基于Spark的电影推荐系统设计与实现(论文+源码)_kaic
摘 要
在云计算、物联网等技术的带动下,我国已步入大数据时代。电影是人们日常生活中重要的一种娱乐方式,身处大数据时代,各种类型、题材的电影层出不穷,面对琳琅满目的影片,人们常感到眼花缭乱。因此,如何从海量电影中快速筛选符合个人喜好的电影,成为了个性化电影推荐系统的热门研究方向。为了向用户推荐高质量的电影,满足其个人喜好,特设计和实现一个电影推荐系统,该系统为用户提供个性化的电影推荐,让用户能够轻松找到符合自己喜好的电影。
该电影推荐系统采用Spark技术,使用基于人口统计学,基于内容以及协同过滤等推荐算法,通过离线、实时和详情页等推荐方式,使用户更加方便快捷地查找符合个人喜好的电影,提高用户满意度。同时,系统也涉及前端查看页面、后台业务处理和算法设计等众多操作,以确保整个系统的精准稳定性和高效性。
关键词:Spark技术;协同过滤;大数据;电影推荐系统
ABSTRACT
Driven by technologies such as cloud computing and the Internet of Things, China has stepped into the era of big data.Film is an important way of entertainment in People's Daily life. In the era of big data, films of various types and themes emerge endlessly, and people often feel dazzled in the face of a dazzling array of films.Therefore, how to quickly select movies that meet personal preferences from a large number of movies has become a hot research direction of personalized movie recommendation system.In order to recommend high quality movies to users and meet their personal preferences, a movie recommendation system is designed and implemented. The system provides users with personalized movie recommendations, so that users can easily find movies that meet their preferences.
The movie recommendation system adopts Spark technology, uses demography based, content based and collaborative filtering recommendation algorithms, through offline, real-time and detailed page recommendation methods, users can more easily and quickly find the movie that meets their personal preferences, and improve user satisfaction.At the same time, the system also involves many operations such as front-end viewing pages, back-end business processing and algorithm design to ensure the accuracy, stability and efficiency of the entire system.
KEY WORDS: Spark Technology;Collaborative Filtering Algorithm;Big Data;Movie Recommendation System
目 录
第1章 绪论1
1.1 课题背景1
1.2 课题的目的和意义2
1.3 国内外研究现状2
1.4 课题研究的内容3
第2章 电影推荐系统的开发技术介绍4
2.1 推荐系统相关技术4
2.1.1 Spark4
2.1.2 MongoDB4
2.1.3 Web4
2.2 推荐算法介绍5
2.2.1 基于人口统计学的推荐算法5
2.2.2 基于内容的推荐算法6
2.2.3 基于协同过滤的推荐算法7
2.3 推荐系统介绍7
第3章 电影推荐系统分析和设计9
3.1 电影推荐系统分析9
3.1.1 可行性分析9
3.1.2 功能需求分析9
3.2 电影推荐系统设计10
3.2.1 基于人口统计学的推荐算法设计10
3.2.2 基于内容的推荐算法设计11
第4章 电影推荐系统实现14
4.1 系统开发环境14
4.1.1 系统环境介绍14
4.1.2 系统服务运行14
4.2 系统功能的实现16
4.2.1 用户登录与注册16
4.2.2 个性化推荐17
4.2.3 电影搜索24
4.2.4 用户评分25
第5章 电影推荐系统测试27
5.1 功能测试27
5.2 性能测试28
结论29
参考文献30
致谢31
第1章 绪论
1.1 课题背景
在当今快速发展的互联网时代,各种网站和应用程序如雨后春笋般涌现,为用户提供资源访问,涵盖音乐、电影、书籍、商品等领域,极大地便利了人们的生活。然而,随着互联网资源的日益丰富,选择符合自己喜好的项目变得非常耗时,最终可能无法实现,导致时间的严重浪费。因此,迫切需要一种个性化的推荐系统,能够为用户提供符合其偏好的资源,并过滤掉冗余信息[1]。
个性化推荐系统基于用户与物品之间的隐藏特征构建模型,根据模型向用户推荐符合用户偏好和需求的信息,从而节省用户寻找自己喜欢的资源的时间。许多互联网科技公司,如腾讯、网易云、百度等,都把推荐系统作为一个热门的研究领域,且在不同的应用领域都有自己的专长。由于用户有不同的兴趣爱好和关注的领域,推荐系统需要针对不同的用户进行有针对性的推荐,以满足他们的个性化需求。
推荐系统已经广泛渗透到人们生活的各个领域,成为互联网行业研究的热点项目之一。随着计算机网络和信息载体技术的飞速发展,视频领域尤其受益。视频网站每天积极更新作品,也有大量用户上传自制作品,丰富了网站的内容信息。然而,作品数量的不断增加也给网站带来了巨大的负担,这就凸显了一个高质量的推荐系统对于视频网站的重要性。
目前,主流的视频网站可以分为两类。一类是提供专业影视作品的视频网站,如优酷、爱奇艺、土豆视频等。这些网站的数据结构比较完整,主要向用户推荐完整的电影,这些电影的生命周期很长,但有时会因为持续时间长,内容相对单调而让用户感到无聊。另一类是用户原创视频,这些视频在上传到视频网站之前被打上标签,这些视频网站以短视频为主,如哔哩哔哩、抖音和快手。这些网站上的视频种类和数量都非常丰富,内容也非常丰富多样。但由于审查水平低,数据结构混乱、不完整,劣质视频层出不穷。这些作品的生命周期很短,随着时间的推移,它们会逐渐从公众的视野中消失。
这两种视频网站各有优缺点,但无论是哪一种视频网站,都面临着作品增多、信息过载的问题。一方面,视频网站的用户希望能够从海量的影视资源中快速挑选出符合自己口味的作品,从而提高影视资源的获取效率。另一方面,一些企业希望通过向客户推荐相关度高、兴趣度高的影视资源,树立良好的品牌形象,增强客户对企业的信任和忠诚度,从而激活客流量,减少客户流失。
因此,在影视推荐系统的研究过程中,寻找更有效的方式,根据用户的喜好来推荐影视资源,成为重要的研究内容之一。
1.2 课题的目的和意义
随着社会的迅速发展,计算机技术的应用范围越来越广泛,技术的进步也在推动社会变革。信息量的巨大增长让数据统计难度加大,甚至造成一定程度信息冗杂超出承载量,这也是当下互联网需要急需解决的问题。对于大量数据的运用,需要对互联网进行改进,首先需要的便是开发搜索系统,能帮用户快速梳理数据。而搜索系统的运行也需要在用户使用前对数据进行整合处理,当用户需要某个数据时搜索系统便能根据搜索中的规则进行快速获取信息。接下来就是推荐系统,所谓的推荐系统则是基于搜索系统上对用户信息进行整合后的再生成,以便用户在有需求时主动推荐,让用户有更多选择。简而言之,搜索和推荐虽侧重不同,但都作为用户的助手,能帮助用户在冗杂庞大的数据面前为用户提供清晰的数据思路,让用户能使用关键词就能迅速检索信息,因此,在这种情况下,推荐系统显得尤为重要。
本系统的开发在Spark的电影推荐系统中进行的升级和改善,参考并使用协同过滤算法来向用户推荐电影。该推荐系统具备处理大量数据的能力,而Spark计算框架则是目前最先进的一代框架之一,将这个用于大数据的计算可以较大地提高推荐系统运行效率。
1.3 国内外研究现状
早期在搜索系统的使用中受到一定的启发,便使得推荐系统的开发有了一定的指向性,尤其体现在对数据内容的推荐上。这方法不但可以自行分析物品的内容,还能自我检索出用户使用习惯和使用频次来自主建立用户能够确定推荐物品的相关性大小,从而为用户提供更加个性化和符合其兴趣的推荐内容[2]。但是,由于当时信息技术有限,这也使得互联网对数据的挖掘深度和方向有一定的限制,造成某些信息提取的准确度不高,比如模式复杂的信息(如音乐、戏剧等),因此推荐系统中侧重于数据内容的推荐不是很好。在这些方法中,基于协同过滤的推荐算法是最为经典的[3]。
尽管国内推荐系统的应用比国外稍晚,但其发展速度极快。当前,国内许多影视网站都已经建立了自己的推荐系统,比如腾讯视频的“猜你会追”、爱奇艺的“猜你喜欢”以及优酷的“今日推荐”等推荐模块[4]。为了处理庞大的推荐系统计算数据,各互联网公司纷纷采用了通用计算引擎Spark,包括腾讯、优酷土豆等在线视频软件公司。
Spark拥有多项功能,这为电影推荐系统提供了巨大的便利。通过使用Spark,这些公司能够更高效地处理大规模的数据,进行实时的数据分析和处理。此外,Spark还具备机器学习能力,可以根据用户的行为和偏好进行模型训练和推荐优化,提供更加个性化和精准的推荐结果。
借助Spark的强大功能,电影推荐系统能够更好地应对数据量的挑战,并提供更好的用户体验。互联网公司通过利用Spark的技术优势,不仅能够更好地理解用户的喜好和兴趣,还能够利用机器学习算法不断优化推荐效果,提供更符合用户需求的推荐内容[5]。
1.4 课题研究的内容
本文使用Spark技术来实现电影推荐系统,不但设计了软件架构体系,还要将该系统进行分层,比如view层、business层等。以上四大模块中的实时推荐模块则是使用Spark Streaming技术来实时推荐电影。而离线推荐却是使用了基于人口统计学的推荐算法。热门推荐模块和详情页推荐模块分别采用Spark计算框架和基于内容的推荐算法来实现。通过这些模块的结合,系统能够根据用户的历史行为和实时需求,提供个性化、精准的电影推荐服务。
第2章 电影推荐系统的开发技术介绍
2.1 推荐系统相关技术
2.1.1 Spark
本项目所采用的核心技术是Spark,它是一种用于大数据分析计算的引擎框架,能够有效处理企业级数据的批量处理任务。Spark框架具备以下突出的优点:
1)Spark采用Scala作为函数式编程语言,并与Java兼容,具有简洁的语法和多样的数据结构,提供了强大的编程能力。
2)Spark采用内存存储中间数据的策略,不同于MapReduce的磁盘存储方式,使得Spark在迭代计算时运算速度更快。这种方式大大加速了数据处理能力,减少了磁盘I/O的时间消耗。
3)Spark能够处理大批量复杂格式的数据转换,并且易于上手。它的核心数据结构RDD(弹性分布式数据集)使用Java对象作为数据格式,减少了反序列化和对象序列化的开销。
本项目选择使用Spark作为分布式数据处理引擎,该框架以单独的进程运行每个应用程序,保留进程状态,并采用多线程运行模式,从而减少了线程切换的时间开销,提高了任务执行的效率。此外,Spark生态系统提供了多种实用组件,方便开发人员实现业务逻辑和实时数据处理,并降低了机器学习部分的编写难度。基于这些优势,本项目选择Spark技术,以提高运行速度、支持批量数据的并行处理,并能够灵活使用多种组件来满足项目需求。
2.1.2 MongoDB
MongoDB是一种非关系型的数据库,这种数据库采用“键值对”的形式来存储数据。由于这种结构化方式,MongoDB非常适用于处理大规模数据,系统还可以通过增加硬件设备来进行扩展,以提高系统的处理能力。MongoDB采用了简单索引机制,使得查询操作更加高效。此外,MongoDB支持不同数据格式的存储,对数据格式的要求较低,能够满足Web应用的需求。
2.1.3 Web
在后端运行方面,本项目采用了Spring和Maven作为关键框架。Spring框架通过使用.xml和.resource文件进行项目环境的配置,从而简化了环境设置的流程。同时,Spring框架保留了AOP和IOC的特性,为后端模块的开发提供了便利。而Maven技术用于管理项目的依赖库,并提供了方便的打包和部署功能。
在前端方面,本项目选择了AngularJS2框架作为开发工具。AngularJS2是一个轻量级的响应式网站系统,它具备适应多种屏幕尺寸的能力,并且拥有美观大方的设计特点。这使得前端开发更加灵活和易于实现。
2.2 推荐算法介绍
推荐系统的关键在于推荐算法,它对推荐系统的推荐质量产生了深远的影响。因此,在不同的应用环境中选择合适的推荐算法非常重要。本章简要介绍了三种常见的推荐算法,包含以人口统计为核心的推荐方法、以内容为核心的推荐方法和基于协同过滤的推荐方法。
2.2.1 基于人口统计学的推荐算法
这种算法与其他推荐算法不同,不需要用户的历史行为偏好数据,因此称之为无历史行为偏好数据算法。相比于其他推荐算法,基于人口统计学的算法具有较高的可解释性和易理解性。在这种算法中,当用户不提供足够的信息或者处于用户初步了解阶段,可以使用人口统计学数据对其进行推荐,因此它不会遇到冷启动问题。如图2.1所示。
图2.1 基于人口统计学的推荐示例图
该算法的核心是用户的基本信息,但即使没有这些信息,仍可以收集用户的隐藏信息。例如,可以获取用户在浏览器中登录的时间、地点、时段和时长等上下文信息,并将其转化为用户标签。随后,可以使用聚类方法对这些标签进行数据处理,提取出一些特征,以便对用户进行推荐。
如果找到了特定标签的用户,则可以根据预设规则向他们推荐商品。这些规则可以自行定义,也可以通过模型发现。用户如果打上这些标签,根据这些数据了解消费者的全貌并进行精准定位,以进行更有效的营销推荐。
然而,这种推荐算法存在一些缺点,主要表现为推荐准确率较低,并且很难获取用户的个人身份信息。因此,这并不是业界主流的推荐算法。但是,使用大数据分析可以对用户的行为数据进行特征提取和标签打标,以实现更准确的推荐和更深入的用户画像。
2.2.2 基于内容的推荐算法
基于内容的推荐算法是一种主要依赖物品内容的推荐方法。它通过为每个物品打上标签,然后找到具有相似标签的其他物品,从而为用户提供推荐。例如,假设用户A喜欢电影《美国队长2》,系统会分析该电影的基本内容信息,并提取关键标签,如动作、间谍、惊险等。然后,系统将根据这些标签来寻找其他具有相似内容信息的电影,然后推荐给用户,算法核心在于对物品的内容进行特征提取和相似度匹配,而不是依赖用户的基本信息或行为数据。因此,这种算法在一些领域,如新闻推荐和音乐推荐等方面,能够产生比较好的效果。如图2.2所示。
图2.2 基于内容的推荐示例图
基于内容的推荐算法通过处理电影的元数据,抽取电影的内在特征值并构建特征向量,计算其与其他电影的距离与相似度,以此推荐给用户相似的电影。这种算法具有简单快速、推荐结果相对准确和稳定性强的特点。然而,它也存在一个较大的问题,即过度依赖物品内容和标签数据的完整性。
在互联网上存在着数量庞大的信息和事物,很难对它们进行严格和全面的手动描述。因此,对于一个新的物品来说,如果它的描述标签尚未出现,那么它很难被准确地推荐给用户。这限制了基于内容的推荐算法的适用范围和准确度。
此外,这种算法仅关注事物自身的特点,而没有考虑使用者对事物的态度和偏好。因此,在挖掘使用者潜在兴趣和对新用户进行推荐方面存在明显的缺陷。它无法全面考虑用户的喜好和行为,可能导致推荐结果与用户的实际需求和偏好不完全匹配。
有些网站采用专业人员手动打标签的方法来获取电影、音乐、图书等物品的元数据,而不是使用机器学习算法来提取信息。因为机器学习算法提取的信息可能不够准确,如果成本允许,采用专业人员的标签会提高推荐效果,这就被称为专家生成的内容(PGC)。相对应的,还有一种叫做用户生成内容(UGC)的概念,用户可以根据自己的行为数据对物品进行标签。
2.2.3 基于协同过滤的推荐算法
通过挖掘用户和物品之间的特征相似度,从海量的用户和物品中寻找出能够满足用户需求的物品,并进行推荐,从而实现了个性化推荐。该算法是在计算用户兴趣、习惯和物品特征之间的关系的基础上进行的。根据用户的历史行为来预测未来可能喜欢的物品,从而提高用户满意度。协同过滤算法面临两个主要问题:数据稀疏性和冷启动问题。
类似于分类过程,可以通过比较近邻的分类标签来预测目标用户的喜好。这种方法可以根据物品的标签和分类信息,找到与目标用户喜欢的物品相似的其他物品,从而进行推荐。而基于模型的推荐算法则是通过使用用户行为数据来训练一个模型,通过分析这些数据,可以挖掘出用户和物品之间的特征和规律。然后,利用这些特征和规律来进行个性化的推荐预测。
2.3 推荐系统介绍
推荐系统的目的是将用户和物品联系起来,以满足用户的个人喜好需求。它的主要作用是帮助用户发现他们感兴趣的物品,同时也将物品展示给感兴趣的用户。三者之间的关系如图2.3所示:
图2.3 推荐系统关系图
通常,推荐系统的设计包括以下三个步骤:
首先,系统需要收集用户过去的行为数据并将其存储在数据库中。
随后,对这些数据进行分析,以建立用户和物品的模型,并提取有用的信息。通过使用相关的推荐算法,计算基于用户或物品的相似度。
最后,系统会将与用户兴趣相符合的前几个物品推荐给他们,以便他们可以更容易地发现自己感兴趣的物品。







相关文章:
基于Spark的电影推荐系统设计与实现(论文+源码)_kaic
摘 要 在云计算、物联网等技术的带动下,我国已步入大数据时代。电影是人们日常生活中重要的一种娱乐方式,身处大数据时代,各种类型、题材的电影层出不穷,面对琳琅满目的影片,人们常感到眼花缭乱。因此,如…...

基于python+django+vue的医院预约挂号系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示 【2025最新】基于协同过滤pythondjangovue…...

镀金引线---
一、沉金和镀金 沉金和镀金都是常见的PCB金手指处理方式,它们各有优劣势,选择哪种方式取决于具体的应用需求和预算。 沉金(ENIG)是一种常用的金手指处理方式,它通过在金手指表面沉积一层金层来提高接触性能和耐腐蚀性…...
『功能项目』窗口可拖拽脚本【59】
本章项目成果展示 我们打开上一篇58第三职业弓弩的平A的项目, 本章要做的事情是给坐骑界面挂载一个脚本让其显示出来的时候可以进行拖拽 创建脚本:DraggableWindow.cs using UnityEngine; using UnityEngine.EventSystems; public class DraggableWindo…...

Map--08--CurrentHashMap 与 Hashtable的异同?
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Map方法computeIfAbsent1.computeIfAbsent 方法的简介2.案例computeIfAbsent() Map方法computeIfAbsent computeIfAbsent方法是Java 8中引入的一种简化操作Map的方…...
存储与卷)
Docker学习笔记(三)存储与卷
挂载机制介绍 我们都知道,默认下,Docker容器与宿主机是完全隔离的,这种特性使得我们创建与删除容器都变得更方便,不需要再去删除宿主机上容器遗留下来的痕迹。 但是,当我们使用数据库一类需要持久化数据、共享数据…...

硬件工程师笔试面试——滤波器
目录 12、滤波器 12.1 基础 滤波器原理图 滤波器实物图 12.1.1 概念 12.1.2 滤波器的分类 12.1.3 滤波器的工作原理 12.1.4 滤波器的应用 12.1.5 滤波器设计的关键参数 12.2 相关问题 12.2.1 不同类型的滤波器在实际应用中的具体作用是什么? 12.2.2 如何设计一个简…...

【SpringBoot3】面向切面 AspectJ AOP 使用详解
文章目录 一、AspectJ介绍二、简单使用步骤1、引入依赖2、定义一个Aspect3、开启AOP支持 三、AOP 核心概念四、切点(Pointcut)1. execution2. within3. this & target4. args & args5. within & target & annotation 五、通知࿰…...
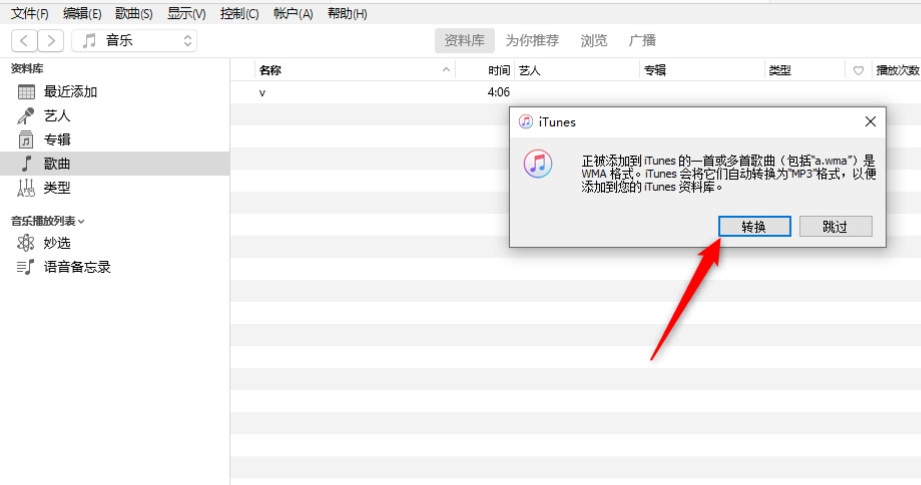
wav怎么转mp3格式?给你推荐几种音频格式转换方法
wav怎么转mp3格式?将wav文件转换为MP3格式是一个常见的操作,尤其适用于需要节省存储空间或确保文件兼容性的场景。wav文件保存了音频的所有原始数据,这使得它们的文件体积往往非常庞大。相比之下,MP3格式通过有损压缩技术显著减小…...

Redis的AOF持久化、重写机制、RDB持久化、混合持久化
1、AOF持久化 1.1.AOF持久化大致过程 概括:命令追加(append)、文件写入、文件同步(sync) Redis 每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里,然后重启 Redis 的时候&#…...

Dom4j使用xpath查询xml文
Dom4j使用xpath查询带有命名空间的xml文件 方式1 忽略命名空间 DocumentFactory factory DocumentFactory.getInstance(); SAXReader reader new SAXReader(factory); Document document reader.read(xmlFilePath); Element rootElement document.getRootElement(); Nod…...

国家专精特新小巨人企业指标解析与扶持领域
一、什么是国家专精特新小巨人 (一)概念与定义 专精特新“小巨人”企业是指那些在细分市场中具有专业化、精细化、特色化和新颖化特征的中小企业中的佼佼者。这些企业在创新能力强、市场占有率高、掌握关键核心技术以及质量效益方面表现突出࿰…...

进程的属性
tips: task_struct就是linux下的PCB 操作系统不相信任何外部用户,而是只提供窗口,不可能直接与用户打交道,而是通过操作系统 tast_struct用来描述所有进程,用来管理 ; 和 && 可以同时跑两个命令 进…...

Git 中的refs
在 Git 中,refs 是用来存储 Git 对象(如提交、树、标签等)的引用。每个 ref 都是一个指针,指向一个特定的 Git 对象。以下是 Git 中几种常见的 refs 及其含义: 1. refs/heads/ 表示:本地分支。 用途&…...

408算法题leetcode--第六天
58. 最后一个单词的长度 58. 最后一个单词的长度思路:反向遍历时间:O(n);空间:O(1) class Solution { public:int lengthOfLastWord(string s) {int id s.size() - 1;while(s[id] ){--id;}int ret 0;while(id > 0 &&…...

ubuntu64位系统无法运行32位程序的解决办法
在 64 位的 Ubuntu 系统上运行 32 位程序时,如果出现问题,可能是由于缺少 32 位库支持。以下步骤可以帮助你解决这一问题: 1. 启用 32 位架构 首先,确保系统支持 32 位架构。你可以通过以下命令添加 32 位架构支持: …...

深入理解Go语言中的并发封闭与for-select循环模式
在现代编程中,并发已经成为提高程序性能和响应能力的关键手段。然而,在并发环境下,如何安全地访问和操作共享数据却是一大挑战。本文将深入探讨Go语言中的**封闭(confinement)**技术,以及常见的for-select循环模式,帮助您编写更高效、更安全的并发代码。 并发编程中的安…...

Java学习Day42:骑龙救!(springMVC)
springMVC与sevlet都是对应表现层web的,但是越复杂的项目使用SpringMVC越方便 基于Java实现MVC模型的轻量级web框架 目标: 小案例: 1.导入依赖 spring-context: 提供 Spring 框架的核心功能,如依赖注入、事件发布和其他应用上…...

原型模式详细介绍和代码实现
🎯 设计模式专栏,持续更新中, 欢迎订阅:JAVA实现设计模式 🛠️ 希望小伙伴们一键三连,有问题私信都会回复,或者在评论区直接发言 Java实现原型模式 介绍: 原型模式(Prototype Patte…...
地图创作 5 图层样式)
ArcGIS Pro SDK (十三)地图创作 5 图层样式
ArcGIS Pro SDK (十三)地图创作 5 图层样式 文章目录 ArcGIS Pro SDK (十三)地图创作 5 图层样式1 风格管理1.1 如何按名称获取项目中的样式1.2 如何创建新样式1.3 如何向项目添加样式1.4 如何从项目中删除样式1.5 如何将样式项添加到样式1.6 如何从样式中删除样式项1.7 如…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...