多模态大语言模型综述(中)-算法实用指南
本文是Multimodal Large Language Models: A Survey的译文之算法实用指南部分。
- 上:摘要、概念与技术要点实用指南
- 中:算法实用指南(本文)
- 下: 任务的实用指南(应用)、挑战等
原始信息
- 标题: Multimodal Large Language Models: A Survey
- 译文: 多模态大语言模型综述
- 地址: arxiv.org/pdf/2311.13…
- 作者: Jiayang Wu , Wensheng Gan, Zefeng Chen , Shicheng Wan , Philip S. Yu
如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

IV. 算法实用指南
多模态的算法可分为两类: 基础模型和大规模多模态预训练模型。基础模态是多模态的基本框架, 许多新的大规模多模态预训练模型都是基于它进行改进的。
下图是论文涉及的算法清单,含模型名字、年份、技术要点、功能及参考编号,以及代码开源情况。

基础模型
Transformer
Transformer[39]于2017年提出,颠覆了传统的深度学习模型,在机器翻译任务中取得了良好的性能。它因能够在大规模语料库上进行自我监督的预训练,并随后对下游任务进行微调而受到关注。许多预先训练的大规模模型都遵循了这种范式。
Transformer的权重共享特性与输入序列长度无关,因此适用于多模态应用。
模型中的某些模块可以共享权重参数。Transformer中的权重共享概念源于自注意模块和前馈神经网络不受输入序列长度的影响。这种权重共享概念也可以应用于多模态模型。例如,在涉及图像和文本的多模态设置中,从图像训练中学习到的权重参数可以用于文本训练,并且结果仍然有效,有时即使不需要微调。
VIT(vision transformer)
Transformer模型及其自注意机制在自然语言处理(NLP) 领域的卓越性能引起了计算机视觉领域的广泛关注。许多研究已经开始将Transformer机制纳入计算机视觉任务中。
然而,Transformer在输入数据大小方面有局限性,需要仔细考虑输入策略。Google从之前的工作中汲取灵感,提出了视觉转换器(ViT)模型,该模型由强大的计算资源提供支持。ViT模型通过将图像分割成块(例如,将图像分割为16个块)来解决输入大小限制[40]。然后对这些补丁进行处理,并将其转换为Transformer可以通过线性映射处理的输入。这一突破弥补了计算机视觉和NLP之间的差距。与以前的方法相比,ViT不仅使Transformer能够处理图像,而且还引入了更有效的图像特征提取策略。
BEiT
如果ViT可以被视为计算机视觉中Transformer模型的自适应,那么BEiT可以被认为是计算机视觉中BERT的自适应[24]。生成式预训练(Generative pre-training)是自我监督(self-supervised)学习中的一种重要方法和训练目标,在这种学习中,模型学习如何在不依赖标签或手动标注的情况下生成数据。生成预训练在自然语言处理方面取得了重大成功。
BEiT解决了计算机视觉生成式预训练中的两个关键挑战。第一个挑战是如何将图像信息转换为类似于NLP的离散令牌。BEiT使用离散视觉嵌入聚合方法对图像进行离散化。第二个挑战是如何将图像信息有效地纳入预训练过程。BEiT利用完善的ViT结构来处理图像信息。通过解决这两点,BEiT成功地将掩蔽语言建模(MLM)和掩蔽图像建模(MIM)方法应用于计算机视觉领域,将生成预训练引入计算机视觉领域并实现了大规模的自监督预训练。
大规模多模态预训练模型
Visual ChatGPT
Visual ChatGPT[38]结合了不同的视觉基础模型(VFM)来处理各种视觉任务,例如图像理解和生成。不仅允许用户发送和接收语言,还允许用户接收图像,从而实现复杂的视觉问题和指令。该系统还引入了Prompt Manager,它有助于利用VFM并以迭代的方式接收他们的反馈。这个迭代过程一直持续到系统满足用户的要求或达到结束条件。通过提示将视觉模型信息注入ChatGPT,系统将视觉特征与文本空间对齐,增强了ChatGPT的视觉理解和生成能力。
Visual ChatGPT具有处理语言和图像之外的模态的能力。虽然该系统最初专注于语言和图像,但它为融入视频或语音等其他模态开辟了可能性。这种灵活性消除了每次引入新的模态或功能时训练全新的多模态模型的需要。
MM-REACT
MM-REACT[41]将ChatGPT与各种视觉模型相结合,以实现多模态任务,主要通过VQA格式进行演示。在回答问题时,ChatGPT将视觉模型作为工具,并根据具体问题决定是否使用它们。
该系统与之前使用VQA的字幕模型和语言图像模型的作品有相似之处。在这些方法中,字幕模型将图像转换为文本,然后由更大的模型用作证据来生成答案。然而,MM-REACT在自主决定是否调用视觉模型的能力方面有所不同。
Frozen
Frozen[42]介绍了在多模态上下文学习中使用LLM的新概念。具体方法包括使用视觉编码器(visual encoder)将图像转换为嵌入(embedding)。然后将这些嵌入与文本连接,创建一个集成了两种模态的组合数据格式。随后,该模型使用自回归方法来预测下一个令牌。在整个训练过程中,LLM保持冻结状态,而视觉编码器是可训练的。这允许最终模型保留其语言建模能力,同时获得在多模态环境中执行上下文学习的能力。
BLIP-2
BLIP-2[43]在编码图像时采用了与Flamingo类似的方法,利用Qformer模型提取图像特征。Qformer扮演的角色类似于火烈鸟的感知重采样器。然后,该模型通过交叉注意力促进图像-文本交互。训练期间,BLIP-2冻结视觉编码器和LLM,并且仅微调Qformer。然而,当对特定的下游任务数据集进行微调时,BLIP-2解锁视觉编码器,并将其与Qformer一起进行微调。
BLIP-2的训练过程包括两个阶段
- 只有Qformer和视觉编码器(visual encoder)参加训练。它们使用经典的多模态预训练任务进行训练,如图像文本匹配、对比学习和基于图像的文本生成。这个阶段使Qformer能够学习如何从视觉编码器中快速提取与文本相关的特征。
- 将Qformer编码的矢量插入LLM中用于字幕生成。BLIP-2在VQA的零样本和微调方案中都表现出了良好的性能。对于同一任务,它在不同数据集之间具有良好的可转移性。
LLaMA-Adapter
LLaMA-Adapter[44] 通过插入适配器在LLaMA中引入了高效的微调,可以扩展到多模态场景。适配器是自适应提示向量,作为可调参数连接到Transformer的最后一层。当应用于多模态设置时,首先使用冻结视觉编码器将图像编码为多尺度特征向量。然后,在将这些向量按元素添加到自适应提示向量之前,通过级联和投影操作来聚合这些向量。
MiniGPT-4
MiniGPT-4 [45] 是基于BLIP-2和Vicuna的组合的GPT-4的某些功能的复制。它直接从BLIP-2传输Qformer和视觉编码器,并将它们与LLM一起冻结,只在视觉侧留下一个线性层进行微调。这种可调参数的压缩导致模型大小为15M。
此外,还采用了两阶段微调策略: i).字幕(Caption)生成被用作训练任务。该模型生成多个字幕,然后使用ChatGPT重写这些字幕,以创建详细而生动的描述。ii).构造一组高质量的图像-文本对以用于进一步的微调。这组图像-文本对用于细化模型。
LLaVA [46]
LLaVA[46]和MiniGPT-4是相似的,因为它们都旨在实现多模态指令的微调。
然而,它们在数据生成和训练策略方面有所不同,导致了LLaVA模型的发展。在数据生成中,LLaVA利用GPT-4创建各种指令微调数据,包括多回合QA、图像描述和复杂推理任务。这确保了模型能够处理广泛的查询。由于GPT-4的当前接口只接受文本输入,因此需要将图像信息转换为文本格式。本研究使用为COCO数据集中的每个图像提供的五个标题和边界框坐标作为输入到GPT-4的文本描述。
关于训练策略,LLaVA采用两阶段方法。i) 根据特定规则,使用从cc3m数据集过滤的600000个图像-文本对对对模型进行了微调。微调过程冻结了视觉和语言模型,只专注于微调线性层。ii)使用上述数据生成策略,生成160000个指令微调数据样本。然后使用语言模型丢失对模型进行进一步的微调。在这个阶段,视觉模型被冻结,线性层和语言模型都被微调。
PICa
PICa[47]是第一次尝试使用LLM来解决VQA任务。其目的是使LLM能够理解和处理图像信息。为了实现这一点,先前的研究采用了字幕模型将图像转换为相应的文本描述。然后,将标题和问题一起输入GPT-3,形成三元组(问题、标题、答案),并利用上下文学习来训练GPT-3回答新问题。在为数不多的情境学习场景中,PICa取得了比 Frozen 更好的成绩,但仍落后于Flamingo。这可归因于在将图像转换为字幕期间视觉信息的丢失。
视觉信息在回答问题中起着至关重要的作用,将图像转换为文本的过程不可避免地会导致视觉细节和语义的损失,从而限制模型的性能。
PNP-VQA
PNP-VQA[48]利用字幕模型和预训练语言模型(PLM)来处理VQA任务。然而,在PLM的选择方面,它与PICa不同,因为它采用了一个名为UnifiedQAv2的问答模型。PNP-VQA专注于实现零样本VQA能力。为了解决字幕中图像信息丢失的问题,PNPVQA在生成字幕之前引入了图像问题匹配模块。该模块识别图像中与给定问题最相关的补丁。然后专门为这些选定的补丁生成字幕。这些标题补丁对,以及原始问题,被用作上下文,并被输入到UnifiedQAv2模型中。这种方法通过结合相关的图像补丁作为上下文,确保生成的字幕与问题密切相关。通过结合图像问题匹配模块并利用UnifiedQAv2作为PLM,PNP-VQA旨在提高生成的VQA字幕的相关性和准确性。这种策略允许模型有效地利用图像和问题信息,以便生成更具上下文相关性的答案。
Img2LLM
Img2LLM[49]旨在解决将LLM用于VQA任务时的两个主要问题: 1) 模态断开,LLM无法有效处理视觉信息;2) 任务断开,通过文本生成预先训练的LLM在没有微调的情况下难以使用VQA的字幕。为了克服这两问题,作者建议通过(问答)对传递视觉信息。具体地,该方法涉及使用字幕模型或类似于PNP-VQA的方法来生成图像的字幕。从这些字幕(captions)中,可以提取出可能作为某些问题答案的相关单词,如名词和形容词。随后,使用问题生成模型来生成相应的问题,从而创建问题,回答对。这些配对在上下文学习中起到示范作用,帮助LLM回答有关给定图像的问题。通过问答对传输视觉信息,Img2LLM解决了模态断开和任务断开问题,使LLM能够更好地利用视觉信息执行VQA任务。
术语
- VQA:自由形式和开放式视觉问答
- PNP-VQA:Plug-and-Play VQA, 零样本训练的VQA
相关文章:
多模态大语言模型综述(中)-算法实用指南
本文是Multimodal Large Language Models: A Survey的译文之算法实用指南部分。 上:摘要、概念与技术要点实用指南中:算法实用指南(本文)下: 任务的实用指南(应用)、挑战等 原始信息 标题: Multimodal Large Language Models: A Survey译文: 多模态大…...

Qt | ubuntu20.04安装Qt6.5.3并创建一个example完整教程(涉及诸多开发细节,商用慎重)
点击上方"蓝字"关注我们 01、下载 >>> 下载Qt在线安装包 这里采用镜像地址进行下载,避免网络过慢。 镜像地址:http://mirrors.ustc.edu.cn/qtproject/archive/online_installers/4.5/ 选择最新版本下载,如截至目前最新版本为qt-unified-linux-x64-4.5.2…...

苏州科技大学、和数联合获得国家知识产权局颁发的3项发明专利证书
近日,基于“苏州科技大学-和数智能软件区块链技术工程实验室”的研究成果,国家知识产权局正式授权了苏州科技大学、苏州和数区块链应用研究院联合申报的3项发明专利证书。 分别为: 一种基于双账本的物联网数据存储与共享方法 一种面向物联网…...

CleanMyMac X2024破解版mac电脑清理工具
今天,我要跟大家分享一个让我彻底告别电脑卡顿的秘密武器——CleanMyMac X。这不仅仅是一款普通的清理工具,它是你电脑的私人健身教练,让电脑焕发青春活力! CleanMyMac直装官方版下载地址: http://wm.makeding.com/i…...
微软数据库的SQL注入漏洞解析——Microsoft Access、SQLServer与SQL注入防御
说明:本文仅是用于学习分析自己搭建的SQL漏洞内容和原理,请勿用在非法途径上,违者后果自负,与笔者无关;本文开始前请认真详细学习《中华人民共和国网络安全法》及其相关法规内容【学法时习之丨网络安全在身边一图了解网络安全法_中央网络安全和信息化委员会办公室】 。…...

无人机之处理器篇
无人机的处理器是无人机系统的核心部件之一,它负责控制无人机的飞行、数据处理、任务执行等多个关键功能。以下是对无人机处理器的详细解析: 一、处理器类型 无人机中使用的处理器主要包括以下几种类型: CPU处理器:CPU是无人机的…...

828华为云征文 | 华为云Flexus X实例上实现Docker容器的实时监控与可视化分析
前言 华为云Flexus X,以顶尖算力与智能调度,引领Docker容器管理新风尚。828企业上云节之际,Flexus X携手前沿技术,实现容器运行的实时监控与数据可视化,让管理变得直观高效。无论是性能瓶颈的精准定位,还是…...

缓存预热/雪崩/穿透/击穿
1. 缓存预热 预先将MySQL中的数据同步至Redis的过程 2. 缓存雪崩 Redis主机出现故障,或有大量的key同时过期大面积失效导致Redis不可用 Redis中key设置为永不过期,或者过期时间错开Redis缓存集群实现高可用多缓存结合预防雪崩服务降级 3. 缓存穿透 …...

C/C++:优选算法
一、双指针 1.1移动零 链接:283. 移动零 - 力扣(LeetCode) 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。请注意 ,必须在不复制数组的情况下原地对数组进行操…...
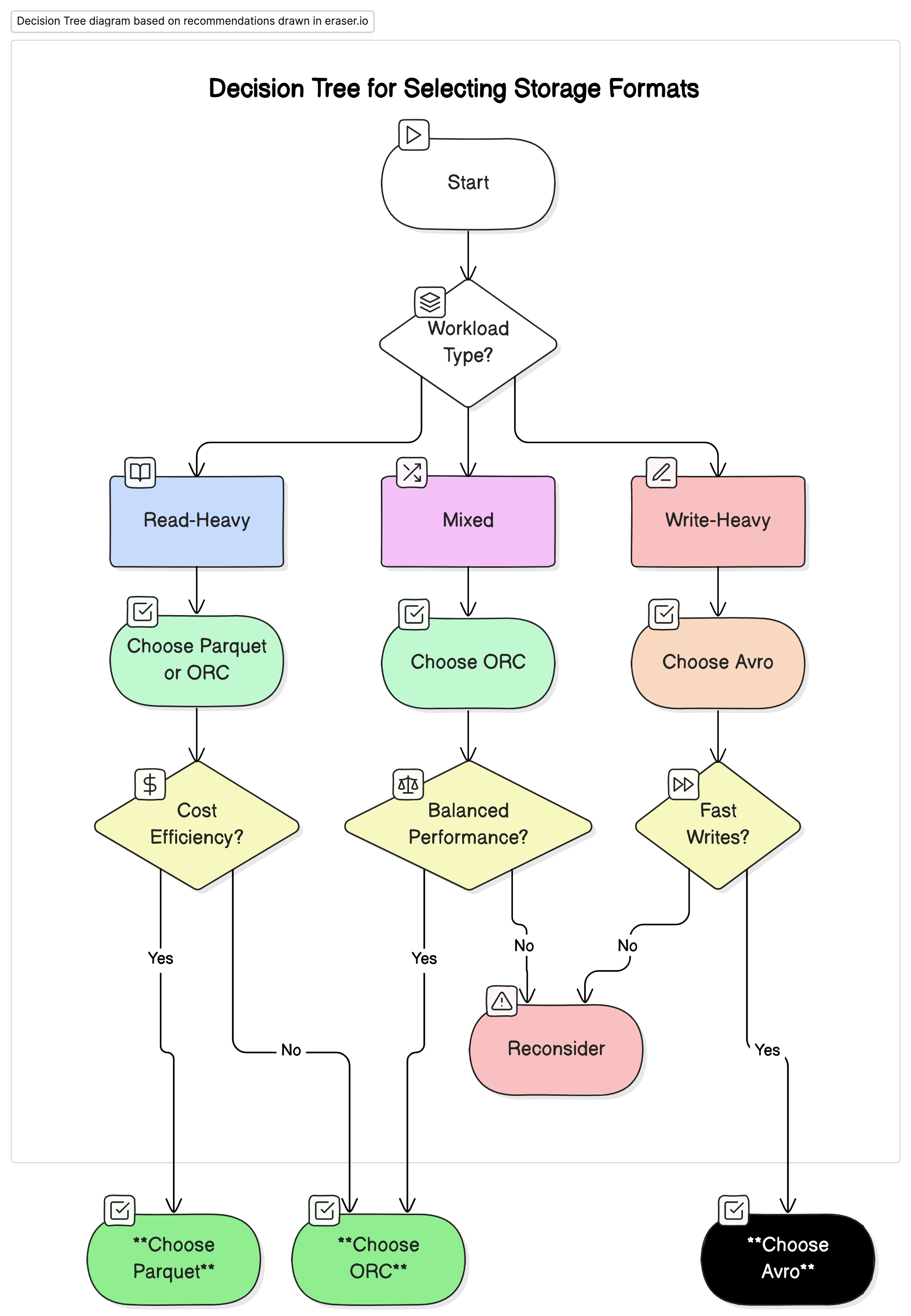
用于大数据分析的数据存储格式:Parquet、Avro 和 ORC 的性能和成本影响
高效的数据处理对于依赖大数据分析做出明智决策的企业和组织至关重要。显著影响数据处理性能的一个关键因素是数据的存储格式。本文探讨了不同存储格式(特别是 Parquet、Avro 和 ORC)对 Google Cloud Platform (GCP) 上大数据环境…...

【Jupyter Notebook】安装与使用
打开Anaconda Navigator点击"Install"(Launch安装前是Install)点击"Launch" 点击"File"-"New"-"Notebook" 5.点击"Select"选择Python版本 6.输入测试代码并按"EnterShift"运…...

默认端口被占用后,如何修改Apache2 端口
你可以通过以下步骤修改 Apache2 的默认端口(80 端口): 1. 修改 Apache2 配置文件 首先,你需要编辑 Apache2 的端口配置文件: sudo nano /etc/apache2/ports.conf在文件中,你会看到类似以下的内容&#…...

Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(2) (*****生成数据结构类的方式特别有趣****)
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(1)-CSDN博客 本节内容 实现目标 通过已经得到的Excel表格…...

Idea 中的一些配置
配置 javap jdk 自带的 javap 可以用来查看字节码信息。 配置过程: 打开设置,定位到 Tools,External Tools新建项,Program 中填 javap 的路径Argument 中填 -c $FileClass$Working directory 中填 $OutputPath$ Argument 中也…...
VulnHub DC-1-DC-7靶机WP
VulnHub DC系列靶机:https://vulnhub.com/series/dc,199/ # VulnHub DC-1 nmap开路获取信息 Nmap scan report for 192.168.106.133 Host is up (0.00017s latency). Not shown: 997 closed ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open http 1…...

基于DPU的容器冷启动加速解决方案
1. 方案背景 1.1. 业务背景 随着容器技术的迅猛发展与广泛应用,一种新的云计算服务模式应运而生-函数即服务(FaaS, Function as a Service)。FaaS作为一种无服务器(Serverless)计算方式,极大地简化了开发…...

SOME/IP 通信协议详细介绍
标签: SOME/IP 通信协议详细介绍; SOME/IP; SOME/IP 通信协议详细介绍 SOME/IP 通信协议详细介绍 官网: https://some-ip.com/ 1. 什么是SOME/IP? SOME/IP(Scalable service-Oriented MiddlewarE over IP…...

基于Boost库的搜索引擎开发实践
目录 1.项目相关背景2.宏观原理3.相关技术栈和环境4.正排、倒排索引原理5.去标签和数据清洗模块parser5.1.认识标签5.2.准备数据源5.3.编写数据清洗代码parser5.3.1.编写读取文件Readfile5.3.2.编写分析文件Anafile5.3.2.编写保存清洗后数据SaveHtml5.3.2.测试parser 6.编写索引…...

【2023年】云计算金砖牛刀小试3
A场次题目:OpenStack平台部署与运维 业务场景: 某企业拟使用OpenStack搭建一个企业云平台,用于部署各类企业应用对外对内服务。云平台可实现IT资源池化,弹性分配,集中管理,性能优化以及统一安全认证等。系统结构如下图: 企业云平台的搭建使用竞赛平台提供的两台云服务…...

在以太坊中不同合约之间相互调用的场景有哪些?
在以太坊中,合约调用合约的场景有很多,以下是一些常见的情况: 一、复杂业务逻辑的拆分 模块化设计: 当一个智能合约的业务逻辑变得复杂时,可以将其拆分为多个较小的合约,每个合约负责特定的功能。例如&…...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

OSINT自动化平台ClawShield:模块化架构与安全运营实战解析
1. 项目概述:一个面向安全运营的公开情报收集与分析平台最近在整理自己的开源项目收藏夹,发现一个挺有意思的仓库,叫SleuthCo/clawshield-public。乍一看这个名字,“ClawShield”,爪子与盾牌,就透着一股子攻…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

碧蓝航线自动化脚本:让游戏管理变得轻松高效
碧蓝航线自动化脚本:让游戏管理变得轻松高效 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每天重…...

GURU-Ai:面向开发者的AI命令行工具集,提升代码理解与运维效率
1. 项目概述:一个面向开发者的AI助手工具集最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个大而全的AI模型或者聊天机器人,但点进去仔细研究后,我发现它的定位其实非常…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

Supabase AI Agent技能库:安全集成数据库操作与边缘函数调用
1. 项目概述:当Supabase遇上AI Agent,一个技能库的诞生最近在捣鼓AI Agent应用开发,发现一个挺有意思的现象:大家都能用LangChain、LlamaIndex这些框架快速搭出个Agent的架子,但真想让这个Agent去干点具体、有用的活儿…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

构建高可用AI模型代理服务:统一接口、智能路由与生产级部署
1. 项目概述:一个无处不在的AI助手接口最近在折腾AI应用开发的朋友,可能都遇到过这样一个痛点:想在自己的项目里快速接入一个靠谱的、能处理复杂对话的AI模型,但要么被OpenAI的API调用限制和网络问题搞得焦头烂额,要么…...

Ruby专属LLM应用框架ruby_llm:从基础集成到生产部署实战
1. 项目概述:一个为Ruby语言量身打造的LLM应用框架如果你是一名Ruby开发者,最近被各种大语言模型(LLM)的应用搞得心痒痒,但看着满世界的Python库和框架感到无从下手,那么crmne/ruby_llm这个项目可能就是你在…...