SQL语法:浅析select之七大子句
Mysql版本:8.0.26
可视化客户端:sql yog
目录
- 一、七大子句顺序
- 二、演示
- 2.1 from语句
- 2.2 on子句
- 2.3 where子句
- 2.4 group by子句
- 2.4.1 WITHROLLUP,加在group by后面
- 2.4.2 是否可以按照多个字段分组统计?
- 2.4.3 分组统计时,select后面字段列表的问题
- 2.5 having子句
- 2.6 order by子句
- 2.7 limit子句
提示:以下是本篇文章正文内容,下面案例可供参考
一、七大子句顺序
(1) from: 从哪些表中筛选。
(2) inner l left | right … on: 关联多表查询时,去除笛卡尔积
(3) where: 从表中筛选的条件
(4) group by: 分组依据
(5) having: 在分组统计结果中再次筛选 (with rollup)
(6) order by: 排序
(7) limit: 分页
注意:必须按照 (1) - (7) 的顺序编写子句。
二、演示
测试数据准备如下:
①创建数据表 t_department:
CREATE TABLE `t_department` (`did` int NOT NULL AUTO_INCREMENT COMMENT '部门编号',`dname` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '员工名称',`description` varchar(200) DEFAULT NULL COMMENT '员工简介',PRIMARY KEY (`did`),UNIQUE KEY `dname` (`dname`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci

②创建数据表t_employee
CREATE TABLE `t_employee` (`eid` int NOT NULL AUTO_INCREMENT COMMENT '员工编号',`ename` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '员工姓名',`salary` double NOT NULL COMMENT '薪资',`commission_pct` decimal(3,2) DEFAULT NULL COMMENT '奖金比例',`birthday` date NOT NULL COMMENT '出生日期',`gender` enum('男','女') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '男' COMMENT '性别',`tel` char(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '手机号码',`email` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '邮箱',`address` varchar(150) DEFAULT NULL COMMENT '地址',`work_place` set('北京','深圳','上海','武汉') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '北京' COMMENT '工作地点',`hiredate` date NOT NULL COMMENT '入职日期',`job_id` int DEFAULT NULL COMMENT '职位编号',`mid` int DEFAULT NULL COMMENT '领导编号',`did` int DEFAULT NULL COMMENT '部门编号',PRIMARY KEY (`eid`),KEY `job_id` (`job_id`),KEY `did` (`did`),KEY `mid` (`mid`),CONSTRAINT `t_employee_ibfk_1` FOREIGN KEY (`job_id`) REFERENCES `t_job` (`jid`) ON DELETE SET NULL ON UPDATE CASCADE,CONSTRAINT `t_employee_ibfk_2` FOREIGN KEY (`did`) REFERENCES `t_department` (`did`) ON DELETE SET NULL ON UPDATE CASCADE,CONSTRAINT `t_employee_ibfk_3` FOREIGN KEY (`mid`) REFERENCES `t_employee` (`eid`) ON DELETE SET NULL ON UPDATE CASCADE,CONSTRAINT `t_employee_chk_1` CHECK ((`salary` > 0)),CONSTRAINT `t_employee_chk_2` CHECK ((`hiredate` > `birthday`))
) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci

③创建数据表t_job
CREATE TABLE `t_job` (`jid` int NOT NULL AUTO_INCREMENT COMMENT '职位编号',`jname` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '职位名称',`description` varchar(200) DEFAULT NULL COMMENT '职位简介',PRIMARY KEY (`jid`),UNIQUE KEY `jname` (`jname`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci

2.1 from语句
👉功能:
表示从某个表中筛选数据
案例:查询t_department表的所有欣喜
代码演示如下:
select *
from t_department #表示从某个表中筛选数据

2.2 on子句
👉特点:
(1)on必须配合join使用
(2)on后面只写关联条件
所谓关联条件是两个表的关联字段的关系
例如:t_employee表和t_department表关联,t_employee.did=t_department.did
(3)有n张表关联,就有n-1个关联条件
两张表关联,就有1个关联条件
三张表关联,就有2个关联条件
案例:#查询员工的编号,姓名,职位编号,职位名称,部门编号,部门名称,需要t_employee员工表,t_department部门表,t_job职位表。
代码如下(示例):
SELECT eid,ename,t_job.job_id,t_job.job_name, `t_department`.`did`,`t_department`.`dname`
FROM t_employee INNER JOIN t_department INNER JOIN t_job
ON t_employee.did = t_department.did AND t_employee.job_id = t_job.job_id;

2.3 where子句
👉功能:
在查询结果中筛选
案例:#查询所有男员工的姓名和部门名称
代码演示如下:
SELECT ename,dname
FROM t_department RIGHT JOIN t_employee ON t_employee.`did`=t_department.`did`
WHERE t_employee.`gender`='男';

2.4 group by子句
👉功能:
分组依据
案例:#查询每一个部门的平均薪资
代码演示如下:
SELECT dname,AVG(salary) AS 平均薪资
FROM t_department RIGHT JOIN t_employee ON t_department.`did`=t_employee.`did`
GROUP BY t_department.`dname`;

案例:#查询每一个部门所有男员工的平均薪资
SELECT t_employee.did,dname,AVG(salary) AS 平均薪资
FROM t_employee RIGHT JOIN t_department ON t_department.`did`=t_employee.`did`
WHERE gender='男'
GROUP BY t_employee.`did`;

2.4.1 WITHROLLUP,加在group by后面
WITHROLLUP:在group分组字段的基础上再进行统计数据。
案例:#按照部门统计人数,并合计总数
代码演示如下:
SELECT IFNULL(did,'合计') AS "部门编号" , COUNT(*) AS "人数" FROM t_employee GROUP BY did WITH ROLLUP;

2.4.2 是否可以按照多个字段分组统计?
案例:#分别统计查询每一个部门男、女员工的平均薪资
代码演示如下:
SELECT t_employee.did,dname,gender,AVG(salary) AS 平均薪资
FROM t_employee RIGHT JOIN t_department ON t_department.`did`=t_employee.`did`
GROUP BY t_employee.`did`,gender;

2.4.3 分组统计时,select后面字段列表的问题
案例:统计每个部门的人数
代码演示如下:
SELECT eid,ename, did, COUNT(*) FROM t_employee;

❌
分析:不符合案例需求,案例需求只要统计各部门的总人数,而不是统计总人数,况且加上count(*)【count(),它的功能是统计记录数,,又是分组函数,即函数执行完后,得到结果的行数可能会变少,有可能是1行,也可能是几行】,如果不加分组条件,此查询语句会查询所有的人数+带返回第一个员工的员工编号和姓名以及部门编号。
代码改善如下:
SELECT eid,ename, did, COUNT(*) FROM t_employee GROUP BY did;

❌
分析:虽然加了group by did,即按部门编号分组,但整个查询语句返回的”eid“和”ename“等字段下的记录有歧义,如下所示:

红圈勾出的记录是在表达,部门编号为1的部门下有14个员工编号为1,名为"孙洪亮"的员工吗?,显然不对,不符合逻辑,古往今来,没有十四胞胎,且一模一样的人。
正确代码如下:
SELECT did, COUNT(*) FROM t_employee GROUP BY did;
分组统计时,select后面只写和分组统计有关的字段,其他无关字段不要出现,否则会引起歧义
2.5 having子句
👉功能:
在分组统计结果中再次筛选
案例:#分别统计查询每一个部门男、女员工的平均薪资,只显示平均薪资在10000元以上的记录
代码演示如下:
SELECT t_employee.did,dname,gender,AVG(salary) AS 平均薪资
FROM t_employee RIGHT JOIN t_department ON t_department.`did`=t_employee.`did`
GROUP BY t_employee.`did`,gender
HAVING 平均薪资>10000;

where和having的区别别?
-
where是针对原表的原始数据筛选,后面不能接分组函数(avg,sum,count,max,min)等
-
having是针对分组统计结果的再次筛选,后面可以接分组函数,还可以使用统计结果的别名
2.6 order by子句
👉功能:
升序和降序,默认是升序
asc代表升序【从小到大】
desc 代表降序【从大到小】
案例:#查询所有员工的姓名和薪资,按照薪资从高到低排序
代码演示如下:
SELECT ename,salary
FROM t_employee
ORDER BY salary DESC; #默认是升序,降序要加desc,升序可以加asc

案例:#查询所有员工的姓名和薪资、出生日期,按照薪资从高到低排序 。如果薪资相同的,按照出生日期从小到大。
代码演示如下:
SELECT ename,salary,birthday
FROM t_employee
ORDER BY salary DESC,birthday ASC;

2.7 limit子句
👉功能:分页显示结果。
注意:
limit m,n
n:表示最多该页显示几行
m:表示从第几行开始取记录,第一个行的索引是0
m = (page-1)×n
page表示第几页
每页最多显示5条,n=5
第1页,page=1,m = (1-1)*5 = 0; limit 0,5
第2页,page=2,m = (2-1)*5 = 5; limit 5,5
第3页,page=3,m = (3-1)*5 = 10; limit 10,5
每页显示20条,n=20
第6页,page=6,m = (6-1)*20;limit 100,20
案例:#查询员工信息,按照每页显示5条的规则,查询第1页
代码演示如下:
SELECT *
FROM t_employee
LIMIT 0,5;

案例:#查询员工信息,按照每页显示5条的规则,查询第2页
代码演示如下:
SELECT *
FROM t_employee
LIMIT 10,5;

相关文章:
SQL语法:浅析select之七大子句
Mysql版本:8.0.26 可视化客户端:sql yog 目录一、七大子句顺序二、演示2.1 from语句2.2 on子句2.3 where子句2.4 group by子句2.4.1 WITHROLLUP,加在group by后面2.4.2 是否可以按照多个字段分组统计?2.4.3 分组统计时,…...

中国人民大学与加拿大女王大学金融硕士——去有光的地方,并成为自己的光
光是我们日常生活中一个重要的元素,试想一下如果没有光,世界将陷入一片昏暗。人生路亦是如此,我们从追逐光、靠近光、直到自己成为光。人民大学与加拿大女王大学金融硕士项目是你人生路上的一束光吗 渴望想要成为一个更好的人,就…...

Python数据结构与算法篇(五)-- 二分查找与二分答案
1 二分法介绍 1.1 定义 二分查找又称折半查找、二分搜索、折半搜索等,是一种在静态查找表中查找特定元素的算法。 所谓静态查找表,即只能对表内的元素做查找和读取操作,不允许插入或删除元素。 使用二分查找算法,必须保证查找表中…...
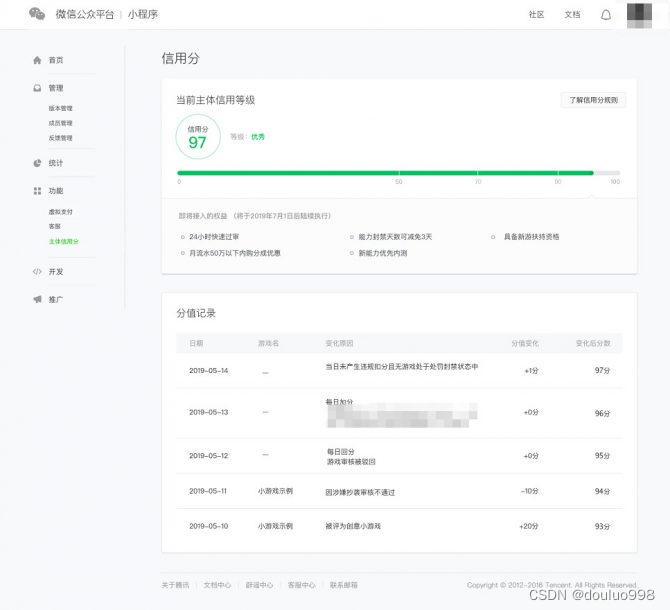
小游戏也要讲信用
当下,小游戏鱼龙混杂,官方为能更好地保护用户、开发者以及平台的权益,近日宣布7月1日起试行小游戏主体信用分机制。 主体信用分是什么呢?简单来说,这是针对小游戏主体下所有小游戏帐号行为,对开发者进行评…...

贪心算法11
1. 贪心算法的概念 所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。 贪心算法没有固定的算法框架,算法设计的关键是贪心…...
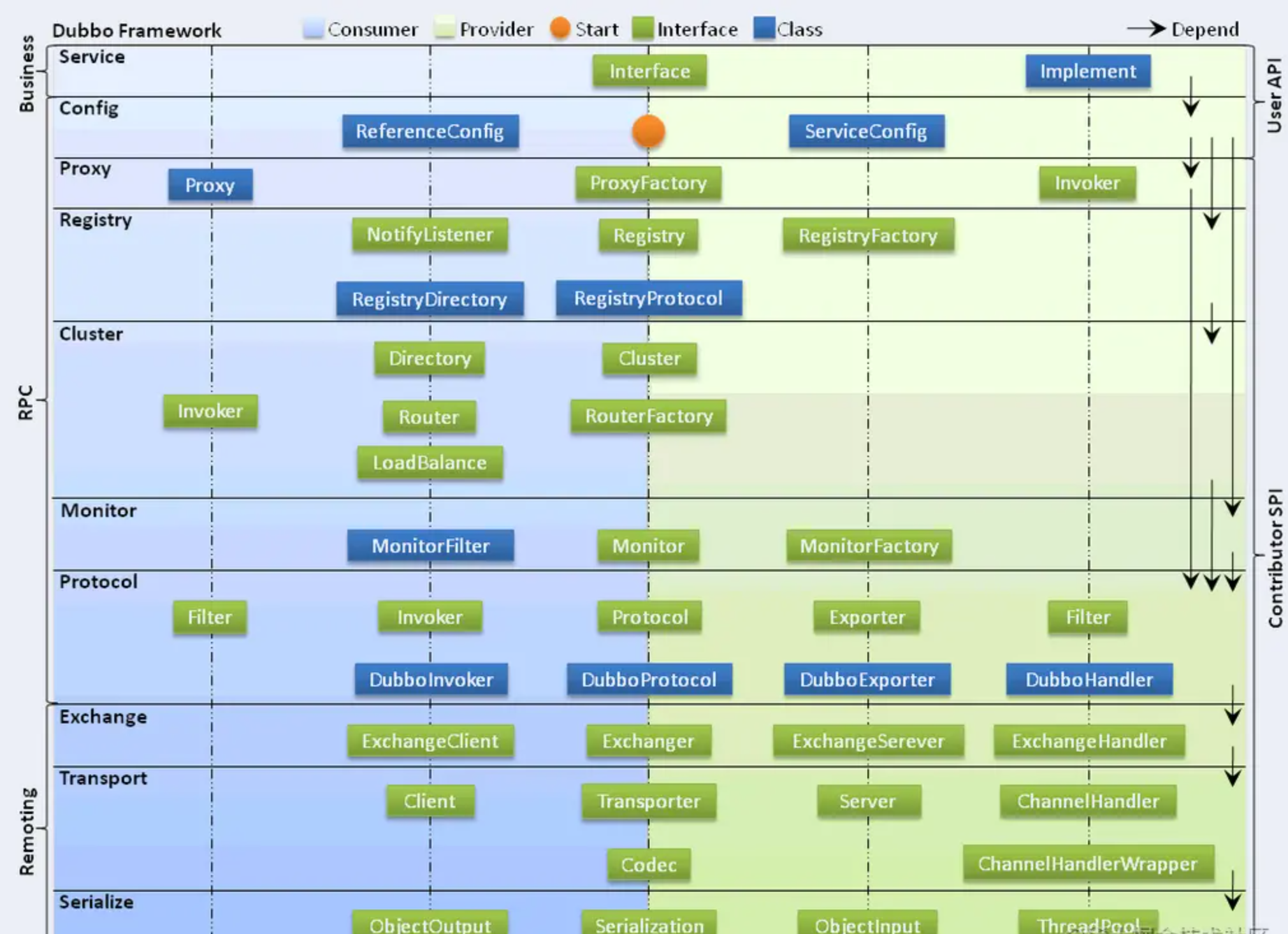
【并发编程】JUC并发编程(彻底搞懂JUC)
文章目录一、背景二、什么是JUC?三、JUC框架结构四、JUC框架概述五、JUC中常用类汇总六、相关名词进程和线程进程线程创建线程的几种常见的方式并发和并行用户线程和守护线程七、synchronized 作用范围:八、Lock锁(重点)什么是 Lock锁类型Lock接口lock()…...

Compose 动画 (七) : 高可定制性的动画 Animatable
1. Animatable和animateDpAsState的区别是什么 Animatable是Android Compose动画的底层API,如果我们查看源码,可以发现animateDpAsState内部是调用的animateValueAsState,而animateValueAsState内部调用的是Animatable animateDpAsState比A…...

vue3组件传值
1.父向子传值 父组件 引入子组件 import Son from ./components/Son.vue 设置响应式数据 const num ref(99) 绑定到子组件 <Son :num"num"></Son> 子组件 引入defineProps import { defineProps } from vue; 生成实例接收数据 type设置接收类…...

小白开发微信小程序00--文章目录
一个小白,一个老牛,空手能不能套白羊,能不能白嫖?我告诉你,一切都so easy,这个系列从0到106,屌到上天,盖过任何一个,试问,网上讲微信小程序开发的,…...
随手记录第九话 -- Java框架整合篇
框架莫过于Spring了,那就以它为起点吧。 本文只为整理复习用,详细内容自行翻看以前文章。 1.Spring 有人说是Spring成就Java,其实也不是并无道理。 1.1 Spring之IOC控制反转 以XML注入bean的方式为入口,定位、加载、注册&…...
电影《铃芽之旅》观后感
这周看了电影《铃芽之旅》,整部电影是新海诚的新作。电影讲述的是女主铃芽为了关闭往门,在日本旅行中,遭遇灾难的故事。 (1)往昔记忆-往昔之物 电影中,有很多的“往门”,换成中国的话说…...
Web自动化测试(二)(全网最给力自动化教程)
欢迎您来阅读和练手!您将会从本章的详细讲解中,获取很大的收获!开始学习吧! 2.4 CSS定位2.5 SeleniumBuilder辅助定位元素2.6 操作元素(键盘和鼠标事件) 正文 2.4 CSS定位 前言 大部分人在使用selenium定…...

【C语言经典例题!】逆序字符串
目录 一、题目要求 二、解题步骤 ①递归解法 思路 完整代码 ②循环解法 思路 完整代码 嗨大家好! 本篇博客中的这道例题,是我自己在一次考试中写错的一道题 这篇博客包含了这道题的几种解法,以及一些我自己对这道题的看法ÿ…...

21 - 二叉树(三)
文章目录1. 二叉树的镜像2. 判断是不是完全二叉树3. 完全二叉树的节点个数4. 判断是不是平衡二叉树1. 二叉树的镜像 #include <ctime> class Solution {public:TreeNode* Mirror(TreeNode* pRoot) {// write code hereif (pRoot nullptr) return pRoot;//这里记得要记得…...

【A-Star算法】【学习笔记】【附GitHub一个示例代码】
文章目录一、算法简介二、应用场景三、示例代码Reference本文暂学习四方向搜索,一、算法简介 一个比较经典的路径规划的算法 相关路径搜索算法: 广度优先遍历(BFC)深度优先遍历(DFC)Di jkstra算法&#…...

纽扣电池澳大利亚认证的更新要求
澳大利亚强制性安全和信息标准草案具体规定了对含有纽扣电池和纽扣电池以 及纽扣电池和纽扣电池本身的消费品的要求, 适用范围 1.本法规适用于: 纽扣锂电池(任何尺寸和类型); 直径为16毫米或以上的纽扣锂电池: 一起提供的纽扣电池(未预先安装在产品中)。 2.但是&…...

零代码零距离,明道云开放日北京站圆满结束
文/麦壁瑜 编辑/李雨珂 2023年3月17日,为期一天的明道云开放日北京站圆满结束。本次开放日迎来超过100名伙伴和客户现场参会,其中不乏安利、通用技术集团、民生银行、迈外迪、DELSK集团、中国人民养老保险、北京汽车等知名企业代表。北京大兴机场、作业…...
第五章Vue路由
文章目录相关理解vue-router的理解对SPA应用的理解路由的理解基本路由几个注意点嵌套路由——多级路由路由query参数命名路由路由的params参数路由的props配置路由跳转的replace方法编程式路由导航缓存路由组件路由组件独有的生命钩子activated和deactivated路由守卫全局路由守…...
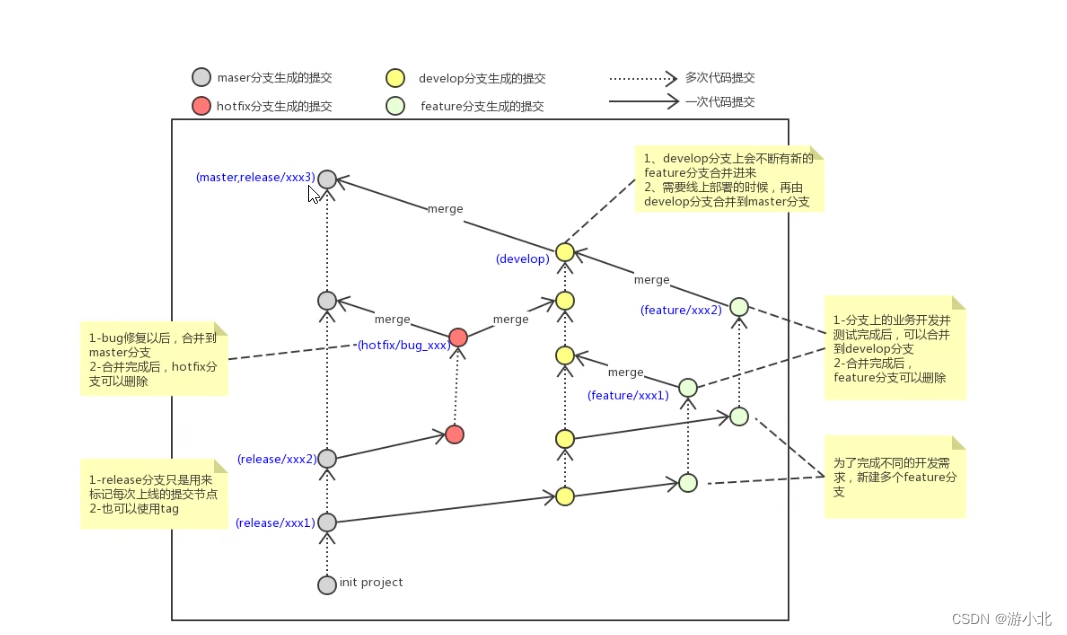
Git常用指令
Git是什么: Git是分布式版本控制系统(Distributed Version Control System,简称 DVCS),分为两种类型的仓库: 本地仓库和远程仓库 第一步先新建仓库,本地 init ,然后提交分枝 链接仓库…...

Java每日一练(20230329)
目录 1. 环形链表 II 🌟🌟 2. 基础语句 ※ 3. 最小覆盖子串 🌟🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日一练 专栏 1. 环形…...

STL到STEP格式转换:技术选型与实施指南
STL到STEP格式转换:技术选型与实施指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在制造业数字化转型的背景下,3D数据格式互操作性已成为工程团队面临的核心挑战。…...

紧急预警:Midjourney即将关闭--style raw参数入口!最后48小时掌握赛博朋克硬核写实风格迁移技巧
更多请点击: https://intelliparadigm.com 第一章:紧急预警:Midjourney即将关闭--style raw参数入口!最后48小时掌握赛博朋克硬核写实风格迁移技巧 立即行动:锁定--style raw的最后窗口期 Midjourney v6.9 已悄然启动…...

AI IDE CLI:为AI编程助手打造的轻量级本地开发环境
1. 项目概述:一个为AI时代量身定制的本地开发环境CLI工具如果你是一名开发者,最近肯定没少和各类AI编程助手打交道。无论是GitHub Copilot、Cursor,还是各种本地部署的大模型,它们正在深刻地改变我们写代码的方式。但随之而来的一…...
)
告别手动填坑:用SSC工具+Excel快速搞定LAN9252 EtherCAT从站XML配置(附64点IO实例)
高效配置LAN9252 EtherCAT从站的自动化工具链实践 在嵌入式工业通信领域,EtherCAT因其卓越的实时性能被广泛采用,而LAN9252作为高性价比的从站控制器芯片,配合SPI接口成为许多开发者的首选方案。然而传统XML配置流程的复杂性往往成为项目瓶颈…...

NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的700+高级设置
NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的700高级设置 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 作为一款开源显卡配置工具,NVIDIA Profile Inspector提供了直…...
:Lobster)
OpenClaw从入门到应用——工具(Tools):Lobster
通过OpenClaw实现副业收入:《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》 Lobster 是一个工作流 Shell,它让 OpenClaw 将多步工具序列作为单一的、确定性的操作来运行,并带有明确的审批检查点。 引子 你的助手可以…...

pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境
pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境 【免费下载链接】pyecharts-assets 🗂 All assets in pyecharts 项目地址: https://gitcode.com/gh_mirrors/py/pyecharts-assets 还在为pyecharts图表加载慢而烦恼吗&…...

Boss-Key终极指南:5分钟掌握办公隐私保护神器的一键隐藏窗口技巧
Boss-Key终极指南:5分钟掌握办公隐私保护神器的一键隐藏窗口技巧 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在数字化办公…...

赛博朋克风格商业变现闭环:从DALL·E对比测试到Fiverr接单模板,7天打造高单价AI艺术IP
更多请点击: https://intelliparadigm.com 第一章:赛博朋克视觉语法与AI艺术IP的神经接口 赛博朋克视觉语法并非仅关乎霓虹、雨巷与义体——它是一套高度结构化的符号系统,其色彩模型(如青紫-品红双主调)、构图逻辑&a…...
)
别再只盯着JWT了!手把手教你用Python解密JWE Token(附完整代码)
深入实战:用Python解密JWE Token的全流程指南 在当今的Web应用开发中,Token已成为身份验证和授权的主流方式。大多数开发者对JWT(JSON Web Token)已经相当熟悉,能够轻松地在jwt.io等工具上解码和验证。然而,…...