【大模型专栏—进阶篇】智能对话全总结

大模型专栏介绍
😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文为大模型专栏子篇,大模型专栏将持续更新,主要讲解大模型从入门到实战打怪升级。如有兴趣,欢迎您的阅读。
💡适合人群:本科生、研究生、大模型爱好者,期待与你一同探索、学习、进步,一起卷起来叭!
🔗篇章一:本篇主要讲解Python基础、数据分析三件套、机器学习、深度学习、CUDA等基础知识、学习使用AutoDL炼丹
🔗篇章二:本篇主要讲解基本的科研知识、认识数据和显卡、语言模型如RNN、LSTM、Attention、Transformer、Bert、T5、GPT、BLOOM、LLama、Baichuan、ChatGLM等系列、强化学习教程、大模型基础知识及微调等
🔗篇章三:本篇主要讲解智能对话、大模型基础实战如Ollama、Agent、QLoar、Deepspeed、RAG、Mobile Agent等、大模型领域前沿论文总结及创新点汇总
目录
- 智能对话
- 多轮对话
- 知识图谱
- KBQA系统
- FAQ
- 生成式对话系统
智能对话
- 分类:
- 交互方式
- 文本对话系统:用户使用文本输入与机器人进行交互,是单一的NLP问题,使用场景包括网页客服机器人、APP客服机器人等

- 语音对话系统:分为内呼和外呼机器人,用户通过语音直接与机器人进行交流,涉及ASR、NLP及TTS系统,使用场景包括快递/银行官/运营商客服、电话推销、电话回访等



- 文本对话系统:用户使用文本输入与机器人进行交互,是单一的NLP问题,使用场景包括网页客服机器人、APP客服机器人等
- 对话目的
- 任务型对话:任务型对话,又称多轮对话系统,在
预设流程中执行固定对话流程 - 问答型对话:通过对
知识库的检索获取问答结果,例如FAQ系统和KBQA系统 - 闲聊对话:基于知识库检索或者生成模型进行闲聊式对话
- 任务型对话:任务型对话,又称多轮对话系统,在
- 应用场景
- 多轮对话:多轮对话系统由
DM和NLU系统构成,针对不同任务定制对话流程 - KBQA:基于
知识图谱对外提供可靠的问答服务 - FAQ:基于
信息检索对外提供基础问答服务 - 生成式对话:基于
文本生成能力对外提供问答服务
- 多轮对话:多轮对话系统由
- 交互方式
多轮对话
- 定义:多轮对话指根据上下文内容,进行
连续的、以达到解决某一类特定任务为目的的对话。 - 多轮对话系统参考历史信息的能力,在不同框架下实现方式:
- 对于传统多轮对话系统,通过
用户query驱动预设DM流程的方式实现。 - 对于LLM,可以通过
将前N轮对话内容与当前query组合传入模型的方式实现。多轮对话系统主要用于以下场景: - 机器人替代或部分替代人工完成
流程明确的沟通过程场景。 - 由LLM实现的
开放域多轮对话场景。
- 对于传统多轮对话系统,通过
传统多轮对话系统:
- 核心模块:
对话定制模块,用于根据多轮对话场景定制对话流程,生成对话流程文件。大部分为界面化拖拽方式,由公司自研或者使用第三方DMN工具,也可以以SOP脚本方式实现对话定制。- 公司自研DMN系统
界面化的多轮对话定制系统,采用拖拽和连接的方式构建多轮对话逻辑,提供丰富的节点类型和功能选择,基于公司内部的NLU系统方便的完成节点跳转条件配置等工作 - 第三方DMN软件
第三方DMN软件,例如Camunda Modeler等 - SOP脚本
采用文本形式组织多轮对话流程,一行为一个节点,每行定义满足条件、禁止条件、跳转节点、播报话术等信息
- 公司自研DMN系统
对话管理模块,即Dialogue Manager,提供对话引擎、对话状态管理等功能,用于驱动定制好的对话流程。- DM引擎
加载多轮对话文件,在内存中建立图结构、树结构或其他形式的流程结构,在新query进入后,驱动流程运行 - 上下文状态维护与更新
维护多路对话的状态(session),包括历史轮次信息、各变量中间状态的维护与更新 - DM工程框架
DM系统的整体执行逻辑,包括消息的接收处理,对DM系统内部模块的调用和结果信息整合,是DM系统的外部工程框架
- DM引擎
NLU模块,提供意图识别、槽位提取和NLG功能。- 意图解析
对用户query进行意图解析,通过意图决定DM流程走向,一般采用规则系统与多标签文本分类任务相结合的方式 - 槽位填充
对用户query中的槽位信息进行提取,例如,姓名/电话号码/物品名称,一般采用规则系统与NER相结合的方式 - NLG
根据意图进入新节点后,返回新节点配置的NLG回复话术
- 意图解析
知识图谱
- 介绍:知识图谱是一种用
图模型来描述知识和建模世界万物之间的关联关系的技术方法。 - 背景:知识图谱是Google于2012年提出,最早的应用是提升搜索引擎的能力。随后,知识图谱在辅助智能问答、自然语言理解、大数据分析、推荐计算、物联网设备互联、可解释性人工智能等多个方面展现出丰富的应用价值。
- 组成:知识图谱由
节点和边组成- 节点可以是
实体,如一个人、一本书等,或是抽象的概念,如人工智能、知识图谱等。 - 边可以是
实体的属性,如姓名、书名,或是实体之间的关系,如朋友、配偶。
- 节点可以是
- 知识抽取
- 实体抽取:从文本中检测出命名实体,并将其分类到预定义的类别中,例如人物、组织、地点、时间等
- 关系抽取:从文本中识别抽取实体及实体之间的关系,即SPO三元组,例如父子关系、上下级关系等
- 事件抽取:识别文本中关于事件的信息,并以结构化的形式呈现。例如,某事件发生的地点、时间等
- 知识表示
- 介绍:知识表示就是
对知识的一种描述,或者说是对知识结构的一组约定,一种计算机可以接受的用于描述知识的数据结构。本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
- RDF:图数据库的一种描述方式,或者说是一种使用协议。它以"三元组"(triple)的方式,描述事物与事物之间的直接关系。

- 三元组:RDF的核心概念,指的是两个事物和它们之间的关系,在语法上呈现为"主语+谓语+宾语",也就是SPO三元组。
- 要求:谓语(即事物之间的关系)必须有明确定义。如果谓语是给定的,就可以用主语去查询宾语,或者用宾语去查询主语。
- SPARQL:RDF
数据库的查询语言,跟SQL的语法很像。- 核心思想:根据给定的谓语动词,从三元组提取符合条件的主语或宾语。
- 示例:

- 属性图:属性图由节点集和边集组成。目前被图数据库业界采纳最广的一种图数据模型。
- 性质:
- 每个节点具有唯一的id;
- 每个节点具有若干条出边;
- 每个节点具有若干条入边;
- 每个节点具有一组属性,每个属性是一个键值对;
- 每条边具有唯一的id;
- 每条边具有一个头节点;
- 每条边具有一个尾节点;
- 每条边具有一个标签,表示联系;
- 每条边具有一组属性,每个属性是一个键值对。
- 示例:

- 性质:
- 知识存储:
- 背景:传统关系数据库无法有效适应知识图谱的图数据模型。
- 数据库:
- 负责存储RDF图(RDF graph)数据的三元组库(Triple Store),如DBpedia,应用较少。
- DBpedia:

- DBpedia:
- 管理属性图(Property Graph)的图数据库(Graph Database),如Neo4j、Nebula。【主流】
- Neo4j:

- Nebula:

- 定义:一款
开源的分布式图数据库,擅长处理千亿个顶点和万亿条边的超大规模数据集。提供高吞吐量、低延时的读写能力,内置ACL机制和用户鉴权,为用户提供安全的数据库访问方式。 - 服务:
Graph服务、Meta服务和Storage服务,是一种存储与计算分离的架构。Graph服务负责处理计算请求,Storage服务负责数据存储,Meta服务负责数据管理。
- Storage服务的层次结构:

- Storage interface:Storage服务的最上层,定义了一系列和图相关的API
- Consensus:Storage服务的中间层,实现了Multi Group Raft,保证强一致性和高可用性;
- Store Engine:Storage服务的最底层,是一个单机版本地存储引擎
RocksDB(见结尾补充内容)。
- Storage服务的层次结构:
- 实例:一个NebulaGraph实例由一个或多个图空间组成。每个图空间都是物理隔离的,用户可以在同一个实例中使用不同的图空间存储不同的数据集。[https://docs.nebula-graph.com.cn/2.6.1/1.introduction/1.what-is-nebula-graph/]

- 能力:
- 高吞吐低时延;
- 支持线性扩容缩容;
- 兼容OpenCypher及多种工具;
- 支持数据备份即快速恢复。
- 定义:一款
- Neo4j:
- 负责存储RDF图(RDF graph)数据的三元组库(Triple Store),如DBpedia,应用较少。
- 架构:
- 开放域知识图谱架构:

- 垂域知识图谱架构:

- 开放域知识图谱架构:
- 搭建流程示例:
- 需求:搭建饮食知识图谱
- 各类型食物(蔬菜、肉类、水果、坚果)的营养成分(热量、脂肪含量、蛋白质含量、碳水含量);(数仓数据)
- 各类菜品(素菜、荤菜、荤素搭配、主食)的食材、调料、营养成分、特性(例如低油/低脂/低糖)、烹饪方法、菜系、口味(苦辣酸甜);(无数据)
- 一日三餐的菜品搭配;(有菜品科学搭配方案)
- 不同用户需求(减脂/增肌)的菜品搭配;(有菜品科学搭配方案)
- 食物、食材、调料、菜品、用餐类型之间的明确关系;(无数据)
- 数据来源:

- 图谱建模:

- 需求:搭建饮食知识图谱
- 介绍:知识表示就是
RocksDB补充:
- 介绍:一个高性能、可扩展、嵌入式、持久化、可靠、易用和可定制的
键值存储库。 - 数据结构:RocksDB采用
LSM树数据结构,支持高吞吐量的写入和快速的范围查询,可被嵌入到应用程序中,实现持久化存储,支持水平扩展,可以在多台服务器上部署,实现集群化存储,具有高度的可靠性和稳定性,易于使用并可以根据需求进行定制和优化。它广泛应用于互联网公司和数据密集型应用中。
- LSM(Log-Structured Merge Tree):
将所有的数据修改操作(如插入、更新、删除)都记录在一个顺序日志文件中,这个日志文件又称为写前日志(Write-Ahead Log,WAL)。顺序日志文件的好处是顺序写入,相比随机写入可以提高写入性能。- LSM层级:LSM树中的层级可以分为内存和磁盘两个部分
- 内存层:内存层也被称为
MemTable,是指存储在内存中的数据结构,用于缓存最新写入的数据。当数据写入时,先将其存储到MemTable中,然后再将MemTable中的数据刷写到磁盘中,生成一个新的磁盘文件。由于内存读写速度非常快,因此使用MemTable可以实现高吞吐量的写入操作。 - 磁盘层:磁盘层是指
存储在磁盘中的数据文件,可以分为多个层级。一般来说,LSM树中的磁盘层可以分为Level-0 ~ Level-N几个层级。- Level-0:Level-0是最底层的磁盘层,存储的是
从内存层刷写到磁盘中的文件。Level-0中的文件大小一般比较小,排序方式为按照写入顺序排序。由于数据写入的速度很快,因此Level-0中的文件数量也比较多。 - Level-1:Level-1是Level-0的上一层,存储的是由
多个Level-0文件合并而来的文件。Level-1中的文件大小一般比较大,排序方式为按照键值排序。由于Level-0中的文件数量比较多,因此Level-1中的文件数量也比较多。 - Level-2及以上:Level-2及以上的磁盘层都是由
多个更低层级的文件合并而来的文件,文件大小逐渐增大,排序方式也逐渐趋向于按照键值排序。由于每个层级的文件大小和排序方式不同,因此可以根据查询的需求,选择最适合的层级进行查询,从而提高查询效率。
- Level-0:Level-0是最底层的磁盘层,存储的是
- 内存层:内存层也被称为
- LSM层级:LSM树中的层级可以分为内存和磁盘两个部分
- sstable文件:
- sstable文件
由block组成,block也是文件读写的最小逻辑单位,当读取一个很小的key,其实会读取一个block到内存,然后查找数据。 - 默认的block_size大小为4KB。每个sstable文件都会包含索引的block,用来加快查找。所以
block_size越大,index就会越少,也会相应的节省内存和存储空间,降低空间放大率,但是会加剧读放大,因为读取一个key实际需要读取的文件大小随之增加了。 - 在生产环境使用Nebula数据库时,数据压缩参数、最大读取文件数量和block参数是重要的内存优化参数。
- sstable文件
- LSM(Log-Structured Merge Tree):
Nebula图数据库搭建补充:
1.下载需要的安装包:

2.连接服务器,进入工作目录:
# 明确操作系统类型和版本
# Ubuntu
cat /etc/issue
# Ubuntu 20.04.4 LTS \n \l# CentOS
cat /etc/redhat-release
# CentOS Linux release 7.7.1908 (Core)# 准备工作目录
cd ~/autodl-tmp/artboy
mkdir nebula && mkdir nebula_info# 转移数据盘
cd nebula
mv ~/autodl-tmp/nebula/nebula-* .# ls
# nebula-console-2.6.0 nebula-graph-2.6.0.ubuntu1804.amd64.tar.gz nebula-graph-studio-3.1.0.x86_64.tar.gzmv ~/autodl-tmp/nebula/nvm-0.39.3.tar.gz .
# ls
# nebula-console-2.6.0 nebula-graph-studio-3.1.0.x86_64.tar.gz nebula-graph-2.6.0.ubuntu1804.amd64.tar.gz nvm-0.39.3.tar.gz# 安装nebula-graph-2.6.0
tar -xvf nebula-graph-2.6.0.ubuntu1804.amd64.tar.gz
cd nebula-graph-2.6.0.ubuntu1804.amd64
# ls
# bin etc logs pids scripts share
3.单机配置:
进⼊安装包的etc配置⽂件⽬录,将三个核⼼组件的配置⽂件nebula-meta.conf.default、nebula-storaged.conf.default、nebulagraphd.conf.default复制为nebula-meta.conf、nebula-storaged.conf、nebula-graphd.conf
# 修改配置
cd etc
mv nebula-graphd.conf.default nebula-graphd.conf && mv nebula-storaged.conf.default nebula-storaged.conf && mv nebula-metad.conf.default nebula-metad.conf
# ls
# nebula-graphd.conf nebula-metad.conf.production nebula-storaged-listener.conf.production nebula-graphd.conf.production nebula-storaged.conf nebula-metad.conf nebula-storaged.conf.production
单机就是执⾏⼀次上⾯的配置⽂件复制,集群就是每台集群复制⼀次
4.日志文件配置:
Nebula执行过程中会产生大量日志信息,如果不进行日志监听级别和存储路径的修改,⽇志会很快占⽤⼤量内存,导致服务器/目录被占满,对nebula-graphd.conf、nebula-metad.conf、nebula-storaged.conf进⾏如下修改:
修改nebula-graphd.conf
# 1.复制路径
pwd
# /root/autodl-tmp/artboy/nebula/nebula-graph-2.6.0.ubuntu1804.amd64/etcvim nebula-graphd.conf########## logging ##########
# The directory to host logging files
--log_dir=/root/autodl-tmp/artboy/nebula_info/graph_logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=1
修改nebula-metad.conf
vim nebula-metad.conf########## logging ##########
# The directory to host logging files
--log_dir=/root/autodl-tmp/artboy/nebula_info/meta_logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=1########## storage ##########
# Root data path, here should be only single path for metad
--data_path=/root/autodl-tmp/artboy/nebula_info/meta_data
修改nebula-storaged.conf
vim nebula-storaged.conf########## logging ##########
# The directory to host logging files
--log_dir=/root/autodl-tmp/artboy/nebula_info/storage_logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=1########## Disk ##########
# Root data path. Split by comma. e.g. --data_path=/disk1/path1/,/disk2/path2/
# One path per Rocksdb instance.
--data_path=/root/autodl-tmp/artboy/nebula_info/storagea_data
Nebula Storage服务的最底层,是⼀个单机版本地存储引擎Rocksdb,可以通过对Rocksdb进⾏参数调整来优化Storage的内存使⽤:
############## rocksdb Options ##############
# rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
--rocksdb_db_options={"max_background_jobs":"8", "max_open_files":"50000"}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
#--rocksdb_column_family_options={"write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level base":"268435456"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"32768"}
优化效果:

5.Nebula启动:
进入执行脚本:
cd ../scripts# ls
# meta-transfer-tools.sh nebula-graphd.service nebula-metad.service nebula.service nebula-storaged.service utils.sh# 启动服务
./nebula.service start all[WARN] The maximum files allowed to open might be too few: 1024
[INFO] Starting nebula-metad...
[INFO] Done
[INFO] Starting nebula-graphd...
[INFO] Done
[INFO] Starting nebula-storaged...
[INFO] Done# 查看状态
./nebula.service status all[WARN] The maximum files allowed to open might be too few: 1024
[INFO] nebula-metad(3ba41bd): Running as 2034, Listening on 9559
[INFO] nebula-graphd(3ba41bd): Running as 2101, Listening on 9669
[INFO] nebula-storaged(3ba41bd): Exited
一般我们使用lsof来查看端口占用情况
# 1.更新apt-get服务
apt-get update
# 2.安装lsof命令
apt-get install lsof
# 3. 查看端口占用情况
lsof -i:9669
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nebula-gr 2101 root 516u IPv4 263043713 0t0 TCP *:9669 (LISTEN)
安装nebula-graph-studio
tar -xvf nebula-graph-studio-3.1.0.x86_64.tar.gz
启动nebula-graph-studio需要npm命令,autodl服务器默认没有npm命令,需要通过nvm安装node.js
# 1.解压
tar -xvf nvm-0.39.3.tar.gz
# 2.添加配置命令,对~/.bashrc进⾏如下修改:
# ls
# ~/autodl-tmp/artboy/nebula# ls
# nvm-0.39.3.tar.gz nvm-0.39.3vim ~/.bashrc
# 底部那里添加以下内容
export NVM_DIR="/root/autodl-tmp/artboy/nebula/nvm-0.39.3"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"# 3.source一下
source ~/.bashrc# 4.测试nvm命令
nvm -v
# 0.39.3
安装nodejs和nrpm:
nvm install 16.17.0
启动nebula-graph-studio:
cd nebula-graph-studio
# ls
# DEPLOY.md nebula-graph-studio nebula-http-gateway# 1.
cd nebula-http-gateway
nohup ./nebula-httpd &
# [1] 4241# 2.
cd ../nebula-graph-studio
npm run start
# lsof -i:7001
# COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
# node 4288 root 23u IPv4 263509160 0t0 TCP *:7001 (LISTEN)
6.本地访问:
1.点击自定义服务,选择Linux/Mac

粘贴,修改需要映射的端口号:

访问本地端口:

输入账号密码进行登录:

KBQA系统
- 介绍:一种根据知识库知识,准确、简洁地回答自然语言问题的问答系统。
- 实现方式:
- 基于
语义解析(Semantic Parsing)的方法:对问句进行句法/语法解析和信息提取,并将解析结果组合成可执行的逻辑表达式(如SPARQL),直接从图数据库中查询答案。- 步骤:将
自然语言的问句解析成逻辑形式(Logic Form)- (1)问题解析:解析自然语言问题句法&语义(Pythia);

- (2)模板生成:通过规则系统将语义信息映射为SPARQL模板;

- (3)模板实例化:通过实体链接和关系链接将SPARQL模板中的slot进行填充得到完整的可查询的模板;
- 实体词链接:SPARQL模板要想作用于一个RDF数据库,需要将模板中的字符串映射为RDF数据库中的实体词(比如:
类型词、实例词和属性词等)类型词与实体词链接:对于待匹配的字符串s,从WordNet中获取近义词词典S(s),找到符合查找类型label(e)的所有实体e,利用字符串相似度计算实体e与每个近义词的相似度,选出字符串相似度最高的实体。
- trigram:三元分词,把句子从头到尾每三个字组成一个词语。
- 编辑距离:两个字串之间,由一个转换成另一个所需的最少编辑操作次数。
- 最大子串相似度:两个字符串之间最长的相同子字符串的长度。
- 属性/关系词链接:由于属性词(谓词)可以有多重说法,所以属性词的链接相对复杂,这里采用
BOA(Bootstrapping linked datA)框架,通过bootstrap的方法挖掘出不同的自然语言说法到谓词的映射:- (1)对于每一个谓词,通过知识库K我们可以得到很多满足I ( p ) = { ( x, y ) : ( x p y )∈K }的样例;
- (2)对于每个样例{ x y },我们可以从语料库(如wiki等)
找出x和y共现的句子; - (3)根据
label(x) .* label(y)或label(y) .* label(x)的正则从共现句中匹配出子串; - (4)对于这些子句,BOA会抽象出
NLE表达式θ,形如?D?representation?R?或者?R?representation?D?,其中?D?和?R?为label(x)和label(y)的占位符,例如,?book? is abook of ?author?。NLE抽取过程会得到一个庞大集合(p, θ),称之为BOA patterns,每一个θ都代表p的一种潜在表示; - (5)对每一个挖掘出来的
表达式θ,我们可以计算出其与某个谓词p的匹配得分,根据这个得分我们可以筛选出最合适的映射关系。 - 评估指标:
- 一个好的NLE θ能够覆盖 I ( p ) 中的多个元素,即θ的支持性support;(
类似TF)【大白话:吃,覆盖多少句子合理(老虎吃肉,小明吃汉堡,…)】
- 一个好的 NLE θ 的占位符 ?D? 和 ?R? 应该只匹配 rdf:type 在 p 的 range 和 domain 限制范围内的实体 label,即 θ 的典型性 typicity; (
主-宾类型适配度)【大白话:吃(小明吃汉堡、小明吃苹果);喜欢(小明喜欢苹果,小明喜欢电影);吃和喜欢跟的宾语类型不一样,相当于类型加了一层限制】
- 一个好的NLE θ应该专门用来表达p,也就是说它只能表征少数的p,即θ的特异性specificity。(
类似IDF)【大白话:小明喜欢xx,小明害怕xx,喜欢和害怕能好多替换,专一性越弱,分子分母越接近,log越小】
- 一个好的NLE θ能够覆盖 I ( p ) 中的多个元素,即θ的支持性support;(
- SPARQL排序:通过模版实例化过程后,得到一批候选SPARQL,接下来需要
排序并选择最优SPARQL- 实现方法:对SPARQL中填入的每一个链接词,计算如下的分数score(e)(链接词的相似性分数σ(e)与三元组的显著性分数φ(e)):【大白话:σ(e)的含义是
我喜欢你的关系在整个知识图谱出现过多少次;score:我和你是妻子。我在图谱的贡献 + 妻子在图谱的贡献】
- 实现方法:对SPARQL中填入的每一个链接词,计算如下的分数score(e)(链接词的相似性分数σ(e)与三元组的显著性分数φ(e)):【大白话:σ(e)的含义是
- 实体词链接:SPARQL模板要想作用于一个RDF数据库,需要将模板中的字符串映射为RDF数据库中的实体词(比如:
- (4)模板排序:因为自然语言的模糊性,一句话可能映射为多个SPARQL模板,所以会对多个模板进行排序;
- (5)模板查询:用SPARQL模板从RDF数据查询获取结果。
- (1)问题解析:解析自然语言问题句法&语义(Pythia);
- 语义解析补充:
- 论文的实验是在QALD5数据集(QALD5基准:包含两组50个关于DB-pedia的问题)上验证,通过SPARQL查询和答案注释,每个问题都采用准确和召回进行评估。
- 评估结果:平均precision为0.61,平均recall为0.63,由此计算F值为0.62。
- 核心问题:
解决两种描述语言之间的不匹配问题,一种是数据库中的干净、规范化的本体论描述语言,另一种是自然语言中获取的查询描述语言,如何将这两种描述语言匹配起来,是KBQA的难点。
- AMR:大模型出现之前,比较有潜力的方法,该方法旨在
使用问题中传达的信息,直接从知识库中检索并排序答案
- 论文的实验是在QALD5数据集(QALD5基准:包含两组50个关于DB-pedia的问题)上验证,通过SPARQL查询和答案注释,每个问题都采用准确和召回进行评估。
- 步骤:将
- 基于
信息检索(Information Retrieval)的方法:先解析出问句的主实体,再从KG中查询出主实体关联的多个三元组,组成子图路径(也称多跳子图),之后分别对问句和子图路径编码、排序,返回分数最高的路径作为答案。
- (1)从问题中确定中心实体,并从知识库中提取出特定于问题的子图,理想情况下,该图应该包含所有与中心实体相关的实体和关系;
- (2)通过一个问题表示模块,对输入的问题进行embedding,得到编码向量;
- (3)通过候选答案表示模块,对候选子图进行embedding;
- (4)对问题embedding和候选子图embedding进行相似度计算,选出目标答案。
- 基于Bert:
- 方法:

- 1.首先找到实体链接系统中
连接主题实体e_topic和候选实体ei的所有路径(设置最大路径数并在数量超过阈值时应用下采样); - 2.然后通过在知识库KB中用实体名称替换节点和用关系名称替换边来
构建每条路径的文本形式; - 3.然后
concatenate问题q和所有路径p1, …,pn生成输入样本:xi = [CLS]q[SEP]p1 [SEP]……pn[SEP]; - 4.将样本提供给BERT并采用
与[CLS] token对应的表示进行二分类(将这些路径视为主题实体e_topic和候选实体ei之间的事实,目标是使用BERT来预测假设“ei is the answer ofq”是否得到这些知识库KB事实的支持)。
- 1.首先找到实体链接系统中
- 预训练任务:

- 1.Relation Extraction(RE):
从句子中推断关系,基于大规模关系抽取开源数据集,生成了大量一跳([CLS]s[SEP]h, r, t[SEP])与两跳([CLS]s1 , s2 [SEP]h1 , r1 , t1 (h2 ), r2 ,t2 [SEP])的文本对训练数据,让模型学习自然语言与结构化文本间的关系。 - 2.Relation Matching(RM):
判断两个句子是否表达相同关系,为了让模型更好的捕捉到关系语义,我们基于关系抽取数据生成了大量文本对,拥有相同关系的文本互为正例,否则为负例。 - 3.Relation Reasoning(RR):
自监督方式从知识库构建数据,对缺失连接进行推理。为了让模型具备一定的知识推理能力,假设图谱中的(h, r, t)缺失,并利用其他间接关系来推理(h, r, t)是否成立,输入格式为:[CLS]h, r, t[SEP]p1 [SEP] . . . pn [SEP]。
- 1.Relation Extraction(RE):
- 方法:
- 基于
FAQ
- 介绍:FAQ系统
基于问答库,采用文本匹配的方式召回候选问答对,排序后进行问答回复,提供一问一答式的问答体验。 - 流程:
- 知识库构建:通过内部数据及外部采集数据搭建QA知识库,后续FAQ问答基于知识库内容。


- 召回策略实现:实现从FAQ库内召回候选问答簇的算法策略。
- 匹配策略实现:实现对召回问答簇进行文本匹配的精排策略,用于确定候选的TopK个答案。
- FAQ系统搭建:完成FAQ整体系统的搭建,串联FAQ系统中的各个模块。
- 知识库构建:通过内部数据及外部采集数据搭建QA知识库,后续FAQ问答基于知识库内容。
- 架构:
- 1.0:

- 2.0:

- 3.0:

- 1.0:
生成式对话系统

📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2024.9.15
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,本人也很想知道这些错误,恳望读者批评指正!

相关文章:
【大模型专栏—进阶篇】智能对话全总结
大模型专栏介绍 😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文为大模型专栏子篇,大模型专栏将持续更新,主要讲解大模型从入门到实战打怪升级。如有兴趣,欢迎您的阅读。 Ǵ…...

MVC应用单元测试以及请求参数的验证
SpringMVC支持对Controller单元测试 RunWith(SpringJUnit4ClassRunner.class) ContextConfiguration(locations {"classpath:mvc-dispatcher-servlet.xml", }) WebAppConfiguration public class ControllerJUnitBase{Resourceprivate RequestMappingHandlerMappin…...

算法:TopK问题
题目 有10亿个数字,需要找出其中的前k大个数字。 为了方便讲解,这里令k为5。 思路分析(以找前k大个数字为例) 很容易想到,进行排序,然后取前k个数字即可。 但是,难点在于,10亿个数…...

.json文件的C#解析,基于Newtonsoft.Json插件
目录 1. 前言 2. 正文 2.1 问题 2.2 解决办法 2.2.1 思路 2.2.2 代码实现 2.2.3 测试结果 3. 备注 1. 前言 天气晚来秋,这几天天气变凉了,各位同学注意好多穿衣服。回归正题 由于需要,需要将json的配置里面的调理解析出来,做成接口,以便于开发。 2. 正文 2.1 …...

四、(JS)JS中常见的加载事件
一、文档加载监听 (1)抛出疑惑,什么是文档加载监听?为什么要有这个东西? 老样子,我们先讲一个场景,带着大家熟悉为什么会有文档加载监听,是来解决什么问题来着的。 我们先看下这段…...

[网络]https的概念及加密过程
文章目录 一. HTTPS二. https加密过程 一. HTTPS https本质上就是http的基础上增加了一个加密层, 抛开加密之后, 剩下的就是个http是一样的 s > SSL HTTPS HTTP SSL 这个过程, 涉及到密码学的几个核心概念 明文 要传输的真正意思是啥 2)密文 加密之后得到的数据 这个密文…...

React 嵌套类名样式不生效
修改前 父级.blog样式生效,子级.circle样式不生效 // app/blog/page.js import styles from "./page.module.scss"export default function Blog () {return (<div className{styles.blog}><div classNamecircle><div /></div>…...

20Kg载重30分钟续航多旋翼无人机技术详解
一、机架与结构设计 1. 材料选择:为了确保无人机能够承载20Kg的负载,同时实现30分钟的续航,其机架材料需选用轻质高强度的材料,如碳纤维或铝合金。这些材料不仅具有良好的承重能力,还能有效减轻无人机的整体重量&…...

详解c++:认识类
文章目录 前言一、类是什么二、类(class)的使用publicprivate:protected: 前言 C 是一种面向对象的编程语言。面向对象编程是一种编程范式,它使用“对象”来设计软件应用程序。在面向对象编程中,对象包含了…...

HTML5中的重要元素详解
第3章 HTML5中的重要元素 3.1 html根元素 HTML文档中,元素html代表了文档的根,其他所有元素都是在该元素的基础上进行延伸或拓展的,该元素也是HTML文档的最外层元素,因此也称为根元素。 html元素的常用属性: manif…...
)
八股文知识汇总(常考)
八股文知识汇总(常考) 语言特性相关 JAVA知识 - JDK动态代理为什么只能代理有接口的类? 说一下对象创建的过程?ThreadLocal是什么?他的实现原理是什么?ThreadLocal会出现内存泄露吗?String、…...

unity 图片置灰shader
我和chatgpt真强! 在 Unity 编辑器中,右键点击 Assets 文件夹,选择 Create -> Shader -> Unlit Shader。shader代码如下,尽管我看的不是很懂,但确实有用 Shader "Custom/GrayScaleShader" {Properti…...

【C语言】(指针系列2)指针运算+指针与数组的关系+二级指针+指针数组+《剑指offer面试题》
前言:开始之前先感谢一位大佬,清风~徐~来-CSDN博客,由于是时间久远,博主指针的系列忘的差不多了,所以有些部分借鉴了该播主的,有些地方如果解释的不到位,请翻看这位大佬的,感谢大家&…...

探索信号处理:使用傅里叶小波变换分析和恢复信号
在现代信号处理领域,傅里叶变换是分析和处理信号的一种基本工具。然而,传统的傅里叶变换在处理非平稳信号时存在局限性,因为它无法同时提供时间和频率的信息。为了克服这一挑战,傅里叶小波变换(FSWT)应运而…...

俄罗斯方块——C语言实践(Dev-Cpp)
目录 1、创建项目(尽量不使用中文路径) 2、项目复制 3、项目配置 1、调整编译器 2、在配置窗口选择参数标签 3、添加头文件路径和库文件路径 4、代码实现 4.1、main.c 4.2、draw.h 4.3、draw.c 4.4、shape.h 4.5、shape.c 4.6、board.h 4.7、board.c 4.8、cont…...

关于wp网站出现的问题
问题1 问题1:如果出现这个界面的问题 说明是根目录的index.php编码出了问题,用备份的源文件退换一下即可。 问题2 问题2:如果出现页面错位现象,可能是某个WP插件引起的问题,这里需要逐步排查插件,或者你刚…...
为什么H.266未能普及?EasyCVR视频编码技术如何填补市场空白
H.266,也被称为Versatile Video Coding(VVC),是近年来由MPEG(Moving Picture Experts Group)和ITU(International Telecommunication Union)联合开发并发布的新一代国际视频编码标准…...
)
最全 高质量 大模型 -评估基准数据集(不定期更新)
评估基准是推动人工智能领域技术进步和应用落地的关键工具,通过这些基准,我们可以更全面地理解LLMs的能力,并指导未来的研究和实践。 评估基准,是一套衡量标准,就像老师用考试来检查学生学得怎么样。在大模型的世界里…...

react 中, navigate 跳转链接 2种写法
react 中, navigate 下面2种写法, 有什么区别, import { useNavigate } from "react-router-dom"; const navigate useNavigate(""); onClick{() > navigate("/signup")}import { Navigate } from "react-route…...
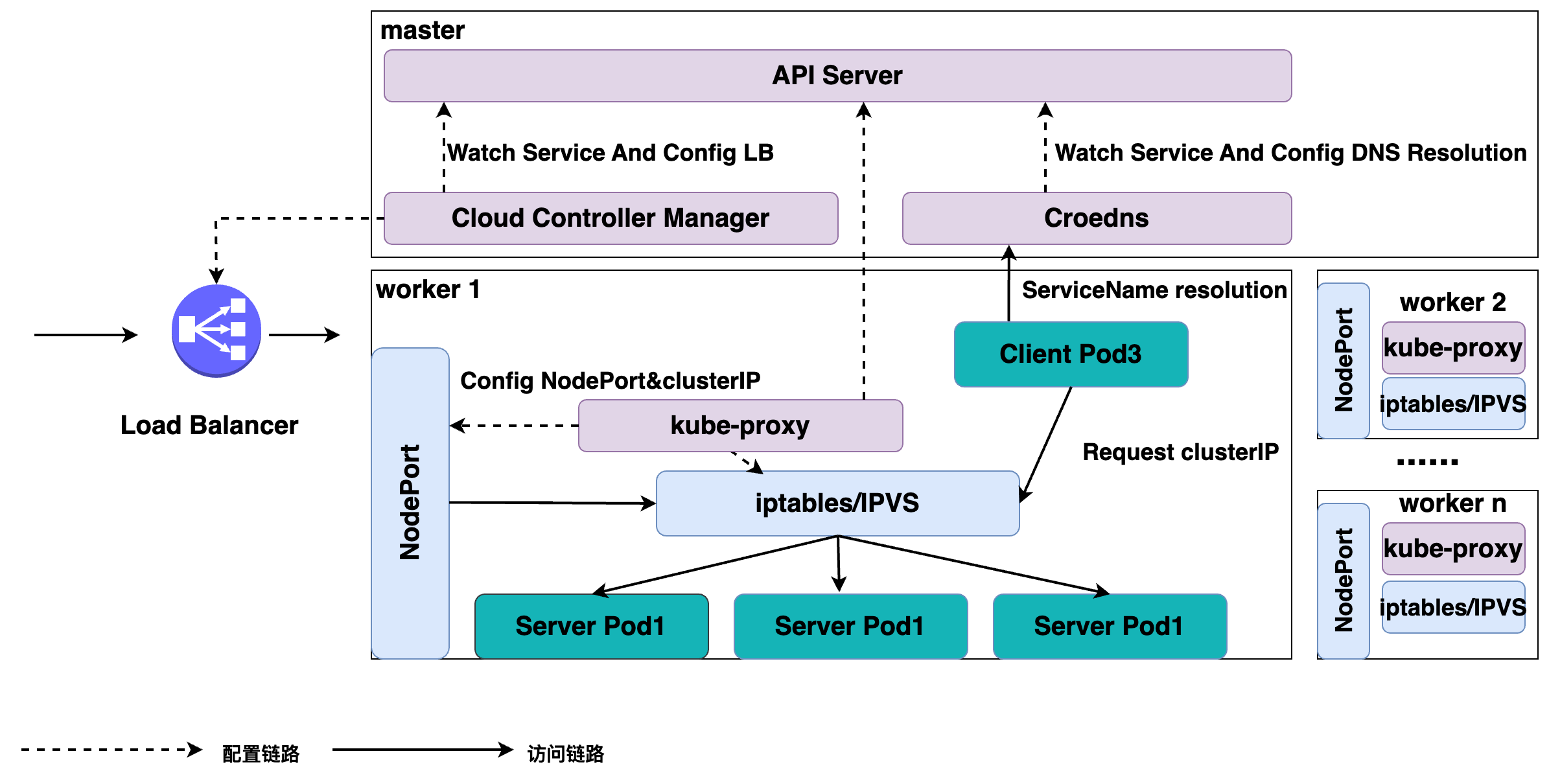
k8s Service 服务
文章目录 一、为什么需要 Service二、Kubernetes 中的服务发现与负载均衡 -- Service三、用例解读1、Service 语法2、创建和查看 Service 四、Headless Service五、集群内访问 Service六、向集群外暴露 Service七、操作示例1、获取集群状态信息2、创建 Service、Deployment3、创…...

Nikto实战指南:从基础扫描到高级漏洞检测
1. Nikto入门:你的第一把Web安全扫描枪 第一次听说Nikto的时候,我正在给客户的电商网站做安全评估。当时手动检查了三个小时都没发现明显漏洞,抱着试试看的心态运行了Nikto,结果两分钟就揪出了五个高危风险点——包括一个暴露的ph…...

C/C++标准库解析:从原理到实践
1. C/C 标准库的本质与标准化过程作为一名长期从事系统开发的程序员,我经常遇到新手对标准库的困惑:这些看似"凭空出现"的函数和类到底从何而来?让我们从最基础的概念开始拆解。C和C标准库的本质是一套经过严格定义的编程接口规范。…...

002、YOLOv1深度解析:You Only Look Once的开创性架构与核心思想
从一次深夜调试说起 上周在部署一个老版本的实时检测模型时,我又遇到了那个经典问题:检测框在物体快速移动时总会出现“抖动”,相邻帧之间的预测结果不一致。同事建议上卡尔曼滤波做后处理,我却在想——如果模型本身就能看到“全局…...

STM32驱动SIM800C的硬件抽象层设计与实现
1. 项目概述ARCH_GPRS_V2_HW是基于 Seeed Studio 推出的 ARCH GPRS V2 硬件模块开发的一套底层驱动库,其原始设计源自官方提供的Arch GPRS HW DEMO工程。该库并非通用 AT 指令封装层,而是一套面向 STM32 平台(典型为 STM32F407VET6 或 STM32F…...

React Native 项目重构利器:使用 react-native-rename 快速迁移应用品牌
React Native 项目重构利器:使用 react-native-rename 快速迁移应用品牌 【免费下载链接】react-native-rename Rename react-native app with just one command 项目地址: https://gitcode.com/gh_mirrors/re/react-native-rename react-native-rename 是一…...

造相-Z-Image-Turbo LoRA镜像合规性:符合中国AI生成内容标识与内容安全要求
造相-Z-Image-Turbo LoRA镜像合规性:符合AI生成内容标识与内容安全要求 1. 项目概述与核心价值 造相-Z-Image-Turbo LoRA镜像是一个基于先进AI技术的图片生成Web服务,专门为需要高质量图像生成的用户设计。这个服务不仅提供了强大的图像生成能力&#…...

终极网盘直链下载助手完整指南:八大平台一键解锁免费高速下载
终极网盘直链下载助手完整指南:八大平台一键解锁免费高速下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

中国科技发展与华人贡献解析
中国科技发展与华人贡献解析纵观全球科技发展的壮阔历程,华人力量始终是不可或缺的核心支柱,中国科技的崛起与腾飞,既离不开本土科研工作者的深耕细作,更得益于海外华人的默默坚守与无私奉献。然而,长期以来࿰…...

图片调色思路分享
图片调色是摄影后期处理的核心环节,旨在塑造画面的色彩氛围、统一风格、突出主题或表达情感。以下是一个系统的调色思路,结合了您提纲中的基础调整与色彩管理部分:1. 基础定调与校正 (奠定基础)审视直方图与曝光:首先观察图像的直…...

大模型学习指南:小白程序员必备,收藏这份2026年开源大模型体系与实战教程!
大模型学习指南:小白程序员必备,收藏这份2026年开源大模型体系与实战教程! 本文全面介绍了2026年主流开源大模型体系(如Llama、Qwen、Mistral等),解析了Prefix Decoder、Causal Decoder、Encoder-Decoder的…...