Python Pickle 与 JSON 序列化详解:存储、反序列化与对比
Python Pickle 与 JSON 序列化详解:存储、反序列化与对比
文章目录
- Python Pickle 与 JSON 序列化详解:存储、反序列化与对比
- 一 功能总览
- 二 Pickle
- 1 应用
- 2 序列化
- 3 反序列化
- 4 系统资源对象
- 1)不能被序列化的系统资源对象
- 2)强行序列化系统资源对象
- 三 Json
- 1 应用
- 2 序列化
- 3 反序列化
- 4 不能序列化 class 类
- 四 Pickle 和 Json 对比
- 五 完整代码示例
- 六 源码地址
在 Python 中,序列化是保存数据和对象的重要方式,其中 Pickle 和 JSON 是常用的两种序列化方法。本文详细介绍了如何使用 Pickle 和 JSON 进行数据和类的序列化与反序列化操作。通过 Pickle,能够将 Python 对象保存为二进制文件,而 JSON 更适用于跨语言的数据交换。文章包含了 Pickle 的序列化、反序列化,以及如何处理系统资源对象。还涵盖了 JSON 的基本操作及其与 Pickle 的对比,帮助开发者根据不同场景选择合适的序列化方式。
一 功能总览
| Pickle | Json |
|---|---|
| pickle.dumps() | json.dumps() |
| pickle.dump() | json.dump() |
| pickle.load() | json.load() |
二 Pickle
1 应用
使用 pickle 去 dumps 数据
# import pickle data = {"filename": "f1.txt", "create_time": "today", "size": 111}print(pickle.dumps(data))
2 序列化
将数据转换成文件储存
# 用 pickle.dump() 将字典直接转换成一个文件。data = {"filename": "f1.txt", "create_time": "today", "size": 111}with open("data.pkl", "wb") as f:pickle.dump(data, f)print(os.listdir())with open("data.pkl", "rb") as f:data = pickle.load(f)print(data)
3 反序列化
pickle 可以将 类打包成文件,然后 unpickle 还原回来,File 类
class File:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = sizedef change_name(self, new_name):self.name = new_name
从 data.pkl 文件中 反序列化回来
# 打包类,File类data = File("f2.txt", "now", 222)# 存with open("data.pkl", "wb") as f:pickle.dump(data, f)# 读with open("data.pkl", "rb") as f:read_data = pickle.load(f)print(read_data.name)print(read_data.size)
4 系统资源对象
1)不能被序列化的系统资源对象
注:依赖外部系统状态的对象不能被序列化,比如 打开文件,网络连接,线程,进程,栈帧等等。
class File02:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = size# 打开文件self.file = open(name, "w")# 依赖外部系统状态的对象不能被序列化,比如 打开的文件,网络连接,线程,进程,栈帧等等。# data = File02("f3.txt", "now", 222)# pickle 存,会报错# TypeError: cannot pickle '_io.TextIOWrapper' object# with open("data.pkl", "wb") as f:# pickle.dump(data, f)
2)强行序列化系统资源对象
硬要用依赖外部系统状态的对象去 pickle 保存,可以规避一下,看 类 File03
class File03:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = sizeself.file = open(name, "w")def __getstate__(self):# pickle 出去需要且能被 pickle 的信息pickled = {"name": self.name, "create_time": self.create_time, "size": self.size}return pickleddef __setstate__(self, pickled_dict):# unpickle 加载回来,重组 classself.__init__(pickled_dict["name"], pickled_dict["create_time"], pickled_dict["size"])
示例
# 硬要用依赖外部系统状态的对象去 pickle 保存,可以规避一下# pickle.dump() 会调用 __getstate__() 获取序列化的对象。 __setstate__() 在反序列化时被调用。data = File03("f3.txt", "now", 222)# 存with open("data.pkl", "wb") as f:pickle.dump(data, f)# 读with open("data.pkl", "rb") as f:read_data = pickle.load(f)print(read_data.name)print(read_data.size)print()
三 Json
1 应用
# Json
# import json
data = {"filename": "f1.txt", "create_time": "today", "size": 111}
j = json.dumps(data)
print(j)
print(type(j))
2 序列化
Json 储存数据
# Json 储存数据
data = {"filename": "f1.txt", "create_time": "today", "size": 111}
with open("data.json", "w") as f:json.dump(data, f)print("直接当纯文本读:")
with open("data.json", "r") as f:print(f.read())
3 反序列化
print("用 json 加载了读:")
with open("data.json", "r") as f:new_data = json.load(f)
print("字典读取:", new_data["filename"])
4 不能序列化 class 类
class File04:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = sizedef change_name(self, new_name):self.name = new_name
# json 不能序列化保存 class
# TypeError: Object of type File is not JSON serializable
data = File04("f4.txt", "now", 222)
# 存,会报错
# with open("data.json", "w") as f:
# json.dump(data, f)四 Pickle 和 Json 对比
| 对比 | Pickle | Json |
|---|---|---|
| 存储格式 | Python 特定的 Bytes 格式 | 通用 JSON text 格式,可用于常用的网络通讯中 |
| 数据种类 | 类,功能,字典,列表,元组等 | 基本和 Pickle 一样,但不能存类,功能 |
| 保存后可读性 | 不能直接阅读 | 能直接阅读 |
| 跨语言性 | 只能用在 Python | 可以跨多语言读写 |
| 处理时间 | 长(需编码数据) | 短(不需编码) |
| 安全性 | 不安全(除非你信任数据源) | 相对安全 |
五 完整代码示例
# This is a sample Python script.# Press ⌃R to execute it or replace it with your code.
# Press Double ⇧ to search everywhere for classes, files, tool windows, actions, and settings.
import pickle
import os
import jsonclass File04:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = sizedef change_name(self, new_name):self.name = new_nameclass File03:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = sizeself.file = open(name, "w")def __getstate__(self):# pickle 出去需要且能被 pickle 的信息pickled = {"name": self.name, "create_time": self.create_time, "size": self.size}return pickleddef __setstate__(self, pickled_dict):# unpickle 加载回来,重组 classself.__init__(pickled_dict["name"], pickled_dict["create_time"], pickled_dict["size"])class File02:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = sizeself.file = open(name, "w")class File:def __init__(self, name, create_time, size):self.name = nameself.create_time = create_timeself.size = sizedef change_name(self, new_name):self.name = new_namedef print_hi(name):# Use a breakpoint in the code line below to debug your script.print(f'Hi, {name}') # Press ⌘F8 to toggle the breakpoint.# 主要涉及到的功能# Pickle# pickle.dumps()# pickle.dump()# pickle.load()# Json# json.dumps()# json.dump()# json.load()data = {"filename": "f1.txt", "create_time": "today", "size": 111}print(pickle.dumps(data))# 用 pickle.dump() 将字典直接转换成一个文件。data = {"filename": "f1.txt", "create_time": "today", "size": 111}with open("data.pkl", "wb") as f:pickle.dump(data, f)print(os.listdir())with open("data.pkl", "rb") as f:data = pickle.load(f)print(data)# 打包类,File类data = File("f2.txt", "now", 222)# 存with open("data.pkl", "wb") as f:pickle.dump(data, f)# 读with open("data.pkl", "rb") as f:read_data = pickle.load(f)print(read_data.name)print(read_data.size)# 依赖外部系统状态的对象不能被序列化,比如 打开的文件,网络连接,线程,进程,栈帧等等。# data = File02("f3.txt", "now", 222)# pickle 存,会报错# TypeError: cannot pickle '_io.TextIOWrapper' object# with open("data.pkl", "wb") as f:# pickle.dump(data, f)# 硬要用依赖外部系统状态的对象去 pickle 保存,可以规避一下# pickle.dump() 会调用 __getstate__() 获取序列化的对象。 __setstate__() 在反序列化时被调用。data = File03("f3.txt", "now", 222)# 存with open("data.pkl", "wb") as f:pickle.dump(data, f)# 读with open("data.pkl", "rb") as f:read_data = pickle.load(f)print(read_data.name)print(read_data.size)print()# Jsondata = {"filename": "f1.txt", "create_time": "today", "size": 111}j = json.dumps(data)print(j)print(type(j))print()# Json 储存数据data = {"filename": "f1.txt", "create_time": "today", "size": 111}with open("data.json", "w") as f:json.dump(data, f)print("直接当纯文本读:")with open("data.json", "r") as f:print(f.read())print("用 json 加载了读:")with open("data.json", "r") as f:new_data = json.load(f)print("字典读取:", new_data["filename"])print()# json 不能序列化保存 class# TypeError: Object of type File is not JSON serializabledata = File04("f4.txt", "now", 222)# 存,会报错# with open("data.json", "w") as f:# json.dump(data, f)# Pickle 和 Json 的不同# 存储格式 Python 特定的 Bytes 格式 通用 JSON text 格式,可用于常用的网络通讯中# 数据种类 类,功能,字典,列表,元组等 基本和 Pickle 一样,但不能存类,功能# 保存后可读性 不能直接阅读 能直接阅读# 跨语言性 只能用在 Python 可以跨多语言读写# 处理时间 长(需编码数据) 短(不需编码)# 安全性 不安全(除非你信任数据源) 相对安全# Press the green button in the gutter to run the script.
if __name__ == '__main__':print_hi('pickle 和 json 序列化')# See PyCharm help at https://www.jetbrains.com/help/pycharm/复制粘贴并覆盖到你的 main.py 中运行,运行结果如下。
Hi, pickle 和 json 序列化
b'\x80\x04\x958\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08filename\x94\x8c\x06f1.txt\x94\x8c\x0bcreate_time\x94\x8c\x05today\x94\x8c\x04size\x94Kou.'
['new_file4.txt', 'Function 函数.py', 'new_file5.txt', '如何控制异常 try-except.py', 'new_file.txt', 'me.py', 'new_file2.txt', '.DS_Store', 'new_file3.txt', 'f3.txt', 'Module 模块.py', 'chinese.txt', 'no_file.txt', 'module', 'user', '数据种类.py', '__pycache__', 'data.json', 'project', '正则表达式.py', 'file.py', '单元测试.py', 'pickle 和 json序列化.py', '变量与运算.py', 'data.pkl', '文件目录管理.py', '条件判断.py', 'Class 类.py', 'main.py', '读写文件.py', 'for 和 while 循环.py', '.idea']
{'filename': 'f1.txt', 'create_time': 'today', 'size': 111}
f2.txt
222
f3.txt
222{"filename": "f1.txt", "create_time": "today", "size": 111}
<class 'str'>直接当纯文本读:
{"filename": "f1.txt", "create_time": "today", "size": 111}
用 json 加载了读:
字典读取: f1.txt
六 源码地址
代码地址:
国内看 Gitee 之 pickle 和 json序列化.py
国外看 GitHub 之 pickle 和 json序列化.py
引用 莫烦 Python
相关文章:

Python Pickle 与 JSON 序列化详解:存储、反序列化与对比
Python Pickle 与 JSON 序列化详解:存储、反序列化与对比 文章目录 Python Pickle 与 JSON 序列化详解:存储、反序列化与对比一 功能总览二 Pickle1 应用2 序列化3 反序列化4 系统资源对象1)不能被序列化的系统资源对象2)强行序列…...

第二百三十二节 JPA教程 - JPA教程 - JPA ID自动生成器示例、JPA ID生成策略示例
JPA教程 - JPA ID自动生成器示例 我们可以将id字段标记为自动生成的主键列。 数据库将在插入时自动为id字段生成一个值数据到表。 例子 下面的代码来自Person.java。 package cn.w3cschool.common;import javax.persistence.Entity; import javax.persistence.GeneratedValu…...

计算机网络 ---- 计算机网络的体系结构【计算机网络的分层结构】
一、以快递网络来引入分层思想 1.1 “分层” 的设计思想【将庞大而复杂的问题,转化为若干较小的局部问题】 从我们最熟悉的快递网络出发,在你家附近会有一个快递终点站A,在其他的城市,也会有这种快递终点站,比如说快递…...

Vite + Electron 时,Electron 渲染空白,静态资源加载错误等问题解决
问题 如果在 electron 里直接引入 vite 打包后的东西,那么有些资源是请求不到的 这是我的引入方式 根据报错,我们来到 vite 打包后的路径看一看 ,修改一下 dist 里的文件路径试了一试 修改后的样子,发现是可以的了 原因分析 …...
)
ZAB协议(算法)
一、ZAB(ZooKeeper Atomic Broadcast)介绍 ZAB 即 ZooKeeper Atomic Broadcast,是 ZooKeeper 实现分布式数据一致性的核心算法。它是一种原子广播协议,用于确保在分布式环境中,多个 ZooKeeper 服务器之间的数据一致性。…...
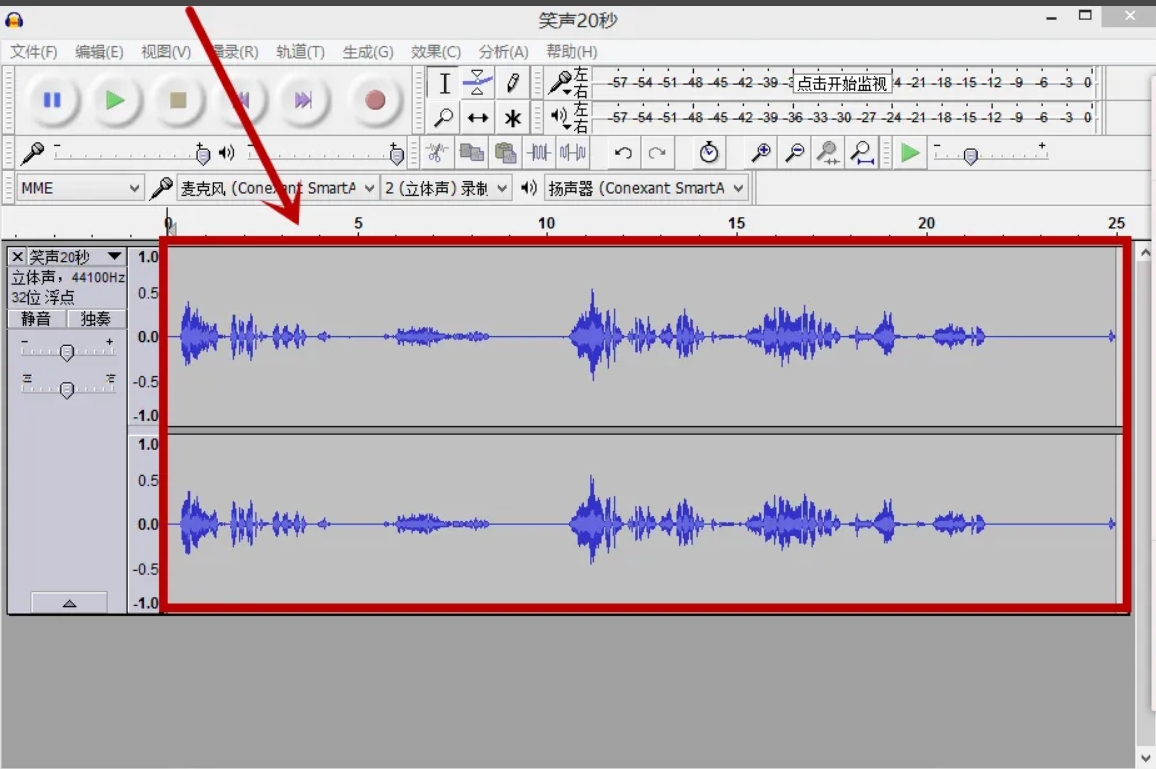
多个音频怎么合并?把多个音频合并在一起的方法推荐
多个音频怎么合并?无论是制作连贯的播客节目还是将音乐片段整合成专辑,音频合并已成为许多创作者的常见需求。通过有效合并音频,可以显著提升项目的整体质量,确保内容的连续性和一致性。然而,合并后的文件通常比原始单…...
 与 DRF APIView 的区别解析)
【Django】Django Class-Based Views (CBV) 与 DRF APIView 的区别解析
Django Class-Based Views (CBV) 与 DRF APIView 的区别解析 在 Django 开发中,基于类的视图(Class-Based Views, CBV)是实现可重用性和代码结构化的利器。而 Django REST Framework (DRF) 提供的 APIView 是针对 API 开发的扩展。 一、CBV …...

如何增加Google收录量?
想增加Google收录量,首先自然是你的页面数量就要多,但这些页面的内容也绝对不能敷衍,你的网站都没多少页面,谷歌哪怕想收录都没办法,当然,这是一个过程,持续缓慢的增加页面,增加网站…...

leetcode练习 格雷编码
n 位格雷码序列 是一个由 2n 个整数组成的序列,其中: 每个整数都在范围 [0, 2n - 1] 内(含 0 和 2n - 1)第一个整数是 0一个整数在序列中出现 不超过一次每对 相邻 整数的二进制表示 恰好一位不同 ,且第一个 和 最后一…...

【LLM:Gemini】文本摘要、信息提取、验证和纠错、重新排列图表、视频理解、图像理解、模态组合
开始使用Gemini 目录 开始使用Gemini Gemini简介 Gemini实验结果 Gemini的多模态推理能力 文本摘要 信息提取 验证和纠错 重新排列图表 视频理解 图像理解 模态组合 Gemini多面手编程助理 库的使用 引用 本文概述了Gemini模型和如何有效地提示和使用这些模型。本…...

CMS之Wordpress建设
下载 https://cn.wordpress.org/ 宝塔安装Wordpress 创建网站 上传文件、并解压、剪切文件到项目根目录 安装 -> 数据库信息 -> 标题信息 http://wordpress.xxxxx.com 登录 http://wordpress.xxxxxxxxx.com/wp-admin/ 1. 主题(模板) wordpress-基本使用-02-在主题…...

使用Neo4j存储聊天记录的简单教程
引言 在当今的数据驱动世界中,关系型数据库有时难以处理复杂的、相互关联的数据集。Neo4j作为一款开源图数据库,以其高效管理高连接数据的能力而广受欢迎。本篇文章将详细介绍如何使用Neo4j来存储聊天信息历史,引导您在实际项目中利用其强大…...

前端面试常考算法
快速排序 #include<iostream> #include<cstdio> using namespace std; const int N 100005; int a[N];void quick_sort(int a[], int l, int r) {if (l > r) return;int x a[l r >> 1];int i l - 1, j r 1;while (i < j) {while (a[i] < x);…...

【机试准备】常用容器与函数
Vector详解 原文链接:【超详细】C vector 详解 例题,这一篇就够了-CSDN博客 向量(Vector)是一个封装了动态大小数组的顺序容器(Sequence Container)。跟任意其它类型容器一样,它能够存放各种…...
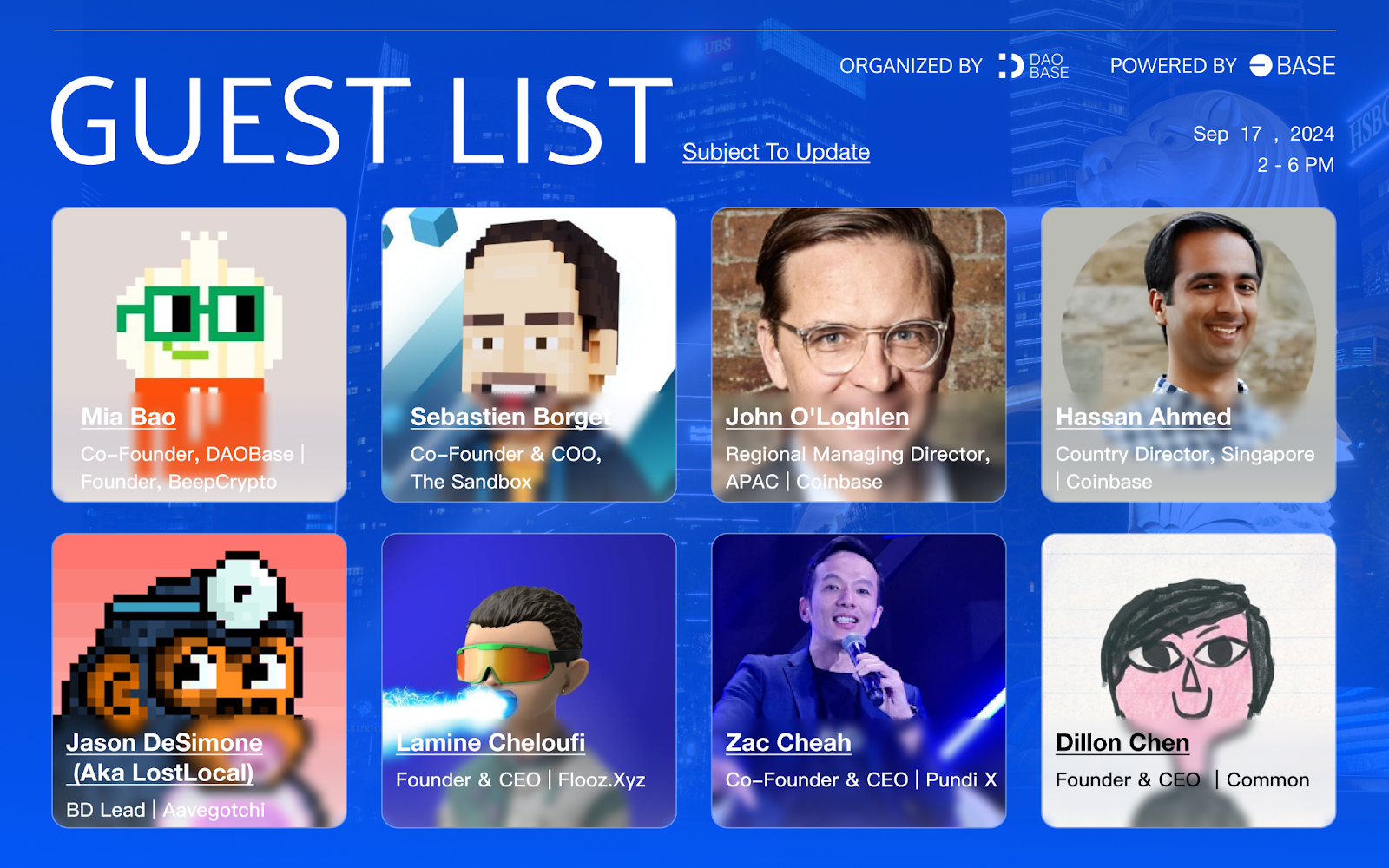
Base 社区见面会 | 新加坡站
活动信息 备受期待的 Base 社区见面会将于 Token2049 期间在新加坡举行,为 Base 爱好者和生态系统建设者提供一个独特的交流机会。本次活动由 DAOBase 组织,Base 和 Coinbase 提供支持,并得到了以下合作伙伴的大力支持: The Sand…...

麒麟操作系统搭建Nacos集群
Nacos 集群搭建 2.4.2 环境介绍 操作系统Kylin Linux Advanced Server V10 (Lance)Kylin Linux Advanced Server V10 (Lance)Kylin Linux Advanced Server V10 (Lance)内核版本Linux 4.19.90-52.22.v2207.ky10.aarch64Linux 4.19.90-52.22.v2207.ky10.aarch64Linux 4.19.90-52…...

Imagination推出性能最高且具有高等级功能安全性的汽车GPU IP
Imagination DXS GPU 进一步扩大其在汽车领域的领先地位 产品亮点 : 峰值性能比 Imagination 上一代汽车 GPU 提高了 50%,可扩展至 192GPixel/s、6 TFLOPS 和 24TOPS计算工作负载的性能提升多达十倍引入创新的分布式功能安全机制,以最小的…...

端口大全说明,HTTP,TCP,UDP常见端口对照表
HTTP,TCP,UDP常见端口对照表,下面罗列了包括在Linux 中的服务、守护进程、和程序所使用的最常见的通信端口小贴士:CtrlF 快速查找 Http端口号(点标题可收缩或展开) No1.最常用端口 端口号码/层名称注释1tcpmuxTCP端口服务多路复用5rje远程作…...

dplyr、tidyverse和ggplot2初探
dplyr、tidyverse 和 ggplot2 之间有紧密的联系,它们都是 R 语言中用于数据处理和可视化的工具,且都源于 Hadley Wickham 的工作。它们各自有不同的功能,但可以无缝协作,帮助用户完成从数据处理到数据可视化的工作流。以下是它们之…...

pandas:读取各类文件方法以及爬虫时json数据保存
文件的读取与写入 | 常用读文件方法 | 说明 | | -------------- | ---------------- | | read_csv | 读取CSV文件 | | read_excel | 读取Excel文件 | | read_html | 读取网页HTML文件 | | read_table | 通用读取方法 | | 常用写文…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...

JS红宝书笔记 - 3.3 变量
要定义变量,可以使用var操作符,后跟变量名 ES实现变量初始化,因此可以同时定义变量并设置它的值 使用var操作符定义的变量会成为包含它的函数的局部变量。 在函数内定义变量时省略var操作符,可以创建一个全局变量 如果需要定义…...
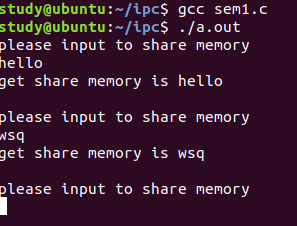
Linux-进程间的通信
1、IPC: Inter Process Communication(进程间通信): 由于每个进程在操作系统中有独立的地址空间,它们不能像线程那样直接访问彼此的内存,所以必须通过某种方式进行通信。 常见的 IPC 方式包括&#…...