如何简单实现ELT?
在商业中,数据通常和业务、企业前景以及财务状况相关,有效的数据管理可以帮助决策者快速有效地从大量数据中分析出有价值的信息。数据集成(Data Integration)是整个数据管理流程中非常重要的一环,它是指将来自多个数据源的数据组合在一起,提供一个统一的视图。
数据集成可以通过各种技术来实现,本文主要介绍如何用ELT(extract, load, transform)实现数据集成。区别于传统的ETL和其他的技术,ELT非常适合为数据湖仓或数据集市提供数据管道,并且可以用更低的成本,根据需求,随时对大量数据进行分析。
接下来将通过一个简单的示例(Demo)介绍如何实现ELT流程,具体的需求是将原始的电影票房数据保存到数据仓库,然后再对原始数据进行分析,得出相关的结果并且保存在数据仓库,供数据分析团队使用,帮助他们预测未来的收入。
技术栈选择
-
Data Warehouse: Snowflake
Snowflake是最受欢迎,最容易使用的数据仓库之一,并且非常灵活,可以很方便地与AWS、Azure以及Google Cloud集成。 -
Extract:通过k8s的cronjob将数据库的数据存到S3。
这里的技术选型比较灵活,取决于源数据库的类型以及部署的平台。Demo中将源数据从数据库提取出来后放在AWS S3,原因是Snowflake可以很方便与S3集成,支持复制数据到仓库并且自动刷新。
-
Load:通过Snowflake的External Tables将S3中的数据复制进数据仓库。
-
Transform:dbt
dbt支持使用SQL来进行简单的转换,同时提供了命令行工具,使用dbt我们可以进行良好的工程实践比如版本控制,自动化测试以及自动化部署。但对于比较复杂的业务场景来说,转换的过程一般都通过自己写代码实现。
-
Orchestrator: Airflow
Airflow和Oozie相比有更加丰富的监控数据以及更友好的UI界面。
下图描述了如何使用上述技术栈实现ELT:
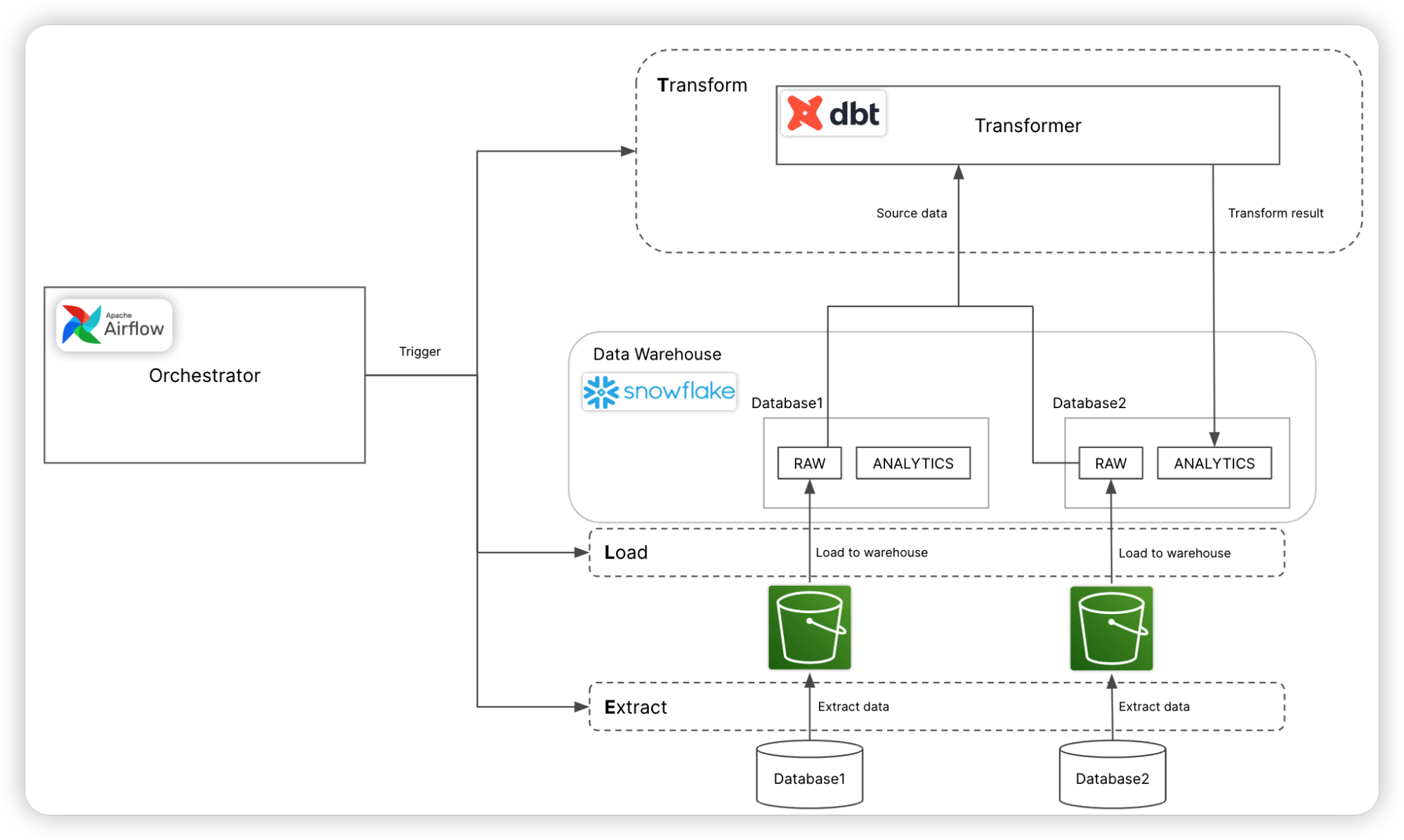
图中使用的Logo来自snowflake,dbt和Airflow的官方网站
工具介绍
Snowflake:数据存储
Snowflake是一个将全新的SQL查询引擎与一个专为云设计的创新架构相结合的数据云平台,它支持更快更灵活地进行数据存储、处理以及分析。
示例中将Snowflake作为数据仓库,存储原始数据电影院票房数量以及转换后的数据。
权限管理
和AWS类似,注册Snowflake后会持有一个拥有所有权限的root account。 如果直接使用此账号进行操作会非常危险,所以可以通过Snowflake提供的user和role来进行细粒度的权限管理。
最佳实践是用root account创建新的user并通过role赋予足够的权限,后续的操作都使用新创建的user来进行。
在下面的示例中,创建了一个名为TRANSFORMER的role,并且赋予它足够的权限。然后再创建一个使用这个role的user,在更方便地管理权限的同时,也实践了最小权限原则:
-- create roleCREATE ROLE TRANSFORMER COMMENT = 'Role for dbt';-- grant permission to the roleGRANT USAGE, OPERATE ON WAREHOUSE TRANSFORMING TO ROLE TRANSFORMER;GRANT USAGE, CREATE SCHEMA ON DATABASE PROD TO ROLE TRANSFORMER;GRANT ALL ON SCHEMA "PROD"."RAW" TO ROLE TRANSFORMER;GRANT ALL ON SCHEMA "PROD"."ANALYTICS" TO ROLE TRANSFORMER;GRANT SELECT ON ALL TABLES IN SCHEMA "PROD"."RAW" TO ROLE TRANSFORMER;GRANT SELECT ON FUTURE TABLES IN SCHEMA "PROD"."RAW" TO ROLE TRANSFORMER;-- create user with role TRANSFORMERcreate user user_demo password='abc123' default_role = TRANSFORMER must_change_password = true;
数据结构
每一个Snowflake的数据库都可以有多个schema,这里我们根据常见的实践,创建了schema RAW和ANALYTICS,分别用来存放原始数据和转换之后的数据:

每一个schema下面都可以有table、view和stage等数据库object。
stage是snowflake提供的一个空间,它支持我们将数据文件上传到这里,然后通过copy命令把外部数据导入到Snowflake。图中MY_S3_STAGE就是Demo中用来加载存放在AWS S3中的数据文件的,我们过这个stage实现了ELT中的L(Loading)。
dbt (data build tool):原始数据转化
在完成了原始数据的Extract和Loading后,怎样根据需求对它们进行Transform从而获得隐藏在数据中的有效信息呢?
这里我们选择dbt来进行数据的转化,它是一个支持我们通过简单地编写select语句来进行数据转换的工具,在Demo中它帮助完成了历史票房数据的统计工作。
Model
一个model就是一个写在.sql文件中的select语句,通常会默认使用文件名作为transform结果的表名。下面是demo中的一个model,from语句后面跟着的是一个dbt提供的引用源数据的方法。在model目录里的配置文件中声明源数据表之后,就可以直接通过source()方法来引用source table了。
select *from {{ source('ticket_sales','annual_ticket_sales') }}where ticket_year > ‘2010’Jinja Function
当需求变得更复杂时,如果仅仅通过SQL实现转换将会很困难,所以可以通过Jinja Function来实现在SQL中无法做到的事。
比如在有多个Model的dbt工程中,通常会有一些可以复用的逻辑,类似于编程语言中的函数。有了Jinja Function,就可以把要复用的逻辑提取成单独的Model,然后在其他Model中通过表达式{{ ref() }}来引用它:
select sum(total_inflation_adjusted_office) as total_salesfrom {{ ref('annual_ticket_sales') }}
Materializations
在上一部分的场景中,通常不希望把可复用的逻辑持久化在数据仓库中。
这里就可以引入配置Materializations来改变dbt对于model的持久化策略,比如将此配置设置为Ephemeral:
{{ config(materialized=‘table’) }}
这样model就仅被当作临时表被其他model引用而不会被持久化在数据仓库中。如果设置为View,model就会被在数据仓库中创建为视图。除此之外这个配置还支持类型:Table以及Incremental**。**
Test
为了防止原始数据有脏数据,所以在这里引入测试帮助保证最后结果的正确性。dbt提供了两种级别的测试:
- Generic test:这是一种比较通用的测试,为字段级别,它通常可以加在对Source和Target的声明里,应用于某一个字段并且可以重复使用。比如在demo中,我们希望ticket_year这个字段不为空并且是不会重复的:
tables:- name: annual_ticket_salescolumns:- name: ticket_yeardescription: "Which year does the sales amount stands for"tests:- not_null- unique- name: tickets_soldtests:- not_null- name: total_box_officetests:- not_null- Singular Test:它是通过一段SQL语句来定义的测试,是表级别。
比如查询源数据表里total_box_office小于0的记录,当查询不到结果时表示测试通过:
select total_box_officefrom {{source('ticket_sales','annual_ticket_sales')}}where total_box_office < 0
Airflow:任务编排
有了把原始数据集成进数据仓库的方法,也完成了数据转化的工程, 那么如何才能让它们有顺序地、定时地运行呢?
这里我们选择用Airflow进行任务的编排,它是一个支持通过编程编写data pipeline,并且调度和监控各个任务的平台。
DAG
第一步就是为我们的ELT流程创建一个流水线,在Airflow中,一个DAG(Directed Acyclic Graph)就可以看作是一个pipeline。声明它的时候需要提供一些基本的属性,比如DAG name, 运行间隔以及开始日期等等。
Airflow支持使用Python语言编写pipeline的代码,因此也具有较强的扩展性。
Demo中我们设置这个DAG的开始日期是2022年5月20号,并且期望它每天运行一次:
default_args = {'start_date': datetime(2022, 5, 20)}with DAG('annual_ticket_processing', schedule_interval='@daily',default_args=default_args, catchup=True) as dag:Task
流水线创建完成之后,我们需要将ELT的各个步骤加入到这个流水线中。这里的每一个步骤被称为Task,Task是Airflow中的基本执行单位,类似于pipeline中的step。在Demo中,在数据仓库中创建表、把原始数据加载到数据仓库、测试和数据转化分别是一个task。
在Airflow中,可以通过Operator快速声明一个task,Operator是一个提前定义好的模版,只需要提供必要的参数比如task id,SQL语句等即可。
下面这个task的功能是在Snowflake中创建表,需要提供的是一个连接Snowflake的Connection,要运行的SQL语句以及目标database和schema:
snowflake_create_table = SnowflakeOperator(task_id='snowflake_create_table',snowflake_conn_id='love_tech_snowflake',sql=CREATE_TABLE_SQL_STRING,database='PROD',schema='RAW',)
Task dependency
当我们对于task的运行顺序有特定要求时,比如为了保证最后报告的准确性,希望在对原始数据的测试通过之后再进行数据转化。这时可以通过定义task之间的依赖关系,来对它们的运行顺序进行编排,如下的依赖关系表示先在Snowflake创建数据表,然后将原数据加载到其中,完成后对于原始数据进行测试,如果测试失败就不会再运行后续的task:
snowflake_create_table >> copy_into_table >> dbt_test >> transform_data
Backfill
在平时的工作中,我们经常会遇到业务变动导致数据表里新增一个字段的情况,此时就需要将原始数据重新同步一遍。这时就可以利用Airflow提供的Backfill机制,帮助我们一次性回填指定区间内缺失的所有历史任务。
比如Demo中DAG的start date是5月20日,所以在打开开关之后,Airflow帮我们回填了start date之后的所有DAG run:

上图中DAG是在5月25日创建的,但Airflow却只从开始日期创建任务到24号,看起来缺失了25号的任务。原因是上图的24号是logical date(execution date),即trigger DAG run的日期。因为在定义DAG的时候将schedule_interval属性设置为daily,所以在25日(Actually Execute Date)当天只会执行24日(logical date)的任务。
监控和调试
Airflow提供了友好的UI界面让我们可以更方便地从各种维度监控以及调试,比如查看一年的运行情况:

或者每一个task的运行时间:

以及task的log:

等等,这里只列举了其中几个,大家有兴趣的话可以自己探索。
Parallelism
通常我们需要把多个数据源的数据,集成到同一个数据仓库中便于进行分析,因为这些task之间互相没有影响,所以可以通过同步运行它们来提高效率。
这种场景下,一方面可以通过配置参数Parallelism来控制Airflow worker的数量,也就是同时可以运行的task的数量,另一方面也需要更改Executor的类型,因为默认的Sequential Executor只支持同时运行一个task。
假设task的依赖关系声明为:task_1 >> [task_3, task_2] >> task_4
,在更换到Local Executor并且设置parallelism为5之后,启动Airflow,可以发现Airflow会创建5个worker。这时再触发DAG run,task2和task3就可以同时运行了:
~ yunpeng$ ps -ax | grep 'airflow worker'59088 ttys017 0:02.81 airflow worker -- LocalExecutor59089 ttys017 0:02.82 airflow worker -- LocalExecutor59090 ttys017 0:02.81 airflow worker -- LocalExecutor59091 ttys017 0:02.82 airflow worker -- LocalExecutor59092 ttys017 0:02.81 airflow worker -- LocalExecutor
DEMO运行结果
原始数据被加载到Snowflake的RAW schema中,dbt project可以随时引用这些数据:

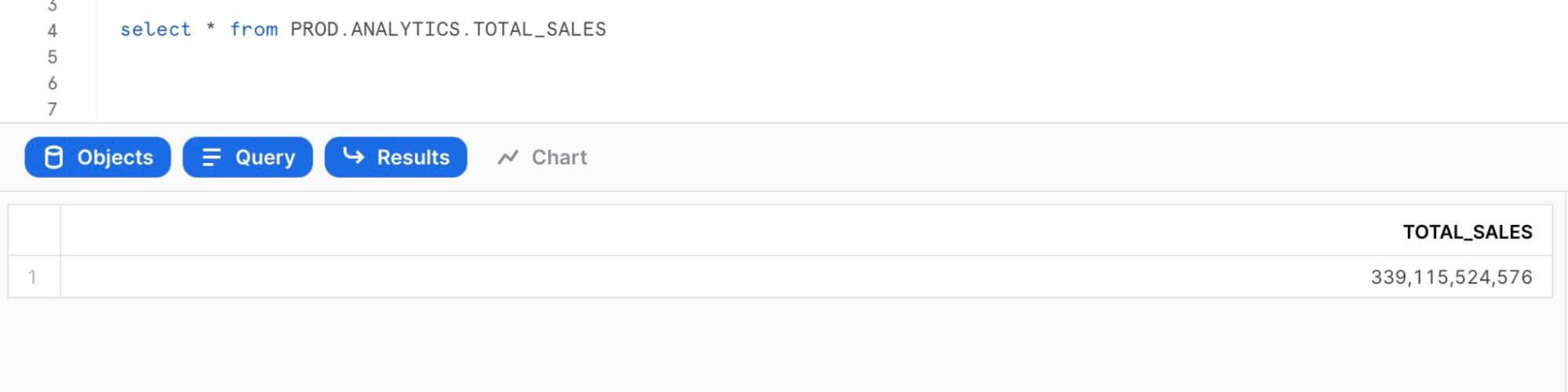
转换结果被持久化在ANALYTICS schema里,这些数据可以直接用来分析,也可以作为源数据被再次引用:
Repo link
dbt project: https://github.com/littlepainterdao/dbt_development
Airflow: https://github.com/littlepainterdao/airflow
本文整体比较基础,希望之前没有接触过ELT的同学可以通过这篇文章对它以及Snowflake,dbt和Airflow有初步的了解。
文/Thoughtworks 丁云鹏,张倬凡
原文链接:https://insights.thoughtworks.cn/how-to-implement-elt/
相关文章:
如何简单实现ELT?
在商业中,数据通常和业务、企业前景以及财务状况相关,有效的数据管理可以帮助决策者快速有效地从大量数据中分析出有价值的信息。数据集成(Data Integration)是整个数据管理流程中非常重要的一环,它是指将来自多个数据源的数据组合在一起&…...
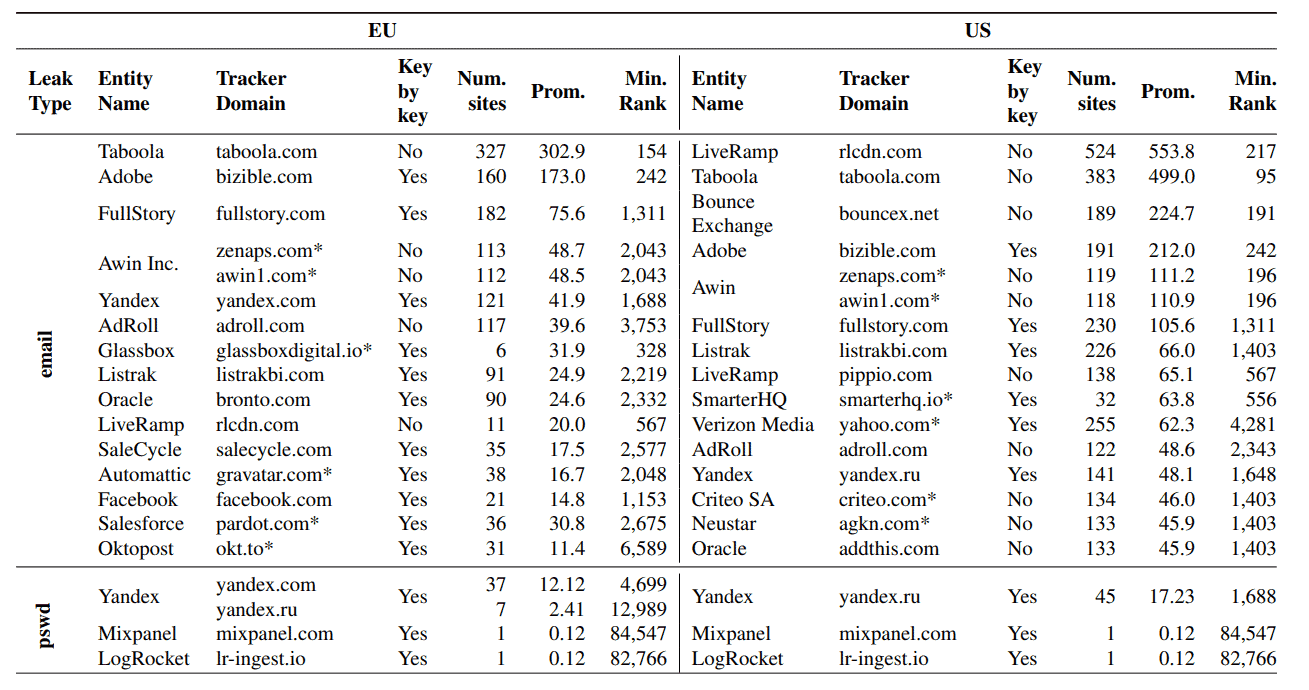
细思极恐,第三方跟踪器正在获取你的数据,如何防范?
细思极恐,第三方跟踪器正在获取你的数据,如何防范? 当下,许多网站都存在一些Web表单,比如登录、注册、评论等操作需要表单。我们都知道,我们在冲浪时在网站上键入的数据会被第三方跟踪器收集。但是&#x…...
-----点点滴滴的积累)
Java基础之==,equal的区别(温故而知新)-----点点滴滴的积累
1. 为运算符,equal 为String数据类型的比较方法;相同内容的对象地址不一定相同,但相相同地址的对象内容一定相同; 比较的是值是否相等,equal比较的是是否是同一个对象。 2.基本概念不同 1)对于,…...

SpringBoot项目使用切面编程实现数据权限管理
springBoot项目使用切面编程实现数据权限管理什么是数据权限管理如何实现数据权限管理什么是数据权限管理 不同用户在某页面看到数据不一致,实现每个用户之间数据隔离的效果。 如以下场景: ● 页面期望展示当前登录人所在部门的数据。 ● 页面期望展示当…...

亚马逊测评是做什么的,风险有哪些?
自养号测评顾名思义就是自己养国外的买家账号给自己店铺提升销量和评论,做过多年的跨境卖家都知道测评可以快速提高产品的排名、权重和销量,(国内某宝一样的逻辑)但随着测评需求日益增大,卖家在寻求真人测评时也很容易…...

安科瑞导轨式智能通讯管理机
安科瑞 李亚娜 一、概述 AWT200 数据通讯网关应用于各种终端设备的数据采集与数据分析。实现设备的监测、控制、计算,为系统与设备之间建立通讯纽带,实现双向的数据通讯。实时监测并及时发现异常数据,同时自身根据用户规则进行逻辑判断&…...

vs2010下 转换到 COFF 期间失败: 文件无效或损坏
因为同一个电脑上安装多个VS,有多个cvtres.exe。按照下面的操作如果还是不行就在C盘搜索cvtres.exe,然后挨个重命名,看看是调用的哪个,然后修改就可以了。 用VS2010编译C项目时出现这样的错误: LNK1123: 转换到 COFF …...

托福高频真词List19 // 附托福TPO阅读真题
目录 3.28单词 3.29真题 3.28单词 legitimately/properlyadv.正当地likewise/similarlyadv.同样地reveal/showv.揭示substantiate/confirmv.证实suppress/stop by forcev.镇压trend/tendencyn.趋势empirical/based on observationa.凭借经验的illuminate/li…...

Go语言项目标准结构应该如何组织的?
这里写自定义目录标题Go项目本身的目录结构Go语言项目典型目录结构GO语言项目最小标准目录结构可执行的Go语言项目目录结构库的Go语言项目目录结构关于internal目录总结参考文章每当我们写一个非hello world实用程序的Go程序或库时,我们都会在项目结构、代码风格和标…...

设计模式简介
设计模式简介 设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错…...

#详细介绍!!! 线程池的拒绝策略(经典面试题)
本篇单独讲解线程池的拒绝策略,介绍了当线程池任务满了之后,线程池会以什么样的方式来响应添加进来的任务 目录 一:理解线程池拒绝策略的触发情况代码理解 二:线程池的四种常见的拒绝策略 1.ThreadPoolExecutor.AbortPolicy 2…...

正则表达式作业
利用正则表达式完成下面的操作: 一、不定项选择题 能够完全匹配字符串"(010)-62661617"和字符串"01062661617"的正则表达式包括(A ) A. r"\(?\d{3}\)?-?\d{8}" B. r"[0-9()-]" C. r"[0-9(-)]*\d*&qu…...

《扬帆优配》交易拥挤度达历史极值 当前A股TMT板块性价比几何?
上周,A股商场企稳,但盘面风格分歧再度加深:很多资金涌入以ChatGPT、数字经济为代表的TMT板块,而新能源以及前期强势的“中字头”种类都呈现了回调。兴业证券计算显现,3月24日,TMT及电子板块的商场成交金额占…...

C/C++开发,无可避免的IO输入/输出(篇三).字符串流(内存流)IO处理
目录 一、字符串流 1.1 字符串流继承体系 1.2 字符串流本质-类模板std::basic_stringstream 1.3 字符串流缓冲-std::stringbuf 1.4 stringbuf与序列缓冲 1.5 字符串流的打开模式 二、字符串流的运用 2.1 格式转换是其拿手好戏 2.2 字符串流仅提供移动赋值 2.3 std::basic_str…...

什么是HTTP请求?【JavaWeb技术】
HTTP请求是指从客户端到服务器的请求消息,建立HTTP请求需要经历以下7个步骤才能请求成功。 (1)建立TCP连接 在HTTP开始工作前,Web浏览器需先通过网络和Web服务器连接,连接过程主要使用TCP/IP完成。 (2)Web浏览器向Web服务器发送请求命令 一旦…...

浅聊面试这件事
目录 哪个时间点适合跳槽 如何准备面试 面试原则 面试常见问题 哪个时间点适合跳槽 金三银四、金九银十,这些都📌标记为我们的最佳跳槽节点,但是这些节点真的是最佳的么,也需要因人而异。 如果公司年前不发年终奖,…...

【致敬未来的攻城狮计划】连续打卡第7天+瑞萨RA2E1点亮LED
开启攻城狮的成长之旅!这是我参与的由 CSDN博客专家 架构师李肯(http://yyds.recan-li.cn)和 瑞萨MCU (瑞萨电子 (Renesas Electronics Corporation) ) 联合发起的「 致敬未来的攻城狮计划 」的第 7 天,点击…...

Sam Altman专访:GPT-4没太让我惊讶,ChatGPT则让我喜出望外
导读ChatGPT、GPT-4 无疑是 2023 年年初人工智能界最大的「爆款」。3 月 26 日,OpenAI CEO、ChatGPT 之父 Sam Altman 接受了著名学者与科技播客、麻省理工大学研究员 Lex Fridman 的专访,Sam 分享了从OpenAI内部视角如何看待ChatGPT和GPT-4的里程碑式意…...

弯道超车的机会
弯道超车的机会 原文地址:https://bmft.tech/#/1-throught/0302-chance 前言 我一直很想把自己思考的东西表达出来,苦于语文成绩差,文字功力不够,想来想去也不知道用什么话来开场。我不喜欢站在高处对别人指指点点,…...

【设计模式】创建型模式之原型模式
【设计模式】创建型模式之原型模式 文章目录【设计模式】创建型模式之原型模式1.概述2. 构成3. 实现3.1 浅克隆3.2 深克隆1.概述 原型模式(Prototype Pattern):是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...
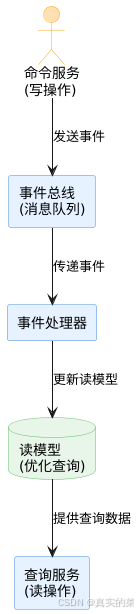
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...