Linux 文件 IO 管理(第一讲)
Linux 文件 IO 管理(第一讲)
- 回顾 C 语言文件操作,提炼理解
- 新创建的文件为什么被放在可执行文件的同级目录下?
- 上述 log.txt 何时被创建?又是谁在打开它?
- 那文件没有被打开的时候在哪里?
- 一个进程可以打开多个文件吗?
- 如何管理?
- 认识文件
- 理解文件
- 用户如何通过进程操作文件呢?
- 使用系统调用对文件操作
- open
- 权限掩码
- flags 参数(标记位传参)
- close
- write
- 几个问题
- open 的返回值
- 文件描述符
- 文件描述符分配规则
- 理解读写
- 读
- 写
- 结论
- open 的作用
- 理解 Linux 系统一切皆文件
- 文件描述符 fd 和 C 语言库函数里的 FILE*
回顾 C 语言文件操作,提炼理解
下面的 C 语言代码一定很熟悉才对:
#include <stdio.h>
int main()
{FILE* fp = fopen("log.txt", "w");if (fp == NULL){perror("fopen");return 1;}fclose(fp);return 0;
}
代码意思很简单,就是以 'w' 的方式 打开 一个名为 log.txt 的文件:
- 失败,则返回失败原因并退出(
perror可以看成,底层封装类似strerror的函数,根据错误码给你描述错误原因) - 成功 就有情况了:
- 如果存在
log.txt文件,就会 清空log.txt里的内容,从文件开头写入(可以直接理解 输出重定向>的工作机制) - 如果不存在
log.txt文件,就会 在可执行文件的同级目录下创建log.txt文件
- 如果存在
新创建的文件为什么被放在可执行文件的同级目录下?
这个问题也可以先揪住最核心的矛盾:系统怎么知道可执行文件的路径呢?
前面进程的内容就说了,代码跑起来变成进程后,进程会维护自己的工作目录,那么创建文件总不能胡乱位置创建,和自己的可执行文件放在一起当然是更好的选择
所以这个路径有个更普适的名字,叫做 当前路径
上述 log.txt 何时被创建?又是谁在打开它?
是在你 gcc 编译的时候吗?并不是吧
而是你 运行被编译后的可执行文件的时候
也就是说,我们要进行文件操作,前提是要把我们的程序跑起来变成进程:就像文件的打开和关闭,是 CPU 执行到这部分代码的原因啊
所以 打开文件,本质上是进程打开文件
那文件没有被打开的时候在哪里?
再理解一下问题:
如果现在 已经存在 log.txt 文件,再次运行上述代码, log.txt 文件 在没有被打开的时候 在哪里?
磁盘硬盘 对吧,总不能直接加载到空间紧张的内存里吧
一个进程可以打开多个文件吗?
可以,一定是可以的
那 OS 里有那么多进程,所以在大多数情况下,OS 内部一定存在大量的被打开的文件
打开这么多文件 OS 不会混乱吗?还真是不会,毕竟 OS 是管理者,会对文件进行管理
如何管理?
先描述,再组织 :
一定是会存在和类似进程 PCB 一样的结构体来描述文件属性的!!!通过此结构体,OS 可以有效管理计算机内的文件属性(通过管理文件的数据)
而既然是 进程打开文件,那么最后一定是演化为两个结构体之间的指针关系
认识文件
你真的认识文件吗?如果是,那文件是什么呢?
文件里会存放数据,毋庸置疑;那如果现在新创建一个文件,里面毛都没有,请问这个新文件占据磁盘空间吗?占据吧?虽然里面没有内容,但是这个文件的文件名,创建时间,大小,权限,类型,路径,最近修改时间等等都要知道吧?
不说别的,你把数据存放在文件里是为什么?是为了有朝一日能更好的找到它并且顺利的把数据拿出来吧!既如此,文件的相关属性就必不可少!!!
所以:文件 = 文件属性 + 文件内容,那么 描述文件的结构体 大差不差是 存放管理文件的相关属性 的!!!
理解文件
不要受程序语言影响,我们 在意的一直都是进程和文件的关系,语言编译运行后不就是进程吗?
所以操作文件的本质是:进程在操作文件
用户如何通过进程操作文件呢?
文件是在磁盘硬盘上的,磁盘硬盘是外设啊,是硬件资源,所以你 向文件中写入本质上就是向外设中写入!
你是用户啊,你有资格 直接 写入吗?不好意思,没有
因为 OS 才是软硬件的管理者,要想写入文件,也就是外设,你绕不开 OS ,那怎么办?
OS 就必须为我们提供系统调用,而我们在任何一门语言里使用的文件接口函数,一定是对 系统调用 封装的结果
所以除了 库函数,我们还可以直接使用 系统调用 来操作文件
使用系统调用对文件操作
open
这是 打开文件 的系统调用
使用 man 2 open 命令查看该 系统调用 原型:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
需要包以下头文件:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
仔细阅读以下代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{// system callumask(0);int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);if (fd < 0){perror("open");return 1;}return 0;
}
此时,如果当前路径没有此 log.txt 文件,那将会被创建:
- 上面的代码创建出来的
log.txt文件权限是-rw-rw-rw-,即:所有角色都具有读写权限- 现在大可以把
open的第三个参数去掉,用第一个原型open;会发现编译运行后的log.txt文件权限是乱码哦 - 为什么?使用 系统调用 就是让 OS 帮你做事情,OS 如何得知你要创建的文件应该是什么权限呢?所以 第三个参数就是要指明,被创建的文件的权限!
- 那
umask(0);是什么意思?如果不带这一行代码,会发现编译运行后的log.txt文件权限是-rw-rw-r--,就是 权限掩码 造成的
- 现在大可以把
- 而
open第二个参数作用,就是指明打开文件的操作,O_WRONLY是只写,O_CREAT是创建(如果没有此文件就创建)- 那为什么会存在两个
open呢?因为第一个两个参数的open是操作已存在的文件呐!所以压根不需要传什么看不懂的权限
- 那为什么会存在两个
权限掩码
umask(0); 这一步,是在程序编译为可执行文件运行之后,动态的 调整 当前进程 对应的创建文件时的掩码;可是系统中人家自己就有 权限掩码 (umask 命令就能查询),那上述代码里是要创建权限为 666 的文件,进程会使用哪个掩码呢?
一般采用 就近原则,有自己设置的就用自己设置的,没有就用系统的
flags 参数(标记位传参)
这似乎是个 int 整型对吧,那为何是上述代码样式的传参呢?
O_WRONLY | O_CREAT
我们知道一个 int 整型是 32 位 bit ,所以一定可以使用比特位进行标志位的传递,这是 OS 设计很多系统调用的常见方法
通俗点讲,这个 flags 看起来是个整数,但咱是按比特位来使用;所以在本质上,flags 是一张 位图
而类似 O_WRONLY 这样的参数全部都是大写的,按照编程习惯,很容易就能想到这是一个 宏
我们直接设计一个 传递 位图标记位 的函数来帮助理解,仔细观察下面代码:
#include <stdio.h>#define ONE 1 // 1 0000 0001
#define TWO (1 << 1) // 2 0000 0010
#define THREE (1 << 2) // 4 0000 0100
#define FOUR (1 << 3) // 8 0000 1000void Print(int flags)
{if (flags & ONE)printf("one\n");if (flags & TWO)printf("two\n");if (flags & THREE)printf("three\n");if (flags & FOUR)printf("four\n");
}int main()
{Print(ONE);printf("\n");Print(TWO);printf("\n");Print(ONE | TWO);printf("\n");Print(ONE | TWO | THREE);printf("\n");Print(ONE | FOUR);printf("\n");Print(ONE | TWO | THREE | FOUR);printf("\n");return 0;
}
很显然,这和上面 open 里的用法一模一样
使用标记位组合的方式一次向指定函数传递多种标记位 ,日后可以将 one two three 的打印变成函数调用,轻松实现相关功能
这就是 标记位传参
所以 O_WRONLY 和 O_CREAT 等等之类的选项就可以直接理解了,是只有一个比特位为 1 的宏,彼此之间宏值不重复,而此时我们只需要理解更多的像这样的选项表示的含义即可 (见名知意)!!!
close
这是 关闭文件 的系统调用
还是 man 2 命令查看:
man 2 close
查看该 系统调用 原型:
int close(int fd);
需要包以下头文件:
#include <unistd.h>
参数就是 open 返回值呢 ^ ^
write
这是 向文件写入 的系统调用,将指定缓冲区写入指定文件,需指明缓冲区的大小
使用 man 2 write 命令查看该 系统调用 原型:
ssize_t write(int fd, const void *buf, size_t count);
需要包以下头文件:
#include <unistd.h>
此系统调用的原型,一看便知其意,应该无需解释,下面演示使用:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>int main()
{// system callumask(0);int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);if (fd < 0){perror("open");return 1;}const char* message = "Hello Linux File!!!\n";write(fd, message, strlen(message));close(fd);return 0;
}
这里需要注意,我们使用的是 strlen 而不是 sizeof ,因为字符串后面要有 '\0' 是你 C 语言的规定,关我文件什么事?而 '\0' 也不是我们要的内容,所以不能是 sizeof
编译通过,删除 原 log.txt 文件,运行可执行文件,会有新 log.txt 生成,可使用 cat log.txt 命令查看文件内容
这很简单,无需解释
现在我们将 message 内容改为 "aaaa" ,此时重新编译,不删除 原 log.txt 文件,直接运行可执行文件,会是什么结果?
运行 cat log.txt 命令,如下结果:
aaaao Linux File!!!
诶? 竟然是从头开始写入,但老内容没有被清空,而是覆盖写入!!!,所以 O_WRONLY | O_CREAT 虽然表示 文件不存在即创建,存在即打开写入,但 默认不清空文件
那我就是要 清空文件 呢?带上 O_TRUNC 选项(意思为 截断)即可:
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
那么现在的意思是:以写的方式打开文件,文件不存在就创建,存在就打开并清空原内容
好样的,就是本文开头使用 C 语言库函数 fopen 的 'w' 打开方式文件的含义
那如果现在我想要追加写入怎么办?就是 C 语言库函数 fopen 的 'a' 打开文件方式的含义
还是核心要义:现在只需找到和意义对应的选项即可!就是 O_APPEND 选项,如下使用即可:
int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
几个问题
open 的返回值
成功了就会创建一个新的文件描述符用来返回,失败了就返回 -1
那这个 int 类型的 fd 究竟是什么呢?
如果你打印 fd 的值就会发现,最小的值是从 3 开始的,那 0,1,2 去哪了?没有并不是不用,而是被其他文件占据了
其实是以下含义:
0:标准输入 --> 常规对应 键盘1:标准输出 --> 常规对应 显示器2:标准错误 --> 常规对应 显示器
当然啦,在 C 语言中也会 默认给我们打开 相应的这三个 文件流 :
stdin:标准输入流stdout:标准输出流stderr:标准错误流
下图 把这几个文件流是当作文件来看 的!!!
因为从类型可以看出,和 C 语言库函数 fopen 函数的返回值是一样的!!!


所以,printf 可以做的操作,fprintf 也可以做,就是需要 指明是什么流 罢了
既然上面 fd 值为 1,2,3 的文件是 默认打开 的,那也就是说我可以直接向 标准输出文件 写入内容,看看会不会在 显示器 上打印就是了,编译运行如下代码即可:
int main()
{ const char* message = "Hello System Call!!!\n";write(1, message, strlen(message));return 0;
}
验证过的都知道,一定是可以的!!!
文件描述符
上面的例子也看到了,调用 write 系统调用 向特定文件里写入居然是使用 fd 这样的整型数字,这到底是什么意思?
现在我们站在 OS 的角度宏观调查 文件管理 的方式:
前面提到 能操作文件的是进程;但一个进程可以打开很多文件,一台机器里运行那么多进程,在磁盘中可能有上万文件,光是被打开就可能有上百文件,OS 要知道哪些文件被打开了,哪些文件正在被读,哪些文件正在被写,哪些文件正准备要被关闭等等;所以 OS 得具备准确管理大量文件的能力
OS 怎么对 被打开的文件 做管理呢? 先描述,再组织,所以 OS 一定会对每一个被打开的文件创建 内核数据结构,名为 struct file ,里面一定包含可以完整描述文件的属性:权限,以什么方式被打开,标记位……
那么在 OS 内核里,有多少文件就有多少 struct file ,所以在 OS 内核里一定会有大量 struct file ,怎么被组织起来呢?高效的数据结构(Linux 是双链表),那么 OS 内部就会使用 双链表组织 这些 struct file ,那么 OS 对文件的管理就转变为了对链表的增删查改!!!
而 struct file 内部一定会有一个指针,指向 文件内核级的缓存,其实就是 OS 给我们申请的一块内存;而 文件 = 属性 + 内容 ,那么将来 OS 会使用磁盘文件的属性初始化 struct file 的内容,而内容会直接 load 进这片 文件内核级的缓存
未来想读,直接从这片缓存里读;想修改写入,会先在这片缓存里修改写入,再由 OS 刷新进入磁盘里
注意:每一个被打开的文件都有自己的 struct file ,而每一个 struct file 都有自己的 文件内核级的缓存
但现在有这么多 struct file ,怎么知道它们都是被哪个进程打开的呢?所以一定要有方法可以表征进程和它打开的文件的关系,因为 OS 把文件是管理在一起的!那么在进程 PCB 里存在属性结构体 struct files_struct* files ,而在其内部,会包含一个 数组 !!!数组的原型为 struct file* fd_array[N] ,只要是数组,就必定有自己的 下标 ,而这个数组是指针为 struct file* 的 指针数组,想要进程和文件产生关系,只需要将文件 struct file 的地址依次填入特定的下标中,现在每一个 struct file 结构体也都对应一个下标
所以现在一个 进程要想操控文件,只需要把此文件的 struct file 对应在 struct file* fd_array[N] 数组中的 下标 返回给上层,上层拿着这个 int 下标,也就是 fd 就可以访问文件了
所以 fd 的本质就是:内核进程和文件映射关系的数组下标 ,而 fd 的名字就叫做:文件描述符

文件描述符分配规则
在 files_struct 数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符
理解读写
读
如果现在一个进程要想读文件 log.txt ,肯定会先打开文件 log.txt ,接着利用磁盘内有关属性初始化对应的 struct file ,然后将其内容拷贝进 文件内核级的缓存
然后会把 文件内核级的缓存 里的数据拷贝进上层应用层
如果进程要读的数据不在这个该缓冲区里,OS 就会将你的进程阻塞住(或者挂起),然后从磁盘里把想要的数据拷贝进缓冲区,完事之后再唤醒该进程,再做拷贝(拷贝数据时进程是被链接到磁盘的等待队列里的,详情见往期本人拙作)
写
如果文件缓冲区没有内容倒也好说,直接将数据拷贝进缓冲区里,然后再由 OS 刷新到磁盘里
那缓冲区要是有数据呢?是修改数据呢?一样的,是先把数据读进缓冲区里修改,然后再由 OS 定期刷新即可
所以 对文件的修改是内存级的修改,是读进来之后把文件改完再刷出去的,哪怕只是修改一个字节,一个比特
结论
无论读写,都必须在合适的时候,让 OS 把文件的内容读到文件缓冲区中
所以无论对于 write 还是 read ,本质上都是拷贝作用!
open 的作用
- 创建 文件结构体
file - 开辟 文件缓冲区 的空间,加载文件数据(可能会延后)
- 查进程的 文件描述符表
- 将 文件结构体
file地址填入对应表的 下标 中 - 返回 下标
理解 Linux 系统一切皆文件
现在可以理解 OS 内核数据结构里的文件,可以是一台机器不止 OS ,还有硬件呢
都知道可以从键盘读数据,往显示器打印刷新数据,那请问如何做到呢?这可是硬件,而读写数据肯定都是从文件角度出发的,不然要重新搞一套机制实现硬件的读写吗,那怎么可能,所以文件和这些硬件有什么关系呢?
所有像磁盘键盘鼠标什么的外设,在冯诺依曼体系结构里被称为 IO 设备,而每一种设备我们关心的就俩:属性和操作方法!!!
同样的,OS 要对每一种设备做管理,同样的六字真言: 先描述,再组织 ,所以每一种设备都存在可以完美描述它的结构体 struct device ,里面拥有必不可少的属性:名字,类型,状态,厂商等等
虽然属性不一样,但他们的类别是一样的!都是用结构体 struct device 描述的,可是 刚刚这些属性并不重要,重要的是方法
每一个设备需不需要方法?需要,不然你怎么操作它?以读和写操作为例:键盘需要读写方法吗?键盘似乎是用来读的,好像没有往键盘写的需求, 但依然需要写的函数,只是会将它置为空!!!
这个理解太重要了,没有往键盘写的需求为什么要设计一个这样的空函数呢?不急我们继续往下说:
除了读写,键盘肯定还会有其他这样的操作函数;而其他设备也一样,会有和键盘一样的读写函数以及其他操作函数;但经验告诉我,每一个设备的操作方法函数实现一定是不一样的,不然为啥是不同的设备呢?而这一层操作往往是设计硬件的工程师完成的,叫做驱动
驱动控制我们的设备去操作,例如读写之类的,这也可以理解,下面 重点来了:
OS 依然会对每一个被打开的硬件设备做管理,而对每一个设备,OS 都会构建 struct file ,虽然里面会包含相关文件的属性,但也一定会包含可以调用底层驱动的 函数指针,因为不同硬件相同功能的驱动接口设计一定是大差不差的,在 struct file 里存放对应驱动的 函数指针 ;如此一来,每一个硬件对应的 struct file 都会有全部操作的 函数指针,因为 OS 毕竟不知道每一个硬件的特性,所以类似没有往键盘写的需求情况下,依然要给出写的驱动,就是这个原因
所以 struct file 在底层还要有自己的 方法指针表,里面都是 函数指针
如果现在要从键盘读数据,OS 就可以找到键盘的 struct file ,调用其内部的关于 read 的 函数指针,紧接着通过 函数指针 找到键盘关于 read 的驱动,就可 完美实现键盘和文件的关联
其他硬件也是如此,现在站在 OS 的角度,不需要关心底层硬件的差异,因为我们读写硬件外设的方法都是调用对应的 函数指针 : 想读谁,直接调用谁的 struct file 里关于读的 函数指针,至于如何实现读,那是驱动的事,和我 OS 没有半毛钱关系!!!
以上技术叫什么呀?如果是使用 C++ 的类来封装这个 struct file ,那这一定会使用 多态 技术!!!
所以在上层看到的视角就是 一切皆文件
而 OS 操作系统这一层又叫做 vfs (virtual file system):虚拟文件系统

那么现在就有很多事情都能说的通了,比如键盘输入为什么有缓冲区?这是因为你的键盘对于 OS 而言是个文件,是文件自然有文件缓冲区啊;所以 OS 从键盘文件的缓冲区读数据,键盘也会将数据送进自己对应的文件缓冲区,而键盘也就是对应 标准输入流(stdin),文件描述符 为 0 的 struct file ,就这么简单
文件描述符 fd 和 C 语言库函数里的 FILE*
通过上面的理解,OS 只认 文件描述符 fd 来操作文件,那 C 语言库函数 里的 FILE* 是如何操控文件的呢?
那第一个问题就是 FILE 是什么?这是 C 语言提供的 结构体类型
但是由于 OS 只认 文件描述符 fd 来操作文件,所以直接大胆猜想,文件结构体 FILE 底层一定封装了 文件描述符 fd ,而在 FILE 里,是一个名为 _fileno 的成员,代码证明:
int main()
{FILE* fp = fopen("log.txt", "w");if (NULL == fp){perror("fopen");return 1;}// 文件描述符 fd 打印printf("fp: %d\n", fp->_fileno);fwrite("Hello", 5, 1, fp);fclose(fp);return 0;
}
咱们之前不是说 stdin , stdout , stderror 不是对应文件描述符 0,1,2 吗?验证:
printf("stdin -> fd: %d\n", stdin->_fileno);
printf("stdout -> fd: %d\n", stdout->_fileno);
printf("stderr -> fd: %d\n", stderr->_fileno);
结论:所有 C 语言上的文件操作函数,底层本质都是对 系统调用 的封装
相关文章:
Linux 文件 IO 管理(第一讲)
Linux 文件 IO 管理(第一讲) 回顾 C 语言文件操作,提炼理解新创建的文件为什么被放在可执行文件的同级目录下?上述 log.txt 何时被创建?又是谁在打开它?那文件没有被打开的时候在哪里?一个进程可…...
Uniapp + Vue3 + Vite +Uview + Pinia 实现购物车功能(最新附源码保姆级)
Uniapp Vue3 Vite Uview Pinia 实现购物车功能(最新附源码保姆级) 1、效果展示2、安装 Pinia 和 Uview3、配置 Pinia4、页面展示 1、效果展示 2、安装 Pinia 和 Uview 官网 https://pinia.vuejs.org/zh/getting-started.html安装命令 cnpm install pi…...

人工智能和大模型的简介
文章目录 前言一、大模型简介二、大模型主要功能1、自然语言理解和生成2、文本总结和翻译3、文本分类和信息检索4、多模态处理三、大模型的技术特性1、深度学习架构2、大规模预训练3、自适应能力前言 随着技术的进步,人工智能(Artificial Intelligence, AI)和机器学习(Mac…...

java -- JDBC
一.JDBC概述: 过java语言操作数据库中的数据。 1.JDBC概念 JDBC(Java DataBase Connectivity,java数据库连接)是一种用于 执行SQL语句的Java API。JDBC是Java访问数据库的标准规范,可以 为不同的关系型数据库提供统一访问,它由…...

supermap iclient3d for cesium模型沿路径移动
可以直接settimeout隔一段时间直接设置位置属性,但是得到的结果模型不是连续的移动,如果想要连续的移动,就需要设置一个时间轴,然后给模型传入不同时间时的位置信息,然后就可以了。 开启时间轴 let start Cesium.Jul…...

基于AlexNet实现猫狗大战
卷积神经网络介绍 卷积神经网络(Convolutional Neural Network,简称CNN),是一种深度学习模型,特别适用于处理图像、视频等数据。它的核心思想是利用卷积层(Convolutional layers)来提取输入数据…...

1.接口测试基础
一、为什么要做接口测试? 1)前后端分离(前端调用后端接口,不测的话接口有问题,功能一定有问题) 2)项目一般都不是独立的,经常要调用外部的项目,项目和项目之间交换数据&a…...

使用mlp算法对Digits数据集进行分类
程序功能 这个程序使用多层感知机(MLP)对 Digits 数据集进行分类。程序将数据集分为训练集和测试集,创建并训练一个具有两个隐藏层的 MLP 模型。训练完成后,模型对测试数据进行预测,并通过准确率、分类报告和混淆矩阵…...

滑动窗口(2)_无重复字符的最长字串
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 滑动窗口(2)_无重复字符的最长字串 收录于专栏【经典算法练习】 本专栏旨在分享学习算法的一点学习笔记,欢迎大家在评论区交流讨论💌 目…...

c语言 —— 结构变量
1.结构变量的定义 类型和变量是不同的概念,只能对变量进行赋值、存取或运算操作,而不能对一个类型进行这些操作。因此在声明了结构类型后,还需要定义结构变量,以便在程序中引用它。结构变量和其他变量一样,必须先定义后使用,定义方法有以下3种: (1)先定义结构类型,再定…...

一个py脚本,提供处理 GET 请求返回网站数据,处理 POST 请求接收并打印数据。支持跨域访问。
from flask import Flask, jsonify, request from flask_cors import CORSapp Flask(__name__)# 允许跨域请求 CORS(app)app.route(/getapi/getadate/test2, methods[GET]) def get_data():response_data {"sites": [{"name": "菜鸟教程", &qu…...

【Elasticsearch系列六】系统命令API
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

c++概念
C语言设计期末考试知识点 1. 基础语法 变量和数据类型: int, float, double, char, bool 等基本数据类型。常量:const 关键字。变量的作用域:局部变量、全局变量。 输入输出: cin 和 cout:标准输入输出流。格式化输出…...

Makefile 学习笔记(一)gcc编译过程
环境准备 .linux 系统(虚拟机) VS code linux 编译过程 预处理: 把.h .c 展开形成一个文件.宏定义直接替换 头文件 库文件 .i 汇编: .i 生成一个汇编代码文件 .S 编译: .S 生成一个 .o .obj 链接: .o 链接 .exe .elf gcc c语言 g c语言 gcc的使用 …...

mybatis的基本使用与配置
注释很详细,直接上代码 项目结构 源码 UserMapper package com.amoorzheyu.mapper;import com.amoorzheyu.pojo.User; import org.apache.ibatis.annotations.Mapper; import org.apache.ibatis.annotations.Select;import java.util.List;Mapper //在运行时生成代…...

2022高教社杯全国大学生数学建模竞赛C题 问题三问题四 Python代码
目录 问题33.1 对附件表单 3 中未知类别玻璃文物的化学成分进行分析,鉴别其所属类型3.2 对分类结果的敏感性进行分析 问题44.1 针对不同类别的玻璃文物样品,分析其化学成分之间的关联关系绘图散点图相关系数图 问题3 3.1 对附件表单 3 中未知类别玻璃文物…...

易于理解和实现的Python代码示例
一些示例代码段,但请注意,由于无法直接执行或访问特定环境,将提供一些通用的、易于理解和实现的Python代码示例。这些示例旨在展示编程的不同方面,从基础到稍微复杂一点的概念。 示例1:简单的Python函数 def greet(n…...
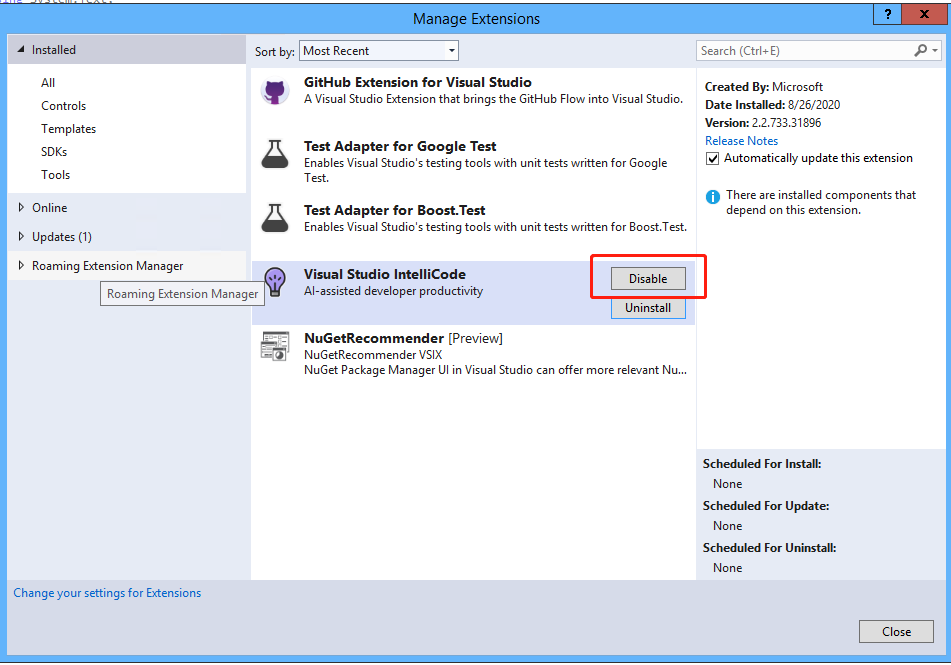
Visual Studio 2019/2022 IntelliCode(AI辅助IntelliSense)功能介绍
IntelliCode 不知在多久以前,我装上了Visual Studio 2019,写代码时,就注意到了下面这样的东西:带五角星的提示。 这个带五角星的提示功能叫做IntelliCode。 我们知道Visual Studio 有个强大的功能叫做Intellisense(智能感知)&am…...

mac安装swoole过程
1.很重要的是得根据自己环境的php版本来选择swoole版本!否则都是做无用功。 Swoole 文档 2.通常pecl install swoole是安装最新版本的,当然安装的方式很多种,这里选择编译安装,因为可以选择不同的swoole版本进行安装,…...

代码随想录算法训练营第三十二天 | 509. 斐波那契数,70. 爬楼梯,746. 使用最小花费爬楼梯
第三十二天打卡,动态规范第一天!今天比较简单,主要理解dp的概念 509.斐波那契数列 题目链接 解题过程 状态转移方程 dp[i] dp[i - 1] dp[i - 2]; 动态规划 class Solution { public:int fib(int n) {if (n < 2) return n;int dp[n …...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

从API Key管理视角看Taotoken平台的安全与审计功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API Key管理视角看Taotoken平台的安全与审计功能 对于依赖大模型API进行开发的团队而言,API Key的管理与安全是项目稳…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...