三年 Sparker 都不一定知道的算子内幕
一、如何在 mapPartitions 中释放资源
mapPartitions是一种对每个分区进行操作的转换操作,于常用的map操作类似,但它处理的是整个分区而不是单个元素。mapPartitions的应用场景适合处理需要在每个分区内批量处理数据的场景,通常用于优化性能和减少计算开销。例如:减少数据库连接、网络连接等。即然涉及到资源的初始化那么必定伴随着资源的释放,这是本节讨论的重点。
以和 mysql 中数据交互为例,下面是一段伪代码
rdd.mapPartitions(iter => {// 初始化数据库连接lazy val connection = initConnection(args)// 迭代数据val result = iter.map(... /*处理逻辑会使用到 connection 对象*/)// 在返回结果之前需要释放资源connection.close()// 返回处理结果result
})
上面的代码在运行阶段之前都是没有问题的(可编译、可打包),不存在语法问题。但是在运行时会报No operations allowed after connection closed,直接分析报错原因是在 map 中使用 connection 获取数据时该连接已经被关闭,直观的感觉是close方法在map之前被调用,真正的原因是什么呢?
众所周知 spark 在调用行动算子之前是不会执行上游算子中的逻辑,在观察 spark rdd 算子链之间传递的对象是 scala 的迭代器,而 scala 的迭代器具有lazy特性的不如 spark 的lazy特性被人“广为流传”
package fun.uhope.practiseobject P2 {def main(args: Array[String]): Unit = {List(1, 2, 3, 4, 5).toIterator.map(x => {println("map被调用了")x})}
}
上面的代码执行后没有任务输出,因为 scala 的迭代器也需要行动算子去触发计算。那么mapPartitions代码的报错原因显然是iter.map(...)只是返回了一个迭代器对象,内部逻辑并没有被执行,随后下一行代码关闭了数据库连接,当 rdd 在后续调用了行动算子其内部也会去触发这个迭代器对象执行对应的内部逻辑,此时数据库连接才会被使用但这个连接早就被关闭了。
对症下药!!!需要在数据库连接关闭之前执行完map逻辑
方案一:强制触发迭代器计算(不推荐)
将迭代器转换为 scala 的集合类型,代码如下
rdd.mapPartitions(iter => {// 初始化数据库连接lazy val connection = initConnection(args)// 迭代数据val result = iter.map(... /*处理逻辑会使用到 connection 对象*/).toList// 在返回结果之前需要释放资源connection.close()// 返回处理结果result.toIterator
})
toList会强制执行迭代器的逻辑,但后果是迭代器中映射的数据会被全部存储在内存中,如果分区的数据过大调用toList可能会发生 OOM。需要慎用
方案二:重写迭代器(推荐)
mapPartitions需要返回一个迭代器,如果这个迭代器可以实现在初始化的时候获取资源连接,在迭代完最后一个元素时释放资源即可。下面是自定义迭代器实现方式
rdd.mapPartitions(iter => {new Iterator[String]{// 初始化数据库连接lazy val connection = initConnection(args)// 判断迭代器是否还有元素override def hasNext: Boolean = {val hasNext = iter.hasNextif (!hasNext) {// 释放资源connection.close()}hasNext}// 获取迭代器元素override def next(): String = {val line = iter.next()... /*处理逻辑会使用到 connection 对象*/}}
})
该方法即保留了迭代器按需摄取数据的能力又实现了资源的及时释放
二、reduceByKey vs groupByKey
word count 入门案例如下
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).foreach(println)
同时按照 sql 的实现逻辑还可以这么写
rdd.flatMap(_.split(" ")).map((_, 1)).groupByKey().mapValues(_.sum).foreach(println)
虽然groupByKey可以实现相同的结果,但效率较低,因为它会将所有相同key的值拉到一起,可能导致较大的网络传输开销和内存消耗。而reduceByKey默认实现了map端预聚合
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
三、 是全局有序吗
众所周知大数据场景下的全局排序是极其消耗资源的,hive 在执行 order by 时会将全部的数据 shuffle 到一个 reduce 节点上进行排序。spark 也提供了 rdd 的排序算子那么是全局有序还是分区有序?
sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9), numSlices = 3).sortBy(x => x).saveAsTextFile("data/sort result")
rdd的分区数是 3 排序后将结果写入本地文件(3 个)依次查看文件数据
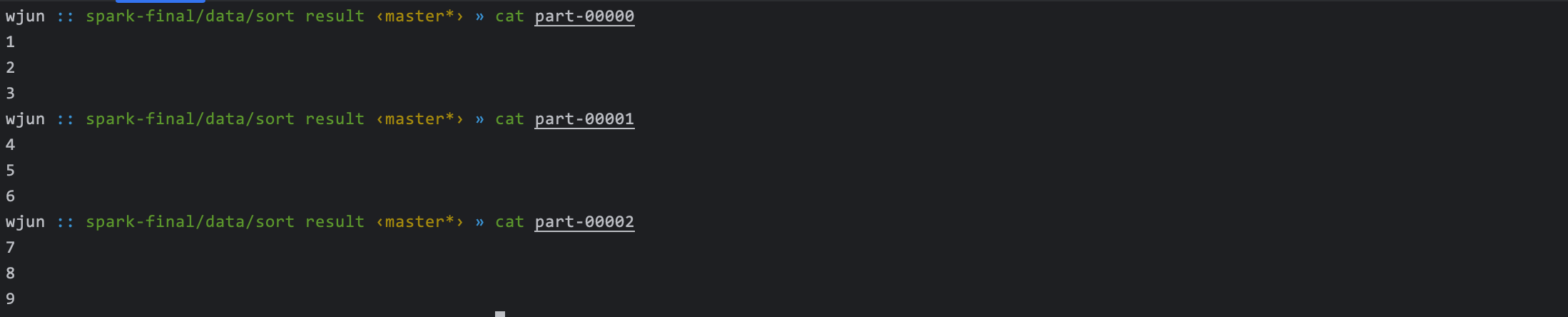
可以看出sortBy居然实现了全局有序,下面一探究竟 spark 是如何在大数据集下进行全局排序。
def sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {this.keyBy[K](f).sortByKey(ascending, numPartitions).values
}def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)] = self.withScope
{val part = new RangePartitioner(numPartitions, self, ascending)new ShuffledRDD[K, V, V](self, part).setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
从调用链来看关键是使用了RangePartitioner分区器,是一种基于范围的分区器。通过随机采样的方式近似估计分区键的分布情况结合分区数(假定为 n)将 rdd 的数据分为 n 段,随后在每个分区中进行局部排序。因为是基于范围的分区,分区之间本身就具备顺序性当每个分区的局部排序完成之后全局排序便自动完成。
四、多种 rePartition
spark 中提供两种方法进行重分区coalesce、repartition。从调用链分析二者的关系
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {coalesce(numPartitions, shuffle = true)
}
理解coalesce的关键是 shuffle 选项,
从是否 shuffle 的角度分析
- 分区增加一定需要 shuffle,至少存在一个分区数据需要分发给多个分区
- 分区减少可以不需要 shuffle,将若干个分区全部分发给一个分区
从分区变化和是否 shuffle 角度分析
- 是否 shuffle 对分区减少没有必然联系
- 不 shuffle 且增加分区时无效
因此
package fun.uhope.transformimport fun.uhope.util.InitSparkContextobject RePartition {def main(args: Array[String]): Unit = {// 重分区val sc = InitSparkContext.withLocal()val sourceRDD = sc.parallelize(Nil)println(s"原始分区数 ${sourceRDD.partitions.length}")// coalesce 可以减少分区也可以增加分区// 减少分区时,可以不发生 shuffle// 增加分区时,shuffle 一定要设置为 true,否则分区数不发生变化val rdd1 = sourceRDD.coalesce(numPartitions = 4, shuffle = false)println(s"变成 4 分区 shuffle false ${rdd1.partitions.length}")val rdd2 = sourceRDD.coalesce(numPartitions = 16, shuffle = false)println(s"变成 16 分区 shuffle false ${rdd2.partitions.length}")val rdd3 = sourceRDD.coalesce(numPartitions = 16, shuffle = true)println(s"变成 16 分区 shuffle true ${rdd3.partitions.length}")// repartition 底层是 coalesce 且一定会发生 shuffleval rdd4 = sourceRDD.repartition(32)println(s"变成 32 分区的 repartition ${rdd4.partitions.length}")val rdd5 = sourceRDD.repartition(4)println(s"变成 32 分区的 repartition ${rdd5.partitions.length}")sc.stop()}
}
结论:coalesce相对repartition更加底层且灵活,但需要理解分区与shuflle的底层逻辑。repartition是coaleace的一种特殊情况,它总是执行shuffle
Tips: 在数据分布不均的情况下减少分区建议使用shuffle这样可以让最终分区的数据变的更加均衡虽然会带来一定的资源消耗
五、广播变量的多种实现方式
Spark 中的广播变量(Broadcast Variables)是一种优化技术,主要用于在集群中高效分发只读数据。通过广播变量,Spark 可以将数据在各个节点上缓存,从而避免在每个任务中重复发送相同的数据,减少网络传输开销和提高性能。通常的使用场景如下:
- 小型只读数据集的共享
- mapjoin
- 机器学习模型广播
- 重复数据缓存
只考虑技术实现通常有:类 scala 闭包变量引用、spark 广播变量、临时文件
类 scala 闭包变量应用
val config = new HashMap[String, String]()
rdd.map(x => config.getOrElse(x, 'Nil')).foreach(println)
从语法上这是 scala 的闭包实现,但 spark 作为分布式计算框架变量 config 的初始化在Driver端完成,但 map 算子的逻辑在Executor端进行。因此类闭包的实现 spark 会将 config 对象进行序列化后通过网络发送到每个Executor的 JVM 中,至于在Executor中会被反序列化几份需要结合广播的变量类型
- 如果是 object 对象,具备单例每个 JVM(Executor) 只有一份
- 如果是 class 对象,每个 task 一份
Tip: 因为需要序列化,因此被广播的变量一定可以被序列化(继承Serializable)。同时因为内置的序列化协议会附带很多其它无用信息在广播大变量时不建议使用
spark 广播变量
val map = new HashMap[String, String]()
val config = sc.broadcast(map)
rdd.map(x => config.value.getOrElse(x, 'Nil')).foreach(println)
对比类闭包的实现,spark 提供的广播变量有以下优点
- 每个
Executor保存一份 - 使用
BitTorrent协议数据分块分发机制,使得数据可以从多个节点分别获取,有效减少数据传输延迟和带宽消耗加速广播过程 - 可以使用
kryo序列化协议,相比 java 内置的序列化性能更高、序列化后的数据包更小
临时文件
在 MapReduce 编程框架中要实现广播(或mapjoin)通常是在 Job 中调用addCacheFile()将文件分发到集群的各个 Mapper 节点上,这个每个 Mapper都可以在本地文件中访问数据副本。Spark 同样支持
sc.addFile("hdfs://user/spark/jobxxx/config.txt")
之后的算子就可以像访问本地文件一样访问数据副本,但这种方式需要自己维护数据读取和解析在使用上的便捷性不如spark 提供的广播变量。这种方式不推荐使用
相关文章:
三年 Sparker 都不一定知道的算子内幕
一、如何在 mapPartitions 中释放资源 mapPartitions是一种对每个分区进行操作的转换操作,于常用的map操作类似,但它处理的是整个分区而不是单个元素。mapPartitions的应用场景适合处理需要在每个分区内批量处理数据的场景,通常用于优化性能…...

PG表空间
目录标题 PG表空间PostgreSQL表空间的最佳实践是什么?如何在PostgreSQL中创建和管理自定义表空间?PostgreSQL表空间对数据库性能的具体影响有哪些?在PostgreSQL中,如何迁移数据到不同的表空间以优化存储布局?PostgreSQ…...

谷粒商城のElasticsearch
文章目录 前言一、前置知识1、Elasticsearch 的结构2、倒排索引 (Inverted Index)2.1、 索引阶段2.2、查询阶段 二、环境准备1、安装Es2、安装Kibana3、安装 ik 分词器 三、项目整合1、引入依赖2、整合业务2.1、创建索引、文档、构建查询语句2.2、整合业务代码 后记 前言 本篇介…...

排队免单模式小程序开发
开发一个排队免单模式的小程序涉及多个方面,包括需求分析、界面设计、后端开发、数据库设计以及测试上线等。下面我将详细介绍每个步骤的概要: 1.需求分析 明确目标:首先确定小程序的核心功能,即排队免单模式的具体实现方式。例如…...

从OracleCloudWorld和财报看Oracle的转变
2024年9月9-12日Oracle Cloud World在美国拉斯维加斯盛大开幕 押注AI和云 Oracle 创始人Larry Ellison做了对Oracle战略和未来愿景的主旨演讲,在演讲中Larry将AI技术和云战略推到了前所未有的高度,从新的Oracle 23c改名到Oracle23ai,到Oracl…...

搭建 PHP
快速搭建 PHP 环境指南 PHP 是一种广泛用于 Web 开发的后端脚本语言,因其灵活性和易用性而受到开发者的青睐。无论是开发个人项目还是企业级应用,PHP 环境的搭建都是一个不可忽视的基础步骤。本指南将带您快速学习如何在不同平台上搭建 PHP 环境&#x…...

kubernetes技术详解,带你深入了解k8s
目录 一、Kubernetes简介 1.1 容器编排应用 1.2 Kubernetes简介 1.3 k8s的设计架构 1.3.1 k8s各个组件的用途 1.3.2 k8s各组件之间的调用关系 1.3.3 k8s的常用名词概念 1.3.4 k8s的分层结构 二、k8s集群环境搭建 2.1 k8s中容器的管理方式 2.2 k8s环境部署 2.2.1 禁用…...

Gateway学习笔记
目录 介绍: 核心概念 依赖 路由 断言 基本的断言工厂 自定义断言 过滤器 路由过滤器 过滤器工厂 自定义路由过滤器 全局过滤器 其他 过滤器执行顺序 前置后置(?) 跨域问题 yaml 解决 配置类解决 介绍&#x…...

创造增强叙事的互动:Allison Crank的沉浸式体验设计理念
在沉浸式技术日新月异的今天,如何通过用户交互增强叙事,而非分散注意力,成为了设计师们共同面临的挑战。作为用户体验设计师和研究员,Allison Crank以其独特的视角和丰富的经验,为我们揭示了这一领域的核心原则与实践方法。 叙事与互动的和谐共生 Allison Crank强调,互…...

Requests-HTML模块怎样安装和使用?
要安装和使用Requests-HTML模块,您可以按照以下步骤进行操作: 打开命令行界面(如Windows的命令提示符或Mac的终端)。 使用pip命令安装Requests-HTML模块。在命令行中输入以下命令并按回车键执行: pip install request…...

[网络]从零开始的计算机网络基础知识讲解
一、本次教程的目的 本次教程我只会带大叫了解网络的基础知识,了解网络请求的基本原理,为后面文章中可能会用到网络知识做铺垫。本次我们只会接触到网络相关的应用层,并不涉及协议的具体实现和数据转发的规则。也就是说,这篇教程是…...

wifiip地址可以随便改吗?wifi的ip地址怎么改变
对于普通用户来说,WiFi IP地址的管理和修改往往显得神秘而复杂。本文旨在深入探讨WiFi IP地址是否可以随意更改,以及如何正确地改变WiFi的IP地址。虎观代理小二将详细解释WiFi IP地址的基本概念、作用以及更改时需要注意的事项,帮助用户更好地…...

黑马十天精通MySQL知识点
一. MySQL概述 安装使用 MySQL安装完成之后,在系统启动时,会自动启动MySQL服务,无需手动启动。 也可以手动的通过指令启动停止,以管理员身份运行cmd,进入命令行执行如下指令: 1 、 net start mysql80…...

如何在 Vue 3 + Element Plus 项目中实现动态设置主题色以及深色模式切换
🔥 个人主页:空白诗 文章目录 一、引言二、项目依赖和环境配置1. VueUse2. use-element-plus-theme3. 安装依赖 三、实现深色模式切换1. 设置深色模式状态2. 模板中的深色模式切换按钮3. 深色模式的效果展示 四、动态切换主题色五、总结 一、引言 在现代…...

Android 如何实现搜索功能:本地搜索?数据模型如何设计?数据如何展示和保存?
目录 效果图为什么需要搜索功能如何设计搜索本地的功能,如何维护呢?总结 一、效果图 二、为什么需要搜索功能 找一个选项,需要花非常多的时间,并且每次都需要指导客户在哪里,现在只要让他们搜索一下就可以。这也是模…...

【K230 实战项目】气象时钟
【CanMV K230 AI视觉】 气象时钟 功能描述:说明HMDI资源3.5寸屏幕 使用方法 为了方便小伙伴们理解,请查看视频 B站连接 功能描述: 天气信息获取:通过连接到互联网,实时获取天气数据,包括温度、湿度、天气状…...

什么是 HTTP/3?下一代 Web 协议
毫无疑问,发展互联网底层的庞大协议基础设施是一项艰巨的任务。 HTTP 的下一个主要版本基于 QUIC 协议构建,并有望提供更好的性能和更高的安全性。 以下是 Web 应用程序开发人员需要了解的内容。 HTTP/3 的前景与风险 HTTP/3 致力于让互联网对每个人…...

IDEA Project不显示/缺失文件
问题:侧边栏project 模式下缺少部分文件 先点close project 打开项目所在目录,删除目录下的.idea文件夹 重新open project打开这个项目即可解决...

浅谈vue2.0与vue3.0的区别(整理十六点)
目录 1. 实现数据响应式的原理不同 2. 生命周期不同 3. vue 2.0 采用了 option 选项式 API,vue 3.0 采用了 composition 组合式 API 4. 新特性编译宏 5. 父子组件间双向数据绑定 v-model 不同 6. v-for 和 v-if 优先级不同 7. 使用的 diff 算法不同 8. 兄弟组…...

深入理解 MySQL MVCC:多版本并发控制的核心机制
在数据库领域,并发控制是确保多个事务能够正确地并发执行而不破坏数据完整性的关键技术。MySQL 作为广泛使用的关系型数据库管理系统,采用了多版本并发控制(Multi-Version Concurrency Control,MVCC)机制来实现高效的并…...


OpenClaw本地化优势:Qwen3-14b_int4_awq模型数据安全实践
OpenClaw本地化优势:Qwen3-14b_int4_awq模型数据安全实践 1. 为什么选择本地化部署 去年我在处理一批客户调研数据时,遇到了一个棘手问题——调研报告包含大量敏感信息,但团队需要AI辅助分析。当时尝试了几个云端方案,要么因为数…...

Docker容器共享内存完全指南:从基础概念到实战调优
Docker容器共享内存完全指南:从基础概念到实战调优 在分布式计算和高性能应用场景中,共享内存(Shared Memory)作为进程间通信(IPC)最高效的方式之一,其重要性不言而喻。而当我们将应用迁移到Doc…...

C语言开发界面太难?libui-ng开源库帮你快速搞定
一、C语言开发者的噩梦,终被一个开源库打破? 搞C语言开发的那些人,基本上都躲不开这么一个让人头疼的点,就是想要去写一个可视化的界面,要嘛就得被迫去学习繁杂的Qt、GTK,不然呢就得拼了命去写Win32代码&a…...

芯片行业的高门槛本质上是一次性固定成本极高导致的
AI 工具这波热潮里,芯片圈有个声音:以后一个人能不能做一颗芯片?很多人讨论的时候跑偏了,一直在聊人效、聊 AI 能替代多少工程师。真正的瓶颈根本不在这里。做过项目的人都知道,一个芯片项目的成本结构大概长这样&…...

OpenClaw备份策略:Qwen3-32B配置与技能库容灾方案
OpenClaw备份策略:Qwen3-32B配置与技能库容灾方案 1. 为什么需要备份OpenClaw环境 去年冬天的一个深夜,我的OpenClaw自动化脚本突然停止工作。经过排查发现是SSD故障导致~/.openclaw目录损坏,丢失了精心调校的模型配置、技能库和任务历史记…...

基于STM32与华为云的粮仓环境监测系统设计
1. 项目概述粮仓环境监测系统是现代农业管理中不可或缺的重要环节。作为一名长期从事农业物联网开发的工程师,我深知传统人工巡检方式存在的诸多痛点:效率低下、数据记录不完整、响应不及时等问题常常导致粮食储存过程中出现不必要的损失。这套基于华为云…...
一)
大一C语言期末必考|程序结构+流程控制(详解+例题+易错点)一
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

好写作AI“期刊论文智造局”:解锁学术发表的通关秘籍
在学术的江湖里,期刊论文就像是一把把锋利的宝剑,是学者们披荆斩棘、开疆拓土的得力武器。然而,想要打造出一把称手的“宝剑”,从选题到撰写,再到格式调整,每一步都充满挑战。别愁啦!好写作AI化…...

TFLI2C库详解:Benewake TFLuna激光测距传感器的I²C驱动开发指南
1. TFLI2C 库概述:面向 Benewake TFLuna 的专用 IC 驱动框架TFLI2C 是一个专为 Benewake TFLuna 激光测距传感器设计的 Arduino 兼容库,其核心目标是通过标准 IC(Inter-Integrated Circuit)总线实现对设备的高可靠性、低开销控制与…...