位图及布隆过滤器的模拟实现与面试题
位图
模拟实现
namespace yyq
{template<size_t N>class bitset{public:bitset(){_bits.resize(N / 8 + 1, 0);//_bits.resize((N >> 3) + 1, 0);}void set(size_t x)//将某位做标记{size_t i = x / 8; //第几个char对象size_t j = x % 8; //这个char对象的第几个比特位_bits[i] |= (1 << j); //标记}void reset(size_t x)//将某位去掉标记{size_t i = x / 8;size_t j = x % 8;_bits[i] &= (~(1 << j));}//测试值是否在bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return _bits[i] & (1 << j);//整型提升,bool是4字节,char是1字节,按符号位来补}private:std::vector<char> _bits;};
}
当然位图也有缺点,它只能处理整型数据。
应用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
位图,是利用一个比特位来标识数据在不在(哈希的直接地址法),优点是节省空间,效率高,缺点是只能处理整型数据且要求数据相对集中。将哈希与位图结合,即布隆过滤器。
位图是要把一个数据通过一个哈希函数映射到一个位置,判断在不在;布隆过滤器是要把一个数据通过多个哈希函数映射到多个位置,降低误判率,判断一定不在或可能在
布隆过滤器
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
模拟实现
哈希函数个数的选择
哈希函数个数越多,布隆过滤器要开的bit位就越多,内存占用更大,则布隆过滤器bit位置为1的速度越快,但是效率变低;个数过少的话,误报率会变高。
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
计算公式为k=m/n∗ln(2)k = m / n * ln(2)k=m/n∗ln(2)以及m=−n∗ln(p)/ln2/ln2m = -n*ln(p) / ln2 / ln2m=−n∗ln(p)/ln2/ln2
第一个公式可以得出m=k∗n/ln2m = k * n / ln2m=k∗n/ln2,当我们用3个哈希函数时,布隆过滤器的长度为3∗n/ln2≈4.33n3*n/ln2 ≈ 4.33n3∗n/ln2≈4.33n。
在代码中,我们直接取5n,代码中为X == 5,可以更改。
struct BKDRHashFunc
{size_t operator()(const std::string& key){size_t hash = 0;for (auto ch : key){hash *= 131;hash += ch;}return hash;}
};struct APHashFunc
{size_t operator()(const std::string& key){size_t hash = 0;const char* str = key.c_str();for (int i = 0; *str; i++){if ((i & 1) == 0){hash ^= ((hash << 7) ^ (*str++) ^ (hash >> 3));}else{hash ^= (~(hash << 11) ^ (*str++) ^ (hash >> 5));}}return hash;}
};struct DJBHashFunc
{size_t operator()(const std::string& key){size_t hash = 5381;const char* str = key.c_str();while (*str){hash += (hash << 5) + (*str++);}return hash;}
};// N是最多存储的数据个数
// 平均存储一个值,开辟X个位
template<size_t N, size_t X = 5, class K = std::string, class HashFunc1 = BKDRHashFunc, class HashFunc2 = APHashFunc, class HashFunc3 = DJBHashFunc>
class BloomFilter
{public:void set(const K& key){//3个哈希函数映射size_t hashi1 = HashFunc1()(key) % (X * N);size_t hashi2 = HashFunc2()(key) % (X * N);size_t hashi3 = HashFunc3()(key) % (X * N);_bs.set(hashi1);_bs.set(hashi2);_bs.set(hashi3);}bool test(const K& key){//3个哈希函数映射size_t hashi1 = HashFunc1()(key) % (X * N);if (!_bs.test(hashi1)){//如果通过一个映射值不在,那肯定不在return false;}size_t hashi2 = HashFunc2()(key) % (X * N);if (!_bs.test(hashi1)){//如果通过一个映射值不在,那肯定不在return false;}size_t hashi3 = HashFunc3()(key) % (X * N);if (!_bs.test(hashi1)){//如果通过一个映射值不在,那肯定不在return false;}//前三个映射值都存在,那么key可能在(有可能三个位置都冲突)return true;}private:std::bitset<N * X> _bs;
};
测试误判率
void test_bloomfilter2()
{srand(time(0));const size_t N = 100000;BloomFilter<N> bf;std::vector<std::string> v1;std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.set(str);}// v2跟v1是相似字符串集,但是不一样std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";url += std::to_string(999999 + i);v2.push_back(url);}size_t n2 = 0;for (auto& str : v2){if (bf.test(str)){++n2;}}std::cout << "相似字符串误判率:" << (double)n2 / (double)N << std::endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){std::string url = "zhihu.com";url += std::to_string(i + rand());v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.test(str)){++n3;}}std::cout << "不相似字符串误判率:" << (double)n3 / (double)N << std::endl;
}
不支持reset
因为某一位可能被多个值映射,有冲突。把这个位reset掉,可能导致真的在的key就变成不在了。
面试题
1、给定100亿个整数,设计算法找到只出现一次的整数
位图要完成的事情是在不在,只需要2种状态==>1个比特位,char的8个比特位可以表示8个数的状态。而这道题需要3种状态(0:00、1:01、n:10)==>2个比特位,char的8个比特位可以表示4个数的状态。
开两个位图,两个位图的相同的位置可以用0和1表示,当这个数出现第1次,第一个位图对应位置置1;第2次及以上次出现,第2个位图对应位置置1。
要筛选出现1次的整数,就用2个位图;要筛选出现2次的整数,就用3个位图,以此类推。
template<size_t N>class twobitset{public:void set(size_t x)//将某位做标记{ if (!_bits1.test(x) && !_bits2.test(x))//00{_bits2.set(x);}else if (!_bits1.test(x) && _bits2.test(x))//01{_bits2.reset(x);_bits1.set(x); //10}else//10{//啥也不做}}private:std::bitset<N> _bits1;std::bitset<N> _bits2;};
}
2、给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集
两个文件的话,每个文件分别使用一个位图,此时位图对应的功能就包括去重+交集。两个位图位置都为1,就是两个文件的交集。
3、位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数。
int的最大值为24亿多,找不超过两次的,要用到2个位图4种状态(00\01\10\11),然后要过滤掉00和11这两个状态对应的数据
4、给一个超过100G大小的log文件, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
ip是这样的127.0.0.1一个字符串。位图只能解决K问题(在不在),不能解决KV问题(多少次)。这里要求出现次数最多的,只能采用map来解决问题,100G大小肯定放不进去内存,我们利用哈希切割,先将文件分为100个小文件(注意不是平均分割),将每个小文件当作一个哈希桶,用函数将ip转成整型,i = HashFunc(ip) % 100,i冲突的ip就会进入对应i号文件,那同一类ip就会进入同一个文件(相同的值一定会进入同一个文件,当然也会有哈希冲突的值),再对每个文件进行map统计出现次数。
如果:单个小文件超过1G,说明这个小文件里冲突的ip很多,a.大多是不同的ip/b.大多是相同的ip,该如何处理?
a.大多是不同的ip的情况,用map肯定无法完全统计,换个字符串哈希转换函数,递归再切分。
b.大多是相同的ip的情况,用map可以统计,大不了再用外排序。
如果map的insert失败,就表示没有内存了,相当于new节点失败,new失败会抛异常,就按a来处理。
5、给两个文件(A、B),分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
query是查询指令,比如可能是一个网页请求或者是一个数据库sql语句。
精确算法:假设每个query指令是50字节,那100亿个query大小约为500GB。将这些数据分到1000个小文件(Axx、Bxx),每个文件约0.5GB。每个小文件是通过同一个哈希函数,对应编号的文件里的数据大多是差不多的,把数据去个重,然后A01和B01分别用哈希表求交集,…A99和B99分别求交集。若小文件超过1GB,就再换个哈希函数再切分。
近似算法:用布隆过滤器,先把一个文件过一遍布隆过滤器,另一个文件来判断一下有哪些在。
6、如何扩展BloomFilter使得它支持删除元素的操作
计数器,有几个值映射到这个位,这个位就是几,当要求reset时,这个位置的值–。但是要实现计数的功能,映射位置就不能再使用一个位标记,而是需要多个位存储计数值,空间消耗成倍增加。故此方案在实际中不会被使用,还不如用哈希表。
相关文章:

位图及布隆过滤器的模拟实现与面试题
位图 模拟实现 namespace yyq {template<size_t N>class bitset{public:bitset(){_bits.resize(N / 8 1, 0);//_bits.resize((N >> 3) 1, 0);}void set(size_t x)//将某位做标记{size_t i x / 8; //第几个char对象size_t j x % 8; //这个char对象的第几个比特…...

在 Python 中将天数添加到日期
使用 datetime 模块中的 timedelta() 方法将天数添加到日期中,例如 result_1 date_1 timedelta(days3)。 timedelta 方法可以传递天数参数并将指定的天数添加到日期。 from datetime import datetime, date, timedelta# ✅ 将天数添加到日期 my_str 09-24-2023 …...

vue3知识点
一、vue3带来了什么? 1.性能的提升 打包大小减少41% 初次渲染快55%,更新渲染快133% 内存减少54% 2.源码的升级 使用Proxy代替defineProperty实现响应式 重写虚拟DOM的实现和Tree-shaking 3.拥抱TypeScript Vue3可以更好的支持TypeScript 4.新的特性 4.1.…...
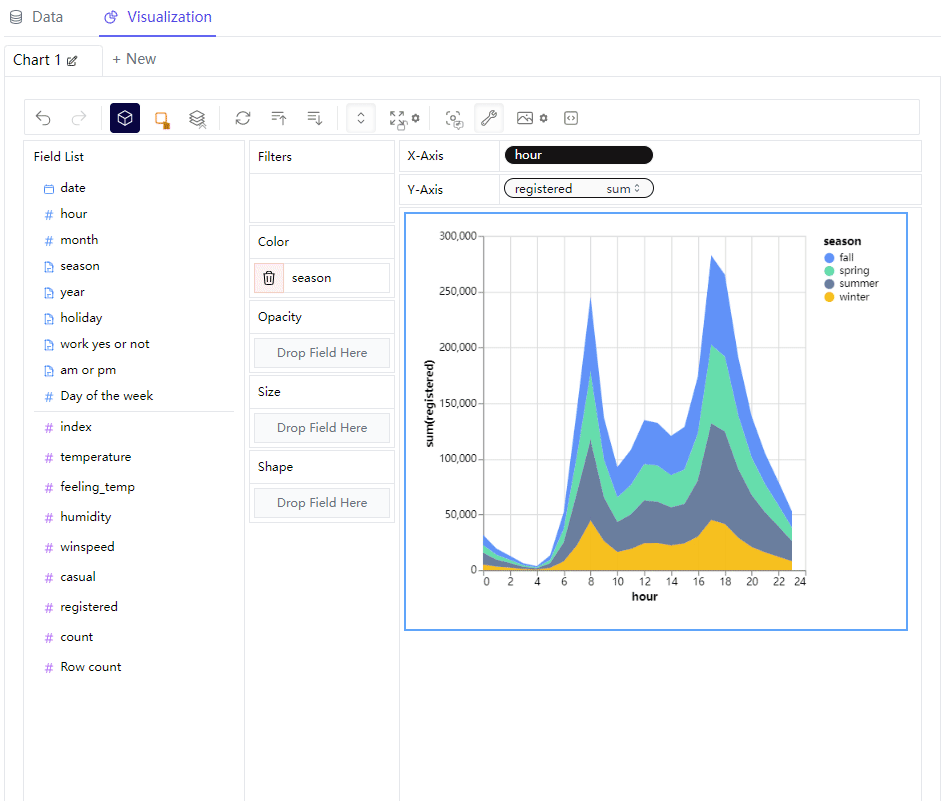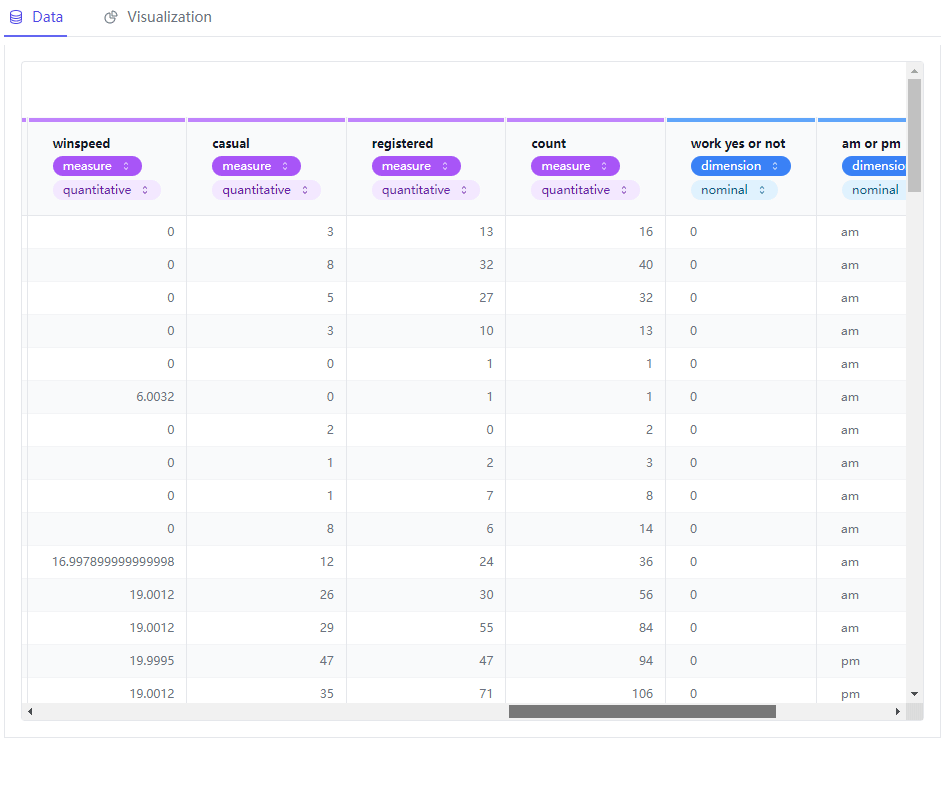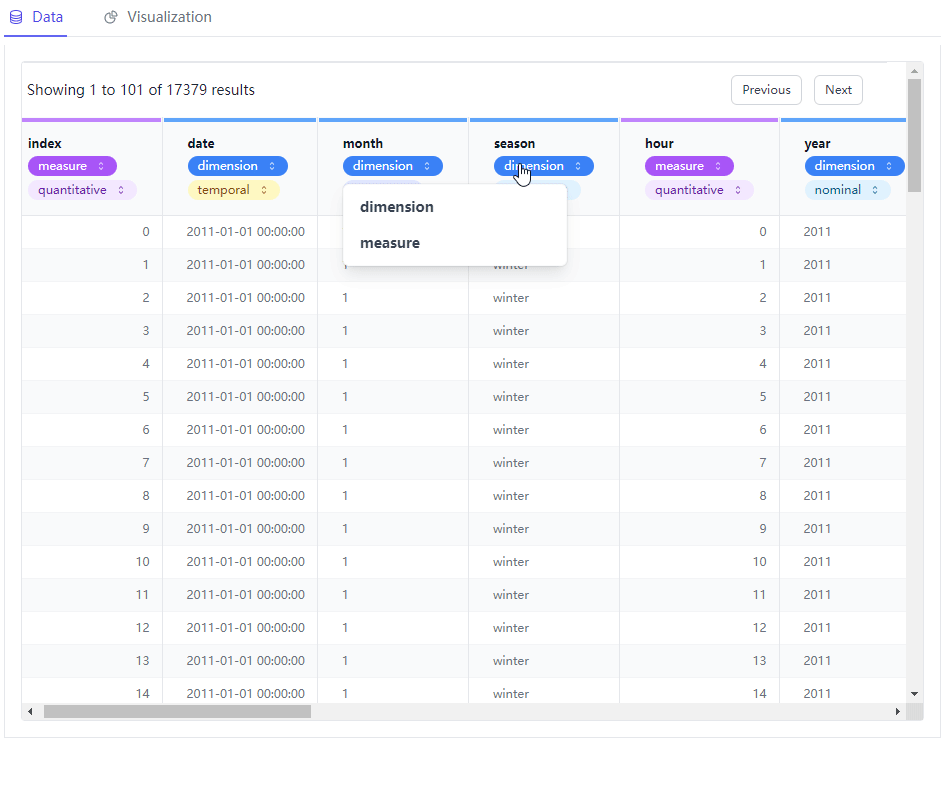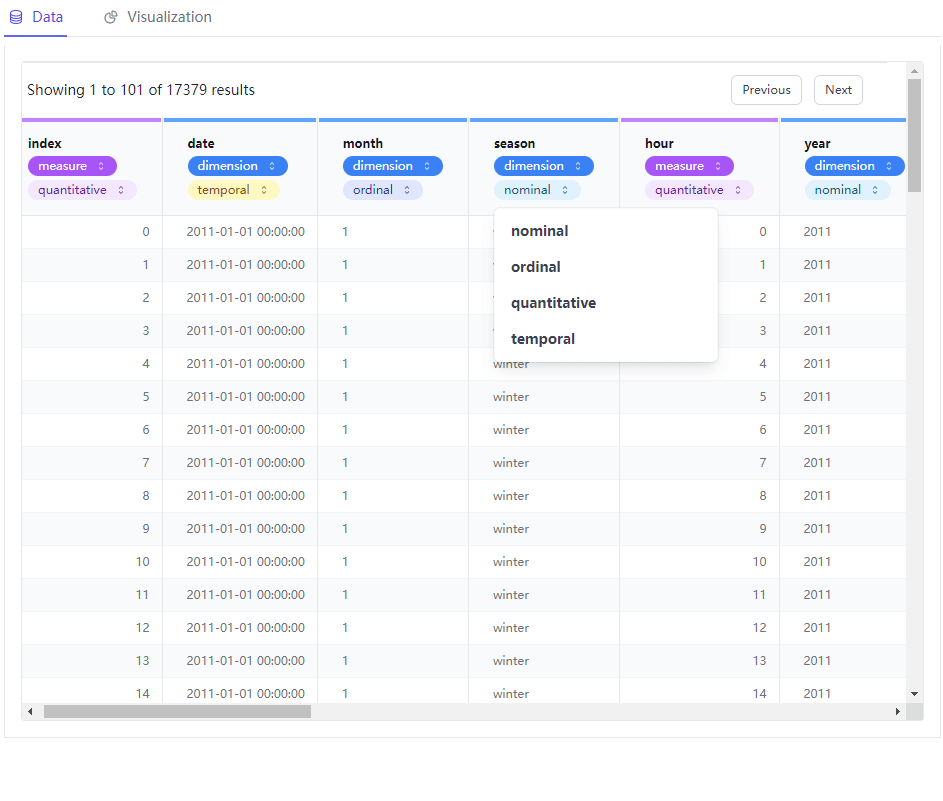
一行代码生成Tableau可视化图表
今天给大家介绍一个十分好用的Python模块,用来给数据集做一个初步的探索性数据分析(EDA),有着类似Tableau的可视化界面,我们通过对于字段的拖拽就可以实现想要的可视化图表,使用起来十分的简单且容易上手,学习成本低&a…...
)
链表——删除元素或插入元素(头插法及尾插法)
目录 链表的结点由一个结构体构成 判断链表是否为空 键盘输入链表中的数据 输出链表中的数据 返回链表的元素个数 清空链表 返回指定位置的元素值 查找数据所在位置 删除链表的元素 插入元素 建立无头结点的单链表 建立有头结点的单链表(头插法ÿ…...

oracle容器的使用
oracle容器的使用 1.下载oracle容器 1.1拉取容器 docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g拉取国内镜像,该镜像大小为2.99G,已经集成了oracle环境,拉取完可以直接用,推荐使用这款oracle镜像 1.2查看…...

基于springboot会员制医疗预约服务管理信息系统演示【附项目源码】
基于springboot会员制医疗预约服务管理信息系统演示开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea M…...

GoogleAdsense国内加载慢怎么解决?
一淘模板 56admin.com 发现GoogleAdsense(谷歌广告联盟)国内加载慢拖网站速度怎么解决?GoogleAdsense是谷歌旗下的站长广告联盟系统,如果站长没有好的变现渠道,挂谷歌联盟是最好的选择(日积月累)…...
【MySQL专题】03、性能优化之读写分离(MaxScale)
在我们了解了MySQL的主从复制的性能优化之后,紧接着《【MySQL专题】02、性能优化之主从复制》中,我们提及的读写分离,来进行读操作和写操作分散到不同的服务器结构中,同时希望对多个从服务器能提供负载均衡,读写分离和…...
Redis7高级之BigKey(二)
1.MoreKey案例 往redis里面插入大量测试数据key 生成100W条redis批量设置kv的语句保存在redisTest.txt for((i1;i<100*10000;i)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done; # 生成100W条redis批量设置kv的语句(keykn,valuevn)写入到/tmp目录下的…...

flex弹性盒子
概念 弹性盒子是一种用于按行或者按列布局的一维布局方法,元素可以膨胀以填充额外的空间,缩小以适应更小的空间 以下属性是给父元素添加的 1.flex-direction --改变轴的方向 row 默认值 默认沿着x轴排版(横向从左到右排列(左对齐ÿ…...

[Java Web]Cookie | 一文详细介绍会话跟踪技术中的Cookie
⭐作者介绍:大二本科网络工程专业在读,持续学习Java,努力输出优质文章 ⭐作者主页:逐梦苍穹 ⭐所属专栏:Java Web 目录Cookie1、工作原理2、如何使用2.1、发送Cookie2.2、获取Cookie3、Cookie的存活时间4、中文错误Coo…...

这可能是2023最全的Java面试八股文,共计1658页,Java技术手册的天花板
前两天有个小伙伴在后台留言,最近的面试越来越难了,尤其是技术面,考察得越来越细,越来越底层,庆幸的是最终顺利找到了工作。 一般技术面试官都会通过自己的方式去考察程序员的技术功底与基础理论知识 比如果这样的问题…...
字节流及存放本地文件上传和下载文件
前言 之前的文章有写过 vuespringboot使用文件流实现文件下载 实现如何通过 D:\file\文件名.文件格式的形式进行下载文件 但是它对于很多业务场景相对适用性不是很广泛。 以及 elementUI加springboot实现上传excel文件给后端并读取excel 也只能是通过elementui的元素类型进行…...

【翻译】下一步:Go 泛型
原文地址: The Next Step for Generics - The Go Blog https://blog.golang.org/generics-next-step 介绍 自从我们上次写下关于在Go中加入泛型的可能性的文章以来,已经快一年了。现在是该更新的时候了。 设计的更新 我们一直在继续完善泛型设计草案。…...
如何简单实现ELT?
在商业中,数据通常和业务、企业前景以及财务状况相关,有效的数据管理可以帮助决策者快速有效地从大量数据中分析出有价值的信息。数据集成(Data Integration)是整个数据管理流程中非常重要的一环,它是指将来自多个数据源的数据组合在一起&…...
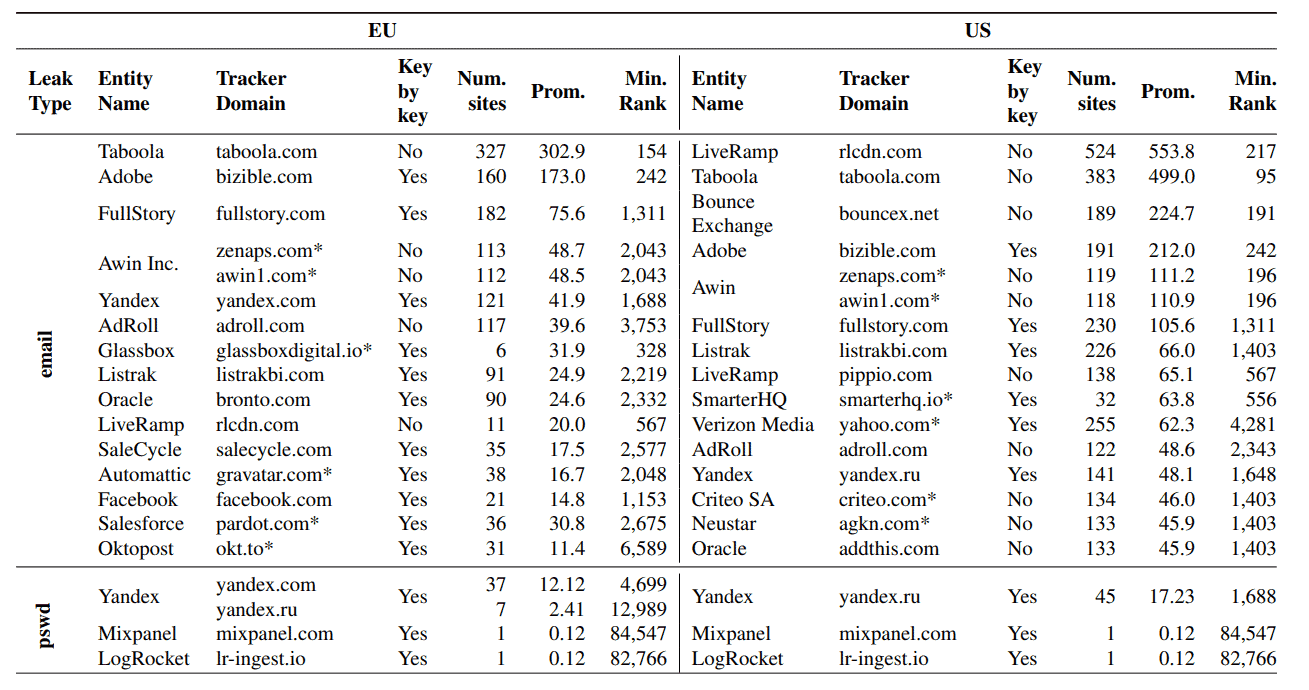
细思极恐,第三方跟踪器正在获取你的数据,如何防范?
细思极恐,第三方跟踪器正在获取你的数据,如何防范? 当下,许多网站都存在一些Web表单,比如登录、注册、评论等操作需要表单。我们都知道,我们在冲浪时在网站上键入的数据会被第三方跟踪器收集。但是&#x…...
-----点点滴滴的积累)
Java基础之==,equal的区别(温故而知新)-----点点滴滴的积累
1. 为运算符,equal 为String数据类型的比较方法;相同内容的对象地址不一定相同,但相相同地址的对象内容一定相同; 比较的是值是否相等,equal比较的是是否是同一个对象。 2.基本概念不同 1)对于,…...

SpringBoot项目使用切面编程实现数据权限管理
springBoot项目使用切面编程实现数据权限管理什么是数据权限管理如何实现数据权限管理什么是数据权限管理 不同用户在某页面看到数据不一致,实现每个用户之间数据隔离的效果。 如以下场景: ● 页面期望展示当前登录人所在部门的数据。 ● 页面期望展示当…...

亚马逊测评是做什么的,风险有哪些?
自养号测评顾名思义就是自己养国外的买家账号给自己店铺提升销量和评论,做过多年的跨境卖家都知道测评可以快速提高产品的排名、权重和销量,(国内某宝一样的逻辑)但随着测评需求日益增大,卖家在寻求真人测评时也很容易…...

双碳目标下太阳辐射预报模式【WRF-SOLAR】模拟方法及改进技术在气象、农林生态、电力等相关领域中的实践应用
太阳能是一种清洁能源,合理有效开发太阳能资源对减少污染、保护环境以及应对气候变化和能源安全具有非常重要的实际意义,为了实现能源和环境的可持续发展,近年来世界各国都高度重视太阳能资源的开发利用;另外太阳辐射的光谱成分、…...

在 Taotoken 上观测多模型 API 调用用量与成本明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 上观测多模型 API 调用用量与成本明细 对于使用多个大模型 API 的开发者而言,清晰、透明地掌握调用情况和…...

如何3步永久保存QQ空间十年回忆:GetQzonehistory数据备份实战指南
如何3步永久保存QQ空间十年回忆:GetQzonehistory数据备份实战指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字记忆时代,QQ空间承载了无数人的青春印记…...

HoYo.Gacha终极指南:如何轻松管理你的米哈游抽卡记录
HoYo.Gacha终极指南:如何轻松管理你的米哈游抽卡记录 【免费下载链接】HoYo.Gacha ✨ 一个非官方的工具,用于管理和分析你的 miHoYo 抽卡记录。(原神 | 崩坏:星穹铁道 | 绝区零)An unofficial tool for managing and a…...

Sora 2 + Premiere = 新一代“AI剪辑OS”?深度拆解其MediaCore架构、Timeline Graph API及动态权重调度算法
更多请点击: https://intelliparadigm.com 第一章:Sora 2 Premiere 新一代“AI剪辑OS”?概念演进与范式重构 传统视频编辑正经历一场静默但深刻的底层迁移——当 Sora 2 的原生时空建模能力与 Adobe Premiere Pro 的专业时间线引擎深度耦合…...
)
WinHex不只是编辑器:手把手教你用它做磁盘镜像与克隆(避坑指南)
WinHex专业磁盘镜像与克隆实战指南:从取证备份到避坑技巧 1. 为什么WinHex是磁盘操作的首选利器 在数据恢复和取证领域,专业工具的选择往往决定了工作的成败。WinHex作为一款久经考验的十六进制编辑器,其功能远超出普通用户的想象。不同于常规…...
)
【权威发布】Midjourney V6结构提示词标准白皮书(含官方未公开的4类语法优先级矩阵与37个避坑节点)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6结构提示词的核心演进与范式变革 Midjourney V6 标志着生成式图像模型在语义理解与结构化表达上的重大跃迁。其提示词(prompt)系统不再仅依赖关键词堆叠࿰…...

物联网服务选型指南:从核心模块解析到实战避坑
1. 物联网服务选型:从数据孤岛到智能系统的桥梁在物联网项目里摸爬滚打了十几年,我见过太多项目卡在“服务选型”这个环节。很多工程师朋友,硬件玩得转,代码写得溜,但一到要把设备连上网,让数据跑起来&…...

告别重复操作:M9A如何用智能自动化重塑《重返未来:1999》游戏体验
告别重复操作:M9A如何用智能自动化重塑《重返未来:1999》游戏体验 【免费下载链接】M9A 重返未来:1999 小助手 | Assistant For Reverse: 1999 项目地址: https://gitcode.com/gh_mirrors/m9/M9A 在当今快节奏的生活中,游戏…...

ComfyUI-Inpaint-CropAndStitch:如何用局部修复技术将AI图像处理速度提升100倍
ComfyUI-Inpaint-CropAndStitch:如何用局部修复技术将AI图像处理速度提升100倍 【免费下载链接】ComfyUI-Inpaint-CropAndStitch ComfyUI nodes to crop before sampling and stitch back after sampling that speed up inpainting 项目地址: https://gitcode.com…...