如何在@GenericGenerator中显式指定schema
现在的情况是,在MySQL中有db1和db2两个数据库。项目使用Hibernate,可同时访问db1和db2,默认数据库为db1。表table2在db2中。且table2的主键名为ids,是自增长字段(Auto Increment)。
table2和ids的定义为:
@Entity
@Table(name = "table2", schema = "db2")
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class Table2 implements java.io.Serializable {private static final long serialVersionUID = 48L;@Id@Column(name = "ids")@GeneratedValue(generator = "idGenerator", strategy = GenerationType.IDENTITY)@GenericGenerator(name = "idGenerator", strategy = "increment")private Integer ids;当向table2中保存数据时,会报错。原因是生成ids时,系统会查询table2中ids的最大值。语句是:
select max(ids) from table2由于默认数据库是db1,因此查询的是db1.table2表。但table2表实际上在db2中,所以系统找不到该表,从而报错。
这就需要在@GenericGenerator中指定max查询语句的schema。通过检查错误信息,发现对应代码在org.hibernate.id.IncrementGenerator.configure()方法中,如下:
public void configure(Type type, Properties params, Dialect dialect) throws MappingException {returnClass = type.getReturnedClass();ObjectNameNormalizer normalizer =( ObjectNameNormalizer ) params.get( PersistentIdentifierGenerator.IDENTIFIER_NORMALIZER );String column = params.getProperty( "column" );if ( column == null ) {column = params.getProperty( PersistentIdentifierGenerator.PK );}column = dialect.quote( normalizer.normalizeIdentifierQuoting( column ) );String tableList = params.getProperty( "tables" );if ( tableList == null ) {tableList = params.getProperty( PersistentIdentifierGenerator.TABLES );}String[] tables = StringHelper.split( ", ", tableList );final String schema = dialect.quote(normalizer.normalizeIdentifierQuoting(params.getProperty( PersistentIdentifierGenerator.SCHEMA )));final String catalog = dialect.quote(normalizer.normalizeIdentifierQuoting(params.getProperty( PersistentIdentifierGenerator.CATALOG )));StringBuilder buf = new StringBuilder();for ( int i=0; i < tables.length; i++ ) {final String tableName = dialect.quote( normalizer.normalizeIdentifierQuoting( tables[i] ) );if ( tables.length > 1 ) {buf.append( "select max(" ).append( column ).append( ") as mx from " );}buf.append( Table.qualify( catalog, schema, tableName ) );if ( i < tables.length-1 ) {buf.append( " union " );}}if ( tables.length > 1 ) {buf.insert( 0, "( " ).append( " ) ids_" );column = "ids_.mx";}sql = "select max(" + column + ") from " + buf.toString();}在初始化Table2实体类时,该方法就会执行。作用是生成对应数据库的select max语句。
在IncrementGenerator的注释中,有一段话:
Mapping parameters supported, but not usually needed: tables, column. (The tables parameter specified a comma-separated list of table names.)
说明在@GenericGenerator中,可以设置参数。在IncrementGenerator.configure()方法中,可以将这些参数读出来。读取参数的方法为params.getProperty("参数名")。例如:
params.getProperty( "column" )
就是读取column参数的值。对应读取schema的语句为:
final String schema = dialect.quote(normalizer.normalizeIdentifierQuoting(params.getProperty( PersistentIdentifierGenerator.SCHEMA ))
);schema的参数名就是PersistentIdentifierGenerator.SCHEMA,也就是"schema"。其他预置保留参数的值大都在org.hibernate.id.PersistentIdentifierGenerator中定义。如:
public interface PersistentIdentifierGenerator extends IdentifierGenerator {/*** The configuration parameter holding the schema name*/public static final String SCHEMA = "schema";/*** The configuration parameter holding the table name for the* generated id*/public static final String TABLE = "target_table";/*** The configuration parameter holding the table names for all* tables for which the id must be unique*/public static final String TABLES = "identity_tables";/*** The configuration parameter holding the primary key column* name of the generated id*/public static final String PK = "target_column";/*** The configuration parameter holding the catalog name*/public static final String CATALOG = "catalog";/*** The key under whcih to find the {@link org.hibernate.cfg.ObjectNameNormalizer} in the config param map.*/public static final String IDENTIFIER_NORMALIZER = "identifier_normalizer";在@GenericGenerator中设置parameter的方法为:
@Id
@Column(name = "ids")
@GeneratedValue(generator = "idGenerator", strategy = GenerationType.IDENTITY)
@GenericGenerator(name = "idGenerator", strategy = "increment", parameters = @Parameter(name = PersistentIdentifierGenerator.SCHEMA, value = "db2"))
private Integer ids;这样就能在table2前加上正确的schema名称(db2),生成正确的查询语句:
select max(ids) from db2.table2如果有多个参数,可以写为:
@GenericGenerator(name = "idGenerator", strategy = "increment", parameters = {
@Parameter(name = PersistentIdentifierGenerator.SCHEMA, value = "db2"),
@Parameter(name=PersistentIdentifierGenerator.CATALOG, value = "db2")})
相关文章:

如何在@GenericGenerator中显式指定schema
现在的情况是,在MySQL中有db1和db2两个数据库。项目使用Hibernate,可同时访问db1和db2,默认数据库为db1。表table2在db2中。且table2的主键名为ids,是自增长字段(Auto Increment)。 table2和ids的定义为&a…...

感知器神经网络
1、原理 感知器是一种前馈人工神经网络,是人工神经网络中的一种典型结构。感知器具有分层结构,信息从输入层进入网络,逐层向前传递至输出层。根据感知器神经元变换函数、隐层数以及权值调整规则的不同,可以形成具有各种功能特点的…...

【C++】——继承详解
目录 1、继承的概念与意义 2、继承的使用 2.1继承的定义及语法 2.2基类与派生类间的转换 2.3继承中的作用域 2.4派生类的默认成员函数 <1>构造函数 <2>拷贝构造函数 <3>赋值重载函数 <4析构函数 <5>总结 3、继承与友元 4、继承与静态变…...

RocketMQ 消费方式
在消息传递系统中,“推(Push)”和“拉(Pull)”是两种不同的消息消费方式,RocketMQ 也支持这两种模式。下面是对这两种模式的详细解释: 1. 推模式(Push Model) 模式简介…...

初始爬虫7
针对数据提取的项目实战: 补充初始爬虫6的一个知识点: etree.tostring能够自动补全html缺失的标签,显示原始的HTML结构 # -*- coding: utf-8 -*- from lxml import etreetext <div> <ul> <li class"item-1">…...

深入理解Appium定位策略与元素交互
深入理解Appium定位策略与元素交互 在移动应用测试领域,Appium作为一款流行的跨平台自动化测试工具,其强大而灵活的元素定位能力对于构建稳定、高效的测试脚本至关重要。本文将深入探讨Appium支持的各种定位方法,并分享如何通过高级技巧和最…...

java基础面试题总结
java基础面试题总结 目录 前言 1. JVM vs JDK vs JRE的了解 2. 谈谈你对编程、编译、运行的理解 3. 什么是字节码?采用字节码的好处是什么? 5. java中的注解有几种,分别是什么? 6. 字符型常量和字符串常量 7.标识符和关键字的认识 8. 泛型ÿ…...

Typescript 的类型断言
类型断言(Type Assertion)是 TypeScript 中的一种机制,允许开发者手动指定某个值的类型,而不是让 TypeScript 自动推断类型。类型断言通常用于在编译时告诉 TypeScript 编译器某个值的具体类型,以便在后续代码中进行类…...

【设计模式】单例模式详解及应用实例
单例模式(Singleton Pattern)是一种创建型设计模式,保证一个类在整个程序的生命周期中只有一个实例,并提供一个全局访问点。单例模式广泛用于需要全局唯一实例的场景,比如数据库连接池、日志对象、线程池等。 单例模式…...

学习图解算法 使用C语言
图解算法 使用C语言 也就是通过C语言实现各种算法 链接:百度云盘 提取码:1001...

基于Netty实现TCP客户端:封装断线重连、连接保持
文章目录 引言I 基于Netty实现TCP客户端基于 Netty 创建客户端 时序图封装思路NettyClient 封装II 客户端的断线重连本质使用过程中断线重连重试策略III 心跳机制心跳检测处理器心跳机制实现逻辑IV 同步等待消息返回V 工具ForkJoinPoolByteConvertUtilsee also处理假死把handle…...

基于形状记忆聚合物的折纸超结构
公众号端文章: 基于SMP的折纸超结构https://mp.weixin.qq.com/s?__bizMzkwMjc0MTE3Mw&mid2247484016&idx4&sn16f8d4aaaff76d776cec19bc0adbdd3b&chksmc0a1afaaf7d626bc0457d9cc4ba1b38424c2aad71ffec548715e47f5611cf00f10d5a511f3b3#rd 折…...

前端用html写excel文件直接打开
源码 <html xmlns:o"urn:schemas-microsoft-com:office:office" xmlns:x"urn:schemas-microsoft-com:office:excel" xmlns"http://www.w3.org/TR/REC-html40"> <head><meta charset"UTF-8"><!--[if gte mso 9]&…...

FastText 和 Faiss 的初探了解
概览 大模型目前已经是如火如荼的程度,各个大厂都有推出面向大众的基础大模型,同时诸多行业也有在训练专有大模型,而大模型的发展由来却是经过多年从文本检索生成、深度学习、自然语言处理,在Transformer架构出来后,才…...
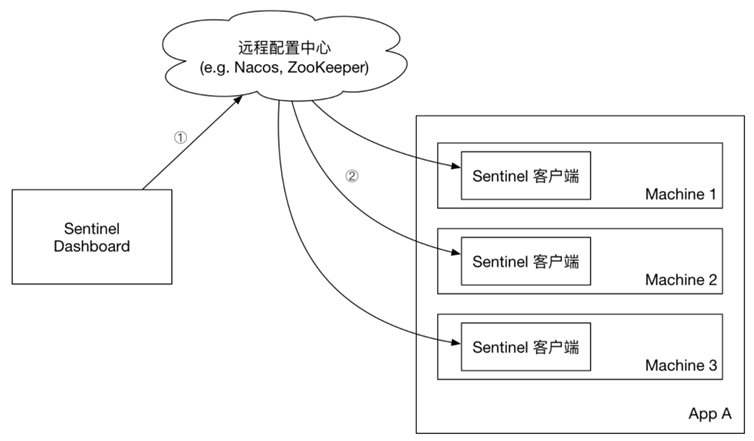
微服务保护学习笔记(五)Sentinel授权规则、获取origin、自定义异常结果、规则持久化
文章目录 前言4 授权规则4.1 基本原理4.2 获取origin4.3 配置授权规则 5 自定义异常结果6 规则持久化 前言 微服务保护学习笔记(一)雪崩问题及解决方案、Sentinel介绍与安装 微服务保护学习笔记(二)簇点链路、流控操作、流控模式(关联、链路) 微服务保护学习笔记(三)流控效果(…...

YOLOv8目标检测模型——遥感小目标检测经验分享
小目标检测——YOLOV8 一、引言 背景介绍 (1)目标检测的重要性 目标检测在许多领域都具有极其重要的作用。在自动驾驶中,目标检测能够识别道路上的障碍物和行人,确保行车安全。在视频监控中,目标检测能够实时发现异…...

构建响应式 Web 应用:Vue.js 基础指南
构建响应式 Web 应用:Vue.js 基础指南 一 . Vue 的介绍1.1 介绍1.2 好处1.3 特点 二 . Vue 的快速入门2.1 案例 1 : 快速搭建 Vue 的运行环境 , 在 div 视图中获取 Vue 中的数据2.2 案例 2 : 点击按钮执行 vue 中的函数输出 vue 中 data 的数据2.3 小结 三 . Vue 常…...

计算机毕业设计选题推荐-在线投票系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

【C/C++】程序的构建(编译)过程概述
🦄个人主页:小米里的大麦-CSDN博客 🎏所属专栏:C_小米里的大麦的博客-CSDN博客 🎁代码托管:C: 探索C编程精髓,打造高效代码仓库 (gitee.com) ⚙️操作环境:Visual Studio 2022 目录 一、前言 二、预处理(Preprocessi…...

ElasticSearch-2-核心语法集群高可用实战-Week2
ES批量操作 1.批量获取文档数据 这里多个文档是指,批量操作多个文档,搜索查询文档将在之后的章节讲解 批量获取文档数据是通过_mget的API来实现的 (1)在URL中不指定index和type 请求方式:GET 请求地址:_mget 功能说明 &#…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...