RDD(弹性分布式数据集)总结
文章目录
- 一、设计背景
- 二、RDD概念
- 三、RDD特性
- 四、RDD之间的依赖关系
- 五、阶段的划分
- 六、RDD运行过程
- 七、RDD的实现
一、设计背景
1.某些应用场景中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。如:迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具。
2.目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。
虽然,类似Pregel等图计算框架也是将结果保存在内存当中,但是,这些框架只能支持一些特定的计算模式,并没有提供一种通用的数据抽象。
3.针对以上问题,Spark提出了一种新的数据抽象模式称为RDD(弹性分布式数据集),RDD是容错的并行的数据结构,并且可以让用户显式的将数据保存在内存中,并且可以控制他们的分区来优化数据替代以及提供了一系列高级的操作接口。
二、RDD概念
1.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
2.RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
3.RDD提供了一组丰富的操作以支持常见的数据运算,分为**“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式**,后者指定RDD之间的相互依赖关系。

4.两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
5.RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。
6.RDD采用了惰性调用,即在RDD的执行过程中(如下图所示),真正的计算发生在RDD的**“行动”操作**,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
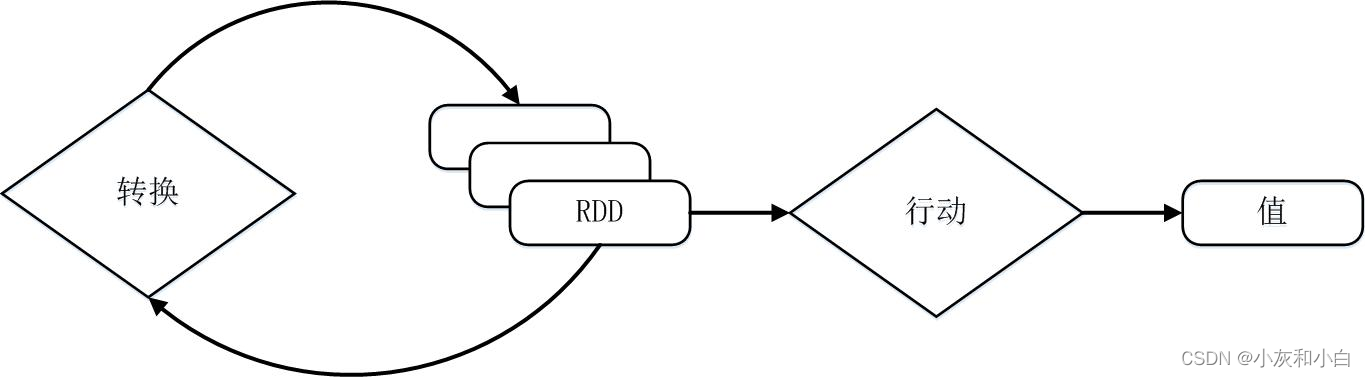
7.例子:
从输入中逻辑上生成A和C两个RDD,经过一系列“转换”操作,逻辑上生成了F(也是一个RDD),之所以说是逻辑上,是因为这时候计算并没有发生,Spark只是记录了RDD之间的生成和依赖关系。
当F要进行输出时,也就是当F进行“行动”操作的时候,Spark才会根据RDD的依赖关系生成DAG,并从起点开始真正的计算。
8.上述这一系列处理称为一个“血缘关系(Lineage),即DAG拓扑排序的结果。
采用惰性调用,通过血缘关系连接起来的一系列RDD操作就可以实现管道化(pipeline),因为这些具有血缘关系的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。
9.一个Spark的“Hello World”程序
val sc= new SparkContext(“spark://localhost:7077”,”Hello World”, “YOUR_SPARK_HOME”,”YOUR_APP_JAR”)
val fileRDD = sc.textFile(“hdfs://192.168.0.103:9000/examplefile”)
val filterRDD = fileRDD.filter(_.contains(“Hello World”))
filterRDD.cache()//表示对filterRDD进行持久化,把它保存在内存或磁盘中(这里采用cache接口把数据集保存在内存中),方便后续重复使用
filterRDD.count()
一个Spark应用程序,基本是基于RDD的一系列计算操作。
这个程序的执行过程如下:
- 创建这个Spark程序的执行上下文,即创建SparkContext对象;
- 从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
- 构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
- 执行到第5行代码时,count()是一个行动类型的操作,触发真正的计算,开始实际执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
三、RDD特性
1.总体而言,Spark采用RDD以后能够实现高效计算的主要原因如下:
(1)高效的容错性。
现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。
在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算得到丢失的分区来实现容错,无需回滚整个系统。
此外,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销。
(2)中间结果持久化到内存。
数据在内存中的多个RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销;
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化开销。
2.Memory Management
Spark为持久化存储RDD提供三种选择:
(1)内存存储反序列化的java对象;
(2)内存存储序列化的数据。
(3)磁盘存储方式。
第一种选择能够提供最快的性能,由于java虚拟机能够本地化获取RDD。另外一种选择能够让用户选择一个相对于空间受限的java对象图(UML图)而言更加具有内存效率的方法(无需组织java对象,仅仅是使用纯粹的数据对象),可是要以减少性能为代价。第三种方法对于过大而不能保存在RAM中的RDD是实用的。可是重计算会有消耗。
为了管理有限的内存。我们在RDDs的级别使用LRU回收策略。
(参考)
四、RDD之间的依赖关系
1.RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),下图展示了两种依赖之间的区别。
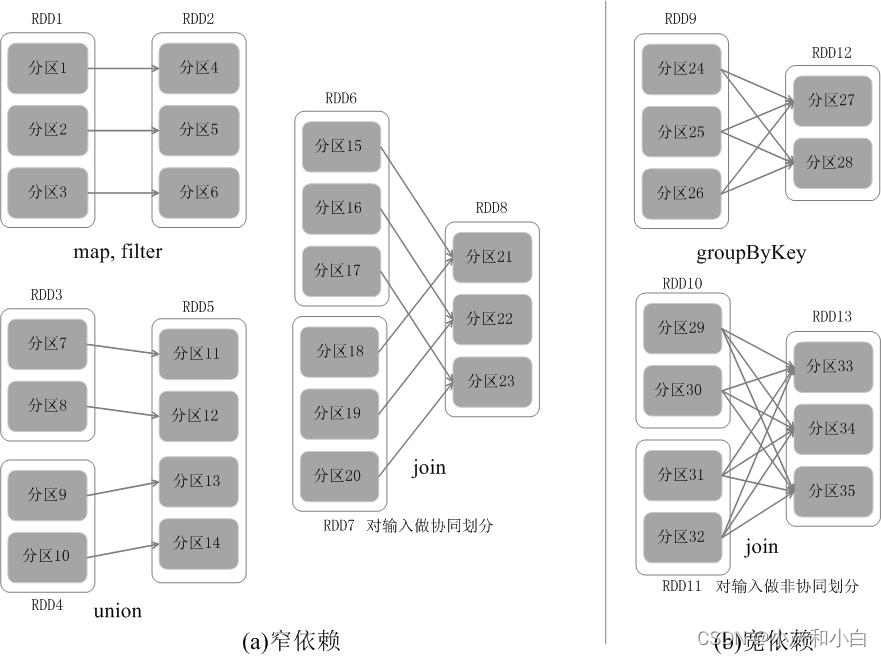
2.窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;(一父一子、多父一子,即每个父分区有一个出度)
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。(一父多子,每个父分区有多个出度)
3.相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。
而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。
4.此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
五、阶段的划分
1.具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
2.把一个DAG图划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集合(可以并行执行的任务集)。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给Executor运行。
六、RDD运行过程
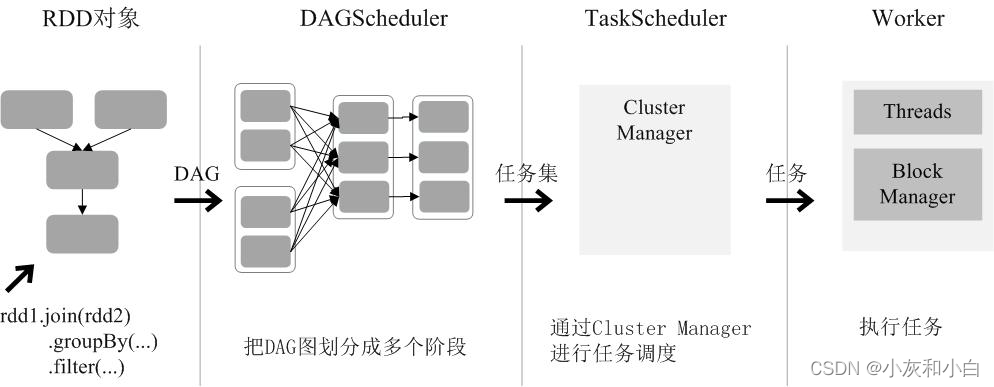
总结一下RDD在Spark架构中的运行过程(如下图所示):
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
七、RDD的实现
1.每个RDD都包含:(1)一组RDD分区(partition,即数据集的原子组成部分);(2)对父RDD的一组依赖,这些依赖描述了RDD的Lineage;(3)一个函数,即在父RDD上执行何种计算;(4)元数据,描述分区模式和数据存放的位置。

2.为什么RDD上需要携带METADATA?
因为依赖多个RDD的变换需要知道是否需要重新整理数据,宽依赖需要,窄依赖不需要。 同时也可以让用户控制更好的局部性和减少整理的工作量。
3.为什么要区分窄依赖和宽依赖?
为了防止失败,窄依赖可以很快的被重计算,掉1-2个PARITION就可以重计算。宽依赖需要一个完整的RDD才可以被重计算。
相关文章:
RDD(弹性分布式数据集)总结
文章目录一、设计背景二、RDD概念三、RDD特性四、RDD之间的依赖关系五、阶段的划分六、RDD运行过程七、RDD的实现一、设计背景 1.某些应用场景中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。如:迭代式算法…...

服务器版RstudioServer安装与配置详细教程
Docker部署Rstudio server 背景:如果您想在服务器上运行RstudioServer,可以按照如下方法进行操作,笔者测试时使用腾讯云服务器(系统centos7),需要在管理员权限下运行 Rstudio 官方提供了使用不同 R 版本的 …...

如何在Java中将一个列表拆分为多个较小的列表
在Java中,有多种方法可以将一个列表拆分为多个较小的列表。在本文中,我们将介绍三种不同的方法来实现这一目标。 方法一:使用List.subList()方法 List接口提供了一个subList()方法,它可以用来获取列表中的一部分元素。我们可以使…...

TryHackMe-Inferno(boot2root)
Inferno 现实生活中的机器CTF。该机器被设计为现实生活(也许不是?),非常适合刚开始渗透测试的新手 “在我们人生旅程的中途,我发现自己身处一片黑暗的森林中,因为直截了当的道路已经迷失了。我啊…...

微信原生开发中 JSON配置文件的作用 小程序中有几种JSON配制文件
关于json json是一种数据格式,在实际开发中,JSON总是以配制文件的形式出现,小程序与不例外,可对项目进行不同级别的配制。Q:小程序中有几种配制文件A:小程序中有四种配制文件分别是:project.config.json si…...

【python】为什么使用python Django开发网站这么火?
关注“测试开发自动化” 弓中皓,获取更多学习内容) Django 是一个基于 Python 的 Web 开发框架,它提供了许多工具和功能,使开发者可以更快地构建 Web 应用程序。以下是 Django 开发中的一些重要知识点: MTV 模式&#…...

Java设计模式(五)—— 责任链模式
责任链模式定义如下:使多个对象都有机会处理请求,从而避免请求的发送者与接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,知道有一个对象处理它为止。 适合使用责任链模式的情景如下: 有许多对…...

VMLogin:虚拟浏览器提供的那些亮眼的功能
像VMLogin这样的虚拟浏览器具有多种功能,如安全的浏览环境、可定制的设置、跨平台的兼容性、更快的浏览速度、广告拦截等等。 虚拟浏览器的不同功能可以为您做什么? 使用虚拟浏览器是浏览互联网和完成其他任务的安全方式,没有风险。您可以在…...

第一个错误的版本
题目 你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。 假设你有 n 个版本 [1, 2, …, n],你想找出…...

2023爱分析·AIGC市场厂商评估报告:拓尔思
AIGC市场定义 市场定义: AIGC,指利用自然语言处理技术(NLP)、深度神经网络技术(DNN)等人工智能技术,基于与人类交互所确定的主题,由AI算法模型完全自主、自动生成内容,…...

MobTech|场景唤醒的实现
什么是场景唤醒? 场景唤醒是moblink的一项核心功能,可以实现从打开的Web页面,一键唤醒App,并恢复对应的场景。 场景是指用户在App内的某个特定页面或状态,比如商品详情页、活动页、个人主页等。每个场景都有一个唯一…...
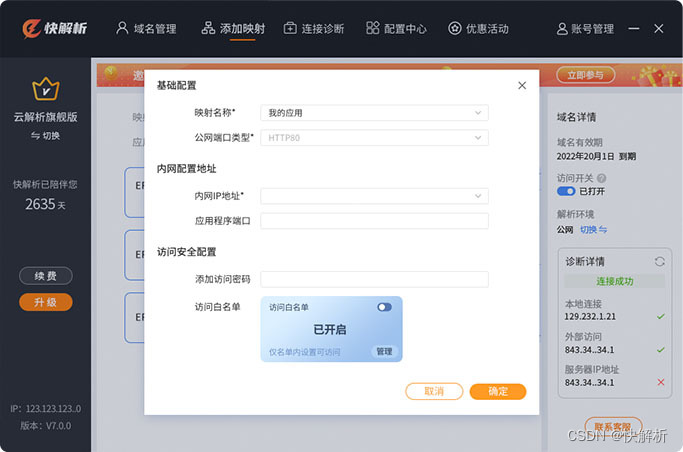
不在路由器上做端口映射,如何访问局域网内网站
假设现在外网有一台ADSL直接拨号上网的电脑,所获得的是公网IP。然后它想访问局域网内的电脑上面的网站,那么就需要在路由器上做端口映射。在路由器上做端口映射的具体规则是:将所有发向自己端口的数据,都转发到内网的计算机。 访…...

ChatGPT 辅助科研写作
前言 总结一些在科研写作中 ChatGPT 的功能,以助力提升科研写作的效率。 文章目录前言一、ChatGPT 简介1. ChatGPT 普通版与 Plus 版的区别1)普通账号2)Plus账号二、New Bing 简介1. 快速通过申请三、辅助学术写作1. 改写论文表述2. 语言润色…...
MySQL最大建议行数 2000w,靠谱吗?
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址 1 背景 作为在后端圈开车的多年…...
【Tomcat 学习】
Tomcat 学习 笔记记录一、Tomcat1. Tomcat目录2. Tomcat启动3. Tomcat部署项目4. 解决Tomcat启动乱码问题5. JavaWeb项目创建部署6. 打war包发布项目7. Tomcat配置文件8. Tomcat配置虚拟目录(不用在webapps目录下)9. Tomcat配置虚拟主机10. 修改web项目默认加载资源路径一、Tom…...

重装系统如何做到三步装机
小白三步版在给电脑重装系统的过程中,它会提供系统备份、还原和重装等多种功能。下面也将介绍小白三步版的主要功能,以及使用技巧和注意事项。 主要功能 系统备份和还原:小白三步版可以帮助用户备份系统和数据,以防止重要数据丢失…...

蓝桥杯单片机第十一届省赛客观题(深夜学习——单片机)
第一场 (1)模电——》多级放大电路 阻容耦合,只通交流,不通直流。 变压器耦合,只通交流,不通直流。 光电耦合,主要是起隔离作用,更多的用在非线性的应用电路中 (2&a…...

Pandas对Excel文件进行读取、增删、打开、保存等操作的代码实现
文章目录前言一、Pandas 的主要函数包括二、使用步骤1.简单示例2.保存Excel操作3.删除和添加数据4.添加新的表单总结前言 Pandas 是一种基于 NumPy 的开源数据分析工具,用于处理和分析大量数据。Pandas 模块提供了一组高效的工具,可以轻松地读取、处理和…...

js常见的9种报错记录一下
js常见报错语法错误(SyntaxError)类型错误(TypeError)引用错误(ReferenceError)范围错误(RangeError)运行时错误(RuntimeError)网络错误(NetworkError)内部错误(InternalError)URI错误(URIError)eval错误&a…...
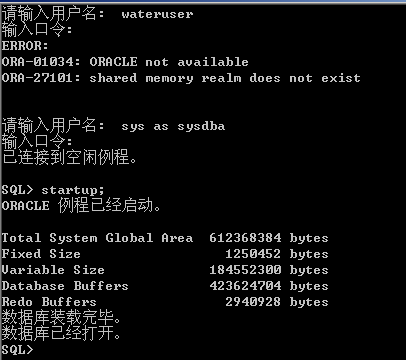
ORACLE not available报错处理办法
用sqlplus的时候 连接用户总是出现ORACLE not available 解决办法: 第一步: 请输入用户名: sys as sysdba 输入口令: 已连接到空闲例程。 第二步: 先连接到管理员用户下将用例开启 SQL> startup; ORACLE 例程已经启动。 然后就会出现一下 Total S…...

NotebookLM如何3分钟解析薛定谔方程?——物理学者私藏的7个Prompt工程技巧曝光
更多请点击: https://intelliparadigm.com 第一章:NotebookLM物理学研究辅助 NotebookLM 是 Google 推出的基于 LLM 的研究型笔记工具,专为学者与科研人员设计。在物理学研究中,它可高效整合 PDF 论文、实验日志、LaTeX 公式片段…...

深入RISC-V链接脚本:从.lds文件看C程序的内存‘出生’与‘搬家’全过程
深入RISC-V链接脚本:从.lds文件看C程序的内存‘出生’与‘搬家’全过程 在嵌入式开发的世界里,一个C程序从源代码到最终在硬件上运行,经历了编译、链接和加载三个关键阶段。这个过程就像一个人的生命历程:编译是"出生"&…...

从零构建安全配置管理系统:告别.env硬编码,拥抱分层加载与密钥安全
1. 项目概述与核心价值最近在整理一个老项目的代码库,发现里面充斥着各种硬编码的配置、散落在各处的API密钥,以及不同环境(开发、测试、生产)下互相冲突的数据库连接字符串。每次部署新环境,都得像寻宝一样࿰…...
)
濒危方言口述史抢救项目紧急启用NotebookLM的72小时部署方案(含田野录音→结构化叙事→GIS时空标注全流程)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM考古学研究辅助 NotebookLM 是 Google 推出的基于 LLM 的研究型笔记工具,其核心能力在于对用户上传的私有文档(如 PDF、TXT)进行语义索引与上下文感知问答…...

2026年国内GEO优化服务商盘点:6家主流选择的实际情况
说明: 本文盘点基于各服务商官网、公开媒体报道、可查询的工商信息整理,所有"案例数据"均来自服务商自我披露。GEO行业整体处于早期阶段,市场上自我标榜"行业第一""全球最强"的说法普遍存在,本文尽…...
数字化架构的演进和治理(附下载方式))
(122页PPT)数字化架构的演进和治理(附下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接 https://download.csdn.net/download/2501_92796370/92683865 资料解读:(122 页 PPT)数字化架构的演进和治理 详细资料请看本解读文章的最后内容 在数字化转…...

小学生如何高效通过GESP七八级
GESP 7-8级是通往信息学竞赛复赛的关键跳板,对小学生而言,需结合科学规划、系统学习与真题实战。以下是高效通关路径: 一、明确目标:GESP 7-8级的核心价值 1、GESP C 7级 ≥80分 或 8级 ≥60分 → 可免CSP-J初赛&…...
BallonsTranslator:3分钟搞定漫画翻译的终极AI辅助工具
BallonsTranslator:3分钟搞定漫画翻译的终极AI辅助工具 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning 项目地址: https…...

将taotoken集成到自动化工作流中提升内容生成效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将taotoken集成到自动化工作流中提升内容生成效率 对于内容创作或社交媒体运营团队而言,保持高质量内容的持续输出是一…...

从手机充电到车载电源:TVS管在消费电子和汽车电子中的实战应用避坑
从手机充电到车载电源:TVS管在消费电子和汽车电子中的实战应用避坑 当你的手机充电器在插拔瞬间冒出火花,或是汽车点火时中控屏幕突然黑屏,背后往往隐藏着一个共同的电子防护难题——瞬态电压冲击。TVS管(瞬态电压抑制二极管&…...