Python热频随机森林分类器算法模型模拟
🎯要点
- 研究发射测量斜率和时滞热频率表征,使用外推法计算三维磁场并定性比较
- 使用基于焓的热演化环模型模拟每条线的热力学响应,测试低频、中频和高频热场景
- 使用光学薄、高温、低密度等离子体的单位体积辐射功率或发射率公式等建模计算
- 使用直方图显示发射测量斜率,计算互相关映射
🍪语言内容分比


🍇Python随机森林模型
引导聚合
在需要良好模型可解释性的应用中,决策树效果非常好,尤其是在深度较小的情况下。然而,具有真实世界数据集的决策树具有很大的深度,深度较高的决策树更容易过度拟合,从而导致模型的方差更大。随机森林模型探索了决策树的这一缺点。在随机森林模型中,原始训练数据是随机抽样并替换的,从而生成小的数据子集(见下图)。这些子集也称为引导样本。然后,这些引导样本作为训练数据输入到许多大深度的决策树中。每个决策树都基于这些引导样本单独训练。这种决策树的聚合称为随机森林集成。集成模型的最终结果通过计算所有决策树的多数票来确定。由于每个决策树都以不同的训练数据集作为输入,因此原始训练数据集中的偏差不会影响从决策树聚合中获得的最终结果。
生成有放回的引导样本:

随机森林算法
随机森林算法有三个主要超参数,需要在训练之前设置。这些包括节点大小、树的数量和采样的特征数量。从这里开始,随机森林分类器可用于解决回归或分类问题。随机森林算法由一组决策树组成,集合中的每棵树都由从有替换训练集中抽取的数据样本组成,称为引导样本。在该训练样本中,三分之一被留作测试数据,称为袋外样本。然后通过特征装袋注入另一个随机性实例,为数据集增加更多多样性并降低决策树之间的相关性。根据问题的类型,预测的确定会有所不同。对于回归任务,将对各个决策树进行平均,对于分类任务,多数投票(即最常见的分类变量)将产生预测类。最后,然后使用袋外样本进行交叉验证,最终确定该预测。

随机森林算法结合了 (1) 引导聚合和 (2) 特征随机性,使用同一数据集构建许多决策树。
- 引导聚合是一种在给定迭代次数和变量(引导样本)内随机抽取数据子集的技术。通常对所有迭代和样本的预测进行平均,以获得最可能的结果。重要的是要理解,它不是将数据“分块”成小块并在其上训练单个树,而是仍然保持初始数据大小。这是一个应用集成模型的示例。
- 特征随机性的主要作用是降低决策树模型之间的相关性。与可以利用所有特征来辨别最佳节点分割的决策树相比,随机森林算法将随机选择这些特征进行决策。最终,这也允许在不同的特征上进行训练。
Python分类器
import pandas as pd
import numpy as np
from umap import UMAP
import seaborn as sns
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1.anchored_artists import AnchoredSizeBar
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.cluster import AgglomerativeClustering
from sklearn.neighbors import kneighbors_graph
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
mypath = '*insert file path/waveforms.csv'
data = pd.read_csv(mypath, index_col = 'uid')
print(f'{data.shape[0]} unique experiment identifiers (uid), recorded with a sampling frequency (KHz) of {((data.shape[1]-1)/5)}')
data.organoid.value_counts()
定义可视化颜色
mycolors = {'Data_D': '#FFA500','Data_G': '#4169E1', 'Data_F': '#FF4500', 'Data_C': '#9400D3', 'Data_A': '#32CD32', 'Data_E': '#228B22', 'Data_G_V2' : '#006400', 'Data_H': '#00BFFF', 'Data_E_V2': '#DC143C', 'Data_F_V2': '#0000FF', 'Data_B': '#000000', }
data['color'] = data['organoid'].apply(lambda orgID: mycolors[orgID])
可视化唯一的实验标识符
fig, ax = plt.subplots(figsize=(15, 8))
sns.barplot(x=data.organoid.value_counts().index, y=data.organoid.value_counts(), palette=mycolors)plt.xticks(rotation=30,fontsize=14)
plt.yticks(fontsize=14)
ax.set_xlabel('Class type', fontsize=16)
ax.set_ylabel('Number of waveforms', fontsize=16)
plt.rcParams["font.family"] = "Arial"right_side = ax.spines["right"]
right_side.set_visible(False)
top_side = ax.spines["top"]
top_side.set_visible(False)
plt.savefig('Figures/barplot.png', dpi = 300, bbox_inches="tight")
plt.show()
鉴于我们正在分析细胞外记录,我们将可视化每个数据集类别产生的平均波形。
class_names = data['organoid'].unique()
fig, ax = plt.subplots(1,9, figsize=(24,4.5))
for unique_class in class_names: df_new = data[data['organoid'] == unique_class] df_new = df_new.iloc[:,:-2].to_numpy() data_mean_perclass = np.mean(df_new, axis=0)sampling_freq = np.linspace(0, 5, 150)
for i in range(class_names.shape[0]): if unique_class == class_names[i]:for row_num in range(df_new.shape[0]): ax[i].plot(sampling_freq, df_new[row_num,:], color = 'lightgray')ax[i].plot(sampling_freq,data_mean_perclass, color=mycolors[unique_class], linewidth=3)ax[i].set_ylim([-1.8, 1.8])ax[i].grid()ax[i].axis('off')ax[i].title.set_text(unique_class) plt.rcParams["font.family"] = "Arial"else: continuescalebar = AnchoredSizeBar(ax[8].transData, 1, "1 ms", 'lower right', frameon=False, size_vertical=0.02, pad=0.1)ax[8].add_artist(scalebar)plt.savefig('Figures/spikes.png', dpi = 300)
👉参阅、更新:计算思维 | 亚图跨际
相关文章:
Python热频随机森林分类器算法模型模拟
🎯要点 研究发射测量斜率和时滞热频率表征,使用外推法计算三维磁场并定性比较使用基于焓的热演化环模型模拟每条线的热力学响应,测试低频、中频和高频热场景使用光学薄、高温、低密度等离子体的单位体积辐射功率或发射率公式等建模计算使用直…...

C++11新增特性:lambda表达式、function包装器、bind绑定
一、lambda表达式 1)、为啥需要引入lambda? 在c98中,我们使用sort对一段自定义类型进行排序的时候,每次都需要传一个仿函数,即手写一个完整的类。甚至有时需要同时实现排升序和降序,就需要各自手写一个类&…...
简介及python代码)
动态主题模型DTM(Dynamic topic model)简介及python代码
文章目录 DTM模型简介DTM实现1:gensim.models.ldaseqmodel包DTM实现2:gensim.models.wrappers.dtmmodel.DtmModel包DTM模型简介 DTM模型(Dynamic Topic Model)是一种用于文本数据分析的概率模型,主要用于发现文本数据背后的主题结构和主题的演化过程。DTM模型是LDA模型的…...

GDPU MySQL数据库 天码行空1 数据库的创建和基本操作
💖 必看 MySQL 5.7默认的 innodb 存储引擎Windows10 和 Centos7 一、实验目的 1.熟知机房用机安全规则。 2.通过上机操作,加深对数据库系统理论知识的理解;通过使用具体的DBMS,了解一种实际的数据库管理系…...

《告别卡顿,一键卸载!IObit Uninstaller 13 免费版让电脑重获新生》
随着电脑使用时间的增长,各种软件的安装和卸载,难免会让电脑变得臃肿不堪,运行速度大不如前。你是否也有过这样的烦恼?别担心,IObit Uninstaller 13 免费版来帮你解决这个问题! IObit Uninstaller 13 是一…...
)
Python|基于Kimi大模型,实现上传文档并进行对话(5)
前言 本文是该专栏的第5篇,后面会持续分享AI大模型干货知识,记得关注。 我们在利用大模型进行文本处理的时候,可能会遇到这样的情况。 笔者在这里举个例子,比如说我们的目标文本是一堆docx文档,或者pdf文档,doc文档等等。这时需要大模型对这样的文档文本内容进行语义处…...

C++设计模式——Prototype Pattern原型模式
一,原型模式的定义 原型模式是一种创建型设计模式,它允许通过克隆已有对象来创建新对象,从而无需调用显式的实例化过程。 原型模式的设计,使得它可以创建一个与原型对象相同或类似的新对象,同时又可以减少对象实例化…...

Vue3 : ref 与 reactive
目录 一.ref 二.reactive 三.ref与reactive的区别 四.总结 一.ref 在 Vue 3 中,ref 是一个用于创建可读写且支持数据跟踪的响应式引用对象。它主要用于在组件内部创建响应式数据,这些数据可以是基本类型(如 number、string、boolean&…...

html实现好看的多种风格手风琴折叠菜单效果合集(附源码)
文章目录 1.设计来源1.1 风格1 -图文结合手风琴1.2 风格2 - 纯图片手风琴1.3 风格3 - 导航手风琴1.4 风格4 - 双图手风琴1.5 风格5 - 综合手风琴1.6 风格6 - 简描手风琴1.7 风格7 - 功能手风琴1.8 风格8 - 全屏手风琴1.9 风格9 - 全屏灵活手风琴 2.效果和源码2.1 动态效果2.2 源…...

Nacos分布式配置中心
分布式配置的优势: 不需要重新发布我们的应用 新建父工程:【将它作为跟 所以要把父工程里面的src删掉】 新建子模块: 新建bootstrap.properties: 在使用Nacos作为配置中心时,推荐在bootstrap.properties中配置Nacos相…...

C# WinForm 中 DataGridView 实现单元格cell 能进编辑状态但是不能修改单元格的效果
在Windows Forms(WinForms)开发中,DataGridView 控件是一个功能强大的组件, 用于显示和管理表格数据。无论是展示大量数据,还是实现交互式的数据操作, DataGridView 都能提供多样的功能支持,比如…...
GANs-生成对抗网络
参考: https://mp.weixin.qq.com/s?__bizMjM5ODIwNjEzNQ&mid2649887403&idx3&snf61fc0e238ffbc56a7f1249b93c20690&chksmbfa0f632460e035f00be6cc6eb09637d91614e4c31da9ff47077ca468caad1ee27d08c04ca32&scene27 https://cloud.tencent.com…...

e冒泡排序---复杂度O(X^2)
排序原理: 1.比较相邻的元素。如果前一个元素比后一个元素大,就交换这两个元素的位置。 2.对每一对相邻元素做同样的工作,从开始第一对元素到结尾的最后一对元素。最终最后位置的元素就是最大值, public class 冒泡排序 {public static void main(String[] args) {I…...

C语言--结构体(学习笔记)
内容借鉴于b站杜远超官方频道(C语言结构体详解【干货】) 首先C语言中定义变量格式为“数据类型 变量名”,如int a; float b;等等。 那么结构体则是将多个变量(数据类型 变量名)结合在一起的一种新的数据类型&…...

Vue项目中实现用户登录后跳回原地址
本地存储 在 Vue 3 中,你可以使用 Vue Router 和 sessionStorage 或 localStorage 来实现用户登录后跳回原来的页面。以下是一种常见的实现方式: 在用户登录之前,记录当前页面的路由路径: 在需要登录的页面组件中,在…...

【Google Chrome Windows 64 version及 WebDriver 版本】
最近升级到最新版本Chrome后发现页面居然显示错乱实在无语, 打算退回原来的版本, 又发现官方只提供最新的版本下载, 为了解决这个问题所有收集了Chrome历史版本的下载地址分享给大家. Google Chrome Windows version 64 位 VersionSize下载地址Date104.0.5112.10282.76 MBhtt…...

[ffmpeg] 音视频编码
本文主要梳理 ffmpeg 中音视频编码的常用函数 API调用 常用 API const AVCodec *avcodec_find_encoder(enum AVCodecID id); AVCodecContext *avcodec_alloc_context3(const AVCodec *codec); void avcodec_free_context(AVCodecContext **avctx); int avcodec_open2(AVCode…...
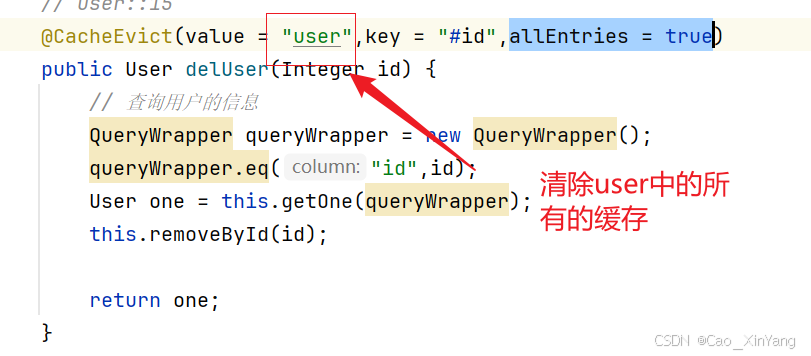
springboot+redis+缓存
整合 添加依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 连接redis,配置yml文件 主机 端口号 数据库是哪一个 密码 配置类 p…...

关于http的206状态码和416状态码的意义、断点续传以及CORS使用Access-Control-Allow-Origin来允许跨域请求
一、关于http的206状态码和416状态码的意义及断点续传 HTTP 2xx范围内的状态码表明客户端发送的请求已经被服务器接受并且被成功处理了,HTTP/1.1 206状态码表示客户端通过发送范围请求头Range抓取到了资源的部分数据,一般用来解决大文件下载问题,一般CDN…...

SOMEIP_ETS_114: SD_Entries_Length_wrong_combined
测试目的: 验证DUT能够拒绝一个包含两个正确条目但条目数组长度不正确的SubscribeEventgroup消息,并以SubscribeEventgroupNAck作为响应。 描述 本测试用例旨在确保DUT遵循SOME/IP协议,当接收到一个条目数组长度与实际条目数量不匹配的Sub…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...