自然语言处理系列六十三》神经网络算法》LSTM长短期记忆神经网络算法
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
文章目录
- 自然语言处理系列六十三
- 神经网络算法》LSTM长短期记忆神经网络算法
- Seq2Seq端到端神经网络算法
- 总结
自然语言处理系列六十三
神经网络算法》LSTM长短期记忆神经网络算法
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。
1. LSTM介绍
长短期记忆网络(long short term memory, LSTM)的设计正是为了解决上述RNN的依赖问题,即为了解决RNN有时依赖的间隔短,有时依赖的间隔长的问题。其中循环神经网络被成功应用的关键就是LSTM。在很多的任务上,采用LSTM结构的循环神经网络比标准的循环神经网络的表现更好。LSTM结构是由Sepp hochreiter和Jurgen Schemidhuber于1997年提出的,它是一种特殊的循环神经网络结构。
2. LSTM结构
长LSTM的设计就是为了精确解决RNN的长短记忆问题,其中默认情况下LSTM是记住长时间依赖的信息,而不是让LSTM努力去学习记住长时间的依赖,如图7.30所示。

图7.30LSTM结构
所有循环神经网络都有一个重复结构的模型形式,在标准的RNN中,重复的结构是一个简单的循环体,如图7.28 所示的A循环体。然而LSTM的循环体是一个拥有四个相互关联的全连接前馈神经网络的复制结构,如图7.30所示。
目前可以先不必了解LSTM细节,只需先明白如下图7.31所示的符号语义:

图7.31 符号语义
Neural NetWork Layer:该图表示一个神经网络层;
Pointwise Operation:该图表示一种操作,如加号表示矩阵或向量的求和、乘号表示向量的乘法操作;
Vector Tansfer:每一条线表示一个向量,从一个节点输出到另一个节点;
Concatenate:该图表示两个向量的合并,即由两个向量合并为一个向量,如有X1和X2两向量合并后为[X1,X2]向量;
Copy:该图表示一个向量复制了两个向量,其中两个向量值相同。
3. LSTM分析
LSTM设计的关键是神经元的状态,如下图7.32所示顶部的水平线。神经元的状态类似传送带一样,按照传送方向从左端被传送到右端,在传送过程中基本不会改变,只是进行一些简单的线性运算:加或减操作。神经元的通过线性操作能够小心地管理神经元的状态信息,将这种管理方式称为门操作(gate)。

图7.32 C-line
门操作能够随意的控制神经元状态信息的流动,如下图7.33所示,它由一个sigmoid激活函数的神经网络层和一个点乘运算组成。Sigmoid层输出要么是1要么是0,若是0则不能让任何数据通过;若是1则意味着任何数据都能通过。

图7.33 gate
LSTM有三个门来管理和控制神经元的状态信息:
1)遗忘门
LSTM的第一步是决定要从上一个时刻的状态中丢弃什么信息,其是由一个sigmoid全连接的前馈神经网络的输出阿里管理,将这种操作称为遗忘门(forget get layer)。如图7.34所示。这个全连接的前馈神经网络的输入是和组成的向量,输出是向量。向量是由1和0组成,1表示能够通过,0表示不能通过。

图7.34 focus-f
2)输入门
第二步决定哪些输入信息要保存到神经元的状态中。这又两队前馈神经网络,如图7.35所示。首先是一个sigmoid层的全连接前馈神经网络,称为输入门(input gate layer),其决定了哪些值将被更新;然后是一个tanh层的全连接前馈神经网络,其输出是一个向量,向量可以被添加到当前时刻的神经元状态中;最后根据两个神经网络的结果创建一个新的神经元状态。

图7.35 focus-i
3)状态控制
第三步就可以更新上一时刻的状态为当前时刻的状态了。上述的第一步的遗忘门计算了一个控制向量,此时可通过这个向量过滤了一部分状态,如图7.36所示的乘法操作;上述第二步的输入门根据输入向量计算了新状态,此时可以通过这个新状态和状态根据一个新的状态,如图 27所示的加法操作。

图7.36focus-C
4)输出门
最后一步就是决定神经元的输出向量是什么,此时的输出是根据上述第三步的状态进行计算的,即根据一个sigmoid层的全连接前馈神经网络过滤到一部分状态作为当前时刻神经元的输出,如图7.37所示。这个计算过程是:首先通过sigmoid层生成一个过滤向量;然后通过一个tanh函数计算当前时刻的状态向量(即将向量每个值的范围变换到[-1,1]之间);接着通过sigmoid层的输出向量过滤tanh函数结果,即为当前时刻神经元的输出。

图7.37focus-o
4.LSTM实现语言模型代码实战
下面实现一个语言模型,它是NLP中比较重要的一部分,给上文的语境后,可以预测下一个单词出现的概率。如果是中文的话,需要做中文分词。什么是语言模型?统计语言模型是一个单词序列上的概率分布,对于一个给定长度为m的序列,它可以为整个序列产生一个概率 P(w_1,w_2,…,w_m)。其实就是想办法找到一个概率分布,它可以表示任意一个句子或序列出现的概率。
目前在自然语言处理相关应用非常广泛,如语音识别(speech recognition) , 机器翻译(machine translation), 词性标注(part-of-speech tagging), 句法分析(parsing)等。传统方法主要是基于统计学模型,最近几年基于神经网络的语言模型也越来越成熟。
下面就是基于LSTM神经网络的语言模型代码实现,先准备下数据和代码环境:
#首先下载PTB数据集并解压放到工作路径下
wget http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
tar xvf simple-examples.tgz
#然后下载tensorflow models库,进入目录models/tutorials/rnn/ptb。然后载入常用的库,#和tensorflow models中的PTB reader,通过它读取数据
git clone https://github.com/tensorflow/models.git
cd models/tutorials/rnn/ptb
LSTM核心如代码7.2所示。
【代码7.2】 lstm.py
#-*- coding: utf-8 -*-
import time
import numpy as np
import tensorflow as tf
import ptb.reader as readerflags = tf.app.flags
FLAGS = flags.FLAGSlogging = tf.loggingflags.DEFINE_string("save_path", './Out',"Model output directory.")
flags.DEFINE_bool("use_fp16", False,"Train using 16-bit floats instead of 32bit floats")def data_type():return tf.float16 if FLAGS.use_fp16 else tf.float32#定义语言模型处理的输入数据的class
class PTBInput(object):"""The input data."""#初始化方法#读取config中的batch_size,num_steps到本地变量。def __init__(self, config, data, name=None):self.batch_size = batch_size = config.batch_sizeself.num_steps = num_steps = config.num_steps #num_steps是LSTM的展开步数#计算每个epoch内需要多好轮训练的迭代self.epoch_size = ((len(data) // batch_size) - 1) // num_steps#通过ptb_reader获取特征数据input_data和label数据targetsself.input_data, self.targets = reader.ptb_producer(data, batch_size, num_steps, name=name)#定义语言模型的class
class PTBModel(object):"""PTB模型"""#训练标记,配置参数,ptb类的实例input_def __init__(self, is_training, config, input_):self._input = input_batch_size = input_.batch_sizenum_steps = input_.num_stepssize = config.hidden_size #hidden_size是LSTM的节点数vocab_size = config.vocab_size #vocab_size是词汇表#使用遗忘门的偏置可以获得稍好的结果def lstm_cell():#使用tf.contrib.rnn.BasicLSTMCell设置默认的LSTM单元return tf.contrib.rnn.BasicLSTMCell(size, forget_bias=0.0, state_is_tuple=True)#state_is_tuple表示接受和返回的state将是2-tuple的形式attn_cell = lstm_cell
#如果训练状态且Dropout的keep_prob小于1,则在前面的lstm_cell之后接一个DropOut层,
#这里的做法是调用tf.contrib.rnn.DropoutWrapper函数if is_training and config.keep_prob < 1:def attn_cell():return tf.contrib.rnn.DropoutWrapper(lstm_cell(), output_keep_prob=config.keep_prob)
#最后使用rnn堆叠函数tf.contrib.rnn.MultiRNNCell将前面构造的lstm_cell
#多层堆叠得到cell#堆叠次数,为config中的num_layers.cell = tf.contrib.rnn.MultiRNNCell([attn_cell() for _ in range(config.num_layers)], state_is_tuple=True)#这里同样将state_is_tuple设置为True#并掉用cell.zero_state设置LSTM单元的初始化状态为0self._initial_state = cell.zero_state(batch_size, tf.float32)#这里需要注意,LSTM单元可以读入一个单词并结合之前存储的状态state计算下一个单词
#出现的概率,#并且每次读取一个单词后它的状态state会被更新#创建网络的词embedding部分,embedding即为将one-hot的编码格式的单词转化为向量
#的表达形式#这部分操作在GPU中实现with tf.device("/cpu:0"):#初始哈embedding矩阵,其行数设置词汇表数vocab_size,列数(每个单词的向量表达
#的维数)设为hidden_size#hidden_size和LSTM单元中的隐含节点数一致#在训练过程中,embedding的参数可以
#被优化和更新。embedding = tf.get_variable("embedding", [vocab_size, size], dtype=tf.float32)#接下来是使用tf.nn.embedding_lookup查询单词对应的向量表达获得inputsinputs = tf.nn.embedding_lookup(embedding, input_.input_data)#如果为训练状态,则添加一层Dropoutif is_training and config.keep_prob < 1:inputs = tf.nn.dropout(inputs, config.keep_prob)#Simplified version of models/tutorials/rnn/rnn.py's rnn().#This builds an unrolled LSTM for tutorial purposes only.#In general, use the rnn() or state_saving_rnn() from rnn.py.##The alternative version of the code below is:##inputs = tf.unstack(inputs, num=num_steps, axis=1)#outputs, state = tf.nn.rnn(cell, inputs,#initial_state=self._initial_state)#定义输出outputsoutputs = []state = self._initial_state#首先使用tf.variable_scope将接下来的名称设为RNNwith tf.variable_scope("RNN"):#为了控制训练过程,我们会限制梯度在反向传播时可以展开的步数为一个固定的值,而这个步#数也是num_steps#这里设置一个循环,长度为num_steps,来控制梯度的传播for time_step in range(num_steps):#并且从第二次循环开始,我们使用tf.get_variable_scope().reuse_variables()
#设置复用变量if time_step > 0: tf.get_variable_scope().reuse_variables()#每次循环内,我们传入inputs和state到堆叠的LSTM单元即(cell)中#注意,inputs有三个维度,第一个维度是batch中的低级个样本,#第二个维度代表是样本中的第几个单词,第三个维度是单词的向量表达的维度。#inputs[:, time_step, :]代表所有样板的第time_step个单词(cell_output, state) = cell(inputs[:, time_step, :], state)#这里我们得到输出cell_output和更新后的stateoutputs.append(cell_output)#最后我们将结果cell_output添加到输出列表ouputs中#将output的内容用tf.contact串联到一起,并使用tf.reshape将其转为一个很长的一维
#向量output = tf.reshape(tf.concat(outputs, 1), [-1, size])#接下来是softmax层,先定义权重softmax_w和偏置softmax_bsoftmax_w = tf.get_variable("softmax_w", [size, vocab_size], dtype=tf.float32)softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=tf.float32)#然后使用tf.matmul将输出output乘上权重并加上偏置得到logitslogits = tf.matmul(output, softmax_w) + softmax_b#这里直接使用tf.contrib.legacy_seq2seq.sequence_loss_by_example计算输出
#logits#和targets的偏差loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits],[tf.reshape(input_.targets, [-1])],[tf.ones([batch_size * num_steps], dtype=tf.float32)])#这里的sequence_loss即target words的averge negative log probability,self._cost = cost = tf.reduce_sum(loss) / batch_size#然后再使用tf.reduce_sum汇总batch的误差。self._final_state = stateif not is_training:return#如果此时不是训练状态,直接返回。#定义学习速率的变量lr,并将其设为不可训练self._lr = tf.Variable(0.0, trainable=False)#再使用tf.trainable_variables获取所有可训练的参数tvarstvars = tf.trainable_variables()#针对前面得到的cost,计算tvars的梯度,并用tf.clip_by_global_norm设置梯度的最
#大范数max_grad_normgrads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),config.max_grad_norm)#这即是Gradient Clipping的方法,控制梯度的最大范数,某种程度上起到正则化的效果。#Gradient Clipping可防止Gradient Explosion梯度爆炸的问题,如果对梯度不加限制,#则可能会因为迭代中梯度过大导致训练难以收敛#然后定义GradientDescent优化器optimizer = tf.train.GradientDescentOptimizer(self._lr)#再创建训练操作_train_op,用optimizer.apply_gradients将前面clip过的梯度应用
#到所有可训练的参数tvars上,#然后使用tf.contrib.framework.get_or_create_global_step()生成全局统一的训练
#步数self._train_op = optimizer.apply_gradients(zip(grads, tvars),global_step=tf.contrib.framework.get_or_create_global_step())#设置一个_new_lr的placeholder用以控制学习速率。self._new_lr = tf.placeholder(tf.float32, shape=[], name="new_learning_rate")#同时定义个assign_lr的函数,用以在外部控制模型的学习速率self._lr_update = tf.assign(self._lr, self._new_lr)#同时定义个assign_lr的函数,用以在外部控制模型的学习速率#方式是将学习速率值传入_new_lr这个place_holder,并执行_update_lr操作完成对学习速
#率的修改def assign_lr(self, session, lr_value):session.run(self._lr_update, feed_dict={self._new_lr: lr_value})#模型定义完毕,再定义定义这个PTBModel class的一些property#Python中的@property装饰器可以将返回变量设为只读,防止修改变量引发的问题#这里定义input,initial_state,cost,lr,final_state,train_op为property,方便外
#部访问@propertydef input(self):return self._input@propertydef initial_state(self):return self._initial_state@propertydef cost(self):return self._cost@propertydef final_state(self):return self._final_state@propertydef lr(self):return self._lr@propertydef train_op(self):return self._train_op#接下来定义几种不同大小的模型的参数
#首先是小模型的设置
class SmallConfig(object):"""Small config."""init_scale = 0.1 #网络中权重值的初始Scalelearning_rate = 1.0 #学习速率的初始值max_grad_norm = 5 #前面提到的梯度的最大范数num_layers = 2 #num_layers是LSTM可以堆叠的层数num_steps = 20 #是LSTM梯度反向传播的展开步数hidden_size = 200 #LSTM的隐含节点数max_epoch = 4 #是初始学习速率的可训练的epoch数,在此之后需要调整学习速率max_max_epoch = 13 #总共可以训练的epoch数keep_prob = 1.0 #keep_prob是dorpout层的保留节点的比例lr_decay = 0.5 #学习速率的衰减速率batch_size = 20 #每个batch中样板的数量vocab_size = 10000#具体每个参数的值,在不同的配置中对比才有意义#在中等模型中,我们减小了init_state,即希望权重初值不要过大,小一些有利于温和的训练
#学习速率和最大梯度范数不变,LSTM层数不变。
#这里将梯度反向传播的展开步数从20增大到35.
#hidden_size和max_max_epoch也相应地增大约3倍;同时,这里开始设置dropout的
#keep_prob到0.5
#而之前设置1,即没有dropout;
#因为学习迭代次数的增大,因此将学习速率的衰减速率lr_decay也减小了。
#batch_size和词汇表vocab_size的大小保持不变
class MediumConfig(object):"""Medium config."""init_scale = 0.05learning_rate = 1.0max_grad_norm = 5num_layers = 2num_steps = 35hidden_size = 650max_epoch = 6max_max_epoch = 39keep_prob = 0.5lr_decay = 0.8batch_size = 20vocab_size = 10000#大型模型,进一步缩小了init_scale并大大放宽了最大梯度范数max_grad_norm到10
#同时将hidden_size提升到了1500,并且max_epoch,max_max_epoch也相应增大了;
#而keep_drop也因为模型复杂度的上升继续下降,学习速率的衰减速率lr_decay也进一步减小
class LargeConfig(object):"""Large config."""init_scale = 0.04learning_rate = 1.0max_grad_norm = 10num_layers = 2num_steps = 35hidden_size = 1500max_epoch = 14max_max_epoch = 55keep_prob = 0.35lr_decay = 1 / 1.15batch_size = 20vocab_size = 10000#TstConfig只是测试用,参数都尽量使用最小值,只是为了测试可以完整允许模型
class TstConfig(object):"""Tiny config, for testing."""init_scale = 0.1learning_rate = 1.0max_grad_norm = 1num_layers = 1num_steps = 2hidden_size = 2max_epoch = 1max_max_epoch = 1keep_prob = 1.0lr_decay = 0.5batch_size = 20vocab_size = 10000#定义训练一个epoch数据的函数run_epoch。
def run_epoch(session, model, eval_op=None, verbose=False):"""Runs the model on the given data."""#记录当前时间,初始化损失costs和迭代数iters。start_time = time.time()costs = 0.0iters = 0state = session.run(model.initial_state)#并执行model.initial_state来初始化状态并获得初始状态#接着创建输出结果的字典表fetches#其中包括cost和final_statefetches = {"cost": model.cost,"final_state": model.final_state,}#如果有评测操作eval_op,也一并加入fetchesif eval_op is not None:fetches["eval_op"] = eval_op#接着进行循环训练中,次数为epoch_sizefor step in range(model.input.epoch_size):feed_dict = {}#在每次循环中,我们生成训练用的feed_dictfor i, (c, h) in enumerate(model.initial_state):feed_dict[c] = state[i].cfeed_dict[h] = state[i].h#将全部的LSTM单元的state加入feed_dict,然后传入feed_dict并执行#fetchees对网络进行一次训练,并且拿到cost和statevals = session.run(fetches, feed_dict)cost = vals["cost"]state = vals["final_state"]#我们累加cost到costs,并且累加num_steps到iters。costs += costiters += model.input.num_steps#我们每完成约10%的epoch,就进行一次结果的展示,依次展示当前epoch的进度,#perplexity(即平均cost的自然常数指数,语言模型性能的重要指标,越低代表模型输出的
#概率分布在预测样本上越好)#和训练速度(单词/s)if verbose and step % (model.input.epoch_size // 10) == 10:print("%.3f perplexity: %.3f speed: %.0f wps" %(step * 1.0 / model.input.epoch_size, np.exp(costs / iters),iters * model.input.batch_size / (time.time() - start_time)))#最后返回perplexity作为函数的结果return np.exp(costs / iters)#使用reader.ptb_raw_data直接读取解压后的数据,得到训练数据,验证数据和测试数据
raw_data = reader.ptb_raw_data('./simple-examples/data/')
train_data, valid_data, test_data, _ = raw_data#这里定义训练模型的配置为小型配置
config = SmallConfig()
eval_config = SmallConfig()
eval_config.batch_size = 1
eval_config.num_steps = 1
#需要注意的是测试配置eval_config需和训练配置一致
#这里将测试配置的batch_size和num_steps修改为1#创建默认的Graph,并使用tf.random_uniform_initializer设置参数的初始化器
with tf.Graph().as_default():initializer = tf.random_uniform_initializer(-config.init_scale,config.init_scale)with tf.name_scope("Train"):#使用PTBInput和PTBModel创建一个用来训练的模型mtrain_input = PTBInput(config=config, data=train_data, name="TrainInput")with tf.variable_scope("Model", reuse=None, initializer=initializer):m = PTBModel(is_training=True, config=config, input_=train_input)#tf.scalar_summary("Training Loss", m.cost)#tf.scalar_summary("Learning Rate", m.lr)with tf.name_scope("Valid"):#使用PTBInput和PTBModel创建一个用来验证的模型mvalidvalid_input = PTBInput(config=config, data=valid_data, name="ValidInput")with tf.variable_scope("Model", reuse=True, initializer=initializer):mvalid = PTBModel(is_training=False, config=config, input_=valid_input)#tf.scalar_summary("Validation Loss", mvalid.cost)with tf.name_scope("Tst"):#使用PTBInput和PTBModel创建一个用来验证的模型Tsttest_input = PTBInput(config=eval_config, data=test_data, name="TstInput")with tf.variable_scope("Model", reuse=True, initializer=initializer):mtst = PTBModel(is_training=False, config=eval_config,input_=test_input)#其中训练和验证模型直接使用前面的cofig,测试模型则使用前面的测试配置eval_configsv = tf.train.Supervisor()#使用tf.train.Supervisor创建训练的管理器sv#并使用sv.managed_session()创建默认的sessionwith sv.managed_session() as session:#再执行训练多个epoch数据的循环for i in range(config.max_max_epoch):#在每个epoch循环内,我们先计算累计的学习速率衰减值,#这里只需要计算超过max_epoch的轮数,再求lr_decay的超出轮数次幂即可#然后将初始学习速率乘以累计的衰减,并更新学习速率。lr_decay = config.lr_decay ** max(i + 1 - config.max_epoch, 0.0)m.assign_lr(session, config.learning_rate * lr_decay)#在循环内执行一个epoch的训练和验证,并输出当前的学习速率,训练和验证即的
#perplexityprint("Epoch: %d Learning rate: %.3f" % (i + 1, session.run(m.lr)))train_perplexity = run_epoch(session, m, eval_op=m.train_op,verbose=True)print("Epoch: %d Train Perplexity: %.3f" % (i + 1, train_perplexity))valid_perplexity = run_epoch(session, mvalid)print("Epoch: %d Valid Perplexity: %.3f" % (i + 1, valid_perplexity))#在完成全部训练之后,计算并输出模型在测试集上的perplexitytst_perplexity = run_epoch(session, mtst)print("Test Perplexity: %.3f" % tst_perplexity)##if FLAGS.save_path:# print("Saving model to %s." % FLAGS.save_path)# sv.saver.save(session, FLAGS.save_path, global_step=sv.global_step)if __name__ == "__main__":tf.app.run()
LSTM经常用来解决处理和预测序列化问题,下面要讲的Seq2Seq端到端神经网络就是基于LSTM的,当然Seq2Seq也不是必须基于LSTM,它也可以是基于CNN的。下面我们来看下Seq2Seq。
Seq2Seq端到端神经网络算法
下一篇文章分享Seq2Seq端到端神经网络算法,更多内容可参见
《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】书籍。
更多的技术交流和探讨也欢迎加我个人微信chenjinglei66。
总结
此文章有对应的配套新书教材和视频:
【配套新书教材】
《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:本书从自然语言处理基础开始,逐步深入各种NLP热点前沿技术,使用了Java和Python两门语言精心编排了大量代码实例,契合公司实际工作场景技能,侧重实战。
全书共分为19章,详细讲解中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注、文本相似度算法、语义相似度计算、词频-逆文档频率(TF-IDF)、条件随机场、新词发现与短语提取、搜索引擎Solr Cloud和Elasticsearch、Word2vec词向量模型、文本分类、文本聚类、关键词提取和文本摘要、自然语言模型(Language Model)、分布式深度学习实战等内容,同时配套完整实战项目,例如对话机器人实战、搜索引擎项目实战、推荐算法系统实战。
本书理论联系实践,深入浅出,知识点全面,通过阅读本书,读者不仅可以理解自然语言处理的知识,还能通过实战项目案例更好地将理论融入实际工作中。
《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:深入浅出,逐步讲解分布式机器学习的框架及应用配套个性化推荐算法系统、人脸识别、对话机器人等实战项目。
【配套视频】
推荐系统/智能问答/人脸识别实战 视频教程【陈敬雷】
视频特色:把目前互联网热门、前沿的项目实战汇聚一堂,通过真实的项目实战课程,让你快速成为算法总监、架构师、技术负责人!包含了推荐系统、智能问答、人脸识别等前沿的精品课程,下面分别介绍各个实战项目:
1、推荐算法系统实战
听完此课,可以实现一个完整的推荐系统!下面我们就从推荐系统的整体架构以及各个子系统的实现给大家深度解密来自一线大型互联网公司重量级的实战产品项目!
2、智能问答/对话机器人实战
由浅入深的给大家详细讲解对话机器人项目的原理以及代码实现、并在公司服务器上演示如何实际操作和部署的全过程!
3、人脸识别实战
从人脸识别原理、人脸识别应用场景、人脸检测与对齐、人脸识别比对、人脸年龄识别、人脸性别识别几个方向,从理论到源码实战、再到服务器操作给大家深度讲解!
自然语言处理NLP原理与实战 视频教程【陈敬雷】
视频特色:《自然语言处理NLP原理与实战》包含了互联网公司前沿的热门算法的核心原理,以及源码级别的应用操作实战,直接讲解自然语言处理的核心精髓部分,自然语言处理从业者或者转行自然语言处理者必听视频!
人工智能《分布式机器学习实战》 视频教程【陈敬雷】
视频特色:视频核心内容有互联网公司大数据和人工智能、大数据算法系统架构、大数据基础、Python编程、Java编程、Scala编程、Docker容器、Mahout分布式机器学习平台、Spark分布式机器学习平台、分布式深度学习框架和神经网络算法、自然语言处理算法、工业级完整系统实战(推荐算法系统实战、人脸识别实战、对话机器人实战)。
上一篇:自然语言处理系列六十二》神经网络算法》MLP多层感知机算法
下一篇:自然语言处理系列六十四》神经网络算法》Seq2Seq端到端神经网络算法
相关文章:
自然语言处理系列六十三》神经网络算法》LSTM长短期记忆神经网络算法
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列六十三神经网络算法》LSTM长短期记忆神经网络算…...

亚马逊IP关联及其解决方案
在电子商务领域,亚马逊作为全球领先的在线购物平台,吸引了众多商家和个人的参与。然而,随着业务规模的扩大,商家在使用亚马逊服务时可能会遇到IP关联的问题,这不仅影响账户的正常运营,还可能带来一系列不利…...

Definition and Detection of Defects in NFT Smart Contracts论文解读、复现
背景知识\定义 NFT 是数字或物理资产所有权的区块链表示。不仅限于数字图片,视频和画作等艺术品也可以转化为 NFT 进行交易。近年来受到广泛关注,2021 年 NFT 交易额达到约 410 亿美元。 智能合约 是在区块链上运行的图灵完备程序。支持各种去中心化…...
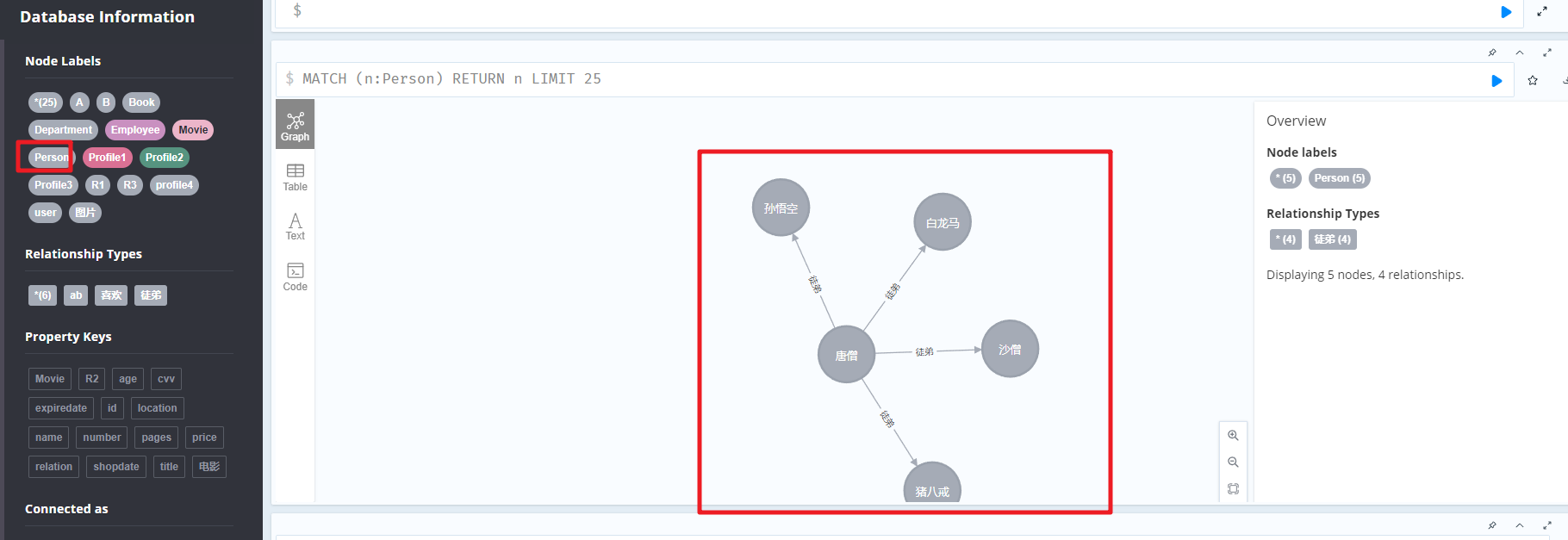
Neo4j图数据库
文章目录 一、Neo4J相关介绍1.为什么需要图数据库方案1:Google方案2:Facebook 2.特定和优势3.什么是Neo4j4.Neo4j数据模型图论基础属性图模型Neo4j的构建元素 5.软件安装 二、CQL语句1.CQL简介2.CREATE 命令3.MATCH 命令4.RETURN 子句5.MATCH和RETURN6.C…...

k8s API资源对象
API资源对象Deployment 最小的资源是pod,deployment是多个pod的集合(多个副本实现高可用、负载均衡等)。 使用yaml文件来配置、部署资源对象。 Deployment YAML示例: vi ng-deploy.yaml apiVersion: apps/v1 kind: Deployment…...

GB/T28181规范解读之编码规则详解
GB/T28181,即《安全防范视频监控联网系统信息传输、交换、控制技术要求》,是我国安防行业的重要标准之一。该标准详细规定了城市监控报警联网系统中信息传输、交换、控制的互联结构、通信协议结构,以及传输、交换、控制的基本要求和安全性要求…...

Vue封装的过度与动画(transition-group、animate.css)
目录 1. Vue封装的过度与动画1.1 动画效果11.2 动态效果21.3 使用第三方动画库animate.css 1. Vue封装的过度与动画 作用:在插入、更新或移除DOM元素时,在合适的时候给元素添加样式类名 1.1 动画效果1 Test1.vue: transition内部只能包含一个子标签。…...

免费云服务器申请教程
免费云服务器的申请流程通常包括以下几个步骤,但请注意,不同云服务提供商的具体步骤可能略有不同。以下是一个通用的申请流程: 一、选择合适的云服务提供商 首先,需要选择一家提供免费云服务器服务的云服务提供商。 免费云服务器汇…...

Spring Cloud Gateway中的常见配置
问题 最近用到了Spring Cloud Gateway,这里记录一下这个服务的常见配置。 spring:data:redis:host: ${REDIS_HOST:xxx.xxx.xxx.xxx}port: ${REDIS_PORT:2345wsd}password: ${REDIS_PASS:sdfsdfgh}database: ${REDIS_DB:8}session:redis:flush-mode: on_savenamespa…...
SelectDB 多计算集群核心设计要点揭秘与场景应用
需求起源 SelectDB 设计多计算集群架构初衷主要源于两类典型的使用场景: 写入与读取隔离:传统数仓架构中,数据的写入和读取在同一个计算集群,当遇到业务写入高峰期或突增的写入压力时,容易因资源相互抢占影响查询服务…...

Docker 清理和查看镜像与容器占用情况
查看容器占用磁盘大小 docker system df 查看单个image、container大小: docker system df -v 清理所有废弃镜像与Build Cache docker system prune -a...

如何在Android 12 aosp系统源码中添加三指下滑截图功能
如何在Android 12 aosp系统源码中添加三指下滑截图功能 系统中截图api非常简单: private static ScreenshotHelper sScreenshotHelper;sScreenshotHelper new ScreenshotHelper(mContext);//调用 sScreenshotHelper.takeScreenshot(WindowManager.TAKE_SCREENSHO…...

使用SQL语句查询MySQL数据表
6.1 创建单表基本查询 1.Select 语句的语法格式及其功能 (1)Select 语句的一般格式。 Select < 字段名称或表达式列表 > From < 数据表名称或视图名称 > [ Where < 条件表达式 > ] [ Group By < 分组的字段名称…...

【AI绘画、换脸、写作、办公】从零开始:使用AIStarter启动器发布AI应用
随着人工智能技术的快速发展,越来越多的开发者希望通过自己的创意来构建和分享AI应用。AIStarter启动器正是为此而设计的一个强大工具,它可以帮助开发者轻松打包并发布自己的AI应用项目。本文将详细介绍如何使用AIStarter启动器来实现这一目标。 注册账…...

eeprom使用 cubemx STM32F407ZGT6【IIC驱动AT24C02】
存储器的简单介绍 ROM(只读存储器)、RAM(随机存取存储器)、Flash(闪存)、和EEPROM(电可擦可编程只读存储器)是四种不同类型的存储介质。ROM用于存储固件或永久数据,不易…...

STL-stack/queue/deque(容器适配器)
目录 编辑 STL-stack 150. 逆波兰表达式求值 stack queue std::stack deque 性能测试 结构 STL-stack 栈的压入、弹出序列_牛客题霸_牛客网输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假。题目…...

NVDLA专题15:Runtime environment-核心模式驱动
核心模式驱动(Kernel Mode Driver) KMD主入口点在内存中接收一个推理作业,从多个可用的作业中选择要执行的作业(如果在多进程系统上),并将其提交给核心引擎调度程序。该核心引擎调度程序负责处理来自NVDLA的中断,调度每…...

计算机毕业设计选题推荐-班级管理系统-教务管理系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

推荐一款开源、高效、灵活的Redis桌面管理工具:Tiny RDM!支持调试与分析功能!
1、引言 在大数据和云计算快速发展的今天,Redis作为一款高性能的内存键值存储系统,在数据缓存、实时计算、消息队列等领域发挥着重要作用。然而,随着Redis集群规模的扩大和复杂度的增加,如何高效地管理和运维Redis数据库成为了许…...

Java项目: 基于SpringBoot+mybatis+maven新闻推荐系统(含源码+数据库+毕业论文)
一、项目简介 本项目是一套基于SpringBootmybatismaven新闻推荐系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、…...

如何在5分钟内为MASA模组全家桶安装中文汉化包:实用指南
如何在5分钟内为MASA模组全家桶安装中文汉化包:实用指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft中MASA模组的英文界面而烦恼吗?MASA模组…...

从芯片手册到PCB:SPL06与MPU9250的I2C实战布线要点与防护设计
从芯片手册到PCB:SPL06与MPU9250的I2C实战布线要点与防护设计 在无人机飞控板的设计中,气压传感器SPL06和九轴传感器MPU9250的稳定工作直接关系到飞行姿态控制的精确性。本文将深入探讨这两个关键传感器在PCB布局中的I2C总线设计要点,以及如何…...

模板 ID 配置化: “公众号路由 + 模板消息发送” 封装成一个干净的业务 Service
文章目录 引言 I “公众号路由 + 模板消息发送” 多公众号 同模板不同 ID 公众号实例 公众号路由 模板消息发送 Service(业务层 ✅) 异步调用 II 公众号账号配置【升级版】 账号配置 启用配置 模板 ID 解析器 公众号 Router(升级版 ✅) III 路由(Redis 版本) WxRedisOps…...

【技术剖析】AI-RPA 的“眼睛”:详解 DOM 树精简与 OmniParser 屏幕解析技术
引言:当 RPA 遇上 AI,谁来做机器的“眼睛”? 2026 年,AI 与 RPA 的融合正在经历一场深刻的技术重构。根据市场研究数据,AIRPA 全球市场规模预计从 2025 年的 47.9 亿美元增长至 2026 年的 56 亿美元,复合年…...

别再手动调了!用MATLAB的Text对象属性批量设置图表字体,效率提升90%
MATLAB科研绘图效率革命:Text对象属性批量操控指南 科研工作者常面临一个看似简单却极其耗时的任务——图表字体格式调整。当论文需要提交到不同期刊,每个期刊对图表字体、字号、颜色都有特定要求时,手动逐个修改轴标签、标题和图例的字体属性…...

如何用开源工具LibreDWG解决CAD文件格式兼容性问题?
如何用开源工具LibreDWG解决CAD文件格式兼容性问题? 【免费下载链接】libredwg Official mirror of libredwg. With CI hooks and nightly releases. PRs ok 项目地址: https://gitcode.com/gh_mirrors/li/libredwg 你是否曾遇到过不同CAD软件之间无法互相打…...

FreeRTOS-Plus-TCP vs LwIP:在GD32F450上如何选择?附LAN8720A驱动避坑指南
FreeRTOS-Plus-TCP与LwIP在GD32F450上的深度对比与实战选型指南 当工程师在资源受限的GD32F450平台上构建网络功能时,FreeRTOS-Plus-TCP和LwIP这两个轻量级TCP/IP协议栈往往成为主要候选。本文将基于实际项目经验,从内存占用、性能表现、开发效率等维度进…...

别再让脚本报错了!按键精灵CBool、CStr、CInt等6种类型转换函数保姆级教程
按键精灵类型转换实战指南:从报错到精通的六种武器 在自动化脚本开发的世界里,按键精灵就像一位不知疲倦的数字助手,能够代替我们完成各种重复性操作。但这位助手有时也会闹脾气——当你从网页抓取的数据需要计算时,当界面读取的…...

鸿蒙心理测评模块实战|PHQ-9/GAD7双量表答题、实时计分与结果本地化存储
一、前言 心晴驿站已正式稳定上架华为应用市场,所有专栏内容均基于线上真实版本复盘产出,所有逻辑、代码、优化方案均通过真机测试、性能校验、隐私合规审核,具备完整落地与参赛复用价值。 在前八篇专栏中,我们完成了项目整体架构…...

2026年主流行工具有何不同?subAgent是趋势还是营销?深度解析!
AI Coding工具中的“subAgent”正从营销词发展为工程抽象,实现上下文、权限、任务和执行的拆分管理。主流工具如Claude Code、Codex、OpenClaw、Gemini CLI均在强化subAgent能力,但设计哲学各异。文章从技术视角解析subAgent的本质、各工具异同及使用选择…...