如何快准稳 实现MySQL大表历史数据迁移?
历史迁移解决方案以微服务架构为基础,使用多种设计模式,如:单例、桥接、工厂、模板、策略等。其中涉及的核心技术有多线程、过滤器等,致力于解决MySQL大表迁移的问题,提供多种迁移模式,如:库到库、库到文件再到库等!
历史数据迁移,顾名思义就是将某个地方的历史数据转移到另外一个地方。需求明了,就一句话能够概括完整。它所涉及的技术其实也不是很难,无非是设计一个复制数据的流程、一个插入数据的流程和一个删除数据的流程。有三个流程去完成这件事情,基本就能搞定。
当然,我们不能仅仅考虑把流程设计得能执行就好,还需要保障流程的健全性。虽然三个流程就有了可行性,并且在实际应用中基本这三个流程是不可缺少的,但是我们必须保证数据安全、流程安全,并且可以直接拓展,这样更有利于我们的项目的接入使用。关键是解决了数据丢失、数据复制不完整的问题。
支付行业:支付行业中对迁移的应用,都是必须保障数据安全的,宁肯数据迁移不成功,也必须保障数据不因为迁移而缺少,所以以上这三个流程并不完善。检查流程的加入:处理上述三个流程,本次需求设计了另外两个检查流程,用来检查查询出来的数据和插入的数据是否完整,这样保障了源库数据和迁移到目标库的数据一致。事务设计:迁移过程中可能会出现各种系统异常而导致数据复制问题,如果不加入事务的考虑,会导致数据丢失,这也是需要解决的问题。内存管理:在迁移过程中,如果一次性加载所以需要迁移的数据到项目或者内存中,基本都会导致OOM之类的问题,这也是我们要仔细考虑到的问题。
五、代码流程设计
数据迁移的办法有很多种,但是其目的都是一致的,都是将数据从源位置,转移到目标位置。项目中设计了一个通用流程来专门管理多种迁移办法,并且用到了多种设计模式来让代码更加简洁和更便于管理迁移。让代码灵活,并且方便二开或者多开。通用流程执行示意图如下,也是该项目主要流程。
简洁的代码和流程,其实得益于原本的流程设计和设计模式的运用。
六、迁移物理架构图解
七、数据库模型设计
数据库模型的设计,是我们整个流程的核心,如果没有这个数据库的模型,我们的代码将会乱成一团。也正是数据库先一步做出了规定,让我们的代码更加灵活。
表名详解
transfer_data_task:迁移任务。在该表中配置对应的迁移任务。该表仅做任务管理,并且指定迁移的执行模式。transfer_database_config:数据源配置。一个迁移任务对应两个数据源配置,一个源数据库配置,一个目标数据库配置,由database_direction字段控制是需要源库还是目标,字段有两个值source、target。transfer_select_config:源库表配置。迁移任务通过task_id关联到源库查询配置,其中主要配置信息就是我们需要查询的表,表字段有哪些,查询条件是什么,一次性查询多少条。最终会在代码中拼接成为查询源库的SQL语句。拼接规则:```select 配置的字段 from 配置的表名 where 配置的条件 limit 配置的限制条数````,目前一个定时任务仅支持配置一个表的迁移。transfer_insert_config:目标库表配置。迁移任务通过task_id关联到目标库配置,其中主要配置信息就是我们需要插入的表,需要插入的字段有哪些,查询的条件是什么,一次性插入多少条。最终会在代码中拼接成为插入目标库的SQL语句。拼接规则:insert into 配置的表名 (配置的字段) values (…),(),()…配置的插入条数据控制value后面有多少个值。transfer_log:日志记录表。在整个迁移过程中,log是不可或缺的,这里设计了任务迁移的日志跟踪。
八、日志选型和日志设计(链路追踪)
日志框架:Log4j
这是一个由Java编写可靠、灵活的日志框架,是Apache旗下的一个开源项目。最开始没有做过多的考虑,选用的原则就一个,市面上实际使用多的,并且开源的框架就行。不过日志的输出确实精心设计的。
在我们很多项目当中,一个接口的日志,从前到后可能会有很多。在排查的过程中,我们也基本是跟着日志从代码最前面往代码最后面推。这个流程在实际应用当中会略微有一些问题,特别是有新线程,或者并发、大流量的情况基本就很难能一句一句排查了。因为你看到的上一句和下一句,并不一定是一个线程写出来的。所以这个时候我们需要去精心设计整个日志输出,让他能够在各种环境中一目了然。
TLog为啥要去自己设计,不直接使用TLog这样的链路最终日志框架呢?这里有一个问题,TLog链路追踪会在我们的项目中为每一次执行创建一个唯一键,不管传递多少个服务,只要都整合了TLog就能按照唯一键一路追踪下去。这里没有使用的原因只有一个,那就是为了方便管理,并且能够更加快捷的访问到日志。我们对日志的输出设计不仅仅做了链路追踪的流程,还讲唯一键直接存入了库里面,追踪迁移任务更加便捷。
自己设计的日志追踪流程,确实会更加灵便,而且由于放入了库中与log表关联起来,更便于我们查询。当然它也有缺点,如果我们忘记这条规则,会导致链路追踪在链路中断裂。
按照链路追踪的模式我们设计了日志,其中最关键的环节就两个。
唯一键的设计(雪花算法、UUID)
雪花算法和UUID的选型,刚开始自己实现了一个雪花算法。
package com.echo.one.utils.uuid;
/** * 雪花算法 * * @author echo * @date 2022/11/16 11:09 /public class SnowflakeIdWorker { /* * 开始时间截 (2015-01-01) / private final long twepoch = 1420041600000L; /* * 机器id所占的位数 / private final long workerIdBits = 5L; /* * 数据标识id所占的位数 / private final long datacenterIdBits = 5L; /* * 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) / private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /* * 支持的最大数据标识id,结果是31 / private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); /* * 序列在id中占的位数 / private final long sequenceBits = 12L; /* * 机器ID向左移12位 / private final long workerIdShift = sequenceBits; /* * 数据标识id向左移17位(12+5) / private final long datacenterIdShift = sequenceBits + workerIdBits; /* * 时间截向左移22位(5+5+12) / private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; /* * 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) / private final long sequenceMask = -1L ^ (-1L << sequenceBits); /* * 工作机器ID(0~31) / private long workerId; /* * 数据中心ID(0~31) / private long datacenterId; /* * 毫秒内序列(0~4095) / private long sequence = 0L; /* * 上次生成ID的时间截 / private long lastTimestamp = -1L;
/* * 构造函数 * * @param workerId 工作ID (0~31) * @param datacenterId 数据中心ID (0~31) / public SnowflakeIdWorker(long workerId, long datacenterId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format(“worker Id can’t be greater than %d or less than 0”, maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format(“datacenter Id can’t be greater than %d or less than 0”, maxDatacenterId)); } this.workerId = workerId; this.datacenterId = datacenterId; } /* * 获得下一个ID (该方法是线程安全的) * * @return SnowflakeId / public synchronized long nextId() { long timestamp = timeGen(); // 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常 if (timestamp < lastTimestamp) { throw new RuntimeException( String.format(“Clock moved backwards. Refusing to generate id for %d milliseconds”, lastTimestamp - timestamp)); } // 如果是同一时间生成的,则进行毫秒内序列 if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; // 毫秒内序列溢出 if (sequence == 0) { //阻塞到下一个毫秒,获得新的时间戳 timestamp = tilNextMillis(lastTimestamp); } } // 时间戳改变,毫秒内序列重置 else { sequence = 0L; } // 上次生成ID的时间截 lastTimestamp = timestamp; // 移位并通过或运算拼到一起组成64位的ID return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence; } /* * 阻塞到下一个毫秒,直到获得新的时间戳 * * @param lastTimestamp 上次生成ID的时间截 * @return 当前时间戳 / protected long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /* * 返回以毫秒为单位的当前时间 * * @return 当前时间(毫秒) */ protected long timeGen() { return System.currentTimeMillis(); }}
这个算法其实还是很优秀的,其中的分布式id保障唯一设计也确实能够很有效的帮组我们获取链路追踪的唯一键。不过在项目中也暴露出来了两个问题:
1)ID重复(雪花算法就是获取唯一id的,为啥会出现重复的呢?后面解释)2)性能瓶颈
在使用过程中雪花算法出现重复,导致唯一键报错。
雪花算法出现重复的可能就几种:
1)因为雪花算法强依赖机器时钟,所以难以避免受到时钟回拨的影响,有可能产生ID重复。2)同一台机器同一毫秒需要生成多个Id,并且对long workerId、long datacenterId控制不完善导致。
第一种情况这基本没法避免,不过时钟回拨很久才发生一次。所以问题还是出现在第二种情况,主要原因是代码不完善。后面也正是因为代码的不完善直接改用UUID。UUID就一行代码就能够解决的事情,这里还要不断去完善设计的代码。
UUID确实简洁,选型UUID看中的也是这一点,同时也还有其他因素。在整个项目中由于代码的灵活性和整个代码的开放性,在执行的过程中可能会出现多个线程,并行执行,并且为了资源能更高效执行,那么对锁的应用是要慎重考虑的。
雪花算法中,使用了sync同步锁,当我们使用多线程去执行代码的时候,同步锁会成为重量级锁,并且成为我们项目执行的性能瓶颈。这样是最终选择UUID的重要因素。
链路设计
链路设计目前是手动将需要加入到整个链路中的日志加上唯一键。
链路的设计比较简单,而且整个流程链路中,只需要在相应流程模式中完善链路即可,比如:在多线程的环境下,怎么去保证当前线程是我原本的前一任务的链路线;执行模式中循环执行回来时,怎么保证新的流程能够用原本的唯一件。
九、迁移模式
迁移模式总共三种,分别对应transfer_data_task中transfer_mode的0、1、2,推荐使用模式1。
0. 库 -> 文件 -> 库(不推荐使用)
模式流程图:
该模式可以有效、安全地保障数据在迁移过程中,不会出现数据错漏,文件相当于备份操作,后期可以直接追溯迁移过程。唯一的缺点就是大表迁移中,如果使用这种模式需要两个东西,一个是具备local\temp读写权限的账号,一个是足够的磁盘。大表数据写入磁盘很暂用空间,在测试中间,尝试了100w数据,写入文件完毕后,发现有10G(大表,150字段左右)。
-
库 -> 库(推荐使用)
-
source.dump copy target.dump(有风险)
十、模块设计
dataMigration-----bin---------startup.sh-----doc---------blog.sql---------blogbak.sql---------community.sql-----src---------main-------------java-----------------com.echo.one---------------------common-------------------------base-----------------------------TransferContext.java-----------------------------TransferDataContext.java-----------------------------BeanUtilsConfig.java-------------------------constant-----------------------------DataMigrationConstant.java-------------------------enums-----------------------------DatabaseColumnType.java-----------------------------DatabaseDirection.java-----------------------------FormatPattern.java-----------------------------StatusCode.java-----------------------------TaskStatus.java-------------------------exception-----------------------------DataMigrationException.java-------------------------factory-----------------------------DataMigrationBeanFactory.java-------------------------framework-----------------------------config---------------------------------RemoveDruidAdConfig.java-----------------------------filter---------------------------------WebMvcConfig.java-----------------------------handler---------------------------------GlobalExceptionHandler.java-----------------------------result---------------------------------Result.java---------------------controller-------------------------TransferDatabaseConfigController.java-------------------------TransferDataTaskController.java-------------------------TransferHealthy.java-------------------------TransferInsertConfigController.java-------------------------TransferLogController.java-------------------------TransferSelectConfigController.java---------------------dao-------------------------TransferDatabaseConfigMapper.java-------------------------TransferDataTaskMapper.java-------------------------TransferInsertConfigMapper.java-------------------------TransferLogMapper.java-------------------------TransferSelectConfigMapper.java---------------------DataMigrationApplication.java---------------------job-------------------------DataTaskThread.java-------------------------TransferDataTaskJob.java-------------------------TransferLogJob.java---------------------po-------------------------TransferDatabaseConfig.java-------------------------TransferDataTask.java-------------------------TransferInsertConfig.java-------------------------TransferLog.java-------------------------TransferSelectConfig.java---------------------processer-------------------------CheckInsertDataProcessModeOne.java-------------------------CheckInsertDataProcessModeTwo.java-------------------------CheckInsertDataProcessModeZero.java-------------------------CheckInsertDataTransactionalProcessModeThree.java-------------------------CheckSelectDataProcessModeOne.java-------------------------CheckSelectDataProcessModeTwo.java-------------------------CheckSelectDataProcessModeZero.java-------------------------CheckSelectDataTransactionalProcessModeThree.java-------------------------DeleteDataProcessModeOne.java-------------------------DeleteDataProcessModeTwo.java-------------------------DeleteDataProcessModeZero.java-------------------------DeleteDataTransactionalProcessModeThree.java-------------------------InsertDataProcessModeOne.java-------------------------InsertDataProcessModeTwo.java-------------------------InsertDataProcessModeZero.java-------------------------InsertDataProcessOneThread.java-------------------------InsertDataTransactionalProcessModeThree.java-------------------------ProcessMode.java-------------------------SelectDataProcessModeOne.java-------------------------SelectDataProcessModeTwo.java-------------------------SelectDataProcessModeZero.java-------------------------SelectDataTransactionalProcessModeThree.java---------------------service-------------------------imp-----------------------------TransferDatabaseConfigServiceImpl.java-----------------------------TransferDataTaskServiceImpl.java-----------------------------TransferHealthyServiceImpl.java-----------------------------TransferInsertConfigServiceImpl.java-----------------------------TransferLogServiceImpl.java-----------------------------TransferSelectConfigServiceImpl.java-------------------------TransferDatabaseConfigService.java-------------------------TransferDataTaskService.java-------------------------TransferHealthyService.java-------------------------TransferInsertConfigService.java-------------------------TransferLogService.java-------------------------TransferSelectConfigService.java---------------------utils-------------------------DateUtils.java-------------------------jdbc-----------------------------JdbcUtils.java-------------------------SpringContextUtils.java-------------------------thread-----------------------------CommunityThreadFactory.java-------------------------thread-----------------------------DataMigrationRejectedExecutionHandler.java-------------------------thread-----------------------------ExecutorServiceUtil.java-------------------------uuid-----------------------------SnowflakeIdWorker.java---------main-------------resources-----------------application.yml-----------------banner.txt-----------------logback-spring.xml-----------------mapper---------------------TransferDatabaseConfigMapper.xml---------------------TransferDataTaskMapper.xml---------------------TransferInsertConfigMapper.xml---------------------TransferLogMapper.xml---------------------TransferSelectConfigMapper.xml-----LICENSE-----pom.xml-----README.md-----dataMigration.iml
十一、设计模式
如果不考虑设计模式,直接硬编码在我们项目当中会有很多耦合,也会导致整个代码的可读性很差(比如下方的代码)。
首先来看项目类的代码执行的步骤:
1、查询源库数据2、检查查询出的源库数据3、插入目标数据库4、检查插入5、删除源库数据
if(mode = 1) … selectData(); checkSelectData(); insertData(); checkInsertData(); deleteData(); if(mode = 2) … selectData(); checkSelectData(); insertData(); checkInsertData(); deleteData(); if(mode = 3) … selectData(); checkSelectData(); insertData(); checkInsertData(); deleteData(); …
每次新增一个mode,我们就需要手动修改代码,增加一个if,极度不易于拓展,而且if的多少影响阅读和美观。当我们加入设计模式之后,这样的if可以直接被取消。
桥接模式的应用
什么是桥接模式?桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。这种模式涉及到一个作为桥接的接口,使得实体类的功能独立于接口实现类。这两种类型的类可被结构化改变而互不影响。
从上面的代码可以知道,假若我们能消除if else很多的代码就不会重复,比如其中的固定执行流程。然后每一个流程代码,我们设计成为一个固定的模板,每个模板都有一个固定的方法,这个时候,对于具体的实现独立出来就完美解决了这样的问题。
首先解决第一个问题:将步骤代码抽象出来,不管哪个模式,都要走定义好的步骤方法。但是具体实现每个模式互不干扰。
public abstract class ProcessMode {
public final void invoke(TransferContext transferContext) { try { handler(transferContext); } catch (DataMigrationException e) { throw e; } catch (Exception e) { throw new DataMigrationException("system error, msg: " + e.getMessage()); } }
protected abstract void handler(TransferContext transferContext);
}
这里直接抽象出来一个类,保障每个流程步骤都属于它的实现类,这样解决了流程步骤的多实现互不干扰。
然后解决if else:有了抽象类了,我们这里直接使用mode去定位对应的具体实现。当然,这里要配合一个小巧的类的注入名的修改。原本靠if else检索位置,现在直接采用类型来定位,这样就不需要使用判断来做了。类加载到容器中都有自己固定的名字,这里我们将每一个mode对应的实现类设计成为带有mode的类。
设计规则:process + 功能 + mode号, 然后我们按照类的实现自动加载使用对应的实现类。
ProcessMode sourceBean = SpringContextUtils.getBean(“process.selectData.” + transferContext.getTransferDataTask().getTransferMode(), ProcessMode.class);
在桥接模式中,我们可以看到需要一个桥(类)来连接对应的实现。
在我们的代码中其实也正是使用了这种思想,来让我们的代码每个mode方式之间互不干扰,但又能和代码紧密相连接。
ProcessMode完美衔接了我们的代码,充当了我们的桥。
单例模式的应用
单例模式很好理解,单例(Singleton)模式的定义:指一个类只有一个实例,且该类能自行创建这个实例的一种模式。
单例模式有三个特点:
类只有一个实例对象; 该单例对象必须由单例类自行创建;类对外提供一个访问该单例的全局访问点。
为什么用单例?
单例最常见的应用场景有:
Windows的Task Manager(任务管理器)就是很典型的单例模式。项目中,读取配置文件的类,一般也只有一个对象。没有必要每次使用配置文件数据,每次new一个对象去读取。 数据库连接池的设计一般也是采用单例模式,因为数据库连接是一种数据库资源。 在Spring中,每个Bean默认就是单例的,这样做的优点是Spring容器可以管理。在servlet编程中/spring MVC框架,每个Servlet也是单例/控制器对象也是单例。
在我们项目中,到哪里的场景很显然就是第一个,他就是一个任务管理器。作为一个开源的迁移数据项目,我们需要考虑不单单是每次仅执行一个任务,而是每次执行多个,并且每次可能会并发执行很多的任务,当然随之而来的就是数据安全为题,和任务重复的问题。这个我们后面再做解释。
单例模式又分为:懒汉式、饿汉式。为了保证数据的安全,我们这里直接选用了饿汉式。
具体实现如下:
public class ExecutorServiceUtil {
private static final Logger logger = LoggerFactory.getLogger(ExecutorServiceUtil.class);
private static ThreadPoolExecutor executorService;
private static final int INT_CORE_POOL_SIZE = 50; private static final int MAXIMUM_POOL_SIZE = 100; private static final int KEEP_ALIVE_TIME = 60; private static final int WORK_QUEUE_SIZE = 2000;
static { executorService = new ThreadPoolExecutor( INT_CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_TIME, TimeUnit.SECONDS, new ArrayBlockingQueue<>(WORK_QUEUE_SIZE), new CommunityThreadFactory(), new DataMigrationRejectedExecutionHandler()); }
private ExecutorServiceUtil() { if(executorService != null){ throw new DataMigrationException(“Reflection call constructor terminates execution!!!”); } }
public static ExecutorService getInstance() { logger.info(“queue size: {}”, executorService.getQueue().size()); logger.info(“Number of active threads: {}”, executorService.getActiveCount()); logger.info(“Number of execution completion threads: {}”, executorService.getCompletedTaskCount()); return executorService; }}
将我们的线程池进行单例化,为的就是解决任务多发或者高发的问题,有序的控制任务内存和执行。既然提到了多发或者高发,肯定需要解决的就是线程安全问题。这里我们不仅使用了单例,还对部分数据操作的类做了数据安全处理。
类关系图
对关键类都去定义了一个:@Scope(value = “prototype”),使用原型作用域,每个任务过来都会生成一个独有的类,这样有效防止数据共享。
十二、事务管理
在数据迁移过程中,事务的执行是很重要的,如不能保证数据一致,可能在迁移过程中直接导致数据丢失。
项目中也有简单的事务应用。由于设计模式的问题,拓展能力很强,代码灵活度也很高。不过接踵而来的就是部分安全代码的问题,比如事务。当我们独立了插入和删除的时候,我们的事务就被拆分了。那我们需要使用分布式事务或事务传播吗?
项目中并没有!
原本设计模式之前,直接包含在一个事务内即可,这里我们使用了设计模式之后,行不通了。
现有的事务逻辑:
不难发现,如果insertData出现问题,insertData的事务会回滚对应的插入数据,当时deleteData继续执行,这个时候肯定会来带数据一致性问题。不过这里采用了流程上的控制来解决这个问题。
假若:一个迁移任务只执行一次insertData,deleteData,为了保证数据一致性,我们将这两个流程设计了固定的执行先后顺序,并且前面一个报错,后面不再继续执行。
报错如果出现再删除,其影响是:那就是源库的数据有一部分并未被删除掉,但是肯定是已经迁移到了目标库,这个时候严格意义上来讲,数据的迁移并不影响,仅仅只是多出来一份数据,没有数据安全问题。
相关文章:

如何快准稳 实现MySQL大表历史数据迁移?
历史迁移解决方案以微服务架构为基础,使用多种设计模式,如:单例、桥接、工厂、模板、策略等。其中涉及的核心技术有多线程、过滤器等,致力于解决MySQL大表迁移的问题,提供多种迁移模式,如:库到库…...

C和指针:函数
函数定义 函数体就是一个代码块,它在函数被调用时执行。 类型 函数名(形式参数) 代码块 与函数定义相反,函数声明出现在函数被调用的地方。 函数声明 编译器是如何知道该函数期望接受的是什么类型和多少数量的参数。 原型 int *find_int( int key…...

Linux——分离部署,分化压力
PQS/TPS 每秒请求数/ 每秒事务数 // 流量衡量参数 可以根据预估QPS 和 服务器的支持的最高QPS 对照计算 就可以得出 需要上架的服务器的最小数量 PV 页面浏览数 UV 独立用户访问量 // 对于网站的总体访问量 response time 响应时间 // 每个请求的响应时间…...

javaaaa
1 飞机票 代码实现: import java.util.Scanner; public class F1 {public static void main(String[] args) {Scanner input new Scanner(System.in);System.out.print("请输入票价: ");double jia input.nextDouble();System.out.print(&…...
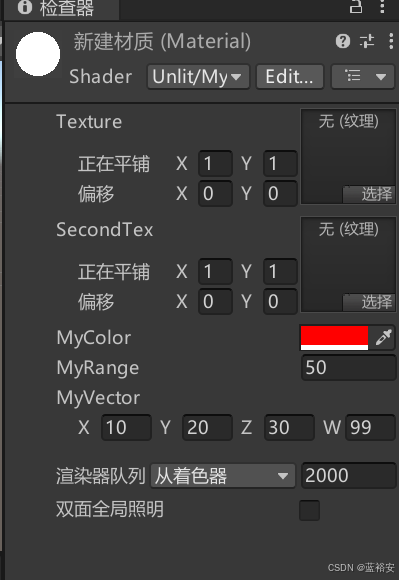
游戏开发引擎___unity位置信息和unlit shader(无光照着色器)的使用,以桌子的渲染为例
unity是左手坐标系 1.位置信息 1.1 代码 using System.Collections; using System.Collections.Generic; using UnityEngine;public class positionTest : MonoBehaviour {public Camera Camera;private void OnGUI(){//世界坐标系,GUI里的标签GUI.Label(new Rec…...

反向沙箱的功能特点
在这个信息化飞速发展的时代,企业的数据安全面临着前所未有的挑战。员工的无意操作、恶意软件的潜伏、甚至是敌对势力的网络攻击,都可能成为企业数据安全的致命威胁。深信达SPN反向沙箱为您筑起了一道坚不可摧的数据安全防线! 来百度APP畅享高…...

可测试,可维护,可移植:上位机软件分层设计的重要性
互联网中,软件工程师岗位会分前端工程师,后端工程师。这是由于互联网软件规模庞大,从业人员众多。前后端分别根据各自需求发展不一样的技术栈。那么上位机软件呢?它规模小,通常一个人就能开发一个项目。它还有必要分前…...

构造函数与析构函数的执行顺序
对象作为成员变量的构造函数与析构函数 当一个类包含另一个类的对象作为成员时,这些成员对象的构造函数会在包含它们的对象的构造函数之前被调用,而它们的析构函数则会在包含它们的对象的析构函数之后被调用。成员对象的构造函数和析构函数的调用顺序与…...

Vue框架;Vue中的选择和循环结构;Vue数据类型;Vue中的事件和动态属性;Vue子组件通过导入在主组件显示在网页;Vue中主组件向子组件传递数据
一,Vue简介 前端现在比较火的三大框架就是:vue ,React,Angular。在国内使用最多的还是: vue >React >Angular Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。它基于标准…...

懒人笔记-opencv4.8.0篇
懒人笔记-opencv4.8.0篇 前言1、卸载 opencv3.4.31.1 cmake1.2 编译过程1.3 卸载1.4 检查代码是否卸载干净 2、安装 opencv4.8.02.1 安装依赖2.2 创建编译目录2.3 设置编译选项2.4 执行编译命令2.5 环境配置2.5.1、环境配置添加库路径2.5.2 更新系统2.5.3 配置bash2.5.4 保存退…...

解决uniapp视频video组件进入全屏再退出全屏后,cover-view失效的问题
给cover-view一个变量如isCloseBtnShow,通过v-if(不要用v-show)来控制显示隐藏。监听video全屏事件,全屏时,设置变量为false,退出全屏时再设为true,这样每次退出全屏,cover-view会重新加载。被覆盖的问题就…...

ip属地河北切换北京
我们知道,每当电脑或手机连接网络时,都会分配到一个网络IP地址,这个IP地址通常与设备所在的地区网络相关联。然而,出于业务或个人需求,有时我们需要将本机的IP地址切换到其他城市。例如要将IP属地河北切换北京…...

fpga入门名词(1)
这是第一代FPGA ,在 FPGA(现场可编程门阵列)设计中,LCA(逻辑单元阵列)通常由几个关键组件构成,包括 IOB、CLB 和 Interconnect。以下是这些组件的简要说明: 1. IOB(Input/Output B…...

设计模式-行为型模式-访问者模式
访问者模式难以实现,且应用该模式可能会导致代码可读性变差,可维护性变差,除非必要,不建议使用; 1.访问者模式定义 允许在运行时将一个或多个操作应用于一组对象,将操作与对象结构分离; 访问者…...

探索Oracle数据库的多租户特性:架构、优势与实践
在云计算和大数据时代,多租户架构成为数据库设计中的一个重要趋势。Oracle数据库的多租户选项(Multitenant)允许单个数据库实例支持多个独立数据库(称为容器数据库和可插拔数据库),每个数据库都有自己的数据…...
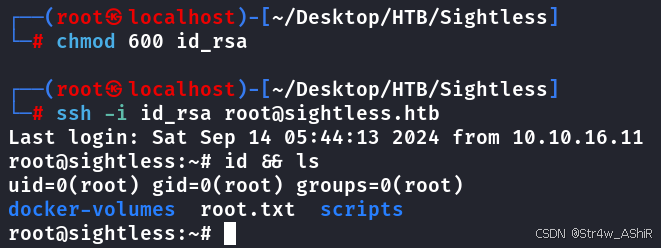
Hack The Box-Sightless
总体思路 CVE-2022-0944->密码破解->chrome调试->PHP-FPM命令执行 信息收集&端口利用 nmap -sSVC sightless.htbStarting Nmap 7.94SVN ( https://nmap.org ) at 2024-09-11 08:40 CST Nmap scan report for sightless.htb Host is up (0.84s latency). Not sh…...

Linux驱动开发-字符设备驱动开发
linux 驱动开发1. 驱动程序的类型2. 驱动开发流程字符设备驱动 1. 基本概念2. 字符设备驱动的基本结构 架构字符设备驱动开发中常用的 API示例以下代码加入了设备类和设备实例的创建 linux 驱动开发 1. 驱动程序的类型 在 Linux 中,驱动程序主要有以下几种类型&am…...
好用的电脑录屏软件有哪些?推荐4款专业工具。
不同系统的电脑上面带有的录屏功能不一样,比如win10上面有Xbox game bar,Mac系统则用的是QuickTime Player,或者是使用快捷键“CommandShift5”。但更方便的,我自己认为是使用一些专业的录屏软件,他门的录制模式多,兼容…...

web基础之XSS
一、搭建XSS平台 安装 1、我这里安装在本地的Phpstudy上,安装过程就是一路下一步(可以改安装路径),附上下载链接: # 官网:https://www.xp.cn/download.html# 蓝莲花 - github下载 https://github.com/fi…...

目标检测-小目标检测方法
小目标检测是计算机视觉中的一个挑战性问题,因为小目标往往在图像中占据的像素较少,容易被背景或其他物体干扰。为了有效地进行小目标检测,研究人员和工程师提出了多种方法和算法来提高检测精度。以下是一些针对小目标检测的有效方式和算法&a…...

IDEA 2018.2.3 下 Maven 依赖包消失?别慌,可能是版本兼容性在作祟
IDEA 2018.2.3 下 Maven 依赖包消失的深度排查指南 当你打开一个尘封已久的老项目,准备继续维护或迁移时,突然发现IDEA的External Libraries里空空如也,只剩下孤零零的JDK包,整个项目文件一片飘红——这种场景对许多维护历史代码库…...

AI智能体任务编排框架:从概念到实战的Mission Control指南
1. 项目概述:为AI智能体打造一个“任务控制中心”最近在折腾AI智能体(Agent)的开发,发现一个挺普遍的问题:当你想让多个智能体协同工作,或者想让单个智能体执行一系列复杂、有依赖关系的任务时,…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

AI助手API开发资源全指南:从入门到实战的宝藏清单
1. 项目概述:一个为AI助手API开发者量身打造的“藏宝图”如果你正在或打算基于OpenAI的Assistant API、Anthropic的Claude API,或是其他主流AI平台的助手接口来构建应用,那么你大概率会遇到一个经典困境:官方文档虽然详尽…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

AI智能体GUI交互实战:从原理到实现,让AI玩转桌面应用
1. 项目概述:一个能“玩”游戏的AI智能体最近在AI智能体(Agent)的圈子里,一个名为“ChattyPlay-Agent”的开源项目引起了我的注意。乍一看名字,你可能会觉得它又是一个基于大语言模型(LLM)的聊天…...

从零打造开源机械爪:低成本机器人抓取方案全解析
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看这个名字,你可能会有点摸不着头脑,它不像“XX管理系统”或者“XX深度学习框架”那样一目了然。但作为一个在开源社区和自动化领域摸爬滚打了十来年的老手…...

Akebi-GC游戏辅助工具:免费开源的游戏体验增强终极指南
Akebi-GC游戏辅助工具:免费开源的游戏体验增强终极指南 【免费下载链接】Akebi-GC (Fork) The great software for some game that exploiting anime girls (and boys). 项目地址: https://gitcode.com/gh_mirrors/ak/Akebi-GC Akebi-GC是一款开源免费的游戏…...

Wedecode:全平台微信小程序源代码反编译与安全审计终极指南
Wedecode:全平台微信小程序源代码反编译与安全审计终极指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh_mirrors/we/wedeco…...