【深度学习|PyTorch】基于 PyTorch 搭建 U-Net 深度学习语义分割模型——附代码及其解释!
【深度学习|PyTorch】基于 PyTorch 搭建 U-Net 深度学习语义分割模型——附代码及其解释!
【深度学习|PyTorch】基于 PyTorch 搭建 U-Net 深度学习语义分割模型——附代码及其解释!
论文地址: https://arxiv.org/abs/1505.04597
代码地址:https://github.com/jakeret/tf_unet
文章目录
- 【深度学习|PyTorch】基于 PyTorch 搭建 U-Net 深度学习语义分割模型——附代码及其解释!
- 1.数据准备
- 2.模型搭建:U-Net
- 3.模型训练
- 4.模型评估
- 总结
1.数据准备
语义分割任务的输入通常是图像以及对应的像素级标签(即每个像素的分类)。我们首先需要加载和预处理数据。
import torch
from torch.utils.data import DataLoader, Dataset
import torchvision.transforms as transforms
from PIL import Image
import osclass SegmentationDataset(Dataset):def __init__(self, image_dir, mask_dir, transform=None):self.image_dir = image_dirself.mask_dir = mask_dirself.transform = transformself.images = os.listdir(image_dir)def __len__(self):return len(self.images)def __getitem__(self, index):img_path = os.path.join(self.image_dir, self.images[index])mask_path = os.path.join(self.mask_dir, self.images[index])image = Image.open(img_path).convert("RGB")mask = Image.open(mask_path).convert("L") # Assuming masks are grayscaleif self.transform is not None:image = self.transform(image)mask = self.transform(mask)return image, mask# 数据加载及预处理
image_dir = "path_to_images"
mask_dir = "path_to_masks"transform = transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor(),
])dataset = SegmentationDataset(image_dir, mask_dir, transform)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
代码解释:
SegmentationDataset:自定义的数据集类,负责读取图像和对应的掩码文件(标签)。__getitem__方法:从文件夹中加载图像和对应的掩码,并进行相应的预处理。transforms:使用 torchvision 中的transforms对图像进行调整(例如,缩放和转换为 Tensor)。
2.模型搭建:U-Net
U-Net 是一种常用于医学图像分割的卷积神经网络。其结构包括下采样路径(编码器)和上采样路径(解码器),并在同一层级将特征图通过跳跃连接传递。
import torch.nn as nn
import torchclass UNet(nn.Module):def __init__(self, in_channels=3, out_channels=1):super(UNet, self).__init__()# Contracting path (Encoder)self.enc_conv1 = self.double_conv(in_channels, 64)self.enc_conv2 = self.double_conv(64, 128)self.enc_conv3 = self.double_conv(128, 256)self.enc_conv4 = self.double_conv(256, 512)# Maxpooling layerself.pool = nn.MaxPool2d(kernel_size=2, stride=2)# Expansive path (Decoder)self.up_conv3 = self.up_conv(512, 256)self.dec_conv3 = self.double_conv(512, 256)self.up_conv2 = self.up_conv(256, 128)self.dec_conv2 = self.double_conv(256, 128)self.up_conv1 = self.up_conv(128, 64)self.dec_conv1 = self.double_conv(128, 64)# Final output layerself.final_conv = nn.Conv2d(64, out_channels, kernel_size=1)def double_conv(self, in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),nn.ReLU(inplace=True))def up_conv(self, in_channels, out_channels):return nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)def forward(self, x):# Encoderenc1 = self.enc_conv1(x)enc2 = self.enc_conv2(self.pool(enc1))enc3 = self.enc_conv3(self.pool(enc2))enc4 = self.enc_conv4(self.pool(enc3))# Decoderdec3 = self.up_conv3(enc4)dec3 = torch.cat((dec3, enc3), dim=1)dec3 = self.dec_conv3(dec3)dec2 = self.up_conv2(dec3)dec2 = torch.cat((dec2, enc2), dim=1)dec2 = self.dec_conv2(dec2)dec1 = self.up_conv1(dec2)dec1 = torch.cat((dec1, enc1), dim=1)dec1 = self.dec_conv1(dec1)# Outputreturn self.final_conv(dec1)# 实例化模型
model = UNet(in_channels=3, out_channels=1).to('cuda' if torch.cuda.is_available() else 'cpu')
代码解释:
double_conv:U-Net 结构中每层包含两个卷积层,卷积核大小为3,使用 ReLU 激活函数。up_conv:用于上采样的转置卷积层。forward:定义了模型的前向传播路径,使用了 U-Net 的跳跃连接,保证上采样时能够使用对应层级的特征图。
3.模型训练
训练模型需要定义损失函数和优化器。我们通常使用交叉熵损失或者 Dice 损失进行语义分割任务。
import torch.optim as optim
import torch.nn.functional as F# 损失函数和优化器
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)# 训练循环
num_epochs = 20
device = 'cuda' if torch.cuda.is_available() else 'cpu'for epoch in range(num_epochs):model.train()running_loss = 0.0for images, masks in dataloader:images = images.to(device)masks = masks.to(device)# Forward passoutputs = model(images)loss = criterion(outputs, masks)# Backward pass and optimizationoptimizer.zero_grad()loss.backward()optimizer.step()running_loss += loss.item()print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(dataloader)}")
代码解释:
criterion:使用二元交叉熵损失(BCEWithLogitsLoss)处理二分类分割任务。对于多类分割,可使用CrossEntropyLoss。optimizer:Adam 优化器,学习率设为 1e-4。- 训练循环:每个 epoch 中,模型进行前向传播、计算损失、反向传播并更新权重。
4.模型评估
为了评估模型性能,可以使用常见的分割指标如 IoU(交并比)或 Dice 系数。
def dice_coefficient(preds, labels, threshold=0.5):preds = torch.sigmoid(preds) # Apply sigmoid to get probabilitiespreds = (preds > threshold).float() # Threshold predictionsintersection = (preds * labels).sum()union = preds.sum() + labels.sum()dice = 2 * intersection / (union + 1e-8) # Add small epsilon to avoid division by zeroreturn dice# 在训练完成后,评估模型
model.eval()
with torch.no_grad():dice_score = 0.0for images, masks in dataloader:images = images.to(device)masks = masks.to(device)outputs = model(images)dice_score += dice_coefficient(outputs, masks)dice_score /= len(dataloader)print(f"Dice Coefficient: {dice_score}")
代码解释:
dice_coefficient:计算 Dice 系数,衡量预测和真实标签的重合程度,值越接近 1 表示预测效果越好。- 评估模型时使用
model.eval()关闭 dropout 等不影响推理过程的操作,并使用torch.no_grad()以节省内存。
总结
以上是从数据准备、模型搭建、训练到精度评估的完整流程。我们基于 PyTorch 实现了一个 U-Net 语义分割模型,并详解了每步的代码。
相关文章:

【深度学习|PyTorch】基于 PyTorch 搭建 U-Net 深度学习语义分割模型——附代码及其解释!
【深度学习|PyTorch】基于 PyTorch 搭建 U-Net 深度学习语义分割模型——附代码及其解释! 【深度学习|PyTorch】基于 PyTorch 搭建 U-Net 深度学习语义分割模型——附代码及其解释! 论文地址: https://arxiv.org/abs/1505.04597 代码地址&a…...

DPDK基础入门(十):虚拟化
I/O虚拟化 全虚拟化:宿主机截获客户机对I/O设备的访问请求,然后通过软件模拟真实的硬件。这种方式对客户机而言非常透明,无需考虑底层硬件的情况,不需要修改操作系统。 半虚拟化:通过前端驱动/后端驱动模拟实现I/O虚拟…...

OpenCV_图像旋转超详细讲解
图像转置 transpose(src, dst); transpose()可以实现像素下标的x和y轴坐标进行对调:dst(i,j)src(j,i),接口形式 transpose(InputArray src, // 输入图像OutputArray dst, // 输出 ) 图像翻转 flip(src, dst, 1); flip()函数可以实现对图像的水平翻转…...

关于 OceanBase 4.x 中被truncate的 table 不再支持进回收站的原因
近期,OceanBase的问答社区中收到了不少用户的询问,关于OceanBase 3.x版本支持被truncate的table进入回收站的功能,为何在升级到4.x版本后不再支持了?为了解答大家的疑惑,我们将通过这篇文章来浅析 OceanBase在4.x版本中…...
)
Numpy索引详解(数值索引,列表索引,布尔索引)
数值索引 数值索引类似列表索引操作使用[],参数为下标,[0,len-1),高维数组的索引使用多个[]连用分别代表一维索引,二维索引... import numpy as np import torchnp.random.seed(1) data1 np.arange(5) data2 np.arange(15).reshape(3,5) …...

大数据新视界 --大数据大厂之MongoDB与大数据:灵活文档数据库的应用场景
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...
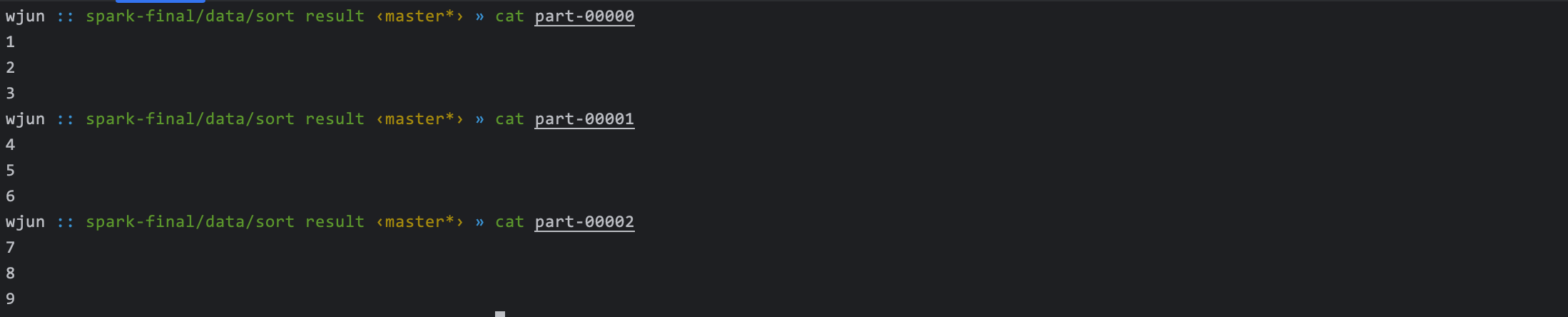
三年 Sparker 都不一定知道的算子内幕
一、如何在 mapPartitions 中释放资源 mapPartitions是一种对每个分区进行操作的转换操作,于常用的map操作类似,但它处理的是整个分区而不是单个元素。mapPartitions的应用场景适合处理需要在每个分区内批量处理数据的场景,通常用于优化性能…...

PG表空间
目录标题 PG表空间PostgreSQL表空间的最佳实践是什么?如何在PostgreSQL中创建和管理自定义表空间?PostgreSQL表空间对数据库性能的具体影响有哪些?在PostgreSQL中,如何迁移数据到不同的表空间以优化存储布局?PostgreSQ…...

谷粒商城のElasticsearch
文章目录 前言一、前置知识1、Elasticsearch 的结构2、倒排索引 (Inverted Index)2.1、 索引阶段2.2、查询阶段 二、环境准备1、安装Es2、安装Kibana3、安装 ik 分词器 三、项目整合1、引入依赖2、整合业务2.1、创建索引、文档、构建查询语句2.2、整合业务代码 后记 前言 本篇介…...

排队免单模式小程序开发
开发一个排队免单模式的小程序涉及多个方面,包括需求分析、界面设计、后端开发、数据库设计以及测试上线等。下面我将详细介绍每个步骤的概要: 1.需求分析 明确目标:首先确定小程序的核心功能,即排队免单模式的具体实现方式。例如…...

从OracleCloudWorld和财报看Oracle的转变
2024年9月9-12日Oracle Cloud World在美国拉斯维加斯盛大开幕 押注AI和云 Oracle 创始人Larry Ellison做了对Oracle战略和未来愿景的主旨演讲,在演讲中Larry将AI技术和云战略推到了前所未有的高度,从新的Oracle 23c改名到Oracle23ai,到Oracl…...

搭建 PHP
快速搭建 PHP 环境指南 PHP 是一种广泛用于 Web 开发的后端脚本语言,因其灵活性和易用性而受到开发者的青睐。无论是开发个人项目还是企业级应用,PHP 环境的搭建都是一个不可忽视的基础步骤。本指南将带您快速学习如何在不同平台上搭建 PHP 环境&#x…...

kubernetes技术详解,带你深入了解k8s
目录 一、Kubernetes简介 1.1 容器编排应用 1.2 Kubernetes简介 1.3 k8s的设计架构 1.3.1 k8s各个组件的用途 1.3.2 k8s各组件之间的调用关系 1.3.3 k8s的常用名词概念 1.3.4 k8s的分层结构 二、k8s集群环境搭建 2.1 k8s中容器的管理方式 2.2 k8s环境部署 2.2.1 禁用…...

Gateway学习笔记
目录 介绍: 核心概念 依赖 路由 断言 基本的断言工厂 自定义断言 过滤器 路由过滤器 过滤器工厂 自定义路由过滤器 全局过滤器 其他 过滤器执行顺序 前置后置(?) 跨域问题 yaml 解决 配置类解决 介绍&#x…...

创造增强叙事的互动:Allison Crank的沉浸式体验设计理念
在沉浸式技术日新月异的今天,如何通过用户交互增强叙事,而非分散注意力,成为了设计师们共同面临的挑战。作为用户体验设计师和研究员,Allison Crank以其独特的视角和丰富的经验,为我们揭示了这一领域的核心原则与实践方法。 叙事与互动的和谐共生 Allison Crank强调,互…...

Requests-HTML模块怎样安装和使用?
要安装和使用Requests-HTML模块,您可以按照以下步骤进行操作: 打开命令行界面(如Windows的命令提示符或Mac的终端)。 使用pip命令安装Requests-HTML模块。在命令行中输入以下命令并按回车键执行: pip install request…...

[网络]从零开始的计算机网络基础知识讲解
一、本次教程的目的 本次教程我只会带大叫了解网络的基础知识,了解网络请求的基本原理,为后面文章中可能会用到网络知识做铺垫。本次我们只会接触到网络相关的应用层,并不涉及协议的具体实现和数据转发的规则。也就是说,这篇教程是…...

wifiip地址可以随便改吗?wifi的ip地址怎么改变
对于普通用户来说,WiFi IP地址的管理和修改往往显得神秘而复杂。本文旨在深入探讨WiFi IP地址是否可以随意更改,以及如何正确地改变WiFi的IP地址。虎观代理小二将详细解释WiFi IP地址的基本概念、作用以及更改时需要注意的事项,帮助用户更好地…...

黑马十天精通MySQL知识点
一. MySQL概述 安装使用 MySQL安装完成之后,在系统启动时,会自动启动MySQL服务,无需手动启动。 也可以手动的通过指令启动停止,以管理员身份运行cmd,进入命令行执行如下指令: 1 、 net start mysql80…...

如何在 Vue 3 + Element Plus 项目中实现动态设置主题色以及深色模式切换
🔥 个人主页:空白诗 文章目录 一、引言二、项目依赖和环境配置1. VueUse2. use-element-plus-theme3. 安装依赖 三、实现深色模式切换1. 设置深色模式状态2. 模板中的深色模式切换按钮3. 深色模式的效果展示 四、动态切换主题色五、总结 一、引言 在现代…...

系统盘空间释放之-Gradle 的默认缓存迁移
最近开发过程中磁盘空间频繁报红,解决一下这两个缓存吧。(以我的电脑为例)一、先明确:这个文件夹是什么?C:\Users\lt\.gradle(1.16GB)作用:Gradle 全局缓存目录,存储所有…...

Unity3D LED点阵屏幕模拟
基于 Unity3D 引擎开发的 LED 点阵屏幕模拟项目,可通过浏览器直接向程序发送 HTTP 指令,实现中英文、数字及各类标点符号的动态显示。系统支持灵活调整点阵规模与显示颜色,并具备超长文本自动循环滚动等功能,满足多样化展示需求。…...

春和景明聚知己 嬴氏酒香醉春光
春风送暖,万物复苏,山野间绿意蔓延,枝头繁花盛放,正是一年中踏春赏景、邀约好友共赴自然的绝佳时节。褪去日常的忙碌与疲惫,邀三五知己,寻一处清幽草地,伴青山绿水、鸟语花香,围坐一…...

本科论文AI率高不高影响答辩?这个问题要搞清楚
很多同学AI率超标之后第一个问题就是:这会不会影响我参加答辩? 这个问题的答案取决于你的学校是怎么规定的,也和你超标的程度有关。我来帮你分析清楚。 各高校对AI率的处理方式 目前各高校的处理方式大致分三类: 第一类&#…...

2026经管大洗牌!只会记账/理论已死,再不考这10个证,迟早被AI取代!
2026经管行业变革与核心证书指南随着AI技术的快速发展,传统经管岗位面临巨大挑战。单纯掌握记账或理论知识的从业者可能面临淘汰风险。以下为未来五年内最具价值的10项认证,帮助从业者保持竞争力。CDA数据分析师证书的核心优势CDA数据分析师证书由国际数…...

终极指南:使用android-advancedrecyclerview实现状态保存的拖拽列表
终极指南:使用android-advancedrecyclerview实现状态保存的拖拽列表 【免费下载链接】android-advancedrecyclerview RecyclerView extension library which provides advanced features. (ex. Googles Inbox app like swiping, Play Music app like drag and drop …...

考研408计算机学科专业基础综合——计算机网络复习
考研408计算机学科专业基础综合 计算机网络复习 核心说明:本笔记聚焦考研408计算机网络高频考点、必背知识点,贴合命题规律(选择题为主、大题集中在核心协议),剔除冗余内容,突出重难点,适配冲刺…...

快速启动Tensorboard并解决本地端口访问问题的实战指南
1. Tensorboard快速启动指南 Tensorboard是TensorFlow生态中不可或缺的可视化工具,它能直观展示模型训练过程中的损失曲线、准确率、计算图等重要信息。但很多新手在第一次使用时,常常卡在启动后无法访问的环节。这里分享我调试过上百个模型总结出的启动…...
)
别再手动改IP了!用NI-USRP Configuration Utility快速配置USRP-2954与LabVIEW通信(附避坑指南)
告别手动配置:NI-USRP Configuration Utility高效连接USRP-2954与LabVIEW全攻略 当第一次将USRP-2954设备连接到电脑时,许多工程师都会遇到一个看似简单却令人头疼的问题——IP配置。设备明明已经通过网线连接,但在LabVIEW中却始终无法识别&…...

LIF蛋白的结构特征与生物学功能研究
一、LIF蛋白的分子结构与分类白血病抑制因子属于IL-6细胞因子家族,是一种多功能的糖蛋白。该蛋白由180个氨基酸残基组成,分子量约为20至25千道尔顿,包含七个α-螺旋结构域,形成典型的上束螺旋结构。LIF蛋白的基因定位于22号染色体…...