qwen2 VL 多模态图文模型;图像、视频使用案例
参考:
https://huggingface.co/Qwen/Qwen2-VL-2B-Instruct
模型:
export HF_ENDPOINT=https://hf-mirror.comhuggingface-cli download --resume-download --local-dir-use-symlinks False Qwen/Qwen2-VL-2B-Instruct --local-dir qwen2-vl
安装:
transformers-4.45.0.dev0
accelerate-0.34.2 safetensors-0.4.5
pip install git+https://github.com/huggingface/transformers
pip install 'accelerate>=0.26.0'
代码:
单张图片
from PIL import Image
import requests
import torch
from torchvision import io
from typing import Dict
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor# Load the model in half-precision on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained("/ai/qwen2-vl", torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("/ai/qwen2-vl")# Image
url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
image = Image.open(requests.get(url, stream=True).raw)conversation = [{"role": "user","content": [{"type": "image",},{"type": "text", "text": "Describe this image."},],}
]# Preprocess the inputs
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe this image.<|im_end|>\n<|im_start|>assistant\n'inputs = processor(text=[text_prompt], images=[image], padding=True, return_tensors="pt"
)
inputs = inputs.to("cuda")# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [output_ids[len(input_ids) :]for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
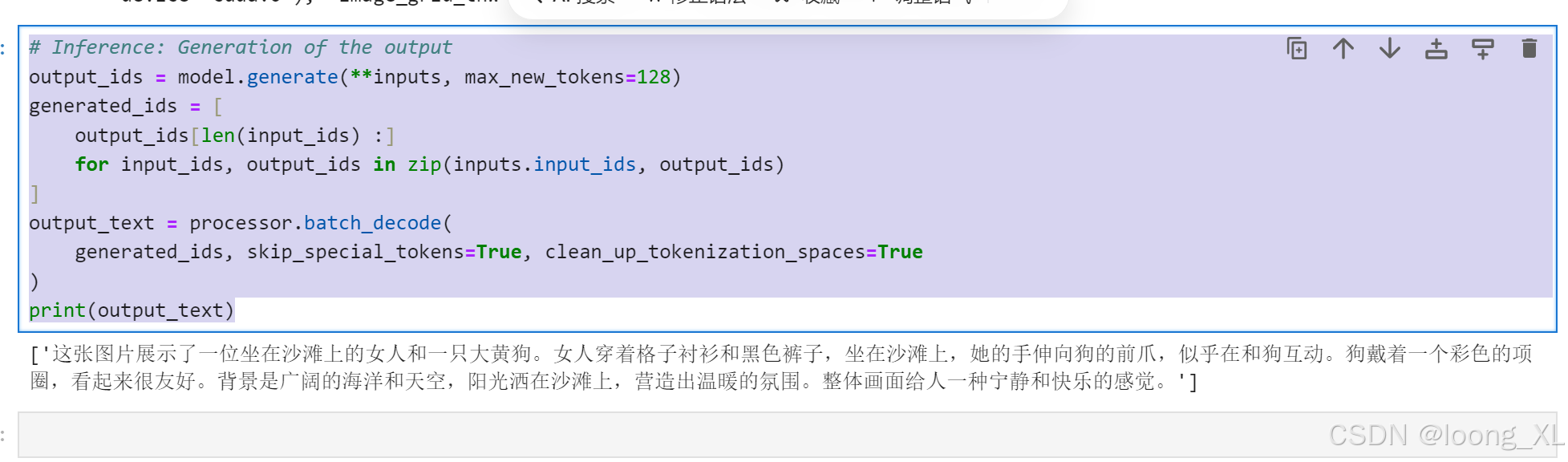
print(output_text)
这是图片:



中文问
# Image
url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
image = Image.open(requests.get(url, stream=True).raw)conversation = [{"role": "user","content": [{"type": "image",},{"type": "text", "text": "描述下这张图片."},],}
]# Preprocess the inputs
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe this image.<|im_end|>\n<|im_start|>assistant\n'inputs = processor(text=[text_prompt], images=[image], padding=True, return_tensors="pt"
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [output_ids[len(input_ids) :]for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
print(output_text)
多张图片
def load_images(image_info):images = []for info in image_info:if "image" in info:if info["image"].startswith("http"):image = Image.open(requests.get(info["image"], stream=True).raw)else:image = Image.open(info["image"])images.append(image)return images# Messages containing multiple images and a text query
messages = [{"role": "user","content": [{"type": "image", "image": "/ai/fight.png"},{"type": "image", "image": "/ai/long.png"},{"type": "text", "text": "描述下这两张图片"},],}
]# Load images
image_info = messages[0]["content"][:2] # Extract image info from the message
images = load_images(image_info)# Preprocess the inputs
text_prompt = processor.apply_chat_template(messages, add_generation_prompt=True)inputs = processor(text=[text_prompt], images=images, padding=True, return_tensors="pt"
)
inputs = inputs.to("cuda")# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [output_ids[len(input_ids) :]for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
print(output_text)


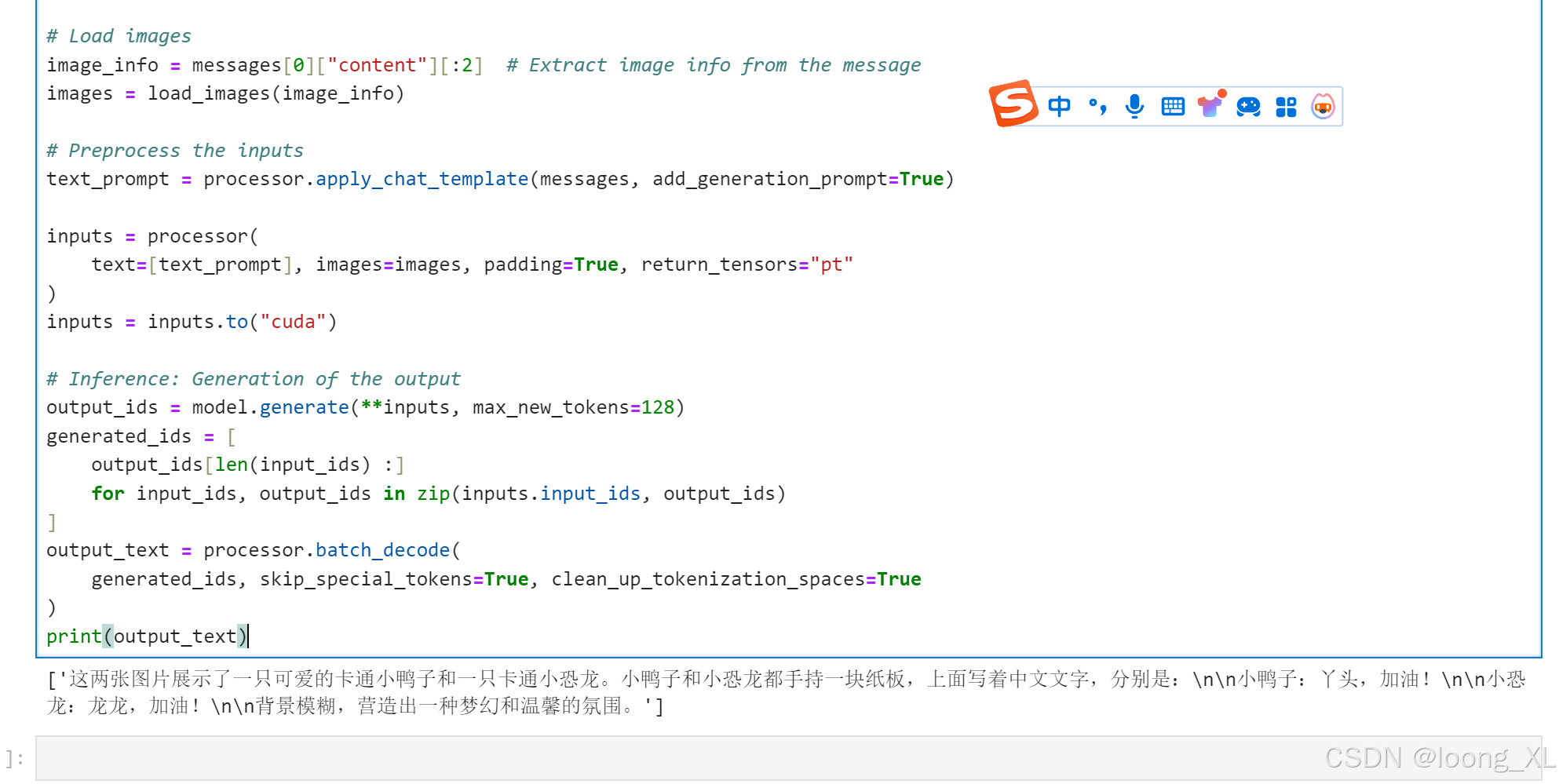
视频
安装
pip install qwen-vl-utils
from qwen_vl_utils import process_vision_info# Messages containing a images list as a video and a text query
messages = [{"role": "user","content": [{"type": "video","video": ["file:///path/to/frame1.jpg","file:///path/to/frame2.jpg","file:///path/to/frame3.jpg","file:///path/to/frame4.jpg",],"fps": 1.0,},{"type": "text", "text": "Describe this video."},],}
]
# Messages containing a video and a text query
messages = [{"role": "user","content": [{"type": "video","video": "/ai/血液从上肢流入上腔静脉.mp4","max_pixels": 360 * 420,"fps": 1.0,},{"type": "text", "text": "描述下这个视频"},],}
]# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt",
)
inputs = inputs.to("cuda")# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
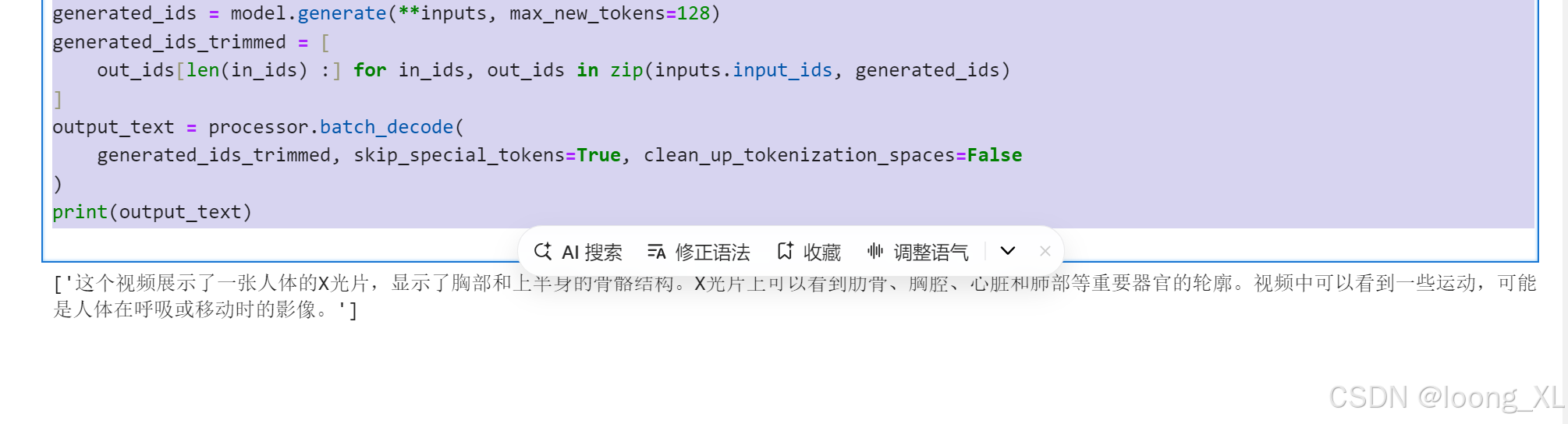
相关文章:
qwen2 VL 多模态图文模型;图像、视频使用案例
参考: https://huggingface.co/Qwen/Qwen2-VL-2B-Instruct 模型: export HF_ENDPOINThttps://hf-mirror.comhuggingface-cli download --resume-download --local-dir-use-symlinks False Qwen/Qwen2-VL-2B-Instruct --local-dir qwen2-vl安装&#x…...

ASPICE评估:汽车软件质量的守护神
随着汽车行业的快速发展,车载软件系统的复杂性和重要性日益凸显。为了确保汽车软件的质量和安全性, 汽车行业引入了ASPICE(Automotive SPICE)评估作为评价软件开发团队研发能力的重要工具。 本文将详细介绍ASPICE评估的概念、过…...

野生动物检测系统源码分享
野生动物检测检测系统源码分享 [一条龙教学YOLOV8标注好的数据集一键训练_70全套改进创新点发刊_Web前端展示] 1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 项目来源AACV Association for the Advancement of Computer Vis…...

【Hot100】LeetCode—75. 颜色分类
目录 1- 思路题目识别技巧 2- 实现⭐75. 颜色分类——题解思路 3- ACM 实现 原题链接:75. 颜色分类 1- 思路 题目识别 识别1 :给定三种类型数据,使得三种数据用一次遍历实现三种数据排序。 技巧 用两条线将数组分为三部分A 线左侧&#x…...
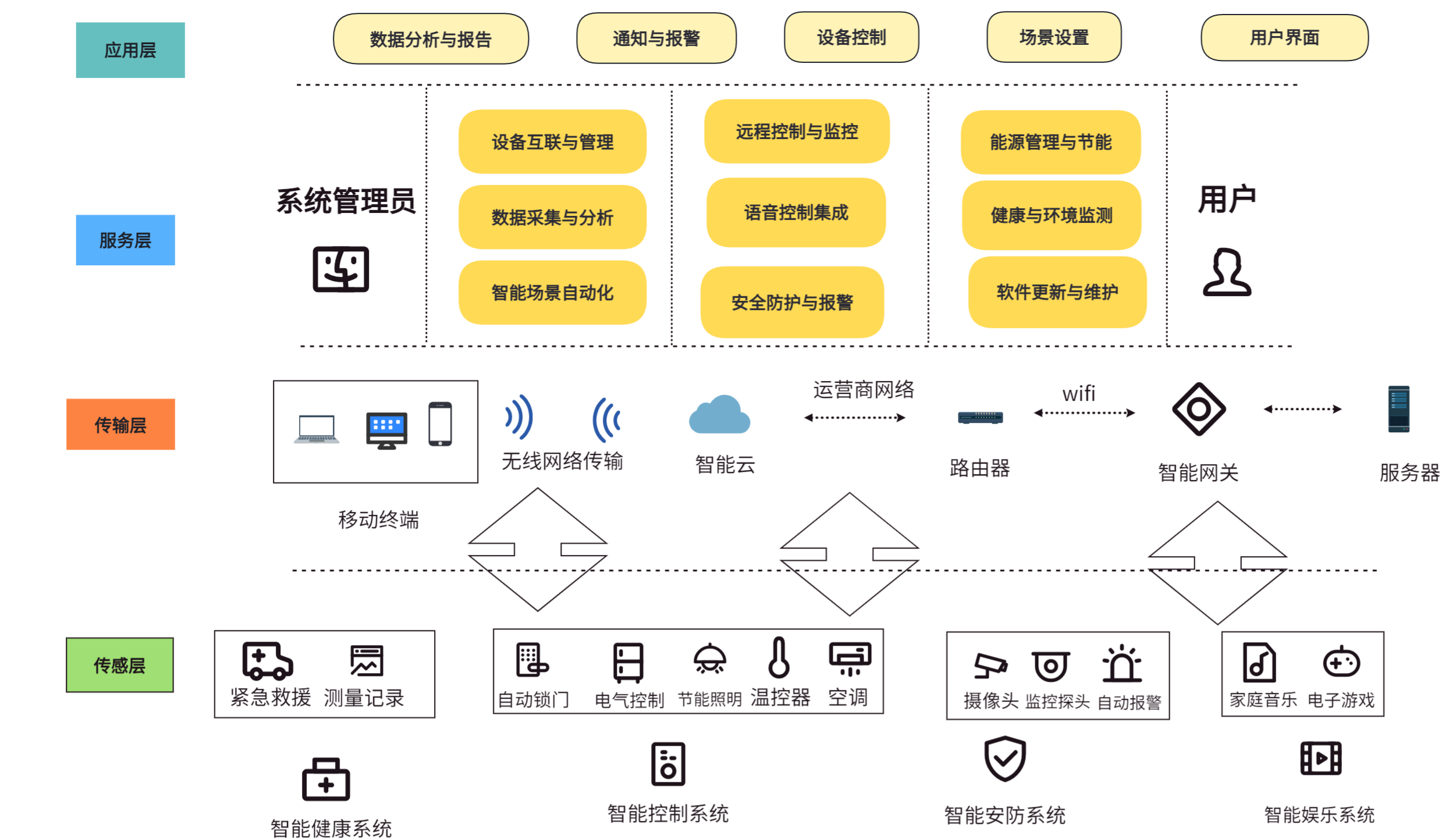
【物联网技术大作业】设计一个智能家居的应用场景
前言: 本人的物联网技术的期末大作业,希望对你有帮助。 目录 大作业设计题 (1)智能家居的概述。 (2)介绍智能家居应用。要求至少5个方面的应用,包括每个应用所采用的设备,性能&am…...
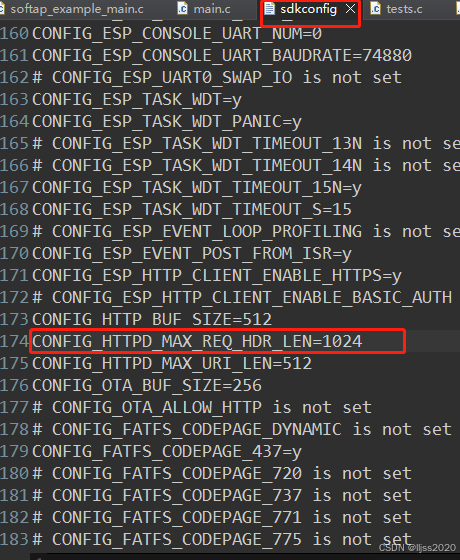
ESP8266做httpServer提示Header fields are too long for server to interpret
CONFIG_HTTP_BUF_SIZE512 CONFIG_HTTPD_MAX_REQ_HDR_LEN1024 CONFIG_HTTPD_MAX_URI_LEN512CONFIG_HTTPD_MAX_REQ_HDR_LEN由512改为1024...
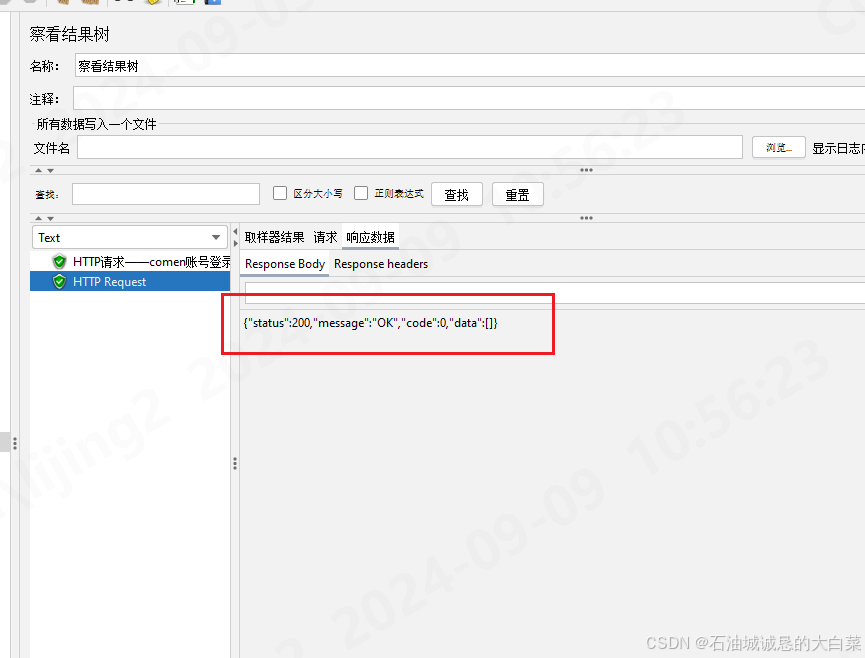
jmeter设置全局token
1、创建setup线程,获取token的接口在所有线程中优先执行,确保后续线程可以拿到token 2、添加配置原件-Http信息头管理器,添加取样器-http请求 配置好接口路径,端口,前端传参数据,调试一下,保证获…...
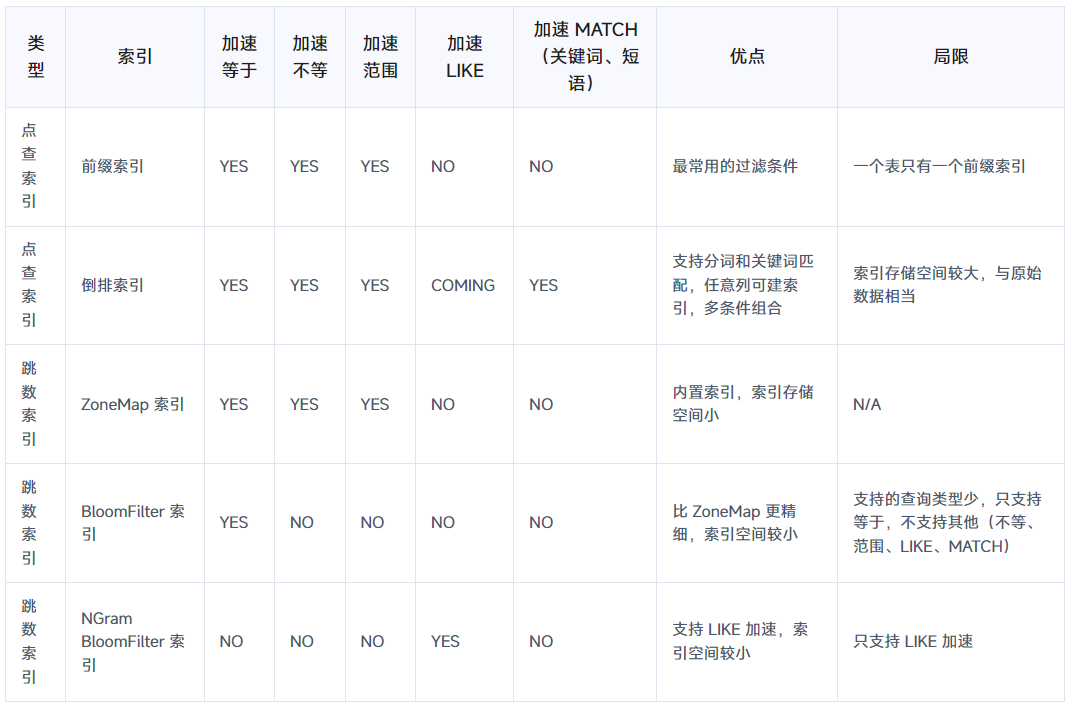
DORIS - DORIS之索引简介
索引概述 索引对比 索引建议 (1)最频繁使用的过滤条件指定为 Key字段,自动建前缀索引,它的过滤效果最好,但是一个表只能有一个前缀索引,因此要用在最频繁的过滤条件上,前缀索引比较小ÿ…...
Java 串口通信—收发,监听数据(代码实现)
一、串口通信与串行通信的原理 串行通信是指仅用一根接收线和一根发送线,将数据以位进行依次传输的一种通讯方式,每一位数据占据一个固定的时间长度。 串口通信(Serial Communications)的概念非常简单,串口按位&#x…...

fileinput pdf编辑初始化预览
var $fileLinkInput $(#file_link_full); $fileLinkInput.fileinput({language: zh,uploadUrl: <?php echo Yii::$app->urlManager->createUrl([file/image, type > work_file]);?>,initialPreview: [defaultFile],initialPreviewAsData: true,initialPrevie…...
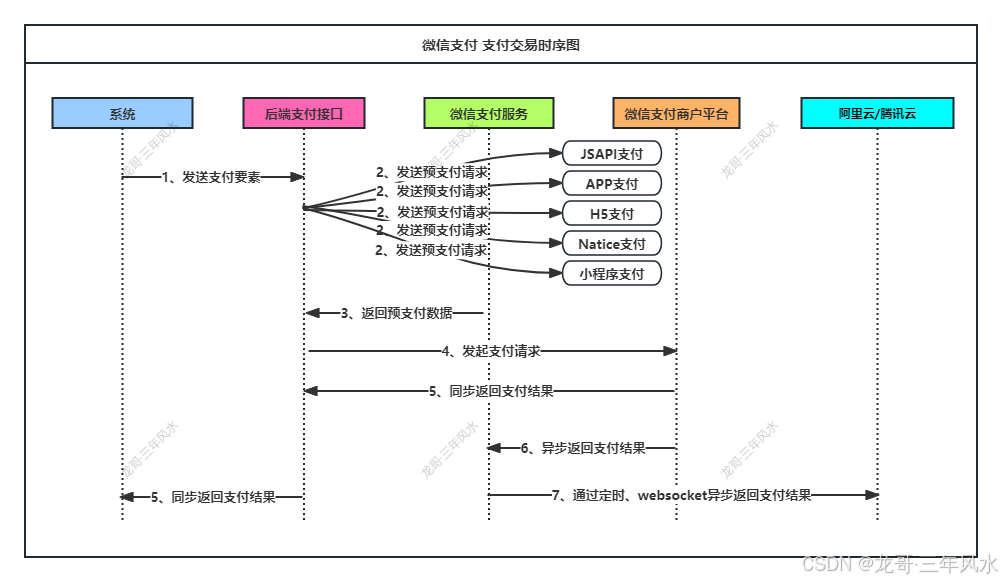
微信支付开发-需求整理及需求设计
一、客户要求 1、通过唤醒机器人参与答题项,机器人自动获取题目,用户进行答题; 2、用户答对题数与后台设置的一样或者更多,则提醒用户可以领取奖品,但是需要用户支付邮费; 3、用户在几天之内不能重复领取奖…...

vs code: pnpm : 无法加载文件 C:\Program Files\nodejs\pnpm.ps1,因为在此系统上禁止运行脚本
在visual studio code运行pnpm出错: pnpm : 无法加载文件 C:\Program Files\nodejs\pnpm.ps1,因为在此系统上禁止运行脚本 解决方案: 到C:\Program Files\nodejs文件夹下删除pnpm.ps1即可。 C:\Program Files\nodejs改成你自己的路径...

web测试必备技能:浏览器兼容性测试
如今,市面上的浏览器种类越来越多(尤其是在平板和移动设备上),这就意味着你所测试的站点需要在这些你声称支持浏览器上都能很好的工作。 同时,主流浏览器(IE,Firefox,Chrome&#x…...
《数据资产管理核心技术与应用》首次大型赠书活动圆满结束
《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著,在2024.9.11号晚上20:00,本书作者张永清联合锋哥聊数仓公众号和清华大学出版社一起,向各大大数据技术爱好者通过三轮互动活动赠送了3本正版图书。…...

vue在一个组件引用其他组件
在vue一个组件中引用另一个组件的步骤 必须在script中导入要引用的组件需要在export default的components引用导入的组件(这一步经常忘记)在template使用导入的组件<script><!-- 第一步,导入--> import Vue01 from "@/components/Vue01.vue";...

软件测试学习笔记丨Postman实战练习
本文转自测试人社区,原文链接:https://ceshiren.com/t/topic/32096#h-22 二、实战练习 2.1 宠物商店接口文档分析 接口文档:http://petstore.swagger.io ,这是宠物商店接口的 swagger 文档。 2.1.1 什么是 swagger Swagger 是…...

kubernetes微服务基础及类型
目录 1 什么是微服务 2 微服务的类型 3 ipvs模式 ipvs模式配置方式 4 微服务类型详解 4.1 ClusterIP 4.2 ClusterIP中的特殊模式headless 4.3 nodeport 4.4 metalLB配合loadbalance实现发布IP 1 什么是微服务 用控制器来完成集群的工作负载,那么应用如何暴漏出去&…...

linux-L3_linux 查看进程(node-red)
linux 查看进程 以查看进程node-red为例 ps aux | grep node-red...

区块链之变:揭秘Web3对互联网的改变
传统游戏中,玩家的虚拟资产(如角色、装备)通常由游戏公司控制,玩家无法真正拥有这些资产或进行交易。而在区块链游戏中,虚拟资产通过去中心化技术记录在区块链上,玩家对其拥有完全的所有权,并能…...
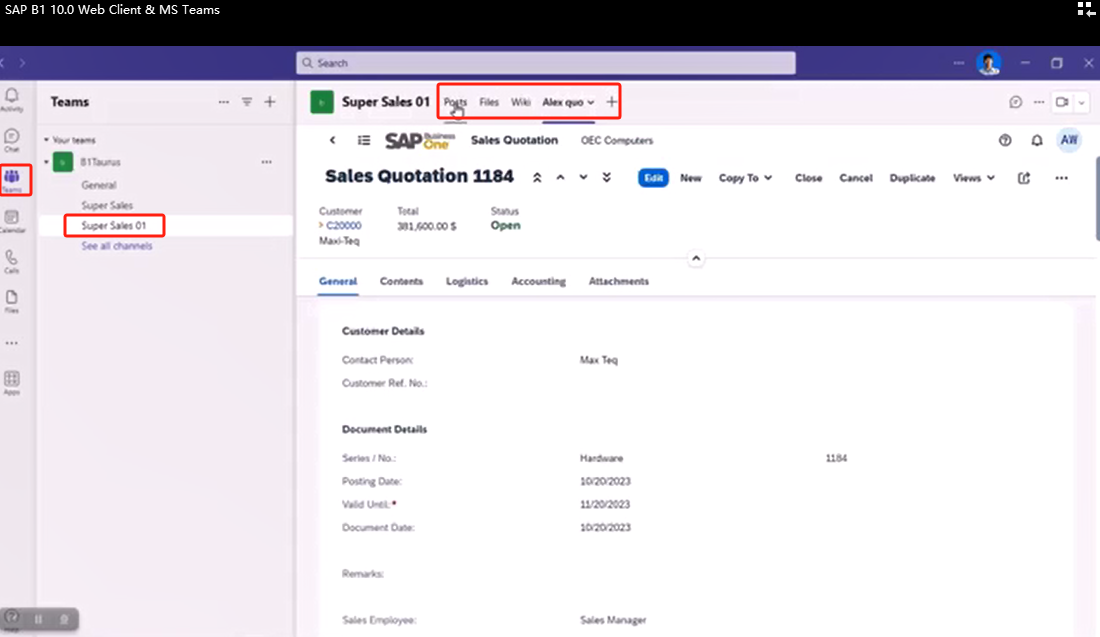
SAP B1 Web Client MS Teams App集成连载一:先决条件/Prerequisites
一、先决条件/Prerequisites 在设置 SAP Business One 应用之前,确保您已具备以下各项:Before you set up the SAP Business One app, make sure you have acquired the following: 1.Microsoft Teams 管理员账户/A Microsoft Teams admin account 您需…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

基于Readability算法的网页内容提取服务:从原理到工程实践
1. 项目概述:一个为现代阅读而生的开源工具 最近在折腾个人知识库和稍后读系统时,我一直在找一个能完美解决“网页内容净化与结构化”痛点的工具。市面上的方案要么太重,要么太简陋,直到我遇到了 Cat-tj/web-reader 。这不仅仅是…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...

AI助手API开发资源全指南:从入门到实战的宝藏清单
1. 项目概述:一个为AI助手API开发者量身打造的“藏宝图”如果你正在或打算基于OpenAI的Assistant API、Anthropic的Claude API,或是其他主流AI平台的助手接口来构建应用,那么你大概率会遇到一个经典困境:官方文档虽然详尽…...

基于Stable Diffusion与LoRA技术打造个人AI头像:从原理到实战
1. 项目概述:当AI开始“自拍”——SelfyAI的定位与核心价值最近在AI图像生成领域,一个名为SelfyAI的项目引起了我的注意。它不是一个简单的文生图工具,而是瞄准了一个非常具体且高频的需求:生成高质量、风格一致的个人AI头像。简单…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...
基于GEMMA与NeoPixel制作智能可穿戴首饰:从硬件选型到代码实现
1. 项目概述:当微型控制器遇见珠宝设计几年前,当我第一次把一块微控制器塞进一个首饰盒里,看着它驱动一圈LED发出柔和的光晕时,我就知道,电子制作和个性化穿戴的结合,远不止于智能手表或健身手环。我们今天…...
)
紧急更新!Midjourney刚推送的--stylize 1000级调优补丁,已实测提升立体主义结构清晰度达4.8倍(附对比数据集下载)
更多请点击: https://intelliparadigm.com 第一章:Midjourney立体主义风格的本质解构 立体主义并非简单地将物体“打碎再拼合”,而是一种对多维时空感知的视觉转译——Midjourney 通过其隐式扩散先验,以概率化方式重构了布拉克与…...