使用Faiss进行K-Means聚类
📝 本文需要的前置知识:Faiss的基本使用
目录
- 1. 源码剖析
- 1.1 参数解释
- 2. 聚类过程详解
- 2.1 初始化聚类中心
- 2.2 分配步骤(Assignment)
- 2.3 更新步骤(Update)
- 2.4 收敛与终止条件
- 3. GPU 加速
- 3.1 索引结构与 GPU
- 3.2 GPU 训练过程
- 3.3 多 GPU 训练
- 4. 聚类后的操作
- 4.1 获取聚类中心
- 4.2 分配新数据点
- 4.3 评估聚类效果
- 5. 参数调优与最佳实践
- 5.1 选择合适的簇数(k)
- 5.2 调整迭代次数(niter)
- 5.3 使用 GPU 的优化
- 5.4 数据预处理
- 6. 实际案例分析
- 6.1 数据集准备
- 6.2 聚类模型训练
- 6.3 聚类结果分析
- 6.4 使用聚类结果进行图像检索
- 7. 常见问题与解决方案
- 7.1 内存不足
- 7.2 聚类效果不佳
- 7.3 GPU 资源不足
- 8. 高级用法与扩展
- 9. 性能优化技巧
- Ref
1. 源码剖析
如下是 Kmeans 的源码(摘自faiss 1.7.4版本):
class Kmeans:"""Object that performs k-means clustering and manages the centroids.The `Kmeans` class is essentially a wrapper around the C++ `Clustering` object.Parameters----------d : intDimension of the vectors to cluster.k : intNumber of clusters.gpu: bool or int, optionalFalse: don't use GPUTrue: use all GPUsnumber: use this many GPUsprogressive_dim_steps:Use a progressive dimension clustering (with that number of steps).Subsequent parameters are fields of the Clustering object. The most important are:niter: int, optionalClustering iterations.nredo: int, optionalRedo clustering this many times and keep the best.verbose: bool, optionalspherical: bool, optionalDo we want normalized centroids?int_centroids: bool, optionalRound centroids coordinates to integer.seed: int, optionalSeed for the random number generator."""def __init__(self, d, k, **kwargs):"""d: input dimension, k: nb of centroids. Additionalparameters are passed on the ClusteringParameters object,including niter=25, verbose=False, spherical=False."""self.d = dself.k = kself.gpu = Falseif "progressive_dim_steps" in kwargs:self.cp = ProgressiveDimClusteringParameters()else:self.cp = ClusteringParameters()for k, v in kwargs.items():if k == 'gpu':if v is True or v == -1:v = get_num_gpus()self.gpu = velse:# if this raises an exception, it means that it is a non-existent fieldgetattr(self.cp, k)setattr(self.cp, k, v)self.centroids = Nonedef train(self, x, weights=None, init_centroids=None):"""Perform k-means clustering.On output of the function call:- The centroids are in the centroids field of size (`k`, `d`).- The objective value at each iteration is in the array obj (size `niter`).- Detailed optimization statistics are in the array iteration_stats.Parameters----------x : array_likeTraining vectors, shape (n, d), `dtype` must be float32 and n shouldbe larger than the number of clusters `k`.weights : array_likeWeight associated to each vector, shape `n`.init_centroids : array_likeInitial set of centroids, shape (n, d).Returns-------final_obj: floatFinal optimization objective."""x = np.ascontiguousarray(x, dtype='float32')n, d = x.shapeassert d == self.dif self.cp.__class__ == ClusteringParameters:# Regular clusteringclus = Clustering(d, self.k, self.cp)if init_centroids is not None:nc, d2 = init_centroids.shapeassert d2 == dfaiss.copy_array_to_vector(init_centroids.ravel(), clus.centroids)if self.cp.spherical:self.index = IndexFlatIP(d)else:self.index = IndexFlatL2(d)if self.gpu:self.index = faiss.index_cpu_to_all_gpus(self.index, ngpu=self.gpu)clus.train(x, self.index, weights)else:# Not supported for progressive dimassert weights is Noneassert init_centroids is Noneassert not self.cp.sphericalclus = ProgressiveDimClustering(d, self.k, self.cp)if self.gpu:fac = GpuProgressiveDimIndexFactory(ngpu=self.gpu)else:fac = ProgressiveDimIndexFactory()clus.train(n, swig_ptr(x), fac)centroids = faiss.vector_float_to_array(clus.centroids)self.centroids = centroids.reshape(self.k, d)stats = clus.iteration_statsstats = [stats.at(i) for i in range(stats.size())]self.obj = np.array([st.obj for st in stats])# Copy all the iteration_stats objects to a Python arraystat_fields = 'obj time time_search imbalance_factor nsplit'.split()self.iteration_stats = [{field: getattr(st, field) for field in stat_fields}for st in stats]return self.obj[-1] if self.obj.size > 0 else 0.0def assign(self, x):"""Assign data points to the nearest cluster centroid.Parameters----------x : array_likeData points to assign, shape (n, d), `dtype` must be float32.Returns-------D : array_likeDistances of each data point to its nearest centroid.I : array_likeIndex of the nearest centroid for each data point."""x = np.ascontiguousarray(x, dtype='float32')assert self.centroids is not None, "Should train before assigning"self.index.reset()self.index.add(self.centroids)D, I = self.index.search(x, 1)return D.ravel(), I.ravel()
聚类时基本只会用到 ClusteringParameters(),以下是该类的源码:
class ClusteringParameters(object):r"""Class for the clustering parameters. Can be passed to theconstructor of the Clustering object."""thisown = property(lambda x: x.this.own(), lambda x, v: x.this.own(v), doc="The membership flag")__repr__ = _swig_reprniter = property(_swigfaiss.ClusteringParameters_niter_get, _swigfaiss.ClusteringParameters_niter_set, doc=r""" clustering iterations""")nredo = property(_swigfaiss.ClusteringParameters_nredo_get, _swigfaiss.ClusteringParameters_nredo_set, doc=r""" redo clustering this many times and keep best""")verbose = property(_swigfaiss.ClusteringParameters_verbose_get, _swigfaiss.ClusteringParameters_verbose_set)spherical = property(_swigfaiss.ClusteringParameters_spherical_get, _swigfaiss.ClusteringParameters_spherical_set, doc=r""" do we want normalized centroids?""")int_centroids = property(_swigfaiss.ClusteringParameters_int_centroids_get, _swigfaiss.ClusteringParameters_int_centroids_set, doc=r""" round centroids coordinates to integer""")update_index = property(_swigfaiss.ClusteringParameters_update_index_get, _swigfaiss.ClusteringParameters_update_index_set, doc=r""" re-train index after each iteration?""")frozen_centroids = property(_swigfaiss.ClusteringParameters_frozen_centroids_get, _swigfaiss.ClusteringParameters_frozen_centroids_set, doc=r"""use the centroids provided as input and do notchange them during iterations""")min_points_per_centroid = property(_swigfaiss.ClusteringParameters_min_points_per_centroid_get, _swigfaiss.ClusteringParameters_min_points_per_centroid_set, doc=r""" otherwise you get a warning""")max_points_per_centroid = property(_swigfaiss.ClusteringParameters_max_points_per_centroid_get, _swigfaiss.ClusteringParameters_max_points_per_centroid_set, doc=r""" to limit size of dataset""")seed = property(_swigfaiss.ClusteringParameters_seed_get, _swigfaiss.ClusteringParameters_seed_set, doc=r""" seed for the random number generator""")decode_block_size = property(_swigfaiss.ClusteringParameters_decode_block_size_get, _swigfaiss.ClusteringParameters_decode_block_size_set, doc=r""" how many vectors at a time to decode""")def __init__(self):r""" sets reasonable defaults"""_swigfaiss.ClusteringParameters_swiginit(self, _swigfaiss.new_ClusteringParameters())__swig_destroy__ = _swigfaiss.delete_ClusteringParameters
1.1 参数解释
Kmeans 初始化时的部分参数来源于 ClusteringParameters,以下是对常用参数的解释:
def __init__(self, d, k, **kwargs):"""Parameters----------d : int参与聚类的向量的维度k : int聚类后簇的个数gpu: bool or int, optionalFalse: 不使用GPUTrue: 使用所有GPUnumber: 使用number个GPU,number=-1时也代表使用所有GPU默认为Falseniter: int, optional聚类算法的迭代次数,默认为25verbose: bool, optional是否输出详细信息,默认为Falsespherical: bool, optional是否在每次迭代后归一化聚类中心,默认为Falsemin_points_per_centroid: int, optional每个簇中的最小点数,默认为39max_points_per_centroid: int, optional每个簇中的最大点数,默认为256seed: int, optional随机种子,默认为1234"""
设 n n n 为参与训练的向量个数, k k k 为簇数,一些注意事项总结如下:
- 若
n > max_points_per_centroid * k,则只会采样max_points_per_centroid * k个向量进行训练,默认是 256 k 256k 256k 个;若n < min_points_per_centroid * k或n < k,则会直接报错。理想情况是min_points_per_centroid * k <= n <= max_points_per_centroid * k。保险起见,通常会选择设置min_points_per_centroid = 1和max_points_per_centroid = n。 - 当迭代次数超过 20 20 20 次且 n > 1000 k n>1000k n>1000k 时,继续增加迭代次数或训练点数量并不会显著提高算法性能,所以faiss默认会选择下采样。
2. 聚类过程详解
在了解了 Kmeans 类和 ClusteringParameters 的基本结构与参数之后,接下来我们深入剖析其聚类过程。这一过程主要包括以下几个步骤:
- 初始化聚类中心(Initialization)
- 分配数据点到最近的聚类中心(Assignment)
- 更新聚类中心(Update)
- 迭代直到收敛或达到最大迭代次数
2.1 初始化聚类中心
初始化是 K-Means 算法中至关重要的一步,因为不良的初始化可能导致收敛到局部最优解。faiss 的 Kmeans 类默认使用 k-means++ 初始化方法,这是一种改进的初始化策略,能够显著提高聚类的效果和收敛速度。
def initialize_centroids(self, x):"""初始化聚类中心,使用 k-means++ 算法。Parameters----------x : array_like训练向量,形状为 (n, d)。Returns-------centroids : array_like初始化后的聚类中心,形状为 (k, d)。"""n, d = x.shapecentroids = np.empty((self.k, d), dtype='float32')# 随机选择第一个聚类中心indices = np.random.choice(n)centroids[0] = x[indices]# 计算每个点到最近聚类中心的距离distances = np.full(n, np.inf)for i in range(1, self.k):distances = np.minimum(distances, np.linalg.norm(x - centroids[i-1], axis=1)**2)probabilities = distances / distances.sum()cumulative_probabilities = np.cumsum(probabilities)r = np.random.rand()next_index = np.searchsorted(cumulative_probabilities, r)centroids[i] = x[next_index]return centroids
上述代码展示了一个简单的 k-means++ 初始化过程。faiss 通过内部的优化和并行计算,实际实现可能更加高效。
2.2 分配步骤(Assignment)
在每次迭代中,算法需要将每个数据点分配到距离最近的聚类中心。faiss 使用了高效的索引结构来加速这一过程,特别是在高维数据和大规模数据集的情况下。
def assign(self, x):"""将数据点分配到最近的聚类中心。Parameters----------x : array_like数据点,形状为 (n, d),dtype 必须为 float32。Returns-------D : array_like每个数据点到最近聚类中心的距离。I : array_like每个数据点所属的聚类中心索引。"""x = np.ascontiguousarray(x, dtype='float32')assert self.centroids is not None, "Should train before assigning"self.index.reset()self.index.add(self.centroids)D, I = self.index.search(x, 1)return D.ravel(), I.ravel()
faiss 利用了 IndexFlatL2 或 IndexFlatIP 索引,根据是否进行球面聚类(spherical)来选择不同的距离度量。使用 GPU 加速后,可以显著提升大规模数据的分配速度。
2.3 更新步骤(Update)
一旦所有数据点被分配到最近的聚类中心,下一步就是更新这些聚类中心的位置。新的聚类中心通常是分配到该簇的所有数据点的均值。
def update_centroids(self, x, assignments):"""更新聚类中心为每个簇中所有数据点的均值。Parameters----------x : array_like数据点,形状为 (n, d)。assignments : array_like每个数据点所属的聚类中心索引。Returns-------new_centroids : array_like更新后的聚类中心,形状为 (k, d)。"""new_centroids = np.zeros((self.k, self.d), dtype='float32')counts = np.bincount(assignments, minlength=self.k)np.add.at(new_centroids, assignments, x)new_centroids /= counts[:, np.newaxis]return new_centroids
在 faiss 中,更新步骤同样经过优化以适应大规模数据和高维空间的需求。
2.4 收敛与终止条件
K-Means 算法通过不断迭代分配和更新步骤,直到满足以下任一终止条件:
- 达到最大迭代次数(
niter) - 聚类中心的变化低于某个阈值(收敛)
在 faiss 中,Clustering 对象会记录每次迭代的目标函数值(即总的平方误差),并通过比较相邻迭代的目标函数值来判断是否收敛。
def has_converged(self, old_obj, new_obj, threshold=1e-4):"""判断聚类是否收敛。Parameters----------old_obj : float前一次迭代的目标函数值。new_obj : float当前迭代的目标函数值。threshold : float收敛阈值。Returns-------converged : bool是否收敛。"""return abs(old_obj - new_obj) < threshold
faiss 通过内部的 iteration_stats 数组记录每次迭代的详细信息,包括目标函数值、时间消耗等,以便进行后续分析和调优。
3. GPU 加速
faiss 的一大优势在于其对 GPU 的支持,这使得在处理大规模、高维度的数据时,聚类过程能够显著加快。以下是 faiss 在 Kmeans 类中如何利用 GPU 的一些关键点。
3.1 索引结构与 GPU
在 train 方法中,根据 spherical 参数的不同,faiss 选择不同的索引结构:
- IndexFlatL2:用于欧氏距离(L2 距离)
- IndexFlatIP:用于内积距离(通常用于球面聚类)
if self.cp.spherical:self.index = IndexFlatIP(d)
else:self.index = IndexFlatL2(d)
一旦索引结构确定,faiss 会将其转换为 GPU 索引:
if self.gpu:self.index = faiss.index_cpu_to_all_gpus(self.index, ngpu=self.gpu)
faiss.index_cpu_to_all_gpus 函数会自动将索引复制到所有可用的 GPU 上,充分利用 GPU 的并行计算能力。
3.2 GPU 训练过程
在 GPU 上训练 K-Means 时,faiss 通过以下方式优化计算:
- 并行计算距离:利用 GPU 的并行计算能力,快速计算所有数据点到聚类中心的距离。
- 高效内存管理:通过 CUDA 流和批处理,最大限度地减少数据传输时间。
- 优化的算法实现:利用高效的 CUDA 核函数,优化 K-Means 的各个步骤。
以下是一个使用 GPU 进行训练的示例:
import faiss
import numpy as np# 生成随机数据
d = 128 # 向量维度
k = 100 # 聚类中心数
n = 1000000 # 数据点数量x = np.random.random((n, d)).astype('float32')# 初始化 Kmeans 对象,使用所有可用的 GPU
kmeans = faiss.Kmeans(d=d, k=k, niter=20, verbose=True, gpu=True)# 训练聚类模型
kmeans.train(x)# 获取聚类中心
centroids = kmeans.centroids# 分配数据点到最近的聚类中心
D, I = kmeans.assign(x)
通过上述代码,可以看到 faiss 的 GPU 加速使用非常简洁,只需在初始化时设置 gpu=True 即可。
3.3 多 GPU 训练
对于极大规模的数据集,单个 GPU 可能无法承载全部计算需求。faiss 通过支持多 GPU 训练,进一步提升了聚类的效率。
# 使用指定数量的 GPU 进行训练
ngpu = 4 # 假设有4个 GPU
kmeans = faiss.Kmeans(d=d, k=k, niter=20, verbose=True, gpu=ngpu)
kmeans.train(x)
在多 GPU 环境下,faiss 会将数据和计算任务分配到多个 GPU 上,充分利用并行计算资源,显著缩短聚类时间。
4. 聚类后的操作
完成聚类后,faiss 提供了一些便捷的方法来进行后续操作,例如获取聚类中心、分配新数据点到最近的聚类中心等。
4.1 获取聚类中心
聚类完成后,聚类中心存储在 centroids 属性中,可以方便地进行访问和保存。
# 获取聚类中心
centroids = kmeans.centroids# 保存聚类中心到文件
np.save('centroids.npy', centroids)# 加载聚类中心
loaded_centroids = np.load('centroids.npy')
4.2 分配新数据点
使用训练好的聚类模型,可以将新的数据点快速分配到最近的聚类中心。
# 生成新的随机数据
new_x = np.random.random((10000, d)).astype('float32')# 分配新数据点
D, I = kmeans.assign(new_x)# D 是距离,I 是聚类中心索引
这种分配操作在许多应用场景中非常有用,例如在向量检索系统中,快速定位相似向量的簇。
4.3 评估聚类效果
faiss 记录了每次迭代的目标函数值和其他统计信息,可以用于评估聚类的效果和收敛情况。
# 获取目标函数值
final_obj = kmeans.obj[-1]
print(f"Final objective value: {final_obj}")# 获取详细的迭代统计信息
iteration_stats = kmeans.iteration_stats
for i, stats in enumerate(iteration_stats):print(f"Iteration {i}: Obj={stats['obj']}, Time={stats['time']}, "f"Imbalance={stats['imbalance_factor']}, Nsplit={stats['nsplit']}")
通过分析这些统计信息,可以了解聚类过程中的优化情况和可能的瓶颈。
5. 参数调优与最佳实践
为了获得最佳的聚类效果和性能,合理地调优 Kmeans 类的参数是至关重要的。以下是一些参数调优的建议和最佳实践:
5.1 选择合适的簇数(k)
选择合适的簇数是 K-Means 聚类中的一个关键问题。常用的方法包括:
- 肘部法则(Elbow Method):绘制不同 k 值下的目标函数值(总的平方误差),选择拐点所在的 k 值。
- 轮廓系数(Silhouette Coefficient):评估聚类的紧密度和分离度,选择轮廓系数最高的 k 值。
- 业务需求:根据具体应用场景的需求,选择合适的簇数。
import matplotlib.pyplot as plt# 计算不同 k 值下的目标函数值
ks = range(10, 200, 10)
objs = []
for k in ks:kmeans = faiss.Kmeans(d=d, k=k, niter=20, verbose=False, gpu=True)kmeans.train(x)objs.append(kmeans.obj[-1])# 绘制肘部图
plt.plot(ks, objs, 'bx-')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Objective value')
plt.title('Elbow Method for Optimal k')
plt.show()
5.2 调整迭代次数(niter)
niter 参数决定了聚类算法的最大迭代次数。默认值通常足够,但在某些情况下,增加迭代次数可以获得更好的聚类结果,尤其是在数据集较为复杂时。
# 增加迭代次数以提高聚类精度
kmeans = faiss.Kmeans(d=d, k=k, niter=100, verbose=True, gpu=True)
kmeans.train(x)
5.3 使用 GPU 的优化
在处理大规模数据时,合理配置 GPU 资源可以显著提升性能:
- 选择合适的 GPU 数量:根据数据规模和硬件资源,选择合适的 GPU 数量进行并行计算。
- 优化批处理大小:调整批处理大小以充分利用 GPU 的计算能力,避免内存不足或计算资源浪费。
- 监控 GPU 利用率:使用工具如
nvidia-smi监控 GPU 的利用率,确保计算资源的高效使用。
# 查看当前 GPU 使用情况
nvidia-smi
5.4 数据预处理
良好的数据预处理可以提升聚类效果和算法的收敛速度:
- 标准化(Normalization):将数据标准化到相同的尺度,避免某些特征对距离度量的影响过大。
- 降维(Dimensionality Reduction):使用 PCA 等方法降低数据维度,减少计算量,同时可能提升聚类效果。
- 去除异常值(Outlier Removal):去除数据中的异常值,避免对聚类结果产生不利影响。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA# 标准化数据
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x)# 降维
pca = PCA(n_components=100)
x_pca = pca.fit_transform(x_scaled).astype('float32')
6. 实际案例分析
为了更好地理解 faiss 的 K-Means 实现,下面通过一个实际案例进行演示。假设我们有一个大规模的图像特征数据集,目标是将这些特征聚类为多个类别,以便于后续的图像检索或分类任务。
6.1 数据集准备
我们使用 faiss 自带的随机数据作为示例:
import faiss
import numpy as np# 设置随机种子以保证结果可重复
np.random.seed(42)# 生成随机图像特征,假设每个特征是 512 维
d = 512
k = 1000 # 预设的簇数
n = 10000000 # 1千万个数据点# 生成随机数据
x = np.random.random((n, d)).astype('float32')
6.2 聚类模型训练
使用 faiss 的 Kmeans 类进行聚类训练:
# 初始化 Kmeans 对象,使用所有可用的 GPU
kmeans = faiss.Kmeans(d=d, k=k, niter=20, verbose=True, gpu=True)# 训练聚类模型
kmeans.train(x)# 获取聚类中心
centroids = kmeans.centroids
6.3 聚类结果分析
训练完成后,我们可以分析聚类结果,包括每个簇的大小、聚类中心的分布等。
# 获取每个簇的大小
cluster_sizes = np.bincount(kmeans.assign(x)[1], minlength=k)# 绘制簇大小分布
import matplotlib.pyplot as pltplt.hist(cluster_sizes, bins=50)
plt.xlabel('Cluster Size')
plt.ylabel('Number of Clusters')
plt.title('Distribution of Cluster Sizes')
plt.show()
通过上述分析,可以观察到聚类中心的分布是否均匀,以及是否存在某些簇过大或过小的情况。
6.4 使用聚类结果进行图像检索
聚类结果可以用于加速图像检索。例如,将查询图像的特征首先分配到最近的簇,然后只在该簇内进行详细的相似度计算,从而减少计算量。
def search(query, centroids, kmeans, top_n=10):"""使用聚类结果进行快速图像检索。Parameters----------query : array_like查询图像的特征,形状为 (d,)。centroids : array_like聚类中心,形状为 (k, d)。kmeans : faiss.Kmeans训练好的 Kmeans 对象。top_n : int返回最近的 top_n 个结果。Returns-------indices : array_like最近的图像索引。distances : array_like最近的图像距离。"""# 分配查询到最近的聚类中心D, I = kmeans.assign(query.reshape(1, -1))cluster_idx = I[0]# 获取该簇内所有数据点的索引cluster_mask = (kmeans.assign(x)[1] == cluster_idx)cluster_data = x[cluster_mask]# 计算查询与簇内数据点的距离index = faiss.IndexFlatL2(d)index.add(cluster_data)D, I = index.search(query.reshape(1, -1), top_n)return I.ravel(), D.ravel()# 示例查询
query = np.random.random((d,)).astype('float32')
indices, distances = search(query, centroids, kmeans, top_n=10)
print(f"Top 10 nearest indices: {indices}")
print(f"Top 10 nearest distances: {distances}")
通过这种方式,检索效率得到了显著提升,特别是在处理大规模数据集时。
7. 常见问题与解决方案
在使用 faiss 进行 K-Means 聚类时,可能会遇到一些常见问题。以下是一些常见问题及其解决方案:
7.1 内存不足
问题描述:在处理大规模数据集时,可能会遇到内存不足的问题,尤其是在 CPU 内存或 GPU 显存有限的情况下。
解决方案:
- 下采样:选择数据集的一部分进行聚类训练。
- 增大
max_points_per_centroid:调整ClusteringParameters中的max_points_per_centroid参数,控制每个簇的最大数据点数。 - 使用多 GPU:分散内存压力,利用多个 GPU 分担计算和存储。
# 使用部分数据进行训练
sample_size = 500000 # 50万数据点
indices = np.random.choice(n, sample_size, replace=False)
x_sample = x[indices]kmeans.train(x_sample)
7.2 聚类效果不佳
问题描述:聚类结果不理想,可能是因为聚类中心初始化不当、数据预处理不充分等原因。
解决方案:
- 调整初始化方法:尝试不同的初始化策略,如随机初始化或 k-means++。
- 数据标准化:对数据进行标准化或归一化处理,确保各特征在相同尺度上。
- 增加迭代次数:适当增加
niter参数,允许算法有更多的迭代机会进行优化。
# 标准化数据
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
x_scaled = scaler.fit_transform(x)# 重新训练聚类模型
kmeans = faiss.Kmeans(d=d, k=k, niter=50, verbose=True, gpu=True)
kmeans.train(x_scaled)
7.3 GPU 资源不足
问题描述:在 GPU 资源有限的情况下,可能无法加载整个数据集或聚类模型。
解决方案:
- 分批处理:将数据集分成多个批次,逐批进行聚类训练。
- 减少簇数:适当减少簇数,降低 GPU 的计算和存储压力。
- 升级硬件:如果条件允许,升级 GPU 硬件以满足计算需求。
# 分批训练示例
batch_size = 1000000 # 每批 100万数据点
for i in range(0, n, batch_size):batch = x[i:i+batch_size]kmeans.train(batch)
8. 高级用法与扩展
faiss 不仅支持基本的 K-Means 聚类,还提供了许多高级功能和扩展,适用于更复杂的应用场景。
增量聚类(Incremental Clustering)
在某些应用中,数据是动态增长的,此时需要对新数据进行增量聚类,而不是重新训练整个模型。faiss 提供了相关的 API 支持增量聚类。
# 假设已有初始聚类模型
kmeans = faiss.Kmeans(d=d, k=k, niter=20, verbose=True, gpu=True)
kmeans.train(initial_x)# 增量训练新的数据
kmeans.train(new_x)
分布式聚类
对于极大规模的数据集,单机训练可能无法满足需求。faiss 通过分布式计算框架,支持在多台机器上进行聚类训练。
# 使用 faiss 的分布式 API 进行聚类
# 具体实现依赖于集群环境和分布式框架
自定义距离度量
除了默认的欧氏距离和内积距离,faiss 还支持自定义距离度量,以适应不同的应用需求。
# 定义自定义距离度量函数
def custom_distance(x, y):# 例如,使用曼哈顿距离return np.sum(np.abs(x - y), axis=1)# 在聚类过程中使用自定义距离
# 需要修改 faiss 的内部实现或扩展现有类
与其他算法结合
faiss 的聚类结果可以与其他算法结合,构建更复杂的机器学习管道。例如,将聚类结果作为分类器的输入特征,或结合深度学习模型进行特征学习。
from sklearn.linear_model import LogisticRegression# 使用聚类中心作为分类特征
cluster_features = kmeans.assign(x)[1]# 训练分类模型
clf = LogisticRegression()
clf.fit(cluster_features, labels)
9. 性能优化技巧
为了充分发挥 faiss 的性能,以下是一些性能优化的技巧:
数据存储格式
确保数据以连续的内存块存储,使用 float32 类型,这样可以提高数据访问和计算效率。
x = np.ascontiguousarray(x, dtype='float32')
并行计算
利用 faiss 的多线程和多 GPU 支持,充分利用计算资源。
import faiss# 设置线程数
faiss.omp_set_num_threads(8)# 使用多 GPU
kmeans = faiss.Kmeans(d=d, k=k, niter=20, verbose=True, gpu=4)
预分配内存
对于大规模数据集,预先分配内存可以减少内存碎片和分配时间。
# 预分配聚类中心
centroids = np.empty((k, d), dtype='float32')
缓存优化
确保数据在内存中的布局有利于缓存访问,减少缓存未命中的次数。
# 确保数据按行主序存储
x = np.ascontiguousarray(x, dtype='float32')
Ref
[1] https://github.com/facebookresearch/faiss/wiki/FAQ
[2] https://github.com/facebookresearch/faiss
[3] Faiss GitHub Repository
[4] K-Means++: The Advantages of Careful Seeding
[5] Scikit-learn Clustering Documentation
相关文章:

使用Faiss进行K-Means聚类
📝 本文需要的前置知识:Faiss的基本使用 目录 1. 源码剖析1.1 参数解释 2. 聚类过程详解2.1 初始化聚类中心2.2 分配步骤(Assignment)2.3 更新步骤(Update)2.4 收敛与终止条件 3. GPU 加速3.1 索引结构与 G…...

通过hosts.allow和hosts.deny限制用户登录
1、Hosts.allow和host.deny说明 两个文件是控制远程访问设置的,通过设置这个文件可以允许或者拒绝某个ip或者ip段的客户访问linux的某项服务。如果请求访问的主机名或IP不包含在/etc/hosts.allow中,那么tcpd进程就检查/etc/hosts.deny。看请求访问的主机…...

PWN College 关于sql盲注
在这个场景中,我们需要利用SQL注入漏洞来泄露flag,但是应用程序并不会直接返回查询结果。相反,我们需要根据应用程序的行为差异(登录成功与否)来推断查询结果。这就是所谓的"布尔盲注"(Boolean-b…...

【Linux篇】Http协议(1)(笔记)
目录 一、http基本认识 1. Web客户端和服务器 2. 资源 3. URI 4. URL 5. 事务 6. 方法 7. 状态码 二、HTTP报文 1. 报文的流动 (1)流入源端服务器 (2)向下游流动 2. 报文语法 三、TCP连接 1. TCP传输方式 2. TCP连…...

员工疯狂打CALL!解锁企业微信新玩法,2024年必学秘籍来啦!
现在工作离不开电脑手机,公司交流也得用新招。腾讯出了个企业微信,就是给公司用的聊天工具。它功能强大,操作简便,很多公司用它来让工作更高效,团队合作更紧密。接下来,我会简单说说怎么上手企业微信&#…...

Spring boot从0到1 - day01
前言 Spring 框架作为 Java 领域中最受欢迎的开发框架之一,提供了强大的支持来帮助开发者构建高性能、可维护的 Web 应用。 学习目标 Spring 基础 Spring框架是什么?Spring IoC与Aop怎么理解? Spring Boot 的快速构建 Spring 基础 学习…...

Flutter 项目结构的区别
如果需要调用原生代码,请创建一个plugin类型的项目开发。如果需要调用C语言,请参考文档:Flutter项目中调用C语言plugin 其实是 package 的一种,全称是 plugin package,我们简称为 plugin,中文叫插件。 1. A…...

EfficientFormerV2:重新思考视觉变换器以实现与MobileNet相当的尺寸和速度。
摘要 https://arxiv.org/pdf/2212.08059 随着视觉变换器(ViTs)在计算机视觉任务中的成功,近期的研究尝试优化ViTs的性能和复杂度,以实现在移动设备上的高效部署。提出了多种方法来加速注意力机制,改进低效设计…...

ASP.NET Core高效管理字符串集合
我们在开发 Web 项目时经常遇到需要管理各种来源的字符串集合(例如HTTP 标头、查询字符串、设置的值等)的情况。合理的管理这些字符串集合不仅可以减少出bug的几率,也能提高应用程序的性能。ASP.NET Core 为我们提供了一种特殊的只读结构体 S…...

vm-tools的卸载重装,只能复制粘贴,无法拖拽文件!
开始 ubuntu22.04 LTSVMwareTools-10.3.25-20206839.tar.gzVMware Workstation 17 Pro 各种该尝试的配置都尝试了,比如: 1.开启复制粘贴拖拽; 2.VMware Tools拖拽失效; 3.解决VMware无法拖拽. 均没有奏效. 安装过程报错, 报错异常: The installation of VMware Tools 10.3.25…...

Docker 容器网络技术
Docker 容器网络技术 一、概述 Docker 容器技术在微服务架构和云原生应用中扮演着重要角色。容器的轻量化和快速启动特性,使得它们成为现代应用部署的首选。然而,容器的网络连接和管理是一个复杂的问题,尤其是当涉及到容器间通信时。Docker…...

C++ 起始帧数、结束帧数、剪辑视频
C 指定起始帧数、结束帧数、 剪辑视频 C 无法直接用H264,只能用avi编码格式 #include <iostream> #include <opencv2/opencv.hpp>int main() {// 读取视频:创建了一个VideoCapture对象,参数为摄像头编号std::string path &quo…...

【项目一】基于pytest的自动化测试框架———解读requests模块
解读python的requests模块 什么是requests模块基础用法GET与POST的区别数据传递格式会话管理与持久性连接处理相应结果应对HTTPS证书验证错误处理与异常捕获 这篇blog主要聚焦如何使用 Python 中的 requests 模块来实现接口自动化测试。下面我介绍一下 requests 的常用方法、数…...

升级Ubuntu内核的几种方法
注意: Ubuntu主线内核由 Ubuntu 内核团队提供,用于测试和调试目的。 它们不受支持且不适合生产使用。 仅当它们可以解决当前内核遇到的关键问题时,才应该安装它们。 1、手动下载deb文件升级内核 来源:kernel.ubuntu.com/main…...

Android绘制靶面,初步点击位置区域划分取值测试
自定义View: public class TargetView extends View {private Paint paint;private int[] radii {100, 250, 400, 550, 700}; // 五个圆的半径private int numberOfSegments 8;private int[][] regionValues; // 存储每个区域的值public TargetView(Context cont…...
)
【SpringBoot】调度和执行定时任务--Quartz(超详细)
Quartz 是一个功能强大的任务调度框架,广泛用于在 Java 应用程序中定时执行任务,同时它支持 Cron 表达式、持久化任务、集群等特性。以下是 Quartz 的详细使用教程,包括安装、基本概念、简单示例和高级功能。 1. 安装 Quartz 首先ÿ…...
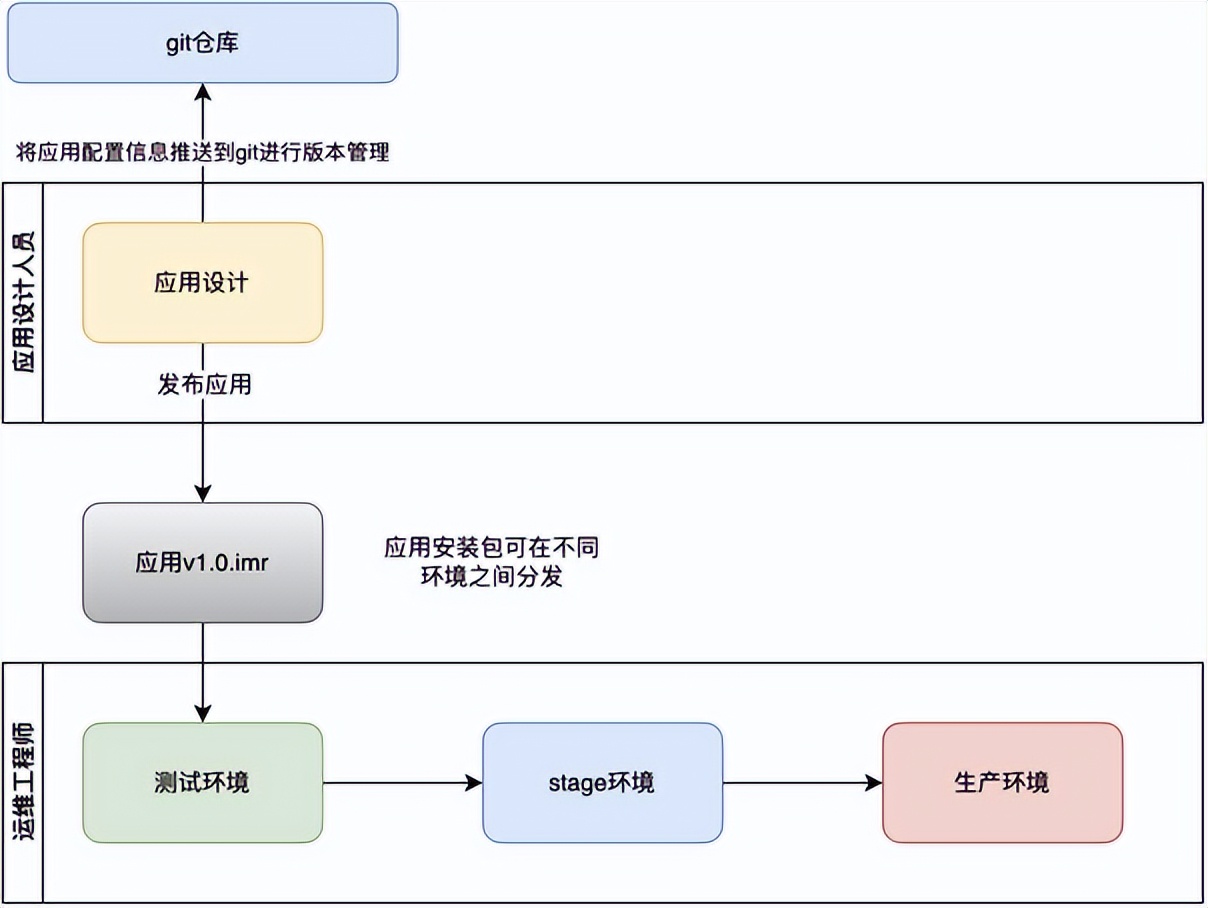
低代码开发平台系统架构概述
概述 织信低代码开发平台(产品全称:织信Informat)是一款集成了应用设计、运行与管理的综合性平台。它提供了丰富的功能模块,帮助用户快速构建、部署和维护应用程序。织信低代码平台通过集成丰富的功能模块,为用户提供…...

源码编译llama.cpp 、ggml 后端启用自定义BLAS加速
源码编译llama.cpp 、ggml 后端启用自定义BLAS加速 我在llama.cpp 官网上提交了我的解决方案:How to setup OpenBlas on windows? #625 GGML 官网 https://github.com/ggerganov/ggml/issues/959 windows on arm 编译 llama.cpp 、ggml 后端启用自定义BLAS加速 …...
glb数据格式
glb数据格式 glb 文件格式只包含一个glb 文件,文件按照二进制存储,占空间小 浏览 浏览glb工具的很多,ccs,3D查看器等都可以,不安装软件的话用下面网页加载就可以,免费 glTF Viewer (donmccurdy.com) glb…...

手语识别系统源码分享
手语识别检测系统源码分享 [一条龙教学YOLOV8标注好的数据集一键训练_70全套改进创新点发刊_Web前端展示] 1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 项目来源AACV Association for the Advancement of Computer Vision …...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...