网络原理(3)—— 应用层、传输层(TCP)
1. 应用层
日常开发中最常用到的一层,主要涉及到两种情况:
1) 使用现成的应用层协议
2) 自己定义应用层协议
1.1 自定义应用层协议的流程
1. 明确前后端交互过程中需要传递哪些信息
实例:开发一个外卖软件
打开软件,首先需要展示一个“商家列表”,根据需求决定传递哪些信息
a) 请求:用户 id,用户所在的位置(外卖上显示的商家列表都是用户附近的商家)
b) 响应:商家列表,其中包含多个商家,每个商家的信息中又包含:商家名、图片、距离、评分等
2. 明确组织这些信息的格式(使用现有的格式)
针对信息组织的格式有很多种方式,使用哪种方式都可以,但是要保证前后端是同一种方式
例如:使用行文本的方式来组织上述数据
a) 请求:
格式:用户 id,用户位置\n
实际:1001,E45N60\n
b) 响应
格式:商家 id,商家名称,商家图片地址,商家距离,商家评分;商家 id,商家名称,商家图片地址,商家距离,商家评分\n
实例:2001,煎饼果子,http://image1.com,1.5km,4.5;2002,蛋炒饭,http://image2.com,2.0km,4.6\n
上述“行文本”这样简单粗暴的方案在实际开发中很少会用
1.2 常用的信息组织方案如下:
1. xml (传统的方案)
通过 “成对的标签” 表示 “键值对” 信息
<request><userId>1001</userId><position>E45N60<position>
</request>xml 进行网络传输的时候,会消耗大量的带宽
2. JSON (当前更主流的方案)
JSON 也是 “键值对” 格式,键和值之间使用 : 分割,键值对之间使用 , 分割,所有的键值对都使用 { } 括起来
{"userId":1001,"position":"E45N60"
}其相比于 xml 来说,可读性比较好,同时也能节省一定的带宽
但是它的可读性也不是完全那么好,因为其没有明确要求数据的格式,所以存在一些极端情况,如下
{"userId":1001,"position":"E45N60","userId":1001,"position":"E45N60","userId":1001,"position":"E45N60","userId":1001,"position":"E45N60","userId":1001,"position":"E45N60"}像这样 { } 里若有 20,30 个键值对(日常开发很常见),可读性就不高了
3. yml(yaml)
强制要求了数据组织的格式,如下
request:userId:1001position:"E45N60"yml 强制要求了键值对必须独占一行,而且“嵌套”结构必须通过缩进来进行表示
4. google protobuffer
前三个方案都是关注可读性,protobuffer 则关注性能,牺牲了可读性(通过二进制的方式组织数据),直接通过“位置”约定字段的含义,不需要传输 key 的名字,也会针对传输的数值进行二进制的编码,起到一些“压缩”效果
极大的缩减了要传输的数据的体积,从而带宽消耗就越小,效率就越高
但由于二进制数据无法肉眼阅读,调试相关程序的时候就会比较麻烦
2. 传输层
2.1 端口号
端口号是一个整数,用来区分不同的进程,同一时刻,同一个机器上,同一个协议,一个端口只能被一个进程绑定(一个进程是可以绑定多个端口的!)
端口号是通过 2 个字节的无符号整数表示的,取值范围:0~65535,0 端口比较特殊(随机设定空闲端口),一般不会使用
端口号划分
- 1-1023:知名端口号,像 http(80)、https(443)、ssh(22)、ftp(21)、telnet(23)...他们的端口号都是固定的
- 1024-65535:操作系统动态分配的端口号,客户端程序的端口号就是由操作系统从整个范围分配的
tip:
- 编写服务器一定需要先绑定至少一个端口(业务端口),和客户端交互
- 服务器运行过程中,希望能够对这个服务器的行为进行一些“控制”,比如让服务器重新加载某个数据/某个配置/修改服务器的某个功能,就可以通过网络通信完成(让服务器绑定另一个端口(管理端口),通过这个端口编写一个客户端,给服务器发送一些“控制类”的请求)
- 当需要针对服务器运行状态进行检测和调试或需要查看服务器运行中某个关键变量的数值时,不能用调试器来调试,若使用调试器很可能会使服务器的一些线程被阻塞,从而无法给客户端正确提供服务了(可以让服务器绑定另一个端口(调试端口),实现一些相关的打印关键变量的逻辑,由客户端发送对应的调试请求)
2.2 UDP 协议
2.2.1 UDP 的“数据格式”/“报文格式”

tip:
实际上的 UDP 的数据并没有“换行”动作,如下图:

UDP 报头中的四个字段没有指定分隔符,而是通过固定长度来进行区分的,总共 8 字节
UDP 报文长度 = 报头长度 + 载荷长度
报文长度的单位是 “字节”,如:报文长度 1024 => 整个 UDP 数据报就是 1024 字节
由于是使用 2 字节来表示报文长度,所以最大值就是 65535 => 64KB
2.2.2 关于校验和
前提:网络传输过程中是非常容易出现错误的,电信号/光信号/电磁波 受到环境的干扰会使里面传输的信号发生改变(比特翻转)
校验和存在的目的就是为了能够 “发现” 或者 “纠正” 这里出现的错误,给传输的数据中引入额外信息(checksum),用来 发现/纠正 传输数据的错误(只是 “发现错误” 携带的 额外信息 可以少一点,若是想“纠正错误”,就需要 携带更多额外信息,消耗更多的带宽)
1) 校验和纠正原理
1. UDP 中使用 2 个字节作为校验和,使用方案为 CRC校验和(循环冗余校验)
把 UDP 数据报整个数据都进行遍历,分别取出每个字节往 一个 两个 的变量上进行累加,由于整个数据可能很多,加着加着可能结果就溢出了,溢出也没关系,重点不关心最终加和是多少,而是关心校验和结果是否会在传输中发生改变,具体流程如下:

当接收方收到数据后,就可以根据数据的内容,按照同样的算法再算一遍校验和得到 checksum2,如果传输的数据在网络通信过程中没有发生任何改变,那么 checksum1 == checksum2,反之如果 checksum1 != checksum2,就可以认为数据在网络传输中出错了
2) MD5 和 SHA1
除了 CRC 之外,另外两个典型的算法,其中的 MD5 算法本质上是一个 “字符串 hash 算法”。背后的实现过程是一个“数学过程”(可简单理解为套公式)
MD5 的特点(SHA1也是这三个特点):
1) 定长:无论输入的字符串长度多长,算出的 md5 的结果都是固定长度(适合做 校验和 算法)
2) 分散:输入的内容,哪怕只有丁点改变,得到的 md5 值都会相差非常大(适合做 hash 算法)
3) 不可逆:根据输入内容计算 md5 非常简单,但若是已知 md5 值,想要还原出原始的内容,理论上是不可行的(适合作为加密算法)
2.3 TCP 协议
TCP 全称为“传输控制协议(Transmission Control Protocol)”
2.3.1 TCP 的“数据格式”/“报文格式”

4 位首部长度:TCP 的报头长度,表示该 TCP 头部有多少个 32 位 bit(此处的长度单位是 “4 字节”,不是 “字节”)
保留(6位):现在虽然不用,但是先申请下来,如果未来某天 TCP 需要新增属性/或者某个属性的长度不够用,就可以把保留位拿出来使用(用于考虑未来的可扩展性)
选项:optional => 更准确的翻译 “可选的”,TCP 报头变长的主要原因就是 选项 可以有,也可以没有
2.3.2 TCP 相关机制
TCP 最核心的机制就是 “可靠传输”(代码层面感知不到,系统内核完成了这里的工作),但是也不能做到 100% 送达,只能尽可能使数据能到达对方,
1) TCP 核心机制(一)——确认应答
感知对方是否收到,所谓的感知对方收到,就是靠对方告诉一声(应答报文),如下图:

上述应答报文的机制还存在问题,如果发送方发送多个消息的时候,就可能存在歧义,如下:

后发先至是客观的情况,无法改变,可以给传输的数据添加“编号”,通过编号可以区分出数据的先后顺序:

这样即使收到的应答报文顺序出现错乱,也能识别出来
由于 TCP 是面向字节流的,实际上编号并非是按照“第一条、第二条”这样的方式来编排的,而是按照“字节”(第 1 个字节...第 1000 个字节)
每个字节都有一个独立的编号,字节和字节之间,编号是连续的,递增的,按照字节编号这样的机制,就称为“TCP 的序号”
在应答报文中,针对之前收到的数据进行对应的编号,称为 “TCP 的确认序号”
32 位序号
由于编号是连续的,对于一个 TCP 数据报来说,知道了数据部分的第一个字节,就知道了后续所有字节的序号(序号只是针对 TCP 数据报携带的载荷来进行编号的,TCP 报头不参与)

这里 32 位序号(4字节)表示的范围是 0~42亿9千万(0~4GB),是否意味着一个 TCP 一次传输最大就只能传输 4GB呢?
答案是否定的,因为 TCP 是面向字节流的,一个 TCP 数据报(一个 TCP 报头 + 载荷)和下一个 TCP 数据报携带的数据天然就是 “可拼装的”
比如要传输一个特别大的数据,传输过程中本身就会通过多个 TCP 数据报进行携带,这些 TCP 数据报彼此之间携带的载荷都是可以在接收方自动被拼起来的
这样就不像 UDP 存在传输的上限,使用 UDP 传输大数据,就需要考虑调用这一次 send 操作,参数是否超过 64KB,超过 64KB 就不行
32 位确认序号的设定方式

如果是普通报文,序号是有效的,确认序号是无效的;如果是 ack 应答报文,序号和确认序号都是有效的(这是另一套编号的体系,和传输的数据的序号不是一套)
再谈 “后发先至”
TCP 就可以针对接收方收到的数据进行重新排序,确保应用程序 read 到的数据一定是和发送方发的数据顺序是一致的

2) TCP 核心机制(二)——超时重传
实际上网络传输中,并不是一帆风顺的,而是可能会出现 “丢包” 的情况
丢包的原因:
1) 数据传输过程中发生了 bit 翻转,收到这个数据的接收方/中间路由器计算校验和发现对不上了
出现这种情况,就会把这个数据报丢弃掉,不继续往后转发/不交给应用层使用了
2) 数据传输到某个节点(路由器/交换机),这个节点负载太高了
某个路由器单位时间内只能转发 N 个包,现在网络高峰期,这个路由器单位时间需要转发的包超过了 N,后续传输过来的数据就可能被这个路由器直接丢弃掉
发生丢包,是完全随机的,不可预测的!
TCP 对丢包的应对方式
TCP 中通过应答报文来区分是否丢包,收到应答报文说明数据没丢包,没收到说明数据丢包了,发送方发送数据之后,会给出一个 “时间限制”(超时时间),如果在这个时间限制之内没有收到 ack,就视为数据丢包了
如果丢包,就重新发一次,假设网络丢包率 10%(数据报到达对方是 90%),此时进行一次重传,两次传输至少一次到达对方的概率:1 - 10% * 10% = 99%,传输次数越多,数据到达对方的概率就越大
TCP 的去重操作

发送方无法区分上面两种情况,当出现第二种情况后,B 就收到了两份一样的数据(若是传输的数据是 “扣款” 这样的请求就会造成扣两次款的问题)
TCP 针对上述情况,在接收方会有一个 “接收缓冲区”,收到的数据先进入到缓冲区里,后续再收到数据,就会根据序号在缓冲区中找对应的位置(排序),如果发现当前序号 1-1000 这个数据已经在缓冲区中存在了,就直接把新收到的数据丢弃了(去重)
确保应用程序调用 read 读取出来的数据是唯一的,不重复的
超时重传时间的设定
这里的时间不是固定值,而是动态变化的,如:发送方第一次重传,超时时间是 t1,如果重传之后,仍然没有 ack,还会继续重传,第二次重传超时时间是 t2,其中 t2 > t1,每多重传一次,超时时间的间隔会变大/重传的频次会降低
这是因为,经过一次重传之后,就能让数据到达对方的概率提升很多,再重传一次,又会提升很多,若是重传几次都没有到达,说明网络的丢包率已经达到了一个非常高的程度(网络发生了严重故障,大概率没法继续使用了
重传不会无休止的进行,当重传达到一定次数之后,TCP 就不会继续重传了,会先尝试进行 “重置/复位 连接” ,发送一个特殊的数据报 “复位报文”,如果网络这时恢复了,复位报文就会重置连接,使通信可以继续进行,如果网络还是有严重问题,复位报文也没有得到回应,此时 TCP 就会单方面放弃连接
tip:
1) 连接就是通信双方各自保存对方的信息,发送方释放掉之前保存的接收方的相关信息,这个连接就无了
2) 确认应答 和 超时重传 相互补充,共同构建了 TCP “可靠传输机制”(TCP 的可靠传输不是通过“三次握手和四次挥手”保证的!!)
3) TCP 核心机制(三)——连接管理
在正常情况下,TCP 都要经过三次握手建立连接,四次挥手断开连接
三次握手

三次握手的意义
1) 投石问路,初步的验证通信的链路是否畅通(进行可靠传输的 “前提条件”)
类似于日常中,地铁在开始运营之前都会空跑一趟,先进行“链路畅通的验证”
2) 确认通信双方各自的发送能力和接收能力是否正常
类似于连麦时:

tip:
a) 四次也行就是将中间一次拆成两次,但没必要
b) 两次不可行,无法完成通信双方针对各自接发能力的验证
c) 针对 TCP 来说必须是三次握手,但是其他协议握手过程不一定是三次
3) 让通信双方在进行通信之前,对通信过程中需要用到的一些关键参数进行协商
类似于开会时准备茶杯:

TCP 通信时,起始数据的序号就是通过三次握手协商确定的(换而言之,TCP 序号并不是从 1 开始的),每次建立连接 TCP 的起始序号都不同(而且故意差别很大)
这样做的意义就是避免出现 “前朝的剑斩本朝的官”,如下:

给每个连接都协商不同的起始序号,如果发现收到的数据和起始序号以及最近收到的数据序号,有较大差距,就把这个数据视为“前朝”数据
tip:
三次握手对于可靠性是有一定的支持的,但是 “可靠性就是三次握手体现的”,这个说法非常武断,三次握手只是建立连接的时候进行的,一旦连接建立好,数据就开始传输了,和三次握手没关系了
确认应答 + 超时重传 才是负责传输数据中的 “可靠性”
四次挥手

通信双方各自给对方发送“FIN”,各自给对方返回“ACK”,通过这个过程双方各自把对端的信息删除掉
三次握手,是因为中间两次的交互合并在一起了,而对于四次挥手来说,中间两次,不一定能合并(大概率不能)
因为对于三次握手来说,中间的两次 ACK+SYN 都是在内核中,由操作系统负责进行的,因为其执行的时机都是在收到 SYN 之后,所以可以合并
对于四次挥手来说,ACK 是由内核控制的,但是 FIN 的触发则是通过应用程序调用 close/进程退出,来触发的
TCP 回显服务器中例:

三次握手四次挥手中的状态

1) LISTEN(服务器进入的状态)
服务器把端口绑定好,相当于进入了 listen 状态了,此时服务器就已经初始化完毕,准备好随时迎接客户端了
2) ESTABLISHED (客户端和服务器都会进入的状态)
TCP 连接建立完成(保存了对方的信息了),接下来就可以开始进行业务数据的通信了
3) CLOSE_WAIT(被断开连接一方会进入这个状态)
先收到 FIN 的一方(等待代码执行 close 方法)
tip:如果发现服务器这端存在大量的 CLOSE_WAIT 状态的 TCP 连接,说明此时服务器代码可能有 bug,需排查 close 是否写了,是否及时执行到了
4) TIME_WAIT(主动断开一方会进入这个状态)
此处的 TIME_WAIT 按照时间来等待,达到一定时间之后,连接就释放了,这是为了防止发送给对端的 ACK 丢包

当 A 保留一段时间后,没有收到 FIN,说明刚才的 ACK 没丢包,就可以释放这里的连接了
TIME_WAIT 存在的时间称为 2MSL(MSL => 数据报在网络传输中消耗的最大时间)
4) TCP 核心机制(四)——滑动窗口
TCP 的可靠传输代价是降低了传输的效率,为了在可靠传输的基础上,也能有一个不错的效率,引入了滑动窗口(这里的提高效率,只是“亡羊补牢”,使传输效率的损失尽可能降低,并不能使传输效率比 UDP 还高)
没有滑动窗口时的传输如下:

A 每次需要收到 ACK 之后再发下一个数据
有滑动窗口后:

把 “发送一个等待一个” 改为 “发送一批等待一批”,把多次等待 ACK 的时间合并成一份时间,批量发送的数据越多,可以认为效率就越高

窗口控制与重发控制(在滑动窗口传输中出现丢包情况)
情况一:数据包已抵达,ACK 丢了

情况二:数据包丢了

tip:
滑动窗口/快速重传、确认应答/超时重传,彼此之间并不冲突,他们是分情况的
如果通信双方单位时间发送的数据量比较少,就按照 确认应答/超时重传
如果单位时间发送的数据比较多,就会按照 滑动窗口/快速重传
5) TCP 核心机制(五)——流量控制
滑动窗口的窗口大小对于传输数据的性能是直接相关的,窗口越大传输越快,但是也不能无限大,因为通信是双方的事,发送方发的快的同时也要保证接收方能处理的过来(滑动窗口提高速度,相当于踩油门;流量控制制约速度,相当于踩刹车)

解决方案:通过 “定量” 的方式来实现制约(看接收缓冲区剩余空间大小)

TCP 中接收方收到数据的时候,就会把接收缓冲区剩余空间大小通过 ACK 数据报反馈给发送方
下一步,发送方就可以根据这个数据来设置发送的窗口大小了


tip:流量控制不是 TCP 独有的机制,其他的协议,也可能会涉及到流量控制(比如数据链路层中有的协议也支持流量控制
6) TCP 核心机制(六)——拥塞控制
拥塞控制与流量控制是有关联的(也是踩刹车)
流量控制,站在接收方的视角来限制发送方的速度
拥塞控制,站在传输链路的视角来限制发送方的速度

流量控制可以精准的使用接收方 接收缓冲区 剩余空间来进行衡量
但站在传输链路的角度,考量中间节点的情况就很麻烦了,因此可以通过 “做实验” 的方式来找到一个合适的发送速度(面多加水,水多加面)
1. 先按照一个比较小的速度发送数据
2. 数据非常流畅没有丢包,说明网络上传输数据整体比较流畅,就可以加快传输数据的速度
3. 增大到一定的速度之后,发现丢包了,说明网络上可能存在拥堵了,就减慢传输数据的速度
4. 减速之后,发现不丢包了,再加速
5. 加速之后丢包了,再减速
tip:发送速度是持续动态变化的,因为网络环境也是一直变化的
流量控制和拥塞控制都会限制发送窗口,这两个机制会同时起作用,最终实际的发送窗口大小取决于两个机制得到的发送窗口较小值
拥塞控制中,窗口大小具体的变化过程

1) 刚开始传输数据,拥塞窗口会非常小,用一个很小的速度来发送数据(因为当前网络是否拥堵是未知的,刚启动时发数据很慢)
2) 不丢包,增大窗口大小,指数增长(增长速度特别快,短时间内达到很大的窗口大小)
3) 增长到一定程度,达到某个指定的阈值,此时即使没有丢包,也会停止指数增长,变为线性增长(避免太快进入到丢包的节奏)
4) 线性增长也会使发送速度越来越快,达到某个情况下,就会出现丢包
一旦出现丢包,接下来就要减少发送的速度,减小窗口大小,两种处理方式:
a) 经典的方案,回归到开始非常小的初始值,然后指数增长,再线性增长(已废弃不用)
b) 现在的方案,回归到新的阈值上,线性增长(以后都不会指数增长了)
7) TCP 核心机制(七)——延时应答
延时应答是提升效率的机制,尽可能降低可靠传输带来的性能影响

其实在收到数据的时候,应用程序也会源源不断的消费接收缓冲区中的数据
如果我们返回 ACK 的时间稍晚一点,应用程序就有可能读取缓冲区中更多的数据,假设让 ACK 不是立即返回,而是 100ms 之后再返回,可能在这 100ms 内应用程序又消费掉了 2KB 的数据,此时再返回 ACK 携带的窗口大小就是 6KB了
此时返回的 ACK 窗口大小,大概率要比立即返回 ACK 的窗口大小更大,之所以不是一定:
a) 应用程序代码的实现逻辑是不是一刻不停的读取数据
b) 延时时间内是否发送方会发来新的数据
8) TCP 核心机制(八)——捎带应答
在延时应答的基础上,引入的提升效率的机制,把返回的业务数据和 ACK 两者合二为一了
实际网络通信中,大部分的情况都是 “一问一答” 的形式

9) TCP 核心机制(九)——面向字节流
通过面向字节流的方式传输数据,都会涉及到 “粘包问题”(粘的是 TCP 携带的载荷【应用层数据包】)

上面这样应用层数据包在 TCP 的接收缓冲区中连成一片,粘在一起,就称为 “粘包问题”
要想解决粘包问题,关键就是要明确 “包之间的边界”:
方案一:指定分隔符(适用于文本类的数据,xml、yml、json 用此方案)
在前面 TCP echo server 的例子中,我们约定的做法是,请求响应都以 \n 结尾
发送请求响应的时候,专门使用 println 进行写数据;读取请求响应的时候,专门使用 scanner.next 按照 \n 进行解析
tip:需要确认数据内容的正文中,不能包含分隔符,如果传输的数据是纯文本数据,此时使用 \n 或者 ; 之类的可能都不合适,但是可以使用 ascii 中靠前的 “控制字符”(这些字符早就不再使用了),如下图:

方案二:指定数据的长度(适用于传输二进制,protobuf 用此方案)
例如:约定每个应用层数据包开头的 2 / 4 个字节表示数据包的长度

tip:
1) 如果希望在文件中存储结构化数据,也是存在这样的问题,所以存文件也会经常使用 xml/json 这样的格式来存储(解决粘包问题)
2) UDP 这种面向数据报的传输方式就不涉及 粘包问题 ,因为 send/receive 得到的就是一个完整的 DatagramPacket,这里携带的二进制的字节数组就是一个完整的应用层数据包了
10) TCP 核心机制(十)——异常情况处理
1) 进程崩溃
Java 中的体现就是抛出异常,如果没有 catch 的话,最终会到 JVM,进程就直接无了
进程崩溃看起来挺严重,实际上操作系统会进行善后,当进程崩溃时,进程中的 PCB 就要被回收,PCB 中的文件描述符表里对应的所有文件也都会被系统自动关闭
其中针对 socket 文件,就会触发正常的关闭流程(TCP 四次挥手)
2) 主机关机(正常流程的关机)
正常流程点击关机按钮,此时操作系统会先干掉所有的进程,此过程中也会触发四次挥手,但会分为两种情况:
a) 四次挥手非常快,四次挥手已经完成了,关机动作才真正完成
b) 四次挥手没来的及挥完,关机就完成了,如下图:

3) 主机掉电(拔电源)
a) 接收方掉电

A 给 B 发送的数据不会再有 ACK 了
A 触发超时重传,重传的数据依旧没有响应,反复多次之后,A 尝试重置连接(rst),重置操作也没有 ACK,A 就会单方面释放连接(A 把保存的 B 的信息删除掉)
b) 发送方掉电

A 发着发着数据,突然停了,B 的视角并不知道 A 是无了,还是休息一下,晚点再发
此时 B 就会给 A 发送一个数据包(不携带业务数据,只是为了触发 ACK),查询 A 的状态
如果发了这个 “探测报文” 之后,A 返回了 ACK,说明 A 只是休息一下;若发了探测报文,甚至发了多个探测报文,A 都没有 ACK,就可以视为 A 无了
这种探测报文是周期性的,同时这个报文时用来探测对方的 “生死” 的,于是把这样的报文称为 “心跳包”
计算机中非常广泛的使用“心跳包”的思想,TCP 内置了心跳包,由于 TCP 内置的心跳包周期比较长(秒级~分钟级),应用程序这一层通常也会自行实现一些心跳包,达到更快速的 “保活机制”
4) 网线断开
和主机掉电一样
TCP 中的其他标志位
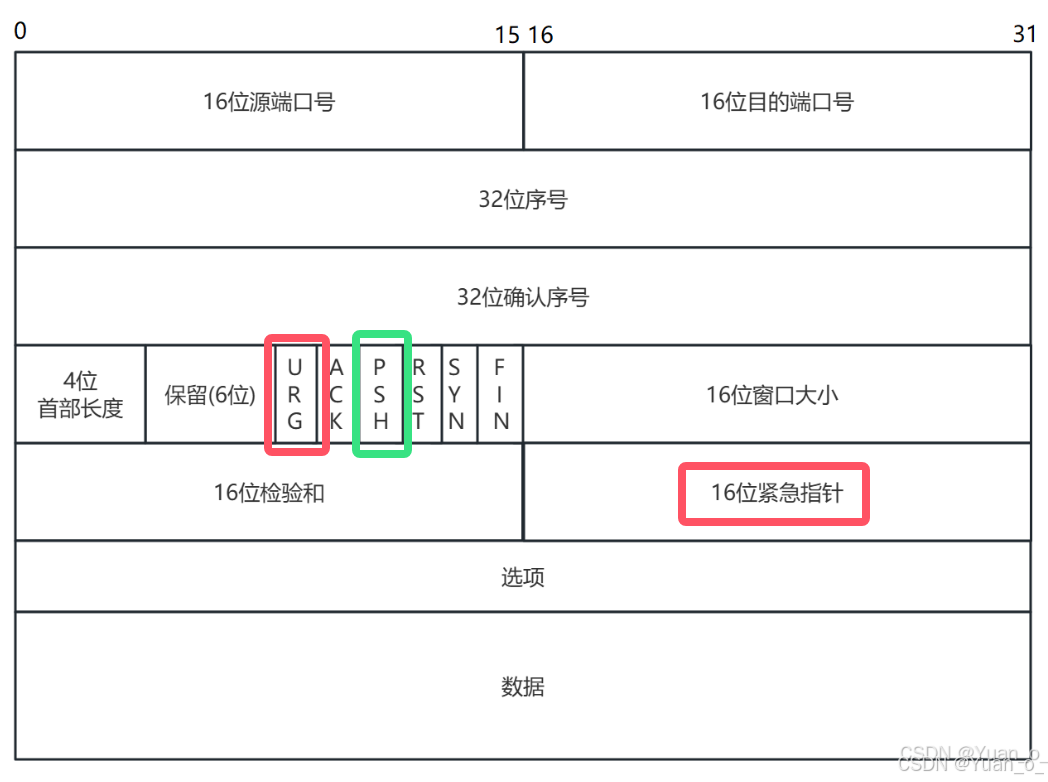
1. URG 是和紧急指针配合使用的
当 URG 设置为 1 时,紧急指针能够生效,紧急指针里面保存的是一个偏移量
TCP 正常情况下,都是按照顺序来传输数据的,紧急指针就是让后谜案的数据排队,根据紧急指针的偏移量,把指定位置的数据优先发送出去(这是特殊场景的特殊方案,不通用,日常开发很少直接涉及)
2. PSH 催促标志位
带有这个标志位的数据就相当于提醒接收方,要尽快的来处理这个数据(也是特殊场景下的特殊方案)
3. 选项
选项中包含 “窗口扩展因子”,结合窗口大小使用
实际窗口大小 = 报头窗口大小 << 窗口扩展因子(相当于指数增长)
TCP/UDP 对比
TCP 对于数据需要可靠传输的场景是首选
UDP 对于可靠性要求不高,对于性能要求很高的场景是首选
经典面试题:用 UDP 实现可靠传输
参考 TCP 的可靠性机制,在应用层实现类似的逻辑,例如:
- 引入序列号,保证数据顺序
- 引入确认应答,确保对端收到了数据
- 引入超时重传,如果隔一段时间没有应答,就重发数据
- 等等。。。
相关文章:
网络原理(3)—— 应用层、传输层(TCP)
1. 应用层 日常开发中最常用到的一层,主要涉及到两种情况: 1) 使用现成的应用层协议 2) 自己定义应用层协议 1.1 自定义应用层协议的流程 1. 明确前后端交互过程中需要传递哪些信息 实例:开发一个外卖软件 打开软件,首先需要展…...

Flutter - Win32程序是如何执行main函数
Win32程序的主体结构 int APIENTRY wWinMain(_In_ HINSTANCE instance, _In_opt_ HINSTANCE prev,_In_ wchar_t *command_line, _In_ int show_command) {// Attach to console when present (e.g., flutter run) or create a// new console when running with a debugger.if …...

linux-系统管理与监控-日志管理
Linux 系统管理与监控:日志管理 1. 日志管理概述 日志文件是系统在运行过程中记录的各种信息,它们是系统管理员排查问题、监控系统健康状况的重要工具。在 Linux 系统中,日志涵盖了系统事件、内核信息、用户操作、软件服务和应用程序等内容…...
VulhubDC-4靶机详解
项目地址 https://download.vulnhub.com/dc/DC-4.zip实验过程 将下载好的靶机导入到VMware中,设置网络模式为NAT模式,然后开启靶机虚拟机 使用nmap进行主机发现,获取靶机IP地址 nmap 192.168.47.1-254根据对比可知DC-4的一个ip地址为192.1…...
[数据集][目标检测]烟叶病害检测数据集VOC+YOLO格式612张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):612 标注数量(xml文件个数):612 标注数量(txt文件个数):612 标注类别…...

Sapiens——人类视觉大模型的基础
引言 大规模预训练以及随后针对特定任务的语言建模微调取得了显著成功,已将这种方法确立为标准做法。同样, 计算机视觉方法正逐步采用大规模数据进行预训练。LAION5B、Instagram-3.5B、JFT-300M、LVD142M、Visual Genome 和 YFCC100M 等大型数据集的出现…...
《深度学习》【项目】 OpenCV 身份证号识别
目录 一、项目实施 1、自定义函数 2、定位模版图像中的数字 1)模版图二值化处理 运行结果: 2)展示所有数字 运行结果: 3、识别身份证号 1)灰度图、二值化图展示 运行结果 2)定位身份证号每一个数…...

机器学习实战—天猫用户重复购买预测
目录 背景 数据集 用户画像数据 用户行为日志数据 训练数据 测试数据 提交数据 其它数据 数据探索 导入依赖库 读取数据 查看数据信息 缺失值分析 数据分布 复购因素分析 特征工程 模型训练 模型验证 背景 商家有时会在特定日期,例如节礼日(Boxing-day),黑…...

一款rust语言AI神器cursor在ubuntu环境下的安装启动教程
虽然cursor目前只支持英文但是它强大的代码联想能力以及问答能力,可以高效的提高编码效率。 如下步骤所有的前提是你的ubuntu上面已经安装了vscode以及其必须的extensions。 1 下载 到官网https://www.cursor.com下载指定版本的软件。 下载到本地以后会生成如下软…...

【C#生态园】发现C#中的数据科学魔法:6款不可错过的库详解
探索C#中的数据科学与机器学习:6个强大库解析 前言 在数据科学和机器学习领域,Python一直占据着主导地位,然而对于习惯使用C#编程语言的开发人员来说,寻找适用于C#的数据科学库一直是一个挑战。本文将介绍几个流行的用于C#的数据…...

导入neo4j数据CSV文件及csv整理demo示例
Neo4j导入CSV文件(实体和关系)_neo4j导入csv关系-CSDN博客 https://blog.csdn.net/m0_69483514/article/details/131296060?spm1001.2101.3001.6661.1&utm_mediumdistribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ER…...

bug | pycharm社区版无sciview解决办法
一个程序运行多个图,plt.show()一次只弹出一个独立窗口,必须关掉一个才能显示下一张图,想找sciview却发现找不到,本来以为是新版pycharm的问题,后来才发现是community版根本没有sciview…不想换专业版了,研…...

PL/SQL程序设计入门
PL/SQL程序设计 PL/SQL起步鼻祖:hello World语法分析声明部分举例 应用举例 PL/SQL 起步鼻祖:hello World 先举个例子,用PL/SQL打印输出hello world declarev_string varchar2(20); beginv_string:hello world;dbms_output.put_line(v_str…...

一、Numpy入门
Numpy入门 前言一、numpy简介二、Numpy的ndarray属性2.1. 直接用 .属性的方法实现2.2. 直接函数的方法实现 三、Numpy的ndarray的创建3.1. ndarray介绍3.2. 数组形式3.3. zeros()、ones() 、 empty()3.4. arange(),类似 python 的 range() ,创建一个一维…...

自动化测试框架设计核心理念——关键字驱动
很多人在接触自动化测试时,都会听到关键字驱动这样的一个概念,但是在研究时却有些不太清楚这种驱动模式的设计及实现到底该如何着手去做。 关键字驱动,作为一种自动化测试框架的设计形式,在很早的时候就已经有提及过了。它的基本…...

GO GIN SSE DEMO
文章目录 接口描述:1.1 /events/time - 时间流1.2 /events/numbers - 数字流 2. 用户管理接口2.1 /user/:id - 获取用户信息2.2 /user - 创建用户 项目结构1. main.go2. 创建 handlers/event_time.go3. 创建 handlers/event_number.go4. handlers/user.go5. 运行服务…...

GEE教程:1950-2023年ECMWF数据中积雪的长时序统计分析
目录 简介 数据 函数 millis() Arguments: Returns: Long 代码 结果 简介 1950-2023年ECMWF数据中积雪的长时序统计分析 数据 ECMWF/ERA5_LAND/DAILY_AGGR是由欧洲中期天气预报中心(ECMWF)提供的数据集。它是一个格网数据集,包含从ERA5-Land再分析数据集中得出的…...

【React Native】路由和导航
RN 中的路由是通过 React Navigation 组件来完成的 Stack 路由导航RN 中默认没有类似浏览器的 history 对象在 RN 中路由跳转之前,需要先将路由声明在 Stack 中<Stack.Navigator initialRouteNameDetails> <Stack.Screen nameDetails /> </Stack.N…...

Linux环境基础开发工具---vim
1.快速的介绍一下vim vim是一款多模式的编辑器,里面有很多子命令,来实现代码编写操作。 2.vim的模式 vim一共有三种模式:底行模式,命令模式,插入模式。 2.1vim模式之间的切换 2.2 谈论常见的模式---命令模式…...

python AssertionError: Torch not compiled with CUDA enabled
查看:torch import torch# 输出带CPU,表示torch是CPU版本的 print(ftorch的版本是:{torch.__version__}) # print(ftorch是否能使用cuda:{torch.cuda.is_available()}) 修改一下代码,将cuda改成cpu 最后运行正常&…...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点 在团队协作或管理多个AI应用项目时,一个常见的痛点是每个…...

DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析
DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify DeTikZify是一款革命性的多模态…...

Actor Framework里的“多米诺骨牌”:一个错误如何让整个嵌套操作者链崩溃?
Actor Framework中的“多米诺效应”:如何避免嵌套操作者链的崩溃 在分布式系统设计中,Actor模型因其天然的并发处理能力而备受青睐。LabVIEW的Actor Framework(AF)通过操作者(actor)的嵌套结构,为复杂系统提供了模块化解决方案。然而&#x…...