数据结构--二叉树(C语言实现,超详细!!!)
文章目录
- 二叉树的概念
- 代码实现
- 二叉树的定义
- 创建一棵树并初始化
- 组装二叉树
- 前序遍历
- 中序遍历
- 后序遍历
- 计算树的结点个数
- 求二叉树第K层的结点个数
- 求二叉树高度
- 查找X所在的结点
- 查找指定节点在不在
- 完整代码
二叉树的概念
二叉树(Binary Tree)是数据结构中一种非常重要的树形结构,它的特点是每个节点最多有两个子节点,通常称为左子节点和右子节点。这种结构使得二叉树在数据存储和查找等方面具有高效性,广泛应用于各种算法和程序中。
节点(Node):二叉树的基本单元,用于存储数据和指向子节点的指针。每个节点可以包含三个部分:数据域、左指针和右指针。数据域用于存储节点的值,左指针指向左子节点,右指针指向右子节点。
特点
有序性:二叉树的每个节点都有明确的左子节点和右子节点之分,这种有序性使得二叉树在数据查找和遍历等方面具有高效性。
递归性:二叉树的很多操作都可以通过递归的方式来实现,例如遍历、插入和删除等。这种递归性使得二叉树的处理变得简洁而统一。
灵活性:二叉树可以根据实际需求进行不同的扩展和变形,例如平衡二叉树、二叉搜索树等,以满足不同的应用场景。
代码实现
以下代码实现的是最普通的二叉树
二叉树的定义
这段代码定义了一个简单的二叉树节点结构体,其中包含指向左子树和右子树的指针以及一个整数值。
通过这种结构,我们可以构建一个二叉树,其中每个节点都有一个值,以及可能存在的左子树和右子树。
// 首先,定义一个结构体类型别名BinTreeNode,这个结构体用于表示二叉树的节点。
typedef struct BinTreeNode { // left是一个指向左子树根节点的指针。 // 在二叉树中,每个节点最多有两个子节点,这里left表示节点的左子树。 struct BinTreeNode* left; // right是一个指向右子树根节点的指针。 // 与left相似,right表示节点的右子树。 struct BinTreeNode* right; // val表示节点存储的数据值,这里是一个整型值。 int val; } BTNode; // BTNode是这个结构体的类型别名,方便后续在代码中使用。 创建一棵树并初始化
BuyNode函数是一个用于创建和初始化二叉树节点的函数。
它接受一个整数val作为参数,动态分配内存来创建一个新的BTNode结构体实例, 并将该实例的left和right指针初始化为NULL,val成员设置为传入的参数值。
如果内存分配失败,则打印错误信息并返回NULL。
如果成功,则返回指向新创建节点的指针。
// 函数用于创建一个新的二叉树节点,并初始化它
BTNode* BuyNode(int val) { // 使用malloc动态分配内存空间,大小为BTNode结构体的大小 // 并将分配到的内存地址强制转换为BTNode指针类型,赋值给newnode BTNode* newnode = (BTNode*)malloc(sizeof(BTNode)); // 检查malloc是否成功分配了内存 // 如果newnode为NULL,说明内存分配失败 if (newnode == NULL) { // 如果内存分配失败,则打印错误信息 perror("malloc fail"); // 并返回NULL,表示节点创建失败 return NULL; } // 初始化新节点的左子树指针为NULL,表示当前没有左子树 newnode->left = NULL; // 初始化新节点的右子树指针为NULL,表示当前没有右子树 newnode->right = NULL; // 将传入的val值赋给新节点的val成员,设置节点的值 newnode->val = val; // 注意这里的val是函数参数,表示节点的数据值 // 返回新创建的节点指针,供外部使用 return newnode; // 节点创建成功,返回其地址
} 组装二叉树
CreatNode函数是一个用于组装特定二叉树的函数。
它首先调用BuyNode函数来创建6个独立的节点,并分别给它们赋值。
然后,它将这些节点通过它们的left和right指针连接起来,形成一个具有特定结构的二叉树。
最后,它返回根节点的指针,以便外部可以访问和操作这棵树。
// 函数用于组装(创建并连接)一个具体的二叉树,并返回其根节点指针
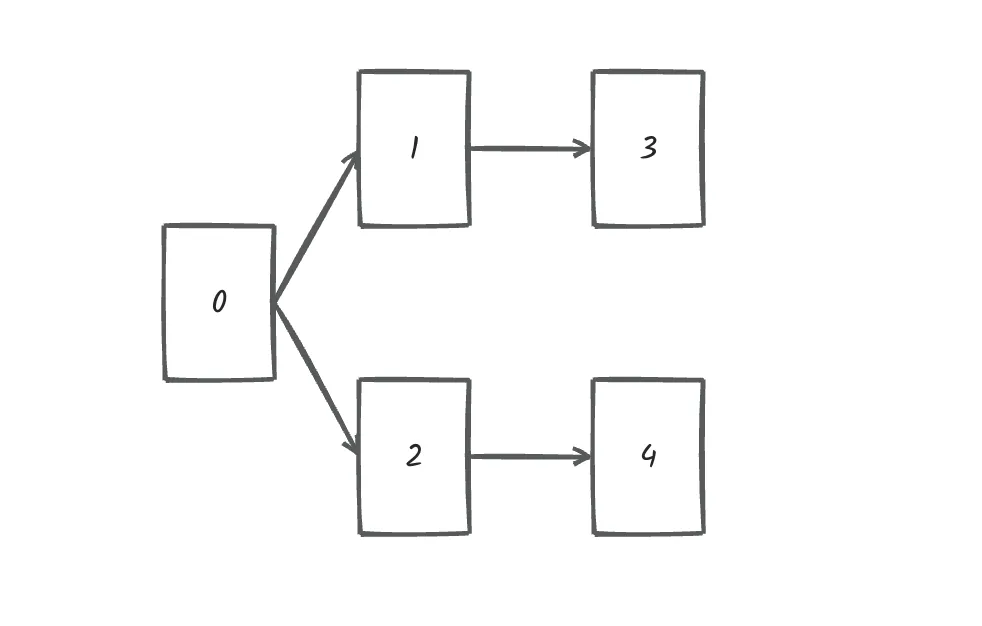
BTNode* CreatNode() { // 调用BuyNode函数创建6个新的二叉树节点,并分别初始化它们的值为1到6 BTNode* n1 = BuyNode(1); // 创建值为1的节点,并作为根节点 BTNode* n2 = BuyNode(2); // 创建值为2的节点 BTNode* n3 = BuyNode(3); BTNode* n4 = BuyNode(4); BTNode* n5 = BuyNode(5); BTNode* n6 = BuyNode(6); // 下面的代码将这些节点连接起来,形成一个具体的二叉树结构 n1->left = n2; // 将n2节点设置为n1节点的左子树 n1->right = n4; // 将n4节点设置为n1节点的右子树 n2->left = n3; // 将n3节点设置为n2节点的左子树(n2没有右子树) n4->left = n5; // 将n5节点设置为n4节点的左子树 n4->right = n6; // 将n6节点设置为n4节点的右子树 //以上是我们人工建的一颗二叉树// 返回根节点的指针,这样外部就可以通过这个指针来访问整棵树了 return n1; // 根节点是n1,所以返回n1的指针
} 前序遍历
从这个函数开始,后面的函数基本都是递归了,强烈建议在刚开始学的时候多画几遍递归展开图,理解每个函数的运行过程,熟练之后就可以直接在脑海里理解过程了。
PreOrder函数实现了二叉树的前序遍历。
前序遍历的顺序是:先访问根节点,然后遍历左子树,最后遍历右子树。
在遍历过程中,如果遇到空节点(即子树不存在),则打印"N "。这里打印N是为了更易于理解。
这个函数通过递归的方式简洁地实现了前序遍历的逻辑。
// 定义前序遍历函数,参数为二叉树的根节点指针
void PreOrder(BTNode* root) { // 首先检查根节点是否为空 if (root == NULL) { // 如果根节点为空,则打印"N "表示此处无节点(NULL的简写) printf("N "); // 然后直接返回,不再继续遍历 return; } // 如果根节点不为空,则首先打印根节点的值 printf("%d ", root->val); // 接着递归地调用前序遍历函数,传入左子树的根节点 // 这样会先遍历整个左子树 PreOrder(root->left); // 最后递归地调用前序遍历函数,传入右子树的根节点 // 这样会遍历整个右子树 PreOrder(root->right);
} 中序遍历
InOrder函数递归地先处理左子树,然后打印当前节点的值,最后处理右子树,直到所有节点都被访问并打印出来。如果树中存在空指针(即某个节点没有左子节点或右子节点),则打印"N "来表示该位置为空。
中序遍历的顺序是:先遍历左子树,然后访问根节点,最后遍历右子树。
在遍历过程中,如果遇到空节点(即子树不存在),则打印"N "。这里打印N是为了更易于理解。
这个函数也是通过递归的方式实现的,每次递归都处理当前节点的左子树、自身和右子树。
// 定义中序遍历函数,参数为二叉树的根节点指针
void InOrder(BTNode* root) { // 首先检查根节点是否为空 if (root == NULL) { // 如果当前节点为空(即已经遍历到叶子节点下面,或者子树不存在) // 则打印"N "表示此处无节点值可输出 printf("N "); // 打印完毕后直接返回,不再继续遍历 return; } // 如果当前节点不为空,则先递归调用中序遍历函数,传入左子节点 // 这样可以确保在打印当前节点之前,先遍历并打印整个左子树 InOrder(root->left); // 遍历完左子树后,回到当前节点,并打印当前节点的值 printf("%d ", root->val); // 打印完当前节点值后,递归调用中序遍历函数,传入右子节点 // 这样可以确保在打印完当前节点后,继续遍历并打印整个右子树 InOrder(root->right);
} 后序遍历
PostOrder函数实现了二叉树的后序遍历。
后序遍历的顺序是:先遍历左子树,然后遍历右子树,最后访问根节点。
这个过程一直进行到所有节点都被访问并打印出来为止。
遍历过程中,若遇到空节点(即某节点没有左子节点或右子节点,或子树不存在),则打印"N "。
函数通过递归方式实现,递归的基准情况是节点为空时返回。
// 定义后序遍历函数,参数为二叉树的根节点指针
void PostOrder(BTNode* root) { // 首先检查传入的根节点是否为空 if (root == NULL) { // 如果根节点为空,表示已经遍历到了叶子节点下面或者子树不存在 // 在此处打印"N ",作为空节点(NULL)的占位符输出 printf("N "); // 打印完空节点后,直接返回,不再继续递归遍历 return; } // 如果当前节点不为空,则先递归调用后序遍历函数,传入左子节点 // 后序遍历的顺序是先遍历左子树 PostOrder(root->left); // 接着递归调用后序遍历函数,传入右子节点 // 后序遍历接下来遍历右子树 PostOrder(root->right); // 在确保左右子树都已经遍历完成后,打印当前节点的值 // 后序遍历的最后一步是访问(打印)根节点 printf("%d ", root->val);
} 计算树的结点个数
TreeSize函数用于递归地计算一棵二叉树中节点的总数。
函数首先检查传入的根节点是否为空,如果为空则返回0,表示没有节点。
如果根节点不为空,则函数递归地调用自身来计算左子树和右子树的节点数,
然后将这两个数相加,并加上1(代表当前根节点),从而得到整棵树的节点总数。
对于每个非空节点,函数会分别计算其左子树和右子树的节点数,然后将这两个数目相加,并加上当前节点自身(计数为1),从而得到以当前节点为根的子树的节点总数。这个过程会一直递归进行,直到遍历完整棵树,最终返回整棵树的节点总数。
递归方法写的代码一般都比较短,但是比一般方法更难以理解
// 定义计算二叉树节点个数的函数,参数为二叉树的根节点指针
int TreeSize(BTNode* root) { // 使用三目运算符(条件运算符)判断根节点是否为空 // 如果root为空,说明已经遍历到了叶子节点下面或者子树不存在,直接返回0 // 否则,递归地计算左子树的节点个数和右子树的节点个数,并将它们相加,再加上根节点自身(即+1) return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
} 求二叉树第K层的结点个数
TreeKLevel函数通过递归的方式求解二叉树第k层的节点个数。
以下方法的核心是:当前树的第k层个数 ==左子树的第k-1层个数 +左子树的第k-1层个数
递归的基准情况有两种:一是当节点为空时返回0,二是当k等于1时返回1。
对于其他情况,函数会递归地调用自身来计算左子树和右子树中第k-1层的节点数,
然后将这两个数相加得到结果。这个过程会一直进行下去,直到达到基准情况为止。
小结:这段代码的核心思想是利用递归逐层向下遍历二叉树,同时记录当前所在的层数。当遍历到目标层时,返回该层的节点数。由于二叉树的层数是从根节点开始计算的,因此在每次递归调用时,都需要将目标层数k减去1,以正确地定位到下一层。通过这种方式,函数能够准确地计算出二叉树中任意一层的节点个数。
// 定义函数TreeKLevel,用于求二叉树第k层的节点个数
// 参数root为二叉树的根节点指针,k为目标层数
int TreeKLevel(BTNode* root, int k) { // 如果根节点为空,说明已经遍历到空树或者子树不存在 // 直接返回0,表示第k层没有节点 if (root == NULL) { return 0; } // 如果k等于1,说明当前层就是第一层(根节点所在的层) // 直接返回1,因为根节点是唯一一个在第1层的节点 if (k == 1) { return 1; } // 如果k大于1,说明目标层在根节点的下面 // 递归地调用TreeKLevel函数,分别传入左子树和右子树的根节点,以及k-1作为新的层数 // 然后将两个递归调用的结果相加,得到第k层的节点总数 // 注意这里k要减1,是因为往下一层递归时,层数要相应地减少 return TreeKLevel(root->left, k - 1) + TreeKLevel(root->right, k - 1);
} 求二叉树高度
该函数通过递归的方式计算二叉树的高度。
递归的基准情况是当节点为空时,返回1(表示空树或不存在的高度,加1是为了方便递归计算)。
/对于非空节点,函数会分别计算其左子树和右子树的高度,然后取两者中的较大值,并加1作为当前树的高度。
返回值是整棵树的高度。
// 定义函数TreeHigh,用于求二叉树的高度
// 参数root为二叉树的根节点指针
int TreeHigh(BTNode* root) { // 如果根节点为空,说明当前子树不存在或为空树 // 按照常规定义,空树的高度为0,但这里为了递归方便,返回1表示高度为0的层级上加1 // 注意:这种定义在递归的上下文中是合理的,但在实际应用中可能需要调整,以确保空树高度为0 if (root == NULL) { return 1; } // 递归调用TreeHigh函数,计算左子树的高度 int leftHigh = TreeHigh(root->left); // 递归调用TreeHigh函数,计算右子树的高度 int rightHigh = TreeHigh(root->right); // 使用三目运算符比较左子树和右子树的高度 // 返回较高的一边的高度,并加上1(加上根节点所在的这一层) return leftHigh > rightHigh ? leftHigh + 1 : rightHigh + 1;
} 查找X所在的结点
TreeFind函数是一个递归函数,用于在二叉树中查找值为x的节点。
它首先检查根节点是否为空或者是否就是要找的节。如果根节点为空,则返回NULL表示未找到。如果根节点的值等于x,则返回根节点的指针。
否则,函数会递归地在左子树和右子树中查找,直到找到目标节点或者遍历完整棵树。
如果在整棵树中都没有找到值为x的节点,则最终返回NULL。
// 定义函数TreeFind,用于在二叉树中查找值为x的节点,并返回该节点的指针
// 参数root为二叉树的根节点指针,x为要查找的值
BTNode* TreeFind(BTNode* root, int x) { // 如果根节点为空,说明已经遍历到了空子树或者树本身为空 // 直接返回NULL,表示在当前子树中没有找到值为x的节点 if (root == NULL) { return NULL; } // 如果根节点的值等于x,说明找到了目标节点 // 直接返回根节点的指针 if (root->val == x) { return root; } // 递归调用TreeFind函数,在左子树中查找值为x的节点 // 将返回的节点指针赋值给ret1 BTNode* ret1 = TreeFind(root->left, x); // 如果ret1不为空,说明在左子树中找到了值为x的节点 // 直接返回ret1,即找到了目标节点的指针 if (ret1) { return ret1; } // 如果左子树中没有找到,继续递归调用TreeFind函数,在右子树中查找值为x的节点 // 将返回的节点指针赋值给ret2 BTNode* ret2 = TreeFind(root->right, x); // 如果ret2不为空,说明在右子树中找到了值为x的节点 // 直接返回ret2,即找到了目标节点的指针 if (ret2) { return ret2; } // 如果左右子树中都没有找到值为x的节点,说明整个树中都不存在该节点 // 返回NULL,表示没有找到目标节点 return NULL;
}
查找指定节点在不在
// 参数:root 是指向二叉树根节点的指针,x 是要查找的节点值
// 返回值:bool 类型,如果找到指定节点则返回 true,否则返回 false,这个通常用于条件语句或者循环语句里,返回true时执行,返回false时不执行
// 功能:在二叉树中查找指定的节点值是否存在
bool TreeFindExit(BTNode* root, int x) { // 如果当前节点为空(即已经遍历到叶子节点之后的位置),则返回 false if (root == NULL) { return false; } // 如果当前节点的值等于要查找的值 x,则说明找到了指定的节点 // 直接返回 true if (root->val == x) { return true; } // 如果当前节点的值不是要查找的值,则递归地在左子树和右子树中查找 // 使用逻辑或操作符 ||,表示如果左子树或右子树中任何一个找到了指定节点就返回 true // 如果左右子树都没有找到,最终会返回 false return TreeFindExit(root->left, x) || TreeFindExit(root->right, x);
}
完整代码
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>//二叉树的定义
typedef struct BinTreeNode {struct BinTreeNode* left;struct BinTreeNode* right;int val;
}BTNode;//创建一棵树并初始化
BTNode* BuyNode(int val) {BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL) {perror("malloc fail");return;//注意这里应该是return NULL}newnode->left = NULL;newnode->right = NULL;newnode->val = val;//这里是valreturn newnode;//创建了就要返回
}//组装二叉树
BTNode* CreatNode() {BTNode* n1 = BuyNode(1);BTNode* n2 = BuyNode(2);BTNode* n3 = BuyNode(3);BTNode* n4 = BuyNode(4);BTNode* n5 = BuyNode(5);BTNode* n6 = BuyNode(6);n1->left = n2;n1->right = n4;n2->left = n3;n4->left = n5;n4->right = n6;return n1;//记得返回
}//前序遍历
void PreOrder(BTNode* root) {if (root == NULL) {printf("N ");return;}printf("%d ", root->val);PreOrder(root->left);PreOrder(root->right);
}//中序遍历
void InOrder(BTNode* root) {if (root == NULL) {printf("N ");return;}InOrder(root->left);printf("%d ",root->val);InOrder(root->right);
}//后序遍历
void PostOrder(BTNode* root) {if (root == NULL) {printf("N ");return;}PostOrder(root->left);PostOrder(root->right);printf("%d ",root->val);
}//计算树的结点个数
int TreeSize(BTNode* root) {return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}//求二叉树第K层的结点个数
int TreeKLevel(BTNode* root,int k) {if (root == NULL) {return 0;}if (k == 1) {//k=1时不需要再往下求了return 1;}return TreeKLevel(root->left, k - 1) + TreeKLevel(root->right, k - 1);
}
//求二叉树高度
int TreeHigh(BTNode* root) {if (root== NULL) {return 1;}int leftHigh = TreeHigh(root->left);int rightHigh = TreeHigh(root->right);return leftHigh > rightHigh ? leftHigh + 1 : rightHigh + 1;
}//查找X所在的结点
BTNode*TreeFind(BTNode*root,int x){if (root == NULL) {return NULL;}if (root->val == x) {return root;}BTNode* ret1=TreeFind(root->left, x);if (ret1) {return ret1;}BTNode* ret2 = TreeFind(root->right, x);if (ret2) {return ret2;}return NULL;}//查找指定节点在不在
bool TreeFindExit(BTNode* root, int x) {if (root == NULL) {return false;}if (root->val == x) {return true;}return TreeFindExit(root->left, x) || TreeFindExit(root->right, x);
}int main() {BTNode* root = CreatNode();PreOrder(root);printf("\n");InOrder(root);printf("\n");PostOrder(root);printf("\n");int high = TreeHigh(root);printf("%d\n", high);int a= TreeKLevel(root,2);printf("%d\n", a);BTNode* b = TreeFind(root, 1);printf("%d\n", b->val);if (TreeFindExit(root, 2)) {printf("存在\n");}else {printf("不存在\n");}return 0;
}
相关文章:
)
数据结构--二叉树(C语言实现,超详细!!!)
文章目录 二叉树的概念代码实现二叉树的定义创建一棵树并初始化组装二叉树前序遍历中序遍历后序遍历计算树的结点个数求二叉树第K层的结点个数求二叉树高度查找X所在的结点查找指定节点在不在完整代码 二叉树的概念 二叉树(Binary Tree)是数据结构中一种…...

【将字符串变为空的编辑距离】
题目描述 求由s串变成t串的编辑距离 在s串的开头/末尾添加一个字符,花费p 在s串的开头/末尾添加一个s串的子串,花费q 每次作都是基于当前的s串 s串初始为空 分析 等价于将一个字符串变为空串的过程 第一层按照长度遍历(如果按照下标i,j遍…...

卡特兰数的推理
卡特兰数(Catalan number),又称卡塔兰数、明安图数,是组合数学中一种常出现于各种计数问题中的数列。它以比利时数学家欧仁查理卡特兰的名字命名,但值得注意的是,这一数列的首次发现可以追溯到1730年&#…...

高精度治具加工的重要性和优势
在现代工业制造中,高精度治具加工扮演着举足轻重的角色。它不仅关乎产品制造的精度与质量,还直接影响到生产效率和成本控制。因此,时利和将深入探讨高精度治具加工的重要性和优势,对于提升工业制造水平具有重要意义。 高精度治具加…...

新版IDEA提示@Autowired不建议字段注入
随着项目的复杂度的增加,我们通常会在一个业务类中注入其他过多的业务类。从而使当前的业务层扩充成一个大而全的功能模块。那么就容易出现一下问题 字段注入会让依赖关系变得不那么明显,因为你无法通过构造函数看到所有的依赖项。使用构造函数时&#…...

adb的安装和使用 以及安装Frida 16.0.10+雷电模拟器
.NET兼职社区 .NET兼职社区 .NET兼职社区 1.下载adb Windows版本:https://dl.google.com/android/repository/platform-tools-latest-windows.zip 2.配置adb环境变量 按键windowsr打开运行,输入sysdm.cpl,回车。 高级》环境变量》系统变量》…...

解决移动端1px 边框优化的8个方法
前言 您是否注意到 1px 边框在移动设备上有时会显得比预期的要粗?这种不一致源于移动屏幕的像素密度不同。 在 Web 开发中,我们使用 CSS 来设置页面样式。但是,CSS 中的 1px 并不总是转换为设备上的物理 1px。这种差异就是我们的“1px 边框…...

频带宽度固定,如何突破数据速率的瓶颈?
目录 目录 引言 信道 频带宽度 信噪比 信噪比的重要性 影响信噪比的因素 码元 码元的特点: 码元与比特的关系: 码元的作用: 码元的类型: Question 类比解释: 技术解释: 引言 在现代通信系统中…...

Linux网络编程 --- 高级IO
前言 IO Input&&Output read && write 1、在应用层read && write的时候,本质把数据从用户层写给OS --- 本质就是拷贝函数 2、IO 等待 拷贝。 等的是:要进行拷贝,必须先判断读写事件成立。读写事件缓冲区空间满…...

Python中给定一个数组a = [2,3,9,1,0],找出其中最大的一个数,并打印出来 求解?
Python有内置的max函数可以取最大值: max([2,3,9,1,0])也可以使用sorted先排序,再索引取出最大值: sorted([2,3,9,1,0])[-1]如果不用内置函数,自己排序算法来找出最大值,也有很多选择。 比如冒泡排序、循环排序、交…...
系统优化工具 | PC Cleaner v9.7.0.3 绿色版
PC Cleaner是一款功能强大的电脑清理和优化工具,旨在通过清理系统垃圾文件、解除恶意软件和优化系统性能来提高计算机的运行效率。该软件提供了多种功能,可以帮助用户维护和提升计算机的整体表现。 PC Cleaner 支持 Windows 7 及以上操作系统࿰…...

JavaSE、JavaEE 与 JavaWeb 的详解与区别
一、JavaSE(Java Standard Edition)——标准版 1. 什么是JavaSE JavaSE,全称Java Standard Edition,译为Java标准版,是Java平台的基础,也是开发者最常使用的Java版本。JavaSE包含了编程中最基础的核心库,如Java的基本语法、面向对象编程、集合框架、多线程、网络编程、…...
HCIE和CCIE,哪个含金量更高点?
在现在内卷的大环境下,技术岗可谓人人自危,也因此各种认证的重视程度直线升高。 特别是华为认证的HCIE和思科认证的CCIE,它们都代表着网络技术领域的顶尖水平。 但面对这两个高含金量的认证,不得不让人问出这个问题:同…...

2024.9.14 Python与图像处理新国大EE5731课程大作业,马尔可夫随机场和二值图割,校正立体图像的深度
1.马尔科夫随机场和二值图割 马尔可夫随机场(MRF, Markov Random Field): MRF 是一种用来描述图像像素之间空间关系的概率模型。它假设图像中的像素不仅取决于自身的值,还与周围像素有关。这种模型经常用于图像分割、去噪等任务。…...

工业大模型市场图谱:53个工业大模型全面梳理
工业场景要求严谨、容错率低,核心业务场景对模型准确率的要求达到95%以上、对幻觉的容忍率为0,因此通用基础大模型的工业知识往往不足以满足工业场景的应用需求。 根据沙丘智库发布的《2024年中国工业大模型应用跟踪报告》,工业大模型是指在…...
【代码随想录训练营第42期 Day58打卡 - 图论Part8 - 拓扑排序
目录 一、拓扑排序介绍 定义 特点 实现方法(2种) 应用 二、题目与题解 题目:卡码网 117. 软件构建 题目链接 题解:拓扑排序 - Kahn算法(BFS) 三、小结 一、拓扑排序介绍 对于拓扑排序,…...

JVM内部结构解析
Java虚拟机(JVM)是Java程序运行的基础环境,它为Java程序提供了一个与平台无关的执行环境。了解JVM的内部结构对于Java开发者来说至关重要,因为它可以帮助开发者优化程序性能,理解垃圾回收机制,以及诊断和解…...

誉龙视音频综合管理平台 RelMedia/FindById SQL注入漏洞复现
0x01 产品简介 誉龙视音频综合管理平台是深圳誉龙数字技术有限公司基于多年的技术沉淀和项目经验,自主研发的集视音频记录、传输、管理于一体的综合解决方案。该平台支持国产化操作系统和Windows操作系统,能够接入多种类型的记录仪,实现高清实时图传、双向语音对讲、AI应用…...

MATLAB系列01:MATLAB介绍
MATLAB系列01:MATLAB介绍 1. MATLAB介绍1.1 MATLAB的优点1.2 MATLAB的缺点1.3 MATLAB的开发环境1.3.1 获取帮助的方法:1.3.2 一些重要的命令:1.3.3 MATLAB搜索路径 1. MATLAB介绍 MATLAB(矩阵实验室的简称)是一种专业的计算机程序࿰…...

GEE 按范围导出 Sentinel-2 卫星影像
Sentinel-2 卫星提供了高分辨率的地表覆盖图像,广泛应用于农业监测、城市规划、环境变化分析等诸多领域。在 Google Earth Engine (GEE) 中,我们能够按特定地理范围导出这些影像,以支持更深入的研究和分析。 使用方法 💻 GEE 提供…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践
DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

MySQL 索引底层 B+ 树原理
聊 MySQL 索引,不讲 B 树,那就是在耍流氓。 大家好,我是乱码字符。今天咱们深入聊聊 MySQL 索引的底层数据结构——B 树。这篇文章能让你彻底搞明白,为什么有时候明明加了索引,查询却还是慢成狗。 先说说为什么要用树结…...

Faderwave合成器设计:从波形塑造到数字滤波的嵌入式音频实践
1. 项目概述:从推子到声音,Faderwave合成器的设计哲学如果你玩过硬件合成器,或者对数字音频合成感兴趣,那你肯定知道,声音设计的起点往往是一个简单的波形。但如何让这个波形“活”起来,变成你脑海中那个独…...

多智能体涌现环境:从局部交互到群体智能的深度解析与实践
1. 项目概述:多智能体涌现环境的深度探索最近在复现和深入研究一个名为“multi-agent-emergence-environments”的开源项目,它来自OpenAI。这个项目名听起来有点学术,但它的核心思想非常迷人:在一个模拟的物理沙盒环境中ÿ…...

像素风格技能图标自动生成:Python+Pillow实现模板化设计
1. 项目概述与核心价值最近在和一些做独立开发者和内容创作者的朋友聊天时,发现一个普遍痛点:大家手头都有不少好想法,但一到具体执行,尤其是需要制作宣传素材时,就卡住了。比如,想给自己的新App做个宣传图…...

AI应用开发实战:从RAG系统到多模型API调用的开源项目解析
1. 项目概述:一个AI项目的开源实践最近在GitHub上看到一个名为“hferello/ai”的项目,这个标题非常简洁,甚至可以说有些“神秘”。乍一看,它可能是一个关于人工智能的通用仓库,但点进去之后,你会发现它远不…...

小智聊天机器人的本地化部署。
前天到了,小智机器人ESP32-S2的套件(非焊接版的那一款),找王同学,学了学怎么焊接。昨天,使用面包板搭建电路,安装元器件,服务器端注册设置,刷程序,很快就完成…...

2025届毕业生推荐的AI学术平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作范畴之内,怎样迅速、精确地给论文确定一个既契合规范又能够切实有效吸…...
)
尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表)
更多请点击: https://intelliparadigm.com 第一章:尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表) 尼泊尔语(नेपाली)作为IS…...