快手自研Spark向量化引擎正式发布,性能提升200%
Blaze 是快手自研的基于Rust语言和DataFusion框架开发的Spark向量化执行引擎,旨在通过本机矢量化执行技术来加速Spark SQL的查询处理。Blaze在快手内部上线的数仓生产作业也观测到了平均30%的算力提升,实现了较大的降本增效。本文将深入剖析blaze的技术原理、实现细节及在快手实际生产环境中的真实表现。
一、研究背景
当下,Spark 的重要发展方向之一是通过向量化执行进一步提升性能。向量化执行的思想是将算子的执行粒度从每次处理一行变成每次处理一个行组,以此来避免大量的函数调用。通过对行组内部处理按列进行计算,同时利用编译技术减少分支判断检查以及更多的 SIMD 优化执行计划。
Blaze 是快手自研的基于Rust语言和DataFusion框架开发的Spark向量化执行引擎,旨在通过本机矢量化执行技术来加速Spark SQL的查询处理。在性能方面,Blaze展现出显著的优势:在TPC-DS 1TB的测试中,Blaze相较于Spark 3.3版本减少了60%的计算时间、Spark 3.5版本减少了40%的计算时间,并大幅降低了集群资源的消耗;此外,Blaze在快手内部上线的数仓生产作业也观测到了平均30%的算力提升,实现了较大幅度的降本增效。
如今,Blaze已开源,拥抱更广阔的开发者社区。开源版本全面兼容Spark 3.0~3.5,用户能够轻松集成Blaze至现有Spark环境中,仅需简单添加Jar包,即可解锁Blaze带来的极致性能优化,享受前所未有的数据处理速度与资源效率。
Github地址: https://github.com/kwai/blaze
二、Blaze的整体架构及核心
Spark on Blaze架构的整体流向
Spark+Blaze 的架构设计原理如下图:
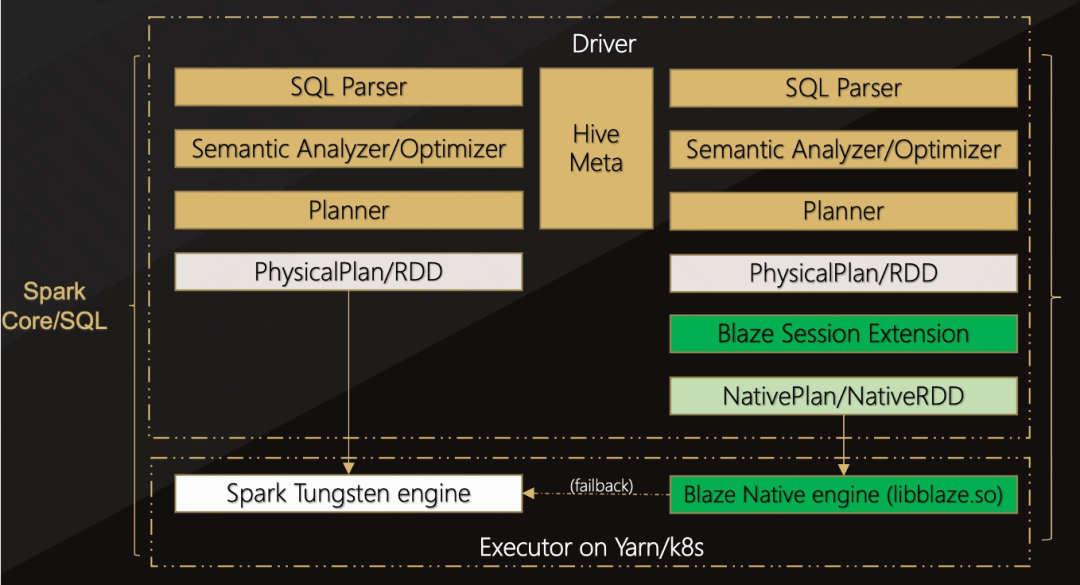
对比Spark原生的执行流程,引入Blaze Session Extension组件所带来的作用是显著的,特别是在提升数据处理效率和性能方面。
Spark原生执行流程主要依赖于Java虚拟机(JVM)进行任务的执行,尽管JVM在提供跨平台、内存管理等方面有着卓越的表现,但在大数据处理场景下,尤其是涉及大规模数据计算和复杂查询时,JVM的性能开销可能会成为瓶颈。
Blaze Session Extension组件的引入,巧妙地解决了这一问题。该组件在Spark生成物理执行计划之后介入,通过其翻译逻辑将这一计划转换为等效的、native向量化引擎可以识别的形式,随后提交到Executor端由native引擎执行计算,从而实现了数据处理效率的飞跃。
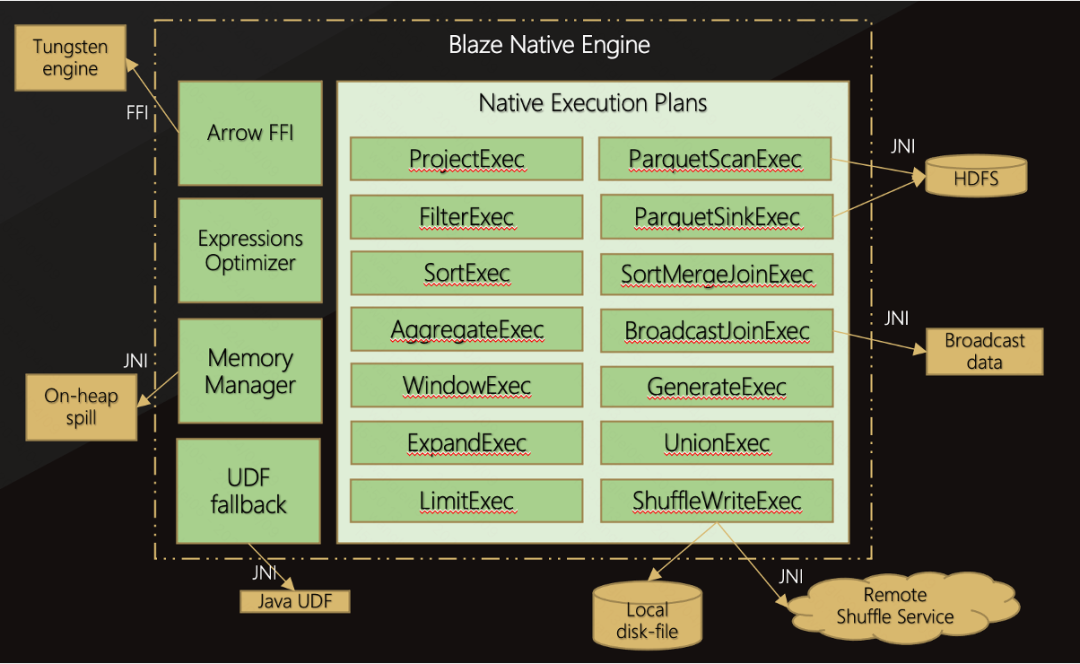
而这一切的背后,离不开Native向量化引擎这一核心模块的支持。该引擎由Rust语言实现,凭借其卓越的性能、安全性和并发处理能力,成功实现了Spark中大多数关键算子的等效替代,包括但不限于Project、Filter、Sort等。这些经过优化的算子在执行过程中,通过向量化技术显著提升了计算效率,使得数据处理过程更加流畅、快速。
四大核心组件
Blaze 架构中的核心模块有四个,共同驱动着大数据性能的显著提升。这些模块分别为:
-
Native Engine:基于 Datafusion 框架实现的与 Spark 功能一致的 Native 算子,以及相关内存管理、FFI 交互等功能。
-
ProtoBuf:定义用于 JVM 和 native 之间的算子描述协议,对 Datafusion 执行计划进行序列化和反序列化。
-
JNI Bridge:实现 Spark Extension 和 Native Engine 之间的互相调用。
-
Spark Extension:Spark 插件,实现 Spark 算子到 Native 算子之间的翻译。
具体的执行过程中,遵循以下步骤:
-
物理执行计划的转换:首先,Spark Extension将 Spark 生成的物理执行计划转换为对应的 Native Plan;
-
生成和提交Native Plan:转换完成后,Native Plan通过JNI Bridge被提交给Native Engine进行进一步的处理。
-
Native 执行层:最后,Native Engine利用其高效的内存管理机制和向量化处理技术,对Native Plan进行真正的执行。执行结果通过JNI Bridge返回给Spark,从而完成整个数据处理流程。
三、Blaze的技术优势:面向生产的深度优化
在跑通 tpch 和 tpcds 测试集并取得预期性能提升后,我们面向线上生产环境进一步做了系列深度优化,包括性能和稳定性等方面工作:
细粒度的FailBack机制
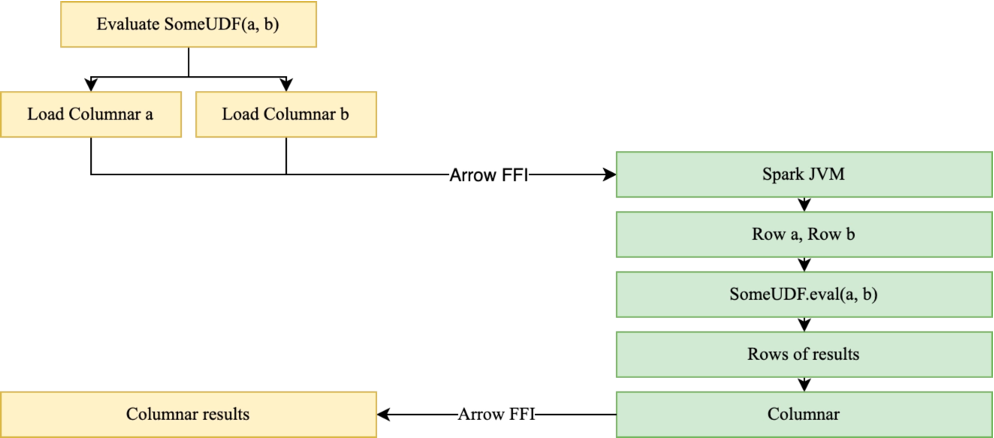
我们针对Spark执行效率的提升,设计并实现了演进式向量化执行方案。这一方案旨在逐步优化算子与表达式的向量化覆盖,同时解决Java UDF无法直接转化为Native执行的问题。通过引入细粒度的FailBack机制,Blaze在翻译过程中遇到暂无Native实现的算子、单个表达式或UDF时,支持算子/单个表达式粒度的回退,能够灵活回退到Spark原生执行。此机制首先确定算子/表达式的依赖参数列,利用Arrow FFI技术将这些参数列作为行传递给Spark进行处理,然后将结果以列的形式回传至Blaze,从而在JVM与Native执行之间构建了一座桥梁。
此方案不仅加速了向量化执行的全面部署,还确保了即便在用户SQL中有少量UDF等不支持的场景,细粒度回退单个表达式开销较小,作业整体依然可以得到优化。
更高效的向量化数据传输格式
在Spark中,Shuffle操作因其复杂的数据流转过程成为性能瓶颈,涉及编码、压缩、网络传输、解压及解码等多个环节。原生Spark采用基于行的序列化与压缩方式,而业界向量化数据则倾向于Arrow格式传输,但实践中发现Arrow与主流轻量压缩算法适配不佳,导致压缩率低下且存在冗余信息。针对此问题,Blaze定制了优化的数据传输格式,不仅去除了列名、数据类型等冗余数据,还使用了byte-transpose列式数据序列化技术,通过重组整型/浮点型数据的字节顺序,显著提升数据压缩效率。这一改进大幅减少了Shuffle过程中的数据传输量,并在实际测试与TPC-DS基准测试中展现出显著的性能提升与资源消耗降低,有效解决了原有问题并优化了系统整体性能。
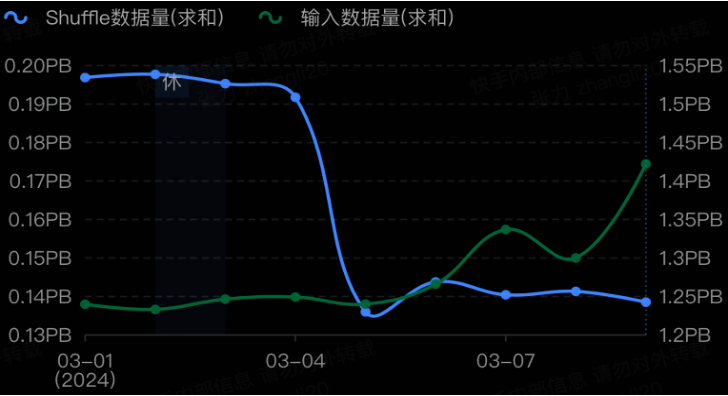
线上2000多个作业的真实数据,上线后输入数据量小幅上涨的情况下,Shuffle数据量相比spark降近30%
减少用户成本的多级内容管理策略
面对Spark与Native执行模式在内存管理上的差异,我们设计了跨堆内堆外的自适应内存管理机制。该机制根据任务的向量化覆盖情况智能调整内存分配,确保资源高效利用。同时,我们构建了堆外内存、堆内内存与磁盘文件之间的多级管理体系,有效防止了内存不足及频繁数据溢写的问题。这些措施不仅保障了向量化引擎上线后任务的稳定运行,无需用户手动调整内存参数,大幅降低了用户操作成本,提升了整体系统的易用性与可靠性。
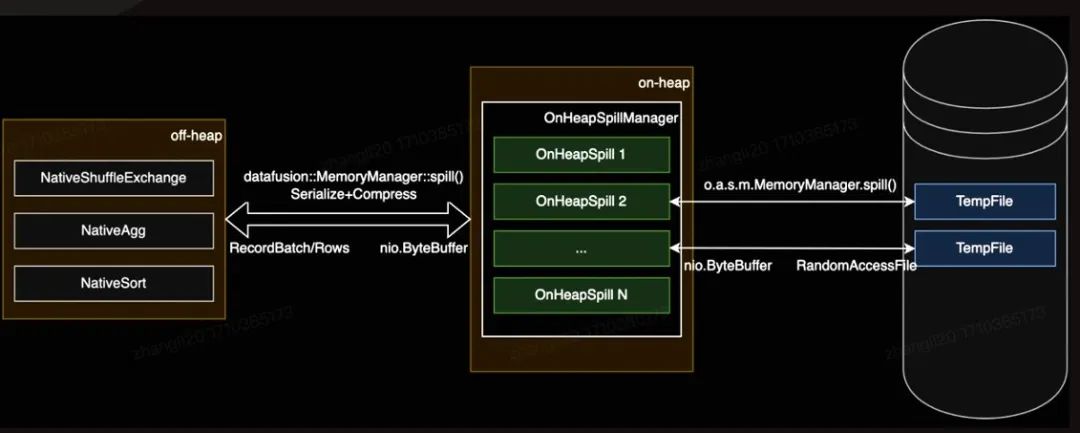
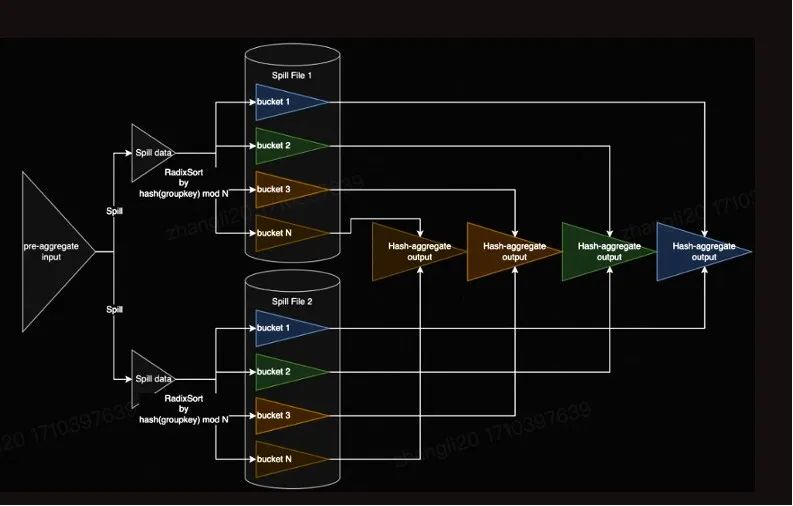
复杂度更优的聚合算法实现
为深度适配Spark的复杂需求,Blaze在aggregate、sort、shuffle等关键算子的实现上并未直接采用DataFusion的现成方案,而是进行了定制化开发。以HashAggregate为例,当面对大规模group-by聚合且内存不足时,Spark会转而采用基于排序的聚合,这涉及高复杂度的排序与归并过程。而在Blaze中,我们采用了基于分桶的归并方式,利用基数排序在spill时进行分桶、溢写,并在合并阶段通过hash 表快速合并,整个流程保持O(n)的复杂度,显著提升了聚合算子的执行效率与资源利用率。
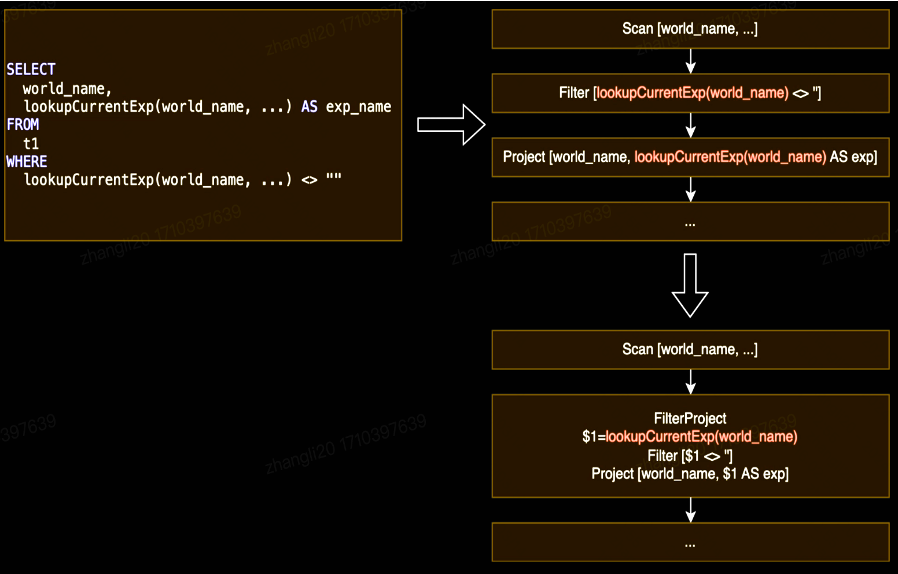
向量化计算场景的表达式重复计算优化
针对SQL执行中算子间常见的重复表达式计算问题,Blaze借鉴了Spark的Whole-stage codegen技术,应用了这一项优化策略。该策略能够智能识别并合并包含重复表达式的算子,如下图中的Project与Filter合并为一个大算子,并在其中对表达式计算结果进行缓存、复用,达到了减少重复计算、提高执行效率的目的。这一优化在应对复杂计算逻辑(如JSON解析多个字段、UDF调用)时尤为显著,能将执行效率提升一倍以上。特别是在内部业务场景中,对于高频调用的重负载UDF,该优化成功减少了约40%的计算开销,显著增强了系统的整体性能与响应速度。
四、当前进展及未来规划
当前进展
Blaze 作为一款高性能数据处理引擎,已取得了显著进展,全面支持多项核心功能,展现出强大的技术实力与广泛的应用潜力。具体而言,Blaze 目前已具备以下关键能力:
-
Parquet向量化读写能力:实现了对Parquet格式数据的高效向量化读写,极大地提升了数据处理的速度与效率。
-
全面算子与表达式支持:覆盖了线上常用的所有算子与表达式,少量不支持的表达式和UDF也可以细粒度回退,确保用户能够无缝迁移并享受向量化处理带来的性能提升。
-
Remote Shuffle Service集成:内部集成了自研的Remote Shuffle Service,同时我们也在和阿里合作,增加对Apache Celeborn 的支持,预计9月份可以提交到社区。
-
TPC-H/TPC-DS测试优异表现:在业界权威的TPC-H/TPC-DS基准测试中,Blaze成功通过全部测试场景,并以TPC-H平均3倍以上、TPC-DS 2.5倍的性能提升展示了其在复杂查询处理上的卓越能力。
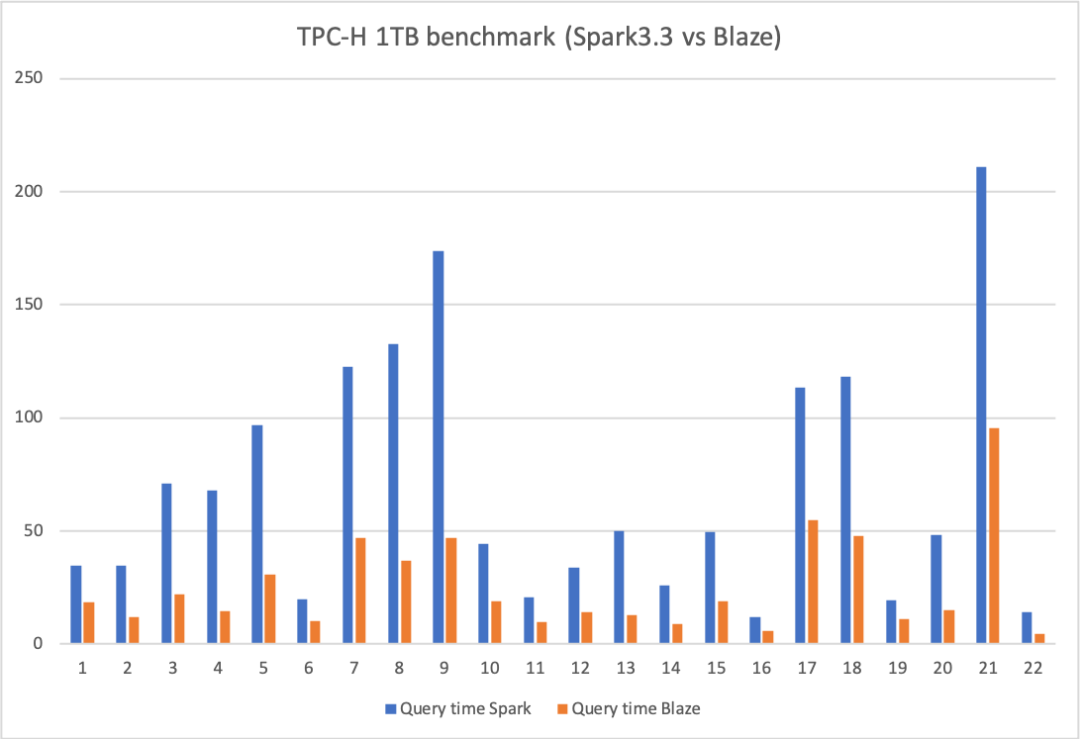
在真实的生产环境中,向量化引擎大规模上线应用,算力平均提升 30%+,成本节约年化数千万元。
未来规划
1. 持续迭代优化,内部线上推全:通过不断收集用户反馈与性能数据,我们将精准定位并修复潜在问题,同时引入更多先进的算法与优化策略,以进一步提升Blaze的性能与稳定性。
2. 支持更多引擎或场景,例如数据湖等:为了满足用户日益多样化的数据处理需求,我们将不断拓展Blaze的应用场景,支持更多类型的数据处理引擎与场景,如数据湖等。通过加强与业界主流技术的兼容性,我们将为用户提供更加灵活、便捷的数据处理方案,助力用户解锁数据价值,推动业务创新与发展。
3. 加强开源社区运营建设,共建生态繁荣:我们深知开源社区对于技术发展与生态繁荣的重要性。因此,我们将在之后加强Blaze开源社区的运营建设,积极构建一个开放、包容、协作的社区环境。当前我们已经与阿里、B站、携程、联通云等公司达成合作。
如果您对该项目感兴趣,欢迎您为项目点个star。
项目地址:https://github.com/kwai/blaze
相关文章:
快手自研Spark向量化引擎正式发布,性能提升200%
Blaze 是快手自研的基于Rust语言和DataFusion框架开发的Spark向量化执行引擎,旨在通过本机矢量化执行技术来加速Spark SQL的查询处理。Blaze在快手内部上线的数仓生产作业也观测到了平均30%的算力提升,实现了较大的降本增效。本文将深入剖析blaze的技术原…...

用网卡的ap模式抓嵌入式设备的网络包
嵌入式设备不像pc上,有一些专门的工具比如wareshark来抓包,嵌入式设备中,有的可能集成了tcpdump,可以用来进行简单的抓包,但是不方便分析,况且有的嵌入式设备不一定就集成了tcpdump工具。 关于tcpdump工具…...

centos 7 升级Docker 与Docker-Compose 到最新版本
一 升级docker 可参考docker官方升级 1, 查看docker 信息 docker info 2,查看docker 版本 docker --version 3 升级前 可停止docker : sudo systemctl stop docker 4 查看已安装的docker 并卸载 [rootlocalhost docker]# yum list installed | grep docker docker.x86…...

Docker_启动redis,容易一启动就停掉
现象以及排查过程 最近在使用docker来搭建redis服务,但是在启动redis哨兵容器时,总是发现这个容器启动后立马就停止了。首先想到的是不是服务器资源不够用了导致的这个现象,排查后发现不是资源问题。再者猜测是不是启动报错了,查看…...

微服务中间件之Nacos
Nacos(Dynamic Naming and Configuration Service)是阿里巴巴开源的一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它提供了服务注册与发现、配置管理以及服务健康监测等核心功能,旨在帮助开发人员更轻松地构建和管理微服…...

C++: 类和对象(上)
📔个人主页📚:秋邱-CSDN博客☀️专属专栏✨:C🏅往期回顾🏆:从C语言过渡到C🌟其他专栏🌟:C语言_秋邱 面向过程和面向对象 C 语言被认为是面向过程的编程…...

Unity程序基础框架
概述 单例模式基类 没有继承 MonoBehaviour 继承了 MonoBehaviour 的两种单例模式的写法 缓存池模块 (确实挺有用) using System.Collections; using System.Collections.Generic; using UnityEngine;/// <summary> /// 缓存池模块 /// 知识点 //…...
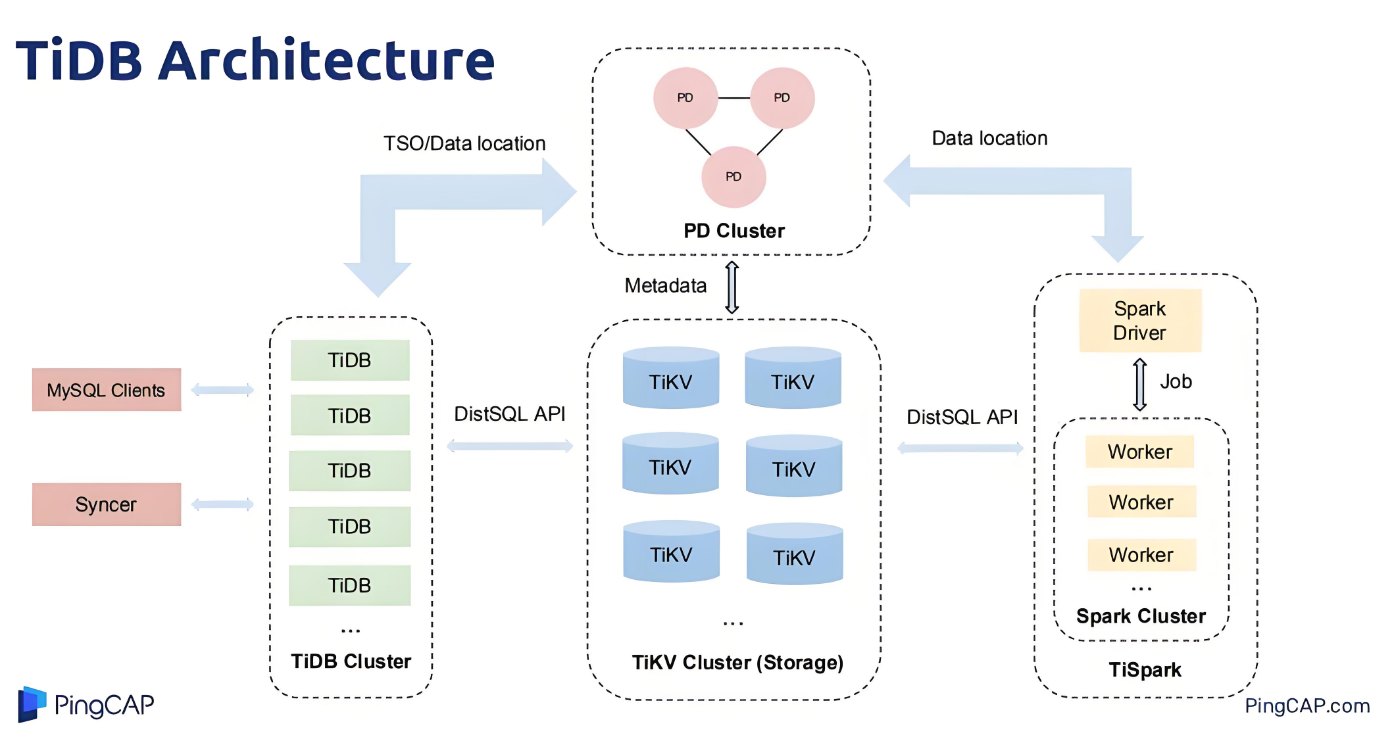
TiDB 数据库核心原理与架构_Lesson 01 TiDB 数据库架构概述课程整理
作者: 尚雷5580 原文来源: https://tidb.net/blog/beeb9eaf 注:本文基于 TiDB 官网 董菲老师 《TiDB 数据库核心原理与架构(101) 》系列教程之 《Lesson 01 TiDB 数据库架构概述》内容进行整理和补充。 课程链接:…...

计算机毕业设计Python深度学习垃圾邮件分类检测系统 朴素贝叶斯算法 机器学习 人工智能 数据可视化 大数据毕业设计 Python爬虫 知识图谱 文本分类
基于朴素贝叶斯的邮件分类系统设计 摘要:为了解决垃圾邮件导致邮件通信质量被污染、占用邮箱存储空间、伪装正常邮件进行钓鱼或诈骗以及邮件分类问题。应用Python、Sklearn、Echarts技术和Flask、Lay-UI框架,使用MySQL作为系统数据库,设计并实…...

多核DSP(6000系列)设计与调试技巧培训
课程介绍: 为帮助从事DSP开发工程师尽快将DSP技术转化为产品,在较短时间内掌握DSP设计技术和问题的解决方法,缩短产品开发周期、增强产品竞争力、节省研发经费。我们特组织了工程实践和教学经验丰富的专家连续举办了多期DSP C6000的培训&a…...

JMeter脚本开发
环境部署 Ubuntu系统 切换到root用户 sudo su 安装上传下载的命令 apt install lrzsz 切换文件目录 cd / 创建文件目录 mkdir java 切换到Java文件夹下 cd java 输入rz回车 选择jdk Linux文件上传 解压安装包 tar -zxvf jdktab键 新建数据库 运行sql文件 选择sql文件即…...

LabVIEW编程快速提升的关键技术
在LabVIEW程序员的成长道路上,以下几个概念和技术的掌握可以显著提升自我能力: 模块化编程:学会将程序分解成小而独立的模块(如子VI),提高程序的可读性、可维护性和可扩展性。这种方式不仅能帮助快速定位问…...
BSN六周年:迈向下一代互联网
当前,分布式技术作为现代计算机科学和信息技术的重要组成部分,在云计算、区块链等技术的推动下,正以多样化的形式蓬勃发展。 而区块链作为一种特殊的分布式系统,近年来也在各个领域得到了广泛关注。通过在区块链上运行智能合约…...

Android 使用scheme唤起app本地打开
记录一下近期任务。。。 以下操作全部基于手机本地已经安装对应app方可执行。 没安装建议web前端校验一下跳动app下载页吧。 AndroidManifest配置如下: <activity android:name".RouterActivity"><intent-filter><dataandroid:host&quo…...

linux 最简单配置免密登录
需求:两台服务器互信登录需要拉起对端服务 ip: 192.168.1.133 192.168.1.137 一、配置主机hosts,IP及主机名,两台都需要 二、192.168.1.137服务器,生成密钥 ssh-keygen -t rsa三、追加到文件 ~/.ssh/authorized_key…...

易语言源码用键盘按键代替小键盘写法教程
相信大家都有遇到过一些难题 比方说想用一些软件 但是发现一些软件需要有小键盘的用户才能使用 那么这样就对于一些无小键盘用户造成了困扰! 今天就给大家分享一个用易语言写的利用软键盘方法 当按下一个按键启动其他热键的方法 以下为源码写法 .版本 2 .支持库 she…...

深度学习和计算机视觉:实现图像分类
深度学习在计算机视觉领域的应用已经取得了革命性的进展。从图像分类到对象检测,再到图像分割和生成,深度学习模型在这些任务中都展现出了卓越的性能。本篇文章将介绍如何使用深度学习进行图像分类,这是计算机视觉中的一个基础任务。 计算机…...
代码随想录算法训练营第五十八天 | 拓扑排序精讲-软件构建
目录 软件构建 思路 拓扑排序的背景 拓扑排序的思路 模拟过程 判断有环 写代码 方法一: 拓扑排序 软件构建 题目链接:卡码网:117. 软件构建 文章讲解:代码随想录 某个大型软件项目的构建系统拥有 N 个文件,文…...

Spring Cloud常见面试题
1.请说说你用过Spring Cloud哪些组件?这些组件分别有什么作用? 1、注册中心:Eureka、Nacos、Zookeeper、Consul;(服务注册) 2、负载均衡:Ribbon、LoadBalancer;(客户端的…...

老古董Lisp实用主义入门教程(9): 小小先生学习Lisp表达式
小小先生 小小先生个子很小,胃口也很小,每次只能干一件事情,还是一件很小很小的事情。 好奇先生已经把explore-lisp代码库安装好,小小先生就只需要打开VS Code, 新建一个lisp为后缀的文件,就能够开始写Lisp代码。 c…...

AI智能体可观测性实战:用AgentOps实现全链路追踪与性能优化
1. 项目概述:当AI智能体遇上“黑匣子”,我们如何看清它的每一步?如果你最近在折腾AI智能体(Agent),无论是用LangChain、AutoGPT还是自己手搓的框架,大概率会遇到一个共同的痛点:调试…...

Adafruit Bluefruit模块DFU模式恢复与固件更新全攻略
1. 项目概述如果你正在玩Adafruit的Bluefruit系列蓝牙模块,比如UART Friend或者SPI Friend,并且某天它突然“变砖”了——连接不上、没反应,或者Arduino IDE里怎么也刷不进新程序,先别急着把它扔进抽屉吃灰。这种情况我遇到过不止…...

学习信息系统项目管理师我们以什么视角学习?
如果你只是死记硬背那些定义,你会觉得这本书枯燥乏味,而且做题时很容易掉进陷阱。但如果你**“入戏”**,把自己当成那个掌握全局的项目经理,很多答案你凭直觉就能选对。为了帮你把“入戏”进行到底,我给你三个**“入戏…...

绿色AI能耗优化:从模型架构到MLOps实践
1. 绿色AI能耗研究的现实意义在深度学习模型参数量呈指数级增长的今天,AI系统的能源消耗已成为不可忽视的环境负担。根据最新研究,训练一个大型语言模型的碳排放量相当于五辆汽车整个生命周期的排放总量。这种惊人的能源消耗与全球减碳目标形成了尖锐矛盾…...

手工打造柔性LED眼罩:从SMD焊接入门到可穿戴电路实践
1. 项目概述:从零打造你的赛博格之眼如果你和我一样,对《银翼杀手》里那些闪烁着冷光的义眼,或是赛博朋克美学中标志性的发光装饰着迷,那么亲手制作一个属于自己的LED眼罩,绝对是一次令人兴奋的旅程。这不仅仅是一个酷…...

等保2.0合规实战:Redis安全配置核查与加固指南
1. Redis安全配置入门:为什么等保2.0要求这么严格? 我第一次接触Redis安全配置是在一次等保2.0合规检查中。当时客户系统因为Redis默认配置导致数据泄露,整个项目组连夜加班整改。从那以后,我就养成了每次部署Redis必做安全检查的…...

基于Adafruit IO与振动传感器的智能洗衣机提醒器DIY教程
1. 项目概述:告别遗忘,让洗衣机“开口说话”你有没有过这样的经历?把衣服塞进洗衣机,按下启动键,然后转头就去忙别的事情,等再想起来时,已经是好几个小时甚至第二天,湿漉漉的衣服在滚…...
)
仅0.3%用户掌握的胶片叙事技巧:用Midjourney实现“过期胶卷”时间衰减效果(含Exif元数据欺骗指令集)
更多请点击: https://intelliparadigm.com 第一章:胶片叙事与数字时代的时间诗学 胶片影像的物理性——帧率、显影时长、机械快门延时——曾将时间锚定为可触摸的物质存在;而数字媒介则以纳秒级采样、无损复制与非线性剪辑,将时间…...

智能卡通信调优实战:手把手教你用逻辑分析仪抓取并解析ISO7816 PPS协商过程
智能卡通信调优实战:手把手教你用逻辑分析仪抓取并解析ISO7816 PPS协商过程 在嵌入式系统和智能卡应用开发中,通信稳定性往往是项目成败的关键。当你的智能卡设备频繁出现通信中断、数据丢失或速率不达标时,问题很可能隐藏在协议协商阶段。IS…...
)
开关电源传导EMI超标?手把手教你用π型滤波器搞定(附SCT2450实测数据)
开关电源传导EMI超标?手把手教你用π型滤波器搞定(附SCT2450实测数据) 在电源设计领域,传导EMI超标是工程师们经常遇到的棘手问题。当你的产品在EMC实验室测试失败时,那种挫败感相信每个硬件工程师都深有体会。传导噪声…...