数据结构(2)单向链表排序和双向链表操作
一单向链表的插入排序
void insertion_sort_link(link_t* plink)
{ // 如果链表头为空,直接返回 if(NULL == plink->phead) { return; } // 初始化指针,p指向当前已排序部分的最后一个节点 node_t* p = plink->phead; // ptemp指向待插入的下一个节点 node_t* ptemp = plink->phead->pnext; // 将当前已排序部分的最后一个节点的下一个指针设为NULL p->pnext = NULL; node_t* pinsert = NULL; // 用于指向待插入的节点 // 遍历待插入的节点 while(ptemp) { pinsert = ptemp; // 将待插入节点指向ptemp ptemp = ptemp->pnext; // 移动ptemp到下一个节点 // 如果待插入节点的值小于当前已排序部分的头节点的值 if(pinsert->data < p->data) { // 将待插入节点插入到链表头部 pinsert->pnext = plink->phead; plink->phead = pinsert; } else { // 找到待插入节点应该插入的位置 while(p->pnext != NULL && p->pnext->data < pinsert->data) { p = p->pnext; // 移动p到下一个节点 } // 插入待插入节点 pinsert->pnext = p->pnext; // 将待插入节点的下一个指针指向p的下一个节点 p->pnext = pinsert; // 将p的下一个指针指向待插入节点 } } return; // 排序完成,返回
}快慢指针
快慢指针是一种常用的算法技巧,通常用于链表中,以解决一些特定的问题,比如寻找链表的中间节点、检测链表是否有环等。以下是快慢指针的基本概念和示例代码。
概念
- 慢指针(slow pointer):每次移动一步。
- 快指针(fast pointer):每次移动两步。
通过这种方式,快指针和慢指针的相对速度可以帮助我们在链表中找到特定的节点或判断某些条件。
示例:寻找链表的倒数第K个节点
node_t * countdown_k(link_t* plink, int key)
{ node_t *pfast = plink->phead; // 快指针初始化为链表头 if (NULL == pfast) { return NULL; // 如果链表为空,返回NULL } node_t *pslow = pfast; // 慢指针初始化为链表头 // 将快指针向前移动key个节点 for (int i = 0; i < key; ++i) { if (NULL == pfast) { return NULL; // 如果在移动过程中快指针变为NULL,返回NULL } pfast = pfast->pnext; // 快指针移动到下一个节点 } // 同时移动快指针和慢指针,直到快指针到达链表末尾 while (pfast) { pfast = pfast->pnext; // 快指针移动到下一个节点 pslow = pslow->pnext; // 慢指针也移动到下一个节点 } // 当快指针到达链表末尾时,慢指针指向的就是倒数第key个节点 return pslow; // 返回倒数第key个节点
}二、双向链表
双向链表是一种链表数据结构,其中每个节点都有两个指针:一个指向下一个节点(next),另一个指向前一个节点(prev)。这种结构使得在链表中进行插入和删除操作更加灵活,因为可以在 O(1) 的时间复杂度内访问前一个节点。
链表结构:
typedef struct node
{ datatype data; // 节点存储的数据 struct node *ppre; // 指向前一个节点的指针 struct node *pnext; // 指向下一个节点的指针
} dnode_t;双向链表和单向链表的区别
双向链表和单向链表是两种常见的数据结构,它们在结构、操作和使用场景上有显著的区别。以下是它们的主要区别和适用场景:
1. 结构区别
-
单向链表:
- 每个节点包含两个部分:数据部分和指向下一个节点的指针(next)。
- 只能从头到尾遍历链表,无法反向遍历。
-
双向链表:
- 每个节点包含三个部分:数据部分、指向下一个节点的指针(next)和指向前一个节点的指针(prev)。
- 可以从头到尾和从尾到头双向遍历。
2. 操作区别
-
插入和删除:
- 单向链表: 在插入或删除节点时,需要找到前一个节点(需要遍历),操作相对复杂。
- 双向链表: 可以直接访问前一个节点,插入和删除操作更为高效。
-
内存使用:
- 单向链表: 每个节点只需存储一个指针,内存占用较小。
- 双向链表: 每个节点需要存储两个指针,内存占用较大。
3. 使用场景
-
单向链表:
- 适用于只需要单向遍历的场景,如实现简单的队列、栈等。
- 当内存使用是一个重要考虑因素时,单向链表更为合适。
-
双向链表:
- 适用于需要频繁插入和删除操作的场景,如实现双向队列、LRU缓存等。
- 当需要频繁反向遍历链表时,双向链表更为高效。
4. 性能比较
- 时间复杂度:
- 插入和删除操作在单向链表中通常需要O(n)的时间复杂度(需要遍历找到前一个节点),而在双向链表中可以在O(1)的时间内完成(直接访问前后节点)。
- 空间复杂度:
- 单向链表的空间复杂度为O(n),双向链表的空间复杂度也是O(n),但由于双向链表每个节点需要额外的指针,实际内存占用更高。
双向链表的基本操作:
// 创建双向链表
dlink_t* create_dlink() { dlink_t * dlink = malloc(sizeof(dlink_t)); // 分配内存 if (NULL == dlink) { return NULL; // 内存分配失败 } dlink->phead = NULL; // 初始化头指针为空 dlink->clen = 0; // 初始化节点计数为0 pthread_mutex_init(&(dlink->mutex), NULL); // 初始化互斥锁 return dlink; // 返回新创建的链表
} // 检查链表是否为空
int is_empty_dlink(dlink_t * pdlink) { return NULL == pdlink->phead; // 如果头指针为空,则链表为空
} // 在链表头部插入节点
int push_into_dlink_head(dlink_t* pdlink, datatype data) { dnode_t * pnode = malloc(sizeof(dnode_t)); // 分配新节点内存 if (NULL == pnode) { return -1; // 内存分配失败 } pnode->data = data; // 设置节点数据 pnode->ppre = NULL; // 新节点的前指针为空 pnode->pnext = NULL; // 新节点的后指针为空 if (is_empty_dlink(pdlink)) { // 如果链表为空 pdlink->phead = pnode; // 将新节点设置为头节点 } else { // 如果链表不为空 pnode->pnext = pdlink->phead; // 新节点的后指针指向当前头节点 pdlink->phead->ppre = pnode; // 当前头节点的前指针指向新节点 pdlink->phead = pnode; // 更新头指针为新节点 } pdlink->clen++; // 增加节点计数 return 0; // 插入成功
} // 打印链表
int print_link(dlink_t * pdlink, int dir) { dnode_t* p = pdlink->phead; // 从头节点开始 if (NULL == p) { return -1; // 如果链表为空,返回错误 } if (dir) { // 正向打印 while (p) { printf("id:%d,name:%s,score:%d\n", p->data.id, p->data.name, p->data.score); // 打印节点数据 p = p->pnext; // 移动到下一个节点 } printf("\n"); } else { // 反向打印 while (p->pnext) { p = p->pnext; // 移动到最后一个节点 } while (p) { printf("id: %d,name: %s,score: %d\n", p->data.id, p->data.name, p->data.score); // 打印节点数据 p = p->ppre; // 移动到前一个节点 } printf("\n"); } return 0; // 打印成功
} // 在链表尾部插入节点
int push_into_dlink_tail(dlink_t* pdlink, datatype data) { if (is_empty_dlink(pdlink)) { // 如果链表为空 push_into_dlink_head(pdlink, data); // 直接在头部插入 return 0; // 插入成功 } dnode_t* p = pdlink->phead; // 从头节点开始 dnode_t* pnode = malloc(sizeof(dnode_t)); // 分配新节点内存 pnode->data = data; // 设置节点数据 pnode->ppre = NULL; // 新节点的前指针为空 pnode->pnext = NULL; // 新节点的后指针为空 if (NULL == pnode) { return -1; // 内存分配失败 } while (p->pnext) { // 找到最后一个节点 p = p->pnext; } pnode->ppre = p; // 新节点的前指针指向最后一个节点 p->pnext = pnode; // 最后一个节点的后指针指向新节点 pdlink->clen++; // 增加节点计数 return 0; // 插入成功
} // 从链表头部删除节点
int pop_into_dlink_head(dlink_t* pdlink) { if (is_empty_dlink(pdlink)) { return -1; // 如果链表为空,返回错误 } dnode_t* p = pdlink->phead; // 获取头节点 pdlink->phead = pdlink->phead->pnext; // 更新头指针为下一个节点 free(p); // 释放头节点内存 pdlink->clen--; // 减少节点计数 if (pdlink->phead == NULL) { return 0; // 如果链表变为空,返回成功 } if (pdlink->phead->pnext) { pdlink->phead->ppre = NULL; // 更新新头节点的前指针为空 } return 0; // 删除成功
} // 从链表尾部删除节点
int pop_into_dlink_tail(dlink_t* pdlink) { if (is_empty_dlink(pdlink)) { return -1; // 如果链表为空,返回错误 } dnode_t* p = pdlink->phead; // 从头节点开始 while (p->pnext) { // 找到最后一个节点 p = p->pnext; } if (p->ppre == NULL) { // 如果只有一个节点 free(p); // 释放节点内存 pdlink->clen--; // 减少节点计数 pdlink->phead = NULL; // 更新头指针为空 return 0; // 删除成功 } p->ppre->pnext = NULL; // 更新倒数第二个节点的后指针为空 free(p); // 释放最后一个节点内存 pdlink->clen--; // 减少节点计数 return 0; // 删除成功
} // 根据名称搜索节点
dnode_t* search_into_dlink(dlink_t* pdlink, char * name) { if (is_empty_dlink(pdlink)) { return NULL; // 如果链表为空,返回NULL } dnode_t* p = pdlink->phead; // 从头节点开始 while (p) { if (strcmp(p->data.name, name) == 0) { // 如果找到匹配的名称 return p; // 返回找到的节点 } p = p->pnext; // 移动到下一个节点 } return NULL; // 未找到匹配的节点
} // 修改节点数据
int change_dlink_node(dlink_t* pdlink, char *name, int dstscore) { if (is_empty_dlink(pdlink)) { return -1; // 如果链表为空,返回错误 } dnode_t* p = pdlink->phead; // 从头节点开始 while (p) { if (strcmp(p->data.name, name) == 0) { // 如果找到匹配的名称 p->data.score = dstscore; // 更新节点的分数 } p = p->pnext; // 移动到下一个节点 } return 0; // 修改成功
} // 销毁链表
int destory_dlink(dlink_t* pdlink) { while (pdlink->phead) { pop_into_dlink_head(pdlink); // 逐个删除头节点 } print_link(pdlink, 1); // 打印链表(此时应为空) free(pdlink); // 释放链表结构体内存 return 0; // 销毁成功
}相关文章:
单向链表排序和双向链表操作)
数据结构(2)单向链表排序和双向链表操作
一单向链表的插入排序 void insertion_sort_link(link_t* plink) { // 如果链表头为空,直接返回 if(NULL plink->phead) { return; } // 初始化指针,p指向当前已排序部分的最后一个节点 node_t* p plink->phead; // ptemp指向待插入的…...

OpenCV结构分析与形状描述符(14)拟合直线函数fitLine()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 拟合一条直线到2D或3D点集。 fitLine 函数通过最小化 ∑ i ρ ( r i ) \sum_i \rho(r_i) ∑iρ(ri)来拟合一条直线到2D或3D点集,…...

Mysql基础练习题 1757.可回收且低脂的产品(力扣)
编写解决方案找出既是低脂又是可回收的产品编号。 题目链接: https://leetcode.cn/problems/recyclable-and-low-fat-products/description/ 建表插入数据: Create table If Not Exists Products (product_id int, low_fats ENUM(Y, N), recyclable …...

Nginx调优,有这篇就够了
目录 1. 工作进程数量 2. Nginx最大打开文件数 3. Nginx事件处理模型 4. 开启高效传输模式 5. 连接超时时间 6. proxy调优 7. fastcgi 调优 8. gzip 调优 9. expires 缓存调优 10. 防盗链 11. 内核参数优化 1. 工作进程数量 #根据cpu个数自动调整工作进程数量 work…...
)
Java语言程序设计基础篇_编程练习题*18.17 (数组中某个指定字符出现的次数)
题目:*18.17 (数组中某个指定字符出现的次数) 编写一个递归的方法,求出数组中一个指定字符出现的次数。需要定义下面两个方法,第二个方法是一个递归的辅助方法。 public static int count(char[] chars, char ch) public static int count(…...

实时(按帧)处理的低通滤波C语言实现
写在前面: 低通滤波采用一般的FIR滤波器,因为本次任务,允许的延迟较多,或者说前面损失的信号可以较多,因此,涉及一个很高阶的FIR滤波器,信号起始段的信号点可以不处理,以及…...
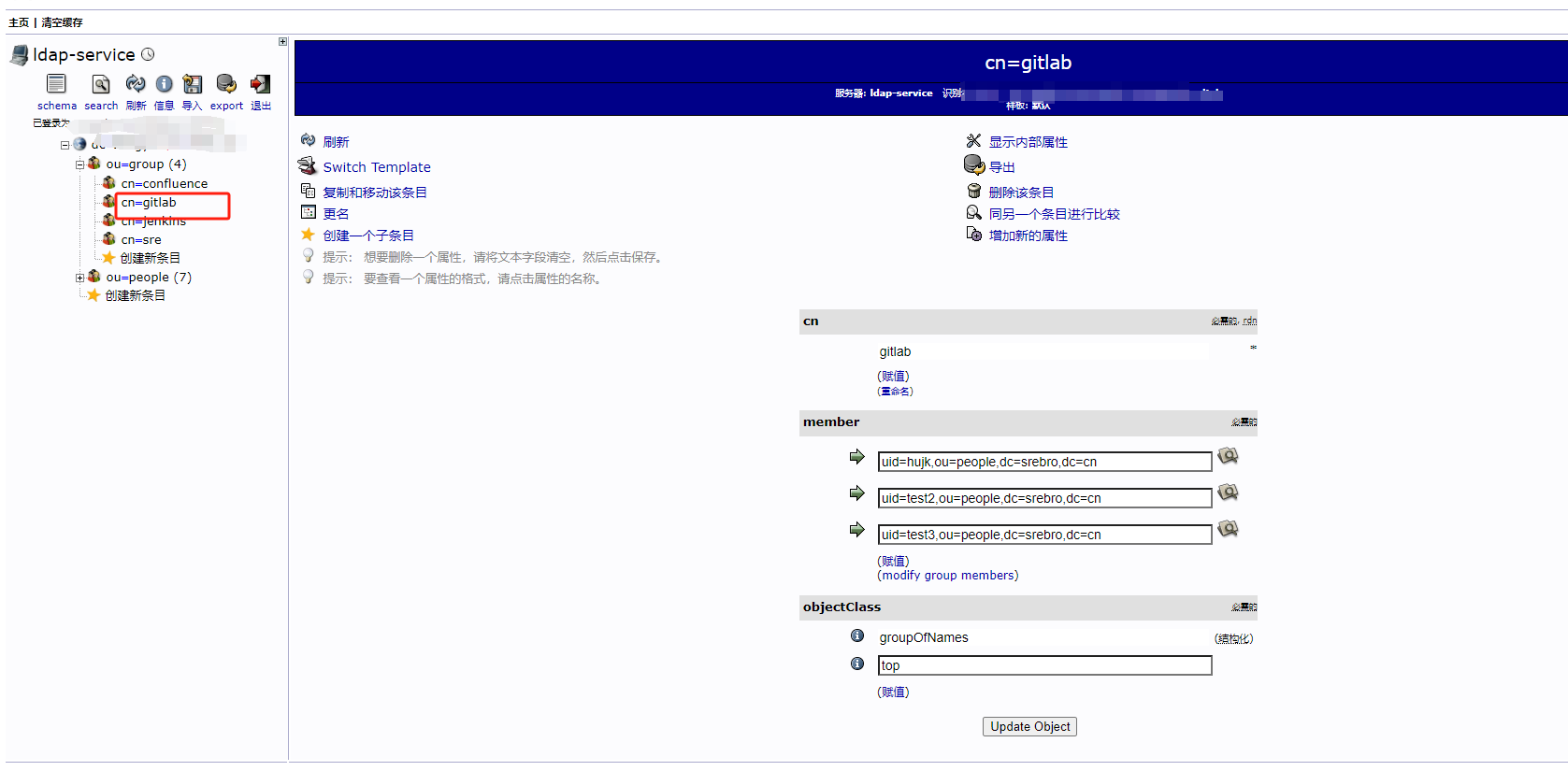
Centos7.9部署Gitlab-ce-16.9
一、环境信息 软件/系统名称版本下载地址备注Centos77.9.2009https://mirrors.nju.edu.cn/centos/7.9.2009/isos/x86_64/CentOS-7-x86_64-DVD-2009.isogitlab-cegitlab-ce-16.9.1https://mirror.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/gitlab-ce-16.9.1-ce.0.el7.x86_64.rpm…...

卷积神经网络(一)
目录 一.卷积神经网络的组成 二.卷积层 目的: 参数: 计算公式 卷积运算过程 三.padding-零填充 1.Valid and Same卷积 2.奇数维度的过滤器 四.stride步长 五.多通道卷积 1.多卷积核(多个Filter) 六.卷积总结 七.池化层(Pooling) 八.全连接层…...

加密与安全_ sm-crypto 国密算法sm2、sm3和sm4的Java库
文章目录 Presm-crypto如何使用如何引入依赖 sm2获取密钥对加密解密签名验签获取椭圆曲线点 sm3sm4加密解密 Pre 加密与安全_三种方式实现基于国密非对称加密算法的加解密和签名验签 sm-crypto https://github.com/antherd/sm-crypto 国密算法sm2、sm3和sm4的java版。基于js…...

VR 尺寸美学主观评价-解决方案-现场体验研讨会报名
棣拓科技VR创新解决方案助力尺寸美学所见即所得! 诚邀各位行业专家莅临指导交流 请扫描海报二维码踊跃报名,谢谢 中国上海 2024.10.25 亮点介绍 1、通过精湛渲染技术,最真实展现设计效果,并通过VR设备一比一比例进行展现。 2、设置相关设…...

网络基础入门指南(三)
一、远程管理交换机 1.配置IP地址 远程管理需要通过IP地址访问网络设备交换机的接口,默认无法配置IP地址需要使用虚接口vlan1 2.配置远程登录密码 远程管理需要配置VTY接口VTY是虚拟终端,是一种网络设备远程连接的方式vty 0 4表示可同时打开5个会话 3…...

大众萨克森:SNP助力汽车制造智能化,实现SAP S/4HANA系统成功升级
关于大众萨克森 VW Sachsen 大众汽车(Volkswagen Sachsen GmbH)包括位于德国茨维考的汽车工厂、位于德累斯顿的透明工厂和位于开姆尼茨的发动机工厂。茨维考汽车厂拥有 7,900名员工,每天生产1,350辆高尔夫和帕萨特汽车。在开姆尼茨的发动机工…...

20240912 每日AI必读资讯
OpenAI计划在接下来的两周内发布Strawberry - 独立产品:尽管草莓是ChatGPT的一部分,但它将作为一个独立的产品发布,具体如何提供尚不清楚。它可能会出现在用户选择的AI模型下拉菜单中,与现有服务有所不同。 - 推理功能ÿ…...

Linux之Shell命令
Shell 是一个 C 语言编写的脚本语言,它是用户与 Linux 的桥梁,用户输入命令交给 Shell 处理,Shell 将相应的操作传递给内核(Kernel),内核把处理的结果输出给用户。 程序执行方式:编译、解释 Sh…...

前端Vue框架实现html页面输出pdf(html2canvas,jspdf)
代码demo: <template><el-dialog class"storageExportDialog" :fullscreen"true" title"" :visible.sync"visible" v-if"visible" width"600px"><div id"exportContainer" …...

SAP Fiori UI5-环境搭建-2022-2024界面对比
文章目录 一、Fiori项目初始化实际操作第一步:新建文件夹(项目文件)第二步:打开我们项目第三步:打开终端 部署环境第四步: XML中新增文本 二、 2023年Vscode中Fiori界面三 、2024年Vscode中Fiori界面 一、Fiori项目初始…...

二百六十三、Java——IDEA项目打成jar包,然后在Linux中运行
一、目的 在用Java对原Kafka的JSON字段解析成一条条数据,然后写入另一个Kafka中,代码写完后打成jar包,放在Linux中,直接用海豚调度运行 二、Java利用fastjson解析复杂嵌套json字符串 这一块主要是参考了这个文档,然…...

【OpenCV2.2】图像的算术与位运算(图像的加法运算、图像的减法运算、图像的融合)、OpenCV的位运算(非操作、与运算、或和异或)
1 图像的算术运算 1.1 图像的加法运算 1.2 图像的减法运算 1.3 图像的融合 2 OpenCV的位运算 2.1 非操作 2.2 与运算 2.3 或和异或 1 图像的算术运算 1.1 图像的加法运算 add opencv使用add来执行图像的加法运算 图片就是矩阵, 图片的加法运算就是矩阵的加法运算, 这就要求加…...

ChatGPT 3.5/4.0使用手册:解锁人工智能的无限潜能
1. 引言 在人工智能的浪潮中,ChatGPT以其卓越的语言理解和生成能力,成为了一个革命性的工具。它不仅仅是一个聊天机器人,更是一个能够协助我们日常工作、学习和创造的智能伙伴。随着ChatGPT 3.5和4.0版本的推出,其功能和应用范围…...

E32.【C语言 】练习:蓝桥杯题 懒羊羊字符串
1.题目 【问题描述】 “懒羊羊”字符串是一种特定类型的字符串,它由三个字符组成,具有以下特点: 1.字符串长度为 3. 2.包含两种不同的字母。 3.第二个字符和第三个字符相同 换句话说,“懒羊羊”字符串的形式应为 ABB,其中A和B是不…...

LDA vs PCA:用sklearn和手写代码,在随机数据集上彻底搞清区别
LDA vs PCA:从数学原理到实战选择的深度解析 引言:为什么我们需要理解这两种降维方法的差异? 在数据科学和机器学习领域,降维技术是我们处理高维数据不可或缺的工具。当我们面对成百上千个特征时,如何有效地提取最有价…...

从芯片手册到PCB:SPL06与MPU9250的I2C实战布线要点与防护设计
从芯片手册到PCB:SPL06与MPU9250的I2C实战布线要点与防护设计 在无人机飞控板的设计中,气压传感器SPL06和九轴传感器MPU9250的稳定工作直接关系到飞行姿态控制的精确性。本文将深入探讨这两个关键传感器在PCB布局中的I2C总线设计要点,以及如何…...

Layerdivider:5步完成AI智能图像分层,免费生成专业PSD文件
Layerdivider:5步完成AI智能图像分层,免费生成专业PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一款革命…...

哔咔漫画下载器:如何轻松构建个人离线漫画图书馆?
哔咔漫画下载器:如何轻松构建个人离线漫画图书馆? 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.…...

对比直接使用官方API,通过Taotoken聚合调用在容灾方面的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API,通过Taotoken聚合调用在容灾方面的体验差异 在开发依赖大模型能力的应用时,服务的稳定…...

5种文本切块策略大解析:从字符到语义,打造高效检索系统!
文本切块是构建向量索引前的重要环节,避免语义切断和检索效果冲淡。文章详细解析了五种常见切块策略:按字符长度切分、按Token长度切分、按句子语义切分、按段落结构切分(含默认语法和自定义语法)以及混合方式切分。每种策略都有其…...

Anubis质检报告XTR文件:从数据字段到质量评估的实战解析
1. XTR文件基础:GNSS质检报告的核心载体 第一次拿到Anubis生成的XTR文件时,我盯着满屏的缩写和数据愣了半天。这种看似晦涩的文本文件,实际上是GNSS数据质量的"体检报告单"。就像医院的血常规化验单需要专业解读一样,XT…...

不用示波器也能调:在Vivado/Quartus里用时序约束搞定RGMII接口的建立保持时间
不依赖示波器的RGMII时序优化:FPGA工具链实战指南 当千兆以太网接口出现数据丢包或误码时,多数工程师的第一反应是抓起示波器测量信号完整性。但在实际项目周期中,硬件调试设备可能无法随时调用,而PCB设计又已成定局。此时&#x…...

查询不准?响应延迟?Perplexity阅读推荐失效全归因,一线SRE团队72小时压测实录
更多请点击: https://intelliparadigm.com 第一章:查询不准?响应延迟?Perplexity阅读推荐失效全归因,一线SRE团队72小时压测实录 问题爆发现场还原 凌晨2:17,Perplexity阅读推荐API的P99延迟突增至8.4s&a…...

LabVIEW多核并行编程实战:从数据流原理到生产者-消费者架构优化
1. 项目概述:从单核到多核的性能跃迁如果你用LabVIEW做过一些稍微复杂的应用,比如高速数据采集、实时图像处理或者复杂的控制算法仿真,大概率会遇到一个瓶颈:程序跑起来感觉“卡”,CPU占用率明明不高,但循环…...