
show()
函数 where() 给出每个类的索引,绘制出的结果如图 6-1 所示。
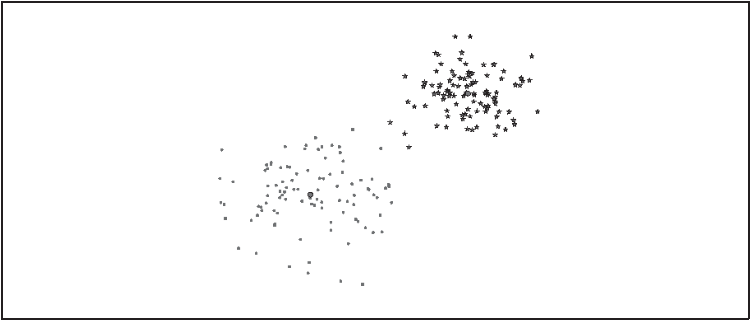
6-1:一个对二维数据用 K-means 进行聚类的示例。类中心标记为绿色大圆环,预测出的类分别标记为蓝色星号和红色点。
6.1.2 图像聚类
让我们在 1.3.6 节的字体图像上,我们用 K-means 对这些字体图像进行聚类。文件selectedfontimages.zip 包含 66 幅来自该字体数据集 fontinages 的图像(为了便于说明这些聚类簇,我们选择这些图像做简单概述)。我们利用之前计算过的前 40 个主成分进行投影,用投影系数作为每幅图像的向量描述符。用 pickle 模块载入模型文件,在主成分上对图像进行投影,然后用下面的方法聚类:
import imtools
import pickle
from scipy.cluster.vq import *
# 获取 selected-fontimages 文件下图像文件名,并保存在列表中
imlist = imtools.get_imlist('selected_fontimages/')
imnbr = len(imlist)
# 载入模型文件
with open('a_pca_modes.pkl','rb') as f:
immean = pickle.load(f)
V = pickle.load(f)
# 创建矩阵,存储所有拉成一组形式后的图像
immatrix = array([array(Image.open(im)).flatten()
for im in imlist],'f')
# 投影到前 40 个主成分上
immean = immean.flatten()
projected = array([dot(V[:40],immatrix[i]-immean) for i in range(imnbr)])
# 进行 k-means 聚类
projected = whiten(projected)
centroids,distortion = kmeans(projected,4)
code,distance = vq(projected,centroids)
与之前一样,上述代码 code 变量中包含的是每幅图像属于哪个簇。这里,我们设定聚类数 k=4,同时用 SciPy 的 whiten() 函数对数据“白化”处理,并进行归一化,使每个特征具有单位方差。你可以试着改变其中的参数,比如主成分数目和 k,观察聚类结果有何改变。利用下面的代码可以可视化聚类后的结果:
# 绘制聚类簇
for k in range(4):
ind = where(code==k)[0]
figure()
gray()
for i in range(minimum(len(ind),40)):
subplot(4,10,i+1)
imshow(immatrix[ind[i]].reshape((25,25)))
axis('off')
show()
这里我们将每个簇显示在一个独立图形窗口中,且在该图形窗口中最多可以显示 40幅图像。我们用 PyLab 的 subplot() 函数来设定网格数,图 6-2 是上面对字体图像聚成 4 类后的可视化结果。关于 SciPy 中 K-means 实现方法以及 scipy.cluster.vq 模块,详见参考指南:http://docs.scipy.org/doc/scipy/reference/cluster.vq.html.
6.1.3 在主成分上可视化图像
为了便于观察上面是如何利用主成分进行聚类的,我们可以在一对主成分方向的坐标上可视化这些图像。一种方法是将图像投影到两个主成分上,改变投影为:projected = array([dot(V[[0,2]],immatrix[i]-immean) for i in range(imnbr)])以得到相应的坐标(在这里 V[[0,2]] 分别是第一个和第三个主成分)。当然,你也可以将其投影到所有成分上,之后挑选出你需要的列。

图 6-2:用 40 个主成分数对字体图像进行 K-means 聚类(k=4)
我们用 PIL 中的 ImageDraw 模块进行可视化。假设你有如上所示投影后的图像,及保存有图像文件名的列表,利用下面简短的脚本可以生成如图 6-3 所示的结果:
from PIL import Image, ImageDraw
# 高和宽
h,w = 1200,1200
# 创建一幅白色背景图
img = Image.new('RGB',(w,h),(255,255,255))
draw = ImageDraw.Draw(img)
# 绘制坐标轴
draw.line((0,h/2,w,h/2),fill=(255,0,0))
draw.line((w/2,0,w/2,h),fill=(255,0,0))
# 缩放以适应坐标系
scale = abs(projected).max(0)
scaled = floor(array([ (p / scale) * (w/2-20,h/2-20) + (w/2,h/2) for p in projected]))
# 粘贴每幅图像的缩略图到白色背景图片
for i in range(imnbr):
nodeim = Image.open(imlist[i])
nodeim.thumbnail((25,25))
ns = nodeim.size
img.paste(nodeim,(scaled[i][0]-ns[0]//2,scaled[i][1]-
ns[1]//2,scaled[i][0]+ns[0]//2+1,scaled[i][1]+ns[1]//2+1))
img.save('pca_font.jpg')
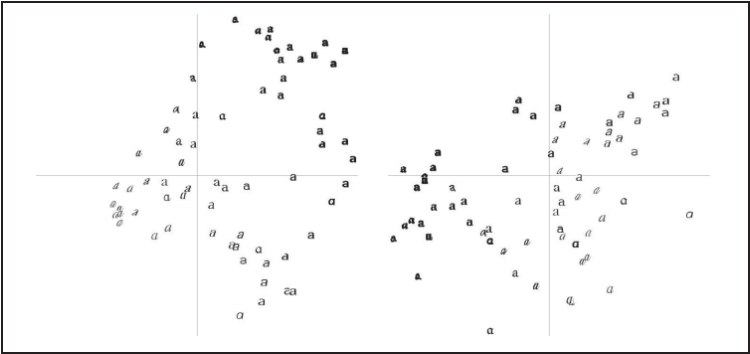
图 6-3:在成对主成分上投影的字体图像。左图用的是第一个和第二个主成分,右图用的是第二个和第三个主成分
这里,我们用到了整数或 floor 向下取整除法运算符 //,通过移去小数点后面的部分,可以返回各个缩略图在白色背景中对应的整数坐标位置。
这类图像说明这些字体图像在 40 维里的分布情况,对于选择一个好的描述子很有帮助。可以很清楚地看到,二维投影后相似的字体图像距离较近。
6.1.4 像素聚类
在结束本节之前,我们来看一个对单幅图像中的像素而非全部图像进行聚类的例子。将图像区域或像素合并成有意义的部分称为图像分割,它是第 9 章的主题。除了在一些简单的图像上,单纯在像素水平上应用 K-means 得出的结果往往是毫无意义的。要产生有意义的结果,往往需要更复杂的类模型而非平均像素色彩或空间一致性。现在,我们仅会在 RGB 三通道的像素值上运用 K-means 进行聚类,分割问题的处理方法会在之后谈到(9.2 节)给予关注及给出细节部分。下面的代码示例载入一幅图像,用一个步长为 steps 的方形网格在图像中滑动,每滑一次对网格中图像区域像素求平均值,将其作为新生成的低分辨率图像对应位置处的像素值,并用 K-means 进行聚类:
from scipy.cluster.vq import *
from scipy.misc import imresize
steps = 50 # 图像被划分成 steps×steps 的区域
im = array(Image.open('empire.jpg'))
dx = im.shape[0] / steps
dy = im.shape[1] / steps
# 计算每个区域的颜色特征
features = []
for x in range(steps):
for y in range(steps):
R = mean(im[x*dx:(x+1)*dx,y*dy:(y+1)*dy,0])
G = mean(im[x*dx:(x+1)*dx,y*dy:(y+1)*dy,1])
B = mean(im[x*dx:(x+1)*dx,y*dy:(y+1)*dy,2])
features.append([R,G,B])
features = array(features,'f') # 变为数组
# 聚类
centroids,variance = kmeans(features,3)
code,distance = vq(features,centroids)
# 用聚类标记创建图像
codeim = code.reshape(steps,steps)
codeim = imresize(codeim,im.shape[:2],interp='nearest')
figure()
imshow(codeim)
show()
K-means 的输入是一个有 steps×steps 行的数组,数组的每一行有 3 列,各列分别为区域块 R、G、B 三个通道的像素平均值。为可视化最后的结果 , 我们用 SciPy 的imresize() 函数在原图像坐标中显示这幅 steps×steps 的图像。参数 interp 指定插值方法;我们在这里采用最近邻插值法,以便在类间进行变换时不需要引入新的像素值。图 6-4 显示了用 50×50 和 100×100 窗口对两幅相对比较简单的示例图像进行像素聚类后的结果。注意,K-means 标签的次序是任意的(在这里的标签指最终结果中图像的颜色)。正如你所看到的,尽管利用窗口对它进行了下采样,但结果仍然是有噪声的。如果图像某些区域没有空间一致性,则很难将它们分开,如下方图中小男孩和草坪的图。空间一致性和更好的分割方法以及其他的图像分割算法会在后面讨论。现在,让我们继续来看下一个基本的聚类算法。

图 6-4:基于颜色像素值用 K-means 对像素进行聚类的结果。左边是原始图像;中间是用 k=3和 50×50 大小的窗口进行聚类的结果;右边是用 k=3 和 100×100 大小的窗口进行聚类的结果
6.2 层次聚类
层次聚类(或凝聚式聚类)是另一种简单但有效的聚类算法,其思想是基于样本间成对距离建立一个简相似性树。该算法首先将特征向量距离最近的两个样本归并为一组,并在树中创建一个“平均”节点,将这两个距离最近的样本作为该“平均”节点下的子节点;然后在剩下的包含任意平均节点的样本中寻找下一个最近的对,重复进行前面的操作。在每一个节点处保存了两个子节点之间的距离。遍历整个树,通过设定的阈值,遍历过程可以在比阈值大的节点位置终止,从而提取出聚类簇。层次聚类有若干优点。例如,利用树结构可以可视化数据间的关系,并显示这些簇是如何关联的。在树中,一个好的特征向量可以给出一个很好的分离结果。另外一个优点是,对于给定的不同的阈值,可以直接利用原来的树,而不需要重新计算。不足之处是,对于实际需要的聚类簇,我们需要选择一个合适的阈值。让我们看看层次聚类算法怎样在代码中体现 1 。创建文件 hcluster.py,将下面代码添加进去:
from itertools import combinations
class ClusterNode(object):
def __init__(self,vec,left,right,distance=0.0,count=1):
self.left = left
self.right = right
self.vec = vec
self.distance = distance
self.count = count # 只用于加权平均
def extract_clusters(self,dist):
""" 从层次聚类树中提取距离小于 dist 的子树簇群列表 """
if self.distance < dist:
return [self]
return self.left.extract_clusters(dist) + self.right.extract_clusters(dist)
def get_cluster_elements(self):
""" 在聚类子树中返回元素的 id """
return self.left.get_cluster_elements() + self.right.get_cluster_elements()
def get_height(self):
""" 返回节点的高度,高度是各分支的和 """
return self.left.get_height() + self.right.get_height()
def get_depth(self):
""" 返回节点的深度,深度是每个子节点取最大再加上它的自身距离 """
return max(self.left.get_depth(), self.right.get_depth()) + self.distance
class ClusterLeafNode(object):
def __init__(self,vec,id):
self.vec = vec
self.id = id
def extract_clusters(self,dist):
return [self]
def get_cluster_elements(self):
return [self.id]
def get_height(self):
return 1
def get_depth(self):
return 0
def L2dist(v1,v2):
return sqrt(sum((v1-v2)**2))
def L1dist(v1,v2):
return sum(abs(v1-v2))
def hcluster(features,distfcn=L2dist):
""" 用层次聚类对行特征进行聚类 """
# 用于保存计算出的距离
distances = {}
# 每行初始化为一个簇
node = [ClusterLeafNode(array(f),id=i) for i,f in enumerate(features)]
while len(node)>1:
closest = float('Inf')
# 遍历每对,寻找最小距离
for ni,nj in combinations(node,2):
if (ni,nj) not in distances:
distances[ni,nj] = distfcn(ni.vec,nj.vec)
d = distances[ni,nj]
if d<closest:
closest = d
lowestpair = (ni,nj)
ni,nj = lowestpair
# 对两个簇求平均
new_vec = (ni.vec + nj.vec) / 2.0
# 创建新的节点
new_node = ClusterNode(new_vec,left=ni,right=nj,distance=closest)
node.remove(ni)
node.remove(nj)
node.append(new_node)
return node[0]
我们为树节点创建了两个类,即 ClusterNode 和 ClusterLeafNode,这两个类将用于创建聚类树,其中函数 hcluster() 用于创建树。首先创建一个包含叶节点的列表,然后根据选择的距离度量方式将距离最近的对归并到一起,返回的终节点即为树的根。对于一个行为特征向量的矩阵,运行 hcluster() 会创建和返回聚类树。距离度量的选择依赖于实际的特征向量,这里我们利用欧式距离 L2(同时提供了L1 距离度量函数),不过你可以创建任意距离度量函数,并将它作为参数传递给hcluster()。对于每个子树,计算其所有节点特征向量的平均值,作为新的特征向量来表示该子树,并将每个子树视为一个对象。当然,还有其他将哪两个节点合并在一起的方案,比如在两个子树中使用对象间距离最小的单向锁,及在两个子树中用对象间距离最大的完全锁。选择不同的锁会生成不同类型的聚类树。为了从树中提取聚类簇,需要从顶部遍历树直至一个距离小于设定阈值的节点终止,这通过递归很容易做到。ClusterNode 的 extract_clusters() 方法用于处理该过程,如果节点间距离小于阈值,则用一个列表返回节点,否则调用子节点(叶节点通常返回它们自身)。调用该函数会返回一个包含聚类簇的子树列表。对于每一个子聚类簇,为了得到包含对象 id 的叶节点,需要遍历每个子树,并用方法 get_cluster_elements() 返回一个包含叶节点的列表。下面,我们在一个简单的例子中观察该聚类过程。首先创建一些二维数据点(和之前 K-means 一样):
class1 = 1.5 * randn(100,2)
class2 = randn(100,2) + array([5,5])
features = vstack((class1,class2))
对这些数据点进行聚类,设定阈值(这里的阈值设定为 5),从列表中提取这些聚类簇,并在控制台打印出来:
import hcluster
tree = hcluster.hcluster(features)
clusters = tree.extract_clusters(5)
print 'number of clusters', len(clusters)
for c in clusters:
print c.get_cluster_elements()
打印结果应该与下面类似:
number of clusters 2
[184, 187, 196, 137, 174, 102, 147, 145, 185, 109, 166, 152, 173, 180, 128, 163, 141,
178, 151, 158, 108,182, 112, 199, 100, 119, 132, 195, 105, 159, 140, 171, 191, 164, 130,
149, 150, 157, 176, 135, 123, 131,118, 170, 143, 125, 127, 139, 179, 126, 160, 162, 114,
122, 103, 146, 115, 120, 142, 111, 154, 116, 129,136, 144, 167, 106, 107, 198, 186, 153,
156, 134, 101, 110, 133, 189, 168, 183, 148, 165, 172, 188, 138,192, 104, 124, 113, 194,
190, 161, 175, 121, 197, 177, 193, 169, 117, 155]
[56, 4, 47, 18, 51, 95, 29, 91, 23, 80, 83, 3, 54, 68, 69, 5, 21, 1, 44, 57, 17, 90, 30,
22, 63, 41, 7, 14, 59, 96, 20, 26, 71, 88, 86, 40, 27, 38, 50, 55, 67, 8, 28, 79, 64,
66, 94, 33, 53, 70, 31, 81, 9, 75, 15, 32, 89, 6, 11, 48, 58, 2, 39, 61, 45, 65, 82, 93,
97, 52, 62, 16, 43, 84, 24, 19, 74, 36, 37, 60, 87, 92, 181, 99, 10, 49, 12, 76, 98, 46,
72, 34, 35, 13, 73, 78, 25, 42, 77, 85]
理想情况下,你应该得到两一个聚类簇,但是在实际数据中,你可能会得到三类或更多这主要依赖于实际生成的二维数据。在这个对二维数据聚类的简单例子中,一个类中的值应该小于 100,另外一个应该大于等于 100。
图像聚类
我们来看一个基于图像颜色信息对图像进行聚类的例子。文件 sunsets.zip 中包含 100 张图像,这些图像是用“sunset”和“sunsets”关键字在 Flickr 下载下来的。在这个例子中,我们用颜色直方图作为每幅图像的特征向量。虽然这样处理有些简单粗糙,但仍然能够很好地说明分层聚类的过程。在包含这些日落图像的文件夹中运行下面的代码:
import os
import hcluster
# 创建图像列表
path = 'flickr-sunsets/'
imlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
# 提取特征向量,每个颜色通道量化成 8 个小区间
features = zeros([len(imlist), 512])
for i,f in enumerate(imlist):
im = array(Image.open(f))
# 多维直方图
h,edges = histogramdd(im.reshape(-1,3),8,normed=True,
range=[(0,255),(0,255),(0,255)])
features[i] = h.flatten()
tree = hcluster.hcluster(features)
我们将 R、G、B 三个颜色通道作为特征向量,将其传递到 NumPy 的 histogramdd()中,该函数能够计算多维直方图(本例中是三维)。我们在每个颜色通道中使用 8 个小区间进行量化,将三个通道量化后的小区间拉成一行后便可用 512(8×8×8)维的特征向量描述每幅图像。为避免图像尺寸不一致,我们用“normed=True”归一化直方图,并将每个颜色通道范围设置为 0...255。将 reshape() 第一个参数设置为 -1会自动确定正确的尺寸,故可以创建一个输入数组来计算以 RGB 颜色值为行向量的直方图。为了可视化聚类树,我们可以画出树状图。树状图是一种显示树布局的图表。在判定给出的描述子向量好坏,以及在特征场合考虑什么是相似的时候,树状图可以提供有用的信息。将下面的代码添加到 hcluster.py 中:
from PIL import Image,ImageDraw
def draw_dendrogram(node,imlist,filename='clusters.jpg'):
""" 绘制聚类树状图,并保存到文件中 """
# 高和宽
rows = node.get_height()*20
cols = 1200
# 距离缩放因子,以便适应图像宽度
s = float(cols-150)/node.get_depth()
# 创建图像,并绘制对象
im = Image.new('RGB',(cols,rows),(255,255,255))
draw = ImageDraw.Draw(im)
# 初始化树开始的线条
draw.line((0,rows/2,20,rows/2),fill=(0,0,0))
# 递归地画出节点
node.draw(draw,20,(rows/2),s,imlist,im)
im.save(filename)
im.show()
这里,画树状图时对于每个节点用了 draw() 方法,将该方法添加到 ClusterNode 类中:
def draw(self,draw,x,y,s,imlist,im):
""" 用图像缩略图递归地画出叶节点 """
h1 = int(self.left.get_height()*20 / 2)
h2 = int(self.right.get_height()*20 /2)
top = y-(h1+h2)
bottom = y+(h1+h2)
# 子节点垂直线
draw.line((x,top+h1,x,bottom-h2),fill=(0,0,0))
# 水平线
ll = self.distance*s
draw.line((x,top+h1,x+ll,top+h1),fill=(0,0,0))
draw.line((x,bottom-h2,x+ll,bottom-h2),fill=(0,0,0))
# 递归地画左边和右边的子节点
self.left.draw(draw,x+ll,top+h1,s,imlist,im)
self.right.draw(draw,x+ll,bottom-h2,s,imlist,im)
在画实际图像缩略图时,叶节点有自己的方法,将该方法添加到 ClusterLeafNode类中:
def draw(self,draw,x,y,s,imlist,im):
nodeim = Image.open(imlist[self.id])
nodeim.thumbnail([20,20])
ns = nodeim.size
im.paste(nodeim,[int(x),int(y-ns[1]//2),int(x+ns[0]),int(y+ns[1]-ns[1]//2)])
树状图的高和子部分由距离决定,这些都需要调整,以适应所选择的图像分辨率。随着坐标向下传递到下一级,会递归绘制出这些节点,上述代码用 20×20 像素绘制叶节点的缩略图,使用 get_height() 和 get_depth() 这两个辅助函数可以获得树的高和宽。
树状图可以通过下面的代码绘制,并保存在 sunset.pdf 中:
hcluster.draw_dendrogram(tree,imlist,filename='sunset.pdf')
图 6-5 展示了日落图像聚类后的树状图。可以看到,树中颜色相似的图像距离较近。
图 6-6 中为三个示例簇。可以通过下面的代码提取该例子中的簇:
# 设置一些(任意的)阈值以可视化聚类簇
clusters = tree.extract_clusters(0.23*tree.distance)
# 绘制聚类簇中元素超过 3 个的那些图像
for c in clusters:
elements = c.get_cluster_elements()
nbr_elements = len(elements)
if nbr_elements>3:
figure()
for p in range(minimum(nbr_elements,20)):
subplot(4,5,p+1)
im = array(Image.open(imlist[elements[p]]))
imshow(im)
axis('off')
show()

图 6-5:用 100 幅日落图像进行层次聚类,将 RGB 空间的 512 个小区间直方图作为每幅图像的特征向量。树中挨的相近的图像具有相似的颜色分布

图 6-6:用 100 幅日落图像进行层次聚类的示例聚类簇,阈值集合设定为树中最大节点距离的 23%
作为最后一个例子,我们对前面的字体图像创建一个树状图:
tree = hcluster.hcluster(projected)
hcluster.draw_dendrogram(tree,imlist,filename='fonts.jpg')
其中,projected 和 imlist 是 6.1 节 K-means 例子中的变量。图 6-7 显示了对字体图像进行层次聚类后的树状图。
6.3 谱聚类
谱聚类方法是一种有趣的聚类算法,与前面 K-means 和层次聚类方法截然不同。对于 n 个元素(如 n 幅图像),相似矩阵(或亲和矩阵,有时也称距离矩阵)是一个n×n 的矩阵,矩阵每个元素表示两两之间的相似性分数。谱聚类是由相似性矩阵构建谱矩阵而得名的。对该谱矩阵进行特征分解得到的特征向量可以用于降维,然后聚类。
谱聚类的优点之一是仅需输入相似性矩阵,并且可以采用你所想到的任意度量方式构建该相似性矩阵。像 K-means 和层次聚类需要计算那些特征向量求平均;为了计算平均值,会将特征或描述子限制为向量。而对于谱方法,特征向量就没有类别限制,只要有一个“距离”或“相似性”的概念即可。
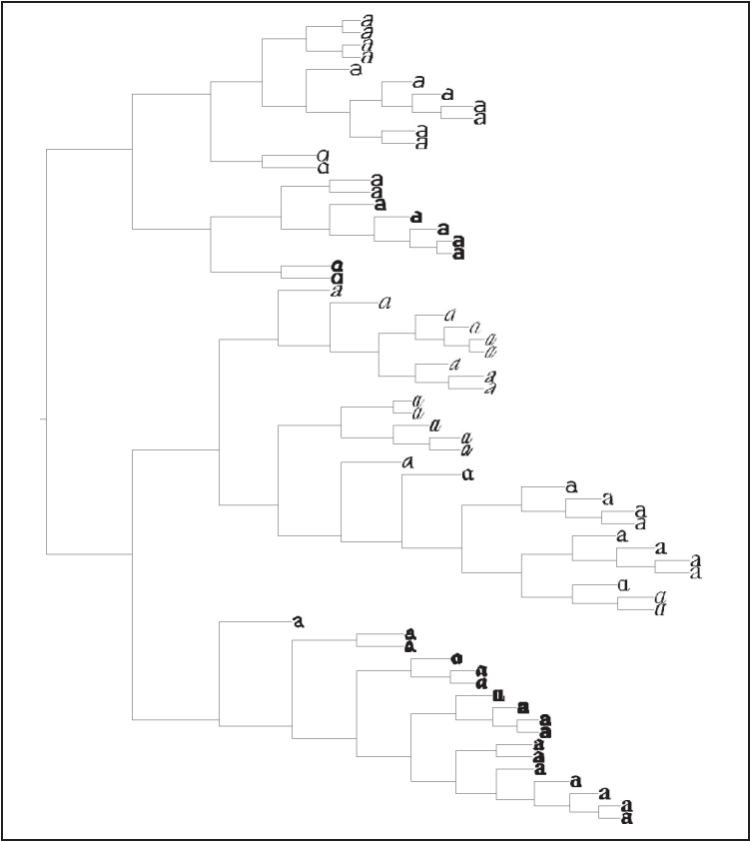
6-7:用 66 幅选定字体图像,使用 40 个主成分作为特征量,用层次聚类方法进行聚类


计算 L 的特征向量,并使用 k 个最大特征值对应的 k 个特征向量,构建出一个特征向量集(记住,我们可能并没有以任何东西来开始),从而可以找到聚类簇。创建一个矩阵,该矩阵的各列是由之前求出的 k 个特征向量构成,每一行可以看做一个新的特征向量,长度为 k。这些新的特征向量可以用诸如 K-means 方法进行聚类,生成最终的聚类簇。本质上,谱聚类算法是将原始空间中的数据转换成更容易聚类的新特征向量。在某些情况下,不会首先使用聚类算法。
讲解了足够的理论,我们来看看真实的例子中谱聚类算法的代码。我们再次使用1.3.6 节 K-means 例子中的字体图像。
from scipy.cluster.vq import *
n = len(projected)
# 计算距离矩阵
S = array([[ sqrt(sum((projected[i]-projected[j])**2))
for i in range(n) ] for j in range(n)], 'f')
# 创建拉普拉斯矩阵
rowsum = sum(S,axis=0)
D = diag(1 / sqrt(rowsum))
I = identity(n)
L = I - dot(D,dot(S,D))
# 计算矩阵 L 的特征向量
U,sigma,V = linalg.svd(L)
k = 5
# 从矩阵 L 的前k 个特征向量(eigenvector)中创建特征向量(feature vector)
# 叠加特征向量作为数组的列
features = array(V[:k]).T
# k-means 聚类
features = whiten(features)
centroids,distortion = kmeans(features,k)
code,distance = vq(features,centroids)
# 绘制聚类簇
for c in range(k):
ind = where(code==c)[0]
figure()
for i in range(minimum(len(ind),39)):
im = Image.open(path+imlist[ind[i]])
subplot(4,10,i+1)
imshow(array(im))
axis('equal')
axis('off')
show()
在本例中,我们用两两间的欧式距离创建矩阵 S,并对 k 个特征向量(eignvector)用常规的 K-means 进行聚类(在该例中,k=5)。注意,矩阵 V 包含的是对特征值进行排序后的特征向量。最后,绘制出这些聚类簇。图 6-8 显示了运行后的聚类簇;需要记住的是,在 K-means 阶段,每次运行的结果可能不同。

图 6-8:用拉普拉斯矩阵的特征向量对字体图像进行谱聚类
我们也可以在没有任何特征向量或没有严格定义相似性的例子中尝试该算法。2.3 节中带有地理标签的 Panoramio 图像是基于它们之间有多少匹配的局部描述符连接起来的。2.3.2 节的矩阵是一个用分数表示的相似性矩阵,其中分数等于匹配的特征数(没有归一化)。由于 imlist 列表包含了图像文件名,并已用 NumPy 的 savetxt() 将相似性矩阵保存到了文件中,所以我们只需修改上面代码的前面几行:
n = len(imlist)
# 载入相似矩阵并重新格式化
S = loadtxt('panoramio_matches.txt')
S = 1 / (S + 1e-6)
这里对分数进行转换,使得相似图像的分数值较小,这样我们就不需要修改上面的代码。我们添加了一个很小的数以防止与 0 相除,后面的代码不需要修改。在该例中选择 k 有些技巧。很多人会认为这里只有两类(即白宫的两侧),以及其他一些垃圾图像。用 k=2 可以得到类似图 6-9 的结果,其中一个聚类簇是包含很多白宫一侧的图像,另一个聚类簇是白宫另一侧的图像和其他所有垃圾图像。将 k 设定为一个较大的值,比如 k=10,则有些聚类簇可能只包含一幅图像(很可能是垃圾图像),另一些是真实的聚类簇。图 6-10 给出了上面示例代码运行的结果。在该例中,仅有两个真实的聚类簇,每个聚类簇包含白宫一个侧面的图像。

图 6-9:用 k=2、局部特征匹配数作为相似性分数对白宫地理图像进行谱聚类的结果
相关文章:
第 6 章图像聚类
本章将介绍几种聚类方法,并展示如何利用它们对图像进行聚类,从而寻找相似的图像组。聚类可以用于识别、划分图像数据集,组织与导航。此外,我们还会对聚类后的图像进行相似性可视化。 6.1 K-means聚类 K-means 是一种将输入数据划…...

HC-SR501人体红外传感器详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 3.工作原理介绍 三、程序设计 main.c文件 body_hw.h文件 body_hw.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 HC-SR501人体红外模块是基于红外线技术的自动控制模块,采用德国原装进口LHI77…...

关于武汉芯景科技有限公司的IIC电平转换芯片XJ9517开发指南(兼容PCF9517)
一、芯片引脚介绍 1.芯片引脚 2.引脚描述 二、系统结构图 三、功能描述 1.电平转换 2.芯片使能/失能 EN 引脚为高电平有效,内部上拉至 VCC(B),允许用户选择中继器何时有效。这可用于在上电时隔离行为不良的从机,直到…...
、getchar()、gets())
C语言:scanf()、getchar()、gets()
一、gets() gets()能吸收空格和换行,因此输入后,对输出要去除空格 和换行\n; #include <stdio.h> #include <string.h> int main() {char str[1000];int count0;gets(str);for(int i0;i<strlen(str);i)count;printf("%s\n",str…...

基于MATLAB的全景图像拼接系统实现
简要的论文框架和技术思路 摘要 本文深入探讨了基于MATLAB平台的块匹配全景图像拼接系统的设计与实现。通过详细解析SIFT/SURF特征提取、RANSAC变换估计、APAP局部对齐、图割算法拼接缝选择及multi-band blending图像融合等关键技术,构建了高效且高质量的全景图像…...

AI模型“减肥”风潮:量化究竟带来了什么?
量化对大模型的影响是什么 ©作者|YXFFF 来源|神州问学 引言 大模型在NLP和CV领域的广泛应用中展现了强大的能力,但随着模型规模的扩大,对计算和存储资源的需求也急剧增加,特别是在资源受限的设备上面临挑战。量化技术通过将模型参数和…...

第四届“长城杯”网络安全大赛 暨京津冀网络安全技能竞赛(初赛) 全方向 题解WriteUp
战队名称:TeamGipsy 战队排名:18 SQLUP 题目描述:a website developed by a novice developer. 开题,是个登录界面。 账号admin,随便什么密码都能登录 点击头像可以进行文件上传 先简单上传个木马试试 测一下&…...

ETCD的备份和恢复
一、引言 ETCD是一个高度可用的键值存储系统,被广泛应用于Kubernetes等分布式系统中以存储关键配置数据和服务发现信息。由于ETCD的重要性,确保其数据的安全性和可靠性至关重要。本文将介绍ETCD备份与恢复的基础知识、常用方法及最佳实践。 二、概述 …...

Linux Makefile文本处理函数知识详解
1.Makefile函数 GNU make 提供了大量的函数用来处理文件名、变量、文本和命令。通过这些函数,用户可以节省很多精力,编写出更加灵活和健壮的Makefile。函数的使用和变量引用的展开方式相同: $(function arguments)${function arguments}关于…...

Rust的数据类型
【图书介绍】《Rust编程与项目实战》-CSDN博客 《Rust编程与项目实战》(朱文伟,李建英)【摘要 书评 试读】- 京东图书 (jd.com) Rust到底值不值得学,之一 -CSDN博客 Rust到底值不值得学,之二-CSDN博客 3.5 数据类型的定义和分类 在Rust…...

如何在vim中批量注释和取消注释
一、批量注释 首先在你需要注释的初始所在行在命令模式下输入CTRL v,然后按下HJKL来控制方向(不能使用键盘上的箭头方向键): 然后输入 shifti: 输入两个斜杠然后加exc就可以完成批量注释: 二、批量取消注…...

Centos7.9 安装Elasticsearch 8.15.1(图文教程)
本章教程,主要记录在Centos7.9 安装Elasticsearch 8.15.1的整个安装过程。 一、下载安装包 下载地址: https://www.elastic.co/cn/downloads/past-releases/elasticsearch-8-15-1 你可以通过手动下载然后上传到服务器,也可以直接使用在线下载的方式。 wget https://artifacts…...

哈希表-数据结构
一、哈希表基本概念 哈希表(也称为散列表)是根据键而直接访问在内存存储位置的数据结构,也就是说实际上是经过哈希函数进行映射,映射道表中一个位置来访问记录,这个存放记录的数组称为散列表。 哈希函数:就…...

指针之旅(4)—— 指针与函数:函数指针、转移表、回调函数
目录 1. 函数名的理解 1.1 “函数名”和“&函数名”的含义 1.2 函数(名)的数据类型 2. 函数指针(变量) 2.1 函数指针(变量)的创建格式 2.2 函数指针(变量)的使用格式 2.3 例子 判别 3. typedef 关键字 3.1 typedef的作用 3.2 typedef的运作逻辑 和 函数指针类型…...

打造线上+线下相结合的O2O平台预约上门服务小程序源码系统 带完整的安装代码包以及搭建部署教程
系统概述 本系统采用前后端分离的设计架构,前端以微信小程序为载体,提供直观、易用的用户界面;后端则采用稳定的服务器架构,确保数据处理的高效与安全。系统主要包括用户端、商户端和管理员端三大模块,通过API接口实现…...

python sys模块
在Python中,sys模块提供了访问和使用解释器的许多功能的方法,包括命令行参数、环境变量、路径管理、标准输入输出流等。sys模块是Python的标准库的一部分,不需要额外安装即可使用。 常用的sys模块功能 1. sys.argv sys.argv是一个包含命令…...

【Linux 报错】SSH服务器拒绝了密码。请再试一次。(xshell)
出现该错误 可能的原因: 你写入的登录密码错误了,错误原因有: 1、本来输入就错误了 2、创建用户时,只创建了用户名,但密码没有重新设置 3、多人使用同一台服务器时,该服务器管理员(本体&#x…...
云计算实训43——部署k8s基础环境、配置内核模块、基本组件安装
一、前期系统环境准备 1、关闭防火墙与selinux [rootk8s-master ~]# systemctl stop firewalld[rootk8s-master ~]# systemctl disable firewalldRemoved symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus…...

TAbleau 可视化 干货分享 | 简单三步助你打造完美仪表板
只需单击几下,你将能轻松创建美观、信息丰富的可视化效果、节省时间并推动业务向前发展! 借助精心设计的仪表板,分析师可以更好地理解复杂数据背后的信息,更有效地向他人分享你的见解,从而做出更明智的决策。 值得思考…...

JVM性能调优之5种垃圾收集器
JDK垃圾收集器 一、Serial GC垃圾收集器Serial GC的工作原理Serial GC的特点Serial GC的配置参数Serial GC的适用场景Serial GC的优缺点优点:缺点: Serial GC的总结 二、Parallel GC垃圾收集器Parallel GC的工作原理Parallel GC的特点Parallel GC的配置参…...

3步搞定显卡风扇异常:用FanControl彻底解决NVIDIA风扇噪音和转速问题
3步搞定显卡风扇异常:用FanControl彻底解决NVIDIA风扇噪音和转速问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitH…...

10个sd-webui-regional-prompter实用技巧:从基础分割到高级2D区域配置
10个sd-webui-regional-prompter实用技巧:从基础分割到高级2D区域配置 【免费下载链接】sd-webui-regional-prompter set prompt to divided region 项目地址: https://gitcode.com/gh_mirrors/sd/sd-webui-regional-prompter sd-webui-regional-prompter是一…...

终极指南:如何用文字描述快速生成专业CAD图纸
终极指南:如何用文字描述快速生成专业CAD图纸 【免费下载链接】text-to-cad-ui A lightweight UI for interacting with the Zoo Text-to-CAD API. 项目地址: https://gitcode.com/gh_mirrors/te/text-to-cad-ui 还在为复杂的CAD软件界面感到困惑吗ÿ…...

RK3588开发板Ubuntu系统深度解析:架构设计与性能优化指南
RK3588开发板Ubuntu系统深度解析:架构设计与性能优化指南 【免费下载链接】ubuntu-rockchip Ubuntu for Rockchip RK35XX Devices 项目地址: https://gitcode.com/gh_mirrors/ub/ubuntu-rockchip 在嵌入式开发领域,Rockchip RK3588处理器凭借其强…...

技术人的黄金十年:软件测试从业者25到35岁每一年该怎么规划?
对于每一位进入软件行业的技术人而言,25岁到35岁这十年几乎决定了整个职业生涯的上限,而软件测试作为产品质量的最后一道防线,这个岗位的能力积累、职业路径选择,更需要在这黄金十年里做好清晰的规划。不同于开发岗的技术迭代焦虑…...

机器学习驱动的中微子-核散射截面建模:从数据学习到振荡分析
1. 项目概述与核心价值 中微子物理正步入一个前所未有的“精密测量”时代。像DUNE(深地下中微子实验)这样的下一代长基线实验,目标是将中微子混合参数的测量精度推至百分之一量级。然而,一个长期存在的“拦路虎”限制了这一目标的…...

从开题到定稿,okbiye AI 写作如何解决毕业论文 90% 的核心痛点
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 作为一名踩过论文无数坑的过来人,我深知毕业季被毕业论文支配的恐惧:对着 Word 空白页无从下笔,开题报告…...

毕业论文神器!2026年好用AI论文平台榜单,高质初稿轻松写
2026 年实测 10 款主流 AI 论文工具,千笔AI以全流程覆盖 语义级降重 免费查重领跑综合榜;ThouPen 稳坐留学生毕业全流程工具头把交椅;免费工具中DeepSeek Scholar、豆包学术版表现亮眼,30 分钟即可生成万字高质量初稿࿰…...

Blender模型导入Unity材质丢失的根因与自动化修复方案
1. 这不是“导出再导入”那么简单:为什么Blender模型进Unity后总变灰、贴图全丢、材质不认 你刚在Blender里花三小时调好一个带PBR材质、多层UV、自发光贴图和顶点色的机械臂模型,导出FBX,拖进Unity——结果:模型是黑的࿰…...
)
C++ 左右值引用 完全详解(从入门到精通)
左右值引用是 C11 引入的最核心、影响最深远的特性,它直接催生了移动语义、完美转发、智能指针优化等现代 C 的基石。本文从最基础的定义开始,逐层深入到所有高级特性和常见陷阱,看完就能解决 99% 的面试和开发问题。一、先彻底搞懂ÿ…...