一文搞懂 Flink Graph 构建过程源码
一文搞懂 Flink Graph 构建过程
- 1. StreamGraph构建过程
- 1.1 transform(): 构建的核心
- 1.2 transformOneInputTransform
- 1.3 构造顶点
- 1.4 构造边
- 1.5 transformSource
- 1.6 transformPartition
- 1.7 transformSink
1. StreamGraph构建过程
链接: 一文搞懂 Flink 其他重要源码点击我
env.execute将进行任务的提交和执行,在执行之前会对任务进行StreamGraph和JobGraph的构建,然后再提交JobGraph。
那么现在就来分析一下StreamGraph的构建过程,在正式环境下,会调用StreamContextEnvironment.execute()方法:
public JobExecutionResult execute(String jobName) throws Exception {Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");// 获取 StreamGraphreturn execute(getStreamGraph(jobName));
}public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {// 构建StreamGraphStreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();if (clearTransformations) {// 构建完StreamGraph之后,可以清空transformations列表this.transformations.clear();}return streamGraph;
}
实现在StreamGraphGenerator.generate(this, transformations);这里的transformations列表就是在之前调用map、flatMap、filter算子时添加进去的生成的DataStream的StreamTransformation,是DataStream的描述信息。
接着看:
public StreamGraph generate() {// 实例化 StreamGraphstreamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);streamGraph.setStateBackend(stateBackend);streamGraph.setChaining(chaining);streamGraph.setScheduleMode(scheduleMode);streamGraph.setUserArtifacts(userArtifacts);streamGraph.setTimeCharacteristic(timeCharacteristic);streamGraph.setJobName(jobName);streamGraph.setGlobalDataExchangeMode(globalDataExchangeMode);// 记录了已经transformed的StreamTransformation。alreadyTransformed = new HashMap<>();for (Transformation<?> transformation: transformations) {// 根据 transformation 创建StreamGraphtransform(transformation);}final StreamGraph builtStreamGraph = streamGraph;alreadyTransformed.clear();alreadyTransformed = null;streamGraph = null;return builtStreamGraph;
}
1.1 transform(): 构建的核心
private Collection<Integer> transform(Transformation<?> transform) {if (alreadyTransformed.containsKey(transform)) {return alreadyTransformed.get(transform);}LOG.debug("Transforming " + transform);if (transform.getMaxParallelism() <= 0) {// if the max parallelism hasn't been set, then first use the job wide max parallelism// from the ExecutionConfig.int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();if (globalMaxParallelismFromConfig > 0) {transform.setMaxParallelism(globalMaxParallelismFromConfig);}}// call at least once to trigger exceptions about MissingTypeInfotransform.getOutputType();Collection<Integer> transformedIds;// 判断 transform 属于哪类 Transformationif (transform instanceof OneInputTransformation<?, ?>) {transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform);} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);} else if (transform instanceof AbstractMultipleInputTransformation<?>) {transformedIds = transformMultipleInputTransform((AbstractMultipleInputTransformation<?>) transform);} else if (transform instanceof SourceTransformation) {transformedIds = transformSource((SourceTransformation<?>) transform);} else if (transform instanceof LegacySourceTransformation<?>) {transformedIds = transformLegacySource((LegacySourceTransformation<?>) transform);} else if (transform instanceof SinkTransformation<?>) {transformedIds = transformSink((SinkTransformation<?>) transform);} else if (transform instanceof UnionTransformation<?>) {transformedIds = transformUnion((UnionTransformation<?>) transform);} else if (transform instanceof SplitTransformation<?>) {transformedIds = transformSplit((SplitTransformation<?>) transform);} else if (transform instanceof SelectTransformation<?>) {transformedIds = transformSelect((SelectTransformation<?>) transform);} else if (transform instanceof FeedbackTransformation<?>) {transformedIds = transformFeedback((FeedbackTransformation<?>) transform);} else if (transform instanceof CoFeedbackTransformation<?>) {transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);} else if (transform instanceof PartitionTransformation<?>) {transformedIds = transformPartition((PartitionTransformation<?>) transform);} else if (transform instanceof SideOutputTransformation<?>) {transformedIds = transformSideOutput((SideOutputTransformation<?>) transform);} else {throw new IllegalStateException("Unknown transformation: " + transform);}// need this check because the iterate transformation adds itself before// transforming the feedback edgesif (!alreadyTransformed.containsKey(transform)) {alreadyTransformed.put(transform, transformedIds);}if (transform.getBufferTimeout() >= 0) {streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout());} else {streamGraph.setBufferTimeout(transform.getId(), defaultBufferTimeout);}if (transform.getUid() != null) {streamGraph.setTransformationUID(transform.getId(), transform.getUid());}if (transform.getUserProvidedNodeHash() != null) {streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash());}if (!streamGraph.getExecutionConfig().hasAutoGeneratedUIDsEnabled()) {if (transform instanceof PhysicalTransformation &&transform.getUserProvidedNodeHash() == null &&transform.getUid() == null) {throw new IllegalStateException("Auto generated UIDs have been disabled " +"but no UID or hash has been assigned to operator " + transform.getName());}}if (transform.getMinResources() != null && transform.getPreferredResources() != null) {streamGraph.setResources(transform.getId(), transform.getMinResources(), transform.getPreferredResources());}streamGraph.setManagedMemoryWeight(transform.getId(), transform.getManagedMemoryWeight());return transformedIds;
}
拿WordCount举例,在flatMap、map、reduce、addSink过程中会将生成的DataStream的StreamTransformation添加到transformations列表中。
addSource没有将StreamTransformation添加到transformations,但是flatMap生成的StreamTransformation的input持有SourceTransformation的引用。
keyBy算子会生成KeyedStream,但是它的StreamTransformation并不会添加到transformations列表中,不过reduce生成的DataStream中的StreamTransformation中持有了KeyedStream的StreamTransformation的引用,作为它的input。
所以,WordCount中有4个StreamTransformation,前3个算子均为OneInputTransformation,最后一个为SinkTransformation。
1.2 transformOneInputTransform
由于transformations中第一个为OneInputTransformation,所以代码首先会走到transformOneInputTransform((OneInputTransformation<?, ?>) transform)
private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) {//首先递归的transform该OneInputTransformation的inputCollection<Integer> inputIds = transform(transform.getInput());//如果递归transform input时发现input已经被transform,那么直接获取结果即可// the recursive call might have already transformed thisif (alreadyTransformed.containsKey(transform)) {return alreadyTransformed.get(transform);}//获取共享slot资源组,默认分组名”default”String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds);//将该StreamTransformation添加到StreamGraph中,当做一个顶点streamGraph.addOperator(transform.getId(),slotSharingGroup,transform.getCoLocationGroupKey(),transform.getOperator(),transform.getInputType(),transform.getOutputType(),transform.getName());if (transform.getStateKeySelector() != null) {TypeSerializer<?> keySerializer = transform.getStateKeyType().createSerializer(env.getConfig());streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer);}//设置顶点的并行度和最大并行度streamGraph.setParallelism(transform.getId(), transform.getParallelism());streamGraph.setMaxParallelism(transform.getId(), transform.getMaxParallelism());//根据该StreamTransformation有多少个input,依次给StreamGraph添加边,即input——>currentfor (Integer inputId: inputIds) {streamGraph.addEdge(inputId, transform.getId(), 0);}//返回该StreamTransformation的id,OneInputTransformation只有自身的一个id列表return Collections.singleton(transform.getId());
}
transformOneInputTransform()方法的实现如下:
1、先递归的transform该OneInputTransformation的input,如果input已经transformed,那么直接从map中取数据即可
2、将该StreamTransformation作为一个图的顶点添加到StreamGraph中,并设置顶点的并行度和共享资源组
3、根据该StreamTransformation的input,构造图的边,有多少个input,就会生成多少边,不过OneInputTransformation顾名思义就是一个input,所以会构造一条边,即input——>currentId
1.3 构造顶点
//StreamGraph类
public <IN, OUT> void addOperator(Integer vertexID,String slotSharingGroup,@Nullable String coLocationGroup,StreamOperator<OUT> operatorObject,TypeInformation<IN> inTypeInfo,TypeInformation<OUT> outTypeInfo,String operatorName) {//将StreamTransformation作为一个顶点,添加到streamNodes中if (operatorObject instanceof StoppableStreamSource) {addNode(vertexID, slotSharingGroup, coLocationGroup, StoppableSourceStreamTask.class, operatorObject, operatorName);} else if (operatorObject instanceof StreamSource) {//如果operator是StreamSource,则Task类型为SourceStreamTaskaddNode(vertexID, slotSharingGroup, coLocationGroup, SourceStreamTask.class, operatorObject, operatorName);} else {//如果operator不是StreamSource,Task类型为OneInputStreamTaskaddNode(vertexID, slotSharingGroup, coLocationGroup, OneInputStreamTask.class, operatorObject, operatorName);}TypeSerializer<IN> inSerializer = inTypeInfo != null && !(inTypeInfo instanceof MissingTypeInfo) ? inTypeInfo.createSerializer(executionConfig) : null;TypeSerializer<OUT> outSerializer = outTypeInfo != null && !(outTypeInfo instanceof MissingTypeInfo) ? outTypeInfo.createSerializer(executionConfig) : null;setSerializers(vertexID, inSerializer, null, outSerializer);if (operatorObject instanceof OutputTypeConfigurable && outTypeInfo != null) {@SuppressWarnings("unchecked")OutputTypeConfigurable<OUT> outputTypeConfigurable = (OutputTypeConfigurable<OUT>) operatorObject;// sets the output type which must be know at StreamGraph creation timeoutputTypeConfigurable.setOutputType(outTypeInfo, executionConfig);}if (operatorObject instanceof InputTypeConfigurable) {InputTypeConfigurable inputTypeConfigurable = (InputTypeConfigurable) operatorObject;inputTypeConfigurable.setInputType(inTypeInfo, executionConfig);}if (LOG.isDebugEnabled()) {LOG.debug("Vertex: {}", vertexID);}
}protected StreamNode addNode(Integer vertexID,String slotSharingGroup,@Nullable String coLocationGroup,Class<? extends AbstractInvokable> vertexClass,StreamOperator<?> operatorObject,String operatorName) {if (streamNodes.containsKey(vertexID)) {throw new RuntimeException("Duplicate vertexID " + vertexID);}//构造顶点,添加到streamNodes中,streamNodes是一个MapStreamNode vertex = new StreamNode(environment,vertexID,slotSharingGroup,coLocationGroup,operatorObject,operatorName,new ArrayList<OutputSelector<?>>(),vertexClass);// 添加到 streamNodesstreamNodes.put(vertexID, vertex);return vertex;
}
1.4 构造边
public void addEdge(Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber) {addEdgeInternal(upStreamVertexID,downStreamVertexID,typeNumber,null, //这里开始传递的partitioner都是nullnew ArrayList<String>(),null //outputTag对侧输出有效);}private void addEdgeInternal(Integer upStreamVertexID,Integer downStreamVertexID,int typeNumber,StreamPartitioner<?> partitioner,List<String> outputNames,OutputTag outputTag) {if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {//针对侧输出int virtualId = upStreamVertexID;upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;if (outputTag == null) {outputTag = virtualSideOutputNodes.get(virtualId).f1;}addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag);} else if (virtualSelectNodes.containsKey(upStreamVertexID)) {int virtualId = upStreamVertexID;upStreamVertexID = virtualSelectNodes.get(virtualId).f0;if (outputNames.isEmpty()) {// selections that happen downstream override earlier selectionsoutputNames = virtualSelectNodes.get(virtualId).f1;}addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {//keyBy算子产生的PartitionTransform作为下游的input,下游的StreamTransformation添加边时会走到这int virtualId = upStreamVertexID;upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;if (partitioner == null) {partitioner = virtualPartitionNodes.get(virtualId).f1;}addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);} else {//一般的OneInputTransform会走到这里StreamNode upstreamNode = getStreamNode(upStreamVertexID);StreamNode downstreamNode = getStreamNode(downStreamVertexID);// If no partitioner was specified and the parallelism of upstream and downstream// operator matches use forward partitioning, use rebalance otherwise.//如果上下顶点的并行度一致,则用ForwardPartitioner,否则用RebalancePartitionerif (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {partitioner = new ForwardPartitioner<Object>();} else if (partitioner == null) {partitioner = new RebalancePartitioner<Object>();}if (partitioner instanceof ForwardPartitioner) {if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {throw new UnsupportedOperationException("Forward partitioning does not allow " +"change of parallelism. Upstream operation: " + upstreamNode + " parallelism: " + upstreamNode.getParallelism() +", downstream operation: " + downstreamNode + " parallelism: " + downstreamNode.getParallelism() +" You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");}}//一条边包括上下顶点,顶点之间的分区器等信息StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber, outputNames, partitioner, outputTag);//分别给顶点添加出边和入边getStreamNode(edge.getSourceId()).addOutEdge(edge);getStreamNode(edge.getTargetId()).addInEdge(edge);}
}
边的属性包括上下游的顶点,和顶点之间的partitioner等信息。如果上下游的并行度一致,那么他们之间的partitioner是ForwardPartitioner,如果上下游的并行度不一致是RebalancePartitioner,当然这前提是没有设置partitioner的前提下。如果显示设置了partitioner的情况,例如keyBy算子,在内部就确定了分区器是KeyGroupStreamPartitioner,那么它们之间的分区器就是KeyGroupStreamPartitioner。
1.5 transformSource
上述说道,transformOneInputTransform会先递归的transform该OneInputTransform的input,那么对于WordCount中在transform第一个OneInputTransform时会首先transform它的input,也就是SourceTransformation,方法在transformSource()
private <T> Collection<Integer> transformSource(SourceTransformation<T> source) {String slotSharingGroup = determineSlotSharingGroup(source.getSlotSharingGroup(), Collections.emptyList());//将source作为图的顶点和图的source添加StreamGraph中streamGraph.addSource(source.getId(),slotSharingGroup,source.getCoLocationGroupKey(),source.getOperator(),null,source.getOutputType(),"Source: " + source.getName());if (source.getOperator().getUserFunction() instanceof InputFormatSourceFunction) {InputFormatSourceFunction<T> fs = (InputFormatSourceFunction<T>) source.getOperator().getUserFunction();streamGraph.setInputFormat(source.getId(), fs.getFormat());}//设置source的并行度streamGraph.setParallelism(source.getId(), source.getParallelism());streamGraph.setMaxParallelism(source.getId(), source.getMaxParallelism());//返回自身id的单列表return Collections.singleton(source.getId());
}//StreamGraph类
public <IN, OUT> void addSource(Integer vertexID,String slotSharingGroup,@Nullable String coLocationGroup,StreamOperator<OUT> operatorObject,TypeInformation<IN> inTypeInfo,TypeInformation<OUT> outTypeInfo,String operatorName) {addOperator(vertexID, slotSharingGroup, coLocationGroup, operatorObject, inTypeInfo, outTypeInfo, operatorName);sources.add(vertexID);
}
transformSource()逻辑也比较简单,就是将source添加到StreamGraph中,注意Source是图的根节点,没有input,所以它不需要添加边。
1.6 transformPartition
在WordCount中,由reduce生成的DataStream的StreamTransformation是一个OneInputTransformation,同样,在transform它的时候,会首先transform它的input,而它的input就是KeyedStream中生成的PartitionTransformation。所以代码会执行transformPartition((PartitionTransformation<?>) transform)
private <T> Collection<Integer> transformPartition(PartitionTransformation<T> partition) {StreamTransformation<T> input = partition.getInput();List<Integer> resultIds = new ArrayList<>();//首先会transform PartitionTransformation的inputCollection<Integer> transformedIds = transform(input);for (Integer transformedId: transformedIds) {//生成一个新的虚拟节点int virtualId = StreamTransformation.getNewNodeId();//将虚拟节点添加到StreamGraph中streamGraph.addVirtualPartitionNode(transformedId, virtualId, partition.getPartitioner());resultIds.add(virtualId);}return resultIds;
}//StreamGraph类
public void addVirtualPartitionNode(Integer originalId, Integer virtualId, StreamPartitioner<?> partitioner) {if (virtualPartitionNodes.containsKey(virtualId)) {throw new IllegalStateException("Already has virtual partition node with id " + virtualId);}// virtualPartitionNodes是一个Map,存储虚拟的Partition节点virtualPartitionNodes.put(virtualId,new Tuple2<Integer, StreamPartitioner<?>>(originalId, partitioner));
}
transformPartition会为PartitionTransformation生成一个新的虚拟节点,同时将该虚拟节点保存到StreamGraph的virtualPartitionNodes中,并且会保存该PartitionTransformation的input,将PartitionTransformation的partitioner作为其input的分区器,在WordCount中,也就是作为map算子生成的DataStream的分区器。
在进行transform reduce生成的OneInputTransform时,它的inputIds便是transformPartition时为PartitionTransformation生成新的虚拟节点,在添加边的时候会走到下面的代码。边的形式大致是OneInputTransform(map)—KeyGroupStreamPartitioner—>OneInputTransform(window)
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {//keyBy算子产生的PartitionTransform作为下游的input,下游的StreamTransform添加边时会走到这int virtualId = upStreamVertexID;upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;if (partitioner == null) {partitioner = virtualPartitionNodes.get(virtualId).f1;}addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);
1.7 transformSink
在WordCount中,transformations的最后一个StreamTransformation是SinkTransformation,方法在
transformSink()
private <T> Collection<Integer> transformSink(SinkTransformation<T> sink) {//首先transform inputCollection<Integer> inputIds = transform(sink.getInput());String slotSharingGroup = determineSlotSharingGroup(sink.getSlotSharingGroup(), inputIds);//给图添加sink,并且构造并添加图的顶点streamGraph.addSink(sink.getId(),slotSharingGroup,sink.getCoLocationGroupKey(),sink.getOperator(),sink.getInput().getOutputType(),null,"Sink: " + sink.getName());streamGraph.setParallelism(sink.getId(), sink.getParallelism());streamGraph.setMaxParallelism(sink.getId(), sink.getMaxParallelism());//构造并添加StreamGraph的边for (Integer inputId: inputIds) {streamGraph.addEdge(inputId,sink.getId(),0);}if (sink.getStateKeySelector() != null) {TypeSerializer<?> keySerializer = sink.getStateKeyType().createSerializer(env.getConfig());streamGraph.setOneInputStateKey(sink.getId(), sink.getStateKeySelector(), keySerializer);}//因为sink是图的末尾节点,没有下游的输出,所以返回空了return Collections.emptyList();
}
//StreamGraph类
public <IN, OUT> void addSink(Integer vertexID,String slotSharingGroup,@Nullable String coLocationGroup,StreamOperator<OUT> operatorObject,TypeInformation<IN> inTypeInfo,TypeInformation<OUT> outTypeInfo,String operatorName) {addOperator(vertexID, slotSharingGroup, coLocationGroup, operatorObject, inTypeInfo, outTypeInfo, operatorName);sinks.add(vertexID);
}
transformSink()中的逻辑也比较简单,和transformSource()类似,不同的是sink是有边的,而且sink的下游没有输出了,也就不需要作为下游的input,所以返回空列表。
在transformSink()之后,也就把所有的StreamTransformation的都进行transform了,那么这时候StreamGraph中的顶点、边、partition的虚拟顶点都构建好了,返回StreamGraph即可。下一步就是根据StreamGraph构造JobGraph了。
可以看出StreamGraph的结构还是比较简单的,每个DataStream的StreamTransformation会作为一个图的顶点(PartitionTransform是虚拟顶点),根据StreamTransformation的input来构建图的边。
相关文章:

一文搞懂 Flink Graph 构建过程源码
一文搞懂 Flink Graph 构建过程 1. StreamGraph构建过程1.1 transform(): 构建的核心1.2 transformOneInputTransform1.3 构造顶点1.4 构造边1.5 transformSource1.6 transformPartition1.7 transformSink 1. StreamGraph构建过程 链接: 一文搞懂 Flink 其他重要源码点击我 e…...
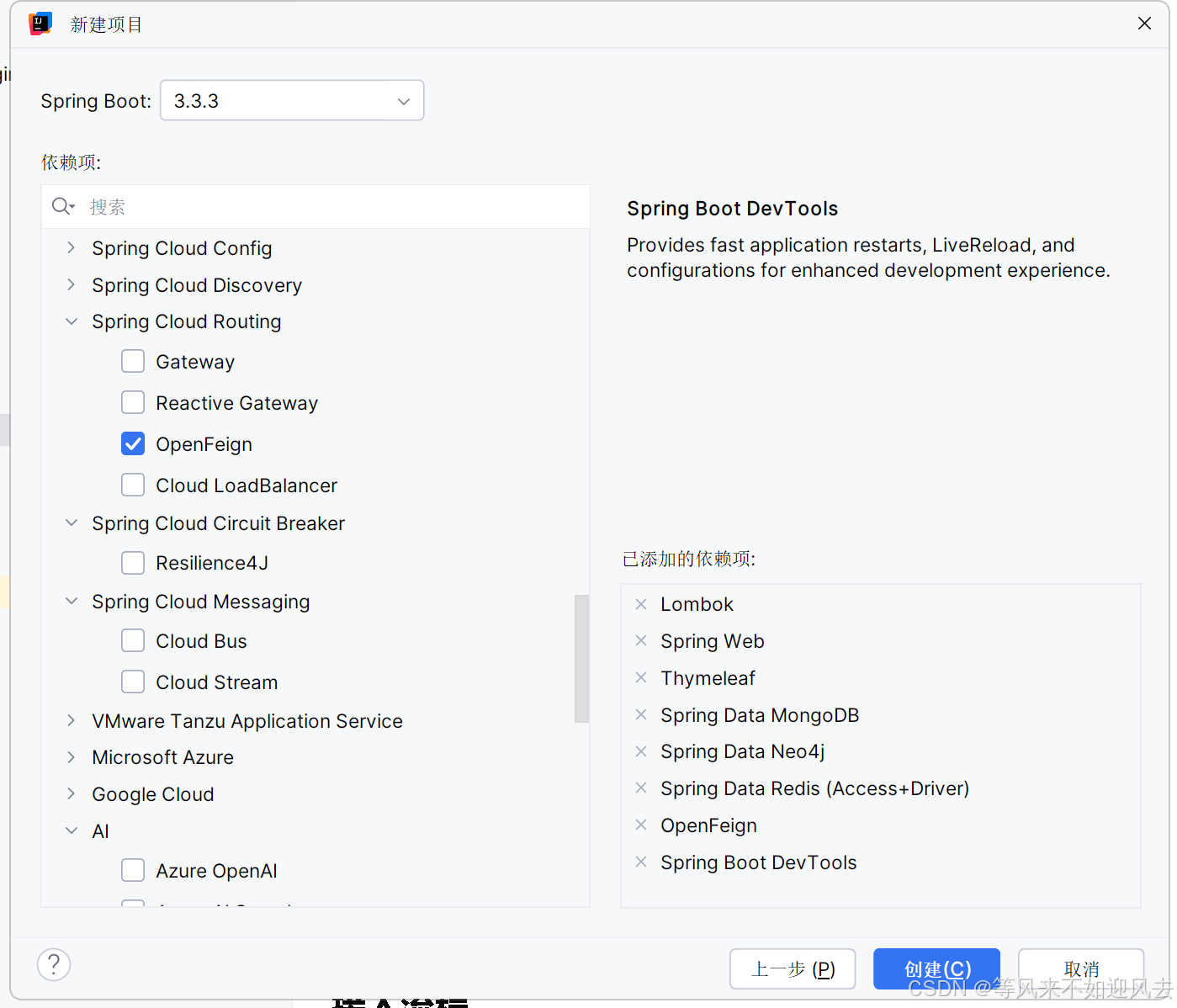
【spring】IDEA 新建一个spring boot 项目
参考新建项目-sprintboot 选择版本、依赖,我选了一堆 maven会重新下载一次么?...

LeetCode[简单] 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 思路:类似与二分查找 唯一需要注意的是,搜索…...
Bootstrap框架的HTML示例)
(代码可运行)Bootstrap框架的HTML示例
Bootstrap:一套流行的前端开发框架,基于HTML、CSS和JavaScript,适用于快速构建响应式Web应用。 以下是一个使用Bootstrap构建的简单响应式Web应用的HTML示例: <!DOCTYPE html> <html lang"en"> <head&…...

IntelliJ IDEA 2024创建Java项目
一、前言 本文将带领大家手把手创建纯Java项目,不涉及Maven。如有问题,欢迎大家在评论区指正说明! 二、环境准备 名称版本jdk1.8idea2024 1.4操作系统win10 jdk的安装教程 idea的安装教程 三、创建项目 首先我们点击新建项目 然后我们…...

Python之 条件与循环(Python‘s Conditions and loops)
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:Linux运维老纪的首页…...

C++学习,多态纯虚函数
多态字面意思是多种形态,当类之间存在层次结构,并且类之间是通过继承时,就会用到多态。多态允许通过基类指针或引用来调用派生类中的成员函数。这种机制允许函数,在运行时根据对象的实际类型来确定执行哪个函数,从而实…...

飞速(FS)与西门子联合打造交换机自动化灌装测试生产线
2024年9月,备受信赖的信息通信技术(ICT)解决方案提供商飞速(FS)与工业自动化领域的领先企业西门子公司正式宣布,双方共同打造的ILTP(智能灌装测试平台)和自动化生产线将正式启动。此…...

Vue组合式API:setup()函数
1、什么是组合式API Vue 3.0 中新增了组合式 API 的功能,它是一组附加的、基于函数的 API,可以更加灵活地组织组件代码。通过组合式 API 可以使用函数而不是声明选项的方式来编写 Vue 组件。因此,使用组合式 API 可以将组件代码编写为多个函…...

Redis底层数据结构(详细篇)
Redis底层数据结构 一、常见数据结构的底层数据结构1、动态字符串SDS(Simple Dynamic String)组成 2、IntSet组成如何保证动态如何确保有序呢? 底层如何查找的呢? 3、Dict(dictionary)3.1组成3.2 扩容3.3 收缩3.4 rehash 4、ZipList连锁更新问题总结特…...

树和二叉树基本术语、性质
总结二叉树的度、树高、结点数等属性之间的关系(通过王道书 5.2.3 课后小题来复习“二叉 树的性质”) 树的相关知识 叶子结点的度0 层次默认从1开始 有些题目从0 开始也不要奇怪 常见考点1:结点数总度数+1 常见考点2࿱…...

FEDERATED引擎
入门 MySQL引擎主要有以下几种: MyISAM:这是MySQL 5.5.5之前的默认存储引擎,不支持事务、外键约束和聚簇索引,适用于读多写少的场景。InnoDB:这是MySQL 5.5.5之后的默认存储引擎,支持事务、外键约束、行级…...

Android NDK工具
Android NDK工具 Android NDK Crash 日志抓取及定位 NDK-STACK 定位 NDK Crash 位置 只要执行如下代码就行: adb logcat | ndk-stack -sym /yourProjectPath/obj/local/armeabi-v7aPS: 必须是带symbols的so,也就是在’\app\src\main\obj\local\下面的…...

使用 Docker 进入容器并运行命令的详细指南
Docker 是一款开源的容器化平台,它可以将应用程序和依赖环境打包到一个可移植的“容器”中,以保证应用不受运行环境的影响。使用 Docker 容器化应用后,有时需要进入容器内部执行一些命令进行调试或管理。 一、Docker 基础命令 在开始进入容…...

【人工智能】OpenAI最新发布的o1-preview模型,和GPT-4o到底哪个更强?最新分析结果就在这里!
在人工智能的快速发展中,OpenAI的每一次新模型发布都引发了广泛的关注与讨论。2023年9月13日,OpenAI正式推出了名为o1的新模型,这一模型不仅是其系列“推理”模型中的首个代表,更是朝着类人人工智能迈进的重要一步。本文将综合分析…...

Spring Boot-版本兼容性问题
Spring Boot 版本兼容性问题探讨 Spring Boot 是一个用于构建微服务和现代 Java 应用的流行框架,随着 Spring Boot 版本的更新和发展,它在功能、性能和安全性上不断提升。但与此同时,Spring Boot 的版本兼容性问题也逐渐成为开发者必须关注的…...

Java原生HttpURLConnection实现Get、Post、Put和Delete请求完整工具类分享
这里博主纯手写了一个完整的 HTTP 请求工具类,该工具类支持多种请求方法,包括 GET、POST、PUT 和 DELETE,并且可以选择性地使用身份验证 token。亲测可用,大家可以直接复制并使用这段代码,以便在自己的项目中快速实现 HTTP 请求的功能。 目录 一、完整代码 二、调用示例…...

如何微调(Fine-tuning)大语言模型?
本文介绍了微调的基本概念,以及如何对语言模型进行微调。 从 GPT3 到 ChatGPT、从GPT4 到 GitHub copilot的过程,微调在其中扮演了重要角色。什么是微调(fine-tuning)?微调能解决什么问题?什么是 LoRA&…...

wopop靶场漏洞挖掘练习
1、SQL注入漏洞 1、在搜索框输入-1 union select 1,2,3# 2、输入-1 union select 1,2,database()# ,可以得出数据库名 3、输入-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schematest#,可以得出数据库中…...

探索Python的隐秘角落:Keylogger库的神秘面纱
文章目录 探索Python的隐秘角落:Keylogger库的神秘面纱背景:为何需要Keylogger?库简介:什么是Keylogger?安装指南:如何将Keylogger纳入你的项目?函数使用:5个简单函数的介绍与代码示…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生
终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否还…...

AI驱动博客平台CodeBlog-app:开发者技术分享的智能解决方案
1. 项目概述:一个为开发者而生的AI驱动博客平台最近在GitHub上看到一个挺有意思的开源项目,叫CodeBlog-ai/codeblog-app。光看名字,你可能会觉得这又是一个普通的博客系统,或者是一个AI写作工具。但当我深入去研究它的代码和设计理…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

如何用nmrpflash拯救你的Netgear路由器:从“变砖“到重生的完整指南
如何用nmrpflash拯救你的Netgear路由器:从"变砖"到重生的完整指南 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器固件升级失败、意外断电或系统崩溃后无法启动…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...