SelectDB 多计算集群核心设计要点揭秘与场景应用
需求起源
SelectDB 设计多计算集群架构初衷主要源于两类典型的使用场景:
-
写入与读取隔离:传统数仓架构中,数据的写入和读取在同一个计算集群,当遇到业务写入高峰期或突增的写入压力时,容易因资源相互抢占影响查询服务的性能和稳定性。如果能引入多个计算集群,通过独立的计算集群分别进行写入、读取操作,即使在写入压力非常高时,也可放心执行计算任务,无需担心影响到服务的稳定性。
-
在线业务和离线业务隔离:大量数据分析场景会使用相同的数据支撑多个业务,比如某业务使用一份数据支持面向 C 端用户的数据查询,另一个业务需要使用相同数据支持企业内部用户的运营分析等,这两个业务对于服务的延时、可用性要求完全不同。传统架构通常会把数据冗余存储到不同系统中,用于满足不同业务的需求,但这会带来冗余数据的存储成本和多套系统的维护成本。如果支持多计算集群架构,可基于同一份数据拷贝,并使用独立隔离的计算资源分别满足在线和离线业务需求,便能为用户带来可观的成本节省和简单的运维体验。
SelectDB Cloud 是基于 Apache Doris 研发的全托管实时数据仓库服务,采用全新的云原生存算分离架构。当计算层与存储层进行了分离设计后,计算层由于没有了数据状态,可支持极其灵活快速的弹性伸缩;而存储层由于和计算解耦,可以极为方便的供多个计算资源进行共享访问。因此,我们在 SelectDB 中引入多计算集群能力,通过数据仓库架构上的创新来更好地满足用户需求。
初识 SelectDB 多集群
在 SelectDB 的架构设计中,一个仓库实例可包含多个集群,类似分布式系统中的计算队列和计算组。数据持久化在底层的共享存储中,多个集群均可共享访问。每个集群本身即为一套分布式系统,包含一个或多个 BE 节点。由于存算分离架构中远程存储访问速度较慢,我们在计算节点本地引入了缓存,以加速数据访问。
例如下面架构图中,仓库 1 中包含集群 1、集群 2、集群 3,它们均可访问存储在共享存储中的数据。
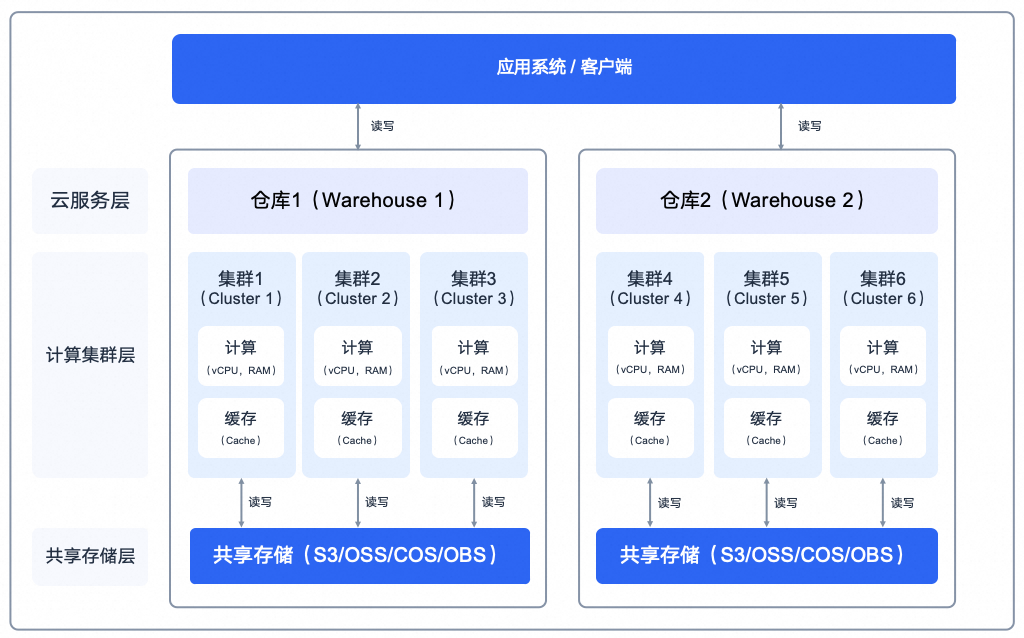
对于多集群的使用方式,用户连接 SelectDB 仓库实例后,可通过命令切换使用不同的计算集群。一个使用多计算集群进行读写分离的样例如下:
-
通过 MySQL Client 连接 SelectDB,使用集群 cluster_1 进行数据库、表的建立。
# 切换使用计算集群 cluster_1 USE @cluster_1;# 创建 database、table CREATE DATABASE test_db; USE test_db; CREATE TABLE test_table (k1 TINYINT,k2 DECIMAL(10, 2) DEFAULT "10.05",k3 CHAR(10) COMMENT "string column",k4 INT NOT NULL DEFAULT "1" COMMENT "int column" ) COMMENT "my first table" DISTRIBUTED BY HASH(k1) BUCKETS 16; -
通过 Stream Load 方式,使用集群 cluster_2 写入样例数据。
curl --location-trusted -u admin:admin_123 -H "cloud_cluster:cluster_2" -H "label:123" -H "column_separator:," -T data.csv http://host:port/api/test_db/test_table/_stream_load其中 data.csv 中的样例数据如下:
1,0.14,a1,20 2,1.04,b2,21 3,3.14,c3,22 4,4.35,d4,23 -
通过 MySQL Client 连接 SelectDB,使用集群 cluster_3 进行数据查询:
# 切换使用计算集群 cluster_3 USE @cluster_3;# 进行查询访问 SELECT * FROM test_table;
多集群的核心设计
在云原生存算分离架构下,多计算集群的实现从技术方案上看似乎并不存在过多难题。但从产品的角度而言,具备成熟易用的多计算集群能力且能运用于用户实际业务场景中,还有较多核心要点需要深度设计。 下面,我们对其中部分关键点进行介绍。
如何保证强一致的数据共享?
存算分离后,数据存储在共享存储中,可以供多个集群访问。在一个集群写入完成后,另一个集群是否能够立即访问到数据? 如果不能,将会存在一定的数据延迟,对很多实时性要求高的业务场景来说,这种方案难以接受。
为了达到数据的强一致访问,SelectDB 不仅实现了数据的共享化,也进行了深度重构,实现元数据的共享化:当数据通过其中一个集群写入共享存储后,会先更新共享的元数据,再返回数据写入结果。当其他集群进行数据访问时,可通过访问共享的元数据中心获取最新的数据信息,从而做到强一致的数据共享。这意味着通过任一个集群写入 SelectDB 中的数据,一旦写入成功,其他集群立即可见。
如何实现数据的多写多读?
基于共享存储,数据的多读是比较容易实现的,但写入是否只能由其中一个集群进行?如果只能通过其中一个集群写入,那该集群是事先人工确定、出问题时人工变更所有写入作业,还是引入分布式锁在多集群之间进行协调、以决定哪个集群来负责写入?
更麻烦的是,当原写入集群处于假死状态,可能出现多个集群尝试去写入的冲突情况,解决这些问题会导致数据仓库的架构复杂度大幅增加。因此关系型数据库在探索了很多年后,大量系统仍采用一写多读的架构。
SelectDB 结合数仓场景的特点,进行了深度思考设计,可实现数据的多写多读,以简化用户的运维过程、降低系统复杂度。具体而言,数仓场景通过采用小批量、多并发的写入方式,来达到写入的高吞吐,数据延迟达到秒级即可满足大多数用户的需求,可以看到数仓的写入事务并发不高,并无关系型数据库每秒数十万的事务并发需求。因此 SelectDB 可以基于数据的 MVCC 多版本机制,借助共享的元数据中心进行事务协调,数据先提交多个集群进行转化处理,然后在更新元数据阶段(生效数据过程)进行分布式协调,先获取到锁的集群写入成功,其他集群则进行重试。由于数据写入的开销主要在转化处理过程,基于这样的分布式协调机制和乐观锁设计,实现多读多写能力的同时,也可利用多集群进一步提升并发写入吞吐。
如何实现灵活可控的缓存能力?
存算分离架构通常采用对象存储或 HDFS 类系统作为远端共享存储,其单次 IO 请求的访问性能较差,相比本地存储性能下降数十倍。如何保障存算分离架构中计算集群的查询性能?进一步的,当采用多集群支持读写分离、在离线隔离场景时,如何保证多集群的查询性能呢?
SelectDB 通过提供精心设计的缓存管理机制,可自动化保障存算分离架构的查询性能,也可按需满足用户灵活多变的调优需求:
-
对于单个计算集群,SelectDB 默认会根据 LRU 策略进行数据缓存,当缓存大小足够存储全部热数据时,即可保障存算分离类系统的性能追平存算一体类系统,由于本地缓存的单副本设计、远端存储的低廉价格,存算分离架构的存储成本要大幅低于存储一体架构。SelectDB 同时提供了手动的缓存控制策略,可通过手动策略保证某些表的数据优先存储于缓存中。此外,当集群进行弹性伸缩时,SelectDB 会自动基于统计信息,提前进行缓存的预热或迁移,以保障变更过程中查询服务平稳。
-
对于多个计算集群,SelectDB 提供了提供了跨集群的缓存同步能力,可同步已有集群的缓存数据到其他集群,从而加速查询性能,并且支持分区粒度的缓存同步控制能力。每个计算集群的缓存是独立的,用户可根据需要按需控制缓存大小。
如何进行权限控制与资源隔离?
一个仓库中的多个计算集群之间,由于计算资源互相独立,因此计算集群间完全隔离。然而,当仓库下有多个计算集群可用时,如何避免用户误用集群,导致业务间的互相干扰?另外,由于存储资源共享,其带宽和 QPS 能力有限,如何保障一个集群对共享存储的访问不干扰其他的集群?
SelectDB 提供完整的权限控制与资源隔离的方案,来保障多计算集群架构有条不紊的运行:
-
对于计算集群的使用,SelectDB 提供一套简单易用的权限机制,集群支持类似库表的权限分配机制,只有给用户分配了某集群的权限,用户才可以使用该集群,从而避免集群误用情况。
-
对于存储资源的访问,SelectDB 支持按照集群规格,进行存储带宽和 IOPS 的限流控制,当超过限速后存储访问请求将进行排队,以避免多个集群之间互相干扰。
解锁更多使用场景
多计算集群架构的最初设计目标主要是为了满足读写隔离、在离线业务隔离等场景应用。SelectDB 的多计算集群方案上线后,有近半用户使用过多计算集群,我们意外发现多计算集群的应用潜力正在持续延伸:
-
弹性临时集群:在实际使用过程中,考虑业务隔离性,用户经常需要一个集群用于临时性业务,例如管理员保留一个隔离的测试集群用于日常访问、新功能正式发布前建立完全仿真的集群进行测试验证、月底或临时性的数据处理任务通过独立的集群进行等。为更好的满足此类需求,SelectDB 也提供了一系列配套能力,如同一个仓库同时支持包月和按量集群的混合计费模式、按量集群支持通过停止闲置计算资源来降低成本等。
-
跨可用区容灾:当前部署架构中,元数据中心、共享存储已支持跨可用区容灾,用户完全可以通过把多集群放置在不同可用区中,来完成全链路的跨可用区容灾。由于请求的处理过程主要在一个集群内部完成,跨可用区的访问仅在少量元数据获取过程,这种方案对查询性能也基本无影响。当某个可用区出现故障时,可通过一条命令,快速把业务切换到其他可用区。
-
集群切换式变更:当用户需要对集群进行某些变更操作时,可通过双集群切换方式进行平滑变更。比如对集群缓存资源进行缩容场景,由于目前集群弹性功能不支持缓存缩容,用户可通过新建低缓存容量的集群替换老集群。另外,后续我们可支持双集群切换来进行 SelectDB 大版本的平滑升级,当升级过程中发现问题时可随时安全回滚,保障大版本升级的稳定性,这也是一个极为重要的应用场景。
设计自省
在线上运营过程中,我们也在持续收集用户使用反馈、观察用户使用卡点,其中有两点设计引起了我们的反思,并正在进行设计上的优化重构:
-
集群命名设计:对于大量云上用户,已经建立实例和集群的专有概念,集群是用户购买在云控制台上购买的最小单元,在 MongoDB、Elasticsearch 等产品中,集群通常等价于实例。而在 SelectDB 的架构设计中,仓库或实例是购买的最小单元,集群是仓库内部的一组计算资源。这里概念设计上的不一致,给不少用户带来了理解上的麻烦。SelectDB 目前正在逐步调整系统架构中的概念,逐步把“计算集群”引导为“计算队列”、“计算组”等更贴切的概念。
-
默认权限策略:为避免集群误用导致多集群之间互相干扰,SelectDB 提供了多集群的权限控制能力,默认普通用户没有集群使用权限,需分配权限后方可使用。此类设计给新用户快速上手带来了较大门槛,不少用户在刚开始使用时会发现无法查询,也增加了仅仅使用单集群时的使用成本。SelectDB 目前正在思考重新设计集群权限部分,默认情况下用户拥有所有集群的使用权限,而把多集群的权限控制作为高阶功能,交给用户按需开启使用。
相关文章:
SelectDB 多计算集群核心设计要点揭秘与场景应用
需求起源 SelectDB 设计多计算集群架构初衷主要源于两类典型的使用场景: 写入与读取隔离:传统数仓架构中,数据的写入和读取在同一个计算集群,当遇到业务写入高峰期或突增的写入压力时,容易因资源相互抢占影响查询服务…...

Docker 清理和查看镜像与容器占用情况
查看容器占用磁盘大小 docker system df 查看单个image、container大小: docker system df -v 清理所有废弃镜像与Build Cache docker system prune -a...

如何在Android 12 aosp系统源码中添加三指下滑截图功能
如何在Android 12 aosp系统源码中添加三指下滑截图功能 系统中截图api非常简单: private static ScreenshotHelper sScreenshotHelper;sScreenshotHelper new ScreenshotHelper(mContext);//调用 sScreenshotHelper.takeScreenshot(WindowManager.TAKE_SCREENSHO…...

使用SQL语句查询MySQL数据表
6.1 创建单表基本查询 1.Select 语句的语法格式及其功能 (1)Select 语句的一般格式。 Select < 字段名称或表达式列表 > From < 数据表名称或视图名称 > [ Where < 条件表达式 > ] [ Group By < 分组的字段名称…...

【AI绘画、换脸、写作、办公】从零开始:使用AIStarter启动器发布AI应用
随着人工智能技术的快速发展,越来越多的开发者希望通过自己的创意来构建和分享AI应用。AIStarter启动器正是为此而设计的一个强大工具,它可以帮助开发者轻松打包并发布自己的AI应用项目。本文将详细介绍如何使用AIStarter启动器来实现这一目标。 注册账…...

eeprom使用 cubemx STM32F407ZGT6【IIC驱动AT24C02】
存储器的简单介绍 ROM(只读存储器)、RAM(随机存取存储器)、Flash(闪存)、和EEPROM(电可擦可编程只读存储器)是四种不同类型的存储介质。ROM用于存储固件或永久数据,不易…...

STL-stack/queue/deque(容器适配器)
目录 编辑 STL-stack 150. 逆波兰表达式求值 stack queue std::stack deque 性能测试 结构 STL-stack 栈的压入、弹出序列_牛客题霸_牛客网输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假。题目…...

NVDLA专题15:Runtime environment-核心模式驱动
核心模式驱动(Kernel Mode Driver) KMD主入口点在内存中接收一个推理作业,从多个可用的作业中选择要执行的作业(如果在多进程系统上),并将其提交给核心引擎调度程序。该核心引擎调度程序负责处理来自NVDLA的中断,调度每…...

计算机毕业设计选题推荐-班级管理系统-教务管理系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

推荐一款开源、高效、灵活的Redis桌面管理工具:Tiny RDM!支持调试与分析功能!
1、引言 在大数据和云计算快速发展的今天,Redis作为一款高性能的内存键值存储系统,在数据缓存、实时计算、消息队列等领域发挥着重要作用。然而,随着Redis集群规模的扩大和复杂度的增加,如何高效地管理和运维Redis数据库成为了许…...

Java项目: 基于SpringBoot+mybatis+maven新闻推荐系统(含源码+数据库+毕业论文)
一、项目简介 本项目是一套基于SpringBootmybatismaven新闻推荐系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、…...

《Python读取 Excel 数据》
关于如何在 Python 中读取excel数据。 方法一: 我们可以使用 pandas 库来读取 Excel 数据。 通过以下命令安装: pip install pandas 以下是读取 Excel 数据的代码: import pandas as pd # 读取 Excel 文件 data pd.read_excel(…...

Druid连接池
一.什么是Druid连接池? Druid 是阿里巴巴开源的一款数据库连接池(Database Connection Pool),具有高效、稳定、安全等特点。除了连接池的功能外,Druid 还提供了强大的 SQL 监控、统计、日志记录、防火墙等功能。它主要…...
资讯类页面智能解析)
Python3网络爬虫开发实战(14)资讯类页面智能解析
文章目录 一、详细页智能解析算法1.1 提取标题1.2 提取正文1.3 提取时间 二、列表页智能解析算法三、智能分辨列表页和详细页四、完整的库4.1 参考文献4.2 Project 页面智能解析就是利用算法从页面的 HTML 代码中提取想要的内容,算法会自动计算出目标内容在代码中的…...

社交媒体的未来:Facebook如何通过AI技术引领潮流
在数字化时代的浪潮中,社交媒体平台不断演变,以适应用户需求和技术发展的变化。作为全球领先的社交媒体平台,Facebook在这一进程中扮演了重要角色。尤其是人工智能(AI)技术的应用,正在深刻地改变Facebook的…...

Java 面试题:从源码理解 ThreadLocal 如何解决内存泄漏 ConcurrentHashMap 如何保证并发安全 --xunznux
文章目录 ThreadLocalThreadLocal 的基本原理ThreadLocal 的实现细节内存泄漏源码使用场景 ConcurrentHashMap 怎么实现线程安全的CAS初始化源码添加元素putVal方法 ThreadLocal ThreadLocal 是 Java 中的一种用于在多线程环境下存储线程局部变量的机制,它可以为每…...

使用人力劳务灵工安全高效的发薪工具
实现企业、劳务、蓝领工人三方的需求撮合、劳务交付、日结考勤、薪费结算一体化闭环,全面为人力企业降低用工成本、提高用工效率。 发薪难 日结/周结/临时工人员难管理,考勤难统计,发薪耗时间 发薪慢 人工核算时间长,微信转账发薪容易限额…...

使用W外链创建微信短链接的方法
创建短链是将长链接转换为更短、更易于分享和记忆的链接的过程。W外链是一个提供短链接生成服务的平台,它支持多种功能,包括但不限于: 短链制作:用户可以将长链接缩短为易于分享的短链接,还支持自定义短链后缀。防红防…...

【人工智能学习笔记】4_4 深度学习基础之生成对抗网络
生成对抗网络(Generative Adversarial Network, GAN) 一种深度学习模型,通过判别模型(Discriminative Model)和生成模型(Generative Model)的相互博弈学习,生成接近真实数据的数据分…...

基于MinerU的PDF解析API
基于MinerU的PDF解析API - MinerU的GPU镜像构建 - 基于FastAPI的PDF解析接口支持一键启动,已经打包到镜像中,自带模型权重,支持GPU推理加速,GPU速度相比CPU每页解析要快几十倍不等 主要功能 删除页眉、页脚、脚注、页码等元素&…...

联想拯救者工具箱终极指南:完全替代Vantage的轻量级硬件管理方案
联想拯救者工具箱终极指南:完全替代Vantage的轻量级硬件管理方案 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...
)
从C++代码到机器指令:用OD和IDA手把手拆解一个简单的main函数(附寄存器图解)
从C代码到机器指令:用OD和IDA手把手拆解一个简单的main函数(附寄存器图解) 在逆向工程的世界里,理解高级语言如何转化为底层机器指令是一项基础而关键的技能。本文将以一个最简单的C main 函数为例,带你一步步追踪其从…...

炸了!Claude 更新后 Mac 老系统直接报废:开发者凌晨三点爬起来修环境
一、真实事故现场:上海某团队的惊魂一夜 2026年5月15日凌晨2:37,上海浦东某科技公司。 高级工程师小李盯着屏幕上的错误信息,手指在键盘上飞快地敲击着。他面前是三个显示器,每个都显示着不同的终端窗口,满屏的红色错误信息像血一样刺眼。 "这怎么可能?"他自…...

【紧急预警】Perplexity v3.2+图谱查询API行为突变:4类高危误用场景及24小时内修复方案
更多请点击: https://codechina.net 第一章:Perplexity知识图谱查询 Perplexity 是一款基于大语言模型的实时知识检索工具,其底层融合了多源结构化知识图谱与动态网页索引能力,支持对实体、关系及事件进行语义化查询。不同于传统…...

Logback彩色日志进阶玩法:自定义颜色规则、区分环境开关,以及文件日志的‘去色’指南
Logback彩色日志进阶实战:从炫彩控制台到严谨生产环境的全链路配置 在软件开发的生命周期中,日志是我们最忠实的伙伴。想象一下深夜调试时,满屏灰白的日志中突然跳出一行醒目的红色ERROR信息——这就是彩色日志赋予我们的"视觉直觉"…...

iMX8MQ开发板实测:存储、网络与4K解码性能深度解析
1. 项目概述:iMX8MQ开发板深度评测最近拿到了一块飞凌嵌入式出品的OKMX8MQ-C开发板,这是一款基于NXP i.MX 8M Quad处理器设计的核心板底板套件。对于从事嵌入式多媒体、边缘计算或者工业网关开发的朋友来说,i.MX8系列一直是热门选择ÿ…...

3分钟上手Windhawk:像安装App一样轻松定制Windows系统
3分钟上手Windhawk:像安装App一样轻松定制Windows系统 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 你是否厌倦了Windows系统一成不变的界…...

Perplexity社会新闻搜索响应延迟突增47%?独家披露其底层新闻图谱更新机制与3类高危缓存失效场景
更多请点击: https://kaifayun.com 第一章:Perplexity社会新闻搜索响应延迟突增47%?独家披露其底层新闻图谱更新机制与3类高危缓存失效场景 Perplexity 社会新闻搜索服务近期观测到 P95 响应延迟从 320ms 飙升至 468ms,增幅达 4…...

终极指南:Visual C++运行库合集AIO - 一站式解决Windows软件依赖问题
终极指南:Visual C运行库合集AIO - 一站式解决Windows软件依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为运行软件时遇到"找不到…...

Avidemux:开源视频剪辑神器,5分钟学会专业级视频处理
Avidemux:开源视频剪辑神器,5分钟学会专业级视频处理 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你知道吗?在开源视频编辑领域,有一款轻量级但功…...