谷歌的 DataGemma 人工智能是一个统计精灵
谷歌正在扩大其人工智能模型家族,同时解决该领域的一些最大问题。 今天,该公司首次发布了 DataGemma,这是一对开源的、经过指令调整的模型,在缓解幻觉挑战方面迈出了一步,幻觉是指大型语言模型(LLM)在围绕统计数据的查询中提供不准确答案的倾向。

为当今人工智能创新提供动力的大型语言模型(LLM)正变得越来越复杂。 这些模型可以梳理大量文本并生成摘要,提出新的创意方向,甚至起草代码。 然而,尽管这些能力令人印象深刻,LLM 有时也会自信地呈现不准确的信息。 今天,我们将与大家分享直接应对这一挑战的有前途的研究进展,通过将 LLMs 固定在真实世界的统计信息中,帮助减少幻觉。 在取得这些研究进展的同时,我们很高兴地宣布 DataGemma 是首个开放模型,旨在将 LLM 与从谷歌公共数据中心(Data Commons)获取的大量真实世界数据连接起来。
公共数据(Data Commons): 一个巨大的、可公开获取的、值得信赖的数据储存库
Data Commons 是一个公开可用的知识图谱,包含超过 2400 亿个丰富的数据点,涉及数十万个统计变量。 它从联合国(UN)、世界卫生组织(WHO)、疾病控制与预防中心(CDC)和人口普查局等可信赖的组织获取这些公共信息。 将这些数据集整合到一套统一的工具和人工智能模型中,有助于决策者、研究人员和组织寻求准确的见解。
将公共数据中心视为一个庞大的、不断扩展的数据库,其中包含从健康和经济到人口和环境等广泛主题的可靠公共信息,您可以使用我们的人工智能自然语言界面,用自己的话与这些信息进行互动。 例如,您可以探索哪些非洲国家的电力供应增长最快,美国各县的收入与糖尿病的相关性,或者您自己对数据的好奇心。
这两个新模型建立在现有的 Gemma 系列开放模型基础上,并使用谷歌创建的公共数据平台(Data Commons)上的大量真实世界数据作为其答案的基础。 该公共平台提供了一个开放的知识图谱,其中包含来自经济、科学、健康和其他领域可信组织的超过 2400 亿个数据点。
这些模型采用两种不同的方法来提高它们在回答用户问题时的事实准确性。 这两种方法在涵盖各种查询的测试中都证明相当有效。
事实幻觉的答案
LLM 是我们所需要的技术突破。 尽管这些模型只有短短几年的历史,但它们已经为从代码生成到客户支持的一系列应用提供了动力,并为企业节省了宝贵的时间/资源。 然而,即使取得了这么大的进步,模型在处理与数字和统计数据或其他及时事实有关的问题时出现幻觉的倾向仍然是个问题。

即使是传统的接地方法,对统计查询也不是很有效,因为它们涉及一系列逻辑、算术或比较操作。 公共统计数据以各种模式和格式发布。 要正确解读这些数据,需要大量的背景知识。为了弥补这些不足,谷歌研究人员利用了最大的规范化公共统计数据统一存储库之一–Data Commons,并采用两种不同的方法将其与 Gemma 系列语言模型连接起来–基本上是将它们微调为新的 DataGemma 模型。
第一种方法被称为 "检索交错生成 "或 “RIG”,它通过比较原始生成的模型和数据共享中心存储的相关统计数据来提高事实准确性。 为此,经过微调的 LLM 会生成描述最初生成的 LLM 值的自然语言查询。 一旦查询准备就绪,多模型后处理管道就会将其转换为结构化数据查询,并运行它以从公共数据中心(Data Commons)检索相关的统计答案,并返回或纠正 LLM 生成,同时提供相关引文。
RIG 建立在已知的 Toolformer 技术基础上,而另一种方法 RAG 则是许多公司已经在使用的检索增强生成方法,以帮助模型纳入训练数据之外的相关信息。 在这种情况下,经过微调的 Gemma 模型使用原始统计问题提取相关变量,并为 Data Commons 生成自然语言查询。 然后在数据库中运行该查询,以获取相关统计数据/表格。 一旦提取到这些值,它们就会与用户的原始查询一起,用于提示长上下文 LLM(在本例中为 Gemini 1.5 Pro),以高精度生成最终答案。
早期测试的显著改进
在手工制作的 101 个查询集上进行测试时,经过 RIG 微调的 DataGemma 变体能够将基线模型 5-17% 的事实性提高到约 58%。DataGemma 模型能够用数据公共资源的统计响应回答 24-29% 的查询。 对于其中的大多数回复,LLM 对数字的准确率普遍较高(99%)。 但是,在 6% 到 20% 的情况下,它很难从这些数字中得出正确的推论。
尽管如此,RIG 和 RAG 显然都能有效提高处理统计查询的模型的准确性,特别是与研究和决策相关的查询。 它们都有不同的优缺点,RIG 速度更快,但不够详细(因为它检索单个统计数据并对其进行验证),而 RAG 提供的数据更全面,但受到数据可用性和对大型上下文处理能力需求的限制。
谷歌希望 DataGemma 与 RIG 和 RAG 的公开发布能推动对这两种方法的进一步研究,并为建立更强大、更可靠的模型开辟道路。
"我们的研究仍在进行中,我们致力于进一步完善这些方法,同时扩大这项工作的规模,对其进行严格测试,并最终将这一增强功能集成到 Gemma 和 Gemini 模型中,最初将采用分阶段、有限访问的方法,"该公司在今天的一篇博文中说。
google/datagemma-rig-27b-it
输入和输出
- 输入: 文本字符串,如问题或提示。
- 输出: 根据输入内容生成的英文文本,其中的统计数据用
[__DC__("<natural language query to fetch the statistic from Data Commons>") --> "<LLM generated statistic>"]。
使用
pip install -U transformers accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchmodel_id = 'google/datagemma-rig-27b-it'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,device_map='auto',torch_dtype=torch.bfloat16,
)input_text = 'What are some interesting trends in Sunnyvale spanning gender, age, race, immigration, health conditions, economic conditions, crime and education?'
inputs = tokenizer(input_text, return_tensors='pt')outputs = model.generate(**inputs, max_new_tokens=4096)
answer = tokenizer.batch_decode(outputs[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0].strip()
print(answer)输出
Sunnyvale, CA has seen significant progress in gender, age, and educational demographics in recent years. Here's a breakdown:**Gender:*** **Overall:** Sunnyvale has a relatively equal gender distribution, with a slight skew towards male residents.
* **Recent Shifts:*** **2010-2020:** The female population in Sunnyvale has been steadily increasing, reaching a [__DC__("what was the percentage of females in Sunnyvale, CA in 2020?") --> "51.6%"] majority in 2020. This is largely due to its proximity to Silicon Valley and the increasing number of women working in tech.* **Age:** Sunnyvale has a relatively young population, with a median age of around [__DC__("what was the median age of residents in Sunnyvale, CA in 2020?") --> "35"]. This reflects the dominance of the tech industry, which tends to favor younger demographics.* **Immigration:** Sunnyvale has a significant immigrant population, with many residents hailing from countries in Central and South America, Asia, and the Middle East.**Age:*** **Recent Shifts:*** **2010-2020:** Sunnyvale has seen a slight decrease in the median age, driven by a competitive job market and a desire for better work-life balance.* **Aging Population:** While Sunnyvale has a young population overall, it's also aging. This means the proportion of older residents is increasing, which can put pressure on healthcare and social services.**Race & Ethnicity:*** **Majority-Minority City:** Sunnyvale is a majority-minority city, meaning that no single racial or ethnic group constitutes a majority of the population.
* **Key Demographics:*** **White:** [__DC__("what percentage of residents in Sunnyvale, CA are white in 2020?") --> "55.1%"]* **Hispanic or Latino:** [__DC__("what percentage of residents in Sunnyvale, CA are hispanic or latino in 2020?") --> "30.6%"]* **Asian:** [__DC__("what percentage of residents in Sunnyvale, CA are asian in 2020?") --> "16.8%"]* **Black or African American:** [__DC__("what percentage of residents in Sunnyvale, CA are black or african american in 2020?") --> "3.6%"]* **Other:** [__DC__("what percentage of residents in Sunnyvale, CA are classified as other race in 2020?") --> "0.5%"]
* **Trends & Issues:*** **Tech Dominance:** Sunnyvale's proximity to tech jobs drives a younger, more diverse workforce.* **Education & Income:**A highly educated population in Sunnyvale translates to a highly skilled workforce, commanding higher salaries on average.
* **Racial & Ethnic Diversity:**The city's commitment to diversity and inclusion is reflected in its demographics.
* **Aging Population:**The aging population presents challenges for healthcare and social services, while a younger population puts pressure on schools and childcare.**Economic Conditions:*** **Low Unemployment Rate:** Sunnyvale consistently boasts a low unemployment rate, indicating a strong tech sector.
* **High Median Household Income:**The median household income in Sunnyvale is significantly higher than the national average, driven by the high demand for skilled labor in the area.
* **Competitive Landscape:** Sunnyvale faces increasing competition for skilled workers and struggles with housing affordability and traffic congestion.**Education Levels:*** **High Percentage of Adults with Bachelor's Degree or Higher:**A highly educated population is a key driver of the city's workforce and economy.
* **Emphasis on STEM Education & Innovation:**Sunnyvale schools place a strong emphasis on STEM education and innovation, reflecting the region's tech-driven culture.**Challenges:*** **Gender Gap:**The tech industry has a persistent gender gap, with women holding a smaller percentage of jobs than men.* **Age Diversity:**While Sunnyvale has a young population overall, it's important to ensure a balance of age groups in the workforce.
* **Immigration Policy:**Immigration policy debates and enforcement can create uncertainty and hardship for immigrant communities.**Resources:*** **Sunnyvale Chamber of Commerce:** https://www.sunnyvalecoc.org/
* **City of Sunnyvale:** https://www.sunnyvale.ca.gov/
* **Stanford University:** https://www.stanford.edu/**Note:**These are just overarching trends. It's important to consult reliable sources like the U.S. Census Bureau and the Bureau of Labor Statistics for more detailed and up-to-date information.
bitsandbytes
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
nf4_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_compute_dtype=torch.bfloat16,
)
model_id = 'google/datagemma-rig-27b-it'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,device_map='auto',quantization_config=nf4_config,torch_dtype=torch.bfloat16,
)
input_text = 'What are some interesting trends in Sunnyvale spanning gender, age, race, immigration, health conditions, economic conditions, crime and education?'
inputs = tokenizer(input_text, return_tensors='pt')
outputs = model.generate(**inputs, max_new_tokens=4096)
answer = tokenizer.batch_decode(outputs[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0].strip()
print(answer)google/datagemma-rag-27b-it
输入和输出
- 输入:包含用户查询的文本字符串,带有统计问题提示。
- 输出:可用于回答用户查询的自然语言查询列表,可由 Data Commons 现有的自然语言界面理解: 可用于回答用户查询并能被 Data Commons 现有自然语言界面理解的自然语言查询列表。
pip install -U transformers accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchmodel_id = 'google/datagemma-rag-27b-it'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,device_map='auto',torch_dtype=torch.bfloat16,
)input_text = """Your role is that of a Question Generator. Given Query below, come up with a
maximum of 25 Statistical Questions that help in answering Query.These are the only forms of Statistical Questions you can generate:
1. What is $METRIC in $PLACE?
2. What is $METRIC in $PLACE $PLACE_TYPE?
3. How has $METRIC changed over time in $PLACE $PLACE_TYPE?where,
- $METRIC should be a metric on societal topics like demographics, economy, health,education, environment, etc. Examples are unemployment rate andlife expectancy.
- $PLACE is the name of a place like California, World, Chennai, etc.
- $PLACE_TYPE is an immediate child type within $PLACE, like counties, states,districts, etc.Your response should only have questions, one per line, without any numbering
or bullet.If you cannot come up with Statistical Questions to ask for a Query, return an
empty response.Query: What are some interesting trends in Sunnyvale spanning gender, age, race, immigration, health conditions, economic conditions, crime and education?
Statistical Questions:"""
inputs = tokenizer(input_text, return_tensors='pt').to('cuda')outputs = model.generate(**inputs, max_new_tokens=4096)
answer = tokenizer.batch_decode(outputs[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0].strip()
print(answer)输出
What is the population of Sunnyvale?
What is the population of Sunnyvale males?
What is the population of Sunnyvale females?
What is the population of Sunnyvale asians?
What is the population of Sunnyvale blacks?
What is the population of Sunnyvale whites?
What is the population of Sunnyvale males in their 20s?
What is the population of Sunnyvale females in their 20s?
What is the population of Sunnyvale males in their 30s?
What is the population of Sunnyvale females in their 30s?
What is the population of Sunnyvale males in their 40s?
What is the population of Sunnyvale females in their 40s?
What is the population of Sunnyvale males in their 50s?
What is the population of Sunnyvale females in their 50s?
What is the population of Sunnyvale males in their 60s?
What is the population of Sunnyvale females in their 60s?
How has the population of Sunnyvale changed over time?
How has the population of Sunnyvale males changed over time?
How has the population of Sunnyvale females changed over time?
How has the population of Sunnyvale asian people changed over time?
How has the population of Sunnyvale black people changed over time?
How has the population of Sunnyvale hispanic people changed over time?
How has the population of Sunnyvale white people changed over time?
How has the score on Sunnyvale schools changed over time?
How has the number of students enrolled in Sunnyvale schools changed over time?
How has the number of students enrolled in Sunnyvale charter schools changed over time?
How has the number of students enrolled in Sunnyvale private schools changed over time?
bitsandbytes
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
nf4_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_compute_dtype=torch.bfloat16,
)model_id = 'google/datagemma-rag-27b-it'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,device_map='auto',quantization_config=nf4_config,torch_dtype=torch.bfloat16,
)
input_text = """Your role is that of a Question Generator. Given Query below, come up with a
maximum of 25 Statistical Questions that help in answering Query.
These are the only forms of Statistical Questions you can generate:
1. What is $METRIC in $PLACE?
2. What is $METRIC in $PLACE $PLACE_TYPE?
3. How has $METRIC changed over time in $PLACE $PLACE_TYPE?
where,
- $METRIC should be a metric on societal topics like demographics, economy, health,education, environment, etc. Examples are unemployment rate andlife expectancy.
- $PLACE is the name of a place like California, World, Chennai, etc.
- $PLACE_TYPE is an immediate child type within $PLACE, like counties, states,districts, etc.Your response should only have questions, one per line, without any numbering
or bullet.If you cannot come up with Statistical Questions to ask for a Query, return an
empty response.Query: What are some interesting trends in Sunnyvale spanning gender, age, race, immigration, health conditions, economic conditions, crime and education?
Statistical Questions:"""
inputs = tokenizer(input_text, return_tensors='pt').to('cuda')outputs = model.generate(**inputs, max_new_tokens=4096)
answer = tokenizer.batch_decode(outputs[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0].strip()
print(answer)资料
- DataGemma: Using real-world data to address AI hallucinations
- Knowing When to Ask - Bridging Large Language
Models and Data
相关文章:
谷歌的 DataGemma 人工智能是一个统计精灵
谷歌正在扩大其人工智能模型家族,同时解决该领域的一些最大问题。 今天,该公司首次发布了 DataGemma,这是一对开源的、经过指令调整的模型,在缓解幻觉挑战方面迈出了一步,幻觉是指大型语言模型(LLM…...

【Python爬虫系列】_021.异步请求aiohttp
课 程 推 荐我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈虚 拟 环 境 搭 建 :👉👉 Python项目虚拟环境(超详细讲解) 👈👈PyQt5 系 列 教 程:👉👉 Python GUI(PyQt5)文章合集 👈👈...

源码运行springboot2.2.9.RELEASE
1 环境要求 java 8 maven 3.5.2 2 下载springboot源码 下载地址 https://github.com/spring-projects/spring-boot/releases/tag/v2.2.9.RELEASE 3 修改配置 修改spring-boot-2.2.9.RELEASE/pom.xml 修改spring-boot-2.2.9.RELEASE/spring-boot-project/spring-boot-tools…...

王者荣耀改重复名(java源码)
王者荣耀改重复名 项目简介 “王者荣耀改重复名”是一个基于 Spring Boot 的应用程序,用于生成王者荣耀游戏中的唯一名称。通过简单的接口和前端页面,用户可以输入旧名称并获得一个新的、不重复的名称。 功能特点 生成新名称:提供一个接口…...

Python 全栈系列271 微服务踩坑记
说明 这个坑花了10个小时才爬出来 碰到一个现象:将微服务改造为并发后,请求最初很快,然后就出现大量的失败,然后过一会又能用。 过去从来没有碰到这个问题,要么是一些比较明显的资源,或者逻辑bug࿰…...

环境搭建2(游戏逆向)
#include<iostream> #include<windows.h> #include<tchar.h> #include<stdio.h> #pragma warning(disable:4996) //exe应用程序 VOID PrintUI(CONST CHAR* ExeName, CONST CHAR* UIName, CONST CHAR* color, SHORT X坐标, SHORT y坐标, WORD UIwide, W…...
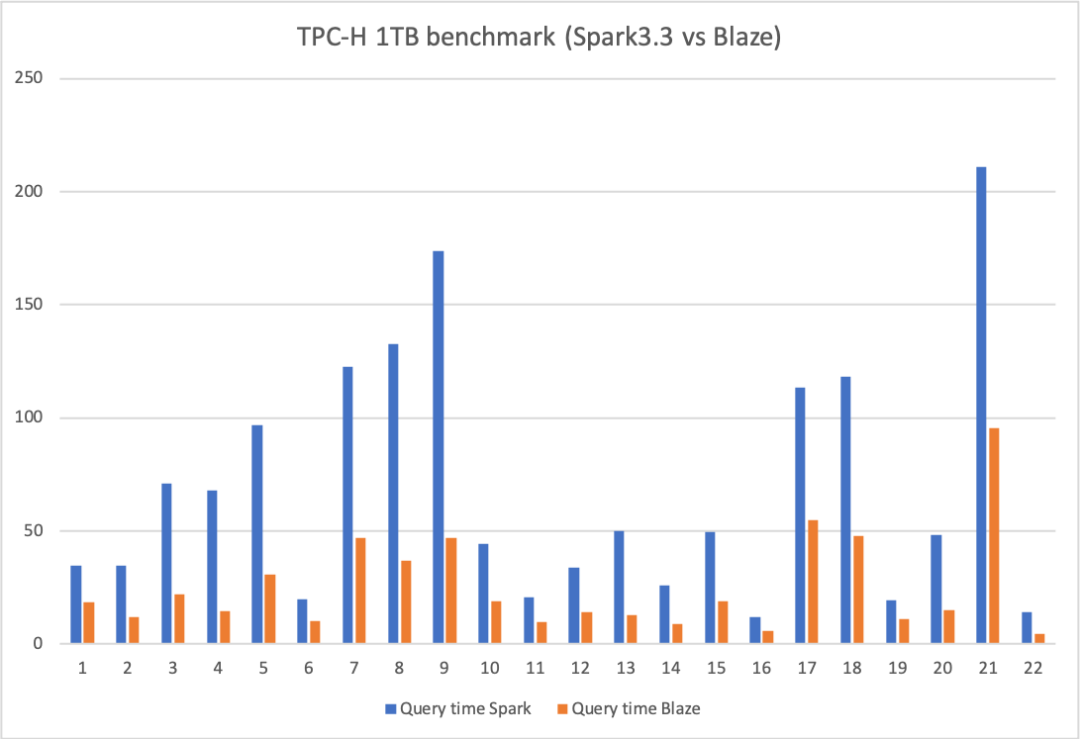
快手自研Spark向量化引擎正式发布,性能提升200%
Blaze 是快手自研的基于Rust语言和DataFusion框架开发的Spark向量化执行引擎,旨在通过本机矢量化执行技术来加速Spark SQL的查询处理。Blaze在快手内部上线的数仓生产作业也观测到了平均30%的算力提升,实现了较大的降本增效。本文将深入剖析blaze的技术原…...

用网卡的ap模式抓嵌入式设备的网络包
嵌入式设备不像pc上,有一些专门的工具比如wareshark来抓包,嵌入式设备中,有的可能集成了tcpdump,可以用来进行简单的抓包,但是不方便分析,况且有的嵌入式设备不一定就集成了tcpdump工具。 关于tcpdump工具…...

centos 7 升级Docker 与Docker-Compose 到最新版本
一 升级docker 可参考docker官方升级 1, 查看docker 信息 docker info 2,查看docker 版本 docker --version 3 升级前 可停止docker : sudo systemctl stop docker 4 查看已安装的docker 并卸载 [rootlocalhost docker]# yum list installed | grep docker docker.x86…...

Docker_启动redis,容易一启动就停掉
现象以及排查过程 最近在使用docker来搭建redis服务,但是在启动redis哨兵容器时,总是发现这个容器启动后立马就停止了。首先想到的是不是服务器资源不够用了导致的这个现象,排查后发现不是资源问题。再者猜测是不是启动报错了,查看…...

微服务中间件之Nacos
Nacos(Dynamic Naming and Configuration Service)是阿里巴巴开源的一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它提供了服务注册与发现、配置管理以及服务健康监测等核心功能,旨在帮助开发人员更轻松地构建和管理微服…...

C++: 类和对象(上)
📔个人主页📚:秋邱-CSDN博客☀️专属专栏✨:C🏅往期回顾🏆:从C语言过渡到C🌟其他专栏🌟:C语言_秋邱 面向过程和面向对象 C 语言被认为是面向过程的编程…...

Unity程序基础框架
概述 单例模式基类 没有继承 MonoBehaviour 继承了 MonoBehaviour 的两种单例模式的写法 缓存池模块 (确实挺有用) using System.Collections; using System.Collections.Generic; using UnityEngine;/// <summary> /// 缓存池模块 /// 知识点 //…...
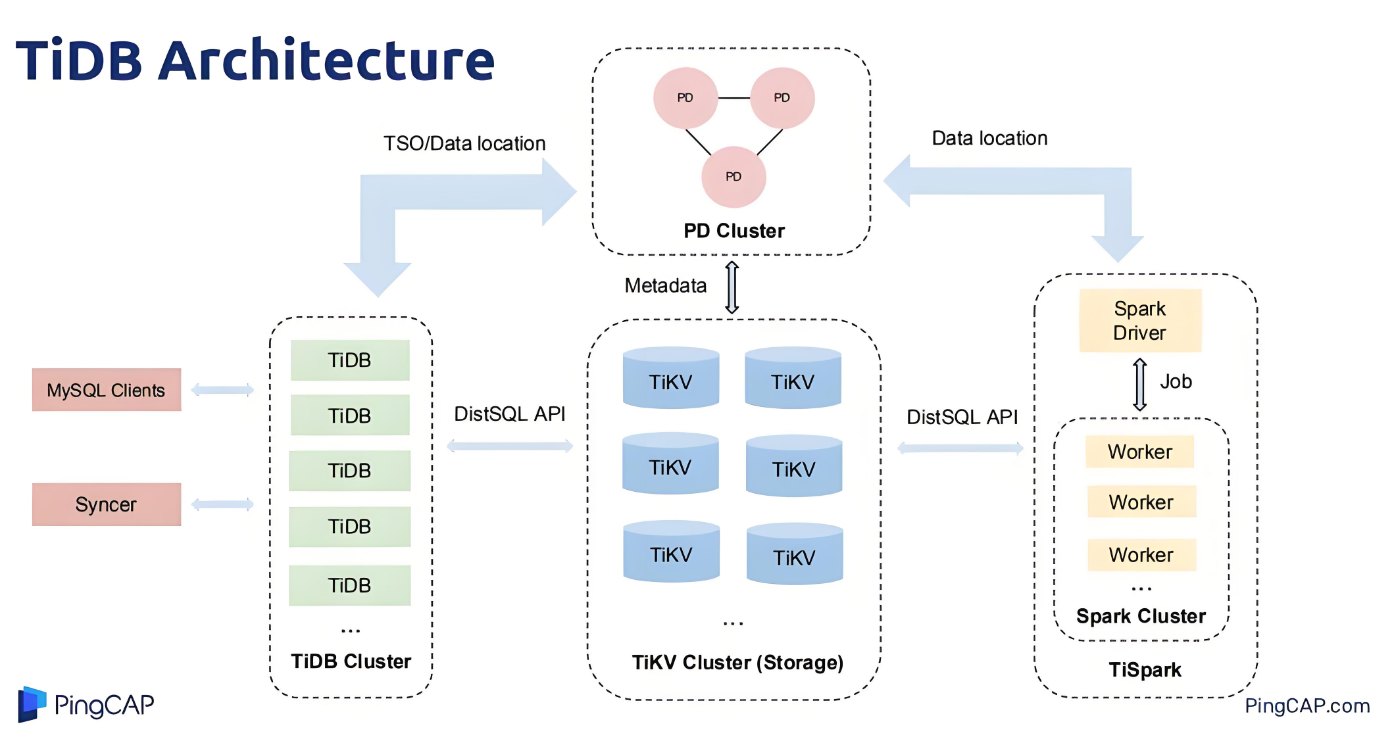
TiDB 数据库核心原理与架构_Lesson 01 TiDB 数据库架构概述课程整理
作者: 尚雷5580 原文来源: https://tidb.net/blog/beeb9eaf 注:本文基于 TiDB 官网 董菲老师 《TiDB 数据库核心原理与架构(101) 》系列教程之 《Lesson 01 TiDB 数据库架构概述》内容进行整理和补充。 课程链接:…...

计算机毕业设计Python深度学习垃圾邮件分类检测系统 朴素贝叶斯算法 机器学习 人工智能 数据可视化 大数据毕业设计 Python爬虫 知识图谱 文本分类
基于朴素贝叶斯的邮件分类系统设计 摘要:为了解决垃圾邮件导致邮件通信质量被污染、占用邮箱存储空间、伪装正常邮件进行钓鱼或诈骗以及邮件分类问题。应用Python、Sklearn、Echarts技术和Flask、Lay-UI框架,使用MySQL作为系统数据库,设计并实…...

多核DSP(6000系列)设计与调试技巧培训
课程介绍: 为帮助从事DSP开发工程师尽快将DSP技术转化为产品,在较短时间内掌握DSP设计技术和问题的解决方法,缩短产品开发周期、增强产品竞争力、节省研发经费。我们特组织了工程实践和教学经验丰富的专家连续举办了多期DSP C6000的培训&a…...

JMeter脚本开发
环境部署 Ubuntu系统 切换到root用户 sudo su 安装上传下载的命令 apt install lrzsz 切换文件目录 cd / 创建文件目录 mkdir java 切换到Java文件夹下 cd java 输入rz回车 选择jdk Linux文件上传 解压安装包 tar -zxvf jdktab键 新建数据库 运行sql文件 选择sql文件即…...

LabVIEW编程快速提升的关键技术
在LabVIEW程序员的成长道路上,以下几个概念和技术的掌握可以显著提升自我能力: 模块化编程:学会将程序分解成小而独立的模块(如子VI),提高程序的可读性、可维护性和可扩展性。这种方式不仅能帮助快速定位问…...
BSN六周年:迈向下一代互联网
当前,分布式技术作为现代计算机科学和信息技术的重要组成部分,在云计算、区块链等技术的推动下,正以多样化的形式蓬勃发展。 而区块链作为一种特殊的分布式系统,近年来也在各个领域得到了广泛关注。通过在区块链上运行智能合约…...

Android 使用scheme唤起app本地打开
记录一下近期任务。。。 以下操作全部基于手机本地已经安装对应app方可执行。 没安装建议web前端校验一下跳动app下载页吧。 AndroidManifest配置如下: <activity android:name".RouterActivity"><intent-filter><dataandroid:host&quo…...

2026杭州本地GEO优化公司排名,优质机构一站式推荐
AI 搜索时代,不少杭州企业踩过这样的坑:花大价钱找服务商做 GEO 优化,每天产出大量文章,结果在豆包、DeepSeek 等 AI 大模型里搜不到品牌信息,询盘没涨、获客成本反倒飙升。GEO 优化从来不是 “堆文章”,而…...

基于Feather RP2040与CircuitPython的CNC旋钮宏键盘DIY指南
1. 项目概述:打造你的专属生产力旋钮如果你经常使用像Cura、Fusion 360或者Adobe系列这类专业软件,一定对频繁切换工具、调整参数时在键盘和鼠标间来回切换的繁琐深有体会。传统的键盘快捷键虽然快,但组合键太多容易忘记,而且缺乏…...

AI教材写作必备:低查重工具,助力高效生成专业教材!
选择 AI 教材编写工具的困境与解决方案 在准备教材之前,选择合适的工具就像进入了一个“纠结的大迷宫”!使用办公软件确实方便,但功能往往太过基础,搭建框架和调整格式都得手动搞定;而如果选择专业的 AI 教材编写工具…...

CCS8.0 TMS320F28335工程配置实战:从零搭建到Flash固件生成
1. CCS8.0开发环境与TMS320F28335基础认知 第一次接触TMS320F28335这款DSP芯片时,我完全被它复杂的开发环境吓到了。直到后来才发现,只要掌握CCS8.0这个开发工具的基本操作逻辑,整个开发过程就会变得异常清晰。这里先给大家科普几个关键概念&…...

从‘一核有难,多核围观’到雨露均沾:深入Linux内核看网卡中断与RSS/RPS
从“一核有难,多核围观”到雨露均沾:Linux内核网络中断负载均衡实战解析 当服务器网卡吞吐量突然暴跌时,很多工程师的第一反应是检查带宽和协议栈参数,却忽略了最底层的CPU中断分配机制。我曾处理过一台数据库服务器,在…...
)
从FreeRTOS到RT-Thread:手把手教你正确使用操作系统的动态内存API(避坑malloc)
从FreeRTOS到RT-Thread:嵌入式实时操作系统动态内存管理实战指南 在嵌入式开发领域,动态内存管理一直是开发者面临的棘手问题之一。当项目从裸机迁移到实时操作系统(RTOS)环境时,许多开发者会不自觉地延续使用标准C库的…...

GetQzonehistory终极指南:三步快速备份QQ空间全部历史说说
GetQzonehistory终极指南:三步快速备份QQ空间全部历史说说 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字记忆时代,QQ空间承载了无数用户的青春回忆和成长…...

为什么选择Lacinia?5大优势带你了解这个强大的GraphQL解决方案
为什么选择Lacinia?5大优势带你了解这个强大的GraphQL解决方案 【免费下载链接】lacinia GraphQL implementation in pure Clojure 项目地址: https://gitcode.com/gh_mirrors/la/lacinia 在当今API开发领域,GraphQL已经成为构建高效数据接口的重…...

书成紫微动,律定凤凰驯:对比臆想歪解,铁哥的天然契合才是真天命
———— 千年颂辞 真天命笺 ————一、两种读法:伪天命 真天命伪天命(臆想歪解)真天命(天然契合)脑补玄学、权谋剧本本心行道、作品证道人追诗、人凑运诗等人、运合心后天强行拟合先天无心自洽悬浮文字游戏落地世…...

Arduino ESP32终极开发指南:从硬件抽象到物联网实战
Arduino ESP32终极开发指南:从硬件抽象到物联网实战 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 ESP32作为物联网开发领域的明星芯片,以其强大的…...