通过多模态关系图学习实现可解释的医学图像视觉问答|文献速递--Transformer架构在医学影像分析中的应用
Title
题目
Interpretable medical image Visual Question Answering via multi-modal relationship graph learning
通过多模态关系图学习实现可解释的医学图像视觉问答。
01
文献速递介绍
医学视觉问答(VQA)是医学多模态大语言模型(LLMs)中的一项重要任务,旨在回答与医学图像相关的临床问题。这是一项具有挑战性的任务,需要结合医学图像诊断和自然语言理解。医学VQA能够为临床医生在解释医学图像时提供“第二意见”,从而降低误诊的风险(Tschandl等,2020)。它还可以部分承担放射科医生的专家咨询角色,回答来自医生和患者的问题,避免中断他们的工作流程,提高效率(Lin等,2023a)。
多模态大语言模型可用于执行这些任务,从而有助于减少低收入和中等收入国家的全球健康不平等现象。例如,在解释复杂病例时,当缺乏专业专家时,医学VQA系统提供的第二意见可能显著增强初级临床医生的信心。部署这样的系统还可以缓解资源匮乏地区的医疗服务短缺,例如非洲,该地区仅占全球医疗劳动力的3%,却承担了全球24%的疾病负担(世界卫生组织等,2021)。医学VQA可以通过降低资源匮乏国家的医疗成本,促进健康生活和福祉,为可持续发展目标(SDGs)做出贡献。
Abatract
摘要
Medical Visual Question Answering (VQA) is an important task in medical multi-modal Large Language Models(LLMs), aiming to answer clinically relevant questions regarding input medical images. This technique hasthe potential to improve the efficiency of medical professionals while relieving the burden on the publichealth system, particularly in resource-poor countries. However, existing medical VQA datasets are small andonly contain simple questions (equivalent to classification tasks), which lack semantic reasoning and clinicalknowledge. Our previous work proposed a clinical knowledge-driven image difference VQA benchmark usinga rule-based approach (Hu et al., 2023). However, given the same breadth of information coverage, the rulebased approach shows an 85% error rate on extracted labels. We trained an LLM method to extract labels with62% increased accuracy. We also comprehensively evaluated our labels with 2 clinical experts on 100 samplesto help us fine-tune the LLM. Based on the trained LLM model, we proposed a large-scale medical VQA dataset,Medical-CXR-VQA, using LLMs focused on chest X-ray images. The questions involved detailed information,such as abnormalities, locations, levels, and types. Based on this dataset, we proposed a novel VQA methodby constructing three different relationship graphs: spatial relationships, semantic relationships, and implicitrelationship graphs on the image regions, questions, and semantic labels. We leveraged graph attention tolearn the logical reasoning paths for different questions. These learned graph VQA reasoning paths can befurther used for LLM prompt engineering and chain-of-thought, which are crucial for further fine-tuning andtraining multi-modal large language models. Moreover, we demonstrate that our approach has the qualitiesof evidence and faithfulness, which are crucial in the clinical field.
医学视觉问答(Visual Question Answering, VQA)是医学多模态大语言模型(LLMs)中的一项重要任务,旨在回答与输入医学图像相关的临床问题。该技术有潜力提高医疗专业人员的工作效率,同时减轻公共卫生系统的负担,尤其是在资源匮乏的国家。然而,现有的医学VQA数据集规模较小,仅包含简单问题(相当于分类任务),缺乏语义推理和临床知识。
我们之前的工作提出了一种基于规则的方法(Hu等,2023),构建了一个临床知识驱动的图像差异VQA基准。然而,在相同的信息覆盖广度下,基于规则的方法在提取标签时表现出85%的错误率。我们训练了一种大语言模型方法来提取标签,准确率提高了62%。我们还与两位临床专家对100个样本的标签进行了全面评估,以帮助我们微调大语言模型。
基于训练好的大语言模型,我们提出了一个大型医学VQA数据集,称为Medical-CXR-VQA,专注于胸部X光图像。所涉及的问题包含详细信息,如异常、位置、程度和类型。在此数据集的基础上,我们提出了一种新颖的VQA方法,通过构建三种不同的关系图:图像区域、问题和语义标签上的空间关系图、语义关系图和隐含关系图。我们利用图注意力机制来学习不同问题的逻辑推理路径。这些学习到的图VQA推理路径可进一步用于大语言模型的提示工程和思维链,这对于进一步微调和训练多模态大语言模型至关重要。
此外,我们的方法展示了证据和可信度的品质,这在临床领域中至关重要。
Method
方法
Given an input medical image 𝐈𝑖 and a question 𝐪𝑖 , as shown inFig. 7, we aim to predict the answer to 𝐪𝑖 based on image information. We propose a multimodal graph-learning model, as shown inFig. 7, by first extracting the region of interest (ROI) using a pretrained Faster R-CNN and then considering each ROI as a node inthe graph. We considered three different relationships to build thegraph relationship/edges: (1) spatial relationships based on ROI-wisespatial locations, (2) semantic relationships based on medical expertknowledge, and (3) implicit relationships to discover additional latentrelationships. Lastly, we compute the answer by fusing multimodalgraphs with a multilayer perceptron network.
给定输入医学图像 𝐈𝑖 和一个问题 𝐪𝑖,如图7所示,我们的目标是基于图像信息预测问题 𝐪𝑖 的答案。我们提出了一种多模态图学习模型,如图7所示,首先使用预训练的Faster R-CNN提取感兴趣区域(ROI),然后将每个ROI视为图中的一个节点。
我们考虑了三种不同的关系来构建图的关系/边:(1) 基于ROI空间位置的空间关系;(2) 基于医学专家知识的语义关系;(3) 用于发现额外潜在关系的隐含关系。最后,我们通过将多模态图与多层感知器网络融合来计算答案。
Conclusion
结论
To promote the development of multi-modal Large Language Modelin medical research, we have utilized LLMs to create a large-scale,clinically driven medical VQA dataset named Medical-CXR-VQA. Thisserves as an extension of our previous work (Hu et al., 2023), whichused a conventional rule-based approach. Our LLM-based approachimproved the dataset construction accuracy by 62% when given thesame keyword extraction set. Furthermore, we proposed a multirelationship graph learning method for VQA, and our method canhighlight the selected reasoning path for answering different questions.The underlying reasoning path can be used to build a chain of thoughtin medical LLM and construct medical knowledge-driven prompts fortraining medical LLM, which will be part of our future work.
为了促进多模态大语言模型在医学研究中的发展,我们利用大语言模型(LLMs)创建了一个名为Medical-CXR-VQA的大规模、临床驱动的医学VQA数据集。这是对我们之前工作的扩展(Hu等,2023),该工作使用了传统的基于规则的方法。我们的基于LLM的方法在相同关键词提取集的情况下将数据集构建的准确性提高了62%。此外,我们提出了一种用于VQA的多关系图学习方法,该方法能够突出回答不同问题的选定推理路径。
这种潜在的推理路径可用于在医学大语言模型中构建思维链,并构建医学知识驱动的提示,以训练医学大语言模型,这将是我们未来工作的一个部分。
Figure
图
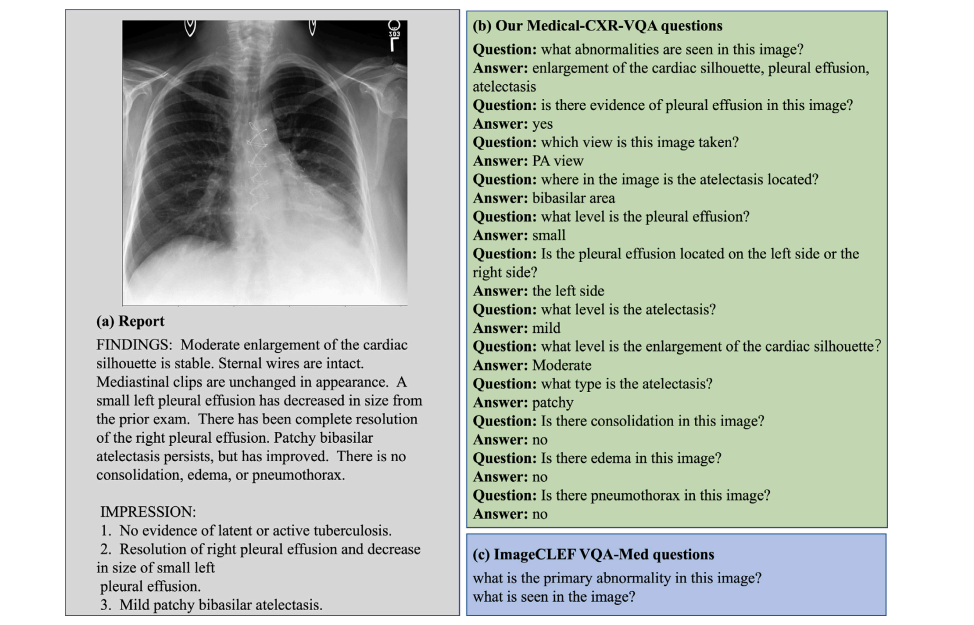
Fig. 1. A comparison between our constructed VQA dataset and the existing ImageCLEF VQA-Med dataset. (a) The report corresponds to the given Chest X-ray image. (b) Ourconstructed question settings, including abnormality, presence, view, location, level, and type. (c) The design of the ImageCLEF VQA-MED questions is too simple.
图1. 我们构建的VQA数据集与现有的ImageCLEF VQA-Med数据集的比较。(a) 报告与给定的胸部X光图像相对应。(b) 我们构建的问题设置,包括异常、存在、视角、位置、程度和类型。(c) ImageCLEF VQA-MED问题的设计过于简单。
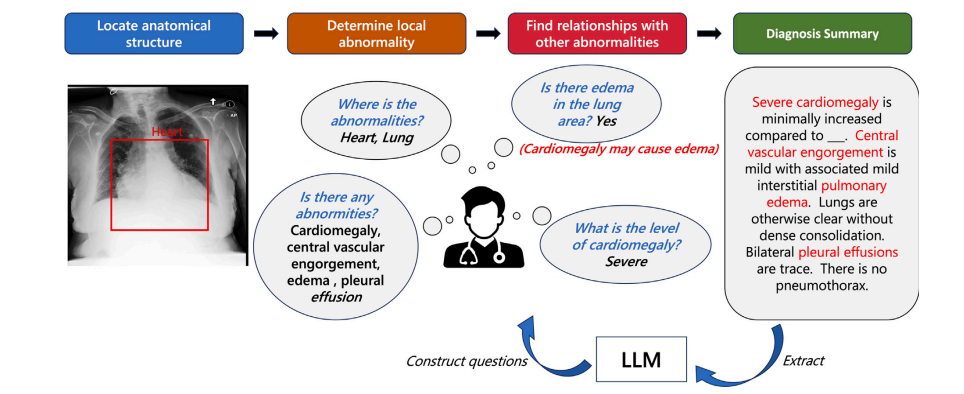
Fig. 2. Clinical practical diagnostic procedure and extraction of clinical key information using LLM for constructing a medical VQA dataset. We further propose a multi-graphmethod for medical VQA and graph reasoning on this dataset. Our proposed graph reasoning path can further be used to build chains of thought on medical LLM (Wei et al.,2022).
图2. 临床实际诊断过程及利用大语言模型(LLM)提取临床关键信息以构建医学VQA数据集。我们进一步提出了一种用于医学VQA的多图方法和在该数据集上的图推理。我们提出的图推理路径还可以用于在医学大语言模型(Wei等,2022)上构建思维链。
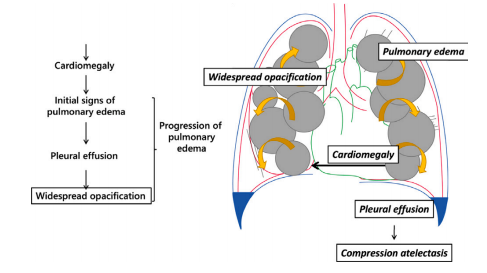
Fig. 3. Clinical motivation for the construction of our dataset and VQA method derivedfrom disease progression.
图3. 我们的数据集构建和VQA方法的临床动机源于疾病进展。
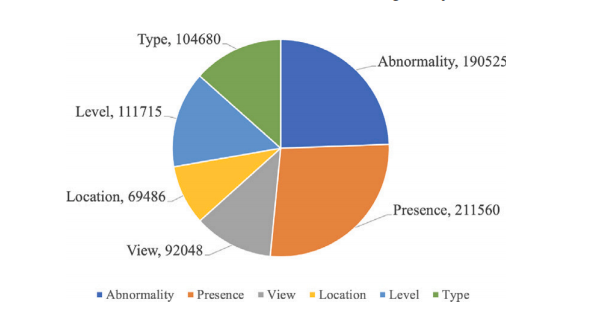
Fig. 4. Question type distribution.
图4. 问题类型分布。
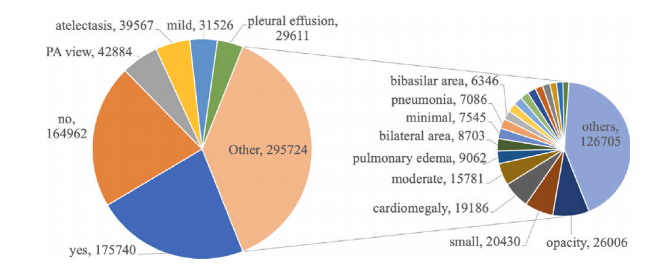
Fig. 5. Answer type distribution.
图5. 答案类型分布。
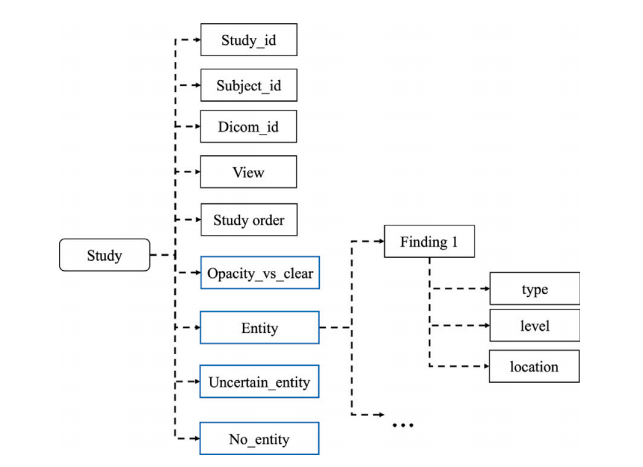
Fig. 6. Detailed structure of KeyInfo for each study.
图6. 每项研究的关键信息(KeyInfo)详细结构。
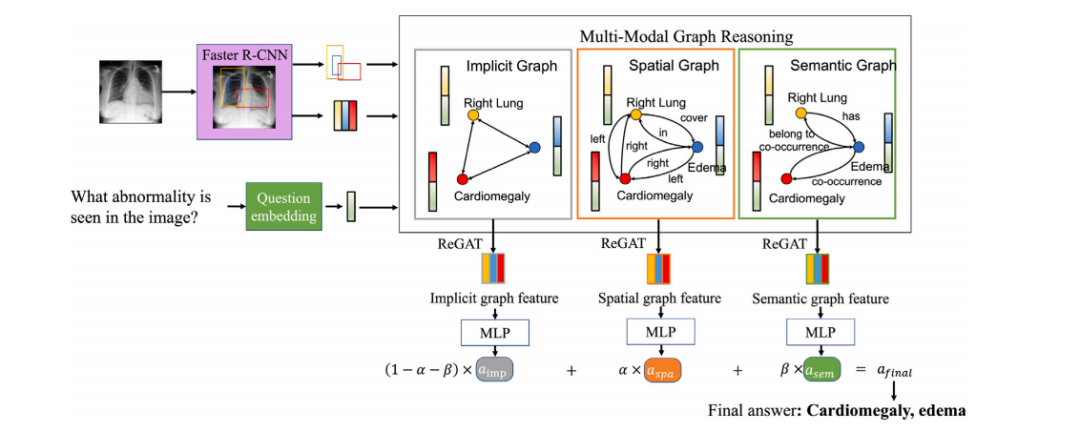
Fig. 7. Proposed multi-modal graph learning medical VQA framework.
图7. 提出的多模态图学习医学VQA框架。
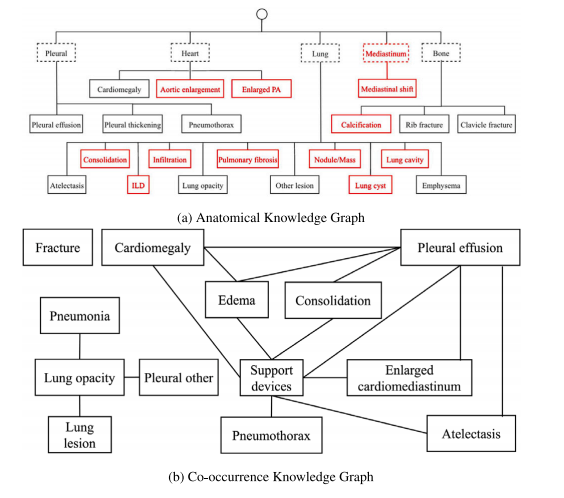
Fig. 8. Knowledge graphs.
图8. 知识图谱。
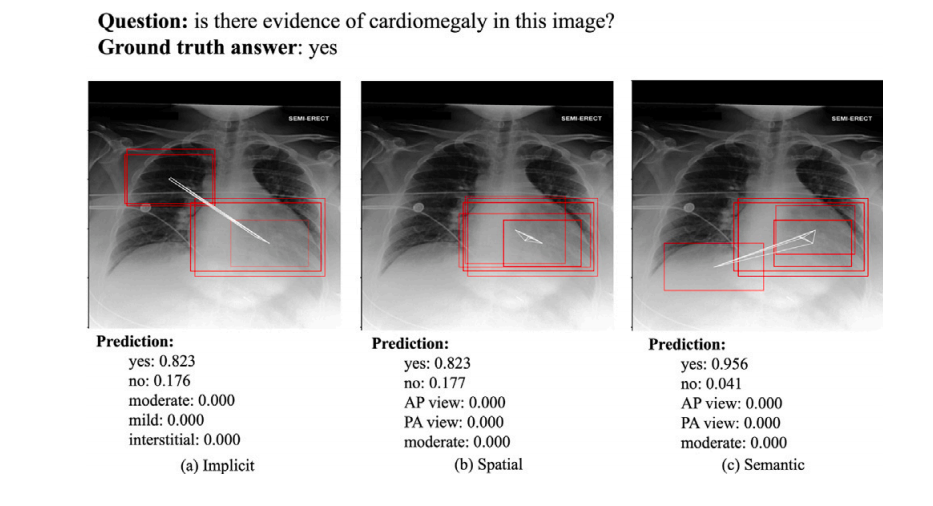
Fig. 9. An example of the ROIs visualization for presence. The red bounding boxes are the activated ROIs.
图9. 一个关于存在的ROI(感兴趣区域)可视化示例。红色边框表示激活的ROI。
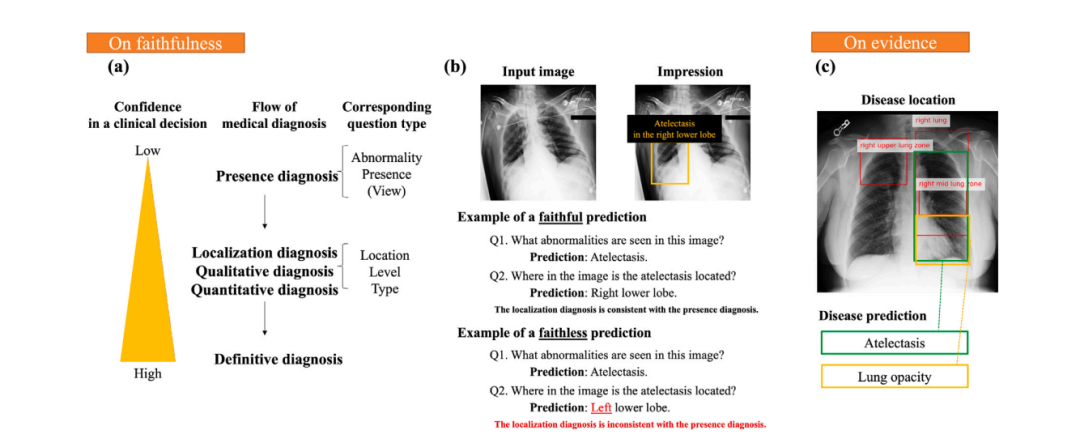
Fig. 10. Illustration of faithfulness and evidence: (a) As finer questions are asked, diagnosis confidence increases. (b) Examples of faithful and faithless predictions. (c) Illustration of evidence.
图10. 可信度和证据的说明:(a)随着更细化问题的提出,诊断信心增加。(b)可信和不可信预测的示例。(c)证据的说明。
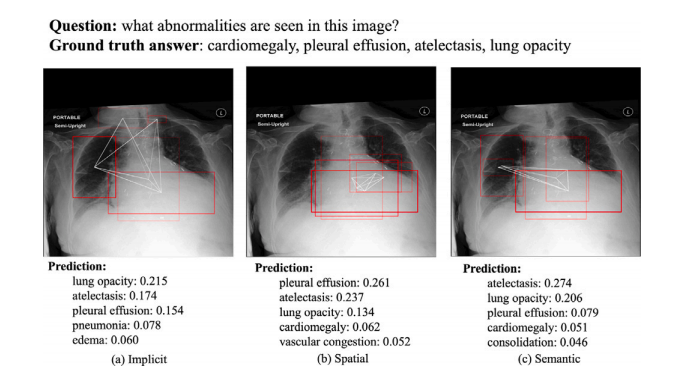
Fig. 11. An example of the ROIs visualization for abnormality. The red bounding boxesare the activated ROIs.
图11. 一个关于异常的ROI(感兴趣区域)可视化示例。红色边框表示激活的ROI。
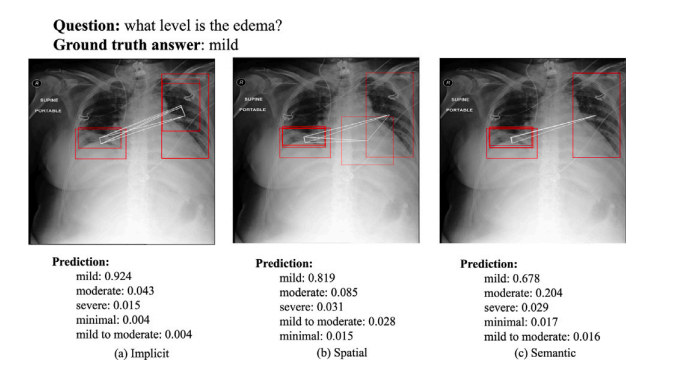
Fig. 12. An example of the ROIs visualization for level. The red bounding boxes arethe activated ROIs.
图12. 一个关于程度的ROI(感兴趣区域)可视化示例。红色边框表示激活的ROI。
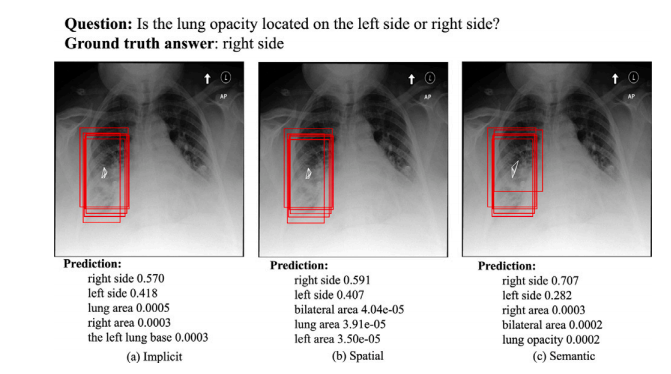
Fig. 13. An example of the visualization result for location. The red bounding boxes are the activated ROIs.
图13. 一个关于位置的可视化结果示例。红色边框表示激活的ROI(感兴趣区域)。
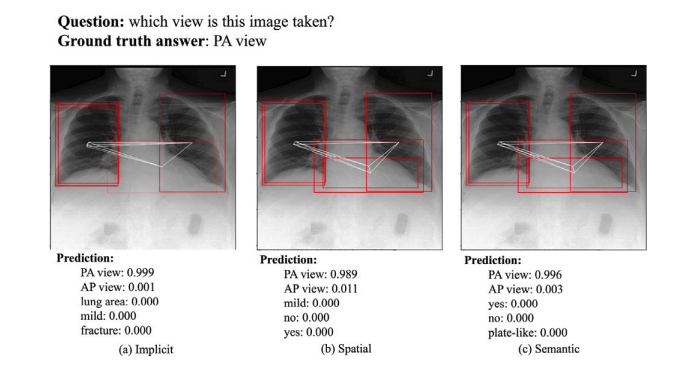
Fig. 14. An example of the ROIs visualization for view. The red bounding boxes are the activated ROIs.
图14. 一个关于视角的ROI(感兴趣区域)可视化示例。红色边框表示激活的ROI。
Table
表

Table 1Abnormality keyword variants.
表1 异常关键词变体。
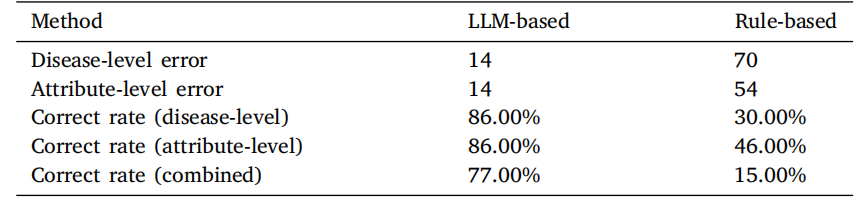
Table 2Comparison of correct rate between LLM-based method and Rule-based method for100 KeyInfo samples. The counts of errors at the disease level include cases ofmisclassification, instances of the disease being missing, and occurrences of the diseasebeing extra. Similarly, the counts of errors at the attribute level encompass situationswhere attributes are incorrectly assigned or missing.
表2 LLM方法与基于规则方法在100个关键信息(KeyInfo)样本中的正确率比较。疾病层级的错误计数包括分类错误、疾病缺失以及多余的疾病情况。类似地,属性层级的错误计数包括属性分配错误或缺失的情况
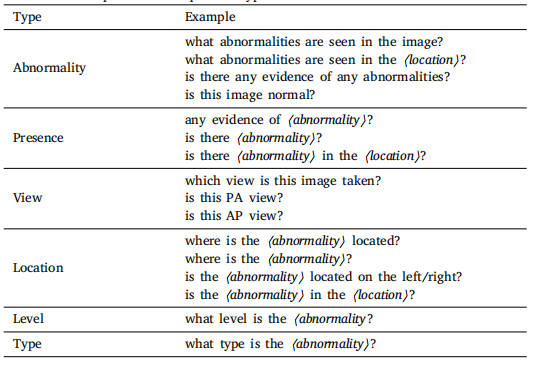
Table 3Full list of examples for each question type.
表3 各种问题类型的完整示例列表。

Table 4Dataset evaluation results by human verifiers
表4 人类验证者对数据集的评估结果。
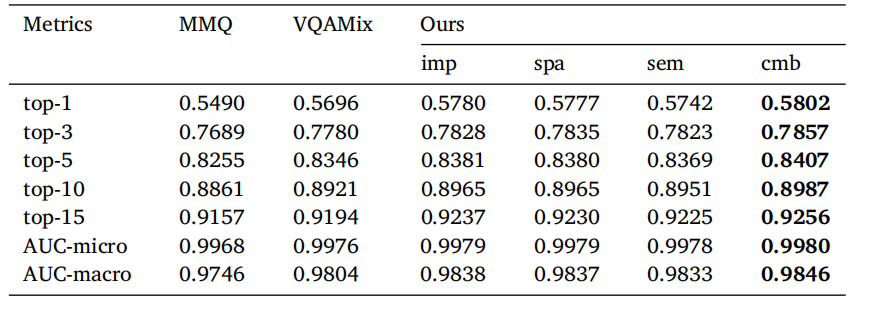
Table 5Comparison of baseline model and our method with three relation graphs and combinedscore using Top-K accuracy and AUC evaluation metrics. AUC-micro computes the finalAUC by aggregating the contributions of each class while AUC-macro treats all classesequally and computes the average AUC. ‘‘imp’’, ‘‘spa’’, ‘‘sem’’, and ‘‘cmb’’ represent‘‘implicit’’, ‘‘spatial’’, ‘‘semantic’’, and ‘‘combined’’ respectively.
表5 基线模型与我们的方法在使用三种关系图和组合得分的Top-K准确率和AUC评估指标下的比较。AUC-micro通过聚合每个类别的贡献来计算最终的AUC,而AUC-macro将所有类别视为相等并计算平均AUC。“imp”、“spa”、“sem”和“cmb”分别代表“隐含”、“空间”、“语义”和“组合”。
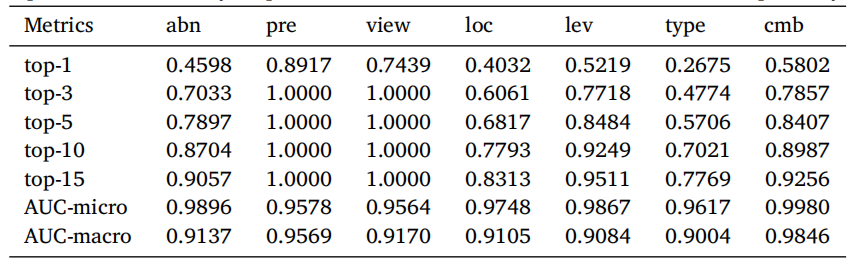
Table 6Evaluation results on different question types. ‘‘abn’’, ‘‘pre’’, ‘‘loc’’, ‘‘lev’’, and ‘‘cmb’’represent ‘‘abnormality’’, ‘‘presence’’, ‘‘location’’, ‘‘level’’, and ‘‘combined’’ respectively.
表6 不同问题类型的评估结果。“abn”、“pre”、“loc”、“lev”和“cmb”分别代表“异常”、“存在”、“位置”、“程度”和“组合”。
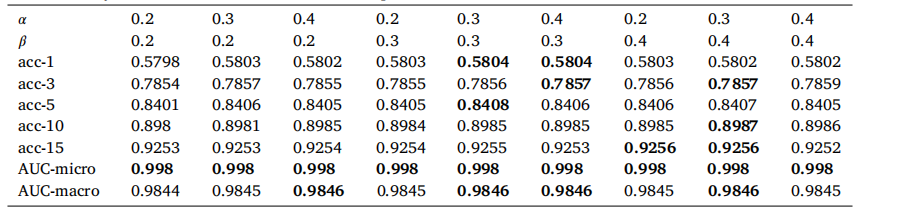
Table 7 Ablation study on how different 𝛼 and 𝛽 values impact the final results on Medical-CXR-VQA dataset.
表7 不同的 𝛼 和 𝛽 值对Medical-CXR-VQA数据集最终结果影响的消融研究。
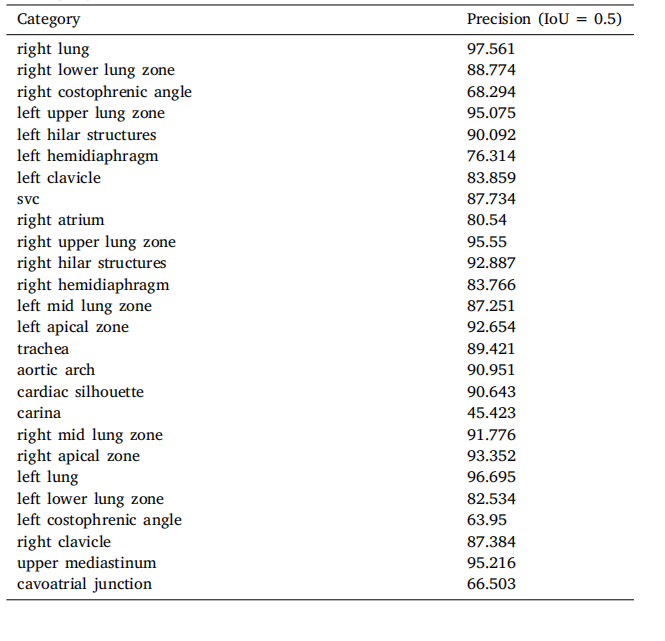
Table A.8Anatomical structure detection results. Precision represents when the Intersection overUnion (IoU) threshold is set to 0.5.
表A.8 解剖结构检测结果。精度表示在交并比(IoU)阈值设置为0.5时的结果。
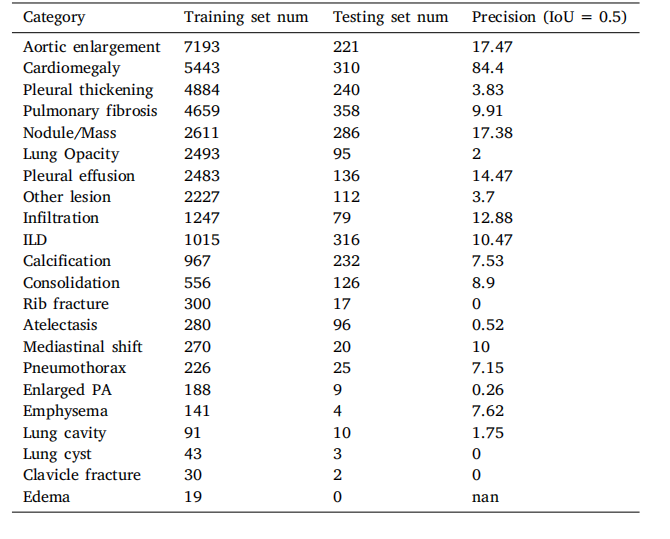
Table A.9Abnormality detection results. Precision represents when the Intersection over Union(IoU) threshold is set to 0.5.
表A.9 异常检测结果。精度表示在交并比(IoU)阈值设置为0.5时的结果。
相关文章:
通过多模态关系图学习实现可解释的医学图像视觉问答|文献速递--Transformer架构在医学影像分析中的应用
Title 题目 Interpretable medical image Visual Question Answering via multi-modal relationship graph learning 通过多模态关系图学习实现可解释的医学图像视觉问答。 01 文献速递介绍 医学视觉问答(VQA)是医学多模态大语言模型(LL…...

从入门到精通,带你探索适合新手的视频剪辑工具
用视频来分享生活已经变成越来越多人的一种习惯,很多时候视频并不能一镜到底,所以还需要一些的修改、剪辑操作,那么这次我将介绍几款视频剪辑工具,希望能够让你分享的道路更加通畅。 1.FOXIT视频剪辑 连接直达>>https://w…...
)
线性规划------ + 案例 + Python源码求解(见文中)
目录 一、代数模型(Algebraic Models)详解1.1什么是代数模型?1.2代数模型的基本形式1.3 安装所需要的Python包--运行下述案例1.4代数模型的应用案例案例 1:市场供需平衡模型Python求解代码Python求解结果如下图:案例 2:运输问题中的线性规划模型进行数学建模分析1. 目标函…...

用Java实现人工智能
用Java实现人工智能 #Java #人工智能 #AI #机器学习 #深度学习 #数据科学 #技术博客 #编程技巧 文章目录 前言环境准备1. 安装Java2. IDE选择3. 依赖管理 数据准备模型训练模型评估分类模型评估回归模型评估模型的交叉验证 模型部署部署模型的基本步骤模型保存与加载Docker容器…...

MobaXterm使用技巧
引言 在现代IT环境中,远程管理和SSH连接已经成为管理员和开发者日常工作的重要组成部分。MobaXterm是一款功能强大的终端模拟器,它集成了多种网络工具,非常适合用于远程管理、编程和网络调试。本文将汇总一些MobaXterm的使用技巧,…...

openstack中的rabbitmq
基本概念 基础介绍 exchange:用于分发信息,有direct、fanout、topic、headers; binding:exchange、queue之间的虚拟连接,由一个或者多个routing key组成; queues:用来暂存消息,供…...

etcd三节点,其中一个坏掉了的恢复办法
一、配置etcdctl环境变量 --------------------------------------------------------------------------------------------- #其中证书实际路径和endpoints,以环境情况为准,查询方式 # ps -ef | grep etcd-cafile # ps -ef | grep etcd-servers export ETCDCTL_API3 export…...

计算机毕业设计 基于SpringBoot框架的网上蛋糕销售系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

C编程控制PC蜂鸣器方法2
在《C编程控制PC蜂鸣器》一文中,我们了解并使用了通过IO端口控制的方式操作硬件,而有些时候这对于一些朋友来说太模糊了,很容易让人迷糊,这次采用最基本的write系统调用来写入input_event数据实现相同功能。这里涉及到的input_event可参考《C编程实现键盘LED闪烁方法2》一文…...

C# SQL 辅助工具
{/// <summary>/// sql 辅助工具/// </summary>public class SqlStructureHelps{#region 增删改查/// <summary>/// 截断/// </summary>/// <typeparam name"T"></typeparam>/// <returns></returns>public static …...

eNSP简单用法
建立一个简单的拓扑图 点击绿色三角开启设备 双击设备可以进行命令编辑 视图 分为三个视图:用户视图、系统视图、接口视图 用户视图 在默认模式下就是,为<huawei> 按ctrlz返回用户视图 系统视图: 在用户视图下输入sys切换&#…...

1035. 不相交的线
1. 题目 1035. 不相交的线 2. 解题思路 题目一看是求最值,那就可以考虑用DP来做。 核心点就是确定DP数组的含义以及状态转移方程: dp数组含义:dp[i][j],nums1 前 i 个数和 nums2 前 j 个数的最大连线数dp[i][j] dp[i - 1][j …...

1.pytest基础知识(默认的测试用例的规则以及基础应用)
一、pytest单元测试框架 1)什么是单元测试框架 单元测试是指再软件开发当中,针对软件的最小单位(函数,方法)进行正确性的检查测试。 2)单元测试框架 java:junit和testing python:un…...

Linux常见查看文件命令
目录 一、cat 1.1. 查看文件内容 1.2. 创建文件 1.3. 追加内容到文件 1.4. 连接文件 1.5. 显示多个文件的内容 1.6. 使用管道 1.7. 查看文件的最后几行 1.8. 使用 -n 选项显示行号 1.9. 使用 -b 选项仅显示非空行的行号 二、tac 三、less 四、more 五、head 六、…...

初识 performance_schema:轻松掌握MySQL性能监控
什么是 performance_schema performance_schema 是 MySQL 5.8 版本的一个强大功能,它就像是一个内置的**“性能侦探”**,专门用来监控和分析 MySQL 服务器的资源消耗和等待情况。有了它,数据库管理员和开发者就能实时了解服务器的运行状态&a…...

linux下top命令查看和解释
怎么看top结果: top - 10:20:48 up 8 days, 14:07, 2 users, load average: 6.04, 5.82, 4.73 Tasks: 11099 total, 1 running, 10916 sleeping, 0 stopped, 1 zombie %Cpu(s): 8.9 us, 4.6 sy, 0.0 ni, 86.1 id, 0.1 wa, 0.0 hi, 0.3 si, 0.0 st K…...

换个手机IP地址是不是不一样?
在当今这个信息爆炸的时代,手机已经成为我们生活中不可或缺的一部分。而IP地址,作为手机连接网络的桥梁,也时常引起我们的关注。你是否曾经好奇,换个手机,IP地址会不会也跟着变呢?本文将深入探讨这个问题&a…...

【从计算机的发展角度理解编程语言】C、CPP、Java、Python,是偶然还是应时代的产物?
参考目录 前言什么是"computer"?计算机的大致发展历程计算机系统结构阶段(1946~1981)计算机网络和视窗阶段(1982~2007)复杂信息系统阶段(2008~today)人工智能阶段 越新的语言是越好的吗、越值得学习吗? 前言 最近读了 《Python语言程序设计基础》 这本书…...

《Google软件测试之道》笔记
介绍 GTAC:Google Test Automation Conference,Google测试自动化大会。 本书出版之前还有一本《微软测试之道》,值得阅读。 质量不是被测试出来的,但未经测试也不可能开发出有质量的软件。质量是开发过程的问题,而不…...

实战讲稿:Spring Boot整合MyBatis
文章目录 实战讲稿:Spring Boot整合MyBatis课程目标课程内容1. 创建员工映射器接口1.1 创建子包1.2 创建接口 2. 测试员工映射器接口2.1 自动装配员工映射器2.2 测试按标识符查询员工方法2.3 测试查询全部员工方法2.4 测试插入员工方法2.5 测试更新员工方法2.6 测试…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...