排序(插入,希尔,选择,堆,冒泡,快速,归并,计数)
本文中的Swap()函数都是下面这段代码
// 交换
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}文章目录
- 常见排序:
- 一.插入排序
- 1.直接插入排序:
- 2.希尔排序:
- 二.选择排序
- 1.选择排序:
- 2.堆排序:
- 三.交换排序
- 1.冒泡排序:
- 2.快速排序:
- 注(重要):三数取中
- (1)Hoare法:
- (2)挖坑法:
- (3)前后指针法:
- 快速排序递归版:
- 快速排序非递归版:
- 四.归并排序
- 1.归并排序
- 归并排序递归版:
- 归并排序非递归版
- 五.计数排序
常见排序:

一.插入排序
1.直接插入排序:

直接插入排序的基本思想:通过取一个数a与前面的数比较,a小则将前面的数后移,a继续向前比较,直到找到比a更小的数,插入到该位置。
代码实现:
// 直接插入排序 时间:O(N^2) 空间:O(1)
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];// [0,end]区间为有序的,排序好的有序区间// end+1位置的值插入到有序区间中while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}
2.希尔排序:

希尔排序的基本思想:先选定一个整数gap,将需要排序的内容分为gap组,所有的距离为gap的在同一组,并对每一组内的数进行排序。然后重复上述操作,直到gap减为1。
我们来看一下分步图:

// 希尔排序 时间:O(N^1.3)(大致) 空间:O(1)
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){// +1保证最后一个gap一定是1// gap > 1 时是预排序// gap == 1 时是插入排序gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
希尔排序就是对直接插入排序的优化,当gap > 1时都是在对数组进行预排序,当gap = 1时,此时的数组已经接近有序了,且当gap为1时,我们代入到希尔排序的代码中,再与上面的插入排序比较一下,我们就能发现是一样的。
二.选择排序
1.选择排序:

选择排序的基本思想:每一次从待排序的数据中选出最小(或最大值),将其放在前面,直到全部待排序的数据元素排完。
为了提高排序效率,我们也可以同时选出最小值和最大值,将最小值放在前面,最大值放在后面。
// 选择排序 时间:O(N^2) 空间:O(1)
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1; // 定义首位元素地址,同时找到最大和最小的,分别放到首和尾while (begin < end){int mini = begin, maxi = begin;for (int i = begin + 1; i <= end; i++) // 找到最大和最小值的下标{if (a[i] < a[mini]){mini = i;}if (a[i] > a[maxi]){maxi = i;}}Swap(&a[begin], &a[mini]);// 若首元素最大,将最小值交换到最前面后,begin会与maxi重叠// 需要更新maxi,防止begin与maxi重叠后,将把最小值交换到最后if (begin == maxi){maxi = mini;}Swap(&a[end], &a[maxi]);begin++;end--;}
}
2.堆排序:
堆排序需要我们对堆这个数据结构有一定了解。

堆排序时利用数据结构树(堆)进行排序的一种算法。通过堆进行选择数据。排升序建大堆,排降序建小堆。
我们来看一下分步图:

// 堆排序 时间:O(NlogN) 空间:O(1)
void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){//找到两个孩子中,较小/较大 的孩子 if (a[child + 1] < a[child] && child + 1 < n){child++;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{// 向下调整建堆 O(N)for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}三.交换排序
1.冒泡排序:

冒泡排序的基本思路:从前向后,两两比较,小的放前,大的放后
// 冒泡排序 时间:O(N^2) 空间:O(1)
void BubbleSort(int* a, int n)
{for (int i = 0; i < n; i++){int flag = 1; // 标记设为1,若后面都有序则直接进行下一次循环for (int j = 0; j < n - i; j++){if (a[j - 1] > a[j]){Swap(&a[j - 1], &a[j]);flag = 0;}}if (flag == 1){break;}}
}
2.快速排序:
快排的代码我们采用分离处理,下面三种方法的代码只写明单趟排序。递归的部分在三种方法之后。
快速排序的基本思想:任取待排序元素中的某个元素作为基准值key,以这个基准值key将数组分割为两部分,左边的所有元素均小于基准值key,右边的所有元素均大于基准值key,然后将左边重复该过程,右边重复该过程,直到数组有序。
注(重要):三数取中
在选取基准值key的时候,如果数组本身是有序的,直接对左边或者右边取key,这时算法的时间复杂度就会退化O(N^2),因此递归的深度比较大,可能会导致栈溢出,这就很坑。所以,我们应该科学的选key,这种方法就是三数取中。
三数取中的基本思路:我们取最左边,中间,最右边三个值,对这三个值进行比较,选择中间大小的值作为key。
// 三数取中
int GetMidi(int* a, int left, int right)
{int midi = (left + right) / 2;// left midi rightif (a[left] < a[midi]){if (a[midi] < a[right]){return midi;}else if (a[left] < a[right]){return right;}else{return left;}}else // a[left] > a[midi]{if (a[midi] > a[right]){return midi;}else if (a[left] < a[right]){return left;}else{return right;}}
}
(1)Hoare法:

在用Hoare法进行排序时,需要注意key的位置:左边做key,右边先走;右边做key,左边先走,这样才能保证相遇位置比key小。

我们来看一下分步图:

// 快速排序hoare版本
int PartSort1(int* a, int left, int right)
{int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]); // 将key值放在左边int keyi = left;int begin = left, end = right;while (begin < end){// 右边找小(右边先走)while (begin < end && a[keyi] <= a[end]){end--;}// 左边找大while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);return begin;
}
(2)挖坑法:

挖坑法的基本思路:先用key存储基准值,将第一个位置形成一个坑位,右侧找比key小的数,放入坑位,这个数的原位置形成新的坑位,重复这个操作,直到最后的坑位左侧都小于key,右侧都大于key。
注意:当此处为坑位时,不进行移动,移动另一个指针。
我们来看一下分步图:

// 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int key = a[left];int begin = left, end = right;int holi = left;while (begin < end){while (begin < end && key <= a[end]){end--;}a[holi] = a[end];holi = end;while (begin < end && key >= a[begin]){begin++;}a[holi] = a[begin];holi = begin;}a[begin] = key;return begin;
}
(3)前后指针法:

前后指针法基本思路:cur找比key小的数,prev找比key大的数,然后进行交换,cur越界,最后将key和prev交换。
这种方法也不用和Hoare法一样考虑先走左还是先走右,也更易理解。
我们来看一下分步图:

// 快速排序前后指针法
int PartSort3(int* a, int left, int right)
{int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int prev = left;int cur = prev + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[keyi], &a[prev]);return prev;
}
快速排序递归版:
对上面三种方法进行递归,进行多次排序。
void QuickSort(int* a, int left, int right)
{if (left >= right)return;if ((right - left + 1) < 10) // 这里小优化一下,数据内容小于10个的时候,直接进行插入排序,不走递归{InsertSort(a + left, right - left + 1);}else{// 三种方式随意选int keyi = PartSort1(a, left, right);//int keyi = PartSort2(a, left, right);//int keyi = PartSort3(a, left, right);// [left, keyi-1] keyi [keyi+1, right]QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}
}
快速排序非递归版:
快排的非递归实现,需要用到栈这个数据结构,因此需要先了解栈。
快排的非递归基本思路:用栈模拟递归的实现,在栈中存储区域范围,然后取栈顶区间,单趟排序,右左子区间入栈,循环上面的操作,直到栈为空。

// 快速排序 非递归实现
#include"Stack.h"
void QuickSortNonR(int* a, int left, int right)
{Stack st;StackInit(&st);StackPush(&st, right); // 先存right才能后用StackPush(&st, left); // 后存left才能先用while (!StackEmpty(&st)) // 循环每走一次相当于之前的一次递归{int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);int keyi = PartSort1(a, begin, end); // 三种方式随意选// [begin, keyi-1] keyi [keyi+1, end]if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}if (begin < keyi - 1){StackPush(&st, keyi - 1);StackPush(&st, begin);}}StackDestroy(&st);
}
四.归并排序
1.归并排序

归并算法的基本思路:将已经有序的子序列合并,得到完全有序的序列;即先把每个子序列变成有序,然后两个子序列有序的合并成为一个新的有序子序列,最终合并为一个完整的有序序列。
我们来看一下分步图:

归并排序递归版:
// 归并排序 时间:O(NlogN) 空间:O(N)
//
// 归并排序递归实现
void _MergeSort(int* a, int* tmp, int begin, int end)
{if (begin >= end){return;}int midi = (begin + end) / 2; // [begin, midi] [midi + 1, end] 分为两个区间// 递归_MergeSort(a, tmp, begin, midi);_MergeSort(a, tmp, midi + 1, end);int begin1 = begin, end1 = midi;int begin2 = midi + 1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");}_MergeSort(a, tmp, 0, n - 1);free(tmp);tmp = NULL;
}
归并排序非递归版
归并排序的基本思路:首先设置gap表示归并的元素个数,然后对子序列中的gap个元素进行归并,更新gap,重复上面操作,以循环的形式模拟递归的过程。
我们来看一下分步图:

// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");}int gap = 1; // 每组归并的数据个数while (gap < n){for (int i = 0; i < n; i += 2 * gap) // i表示每组归并的起始位置{// [begin1, end1][begin2, end2]int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + gap * 2 - 1;int j = i;// 这里需要对范围进行修正,否则有可能会导致数组越界访问// 第二组越界,整组都不需要归并if (begin2 >= n){break;}// 第二组的尾end2越界,修正后,再归并if (end2 >= n){end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));}gap *= 2;}free(tmp);tmp = NULL;
}
五.计数排序
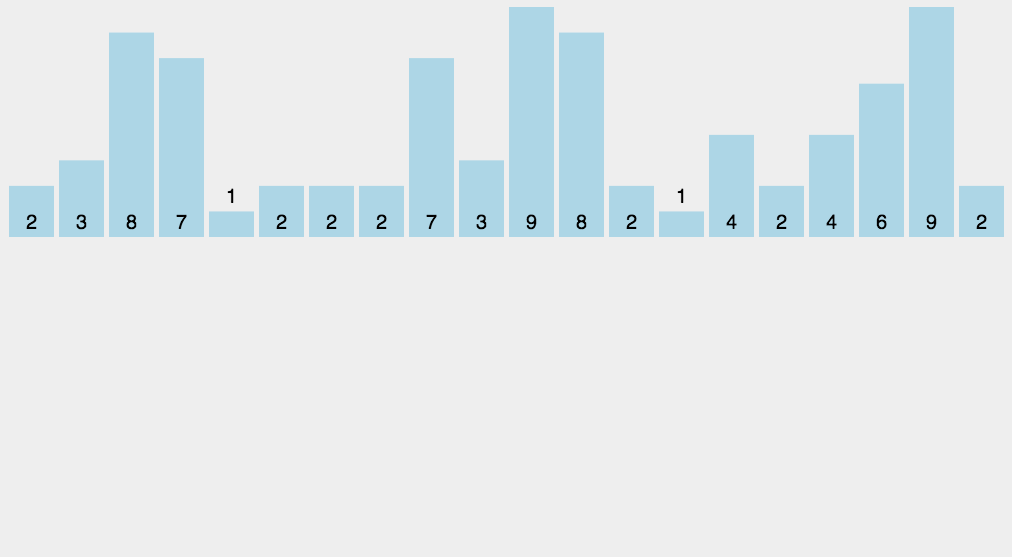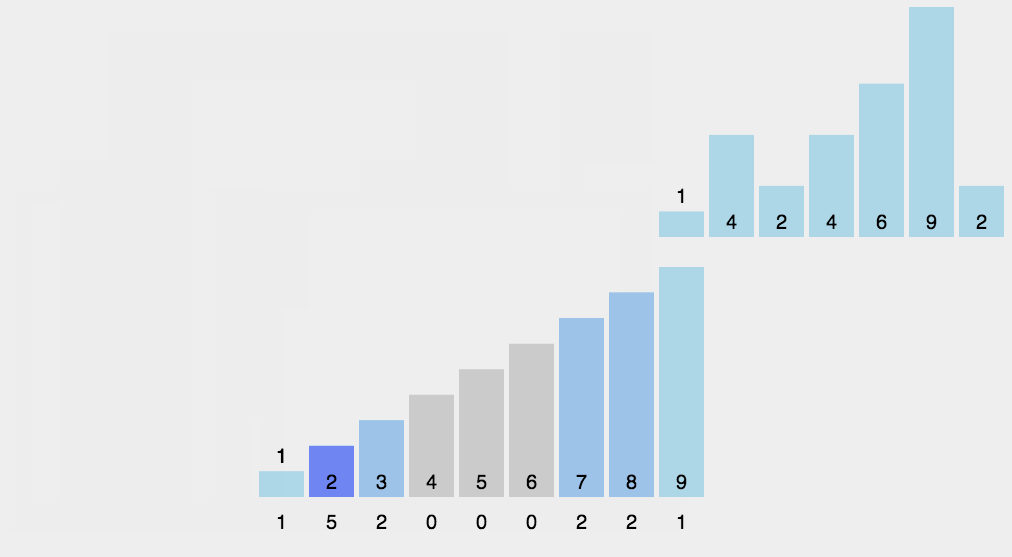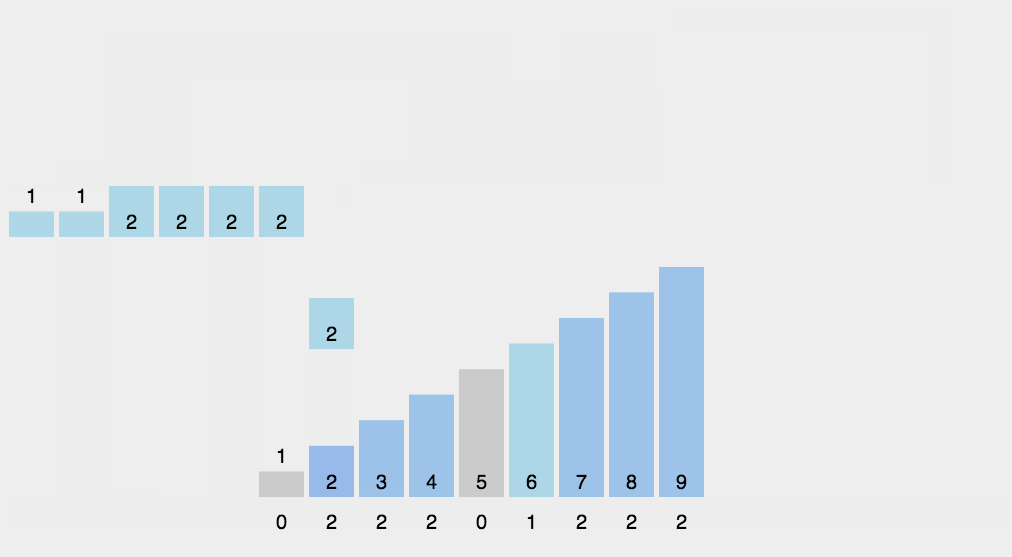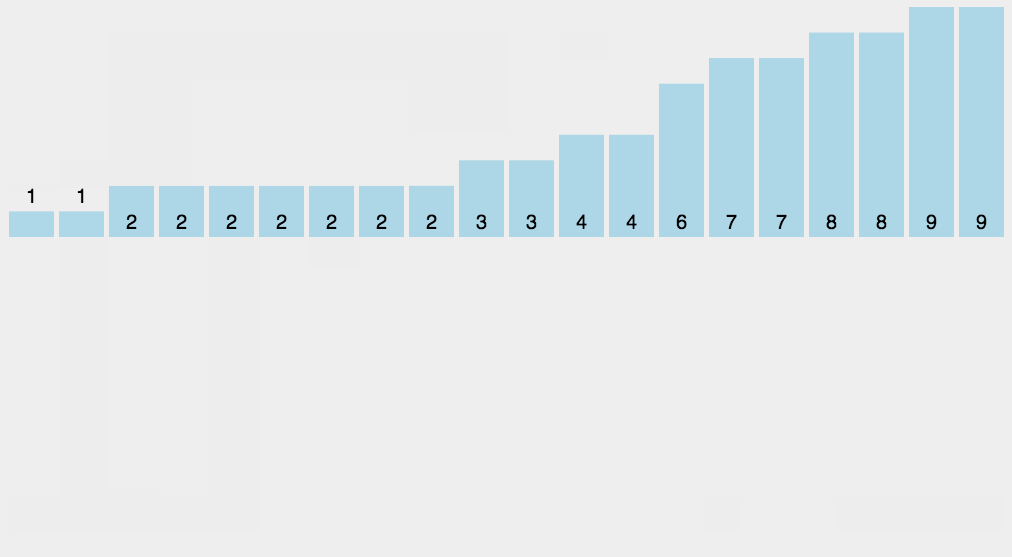
计数排序的基本思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。首先定义一个数组用来统计每个数出现的次数,然后根据统计的结果将序列回收到原来的序列中。
// 计数排序
void CountSort(int* a, int n)
{// 找最大,最小值,max - min + 1为count数组的长度,节省空间int min = a[0], max = a[0];for (int i = 1; i < n; i++){if (a[i] < min){min = a[i];}if (a[i] > max){max = a[i];}}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int));if (count == NULL){perror("malloc fail");}// 统计次数for(int i = 0; i < n; i++){count[a[i] - min]++;}// 排序int j = 0;for (int i = 0; i < range; i++){while (count[i]--){a[j++] = i + min; // 前面存储数据的时候减去了min,这里需要还原加上min}}free(count);count = NULL;
}
相关文章:
排序(插入,希尔,选择,堆,冒泡,快速,归并,计数)
本文中的Swap()函数都是下面这段代码 // 交换 void Swap(int* p1, int* p2) {int tmp *p1;*p1 *p2;*p2 tmp; }文章目录 常见排序:一.插入排序1.直接插入排序:2.希尔排序: 二.选择排序1.选择排序:2.堆排序: 三.交换排…...

【recast-navigation/源码解析】findStraightPath详解以及寻路结果贴边优化
说在前面 recast-navigation版本:1.6.0 叉积cross product 正常来讲,叉乘为: ∣ A ⃗ B ⃗ ∣ ∣ x A y A x B y B ∣ x A ⋅ y B − x B ⋅ y A |\vec{A} \times \vec{B}|\begin{vmatrix} x_A & y_A \\ x_B & y_B \end{vmatrix…...

移动管家手机智能控制汽车系统
手机可以通过下载特定的应用程序来控制汽车系统,实现远程启动、锁/解锁车门、调节车内温度等功能。 手机智能控制汽车系统主要通过下载并安装特定的APP来实现。 首先,用户需要确定自己的手机系统是安卓还是苹果版,然后前往应用…...

828华为云征文|华为云Flexus X实例Redis性能加速评测及对比
目录 前言 一、华为云Flexus X加速Redis购买 1.1 Flexus X实例购买 1.2 Redis加速镜像选择 1.3 重置密码 1.4 登录Flexus X实例 1.5 Flexus X实例Redis验证 二、Redis测评工具介绍 三、华为云Flexus X实例加速Redis测评 3.1 string类型 3.2 hash类型 3.3 list类型 3.4 set类型 …...

【OpenCV3】图像的翻转、图像的旋转、仿射变换之图像平移、仿射变换之获取变换矩阵、透视变换
1 图像的放大与缩小 2 图像的翻转 3 图像的旋转 4 仿射变换之图像平移 5 仿射变换之获取变换矩阵 6 透视变换 1 图像的放大与缩小 resize(src, dsize[, dst[, fx[, fy[, interpolation]]]]) src: 要缩放的图片dsize: 缩放之后的图片大小, 元组和列表表示均可.dst: 可选参数, 缩…...

不要认为996是开玩笑
996 预防针 随着秋招进程的不断推进,有部分同学已经 OC,有部分同学还在苦苦挣扎,并不断降低自己的预期,包括在和 HR 沟通过程中,主动说出自己愿意接受加班,愿意接受 996,以此来博得企业方面的加…...

精益工程师资格证书:2024年CLMP报名指南
随着全球对精益管理的需求日益增长,精益管理专业人士资格认证(CLMP)正成为越来越多精益工程师和精益管理人员提升职业竞争力的首选。作为一种注重管理而非生产的认证,CLMP不仅适用于制造业的专业人士,也吸引了各行业的…...

【Unity基础】如何选择脚本编译方式Mono和IL2CPP?
Edit -> Project Settings -> Player 在 Unity 中,Scripting Backend 决定了项目的脚本编译方式,即如何将 C# 代码转换为可执行代码。Unity 提供了两种主要的 Scripting Backend 选项:Mono 和 IL2CPP。它们之间的区别影响了项目的性能、…...

写在OceanBase开源三周年
我收获的深刻感触get 感触1:解决问题才有生存价值 [产品力] 感触2:永无止境的“易用性” [易用性] 感触3:立下“双赢”的flag 感触4:社区建设离不开用户和开发者参与 感触5:从易用到用户自助 [自助能力] 当时想法很简…...

【笔记】408刷题笔记
文章目录 三对角三叉树求最小带权路径UDP报文首部和TCP报文首部IP报文首部TCP报文首部UDP报文首部 刷新和再生的区别地址译码 为了区分队空队满,可以使用三种处理方式 1)牺牲一个单元 队头指针在队尾指针的下一位置作为队满的标志 队满条件:(…...
GitHub Star 数量前 13 的自托管项目清单
一个多月前,我们撰写并发布了这篇文章《终极自托管解决方案指南》。在那篇文章里我们深入探讨了云端服务与自托管方案的对比、自托管的潜在挑战、如何选择适合自托管解决方案,并深入介绍了五款涵盖不同场景的优秀自托管产品。 关于自托管的优势…...

js实现生成随机数值的数组
生成随机数值的数组 方法一:使用while循环和Set // min 开始数值, max 结束数值, count 数组内填充几个数值 function generateUniqueRandomNumbers(min, max, count) { let result new Set(); while (result.size < count) { let n…...

视频怎么转换成mp3格式?分享5种便捷的转换方法
在日常生活中,我们经常会遇到需要将视频文件中的音频提取出来,转换成MP3格式的情况,以便在手机、MP3播放器或其他设备上播放。今天,我将为大家介绍5种视频转MP3的方法,非常简单便捷,一起来学习下吧。 方法一…...

Reflection 70B如何革新语言模型的准确性与推理能力
在开源人工智能模型领域,HyperWrite 公司开发的 Reflection 70B 模型以其创新的“反射”机制成为新的重量级竞争者。这一模型旨在解决大型语言模型常见的“幻觉”问题,即生成不准确或虚构的信息。Reflection 70B 通过在提供最终响应之前评估和纠正自己的…...

覆盖索引是什么意思?
文章目录 Q1:覆盖索引是什么意思?覆盖索引的工作原理覆盖索引的优势覆盖索引的示例覆盖索引的使用场景覆盖索引的限制总结 Q2:为什么查询所涉及的所有字段都在索引中存在,那么数据库就无需回表?1. **索引本身存储了字段…...

最大间距问题
LeetCode164 最大间距 基数排序 #include <iostream> #include <vector> using namespace std;class Solution { public:int maximumGap(vector<int>& nums) {int nnums.size();if(n<2) return 0;int exp1;int Maxnums[0];vector<int> buf(n)…...

【Hadoop|MapReduce篇】Hadoop序列化概述
1. 什么是序列化 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。 反序列化就是将收到的字节序列(或其他数据传输协议)或者磁盘的持久化数…...

【Elasticsearch系列】Elasticsearch中的分页
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
NLTK:一个强大的自然语言处理处理Python库
我是东哥,一名热爱技术的自媒体创作者。今天,我将为大家介绍一个非常有趣且强大的Python库——NLTK。无论你是刚刚接触Python的小白,还是对自然语言处理(NLP)有些许了解的朋友,NLTK都是一个值得学习的工具。…...

NUUO网络视频录像机 css_parser.php 任意文件读取漏洞复现
0x01 产品简介 NUUO网络视频录像机(Network Video Recorder,简称NVR)是NUUO Inc.生产的一种专业视频监控设备,它广泛应用于零售、交通、教育、政府和银行等多个领域。能够同时管理多个IP摄像头,实现视频录制、存储、回放及远程监控等功能。它采用先进的视频处理技术,提供…...

python学习笔记 | 11.2、面向对象高级编程-使用@property
一、先搞懂:我们为什么要用 property? 1. 原始问题 直接给对象赋值,没法检查数据是否合法: class Student:passs Student() s.score 9999 # 成绩不可能是9999,完全不合理!2. 笨办法解决(太麻…...
原理与工程实践:从分治算法到信号处理应用)
快速傅里叶变换(FFT)原理与工程实践:从分治算法到信号处理应用
1. 从时域到频域:为什么我们需要FFT?如果你曾经处理过音频信号、图像数据,或者调试过通信系统,那你一定对“频谱”这个概念不陌生。我们生活的世界是时间的函数,声音随着时间起伏,图像像素在空间上排列&…...
)
AD9361配置避坑指南:从UART调试到FLASH固化的全流程实战(Verilog源码分析)
AD9361纯逻辑配置实战:从UART调试到FLASH固化的工程化解决方案 在无线通信系统开发中,AD9361作为一款高度集成的射频收发器,其配置方式直接关系到项目开发效率。对于需要脱离处理器依赖、追求极致实时性的场景,纯FPGA逻辑(PL)配置…...

深入STM32F103定时器:用TIM2输入捕获精准测量脉冲宽度与频率
深入STM32F103定时器:用TIM2输入捕获精准测量脉冲宽度与频率 在嵌入式开发中,精确测量外部信号的脉冲宽度和频率是一项常见但极具挑战性的任务。无论是工业控制中的旋转编码器、消费电子中的红外遥控信号,还是无人机领域的PPM控制信号&#x…...

手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线
手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线 在电磁仿真领域,材料参数的精确建模往往是决定仿真结果可靠性的关键因素。当我们需要模拟特殊频段的吸波材料、频率色散介质或各向异性材料时,仅依赖CST内置材料库…...

QiWe 免费开源微信机器人:从零到一的完整开发与部署指南
1. 为什么选择 QiWe 开源框架? 在私域流量运营和社群智能化的浪潮中,微信机器人早已成为降本增效的利器。然而,市面上许多闭源方案不仅收费高昂,还存在严重的数据泄露风险。QiWe 作为一款优秀的免费开源微信机器人框架,…...

手把手调试:用ADC0804读取PT100变送器信号,51单片机程序里的那些‘坑’怎么避?
51单片机实战:PT100温度检测系统避坑指南与ADC0804深度调试 当我们需要在工业控制或高精度测量场景中实现温度监控时,PT100铂电阻因其出色的线性度和稳定性成为首选传感器。然而,将PT100与51单片机结合使用时,从信号采集到温度显示…...

以太网口模块PCB设计全解析:从信号完整性到EMC的实战指南
1. 项目概述:为什么以太网口模块的PCB设计值得深究?干了这么多年硬件设计,画过的板子不计其数,但每次遇到带以太网口的项目,心里还是会多一份谨慎。这玩意儿看着简单,RJ45插座加个变压器,再连到…...

ARM核心板存储选型实战:从DDR到eMMC的避坑指南
1. 项目概述:一个被低估的硬件选型难题在嵌入式系统开发,尤其是基于ARM架构的工控和核心板设计中,存储选型常常被新手甚至一些有经验的工程师视为一个“小问题”。不就是选个Flash和RAM吗?很多人会这么想。然而,在我十…...

wlnmp一键安装包260520更新:多软件版本升级,支持多系统架构快速部署
wlnmp一键安装包更新:多软件版本升级wlnmp一键安装包在260520迎来更新,此次更新涉及多个重要软件的版本升级,包括nginx1.30.1、php8.2.31、php8.3.31等多个php版本,以及MySQL8.0.46、MySQL8.4.9。这些软件版本的更新,为…...