Pandas对Excel文件进行读取、增删、打开、保存等操作的代码实现
文章目录
- 前言
- 一、Pandas 的主要函数包括
- 二、使用步骤
- 1.简单示例
- 2.保存Excel操作
- 3.删除和添加数据
- 4.添加新的表单
- 总结
前言
Pandas 是一种基于 NumPy 的开源数据分析工具,用于处理和分析大量数据。Pandas 模块提供了一组高效的工具,可以轻松地读取、处理和分析各种类型的数据,包括 CSV、Excel、SQL 数据库、JSON 等格式的数据。
一、Pandas 的主要函数包括
pd.read_csv() / pd.read_excel() / pd.read_sql() 等:读取不同格式的数据文件或 SQL 数据库的数据。
DataFrame():创建数据框。
df.head() / df.tail():查看数据框的前几行或后几行。
df.info():查看数据框的基本信息。
df.describe():查看数据框的统计信息。
df.drop():删除数据框的行或列。
df.rename():重命名数据框的行或列。
df.sort_values():按照指定列排序数据框。
df.groupby():按照指定列分组数据框。
df.apply():对指定列应用函数。
pd.concat():合并数据框。
pd.merge():合并数据框的数据。
df.to_csv() / df.to_excel() / df.to_sql() 等:将数据框保存到不同格式的数据文件或 SQL 数据库中。
以上是 Pandas 的一些常用函数,这些函数使得数据的读取、处理和分析变得更加方便和高效。
二、使用步骤
1.简单示例
下面是 Pandas 对 Excel 文件进行读取、增删、打开、保存等操作的代码实现:
import pandas as pd# 读取 Excel 文件
df = pd.read_excel('example.xlsx', sheet_name='Sheet1')# 查看数据
print(df)# 增加一列数据
df['New Column'] = [1, 2, 3, 4, 5]# 删除一列数据
df = df.drop('New Column', axis=1)# 打开 Excel 文件
with pd.ExcelWriter('example.xlsx') as writer:df.to_excel(writer, sheet_name='Sheet1', index=False)
上述代码中,我们首先使用 pd.read_excel() 函数读取名为 example.xlsx 的 Excel 文件的 Sheet1 工作表,并将其存储在 df 变量中。接着,我们使用 print() 函数查看数据。
接下来,我们使用 df[‘New Column’] = [1, 2, 3, 4, 5] 增加一列新数据,表示新列的数据分别为 1、2、3、4 和 5。然后,我们使用 df = df.drop(‘New Column’, axis=1) 删除刚刚增加的一列数据。
最后,我们使用 pd.ExcelWriter() 函数打开 Excel 文件,然后使用 df.to_excel() 函数将数据写入名为 example.xlsx 的工作表 Sheet1 中,并将索引列排除在外。
2.保存Excel操作
Pandas 可以通过 to_excel() 函数将数据框保存到 Excel 文件中。下面是一个示例代码,演示如何将数据框保存到 Excel 文件中:
import pandas as pd# 创建数据框
data = {'Name': ['Tom', 'Jerry', 'Mickey', 'Donald'],'Age': [20, 25, 22, 28],'Gender': ['M', 'M', 'M', 'M']}
df = pd.DataFrame(data)# 保存数据框到 Excel 文件
df.to_excel('example.xlsx', index=False)
在上述代码中,我们首先创建了一个包含姓名、年龄和性别信息的数据字典 data,然后使用 pd.DataFrame() 函数将其转换为数据框 df。最后,我们使用 df.to_excel() 函数将数据框保存到名为 example.xlsx 的 Excel 文件中,并将索引列排除在外。
在 to_excel() 函数中,我们可以设置一些参数来控制保存的格式和内容,例如:
sheet_name:指定要保存的工作表名称。
header:设置是否包含表头行,可以设置为 True 或 False。
index:设置是否包含索引列,可以设置为 True 或 False。
startrow 和 startcol:设置数据框的起始行和列。
float_format:设置浮点数的输出格式。
encoding:设置保存文件时使用的编码格式。
需要注意的是,在使用 to_excel() 函数保存数据框到 Excel 文件时,需要安装相应的依赖库 openpyxl 或 xlsxwriter。如果没有安装这些依赖库,可以使用以下命令安装:
pip install openpyxl
pip install xlsxwriter
安装完依赖库之后,就可以正常地将数据框保存到 Excel 文件中了。
3.删除和添加数据
在 Pandas 中,可以使用 drop() 函数删除数据框中的一行或一列数据,使用 append() 函数添加一行或一列新的数据。下面是示例代码,演示如何删除一行或一列数据以及添加一行或一列新的数据:
import pandas as pd# 创建数据框
data = {'Name': ['Tom', 'Jerry', 'Mickey', 'Donald'],'Age': [20, 25, 22, 28],'Gender': ['M', 'M', 'M', 'M']}
df = pd.DataFrame(data)# 删除一行数据
df = df.drop(0) # 删除第一行数据
print(df)# 删除一列数据
df = df.drop('Gender', axis=1) # 删除“Gender”列
print(df)# 添加一行新数据
new_data = {'Name': 'Daisy', 'Age': 24, 'Gender': 'F'}
df = df.append(new_data, ignore_index=True) # 添加一行新数据
print(df)# 添加一列新数据
new_column = ['A', 'B', 'C', 'D']
df['NewColumn'] = new_column # 添加一列新数据
print(df)
在上述代码中,我们首先创建了一个包含姓名、年龄和性别信息的数据字典 data,然后使用 pd.DataFrame() 函数将其转换为数据框 df。接着,我们使用 drop() 函数删除了第一行数据和“Gender”列,并使用 append() 函数添加了一行新数据和一列新数据。最后,我们打印出修改后的数据框。
在 drop() 函数中,我们需要指定要删除的行或列的标签,并设置参数 axis=0 表示删除行,设置 axis=1 表示删除列。
在 append() 函数中,我们需要指定要添加的新数据,可以是字典、列表或数据框。参数 ignore_index=True 表示忽略原始数据框的索引,并为新添加的行分配新的索引值。
添加新列时,我们可以直接为数据框 df 新建一个列,并将新数据赋值给这个列即可。需要注意的是,新数据的长度必须与数据框的行数相同。
4.添加新的表单
在 Pandas 中,可以使用 ExcelWriter() 对象来向 Excel 文件中添加新的表单。下面是示例代码,演示如何向 Excel 文件中添加新的表单:
import pandas as pd# 读取 Excel 文件
excel_file = pd.ExcelFile('example.xlsx')# 创建 ExcelWriter 对象
writer = pd.ExcelWriter('example.xlsx', engine='openpyxl')# 读取原始数据表单
df = pd.read_excel(excel_file, sheet_name='Sheet1')# 添加新表单
new_data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35]}
df_new = pd.DataFrame(new_data)
df_new.to_excel(writer, sheet_name='Sheet2', index=False)# 保存 Excel 文件
writer.save()
在上述代码中,我们首先使用 ExcelFile() 函数读取了一个名为 example.xlsx 的 Excel 文件。接着,我们使用 ExcelWriter() 函数创建了一个名为 writer 的 ExcelWriter 对象,用于向 Excel 文件中添加新的表单。然后,我们使用 read_excel() 函数读取了原始数据表单,并将其存储在数据框 df 中。接着,我们创建了一个包含姓名和年龄信息的数据字典 new_data,并使用 pd.DataFrame() 函数将其转换为数据框 df_new。然后,我们使用 to_excel() 函数将数据框 df_new 写入到名为 Sheet2 的新表单中,并设置参数 index=False 表示不将索引写入 Excel 文件。最后,我们使用 save() 函数保存 Excel 文件。
需要注意的是,在使用 ExcelWriter() 对象向 Excel 文件中添加新的表单时,需要指定参数 engine=‘openpyxl’,以使用 openpyxl 引擎来处理 Excel 文件。同时,在使用 to_excel() 函数写入数据时,需要传递 ExcelWriter 对象和新表单的名称。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了pandas对excel文档的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。希望对看到的小伙伴有帮助。
相关文章:

Pandas对Excel文件进行读取、增删、打开、保存等操作的代码实现
文章目录前言一、Pandas 的主要函数包括二、使用步骤1.简单示例2.保存Excel操作3.删除和添加数据4.添加新的表单总结前言 Pandas 是一种基于 NumPy 的开源数据分析工具,用于处理和分析大量数据。Pandas 模块提供了一组高效的工具,可以轻松地读取、处理和…...

js常见的9种报错记录一下
js常见报错语法错误(SyntaxError)类型错误(TypeError)引用错误(ReferenceError)范围错误(RangeError)运行时错误(RuntimeError)网络错误(NetworkError)内部错误(InternalError)URI错误(URIError)eval错误&a…...
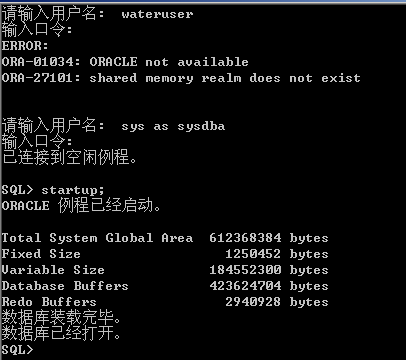
ORACLE not available报错处理办法
用sqlplus的时候 连接用户总是出现ORACLE not available 解决办法: 第一步: 请输入用户名: sys as sysdba 输入口令: 已连接到空闲例程。 第二步: 先连接到管理员用户下将用例开启 SQL> startup; ORACLE 例程已经启动。 然后就会出现一下 Total S…...

【Pandas】Python中None、null和NaN
经常混淆。 空值一般表示数据未知、不适用或将在以后添加数据。缺失值指数据集中某个或某些属性的值是不完整的。 一般空值使用None表示,缺失值使用NaN表示。 注意: python中没有null,但是有和其意义相近的None。 目录 1、None 2. NaN …...

线性表的学习
线性表定义 n个类型相同数据元素的有限序列,记作:a0,a1,a2,a3,...ai-1,ai,ai1...an-1(这里的0,1,2,3,i-1,i,i1,n-1都是元素的序号) 特点 除第一个元素无直接前驱。最后一个元素无直接后续&am…...
51单片机学习笔记_13 ADC
ADC 使得调节开发板上的电位器时,数码管上能够显示 AD 模块 采集电位器的电压值且随之变化。 开发板上有三个应用:光敏电阻,热敏电阻,电位器。 一般 AD 转换有多个输入,提高使用效率。 ADC 通过地址锁存与译码判断采…...

类和对象的基本认识之内部类
什么是内部类?当一个事物的内部,还有一个部分需要一个完整的结构进行描述,而这个内部的完整的结构又只为外部事物提供服 务,那么这个内部的完整结构最好使用内部类。在 Java 中,可以将一个类定义在另一个类或者一个方法…...
【操作系统】进程和线程是什么之间是如何通信的
文章目录1、进程1.1、什么是进程1.2、进程的状态1.3、进程的控制结构1.4、进程的控制1.5、进程的上下文切换1.6、进程上下文切换场景1.7、进程间通信2、线程2.1、什么是线程2.2、线程的上下文切换2.3、线程间通信3、线程与进程的联系1、进程 1.1、什么是进程 进程(process) 是…...

setup、ref、reactive、computed
setup 理解:Vue3.0 中一个新的配置项,值为一个函数 setup 是所有 Composition API(组合API)“表演的舞台” 组件中所用到的数据、方法等,均要配置在 setup 中 setup 函数的两种返回值: 若返回一个对象…...

【Gem5】有关gem5模拟器的资料导航
网上有关gem5模拟器的资料、博客良莠不齐,这里记录一些总结的很好的博客与自己的学习探索。 一、gem5模拟器使用入门 官方的教程: learning_gem5:包括gem5简介、修改扩展gem5的示例、Ruby相关的缓存一致性等。gem5 Documentation࿱…...
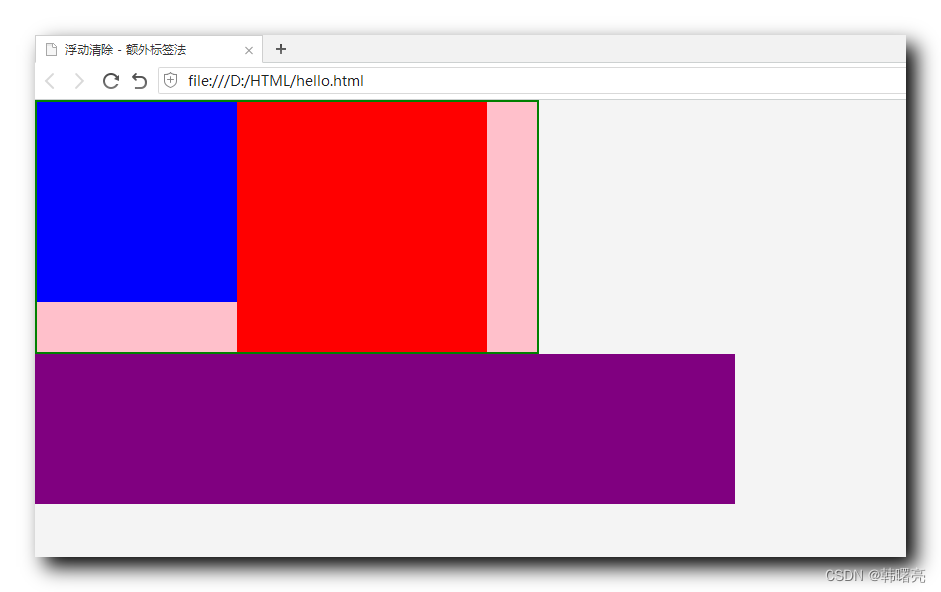
【CSS】清除浮动 ① ( 清除浮动简介 | 清除浮动语法 | 清除浮动 - 额外标签法 )
文章目录一、清除浮动简介二、清除浮动语法三、清除浮动 - 额外标签法1、额外标签法 - 语法说明2、问题代码示例3、额外标签法代码示例一、清除浮动简介 在开发页面时 , 遇到下面的情况 , 父容器 没有设置 内容高度 样式 , 容器中的 子元素 设置了 浮动样式 , 脱离了标准流 , …...

Shell test 命令
文章目录Shell test 命令数值测试字符串测试文件测试Shell test 命令 Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。 数值测试 参数说明-eq等于则为真-ne不等于则为真-gt大于则为真-ge大于等于则为真-lt小于则为真-le…...

pytorch项目实战之实时人脸属性检测系统
简介 本项目采用CelebA人脸属性数据集训练人脸属性分类模型,使用mediapipe进行人脸检测,使用onnxruntime进行模型的推理,最终在intel的奔腾cpu上实现30-100帧完整的实时人脸属性识别系统。 ps:本来是打算写成付费专栏的,毕竟这是…...

JS和Jquery
js函数 function 方法名(参数){ 方法体 return 返回值; } js事件 事件介绍 事件指的就是当某些组件执行了某些操作后,会触发某些代码的执行 onload 某个页面或图像被完成加载 onsubmit 当表单提交时触发事件 onclick 鼠标单击事件…...

Linux设置固定IP
vi /etc/sysconfig/network-scripts/ifcfg-ens33 第一个修改是开启网络 修改完成后重启网络服务 sudo service network restart 然后就可以看到ip 地址了 然后我们开始修改固定IP 主要是下图中的两部分 BOOTPROTO从dhcp改为static HWADD好像改不改都行,我改了&…...

面试准备啊
fail fast 是把数组原来的更改次数记住 每次都去比较 变了 就抛异常 如果数组容量没到64 会先扩容 再树化 缺点:全是偶数 hash分布不均匀 质数比较好(二次哈希也不需要) 效率好 2的n次幂 使用内存屏障解决指令重排序 第一次扩容和之后的不…...
机器人工程专业师生的第二张名片
课堂上多次提及第二张名片。什么是CatGPT-使用效果如何-专业感性非理性总结如下:机器人工程的工作与考研之困惑→汇总篇←其中包括:☞ 机器人工程的工作与考研之困惑“卷”☞ 机器人工程的工作与考研之困惑“歧视”☞ 机器人工程的工作与考研之困惑“取舍…...

【云原生之企业级容器技术 Docker实战一】Docker 介绍
目录一、Docker 介绍1.1 容器历史1.2 Docker 是什么1.3 Docker 和虚拟机,物理主机1.4 Docker 的组成1.5 Namespace1.6 Control groups1.7 容器管理工具1.8 Docker 的优势1.9 Docker 的缺点1.10 容器的相关技术1.10.1 容器规范1.10.2 容器 runtime1.10.3 容器管理工具…...
【Microsoft】与 Bing AI 进行 ⌈狂飙⌋
🎊 今天是3月8号,❤️农历二月十七,💕祝广大女同胞们👩女神节快乐🎉!——以创作之名致敬女性开发者文章目录序言Ⅰ、Bing AI初体验Ⅱ、代码生成Ⅲ、生成图像Ⅳ、使用次数Ⅴ、总结序言 近期&…...

PyDolphinScheduler发布4.0.2版本,修复无法提交工作流到DolphinScheduler 3.1.4的问题
点击蓝字 关注我们PyDolphinScheduler 正式发布 4.0.2 版本,主要修复了 4.0.1 版本无法提交工作流到 Apache DolphinScheduler 3.1.4 的问题。除此之外,PyDolphinScheduler 4.0.2 较大的优化还包括:PyDolphinScheduler 校验 Apache DolphinSc…...

基于龙芯2K1000LA的可信计算在工业边缘安全中的实践
1. 项目概述:当“可信计算”遇上工业边缘 最近在做一个工业数据采集与边缘处理的项目,客户对数据安全的要求提到了前所未有的高度。他们不仅担心数据在传输过程中被窃取,更担心边缘设备本身被恶意篡改,导致采集的数据在源头就“失…...

PlantUML Editor:用代码思维重塑UML绘图的现代工具
PlantUML Editor:用代码思维重塑UML绘图的现代工具 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 你是否厌倦了传统拖拽式UML工具的繁琐操作?PlantUML Editor将彻…...

从EGO-Planner到集群协同:分布式轨迹优化在无人机编队中的应用
1. 项目概述:从单机到集群的自主飞行进化如果你玩过无人机,或者关注过机器人领域,大概会知道让一台机器在空中自主规划路径、避开障碍物已经是个不小的挑战。那么,想象一下,让一群无人机像鸟群一样,在复杂、…...

STEMMA继电器模块实战指南:安全连接微控制器与强电设备
1. 项目概述:从微控制器到物理世界的开关如果你玩过Arduino或者树莓派,肯定有过这样的想法:能不能用我写的几行代码,去控制一下家里的台灯、风扇,甚至是鱼缸的氧气泵?这个想法背后,其实是一个经…...

微软UFO项目:基于视觉大模型的GUI自动化智能体实战解析
1. 项目概述:当“全能”AI助手遇见复杂任务编排 最近在AI应用开发圈里,一个来自微软研究院的项目“UFO”引起了我的注意。这名字听起来挺科幻,全称是“UI-Focused Agent”,直译过来是“专注于用户界面的智能体”。但别被这个直白的…...

Arm DSTREAM调试接口设计与JTAG/SWD协议详解
1. Arm DSTREAM系统与调试接口设计指南1.1 调试接口技术基础1.1.1 JTAG协议架构解析JTAG(Joint Test Action Group)标准IEEE 1149.1定义了五线制调试接口:TCK:测试时钟,同步所有JTAG操作TMS:测试模式选择&a…...
)
文档版本混乱、变更无通知、示例代码过期?Perplexity DevDocs监控体系搭建指南(含GitHub Action自动告警模板)
更多请点击: https://intelliparadigm.com 第一章:文档版本混乱、变更无通知、示例代码过期?Perplexity DevDocs监控体系搭建指南(含GitHub Action自动告警模板) 核心痛点与监控目标 现代开发者文档(如 P…...

用Adafruit MONSTER M4SK改造Boglin玩具:赋予经典怪物互动电子眼
1. 项目概述:当经典玩具遇上开源硬件如果你和我一样,对上世纪80年代那些造型古怪、充满想象力的玩具情有独钟,同时又是个喜欢动手折腾的创客,那么这个项目绝对能让你兴奋起来。今天我们要聊的,是如何让一个几乎被遗忘的…...
Transformer与NLP资源全指南:从原理到工程实践的高效学习路径
1. 项目概述:为什么我们需要一个Transformer与NLP的“Awesome”清单?如果你在过去几年里深度参与过自然语言处理(NLP)领域的工作或学习,那么“Transformer”这个词对你来说,可能已经从一种新颖的架构&#…...

DataCleaner终极指南:免费开源的数据质量分析神器
DataCleaner终极指南:免费开源的数据质量分析神器 【免费下载链接】DataCleaner The premier open source Data Quality solution 项目地址: https://gitcode.com/gh_mirrors/dat/DataCleaner DataCleaner是一款功能强大的开源数据质量解决方案,专…...