Centos7环境下Hive的安装
Centos7环境下Hive的安装
- 前言
- 一、安装Hive
- 1.1 下载并解压
- 1.2 配置环境变量
- 1.3 修改配置
- 1. hive-env.sh
- 2. hive-site.xml
- 1.4 拷贝数据库驱动
- 1.5 初始化元数据库
- 报错
- 1.6 安装MySQL
- 1.7 启动
- 二、HiveServer2/beeline
- 2.1 修改Hadoop配置
- 2.2 修改Hive配置
- 2.2 启动hiveserver2
- 2.3 使用beeline
- 参考文章
前言
对于hive的安装和使用,需要先完成如下配置:
- Hadoop集群(Hadoop搭建集群)
- 安装HBase数据库(HBase数据库搭建)
一、安装Hive
1.1 下载并解压
下载所需版本的 Hive,这里我下载版本为 apache-hive-3.1.2-bin.tar.gz
下载地址:https://archive.apache.org/dist/hive/hive-3.1.2/
# 使用wget命令下载
wget https://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
下载后进行解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/hive-3.1.2
1.2 配置环境变量
# 这里修改自己的环境变量文件
vim /etc/profile.d/my_env.sh
添加环境变量:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
让环境变量生效:
source /etc/profile.d/my_env.sh

1.3 修改配置
1. hive-env.sh
进入安装目录下的 conf/ 目录,拷贝 Hive 的环境配置模板 flume-env.sh.template
cd /opt/module/hive-3.1.2/conf/
cp hive-env.sh.template hive-env.sh
修改 hive-env.sh,指定 Hadoop 的安装路径:
HADOOP_HOME=/opt/module/hadoop-3.1.3

2. hive-site.xml
新建 hive-site.xml 文件,内容如下,主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息:
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop101:3306/hadoop_hive?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>111111</value></property>
</configuration>
1.4 拷贝数据库驱动
将 MySQL 驱动包拷贝到 Hive 安装目录的 lib 目录下, MySQL 驱动的下载地址为:https://dev.mysql.com/downloads/connector/j/

解压后上传jar包到服务器

1.5 初始化元数据库
-
当使用的 hive 是 1.x 版本时,可以不进行初始化操作,Hive
会在第一次启动的时候会自动进行初始化,但不会生成所有的元数据信息表,只会初始化必要的一部分,在之后的使用中用到其余表时会自动创建; -
当使用的 hive 是 2.x及以上版本时,必须手动初始化元数据库。初始化命令:
# schematool 命令在安装目录的 bin 目录下,由于上面已经配置过环境变量,在任意位置执行即可
schematool -dbType mysql -initSchema
这里我使用的是hive-3.1.2-bin.tar.gz,需要手动初始化元数据库。
报错
这里执行后会出现如下报错:
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V

原因是hadoop和hive的两个guava.jar版本不一致,两个jar位置分别位于下面两个目录:
find -name guava*

解决办法是删除低版本的那个,将高版本的复制到低版本目录下
cd /opt/module/hive-3.1.2/lib/
rm -rf guava-19.0.jar
cp /opt/module/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar .
hive默认是derby数据库,但是前面已经配置了mysql,如果没有安装mysql的话会报如下错误:

可以先把前面配置的hive-site.xml文件删掉,再执行schematool -dbType derby -initSchema命令(后面改用mysql数据库时记得重新创建),即可成功初始化元数据库。

1.6 安装MySQL
由于之前已经写过安装mysql的文章,这里就不在赘述,直接放连接云服务器上配置Mysql
连接:https://blog.csdn.net/m0_70405779/article/details/140735557
安装好mysql后可以执行如下命令初始化元数据库
schematool -dbType mysql -initSchema

可以进到mysql中查看,已经创建了前面xml文件中设置的hadoop_hive数据库

1.7 启动
启动hive之前先确保hadoop集群是否启动,没有就启动一下
# 配置了hadoop环境路径的话可以直接执行
start-all.sh

由于已经将 Hive 的 bin 目录配置到环境变量,直接使用以下命令启动,成功进入交互式命令行后执行 show databases 命令,无异常则代表搭建成功。
hive

使用hive
hive> show databases;
hive> show tables;
hive> create table stu(id int, name string);
hive> insert into stu values(1,"chen");
hive> select * from stu;
问题记录
这里再hive中执行insert语句时可能会卡住
可以先退出来,重新进入hive,执行如下命令
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=50000000;
set hive.exec.mode.local.auto.input.files.max=5;
然后再次执行插入语句


二、HiveServer2/beeline
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,因此产生了 HiveServer2。HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务。
HiveServer2 拥有自己的 CLI 工具——Beeline。Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于目前 HiveServer2 是 Hive 开发维护的重点,所以官方更加推荐使用 Beeline 而不是 Hive CLI。以下主要讲解 Beeline 的配置方式。
2.1 修改Hadoop配置
修改 hadoop 集群的 core-site.xml 配置文件,增加如下配置,指定 hadoop 的 root 用户可以代理本机上所有的用户。
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
之所以要配置这一步,是因为 hadoop 2.0 以后引入了安全伪装机制,使得 hadoop 不允许上层系统(如 hive)直接将实际用户传递到 hadoop 层,而应该将实际用户传递给一个超级代理,由该代理在 hadoop 上执行操作,以避免任意客户端随意操作 hadoop。如果不配置这一步,在之后的连接中可能会抛出 AuthorizationException 异常。
关于 Hadoop 的用户代理机制,可以参考:hadoop 的用户代理机制 或 Superusers Acting On Behalf Of Other Users
2.2 修改Hive配置
在hive-site.xml文件中添加如下配置信息:
<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop001</value>
</property><!-- 指定hiveserver2连接的端口号 -->
<property><name>hive.server2.thrift.port</name><value>10000</value>
</property>2.2 启动hiveserver2
由于上面已经配置过环境变量,这里直接启动即可:
hive --service hiveserver2
# 或者
# nohup hiveserver2 &
2.3 使用beeline
可以使用以下命令进入 beeline 交互式命令行,出现 Connected 则代表连接成功。
bin/beeline -u jdbc:hive2://hadoop101:10000 -n root
参考文章
- Linux环境下Hive的安装
- HIve安装配置(超详细)
相关文章:

Centos7环境下Hive的安装
Centos7环境下Hive的安装 前言一、安装Hive1.1 下载并解压1.2 配置环境变量1.3 修改配置1. hive-env.sh2. hive-site.xml 1.4 拷贝数据库驱动1.5 初始化元数据库报错 1.6 安装MySQL1.7 启动 二、HiveServer2/beeline2.1 修改Hadoop配置2.2 修改Hive配置2.2 启动hiveserver22.3 …...

??Ansible——ad-hoc
文章目录 一、ad-hoc介绍二、ad-hoc的使用1、语法2、ad-hoc常用模块1)shell模块2)command模块3)script模块4)file模块5)copy模块6)yum模块7)yum-repository模块8)service模块9&#…...
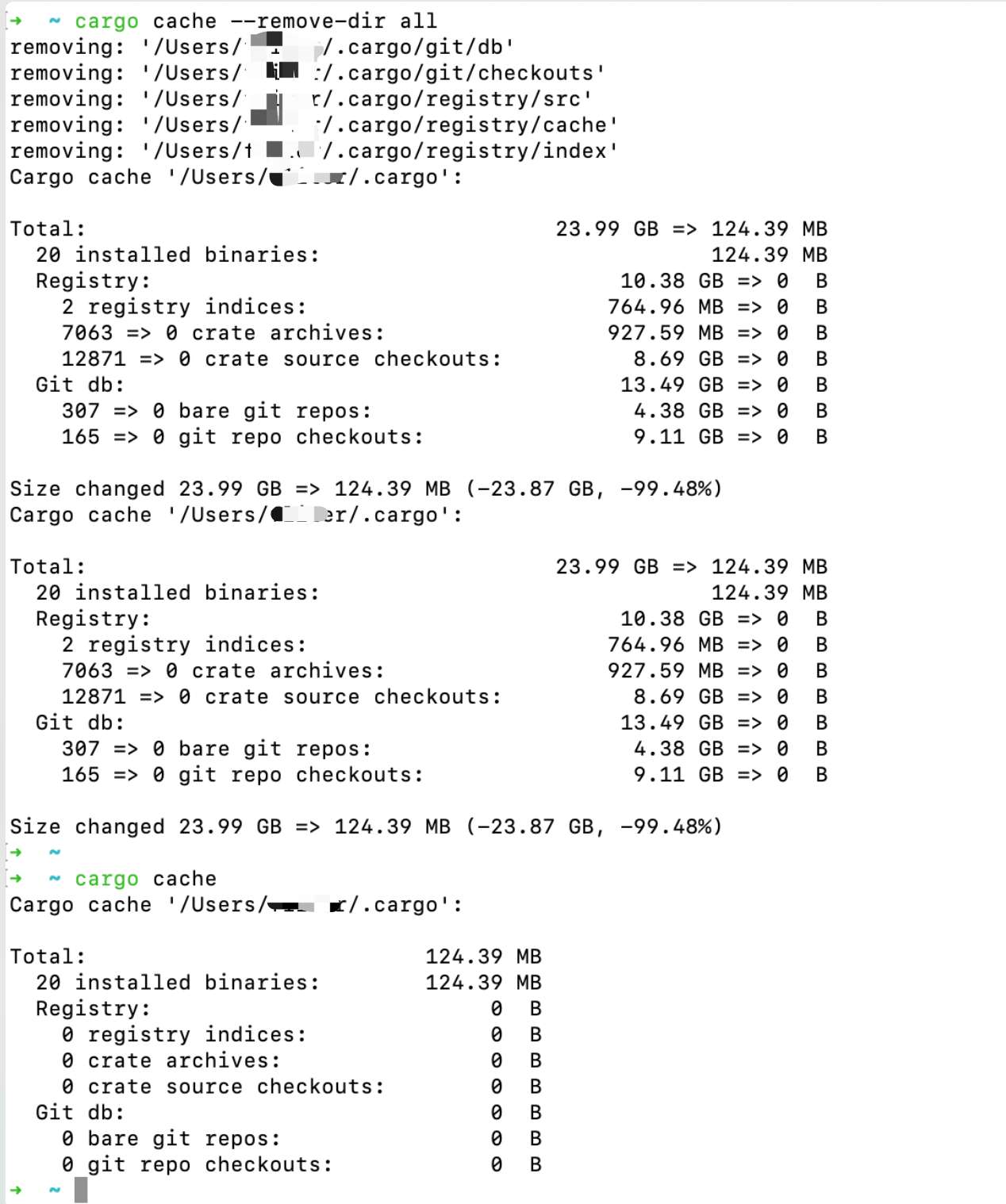
清理Go/Rust编译时产生的缓存
Go Mac 1T的磁盘频频空间高级,发现是/Users/yourname/Library/Caches/go-build 目录占用了大量空间。 此目录保存来自 Go 构建系统的缓存构建工件。 如果目录太大,请运行go clean -cache。 运行go clean -fuzzcache以删除模糊缓存。 当时直接手工清理了…...

【linux】 ls命令
ls 命令是 Linux 和 Unix 系统中用于列出目录内容的命令。它显示指定目录下的文件和子目录列表。如果不指定目录,ls 默认显示当前目录下的内容。 基本用法 ls [选项] [文件或目录...] 无选项:简单地列出当前目录下的文件和目录。文件或目录࿱…...

STM32的寄存器深度解析
目录 一、STM32 寄存器概述 二、寄存器的定义与作用 三、寄存器分类 1.内核寄存器 2.外设寄存器 四、重要寄存器详解 1.GPIO 相关寄存器 2.定时器相关寄存器 3.中断相关寄存器 4.RCC 相关寄存器 五、寄存器操作方法 1.直接操作寄存器 2.使用库函数操作寄存器 六…...

win11 运行vmware workstation 虚拟机很卡,解决办法
本身win11的hyper V和vmare workstation有兼容性问题,正常来说,不能二者共存 需要在win11上流畅运行vmare虚拟机,需要在win11用管理员权限打开power shell 然后在里面运行命令: bcdedit /set hypervisorlaunchtype off powercfg /powerthr…...

C语言 | Leetcode C语言题解之第404题左叶子之和
题目: 题解: bool isLeafNode(struct TreeNode *node) {return !node->left && !node->right; }int sumOfLeftLeaves(struct TreeNode *root) {if (!root) {return 0;}struct TreeNode **q malloc(sizeof(struct TreeNode *) * 2001);in…...

jeesite支持db2数据库初始化sql
点击下载:jeesite5.8.1-db2-sql.rar 提取码: yqev...

微信小程序页面制作——婚礼邀请函(含代码)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

股票量化接口api,国内股票期权怎么交易
炒股自动化:申请官方API接口,散户也可以 python炒股自动化(0),申请券商API接口 python炒股自动化(1),量化交易接口区别 Python炒股自动化(2):获取…...

Spring解决循环依赖的原理
通过将自己注入自己,使用代理对象调用add方法解决了事务失效问题,但是这样不会产生循环依赖吗? 在OrdersCreateServiceImpl 中注入的是OrdersCreateServiceImpl 的代理对象,并不是OrdersCreateServiceImpl 本身实例,构…...
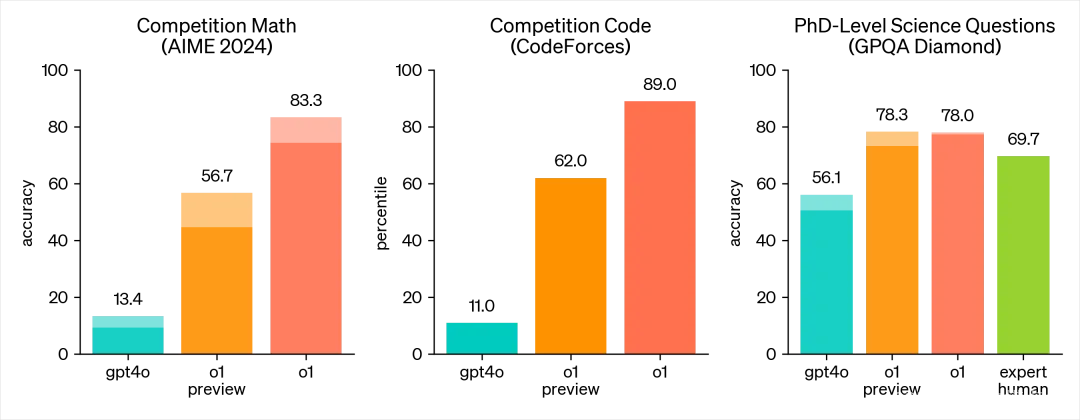
Openal o1初探
9 月 13 日,OpenAI 正式公开一系列全新 AI 大模型,传说的“草莓”终于上线,但是正式命名不叫“草莓”,而是o1。 一、为什么叫o1 为什么取名叫o1,OpenAI是这么说的: For complex reasoning tasks this is…...

基于python+django+vue的学生成绩管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示 【2025最新】基于协同过滤pythondjangovue…...

mimd 公平收敛在相图中的细节
aimd 的收敛已经说腻了,我曾经画了好几次相图。有朋友希望我能画一个 mimd 相图,我就再画一个稍微详细的。 下面相图收敛到稳定点的前提异步 mimd: 之所以要异步,举个例子,在执行 gx 时,要确保 y 已经执…...

爬虫--翻页tips
免责声明:本文仅做分享! 伪线程 from DrissionPage import ChromiumPage import timepage ChromiumPage() page.get("https://you.ctrip.com/sight/taian746.html") # 初始化 第0页 index_page 0# 翻页点击函数 sleep def page_turn():page…...

论文内容分类与检测系统源码分享
论文内容分类与检测检测系统源码分享 [一条龙教学YOLOV8标注好的数据集一键训练_70全套改进创新点发刊_Web前端展示] 1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 项目来源AACV Association for the Advancement of Comput…...
)
【MySQL】将表导出CSV(可以使用excel打开)
1、准备工作 查看数据库: show databases;切换数据库: use 数据库名;查看表名字 show tables;2、单个表导出 需要替换导出csv文件目录和表名 SELECT * INTO OUTFILE 目录/文件名.csv FIELDS TERMINATED BY , ENCLOSED BY " LINES TERMINATED …...

通用四期ARM架构银河麒麟桌面操作系统V10【安装、配置FTP服务端】
一、操作环境 服务端:银河麒麟桌面操作系统V10SP1 (服务端包链接:https://download.csdn.net/download/AirIT/89747026) 客户端:银河麒麟桌面操作系统V10SP1 (客户端包链接:https://downloa…...
:RBO(Rule-Based Optimizer)优化器简介)
梧桐数据库(WuTongDB):RBO(Rule-Based Optimizer)优化器简介
RBO(Rule-Based Optimizer,基于规则的优化器) 是一种早期的数据库查询优化方法,它通过预定义的一组规则来决定查询的执行计划,而不是像 CBO(Cost-Based Optimizer,基于成本的优化器)…...

【农信网-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...

AB包相关知识
Lua与AB包/Addressables以及YooAsset 摘自千问: Lua 是菜谱(逻辑):决定了菜怎么做,味道如何。因为你需要随时换菜谱(热更新),所以菜谱不能死板地印在墙上(编译进主包&a…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

密码学入门:区块链中的密码学原理
密码学入门:区块链中的密码学原理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊密码学这个重要话题。作为一个Web3探索者,密码学是区块链的基础。今天就来分享一下区块链中常用的密码学原理。 为什么密码学很重要&a…...

TigerVNC跨平台远程桌面解决方案:构建企业级安全连接的技术实践
TigerVNC跨平台远程桌面解决方案:构建企业级安全连接的技术实践 【免费下载链接】tigervnc High performance, multi-platform VNC client and server 项目地址: https://gitcode.com/gh_mirrors/ti/tigervnc 在数字化转型浪潮中,远程桌面访问已成…...