EfficientFormerV2:重新思考视觉变换器以实现与MobileNet相当的尺寸和速度。
摘要
https://arxiv.org/pdf/2212.08059
随着视觉变换器(ViTs)在计算机视觉任务中的成功,近期的研究尝试优化ViTs的性能和复杂度,以实现在移动设备上的高效部署。提出了多种方法来加速注意力机制,改进低效设计,或结合适用于移动设备的轻量级卷积形成混合架构。然而,ViT及其变体仍然比轻量级CNNs有更高的延迟或更多的参数,即使是多年前的MobileNet也是如此。在实践中,延迟和大小对于在资源受限的硬件上有效部署至关重要。在这项工作中,我们探讨了一个核心问题,变换器模型能否像MobileNet一样快速运行并保持类似的大小?我们重新审视了ViTs的设计选择,并提出了一个低延迟和高参数效率的新型超网络。我们进一步引入了一种新的细粒度联合搜索策略,通过同时优化延迟和参数数量来寻找高效的架构。我们提出的模型,EfficientFormerV2,在ImageNet-1K上比MobileNetV2高出3.5%的top-1准确率,延迟和参数相似。这项工作证明了经过适当设计和优化的视觉变换器即使在MobileNet级别的大小和速度下也能实现高性能。
https://github.com/snap-research/EfficientFormer
- 引言
视觉变换器(ViTs)[21]的有前途的性能激发了许多后续工作进一步完善模型架构和改进训练策略,从而在大多数计算机视觉基准测试中取得了优越的结果,例如分类[51, 53, 8, 56]、分割[83, 15, 6]、检测[7, 46, 68]和图像合成[22, 27]。作为ViT的核心,多头自注意力(MHSA)机制被证明在模拟2D图像中的空间依赖性方面是有效的,实现了全局感受野。此外,MHSA通过注意力热图作为动态权重学习二阶信息,这在卷积神经网络(CNNs)[28]中是一个缺失的属性。然而,MHSA的成本也是显而易见的——与令牌数(分辨率)的二次计算复杂度相关。因此,ViTs往往比广泛采用的轻量级CNNs更具计算密集性并且有更高的延迟[34, 33],特别是在资源受限的移动设备上,限制了它们在现实世界应用中的广泛部署。
为了缓解这一限制,许多研究工作[58, 59, 60, 47]已经采取。其中,一个方向是减少注意力机制的二次计算复杂度。Swin[52]和随后的工作[20, 51]提出了基于窗口的注意力,使得感受野被限制在一个预定义的窗口大小内,这也启发了后续工作来改进注意力模式[11, 78, 81, 61]。通过预定义的注意力跨度,计算复杂度变为与分辨率线性相关。然而,复杂的注意力模式通常很难在移动设备上支持或加速,因为密集的形状和索引操作。另一条路径是将轻量级CNN和注意力机制结合起来形成混合架构[58, 13, 57]。好处是双重的。首先,卷积是移位不变的,并且擅长捕获局部和详细信息,这可以被认为是ViTs[28]的良好补充。其次,通过在早期阶段放置卷积,同时在最后几个阶段放置MHSA来模拟全局依赖性,我们可以自然地避免在高分辨率上执行MHSA并节省计算[50]。尽管取得了令人满意的性能,但延迟和模型大小仍然不如轻量级CNNs有竞争力。例如,MobileViT[58]在iPhone 12上比MobileNetV2慢至少5倍。正如适用于CNNs的,架构搜索、剪枝和量化技术也得到了深入研究[36, 37, 54, 38, 9, 47, 50]。然而,这些模型仍然出现了明显的缺点,例如,EfficientFormer-L1[47]在速度上与MobileNet相似,并且性能更好,但模型大小是2倍。因此,一个实际但具有挑战性的问题出现了:
我们能否设计一个既轻又快且保持高性能的基于变换器的模型?
在这项工作中,我们解决了上述问题,并提出了一种新的移动视觉骨干家族。我们考虑了三个重要因素:参数数量、延迟和模型性能,因为它们反映了磁盘存储和移动应用。首先,我们引入了新的架构改进,形成了一个强大的设计范式。其次,我们提出了一种细粒度的架构搜索算法,用于联合优化变换器模型的大小和速度。通过我们的网络设计和搜索方法,在保持高性能的同时,我们在各种模型大小和速度约束下获得了一系列的模型,命名为EfficientFormerV2。在完全相同的大小和延迟(在iPhone 12上)下,EfficientFormerV2-S0在ImageNet-1K[19]上比MobileNetV2高出3.5%的top-1准确率。与EfficientFormer-L1[47]相比,EfficientFormerV2-S1在性能相似的同时,体积小2倍,速度快1.3倍(表2)。我们进一步在下游任务(如检测和分割)中展示了有希望的结果(表3)。我们的贡献可以总结如下。
- 我们全面研究了移动友好的设计选择,并引入了新的变化,这是一个实用的指南,用于获得超高效的视觉变换器骨干。
- 我们提出了一种新的细粒度联合搜索算法,用于同时优化变换器模型的大小和速度,实现了优越的帕累托最优性。
- 我们首次展示了视觉变换器模型可以像MobileNetV2一样小和快,同时获得更好的性能。EfficientFormerV2可以作为各种下游任务的强大骨干。
- 相关工作
Vaswani等人[76]提出了注意力机制来模拟NLP任务中的序列,形成了变换器架构。变换器后来被Dosovitskiy等人[21]和Carion等人[7]应用于视觉任务。DeiT[72]通过蒸馏训练改进了ViT,并取得了与CNNs相媲美的性能。后来的研究通过引入层次设计[77, 74]、借助卷积注入局部性[26, 18, 28, 68]或探索不同类型的令牌混合,如局部注意力[52, 20]、空间MLP混合器[71, 70]和非参数化池混合器[86],进一步改进了ViTs。通过适当的变化,ViTs在下游视觉任务[83, 90, 89, 42, 41, 22, 87]中展示了强大的性能。为了从优势性能中受益,ViTs的有效部署已经成为一个研究热点,特别是对于移动设备[58, [13, 60, 57]。为了减少ViTs的计算复杂度,许多工作提出了新的模块和架构设计[40, 29, [23, 45, 65],而其他工作则消除了注意力机制中的冗余[78, 32, 10, 48, 16, 64, 75, 5]。类似于CNNs,架构搜索[12, 24, 9, 92, 50, 17, 80]、剪枝[88]和量化[54]也被探索用于ViTs。
我们总结了高效ViT研究的两个主要缺点。首先,许多优化措施不适合移动部署。例如,通过规范化注意力机制的范围或模式[52, 20, 11, 82],可以将注意力机制的二次计算复杂度降低到线性。尽管如此,复杂的重塑和索引操作甚至在资源受限的设备上都不受支持[47]。重新思考移动友好的设计至关重要。其次,尽管最近的混合设计和网络搜索方法揭示了具有强大性能的高效ViTs[58, 50, 47],它们主要优化了一个指标的帕累托曲线,而在其他方面则竞争力较弱。例如,MobileViT[58]在参数效率上表现优异,但比轻量级CNNs慢得多[66, 69]。EfficientFormer[47]在移动设备上速度极快,但模型大小巨大。LeViT[25]和MobileFormer[13]在FLOPs方面取得了有利的性能,但代价是多余的参数。
- 重新思考混合变换器网络
在本节中,我们研究了高效ViTs的设计选择,并引入了导致更小尺寸和更快速度而不会降低性能的变化。以EfficientFormer-L1[47]作为基线模型,因为它在移动设备上的性能优越。
3.1. 令牌混合器与前馈网络
引入局部信息可以提高性能,并使ViTs对缺乏显式位置嵌入更加健壮[6]。PoolFormer[86]和EfficientFormer[47]采用 3 × 3 3 \times 3 3×3平均池化层(图[2(a))作为局部令牌混合器。用相同内核大小的深度卷积(DWCONV)替换这些层不会引入延迟开销,而性能提高了0.6%,额外参数可以忽略不计(0.02 M)。此外,最近的工作[24, 6]表明,在ViTs的前馈网络(FFN)中注入局部信息建模层也有助于提高性能,而开销很小。值得注意的是,通过在FFN中放置额外的深度 3 × 3 3 \times 3 3×3卷积来捕获局部信息,原始局部混合器(池化或卷积)的功能被复制了。基于这些观察,我们移除了显式的残差连接局部令牌混合器,并将深度 3 × 3 3 \times 3 3×3 CONV移入FFN中,得到了一个启用局部性的统一FFN(图2(b))。我们将统一的FFN应用于网络的所有阶段,如图2(a,b)。这种设计修改简化了网络架构,只包含两种类型的块(局部FFN和全局注意力),并在相同的延迟下将准确性提高到80.3%(见表(1),参数开销很小(0.1 M)。更重要的是,这种修改使我们能够直接搜索具有确切数量模块的网络深度,以提取局部和全局信息,特别是在网络的后期阶段,如第4.2节所讨论。
3.2. 搜索空间细化
通过统一FFN和删除残差连接的令牌混合器,我们检查EfficientFormer的搜索空间是否仍然足够,特别是在深度方面。我们改变了网络深度(每个阶段的块数)和宽度(每个阶段的通道数),发现更深更窄的网络带来了更好的准确性(提高了0.2%),更少的参数(减少了0.13 M),以及更低的延迟(加速了0.1 ms),如表1所示。因此,我们将这个网络设置为新的基线(准确性80.5%),以验证后续的设计修改,并在第4.2节中启用一个更深的超网络进行架构搜索。
此外,具有进一步缩小的空间分辨率 ( 1 64 ) \left(\frac{1}{64}\right) (641)的5级模型已经在高效的ViT艺术中得到了广泛的应用[25, [13, 50]。为了证明我们是否应该从一个5级超网络开始搜索,我们向当前基线网络添加了一个额外的阶段,并验证了性能增益和开销。值得注意的是,尽管给定小特征分辨率的情况下计算开销不是问题,但额外的阶段是参数密集型的。因此,我们需要缩小网络尺寸(深度或宽度),以使参数和延迟与基线模型保持一致,以便进行公平比较。正如在表(1)中看到的,5级模型的最佳性能出人意料地下降到80.31%,参数更多(0.39 M),延迟开销(0.2 ms),尽管节省了MACs(0.12 G)。这与我们的直觉相符,即第五阶段在计算上是高效的,但在参数上是密集的。鉴于5级网络不能在我们的大小和速度范围内引入更多潜力,我们坚持4级设计。这种分析也解释了为什么一些ViTs在MACs-Accuracy方面提供了优秀的帕累托曲线,但在大小方面往往相当冗余[25, [13]。作为最重要的收获,优化单一指标很容易陷入困境,第4.2节中提出的联合搜索为此问题提供了可行的解决方案。
3.3. MHSA改进
然后我们研究了在不增加模型大小和延迟的额外开销的情况下提高注意力模块性能的技术。如图2(c)所示,我们研究了两种MHSA的方法。首先,我们通过添加深度 3 × 3 3 \times 3 3×3 CONV将局部信息注入到值矩阵(V)中,这也被[24, 68]采用。其次,我们通过添加跨头维度的全连接层使注意力头之间进行通信[67],如图2(c)所示的Talking Head。通过这些修改,我们将性能进一步提高到80.8%,与基线模型相比参数和延迟相似。
3.4. 在更高分辨率上的注意力
注意力机制对性能有益。然而,将其应用于高分辨率特征会损害移动效率,因为它具有与空间分辨率相对应的二次时间复杂度。我们研究了有效应用MHSA到更高分辨率(早期阶段)的策略。回想一下,在第3.3节中获得的当前基线网络中,MHSA仅在最后一个阶段使用,空间分辨率为输入图像的 1 32 \frac{1}{32} 321。我们将额外的MHSA应用于倒数第二阶段,特征大小为 1 16 \frac{1}{16} 161,并观察到准确性提高了0.9%。不利的一面是,推理速度几乎减慢了2.7倍。因此,有必要适当降低注意力模块的复杂性。
尽管一些工作提出了基于窗口的注意力[52, 20]或下采样键和值[44]来缓解这个问题,我们发现它们并不适合移动部署。基于窗口的注意力由于复杂的窗口划分和重排序,在移动设备上难以加速。至于在[44]中下采样键(K)和值(V),需要全分辨率的查询(Q)来保持注意力矩阵乘法后的输出分辨率(Out):
Out [ B , H , N , C ] = ( Q [ B , H , N , C ] ⋅ K [ B , H , C , N 2 ] T ) ⋅ V [ B , H , N 2 , C ] \text{Out}_{[B, H, N, C]}=\left(Q_{[B, H, N, C]} \cdot K_{\left[B, H, C, \frac{N}{2}\right]}^{T}\right) \cdot V_{\left[B, H, \frac{N}{2}, C\right]} Out[B,H,N,C]=(Q[B,H,N,C]⋅K[B,H,C,2N]T)⋅V[B,H,2N,C]
其中B, H, N, C分别表示批量大小、头数、令牌数和通道维度。基于我们的测试,模型的延迟仅降低到2.8 ms,仍然比基线模型慢2倍。因此,为了在网络的早期阶段执行MHSA,我们将所有查询、键和值下采样到一个固定的空间分辨率 ( 1 32 ) \left(\frac{1}{32}\right) (321),并将注意力的输出插值回原始分辨率以馈入下一层,如图2r(d)&(e)所示。我们将这种方法称为Stride Attention。如表1所示,这种简单的近似显著降低了延迟从3.5 ms到1.5 ms,并保持了有竞争力的准确性(81.5% vs. 81.7%)。
3.5. 双路径注意力下采样
大多数视觉骨干网络使用步进卷积或池化层来执行静态和局部下采样,并形成层次结构。一些最近的工作开始探索注意力下采样。例如,LeViT[25]和UniNet[50]提出通过注意力机制减半特征分辨率,以实现具有全局感受野的上下文感知下采样。具体来说,查询中的令牌数量减少了一半,以便注意力模块的输出被下采样:
Out [ B , H , N 2 , C ] = ( Q [ B , H , N 2 , C ] ⋅ K [ B , H , C , N ] T ) ⋅ V [ B , H , N , C ] . \text{Out}_{\left[B, H, \frac{N}{2}, C\right]}=\left(Q_{\left[B, H, \frac{N}{2}, C\right]} \cdot K_{[B, H, C, N]}^{T}\right) \cdot V_{[B, H, N, C]} \text{.} Out[B,H,2N,C]=(Q[B,H,2N,C]⋅K[B,H,C,N]T)⋅V[B,H,N,C].
然而,决定如何减少查询中的令牌数量并非易事。Graham等人[25]经验性地使用池化来下采样查询,而Liu等人[50]提出寻找局部或全局方法。为了在移动设备上实现可接受的推理速度,将注意力下采样应用于具有高分辨率的早期阶段是不利的,限制了现有作品在更高分辨率搜索不同下采样方法的价值。
相反,我们提出了一种结合策略,即双路径注意力下采样,它同时利用局部性和全局依赖性,如图2(f)。为了获得下采样的查询,我们使用池化作为静态局部下采样, 3 × 3 3 \times 3 3×3 DWCONV作为可学习的局部下采样,并将结果组合并投影到查询维度。此外,注意力下采样模块与常规步进CONV以残差连接形式连接,形成局部-全局方式,类似于下采样瓶颈[31]或倒置瓶颈[66]。如表11所示,通过稍微增加参数和延迟开销,我们进一步将准确性提高到81.8%,这也比仅使用注意力模块进行子采样,即注意力下采样的性能更好。
- EfficientFormerV2
如上所述,当前的艺术仅仅关注优化一个指标,因此要么在大小上冗余[47],要么在推理速度上慢[58]。为了找到最适合移动部署的视觉骨干,我们提出联合优化模型大小和速度。此外,第3节中的网络设计有利于更深的网络架构(第3.2节)和更多的注意力(第3.4节),这要求改进搜索空间和算法。接下来,我们介绍EfficientFormerV2的超网络设计及其搜索算法。
4.1. EfficientFormerV2的设计
如第3.2节所讨论的,我们采用4级层次设计,获得的特征尺寸分别为输入分辨率的 { 1 4 , 1 8 , 1 16 , 1 32 } \left\{\frac{1}{4}, \frac{1}{8}, \frac{1}{16}, \frac{1}{32}\right\} {41,81,161,321}。与其前身[47]类似,EfficientFormerV2以小内核卷积干开始嵌入输入图像,而不是使用非重叠补丁的低效嵌入,
left.j\right|{j-1}}, \frac{H}{4}, \frac{W}{4}}=\operatorname{stem}\left(\mathbb{X}{0}^{B, 3, H, W}\right)
KaTeX parse error: Can't use function '$' in math mode at position 46: …H和W分别是特征的高度和宽度,$̲\mathbb{X}_{j}$…
\mathbb{X}{i+1, j}^{B, C{j}, \frac{H}{2^{j+1}}, \frac{W}{2^{j+1}}}=S_{i, j} \cdot \operatorname{FFN}^{C_{j}, E_{i, j}}\left(\mathbb{X}{i, j}\right)+\mathbb{X}{i, j}
KaTeX parse error: Can't use function '$' in math mode at position 4: 其中$̲S_{i, j}$是可学习的层…
\mathbb{X}{i+1, j}^{B, C{j}, \frac{H}{2 j+1}, \frac{W}{2 j+1}}=S_{i, j} \cdot \operatorname{MHSA}\left(\operatorname{Proj}\left(\mathbb{X}{i, j}\right)\right)+\mathbb{X}{i, j}
KaTeX parse error: Can't use function '$' in math mode at position 24: …、键(K)和值(V)通过线性层$̲Q, K, V \leftar…
\operatorname{MHSA}(Q, K, V)=\operatorname{Softmax}\left(Q \cdot K^{T}+\mathrm{ab}\right) \cdot V
$$
其中ab是用于位置编码的可学习注意力偏置。
4.2. 联合优化模型大小和速度
尽管基线网络EfficientFormer[47]是通过延迟驱动搜索发现的,并且在移动设备上具有快速的推理速度,但搜索算法有两个主要缺点。首先,搜索过程仅受速度限制,导致最终模型参数冗余,如图1所示。其次,它只搜索深度(每个阶段的块数 N j N_{j} Nj)和阶段宽度 C j C_{j} Cj,这是粗粒度的。实际上,网络的大部分计算和参数都在FFNs中,参数和计算复杂度与扩展比率 E i , j E_{i, j} Ei,j线性相关。 E i , j E_{i, j} Ei,j可以独立于每个FFN指定,无需相同。因此,搜索 E i , j E_{i, j} Ei,j可以实现更细粒度的搜索空间,其中计算和参数可以在每个阶段内灵活且不均匀地分布。这是大多数最近的ViT NAS艺术[24, 50, 47]中缺失的属性,其中 E i , j E_{i, j} Ei,j每阶段保持相同。我们提出了一种搜索算法,可以实现每个块的灵活配置,联合约束大小和速度,并找到最适合移动设备的视觉骨干。
4.2.1 搜索目标
首先,我们介绍指导我们联合搜索算法的指标。鉴于网络的大小和延迟在评估移动友好模型时都很重要,我们考虑一个通用且公平的指标,更好地理解网络在移动设备上的性能。不失一般性
MES = Score ⋅ ∏ i ( M i U i ) − α i \text{MES}=\text{Score} \cdot \prod_{i}\left(\frac{M_{i}}{U_{i}}\right)^{-\alpha_{i}} MES=Score⋅i∏(UiMi)−αi
其中 i ∈ { size , latency , … } i \in \{ \text{size}, \text{latency}, \ldots\} i∈{size,latency,…},并且 α i ∈ ( 0 , 1 ] \alpha_{i} \in (0,1] αi∈(0,1]表示相应的重要性。 M i M_{i} Mi和 U i U_{i} Ui分别代表指标和其单位。分数是一个预定义的基础分数,为了方便起见,设置为100。模型大小是通过参数数量计算的,延迟是部署在设备上的模型的运行时间。由于我们专注于移动部署,使用MobileNetV2的大小和速度作为单位。具体来说,我们定义 U size = 3 M U_{\text{size}}=3 \text{M} Usize=3M,并且 U latency U_{\text{latency}} Ulatency作为在iPhone 12(iOS 16)上部署时1 ms延迟(使用CoreMLTools [I])。为了强调速度,我们设置 α latency = 1.0 \alpha_{\text{latency}}=1.0 αlatency=1.0和 α size = 0.5 \alpha_{\text{size}}=0.5 αsize=0.5。减小大小和延迟可以导致更高的MES,我们搜索MES-Accuracy的帕累托最优。MES的形式是通用的,可以扩展到其他感兴趣的指标,例如推理时间内存占用和能源消耗。此外,每个指标的重要性很容易通过适当定义 α i \alpha_{i} αi来调整。
4.2.2 搜索空间和超网络
搜索空间包括:(i)网络的深度,以每个阶段的块数 N j N_{j} Nj衡量,(ii)网络的宽度,即每个阶段的通道维度 C j C_{j} Cj,以及(iii)每个FFN的扩展比率 E i , j E_{i, j} Ei,j。MHSA的数量可以在深度搜索期间无缝确定,它控制着超网络中保留或删除一个块。因此,我们在超网络的最后两个阶段设置每个块为MHSA后跟FFN,并通过对深度搜索获得所需数量的全局MHSA的子网络。
超网络是通过使用可扩展网络[85]构建的,它以弹性深度和宽度执行,以实现纯评估基础的搜索算法。弹性深度可以通过随机路径增强[35]自然实现。至于宽度和扩展比率,我们遵循Yu等人[84]构建具有共享权重但独立归一化层的可切换层,使得相应层可以在预定义集合的不同通道数下执行,即16或32的倍数。具体来说,扩展比率 E i , j E_{i, j} Ei,j由每个FFN中深度 3 × 3 3 \times 3 3×3卷积的通道数决定,阶段宽度 C j C_{j} Cj由FFN和MHSA块的最后一个投影( 1 × 1 1 \times 1 1×1卷积)的输出通道对齐决定。可切换执行可以表示为:
X ^ i = γ c ⋅ w i c ⋅ X i − μ c σ c 2 + ϵ + β c \hat{\mathbb{X}}_{i}=\gamma_{c} \cdot \frac{w^{i c} \cdot \mathbb{X}_{i}-\mu_{c}}{\sqrt{\sigma_{c}^{2}+\epsilon}}+\beta_{c} X^i=γc⋅σc2+ϵwic⋅Xi−μc+βc
其中 w i c w^{i c} wic指的是切片权重矩阵的前c个滤波器以获得输出的子集, γ c , β c , μ c \gamma_{c}, \beta_{c}, \mu_{c} γc,βc,μc,和 σ c \sigma_{c} σc是归一化层的参数和统计数据,该层专用于宽度c。超网络通过三明治规则[85]进行预训练,通过在每次迭代中训练最大、最小和随机采样的两个子网(我们在算法(1)中将这些子网表示为max, min, rand-1和rand-2)。
讨论。我们超网络的剪枝部分受到可扩展网络[85]的启发。然而,差异也是显著的。首先,搜索目标是不同的。我们应用引入的联合搜索目标来优化模型大小和效率(第4.2.1节)。其次,搜索动作是不同的。深度是通过减少每个块来剪枝的,这是可能的,因为我们统一了设计,只采用两种块:前馈网络(第3.1节)和注意力块。剪枝深度的方式与可扩展网络不同。将所有灵活的搜索动作统一在一个联合目标下以前没有研究过变换器。
4.2.3 搜索算法
现在搜索目标、搜索空间和超网络都已制定,我们提出了搜索算法。由于超网络可以在弹性深度和可切换宽度下执行,我们可以通过分析每个剪枝动作相对于效率增益和准确性下降来搜索具有最佳帕累托曲线的子网络。我们定义动作池为:
A ∈ { A N [ i , j ] , A C [ j ] , A E [ i , j ] } A \in\left\{A_{N[i, j]}, A_{C[j]}, A_{E[i, j]}\right\} A∈{AN[i,j],AC[j],AE[i,j]}
其中 A N [ i , j ] A_{N[i, j]} AN[i,j]表示剪枝每个块, A C [ j ] A_{C[j]} AC[j]指的是缩小一个阶段的宽度, A E [ i , j ] A_{E[i, j]} AE[i,j]表示将每个FFN剪枝到更小的扩展。初始化状态为全深度和宽度(最大的子网),我们在ImageNet-1K的验证部分上评估每个前沿动作的准确性结果( △ A C C \triangle A C C △ACC),这只需要大约4 GPU分钟。同时,参数减少( Δ Params \Delta \text{Params} ΔParams)可以直接从层属性计算,即内核大小、输入通道和输出通道。我们通过在iPhone 12上预先构建的延迟查找表获得延迟减少( Δ Latency \Delta \text{Latency} ΔLatency),使用CoreMLTools进行测量。有了手头的指标,我们可以通过 Δ Params \Delta \text{Params} ΔParams和 Δ Latency \Delta \text{Latency} ΔLatency计算 △ MES \triangle \text{MES} △MES,并选择每MES准确性下降最小的动作: A ^ ← arg min A Δ ACC Δ MES \hat{A} \leftarrow \arg \min _{A} \frac{\Delta \text{ACC}}{\Delta \text{MES}} A^←argminAΔMESΔACC。值得注意的是,尽管动作组合是巨大的,我们每次只需要评估前沿的一个,这是线性复杂度的。详细信息可以在算法(1)中找到。
- 实验
5.1. ImageNet-1K分类
实现细节。我们通过PyTorch 1.12 [62]和Timm库[79]实现模型,并使用16个NVIDIA A100 GPU来训练我们的模型。我们通过在ImageNet-1K [19]上训练300和450个周期从零开始训练模型,使用AdamW [55]优化器。学习率设置为每1024批大小 1 0 − 3 10^{-3} 10−3,余弦衰减。我们使用标准图像分辨率,即 224 × 224 224 \times 224 224×224,进行训练和测试。类似于DeiT [72],我们使用RegNetY-16GF [63]作为教师模型进行硬蒸馏,其top-1准确率为82.9%。我们使用三个测试平台来基准测试延迟:
- iPhone 12 - NPU。我们通过在神经引擎(NPU)上运行模型来获得iPhone 12(iOS 16)上的延迟。模型(批量大小为1)使用CoreML [1]编译。
- Pixel 6 - CPU。我们在Pixel 6(Android)CPU上测试模型延迟。为了获得大多数比较工作的延迟,我们将所有模型的激活替换为ReLU以进行公平比较。模型(批量大小为1)使用XNNPACK [4]编译。
- Nvidia GPU。我们还提供了在高端GPU-Nvidia A100上的延迟。模型(批量大小为64)在ONNX [2]中部署,并由TensorRT [3]执行。
单指标评估。我们在表2中展示了比较结果,包括视觉变换器和CNNs上最近和代表性的工作。没有公开模型或与移动设备不兼容的工作[6, 82, 51]不包含在表[2。EfficientFormerV2系列在单一指标上取得了最佳结果,即参数数量或延迟。对于模型大小,EfficientFormerV2-S0在参数数量更少的情况下比EdgeViT-XXS [60]高出1.3%的top-1准确率,并且与MobileNetV2 [66]相比,在类似数量的参数下高出3.5%的top-1准确率。对于大型模型,EfficientFormerV2-L模型在与最近的EfficientFormerL7 [47]相同准确性的情况下小3.1倍。至于速度,EfficientFormerV2-S2在类似或更低的延迟下,比UniNet-B1 [50]、EdgeViT-S [60]和EfficientFormerL1 [47]分别高出0.8%、0.6%和2.4%的top-1准确率。我们希望结果能提供实际的见解,激发未来的架构设计:现代深度神经网络对架构排列是健壮的,用联合约束(如延迟和模型大小)优化架构不会损害单个指标。
联合优化的大小和速度。此外,我们展示了EfficientFormerV2在考虑模型大小和速度时的优越性能。这里我们使用MES作为评估移动效率的更实用指标,而不是单独使用大小或延迟。EfficientFormerV2-S1在远高于MES的情况下,比MobileVit-XS [58]、EdgeVit-XXS [60]和EdgeViTXS [60]分别高出4.2%、4.6%和1.5%的top-1。有了1.8倍的MES,EfficientFormerV2L比MobileFormer-508M [13]高出4.0%的top-1准确率。评估结果回答了一开始提出的核心问题:通过提出的移动效率基准(第4.2.1节),我们可以避免陷入在单一指标上看似表现良好而牺牲太多其他方面的陷阱。相反,我们可以获得既轻又快的高效移动ViT骨干。
5.2. 下游任务
目标检测和实例分割。我们将EfficientFormerV2作为骨干网络应用于Mask-RCNN [30]流程,并在MS COCO 2017 [49]上进行实验。模型使用ImageNet-1K预训练权重进行初始化。我们使用AdamW [55]优化器,初始学习率为 2 × 1 0 − 4 2 \times 10^{-4} 2×10−4,并进行12个周期的训练,分辨率为 1333 × 800 1333 \times 800 1333×800。按照Li等人[44],我们应用权重衰减为0.05,并冻结骨干网络中的归一化层。如表3所示,EfficientFormerV2S2在类似模型大小的情况下,比PoolFormer-S12 [86]高出6.1 A P box \mathrm{AP}^{\text{box}} APbox和4.9 A P mask \mathrm{AP}^{\text{mask}} APmask。EfficientFormerV2-L比EfficientFormerL3 [47]高出3.3 A P box \mathrm{AP}^{\text{box}} APbox和2.3 A P mask \mathrm{AP}^{\text{mask}} APmask。
语义分割。我们在ADE20K [91]上进行实验,这是一个具有150个类别的具有挑战性的场景分割数据集。我们的模型作为特征编码器集成在Semantic FPN [39]流程中,使用ImageNet-1K预训练权重。我们在ADE20K上训练我们的模型40 K次迭代,批量大小为32,学习率为 2 × 1 0 − 4 2 \times 10^{-4} 2×10−4,采用0.9的多项式衰减。我们应用权重衰减为 1 0 − 4 10^{-4} 10−4,并冻结归一化层。训练分辨率为 512 × 512 512 \times 512 512×512,我们在验证集上采用单尺度测试。如表3所示,EfficientFormerV2-S2比PoolFormer-S12 [86]和EfficientFormer-L1 [47]分别高出5.2和3.5 mIoU。
5.3. 搜索算法的消融分析
我们将提出的搜索算法与随机搜索和EfficientFormer [47]中的一种进行比较。如表4所示,我们的搜索算法获得的模型性能远好于随机搜索,即随机1和随机2。与EfficientFormer [47]相比,我们在类似参数和延迟下实现了更高的准确性,证明了细粒度搜索和联合优化延迟和大小的有效性。
- 讨论和结论
在这项工作中,我们全面研究了变换器骨干,识别了低效设计,并引入了移动友好的新架构变化。我们进一步提出了细粒度的联合搜索大小和速度,并获得了EfficientFormerV2模型家族。我们在不同硬件上广泛基准测试并比较了我们的工作,并证明EfficientFormerV2既轻量级,推理速度超快,又高性能。由于我们专注于大小和速度,一个未来的研究方向是将联合优化方法应用于后续研究,探索其他关键指标,如内存占用和 C O 2 \mathrm{CO}_{2} CO2排放。
- 致谢
这项工作部分得到了陆军研究办公室/陆军研究实验室通过授予东北大学CNS1909172的W911-NF-20-10167计划的支持。
A. 更多实验细节和结果
训练超参数。我们在表5中为ImageNet-1K [19]分类任务提供了详细的训练超参数。这是一个类似的配方,跟随DeiT [73]、LeViT [25]和EfficientFormer [47]进行公平比较。
无蒸馏的结果。我们在表6中提供了没有蒸馏训练的模型。与没有蒸馏训练的代表性工作相比,例如MobileNetV2 [66]、MobileFormer [14](训练了更长的周期)、EdgeViT [60]和PoolFormer [86],我们的模型仍然实现了更好的延迟-准确性权衡。
注意力偏置分析。
注意力偏置被用来作为显式位置编码。缺点是,注意力偏置对分辨率敏感,使得模型在迁移到下游任务时变得脆弱。通过删除注意力偏置,我们观察到在300和450训练周期的准确性分别下降了0.2%(表(7)中的注意力偏置为Y vs. N),表明EfficientFormerV2仍然可以在没有显式位置编码的情况下保持合理的准确性。
B. 搜索算法的更多消融分析
扩展比率的重要性。我们首先讨论了在宽度之上搜索扩展比率的必要性。如表88所示,我们展示了通过调整宽度以保持相同的预算,即每个模型的相同参数数量,改变扩展比率会导致显著的性能差异。因此,仅通过搜索宽度而固定扩展比率无法获得帕累托最优性。
扩展比率搜索的分析。我们在表9中验证了不同搜索算法的性能。我们使用EfficientFormer [47]中的搜索管道获得基线结果,仅搜索深度和宽度。在7 M参数的预算下,我们获得了一个在ImageNet-1K上具有79.2% top-1准确率的子网络。然后,我们应用简单的基于幅度的剪枝以细粒度的方式确定扩展比率。不幸的是,性能没有提高。尽管搜索扩展比率很重要(表87),但通过简单的启发式方法实现帕累托最优性并非易事。最后,我们应用我们的细粒度搜索方法,获得了一个79.4%的top-1准确率的子网络,证明了我们方法的有效性。
不同的 α latency \alpha_{\text{latency}} αlatency和 α size \alpha_{\text{size}} αsize在公式1中的分析。这里,我们提供了分析不同 α latency \alpha_{\text{latency}} αlatency和 α size \alpha_{\text{size}} αsize如何影响搜索结果的结果(表10)。我们的搜索算法对不同的 α \alpha α设置是稳定的。增加大小的权重( α size \alpha_{\text{size}} αsize)会导致模型速度变慢。我们当前的设置( α latency \alpha_{\text{latency}} αlatency为1.0, α size \alpha_{\text{size}} αsize为0.5)是通过与最近的工作(例如EdgeViT、UniNet等)对齐来进行公平比较的。
搜索结果的可视化。在图3中,我们可视化了搜索到的子网络的性能,包括使用EfficientFormer [47]的搜索算法获得的网络和通过我们的细粒度联合搜索找到的网络。我们采用MES作为效率测量,并以对数尺度绘制。结果展示了我们提出的搜索方法的优势性能。
设计选择消融。在检测/实例分割任务中,我们消融了网络设计选择,并证明了来自ImageNet-1K分类任务的结论可以转移。我们在MS-COCO数据集上从零开始训练EfficientFormerV2-S2,训练12个周期,没有ImageNet预训练。结果包含在表11中。例如,第3.1节提到回退到DWConv混合器而不是FFN。我们的设计具有明显优势。此外,如果没有我们提出的步幅注意力(第3.4节),模型会遇到内存问题,无法在移动设备上运行。请注意,第3.2节未包含,因为5级网络在检测任务中并不是常见做法。
更多随机模型及通过超网络与随机搜索的成本分析。我们随机抽取更多模型(10个),并使用更广泛的延迟范围与我们的搜索模型进行比较。如图4所示,通过我们的方法(红线)搜索模型的性能优于随机搜索(蓝点)。我们的超网络训练耗时37 GPU天(A100),是L模型训练时间(8 GPU天)的4.6倍。然而,假设每个候选项至少需要10个随机子网进行搜索,随机搜索L级模型本身的成本累积到80 GPU天(比超网络长2倍)。此外,随机搜索的成本在多个网络(我们工作中的四个)上进一步增加。因此,我们的搜索方法比随机搜索更高效。
超网络的子网络准确性及其与最终准确性的相关性。在图5中,我们展示了从超网络获得的多个子网络的准确性及其与最终准确性的相关性(从零开始训练)。我们参考EagleEye [43]进行比较。通过有效训练的超网络,我们获得了更高的子网络评估准确性(>40%,vs. <10%在EagleEye中),以及与最终准确性(通过Pearson相关系数测量的 r 2 = 0.91 r^{2}=0.91 r2=0.91,vs. 0.63在EagleEye中)的更好相关性。
C. 网络配置
EfficientFormerV2 S0、S1、S2和L的详细网络架构在表12中提供。我们报告了阶段分辨率、宽度、深度和每个块的扩展比率。
相关文章:

EfficientFormerV2:重新思考视觉变换器以实现与MobileNet相当的尺寸和速度。
摘要 https://arxiv.org/pdf/2212.08059 随着视觉变换器(ViTs)在计算机视觉任务中的成功,近期的研究尝试优化ViTs的性能和复杂度,以实现在移动设备上的高效部署。提出了多种方法来加速注意力机制,改进低效设计…...

ASP.NET Core高效管理字符串集合
我们在开发 Web 项目时经常遇到需要管理各种来源的字符串集合(例如HTTP 标头、查询字符串、设置的值等)的情况。合理的管理这些字符串集合不仅可以减少出bug的几率,也能提高应用程序的性能。ASP.NET Core 为我们提供了一种特殊的只读结构体 S…...

vm-tools的卸载重装,只能复制粘贴,无法拖拽文件!
开始 ubuntu22.04 LTSVMwareTools-10.3.25-20206839.tar.gzVMware Workstation 17 Pro 各种该尝试的配置都尝试了,比如: 1.开启复制粘贴拖拽; 2.VMware Tools拖拽失效; 3.解决VMware无法拖拽. 均没有奏效. 安装过程报错, 报错异常: The installation of VMware Tools 10.3.25…...

Docker 容器网络技术
Docker 容器网络技术 一、概述 Docker 容器技术在微服务架构和云原生应用中扮演着重要角色。容器的轻量化和快速启动特性,使得它们成为现代应用部署的首选。然而,容器的网络连接和管理是一个复杂的问题,尤其是当涉及到容器间通信时。Docker…...

C++ 起始帧数、结束帧数、剪辑视频
C 指定起始帧数、结束帧数、 剪辑视频 C 无法直接用H264,只能用avi编码格式 #include <iostream> #include <opencv2/opencv.hpp>int main() {// 读取视频:创建了一个VideoCapture对象,参数为摄像头编号std::string path &quo…...

【项目一】基于pytest的自动化测试框架———解读requests模块
解读python的requests模块 什么是requests模块基础用法GET与POST的区别数据传递格式会话管理与持久性连接处理相应结果应对HTTPS证书验证错误处理与异常捕获 这篇blog主要聚焦如何使用 Python 中的 requests 模块来实现接口自动化测试。下面我介绍一下 requests 的常用方法、数…...

升级Ubuntu内核的几种方法
注意: Ubuntu主线内核由 Ubuntu 内核团队提供,用于测试和调试目的。 它们不受支持且不适合生产使用。 仅当它们可以解决当前内核遇到的关键问题时,才应该安装它们。 1、手动下载deb文件升级内核 来源:kernel.ubuntu.com/main…...

Android绘制靶面,初步点击位置区域划分取值测试
自定义View: public class TargetView extends View {private Paint paint;private int[] radii {100, 250, 400, 550, 700}; // 五个圆的半径private int numberOfSegments 8;private int[][] regionValues; // 存储每个区域的值public TargetView(Context cont…...
)
【SpringBoot】调度和执行定时任务--Quartz(超详细)
Quartz 是一个功能强大的任务调度框架,广泛用于在 Java 应用程序中定时执行任务,同时它支持 Cron 表达式、持久化任务、集群等特性。以下是 Quartz 的详细使用教程,包括安装、基本概念、简单示例和高级功能。 1. 安装 Quartz 首先ÿ…...
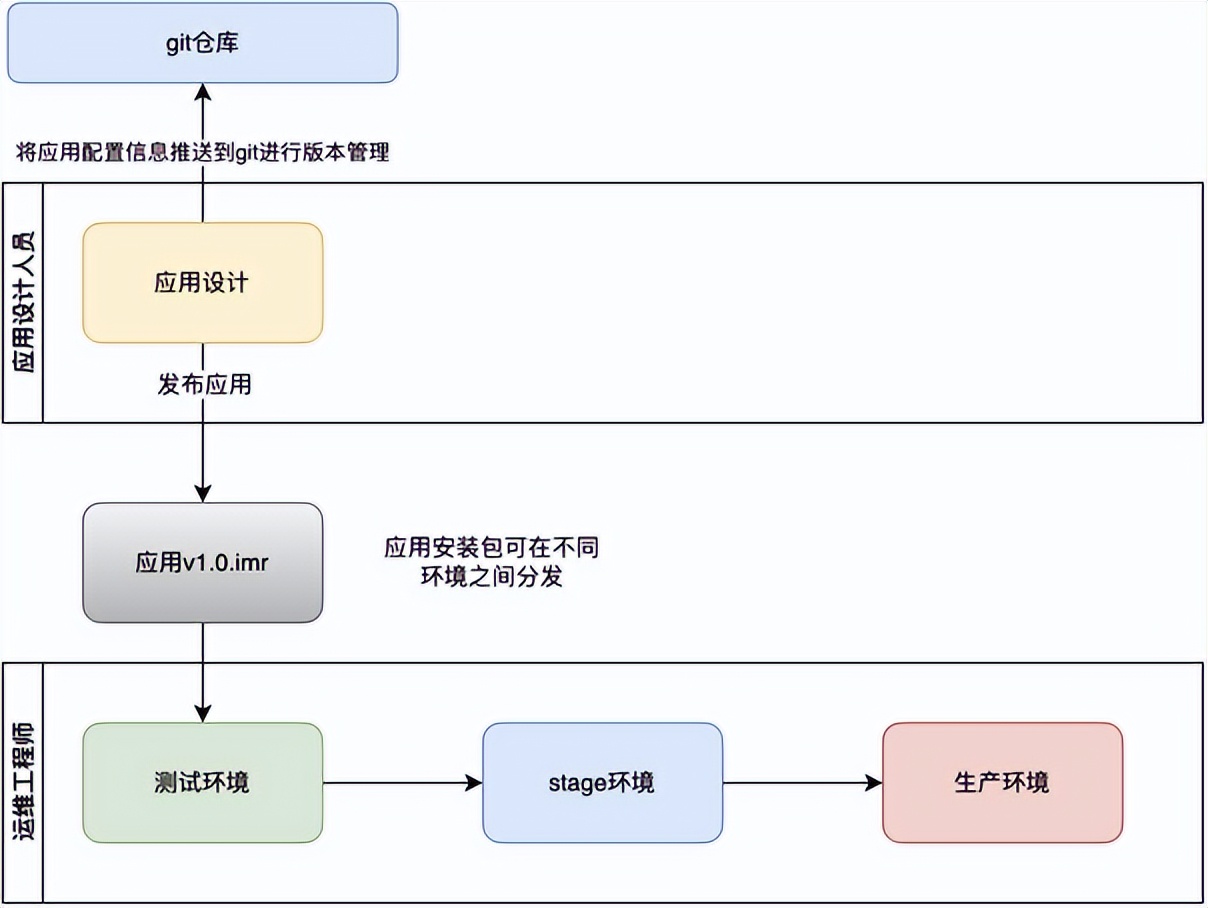
低代码开发平台系统架构概述
概述 织信低代码开发平台(产品全称:织信Informat)是一款集成了应用设计、运行与管理的综合性平台。它提供了丰富的功能模块,帮助用户快速构建、部署和维护应用程序。织信低代码平台通过集成丰富的功能模块,为用户提供…...

源码编译llama.cpp 、ggml 后端启用自定义BLAS加速
源码编译llama.cpp 、ggml 后端启用自定义BLAS加速 我在llama.cpp 官网上提交了我的解决方案:How to setup OpenBlas on windows? #625 GGML 官网 https://github.com/ggerganov/ggml/issues/959 windows on arm 编译 llama.cpp 、ggml 后端启用自定义BLAS加速 …...
glb数据格式
glb数据格式 glb 文件格式只包含一个glb 文件,文件按照二进制存储,占空间小 浏览 浏览glb工具的很多,ccs,3D查看器等都可以,不安装软件的话用下面网页加载就可以,免费 glTF Viewer (donmccurdy.com) glb…...

手语识别系统源码分享
手语识别检测系统源码分享 [一条龙教学YOLOV8标注好的数据集一键训练_70全套改进创新点发刊_Web前端展示] 1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 项目来源AACV Association for the Advancement of Computer Vision …...

Oracle 数据库部署与实施
文章目录 1. macOS 上部署 Oracle 数据库通过 Docker 在 macOS 上部署 2. Linux 上部署 Oracle 数据库直接在 Linux 上部署通过 Docker 在 Linux 上部署 3. Windows 上部署 Oracle 数据库4. 使用 Docker 部署 Oracle 数据库前提条件拉取 Oracle 数据库 Docker 镜像运行 Oracle …...

【Python】 ast.literal_eval 与 eval
一、背景 我在在编写管理后台的过程中,遇到一个小问题,是关于用户名的存储和解码。用户名以base64编码的形式存储在 MySQL 数据库中,并且还保留了b这样的形式,具体为什么要这样存我也不知道,可能是因为有些特殊字符无法直接存储。…...

Java 入门指南:JVM(Java虚拟机)垃圾回收机制 —— 新一代垃圾回收器 ZGC 收集器
文章目录 垃圾回收机制垃圾收集器垃圾收集器分类ZGC 收集器ZGC 的性能优势复制算法指针染色读屏障 ZGC 的工作过程Stop-The-World 暂停阶段并发阶段 垃圾回收机制 垃圾回收(Garbage Collection,GC),顾名思义就是释放垃圾占用的空…...

基于 K8S kubernetes 的常见日志收集方案
目录 1、日志对我们来说到底重不重要? 2、常见的日志收集方案 2.1 EFK 2.2 ELK Stack 2.3 ELKfilebeat 2.4 其他方案 2、elasticsearch组件介绍 3、filebeat组件介绍 3.1 filebeat和beat关系 3.2 filebeat是什么? 3.3 Filebeat工作原理 3.4 …...

Unity3D 小案例 像素贪吃蛇 02 蛇的觅食
Unity3D 小案例 像素贪吃蛇 第二期 蛇的觅食 像素贪吃蛇 食物生成 在场景中创建一个 2D 正方形,调整颜色,添加 Tag 并修改为 Food。 然后拖拽到 Assets 文件夹中变成预制体。 创建食物管理器 FoodManager.cs,添加单例,可以设置…...

【sgCreateCallAPIFunction】自定义小工具:敏捷开发→调用接口方法代码生成工具
<template><div :class"$options.name" class"sgDevTool"><sgHead /><div class"sg-container"><div class"sg-start"><div style"margin-bottom: 10px">调用接口方法定义列表</div…...

京东商品详情的 API 探秘与应用
在当今数字化的商业世界中,获取准确而详细的商品信息对于开发者、商家以及消费者都具有至关重要的意义。京东作为国内领先的电商平台之一,提供了丰富的商品资源和强大的 API 接口,让我们能够轻松获取京东商品的详情信息。本文将带你深入了解如…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...