Zookeeper学习
文章目录
- 学习
- 第 1 章 Zookeeper 入门
- 1.1 概述
- Zookeeper工作机制
- 1.2 特点
- 1.3 数据结构
- 1.4 应用场景
- 统一命名服务
- 统一配置管理
- 统一集群管理
- 服务器动态上下线
- 软负载均衡
- 1.5 下载zookeeper
- 第 2 章 Zookeeper 本地安装
- 2.1 本地模式安装
- 安装前准备
- 配置修改
- 操作 Zookeeper
- 本地安装zk示例
- 2.2 配置参数解读
- tickTime
- initLimit
- syncLimit
- dataDir
- clientPort
- 第 3 章 Zookeeper 集群操作
- 3.1 集群操作
- 3.1.1 集群安装
- 1、集群规划
- 2、解压安装
- 3、配置服务器编号
- 4、配置zoo.cfg文件
- 5、集群操作
- zookeeper集群操作示例
- 3.1.2 选举机制(面试重点)
- 第一次启动
- 非第一次启动
- 3.1.3 ZK 集群启动停止脚本
- zookeeper集群操作脚本操作示例
- 3.2 客户端命令行操作
- 3.2.1 命令行语法
- 启动客户端
- 显示所有操作命令
- 3.2.2 znode 节点数据信息
- 查看当前znode中所包含的内容
- 查看当前节点详细数据
- 3.2.3 节点类型
- 3.2.3.1 持旧/临时/顺序/非顺序
- 3.2.3.2 操作说明
- 1. 分别创建2个普通节点(永久节点 + 不带序号)
- 2. 获得节点的值
- 3. 创建带序号的节点(永久节点 + 带序号)
- 4. 创建短暂节点(短暂节点 + 不带序号 or 带序号)
- 5. 修改节点数据值
- 节点操作示例
- 3.2.4 监听器原理
- 节点的值变化监听
- 示例
- 节点的子节点变化监听
- 示例
- 3.2.5 节点删除与查看
- 3.3 客户端 API 操作
- 3.3.1 IDEA 环境搭建
- 引入依赖
- log4j.properties
- 3.3.2 创建子节点
- 3.3.3 获取子节点并监听节点变化
- 3.3.5 判断 Znode 是否存在
- 3.4 客户端向服务端写数据流程
- 写流程之写入请求直接发送给Leader节点
- 写流程之写入请求发送给follower节点
- 第 4 章 服务器动态上下线监听案例
- 4.1 需求
- 4.2 需求分析
- 4.3 代码
- DistributeClient
- DistributeServer
- 第 5 章 ZooKeeper 分布式锁案例
- 5.1 什么叫做分布式锁呢?
- 5.2 原生zk实现分布式锁案例
- DistributedLock
- DistributedLockTest
- 5.2 Curator 框架实现分布式锁案例
- 使用示例
- 第 6 章 企业面试真题(面试重点)
- 6.1 选举机制
- 6.2 生产集群安装多少 zk 合适?
- 6.3 常用命令
学习
zookeeper官网
curator官网
【尚硅谷】大数据技术之Zookeeper 3.5.7版本教程 - B站视频教程 - 后半句有气无力的
黑马程序员Zookeeper视频教程,快速入门zookeeper技术 - B站视频教程
Zookeeper(从入门到掌握)看完这一篇就够了
分布式锁实现方案-基于zookeeper的分布式锁实现(原理与代码)
zookeeper学习笔记(最全)
第 1 章 Zookeeper 入门
1.1 概述
Zookeeper是一个开源的分布式的,伪分布式框架提供协调服务的Apache项目。ZooKeeper是一个高可用的分布式数据管理和协调框架,并且能够很好的保证分布式环境中数据的一致性。 在越来越多的分布式系统(Hadoop、HBase、Kafka)中,Zookeeper都作为核心组件使用。

Zookeeper工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就 将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应
Zookeeper = 文件系统 + 通知机制

1.2 特点

1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所 以Zookeeper适合安装奇数台服务器。
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
5)数据更新原子性,一次数据更新要么成功,要么失败。
6)实时性,在一定时间范围内,Client能读到最新数据。
1.3 数据结构
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。

1.4 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
1)统一命名管理:对应用/服务进行统一命名,便于识别。
2)统一配置管理:所有节点的配置信息是一致的。配置文件修改后,能快速同步到各个节点上。
3)统一集群管理:实时监控节点变化。
4)服务器动态上下线:客户端能实时洞察到服务器上下线的变化。
5)软负载均衡:Zookeeper中会记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端需求。
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。

统一配置管理
1)分布式环境下,配置文件同步非常常见。
(1)一般要求一个集群中,所有节点的配置信息是一致的,比如 Kafka 集群。
(2)对配置文件修改后,希望能够快速同步到各个节点上。
2)配置管理可交由ZooKeeper实现。
(1)可将配置信息写入ZooKeeper上的一个Znode。
(2)各个客户端服务器监听这个Znode。
(3)一 旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。

统一集群管理
1)分布式环境中,实时掌握每个节点的状态是必要的。
(1)可根据节点实时状态做出一些调整。
2)ZooKeeper可以实现实时监控节点状态变化
(1)可将节点信息写入ZooKeeper上的一个ZNode。
(2)监听这个ZNode可获取它的实时状态变化。

服务器动态上下线
客户端能实时洞察到服务器上下线的变化

软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求

1.5 下载zookeeper
1)官网首页:
https://zookeeper.apache.org/
2)下载截图




第 2 章 Zookeeper 本地安装
2.1 本地模式安装
安装前准备
-
安装 JDK
-
拷贝 apache-zookeeper-3.5.7-bin.tar.gz 安装包到 Linux 系统下
-
解压到指定目录
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/ -
修改名称
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7
配置修改
-
将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg -
打开 zoo.cfg 文件,修改 dataDir 路径:
[atguigu@hadoop102 zookeeper-3.5.7]$ vim zoo.cfg修改如下内容:
dataDir=/opt/module/zookeeper-3.5.7/zkData -
在/opt/module/zookeeper-3.5.7/这个目录上创建 zkData 文件夹
[atguigu@hadoop102 zookeeper-3.5.7]$ mkdir zkData
操作 Zookeeper
-
启动 Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start -
查看进程是否启动
[atguigu@hadoop102 zookeeper-3.5.7]$ jps 4020 Jps 4001 QuorumPeerMain -
查看状态
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Mode: standalone -
启动客户端
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh -
退出客户端
[zk: localhost:2181(CONNECTED) 0] quit -
停止 Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh stop
本地安装zk示例
第一步:解压缩zk,并查看bin目录和conf目录

第二步:创建zkData目录作为zk的数据存储位置,修改zk的配置文件

第三步:启动zk(补充:当启动zk服务器后,使用zkCli连接zk服务时可以使用此命令来指定连接zk服务器的ip:./zkCli.sh -server 119.23.61.24:2181)

2.2 配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
tickTime
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒

initLimit
2)initLimit = 10:LF初始通信时限

Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
syncLimit
3)syncLimit = 5:LF同步通信时限

Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
dataDir
4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
clientPort
5)clientPort = 2181:客户端连接端口,通常不做修改。
第 3 章 Zookeeper 集群操作
3.1 集群操作
3.1.1 集群安装
1、集群规划
在 hadoop102、hadoop103 和 hadoop104 三个节点上都部署 Zookeeper。
2、解压安装
-
在 hadoop102 解压 Zookeeper 安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/ -
修改 apache-zookeeper-3.5.7-bin 名称为 zookeeper-3.5.7
[atguigu@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
3、配置服务器编号
-
在/opt/module/zookeeper-3.5.7/这个目录下创建 zkData
[atguigu@hadoop102 zookeeper-3.5.7]$ mkdir zkData -
在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
[atguigu@hadoop102 zkData]$ vi myid在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
2注意:添加 myid 文件,一定要在 Linux 里面创建,在 notepad++里面很可能乱码
-
拷贝配置好的 zookeeper 到其他机器上
[atguigu@hadoop102 module ]$ xsync zookeeper-3.5.7 并分别在 hadoop103、hadoop104 上修改 myid 文件中内容为 3、4
4、配置zoo.cfg文件
-
重命名/opt/module/zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg -
打开 zoo.cfg 文件
[atguigu@hadoop102 conf]$ vim zoo.cfg修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData增加如下配置
#######################cluster########################## server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 server.4=hadoop104:2888:3888 -
配置参数解读
server.A=B:C:D-
A 是一个数字,表示这个是第几号服务器;
- 集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是
哪个 server。
- 集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是
-
B 是这个
服务器的地址; -
C 是这个服务器
Follower 与集群中的 Leader 服务器交换信息的端口; -
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行
选举时服务器相互通信的端口。
-
-
同步 zoo.cfg 配置文件
[atguigu@hadoop102 conf]$ xsync zoo.cfg
5、集群操作
-
分别启动 Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start -
查看状态
[atguigu@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Mode: follower[atguigu@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Mode: leader[atguigu@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Mode: follower
zookeeper集群操作示例
上传zookeeper压缩包到服务器,并解压到/usr/local/zookeeper-cluster

在/usr/local/zookeeper-cluster/zookeeper-3.4.6创建data文件夹,在文件夹中创建myid文件,并且使用vim写入1

在/usr/local/zookeeper-cluster/zookeeper-3.4.6/conf/ 下的zoo_sample.cfg拷贝一份,名为zoo.cfg文件

修改zoo.cfg配置,注意dataDir下的目录中的zookeeper-1与clientPort的2181

将修改好的zookeeper-3.4.6复制3份,名为zookeeper-1,zookeeper-2,zookeeper-3,需要只需要修改zookeeper-2与zookeeper-3这2个文件夹下的data/myid文件和conf/zoo.cfg配置文件中的端口和数据目录位置

修改zookeeper-2下的data/myid文件和conf/zoo.cfg配置文件中的端口和数据目录位置,同理修改zookeeper-3文件夹下的data/myid文件和conf/zoo.cfg配置文件


在bin所在目录启动zk,会默认在运行目录下产生zookeeper.out日志文件。在全部启动之后,查看zk的状态(注意是全部启动之后,再来查看)

3.1.2 选举机制(面试重点)
第一次启动

-
服务器1启 动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
-
服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
-
服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
-
服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
-
服务器5启动,同4一样当小弟。
非第一次启动

3.1.3 ZK 集群启动停止脚本
1、在 hadoop102 的/home/atguigu/bin 目录下创建脚本
[atguigu@hadoop102 bin]$ vim zk.sh
在脚本中编写如下内容

2、增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x zk.sh
3、Zookeeper 集群启动脚本
[atguigu@hadoop102 module]$ zk.sh start
4、Zookeeper 集群停止脚本
[atguigu@hadoop102 module]$ zk.sh stop
zookeeper集群操作脚本操作示例

3.2 客户端命令行操作
3.2.1 命令行语法
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前 znode 的子节点 [可监听] -w 监听子节点变化 -s 附加次级信息 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path | 获得节点的值 [可监听] -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
启动客户端
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh -server 119.23.61.24:2181
显示所有操作命令
[zk: hadoop102:2181(CONNECTED) 1] help

3.2.2 znode 节点数据信息
查看当前znode中所包含的内容
[zk: 119.23.61.24:2181(CONNECTED) 1] ls /
[zookeeper]
查看当前节点详细数据
[zk: 119.23.61.24:2181(CONNECTED) 2] ls -s /
[zookeeper]cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
-
czxid:创建节点的事务 zxid
每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2之前发生。
-
ctime:znode 被创建的毫秒数(从 1970 年开始)
-
mzxid:znode 最后更新的事务 zxid
-
mtime:znode 最后修改的毫秒数(从 1970 年开始)
-
pZxid:znode 最后更新的子节点 zxid
-
cversion:znode 子节点变化号,znode 子节点修改次数
-
dataversion:znode 数据变化号
-
aclVersion:znode 访问控制列表的变化号
-
ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节点则是 0。
-
dataLength:znode 的数据长度
-
numChildren:znode 子节点数量
3.2.3 节点类型

3.2.3.1 持旧/临时/顺序/非顺序
持久化目录节点
- 客户端与Zookeeper断开连接后,该节点依旧存在
持久化顺序编号目录节点
- 客户端与Zookeeper断开连接后,该节点依旧存在,
- 只是Zookeeper给该节点名称进行顺序编号
临时目录节点
- 客户端与Zookeeper断开连接后,该节点被删除
临时顺序编号目录节点
- 客户端与Zookeeper断开连接后,该节点被删除,
- 只是Zookeeper给该节点名称进行顺序编号。
3.2.3.2 操作说明
1. 分别创建2个普通节点(永久节点 + 不带序号)
[zk: localhost:2181(CONNECTED) 3] create /sanguo "diaochan"
Created /sanguo
[zk: localhost:2181(CONNECTED) 4] create /sanguo/shuguo
"liubei"
Created /sanguo/shuguo
注意:创建节点时,要赋值
2. 获得节点的值
[zk: localhost:2181(CONNECTED) 5] get -s /sanguo
diaochan
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000003
mtime = Wed Aug 29 00:03:23 CST 2018
pZxid = 0x100000004
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 1
[zk: localhost:2181(CONNECTED) 6] get -s /sanguo/shuguo
liubei
cZxid = 0x100000004
ctime = Wed Aug 29 00:04:35 CST 2018
mZxid = 0x100000004
mtime = Wed Aug 29 00:04:35 CST 2018
pZxid = 0x100000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
3. 创建带序号的节点(永久节点 + 带序号)
1、先创建一个普通的根节点/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 1] create /sanguo/weiguo
"caocao"
Created /sanguo/weiguo
2、创建带序号的节点
[zk: localhost:2181(CONNECTED) 2] create -s /sanguo/weiguo/zhangliao "zhangliao"
Created /sanguo/weiguo/zhangliao0000000000
[zk: localhost:2181(CONNECTED) 3] create -s /sanguo/weiguo/zhangliao "zhangliao"
Created /sanguo/weiguo/zhangliao0000000001
[zk: localhost:2181(CONNECTED) 4] create -s /sanguo/weiguo/xuchu "xuchu"
Created /sanguo/weiguo/xuchu0000000002
如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排序时从 2 开始,以此类推。
4. 创建短暂节点(短暂节点 + 不带序号 or 带序号)
1、创建短暂的不带序号的节点
[zk: localhost:2181(CONNECTED) 7] create -e /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo
2、创建短暂的带序号的节点
[zk: localhost:2181(CONNECTED) 2] create -e -s /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo0000000001
3、在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 3] ls /sanguo
[wuguo, wuguo0000000001, shuguo]
4、退出当前客户端然后再重启客户端
[zk: localhost:2181(CONNECTED) 12] quit
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkCli.sh
5、再次查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /sanguo
[shuguo]
5. 修改节点数据值
[zk: localhost:2181(CONNECTED) 6] set /sanguo/weiguo "simayi"
节点操作示例



本地的zkCli命令客户端连接上远程的zookeeper服务端命令:zkCli -server 119.23.61.24:2181,并查看节点


3.2.4 监听器原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节点增加删除)时,ZooKeeper 会通知客户端。
监听机制保证 ZooKeeper 保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序。

节点的值变化监听
1、在 hadoop104 主机上注册监听/sanguo 节点数据变化
[zk: localhost:2181(CONNECTED) 26] get -w /sanguo
2、在 hadoop103 主机上修改/sanguo 节点的数据
[zk: localhost:2181(CONNECTED) 1] set /sanguo "xisi"
3、观察 hadoop104 主机收到数据变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged
path:/sanguo
注意:在hadoop103再多次修改/sanguo的值,hadoop104上不会再收到监听。因为注册一次,只能监听一次。想再次监听,需要再次注册。
示例

节点的子节点变化监听
1、在 hadoop104 主机上注册监听/sanguo 节点的子节点变化
[zk: localhost:2181(CONNECTED) 1] ls -w /sanguo
[shuguo, weiguo]
2、在 hadoop103 主机/sanguo 节点上创建子节点
[zk: localhost:2181(CONNECTED) 2] create /sanguo/jin "simayi"
Created /sanguo/jin
3、观察 hadoop104 主机收到子节点变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged
path:/sanguo
注意:节点的路径变化,也是注册一次,生效一次。想多次生效,就需要多次注册。
示例

(必须是直接子目录才可以监听到哦)
3.2.5 节点删除与查看
1、删除节点
[zk: localhost:2181(CONNECTED) 4] delete /sanguo/jin
2、递归删除节点
[zk: localhost:2181(CONNECTED) 15] deleteall /sanguo/shuguo
3、查看节点状态
[zk: localhost:2181(CONNECTED) 17] stat /sanguo
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000011
mtime = Wed Aug 29 00:21:23 CST 2018
pZxid = 0x100000014
cversion = 9
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 1
3.3 客户端 API 操作
前提:保证 hadoop102、hadoop103、hadoop104 服务器上 Zookeeper 集群服务端启动。
3.3.1 IDEA 环境搭建
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>zookeeper</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>4.3.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>4.3.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-client</artifactId><version>4.3.0</version></dependency></dependencies></project>
log4j.properties
需要在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{H:m:s:SSS} %p [%c] [%t] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
3.3.2 创建子节点
public class ZkClient {private static final Logger log = LoggerFactory.getLogger(ZkClient.class);// 注意:逗号左右不能有空格// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "192.168.134.5:2181";// private String connectString = "119.23.61.24:2181";// 把过期时间设置的长一点, 防止连接超时报错private int sessionTimeout = 100000;private ZooKeeper zkClient;@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {// 只要连接上了zookeeper服务端, 这个监听方法就会执行//(即使下面不创建目录节点,这个监听方法也会在连接上zk后执行)@Overridepublic void process(WatchedEvent watchedEvent) {log.info("【监听】.......{}", watchedEvent);}});}@Testpublic void create() throws KeeperException, InterruptedException {log.info("创建目录节点");// 创建1个持久化的目录节点String nodeCreated = zkClient.create("/atguigu1", "ss.avi".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);log.info("【创建节点成功】{}", nodeCreated);LockSupport.park();}
}
日志输出如下:
19:31:33:068 INFO [com.atguigu.zk.ZkClient] [main] - 创建目录节点
19:31:33:075 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Opening socket connection to server windows10.microdone.cn/192.168.134.5:2181. Will not attempt to authenticate using SASL (unknown error)
19:31:33:076 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Socket connection established, initiating session, client: /192.168.134.5:60131, server: windows10.microdone.cn/192.168.134.5:2181
19:31:33:093 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Session establishment complete on server windows10.microdone.cn/192.168.134.5:2181, sessionid = 0x100026e3b520002, negotiated timeout = 40000
19:31:33:094 INFO [com.atguigu.zk.ZkClient] [main-EventThread] - 【监听】.......WatchedEvent state:SyncConnected type:None path:null
19:31:33:101 INFO [com.atguigu.zk.ZkClient] [main] - 【创建节点成功】/atguigu1
3.3.3 获取子节点并监听节点变化
public class ZkClient {private static final Logger log = LoggerFactory.getLogger(ZkClient.class);// 注意:逗号左右不能有空格// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "192.168.134.5:2181";// private String connectString = "119.23.61.24:2181";private int sessionTimeout = 100000;private ZooKeeper zkClient;@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {/*WatchedEvent#eventType:None NodeCreated NodeDeleted NodeDataChanged NodeChildrenChanged DataWatchRemoved ChildWatchRemoved WatchedEvent#keeperState:UnknownDisconnectedNoSyncConnectedSyncConnectedAuthFailedConnectedReadOnlySaslAuthenticatedExpiredClosedWatchedEvent#path: 字符串类型*/log.info("【监听】.......{}", watchedEvent);}});}@Testpublic void getChildren() throws KeeperException, InterruptedException {log.info("【获取子节点】...");// 1. 获取 / 节点下的子节点, // 2. 如果第二个参数是true, 并且这个方法调用是成功的, 那么就会对给定的节点添加监听, // 这个监听会在这个节点删除或者在这个节点下创建或删除子节点时触发List<String> children = zkClient.getChildren("/", true);for (String child : children) {System.out.println(child);}// 延时LockSupport.park();}
}
启动这个方法后,然后添加2个节点/atguigu2和/atguigu3,发现只有刚开始的一次和添加/atguigu2这2次才触发了监听方法的执行,而添加/atguigu3并未触发监听方法执行(因为1次监听,只能触发1次监听执行)

可观察输出日志如下:
19:35:42:280 INFO [com.atguigu.zk.ZkClient] [main] - 【获取子节点】...
19:35:42:287 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Opening socket connection to server windows10.microdone.cn/192.168.134.5:2181. Will not attempt to authenticate using SASL (unknown error)
19:35:42:288 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Socket connection established, initiating session, client: /192.168.134.5:60218, server: windows10.microdone.cn/192.168.134.5:2181
19:35:42:294 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Session establishment complete on server windows10.microdone.cn/192.168.134.5:2181, sessionid = 0x100026e3b520004, negotiated timeout = 40000
19:35:42:296 INFO [com.atguigu.zk.ZkClient] [main-EventThread] - 【监听】.......WatchedEvent state:SyncConnected type:None path:null
atguigu1
zookeeper
19:36:7:990 INFO [com.atguigu.zk.ZkClient] [main-EventThread] - 【监听】.......WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/
因为客户端开启1次监听,只能触发1次监听回调。而实际我们需要一直监听某个节点,可如下在监听方法中再次开启1次监听,也就是每次监听触发后,再次开启1次监听,就能实现持续监听了:
public class ZkClient {private static final Logger log = LoggerFactory.getLogger(ZkClient.class);// 注意:逗号左右不能有空格// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "192.168.134.5:2181";// private String connectString = "119.23.61.24:2181";private int sessionTimeout = 100000;private ZooKeeper zkClient;@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {log.info("【监听】.......{}", watchedEvent);System.out.println("-------------------------------START");List<String> children = null;try {// 注意防止编译错误, 需要将zkClient提到成员变量位置上去children = zkClient.getChildren("/", true);for (String child : children) {System.out.println(child);}System.out.println("-------------------------------END");} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}});}@Testpublic void getChildren() throws KeeperException, InterruptedException {log.info("【获取子节点】...");// 获取 / 节点下的子节点, 设置watch为true当会触发默认设置的监听器/* List<String> children = zkClient.getChildren("/", true);for (String child : children) {System.out.println(child);}*/// 延时LockSupport.park();}
}
在这里添加/atguigu3,/atguigu4 这2个节点

观察日志输出,可以看到2次添加节点都能够监听到了
19:43:39:261 INFO [com.atguigu.zk.ZkClient] [main] - 【获取子节点】...
19:43:39:268 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Opening socket connection to server windows10.microdone.cn/192.168.134.5:2181. Will not attempt to authenticate using SASL (unknown error)
19:43:39:269 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Socket connection established, initiating session, client: /192.168.134.5:60280, server: windows10.microdone.cn/192.168.134.5:2181
19:43:39:275 INFO [org.apache.zookeeper.ClientCnxn] [main-SendThread(192.168.134.5:2181)] - Session establishment complete on server windows10.microdone.cn/192.168.134.5:2181, sessionid = 0x100026e3b520006, negotiated timeout = 40000
19:43:39:278 INFO [com.atguigu.zk.ZkClient] [main-EventThread] - 【监听】.......WatchedEvent state:SyncConnected type:None path:null
-------------------------------START
atguigu1
zookeeper
atguigu2
atguigu3
-------------------------------END
19:44:5:506 INFO [com.atguigu.zk.ZkClient] [main-EventThread] - 【监听】.......WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/
-------------------------------START
atguigu1
zookeeper
atguigu4
atguigu2
atguigu3
-------------------------------END
19:44:18:013 INFO [com.atguigu.zk.ZkClient] [main-EventThread] - 【监听】.......WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/
-------------------------------START
atguigu1
zookeeper
atguigu4
atguigu5
atguigu2
atguigu3
-------------------------------END
或者最简单的方式如下:
public class Test0 {private static final Logger log = LoggerFactory.getLogger(Test0.class);// 注意zkClient要提取出来放这里, 否则编译有问题private static ZooKeeper zkClient = null;public static void main(String[] args) throws Exception {zkClient = new ZooKeeper("192.168.134.5:2181", 2000, new Watcher() {@Overridepublic void process(WatchedEvent event) {log.info("【监听】...【path】:{}, 【event】:{}", event.getPath(), event);try {// 1. 这个节点必须要存在, 否则会报错// 2. 这里的true, 是监听 / 这个节点删除或者是/下添加子节点或删除子节点时// 触发默认的watcher的回调方法执行zkClient.getChildren("/", true);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}});LockSupport.park();}}
3.3.5 判断 Znode 是否存在
public class ZkClient {private static final Logger log = LoggerFactory.getLogger(ZkClient.class);// 注意:逗号左右不能有空格// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "192.168.134.5:2181";// private String connectString = "119.23.61.24:2181";private int sessionTimeout = 100000;private ZooKeeper zkClient;@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {log.info("【监听】.......{}", watchedEvent);}});}@Testpublic void exist() throws KeeperException, InterruptedException {Stat stat = zkClient.exists("/atguigu", false);System.out.println(stat == null ? "not exist " : "exist");}
}输出如下:
19:49:29:976 INFO [com.atguigu.zk.ZkClient] [main-EventThread] - 【监听】.......WatchedEvent state:SyncConnected type:None path:null
not exist
3.4 客户端向服务端写数据流程
写流程之写入请求直接发送给Leader节点

客户端直接给leader 1个写请求,leader通知其它follower去写,然后follower给leader1个ack应答,当超过半数以上的节点都给了ack应答,那么leader就会给客户端响应写请求成功,这样效率就比较高。
写流程之写入请求发送给follower节点

客户端直接给follower 1个写请求,follower将此写请求转发给leader去写,然后leader通知此follower去写,follower给leader1个ack应答,当超过半数以上的节点都给了ack应答,那么就表示写请求成功,然后leader给follower响应写请求成功,然后由接受请求的follower响应成功给客户端。
第 4 章 服务器动态上下线监听案例
4.1 需求
某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线。
4.2 需求分析

4.3 代码
DistributeClient
public class DistributeClient {private static final Logger log = LoggerFactory.getLogger(DistributeClient.class);// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "192.168.134.5:2181";private int sessionTimeout = 2000;private ZooKeeper zk;public static void main(String[] args) throws Exception {DistributeClient client = new DistributeClient();// 1 获取zk连接client.getConnect();// 2 监听/servers下面子节点的增加和删除// (这一步觉得是多余的, 因为它创建完zk就会主动触发1次监听回调)// client.getServerList();// 3 业务逻辑(睡觉)client.business();}private void business() throws InterruptedException {Thread.sleep(Long.MAX_VALUE);}private void getServerList() throws KeeperException, InterruptedException {List<String> children = zk.getChildren("/servers", true);ArrayList<String> servers = new ArrayList<>();for (String child : children) {log.info("【child】:{}", child);byte[] data = zk.getData("/servers/" + child, false, null);servers.add(new String(data));}// 打印log.info("【ServerList】: {}", Arrays.toString(servers.toArray()));}private void getConnect() throws IOException {zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {try {// 触发下次监听getServerList();} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}});}
}
DistributeServer
public class DistributeServer {private static final Logger log = LoggerFactory.getLogger(DistributeServer.class);// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "192.168.134.5:2181";private int sessionTimeout = 2000;private ZooKeeper zk;public static void main(String[] args) throws Exception{DistributeServer server = new DistributeServer();// 1 获取zk连接server.getConnect();// 2 注册服务器到zk集群server.register(args[0]);// 3 启动业务逻辑(睡觉)server.business();}private void business() throws InterruptedException {Thread.sleep(Long.MAX_VALUE);}private void register(String hostname) throws Exception{// 创建 临时、有序 的节点String create = zk.create("/servers/" + hostname,hostname.getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);log.info("【{}】is online", hostname);}private void getConnect() throws IOException {zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {log.info("【监听】....【path】:{}, 【event】:{}", watchedEvent.getPath(), watchedEvent);}});}
}第 5 章 ZooKeeper 分布式锁案例
5.1 什么叫做分布式锁呢?
比如说"进程 1"在使用该资源的时候,会先去获得锁,"进程 1"获得锁以后会对该资源保持独占,这样其他进程就无法访问该资源,"进程 1"用完该资源以后就将锁释放掉,让其他进程来获得锁,那么通过这个锁机制,我们就能保证了分布式系统中多个进程能够有序的访问该临界资源。那么我们把这个分布式环境下的这个锁叫作分布式锁。

5.2 原生zk实现分布式锁案例
DistributedLock
public class DistributedLock {// private final String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private final String connectString = "192.168.134.5:2181";private final int sessionTimeout = 2000;private final ZooKeeper zk;private CountDownLatch connectLatch = new CountDownLatch(1);private CountDownLatch waitLatch = new CountDownLatch(1);private String waitPath;private String currentMode;public DistributedLock() throws IOException, InterruptedException, KeeperException {// 获取连接zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {// connectLatch 如果连接上zk 可以释放if (watchedEvent.getState() == Event.KeeperState.SyncConnected){connectLatch.countDown();}// waitLatch 需要释放if (watchedEvent.getType()== Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitPath)){waitLatch.countDown();}}});// 等待zk正常连接后,往下走程序connectLatch.await();// 判断根节点/locks是否存在Stat stat = zk.exists("/locks", false);if (stat == null) {// 创建一下根节点zk.create("/locks", "locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}}// 对zk加锁public void zklock() {// 创建对应的临时带序号节点try {currentMode = zk.create("/locks/" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);// wait一小会, 让结果更清晰一些Thread.sleep(10);// 判断创建的节点是否是最小的序号节点,如果是获取到锁;如果不是,监听他序号前一个节点List<String> children = zk.getChildren("/locks", false);// 如果children 只有一个值,那就直接获取锁; 如果有多个节点,需要判断,谁最小if (children.size() == 1) {return;} else {Collections.sort(children);// 获取节点名称 seq-00000000String thisNode = currentMode.substring("/locks/".length());// 通过seq-00000000获取该节点在children集合的位置int index = children.indexOf(thisNode);// 判断if (index == -1) {System.out.println("数据异常");} else if (index == 0) {// 就一个节点,可以获取锁了return;} else {// 需要监听 他前一个节点变化waitPath = "/locks/" + children.get(index - 1);zk.getData(waitPath,true,new Stat());// 等待监听waitLatch.await();return;}}} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}// 解锁public void unZkLock() {// 删除节点try {zk.delete(this.currentMode,-1);} catch (InterruptedException e) {e.printStackTrace();} catch (KeeperException e) {e.printStackTrace();}}}DistributedLockTest
public class DistributedLockTest {public static void main(String[] args) throws InterruptedException, IOException, KeeperException {final DistributedLock lock1 = new DistributedLock();final DistributedLock lock2 = new DistributedLock();new Thread(new Runnable() {@Overridepublic void run() {try {lock1.zklock();System.out.println("线程1 启动,获取到锁");Thread.sleep(5 * 1000);lock1.unZkLock();System.out.println("线程1 释放锁");} catch (InterruptedException e) {e.printStackTrace();}}}).start();new Thread(new Runnable() {@Overridepublic void run() {try {lock2.zklock();System.out.println("线程2 启动,获取到锁");Thread.sleep(5 * 1000);lock2.unZkLock();System.out.println("线程2 释放锁");} catch (InterruptedException e) {e.printStackTrace();}}}).start();}
}
5.2 Curator 框架实现分布式锁案例
1)原生的 Java API 开发存在的问题
(1)会话连接是异步的,需要自己去处理。比如使用 CountDownLatch
(2)Watch 需要重复注册,不然就不能生效
(3)开发的复杂性还是比较高的
(4)不支持多节点删除和创建。需要自己去递归
2)Curator 是一个专门解决分布式锁的框架,解决了原生 JavaAPI 开发分布式遇到的问题。
详情请查看官方文档:https://curator.apache.org/index.html
3)Curator 案例实操
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>zookeeper</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>4.3.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>4.3.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-client</artifactId><version>4.3.0</version></dependency></dependencies></project>使用示例
public class CuratorLockTest {public static void main(String[] args) {// 创建分布式锁1InterProcessMutex lock1 = new InterProcessMutex(getCuratorFramework(),"/locks");// 创建分布式锁2InterProcessMutex lock2 = new InterProcessMutex(getCuratorFramework(), "/locks");new Thread(new Runnable() {@Overridepublic void run() {try {lock1.acquire();System.out.println("线程1 获取到锁");lock1.acquire();System.out.println("线程1 再次获取到锁");Thread.sleep(5 * 1000);lock1.release();System.out.println("线程1 释放锁");lock1.release();System.out.println("线程1 再次释放锁");} catch (Exception e) {e.printStackTrace();}}}).start();new Thread(new Runnable() {@Overridepublic void run() {try {lock2.acquire();System.out.println("线程2 获取到锁");lock2.acquire();System.out.println("线程2 再次获取到锁");Thread.sleep(5 * 1000);lock2.release();System.out.println("线程2 释放锁");lock2.release();System.out.println("线程2 再次释放锁");} catch (Exception e) {e.printStackTrace();}}}).start();}private static CuratorFramework getCuratorFramework() {// 重试策略ExponentialBackoffRetry policy = new ExponentialBackoffRetry(3000, 3);CuratorFramework client = CuratorFrameworkFactory.builder()// .connectString("hadoop102:2181,hadoop103:2181,hadoop104:2181").connectString("192.168.134.5:2181").connectionTimeoutMs(2000).sessionTimeoutMs(2000).retryPolicy(policy).build();// 启动客户端client.start();System.out.println("zookeeper 启动成功");return client;}
}第 6 章 企业面试真题(面试重点)
6.1 选举机制
半数机制,超过半数的投票通过,即通过。
1、第一次启动选举规则:
- 投票过半数时,服务器 id 大的胜出
2、第二次启动选举规则:
-
①EPOCH 大的直接胜出
-
②EPOCH 相同,事务 id 大的胜出
-
③事务 id 相同,服务器 id 大的胜出
6.2 生产集群安装多少 zk 合适?
安装奇数台。
生产经验:
-
10 台服务器:3 台 zk;
-
20 台服务器:5 台 zk;
-
100 台服务器:11 台 zk;
-
200 台服务器:11 台 zk
服务器台数多:好处,提高可靠性;坏处:提高通信延时
6.3 常用命令
ls、get、create、delete
相关文章:
Zookeeper学习
文章目录 学习第 1 章 Zookeeper 入门1.1 概述Zookeeper工作机制 1.2 特点1.3 数据结构1.4 应用场景统一命名服务统一配置管理统一集群管理服务器动态上下线软负载均衡 1.5 下载zookeeper 第 2 章 Zookeeper 本地安装2.1 本地模式安装安装前准备配置修改操作 Zookeeper本地安装…...
FAT32文件系统详细分析 (格式化SD nandSD卡)
FAT32 文件系统详细分析 (格式化 SD nand/SD 卡) 目录 FAT32 文件系统详细分析 (格式化 SD nand/SD 卡)1. 前言2.格式化 SD nand/SD 卡3.FAT32 文件系统分析3.1 保留区分析3.1.1 BPB(BIOS Parameter Block) 及 BS 区分析3.1.2 FSInfo 结构扇区分析3.1.3 引导扇区剩余扇区3.1.4 …...

通义灵码在Visual Studio上
通义灵码在Visual Studio上不好用,有时候会出现重影,不如原生的自动补全好用,原生的毕竟的根据语法来给出提示的。...
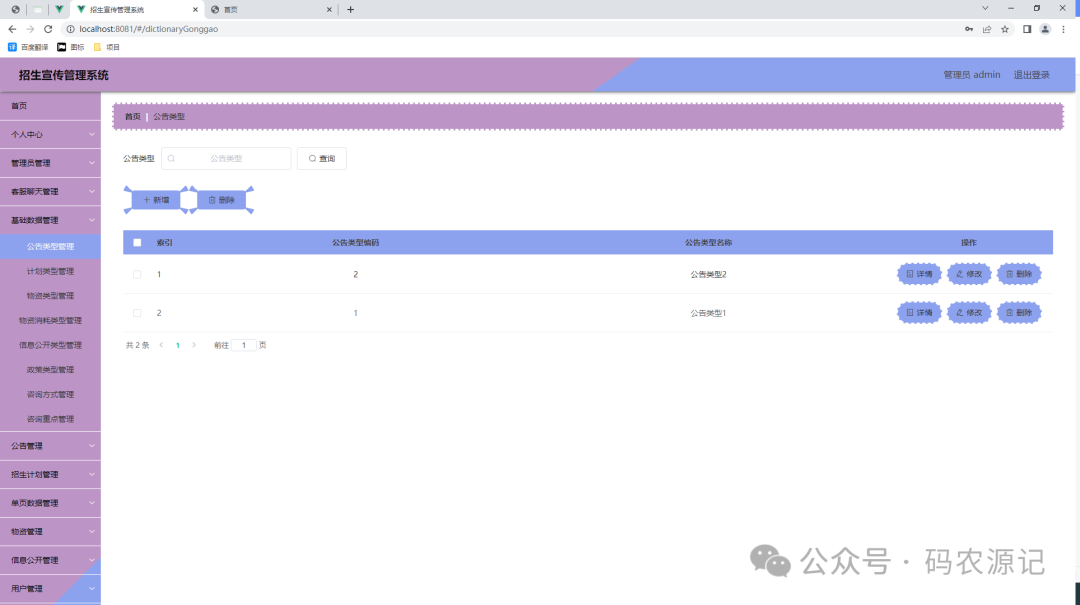
基于SpringBoot的招生宣传管理系统【附源码】
基于SpringBoot的招生宣传管理系统(源码L文说明文档) 目录 4 系统设计 4.1 系统概述 4.2系统功能结构设计 4.3数据库设计 4.3.1数据库E-R图设计 4.3.2 数据库表结构设计 5 系统实现 5.1管理员功能介绍 5.1.1管理员登录 …...

SOT23封装1A电流LDO具有使能功能的 1A、低 IQ、高精度、低压降稳压器系列TLV757P
前言 SOT23-5封装的外形和丝印 该LDO适合PCB空间较小的场合使用,多数SOT23封装的 LDO输出电流不超过0.5A。建议使用时输入串联二极管1N4001,PCB布局需要考虑散热,参考文末PCB布局。 1 特性 • 采用 SOT-23 (DYD) 封装,具有 60.3C/W RθJA •…...

python绘制3d建筑
import matplotlib.pyplot as plt import numpy as np from mpl_toolkits.mplot3d.art3d import Poly3DCollection# 随机生成建筑块数据 def generate_building_blocks(num_blocks, grid_size100, height_range(5, 50), base_size_range(10, 30)):buildings []for _ in range(…...

机器学习实战21-基于XGBoost算法实现糖尿病数据集的分类预测模型及应用
大家好,我是微学AI,今天给大家介绍一下机器学习实战21-基于XGBoost算法实现糖尿病数据集的分类预测模型及应用。首先阐述了 XGBoost 算法的数学原理及公式,为模型构建提供理论基础。接着利用 kaggle 平台的糖尿病数据集,通过详细的…...

ElasticSearch数据类型和分词器
一、数据类型 1、Text (文本数据类型) 2、Keyword(关键字数据类型) 3、Alias(别名类型) 4、Arrays (集合类型) 5、Boolean(布尔类型) 6、日期类型 7、Numeric (数…...

【云原生监控】Prometheus之PushGateway
Prometheus之PushGateway 文章目录 Prometheus之PushGateway介绍作用资源列表基础环境一、部署PushGateway1.1、下载软件包1.2、解压软件包1.3、编辑配置systemctl启动文件1.4、创建日志目录1.5、加载并启动1.6、监控端口1.7、访问PushGateway 二、 配置Prometheus抓取PushGate…...

sqlalchemy JSON 字段写入时中文序列化问题
JSON字段定义 from sqlalchemy import Column, JSONclass Table(Base):__tablename__ "table"__table_args__ ({"comment": "表名称"})...extra Column(JSON, comment"其他属性")...局部序列化 def create(extra):table Table()#…...
C++ 类域+类的对象大小
个人主页:Jason_from_China-CSDN博客 所属栏目:C系统性学习_Jason_from_China的博客-CSDN博客 所属栏目:C知识点的补充_Jason_from_China的博客-CSDN博客 概念概述 类定义了一个新的作用域,类的所有成员都在类的作用域中ÿ…...

QT开发:深入详解QtCore模块事件处理,一文学懂QT 事件循环与处理机制
Qt 是一个跨平台的 C 应用程序框架,QtCore 模块提供了核心的非 GUI 功能。事件处理是 Qt 应用程序的重要组成部分。Qt 的事件处理机制包括事件循环和事件处理,它们共同确保应用程序能够响应用户输入、定时器事件和其他事件。 1. 事件循环(Ev…...
小米,B站网络安全岗位笔试题目+答案
《网安面试指南》http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247484339&idx1&sn356300f169de74e7a778b04bfbbbd0ab&chksmc0e47aeff793f3f9a5f7abcfa57695e8944e52bca2de2c7a3eb1aecb3c1e6b9cb6abe509d51f&scene21#wechat_redirect 《Java代码审…...

微信小程序中巧妙使用 wx:if 和 catchtouchmove 实现弹窗禁止页面滑动功能
大家好,今天我要和大家分享的是在微信小程序开发过程中,如何利用 wx:if 或 wx:elif 来条件性地渲染不同的元素,并结合 catchtouchmove 事件处理函数来解决弹窗弹出时禁止背后页面滑动,而弹窗消失时恢复滑动的功能。 在微信小程序…...

唯徳知识产权管理系统 DownloadFileWordTemplate 文件读取漏洞复现
0x01 产品简介 唯徳知识产权管理系统,由深圳市唯德科创信息有限公司精心打造,旨在为企业及代理机构提供全方位、高效、安全的知识产权管理解决方案。该系统集成了专利、商标、版权等知识产权的全面管理功能,并通过云平台实现远程在线办公,提升工作效率。是一款集知识产权申…...

我在高职教STM32——准备HAL库工程模板(2)
新学期已开始,又要给学生上 STM32 嵌入式课程了。这课上了多年了,一直用的都是标准库来开发,已经驾轻就熟了。人就是这样,有了自己熟悉的舒适圈,就很难做出改变,老师上课也是如此,排斥新课和不熟悉的内容。显然,STM32 的开发,HAL 库已是主流,自己其实也在使用,只不过…...
数字化转型的实战法则:全面剖析《数字化专业知识体系》中的落地策略与最佳实践
开启数字化成功的实践路径 随着全球经济加速迈向数字化,企业不再仅仅依赖传统商业模式,而是通过技术创新提升竞争力与市场地位。然而,数字化转型的成功不仅依赖于战略思维,更需要精准的实战执行。《数字化专业知识体系》…...

远程桌面内网穿透是什么?有什么作用?
远程桌面内网穿透指的是通过特定技术手段,将处于内网中的电脑或服务器,通过外部网络(互联网)进行访问。内网穿透的主要作用是解决在内网环境下,远程设备与外部互联网之间的连接问题,允许用户从外部访问内网…...

【算法专场】分治(上)
目录 前言 什么是分治? 75. 颜色分类 算法分析 算法步骤 算法代码 912. 排序数组 - 力扣(LeetCode) 算法分析 算法步骤 算法代码 215. 数组中的第K个最大元素 - 力扣(LeetCode) 算法分析 算法步骤 编辑…...

腾讯云软件工程师面试问题收集记录-数据库
SQL是什么:结构化查询语言,是一种专门用于管理关系型数据库管理系统的编程语言 MySQL操作命令 数据库操作 登陆数据库:mysql -u 用户面 -p创建数据库:CREATE DATABASE testdb; SQLite操作命令 数据库操作 创建数据库:…...

DAMO-YOLO多模态实践:视觉+文本联合分析系统
DAMO-YOLO多模态实践:视觉文本联合分析系统 你有没有遇到过这样的情况?一个智能摄像头能认出画面里是“一辆车”,但它不知道这是“一辆正在送货的快递车”。或者,一个内容审核系统能识别出图片里有“文字”,却无法判断…...

BERT文本分割模型5分钟快速部署:零基础搭建智能分段工具
BERT文本分割模型5分钟快速部署:零基础搭建智能分段工具 1. 引言:告别文字“墙”,让长文本秒变清晰段落 你有没有过这样的经历?辛辛苦苦听完一场两小时的线上会议,语音转文字工具生成了一份上万字的逐字稿。你满怀期…...

无需编程经验!OFA图像描述工具开箱即用,支持本地离线运行
无需编程经验!OFA图像描述工具开箱即用,支持本地离线运行 1. 前言:为什么选择本地图像描述工具 想象一下这些场景: 你在整理旅行照片时,想快速为每张图添加英文描述工作中需要批量处理商品图片,但担心上…...

OpenClaw性能调优:Qwen3-14B镜像任务吞吐量提升300%实战
OpenClaw性能调优:Qwen3-14B镜像任务吞吐量提升300%实战 1. 问题背景与挑战 去年在尝试用OpenClaw对接本地部署的Qwen3-14B模型时,我发现一个尴尬的现象:当处理批量文件整理任务时,系统平均响应时间会从单任务的3秒暴增到20秒以…...

Legcord:革命性Discord轻量级客户端,10大特性全面解析
Legcord:革命性Discord轻量级客户端,10大特性全面解析 【免费下载链接】ArmCord Legcord is a custom client designed to enhance your Discord experience while keeping everything lightweight. 项目地址: https://gitcode.com/gh_mirrors/ar/ArmC…...
推出磁感应交互方案)
乐鑫联合 Bosch Sensortec(博世传感器)推出磁感应交互方案
在 AI 玩具与智能硬件的设计中,如何在有限的空间与成本条件下,实现稳定且顺畅的配件交互,正成为产品创新的重要课题。 乐鑫信息科技 (688018.SH) 携手 Bosch Sensortec(博世传感器)推出了一种更轻量、更可靠的解决思路…...

工业质检新思路:当UNet遇上钢材缺陷,聊聊PyTorch实战中的那些‘坑’与优化技巧
工业质检实战:UNet在钢材缺陷检测中的高阶优化与避坑指南 第一次把UNet模型部署到钢厂产线时,我盯着监控屏幕上闪烁的误报提示,意识到学术论文里的漂亮指标和真实工业场景之间,隔着无数个深夜调试的神经网络。钢材表面那些细如发丝…...

别光调包了!在EduCoder上通关‘卷积神经网络实现’后,我搞懂了im2col加速的奥秘
从EduCoder实战到工业级优化:im2col如何让卷积计算快10倍 在EduCoder平台完成"卷积神经网络实现"实验时,很多同学会疑惑:为什么提供的代码模板里要用im2col这个看似复杂的函数?直接写四重循环实现卷积不是更直观吗&…...

搞电机控制的兄弟应该都懂,无感算法里磁链观测器+PLL锁相环的组合有多香。今天直接上干货,聊聊非线性磁链观测器的实现套路和实操中那些让你少掉几根头发的技巧
永磁同步电机非线性磁链无感算法、Flux观测器锁相环PLL仿真模型 flux:计算电机磁链,目的为了使得估计的磁链收敛于实际磁链; pll:通过估计磁链计算经过pi调节后使得估计角度跟踪实际角度 模型描述及资料: (…...

串扰是怎么来的?相邻层走线方向比间距更重要
摘要:在高速PCB设计中,串扰是导致信号完整性问题的主要原因之一。许多工程师过于关注走线间距(3W规则),却忽视了相邻层走线方向的影响。本文将从物理机制出发,解释为什么相邻层走线方向正交(垂直…...