MySQL面试题——第二篇
1. MySQL的优化手段有哪些?
MySQL的常见的优化手段有以下五种
1. 查询优化
- 避免select * ,只查询需要的字段。
- 小表驱动大表,即小的数据集驱动大的数据集,比如当B表的数据集小于A表时,用in优化exist。两表执行顺序是先查B表,在查询A表,查询语句: select * from A where id in(select id from B)。
- 一些情况下,可以使用连接代替子查询,因为使用join时,MySQL不会在内存中创建临时表。
2. 优化索引的使用
- 尽量使用主键查询,而非其他索引,因为主键查询不会触发回表查询。
- 不做列运算,把计算放入业务系统实现。
- 查询语句尽可能简单,大语句拆小语句,减少锁时间。
- 不使用select * 查询。
- or查询改写成in查询
- 不用函数和触发器
- 避免使用‘%xx’查询
- 少用join查询
- 使用同类型比较,比如‘123’和‘123’、123和123
- 尽量避免在where子句中使用!=或者<>查询引用会放弃索引而进行全表扫描。
- 列表数据使用分页查询,每页数据量不要太大。
- 用exists代替in查询。
- 避免在索引列上使用is null 和is not null。
- 尽量使用主键查询
- 避免在where子句中对字段进行表达式操作。
- 尽量使用数字型字段,若只包含数值信息的字段尽量不要设计为字符型。
3. 表结构设计优化
- 使用可以存下数据最小的数据类型。
- 使用简单的数据类型,int要比varchar类型处理简单。
- 尽量使用tinyint、smallint、mediumint作为整数类型而非int。
- 尽可能使用not null定义字段,因为null占用4字节空间。
- 尽量少用text类型,非用不可时考虑分表。
- 尽量使用timestamp而非datetime。
- 单表不要有太多字段,建议在20个字段以内。
4. 表拆分
当数据库中的数据非常大时,查询优化方案也不能解决查询速度慢的问题时,可以考虑拆分表,让每张表的数据量变小,从而提高查询效率。
- 垂直拆分:把一张列比较多的表拆分为多张表,比如,用户表中一些字段经常被访问,将这些字段放在一张表中,另外一些不常用的字段放在另一张表中。插入数据时,使用事务确保两张表的数据一致性。
- 水平拆分:表的行数超过200w时,就会变慢,这时可以把一张表的数据拆分成多张表来存放。通常情况下,使用取模的方式进行表的拆分。
读写分离
一般来说,数据库都是读多写少,换言之,数据库的压力多数是因为大量的读取数据操作造成的,我们可以使用数据库集群的方案,使用一个库作为主库,负责写入数据;其他库作为从苦,负责读取数据。
2. 主键使用自增id还是UUID
如果是单机的话,选择自增id;如果是分布式系统,优先考虑UUID,但还是最好有一套分布式唯一ID生产方案。
自增ID:数据存储空间小,查询效率高。但是,不适合分布式场景。
UUID:适合大量数据的插入和更新操作,但是,他是无序的,插入数据效率慢,占用空间大。
3. 如何优化长难的查询语句
- 将一个大的查询分为多个小的相同的查询
- 减少冗余记录的查询
- 一个复杂查询可以考虑拆分成多个简单查询。
- 分解关联查询,让缓存的效率更高。
4. 一条SQL执行过长的时间,从哪些方面入手优化
- 查看是否涉及多表和子查询,优化SQL结构,去除冗余字段,是否可拆表等。
- 优化索引结构,看是否可以适当添加索引
- 数量大的表,可以考虑进行 分表
- 数据库主从分离,读写分离
- explain分析sql语句,查看执行计划,优化SQL
- 查看MySQL执行日志,分析是否有其他方面问题。
5. 如果某个表有近千万行数据,CRUD比较慢,如何优化
- 分表分库
某个表有近千万数据,可以考虑优化表结构,分表(水平分表、垂直分表)。- 索引优化
6. 如何删除百万级别或以上的数据
- 删除百万数据的时候可以先删除索引
- 批量删除其中无用数据
- 删除完成后重新添加索引。
7. MySQL有哪些重要的日志文件
1. 错误日志:用来记录MySQL服务器运行过程中的错误信息
2. 查询日志:查询日志在MySQL中被称为通用日志,查询日志中记录了数据库执行的所有命令。如果不是在调试环境中,不建议开启查询日志功能,否则日志会非常大,影响MySQL性能。
3. 慢日志:慢查询会导致CPU、内存消耗过高,当数据库遇到瓶颈时,大部分时间都是由于慢查询导致的。开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句。
4. redo log(重做日志):为了最大程度的避免数据写入时,因为IO瓶颈造成的性能问题,MySQL采用了一种缓存机制,先将数据写入内存中,再批量把内存中的数据统一刷回磁盘。为了避免将数据刷回磁盘过程中,因为掉电或者系统故障带来的数据丢失,InnoDB采用redo log来解决此问题。
5. undo log(回滚日志):用于存储日志被修改前的值,从而保证如果修改出现异常,可以使用undo log日志来实现回滚。undo log和redo log记录物理日志不一样,他是逻辑日志,可以认为,当delete一条记录时,undo log中会记录一条相反的insert 记录,update一条记录时,记录一条对应的相反的update记录。当执行rollback时,就可以从undolog中的逻辑记录读取到相应的内容并进行回滚。undo log默认存放在共享表空间中,在MySQL5.6后,undo log存放位置还可以设置在自定义目录。
6. binlog(二进制日志):二进制文件,主要记录所有数据库表结构变更,比如create、alter等,以及表数据修改,比如,insert、update、delete等,binlog中记录了对mysql数据库执行更改的所有操作,并且记录了语句发生时间,执行时长,操作数据等信息。
8. MySQL的binlog有几种格式,分别有什么区别
有三种格式:statement、row和mixed
statement:每一条会修改数据的SQL都会记录在binlog中,不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能,由于SQL执行是有上下文的,因此在保存的时候需要保存相关信息,同时,使用了函数之类的语句无法被记录复制。
row:不记录SQL语句上下文相关信息,仅保存哪条记录被修改,记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动,因此,这种模式的文件保存的信息太多,日志量太大。
mixed:一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
9. redo log 和binlog有什么区别
redo log 和 binlog 都是MySQL的重要日志,区别如下:
- redo log是物理日志,记录的是【在某个数据页上做了修改】
- bin log是逻辑日志,记录的是这个语句的原始逻辑,比如【给ID=2这一行c字段加1】
- redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
redo log是循环写的,空间固定会用完,binlog是追加写入的,追加写是指binlog文件写到一定大小会切换到下一个,并不会覆盖以前的日志。
最开始MySQL里没有InnoDB引擎,MySQL自带的引擎是MyISAM,但是MyISAM没有crash-safe能力,binlog只能用于归档,而InnoDB是另一个公司以插件形式引入MySQL的,既然只依靠binlog是没有crash-safe能力的,所以InnoDB使用另外一套日志系统,也就是redo log实现crash-safe。
10. 什么是脏页和干净页
MySQL为了操作的性能优化,把数据更新先放入内存中,之后在统一更新到磁盘,当内存数据和磁盘数据不一致的时候,称这个内存页为脏页;内存数据写到磁盘后,内存的数据和磁盘上的内容就一致了,我们称为【干净页】。
11. 什么情况下会引发MySQL刷脏页的操作
- 内存写满了,这个时候就会引发flush操作,对应到InnoDB就是redo log写满了。
- 系统内存不足了,当需要新的内存页的时候,就会淘汰一些内存页,如果淘汰的是脏页这个时候就会触发flush操作。
- 系统空闲的时候,MySQL会同步内存中的数据到磁盘也会触发flush操作。
- MySQL服务关闭的时候也会刷脏页,触发flush操作。
12. MySQL刷脏页很慢可能是什么原因
在MySQL中单独刷一个脏页速度是很快的,如果发现刷脏页速度很慢,说明触发了MySQL刷脏页的【连坐】机制,MySQL【连坐】机制指当MySQL刷脏页的时候如果发现相邻的数据页也是脏页也会一起刷掉,而这个动作会一直蔓延下去。
13.事务执行期间还未提交,如果发生crash,redolog 丢失,是否会导致主备不一致
不会,因为这时候binlog也还在binlog cache里,没发给备库,crash以后redo log和binlog都没有了,从业务角度看这个事务没有提交,所以数据是一致的。
14. 在MySQL中用什么机制来优化随机读/写磁盘对IO的消耗
redo log是用来节省随机写磁盘的IO消耗,而change buffer主要是节省随机读磁盘的IO消耗,redo log会把MySQL的更新操作先记录到内存中,之后统一更新到磁盘,而change buffer是把关键查询数据先加载到内存中,以便优化MySQL 查询。
15. 如何将MySQL的数据恢复到过去某个指定的时间点
例如,今早九点,想把数据恢复成早上六点的状态,这个时候可以先把0点备份的数据库文件,还原到测试库,再从binlog文件中依次取出0:00到6:00的操作信息,重放binlog,就可以完成数据库的还原。
16. 读写分离会带来什么问题?如何解决?
读写分离带来的问题,主要包括
数据一致性问题、延迟问题、负载均衡问题、故障恢复问题。
1. 数据一致性问题
- 问题:由于读写分离会导致数据再不同的数据库副本之间不同步,从而导致读到陈旧数据问题。
- 解决方法:
使用主从复制:通过配置异步复制、半同步复制或者全同步复制保证数据及时同步到从库。
读写分配策略:关键操作从主库读取,非关键数据从从库读取。
2. 延迟问题
- 问题:主从复制通常存在一定的延迟,特别是在数据写入频繁的场景下,从库的延迟可能会导致读到过期的数据。
- 解决方法:
同步复制:虽然会影响性能,但可以确保数据的一致性。
提高硬件性能:通过提升服务器硬件性能、优化网络带宽和配置高效的存储设备来减少复制延迟。
优化复制机制:使用增量复制或者并行复制技术加快复制速度。
3. 负载均衡问题- 问题:读写分离后,如何有效的分配读请求到多个从库,确保负载均衡也是一个挑战
- 解决方法:
负载均衡器:使用专门的负载均衡器来分配请求。
数据库代理
自定义策略
4. 故障恢复问题- 当主库或从库出现故障时,如何迅速恢复。
- 解决方法
主从切换:主库故障时,迅速将从库提升为主库。
自动化运维:使用自动化运维工具来监控和管理主从切换。
数据备份和恢复:定期进行数据备份,确保数据在故障发生时能够迅速恢复。
17. 主从复制原理是什么
MySQL binlog主要记录了MySQL数据库中数据的所有变化(数据库执行的所有DDL和DML语句),因此,根据主库的MySQL binlog日志就能够将主库的数据同步到从库。
具体流程如下:
- 主库将数据库中数据的变化写入到binlog。
- 从库连接主库。
- 从库会创建一个IO线程向主库请求更新的binlog。
- 主库会创建一个binlog dump线程发送binlog,从库中的IO线程负责接收。
- 从库的IO线程将接收的binlog写入到relay log中。
- 从库的SQL线程读取relay log同步数据到本地。
18. 分库分表会带来什么问题
join操作:同一个数据库中的表分布在了不同的数据库中,导致无法使用join操作,这样就导致需要手动进行数据的封装,比如在一个数据库中查询到数据之后,在根据这个数据去另一个数据库中找对应的数据。
事务问题:单个操作涉及到多个数据库,那么数据库自带的事务就无法满足需求。
分布式ID:需要为不同的数据节点生成全局唯一主键。
相关文章:

MySQL面试题——第二篇
1. MySQL的优化手段有哪些? MySQL的常见的优化手段有以下五种 1. 查询优化 避免select * ,只查询需要的字段。小表驱动大表,即小的数据集驱动大的数据集,比如当B表的数据集小于A表时,用in优化exist。两表执行顺序是先查B表&#x…...
Unity Transform 组件
在 Unity 中,Transform 是一个非常重要的组件,它定义了物体的位置、旋转和缩放,几乎每个 GameObject 都包含一个 Transform 组件。Transform 组件的主要属性如下: 1. position 表示物体在世界空间中的位置。可以通过 transf…...

LeeCode 3. 无重复字符的最长子串
经典方法滑动窗口:(两个指针) 针对这个题我们首先假定两个指针 left 和 right 分别指在数组最左端. 然后两个变量记录长度length和maxlength. 并且因为不能有重复的字符,我们使用HashSet结构来当收集结果的表. 随着右指针不断往右移,左指针和右指针之间的就为截取的字符,而这…...

使用canal.deployer-1.1.7和canal.adapter-1.1.7实现mysql数据同步
1、下载地址 --查看是否开启bin_log日志,value on表示开启 SHOW VARIABLES LIKE log_bin; -- 查看bin_log日志文件 SHOW BINARY LOGS; --查看bin_log写入状态 SHOW MASTER STATUS; --查看bin_log存储格式 row SHOW VARIABLES LIKE binlog_format; --查看数据库服…...

VMware Workstation Pro 17下载及安装教程
下载 好消息!从VMware Workstation Pro 17开始,个人可以免费使用了,再也不需要找破解激活码啥的了。 但是坏处却不小:其下载变得异常复杂。首先需要注册账号,外网非常慢很可能注册不上;其次根本找不到下载…...
集采良药:从“天价神药”到低价良药,伊马替尼的真实世界研究!
在医疗科技日新月异的今天,有一种药物以其卓越的疗效和深远的影响力,成为了众多患者心中的“精准武器”——伊马替尼。这款药物不仅在慢性髓细胞白血病(CML)的治疗上屡创佳绩,更是胃肠道间质瘤(GIST&#x…...

00898 互联网软件应用与开发自考复习题
资料来自互联网软件应用与开发大纲 南京航空航天大学 高纲4295和JSP 应用与开发技术(第 3 版) 马建红、李学相 清华大学出版社2019年 第一章 一、选择题 通过Internet发送请求消息和响应消息使用()网络协议。 FTP B. TCP/IP C. HTTP D. DNS Web应…...
)
linux 进程间通信之pthread(条件变量共享和互斥锁共享)
0,互斥锁共享 初始化和销毁mutex互斥锁 int pthread_mutexattr_init(pthread_mutexattr_t *attr); int pthread_mutexattr_destroy(pthread_mutexattr_t *attr); 进程共享属性有两种值: 1、PTHREAD_PROCESS_PRIVATE,这个是默认值(1),同一个进程中的多个线程访问同一个…...

数据结构-2.7.单链表的查找与长度计算
注:本文只探讨"带头结点"的情况(查找思路类似循环找到第i-1 个结点的代码) 一.按位查找: 1.代码演示: 版本一: #include<stdio.h> #include<stdlib.h> //定义单链表结点类型 typedef struct LNo…...
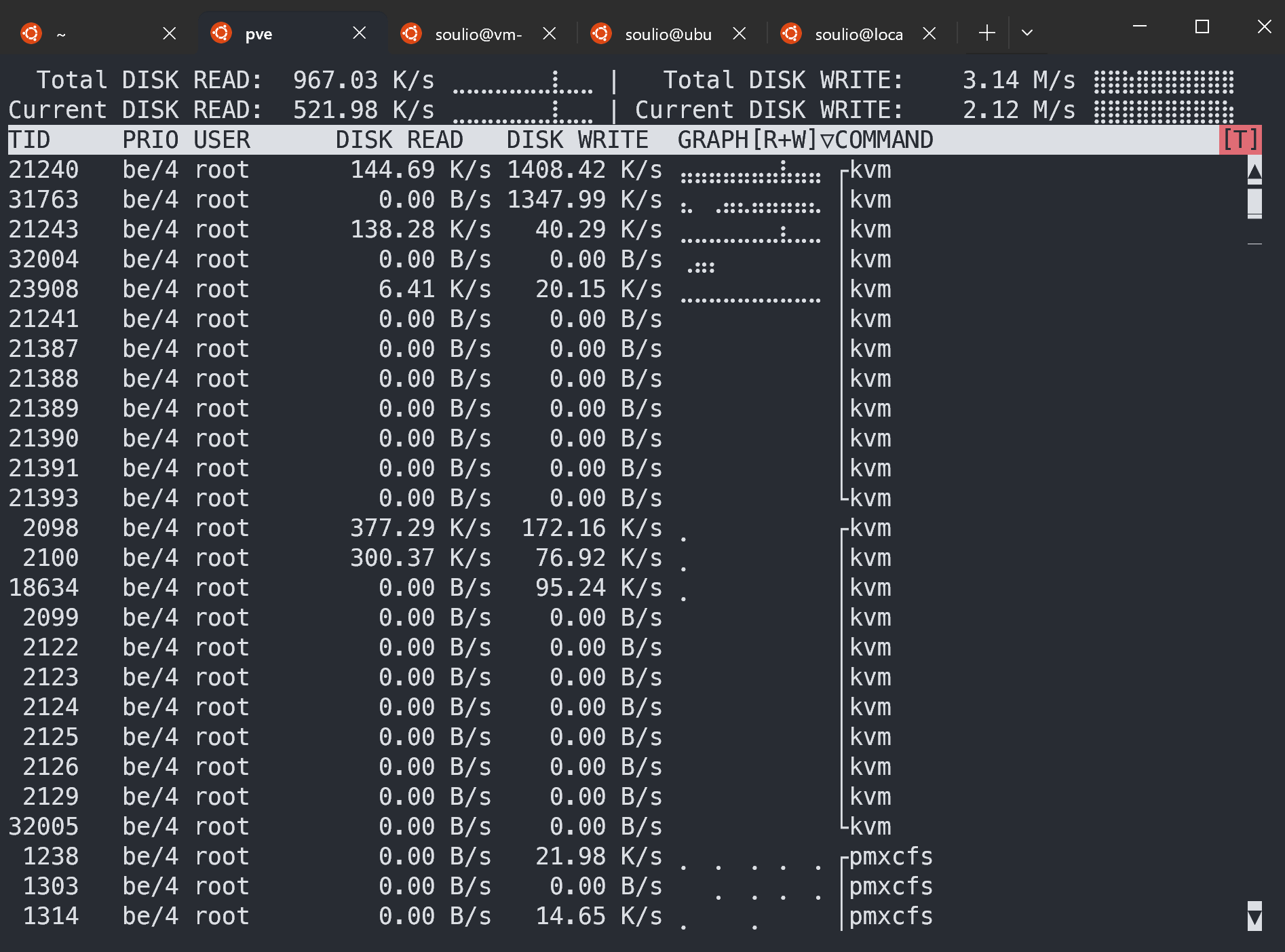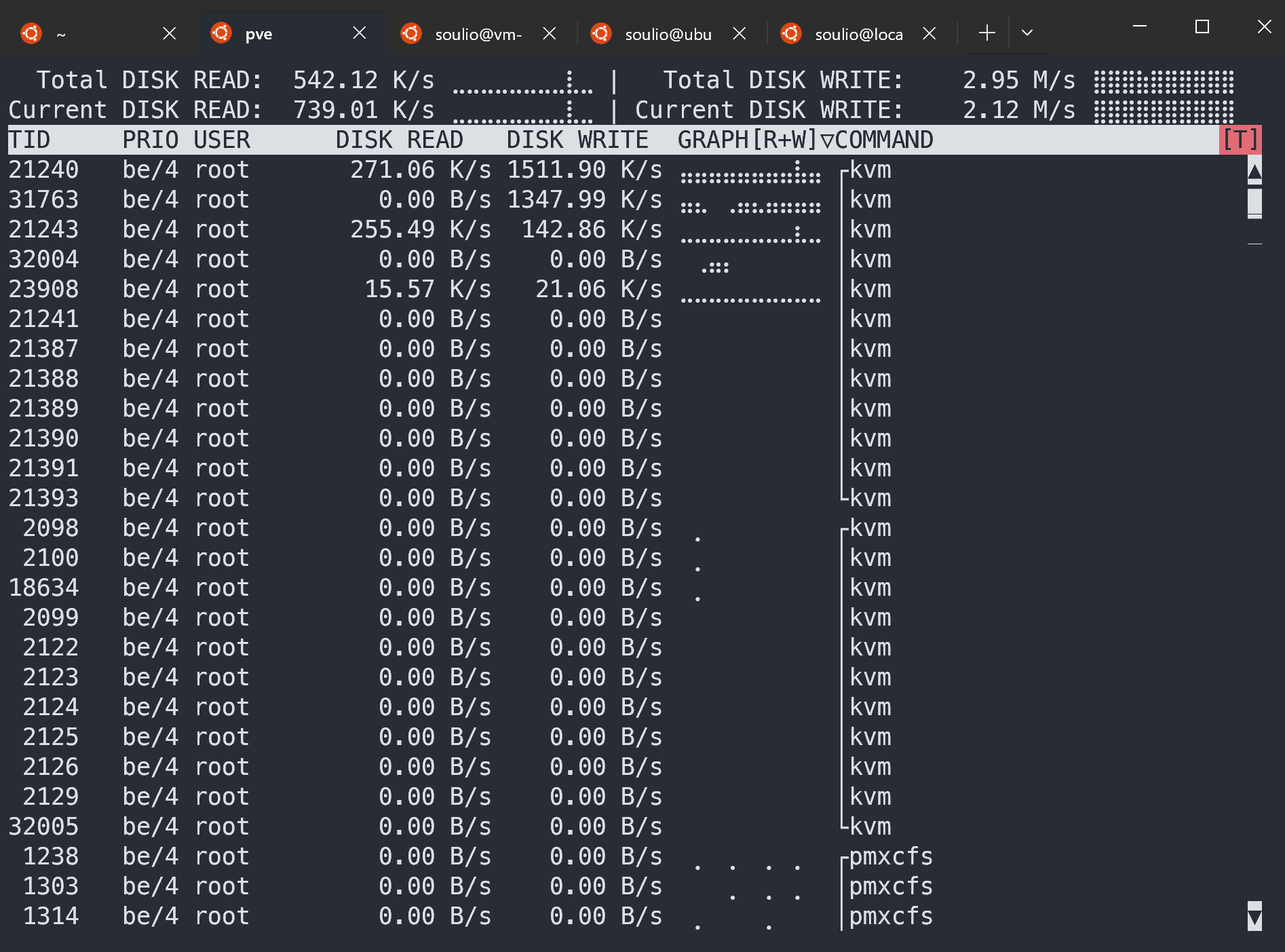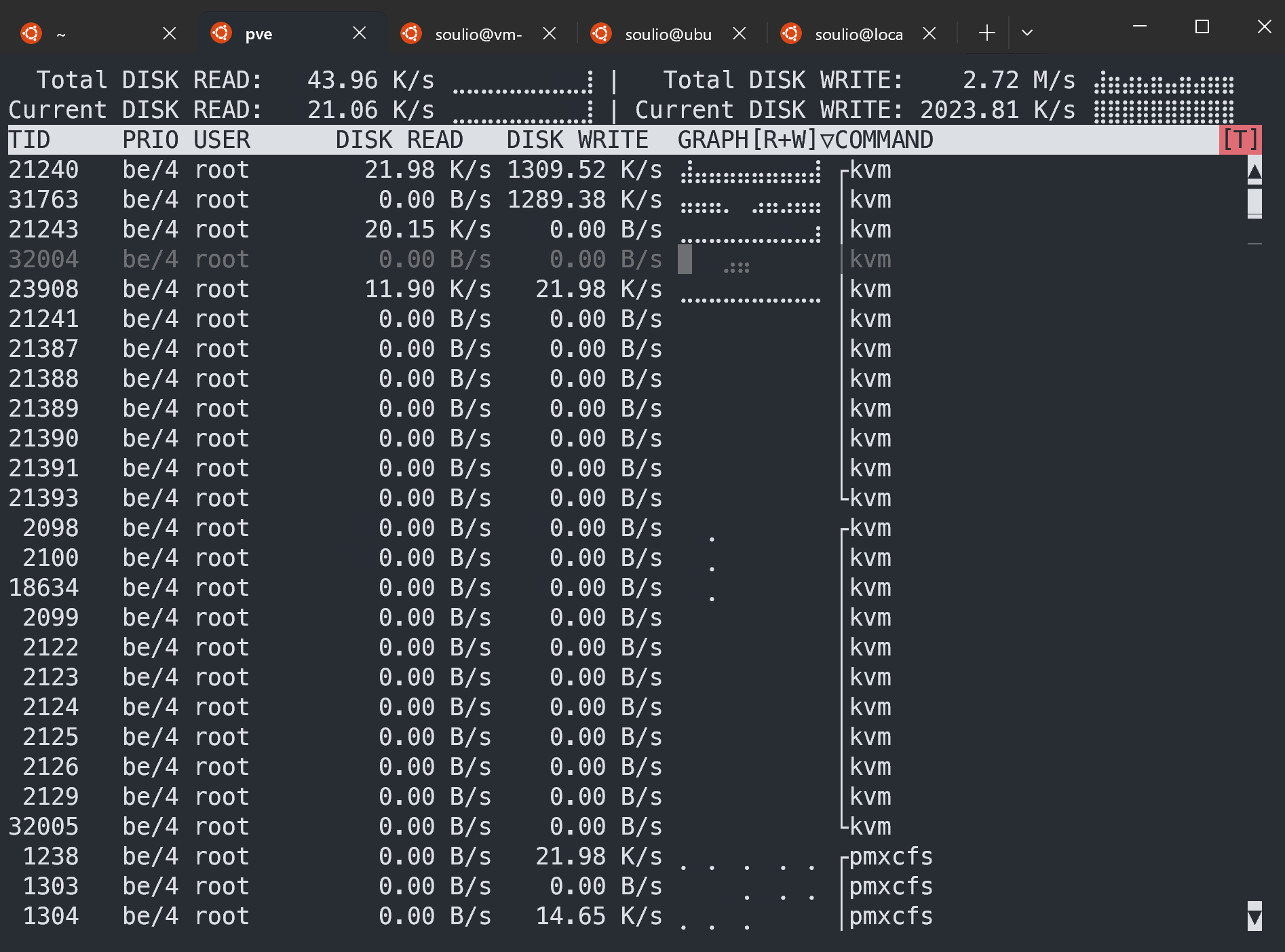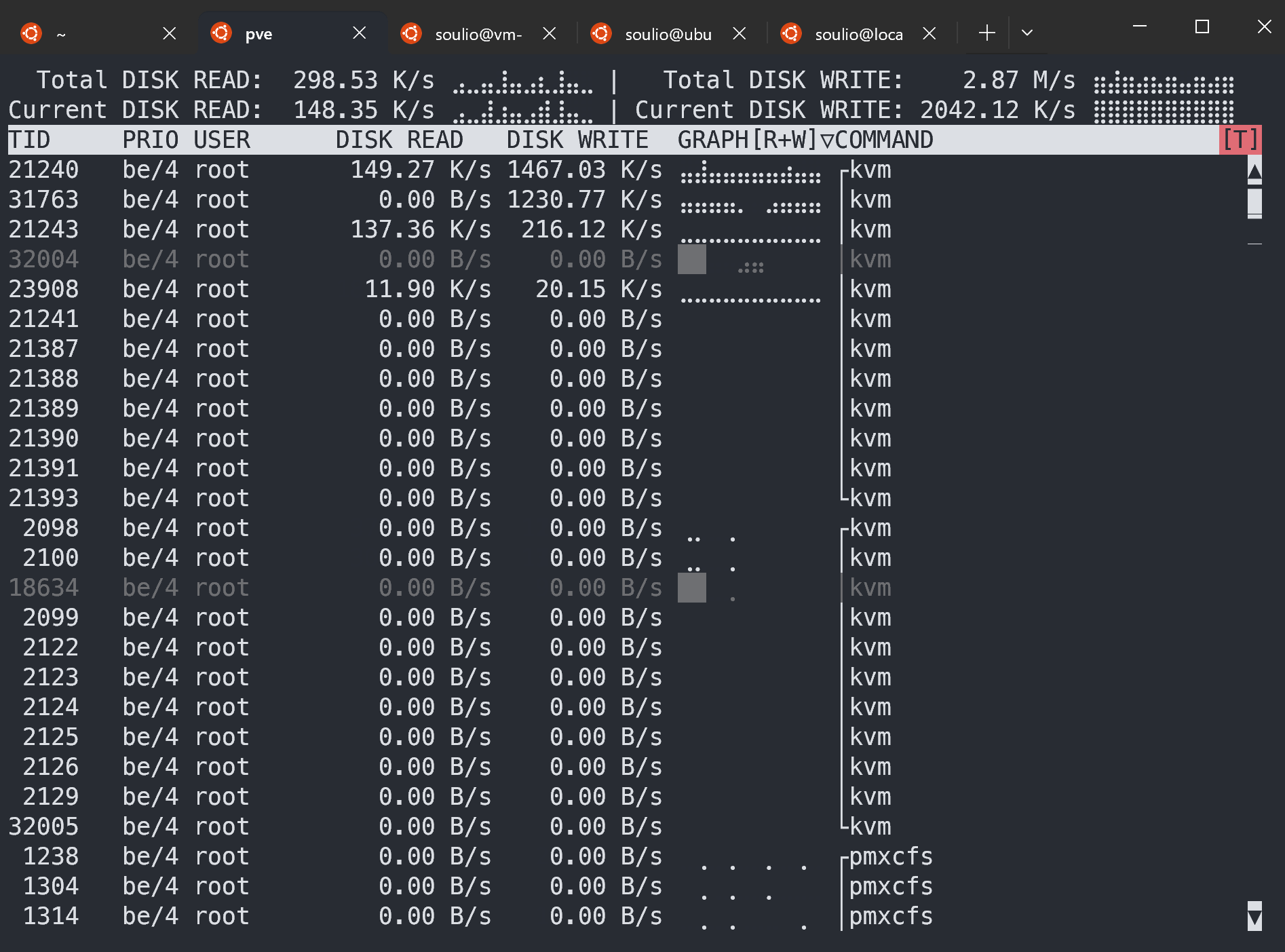
iotop 命令:磁盘IO监控和诊断
一、命令简介 iotop命令用于监视磁盘I/O,实时显示每个进程或线程的读写速率等信息。非常适合用于诊断系统中的I/O瓶颈。 安装 iotop 在大多数Linux发行版中,iotop可能不是预装的。可以使用包管理器来安装它。 例如,在…...

解锁编程新境界:GitHub Copilot 让效率翻倍
Number.1:工具介绍 功能特点: 智能代码生成与补全:通过学习大量代码库和开发者的编码风格,能根据上下文自动推断可能的代码补全选项,甚至可以自动完成函数定义、循环结构等复杂代码片段。例如,当编写一个算…...
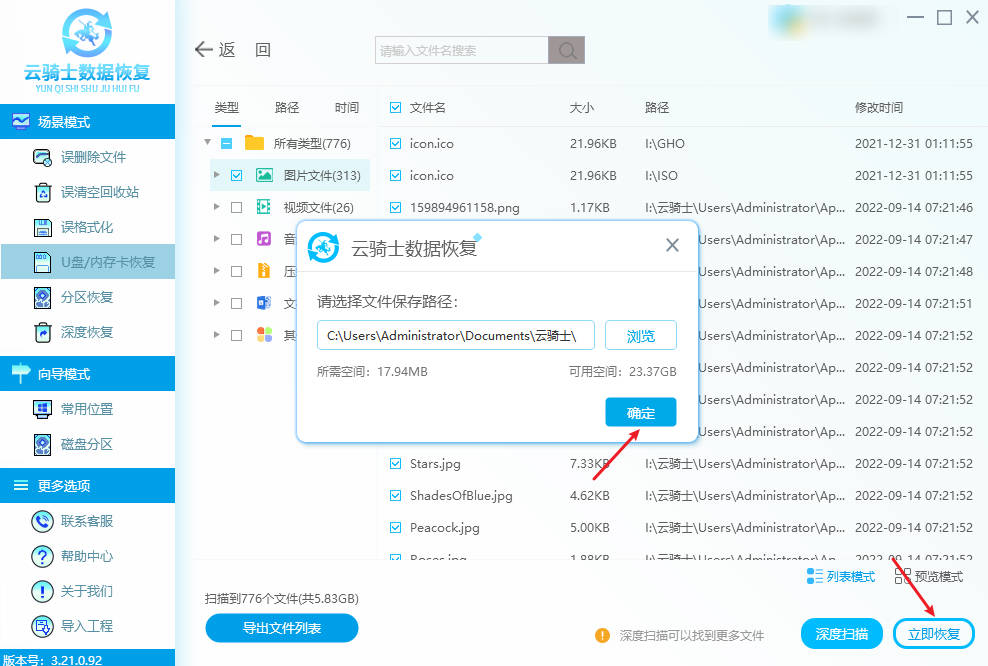
爱普生相机SD卡格式化后数据恢复指南
我借了朋友的爱普生相机,想查看一下内存,哎呀,一不小心按错了,竟然执行了格式化操作,这可真是太让人郁闷了,这还有机会挽救数据吗?心塞,求帮助! 随着数码摄影的普及&am…...

【数据结构】排序算法---基数排序
文章目录 1. 定义2. 算法步骤2.1 MSD基数排序2.2 LSD基数排序 3. LSD 基数排序动图演示4. 性质5. 算法分析6. 代码实现C语言PythonJavaCGo 结语 ⚠本节要介绍的不是计数排序 1. 定义 基数排序(英语:Radix sort)是一种非比较型的排序算法&…...

二叉树(下)
目录 判断树是否相同 判断树是不是另一棵树的子树 二叉树翻转 判断平衡二叉树 二叉树层序遍历 这篇主要提供一些关于二叉树例题的讲解,如果对二叉树及其基本操作有疑问的可以转至: 二叉树(上)-CSDN博客二叉树(中&…...

计算机网络33——文件系统
1、chmod 2、chown 需要有root权限 3、link 链接 4、unlink 创建临时文件,用于非正常退出 5、vi vi可以打开文件夹 ../是向外一个文件夹 6、ls ls 可以加很多路径,路径可以是文件夹,也可以是文件 ---------------------------------…...

算法:76.最小覆盖子串
题目 链接:leetcode链接 思路分析(滑动窗口) 还是老样子,连续问题,滑动窗口哈希表 令t用的hash表为hash1,s用的hash表为hash2 利用hash表统计窗口内的个字符出现的个数,与hash1进行比较 选…...

DNS服务
一.DNS介绍 DNS应用层协议 Domain Name System 域名系统 作用:实现域名解析,解析主机名所对应的IP地址, 在网络环境中设备与设备之间要想相互通信只能依赖IP地址,DNS服务器的作用是实现域名解析。 如上图所示,DNS存…...
任务通知)
STM32 HAL freertos零基础(九)任务通知
1、任务通知 任务通知用于任务之间同步和通信。任务通知允许一个任务向另一个任务发送一个32位的值,并可以选择是否唤醒正在等待通知的任务。这使得任务之间的同步更加简单和灵活。 任务通知功能: 发送通知:一个任务可以向另一个任务发送一个32位的值。 接收通知:接收任…...

Qt+FFmpeg开发视频播放器笔记(三):音视频流解析封装
音频解析 音频解码是指将压缩的音频数据转换为可以再生的PCM(脉冲编码调制)数据的过程。 FFmpeg音频解码的基本步骤如下: 初始化FFmpeg解码器(4.0版本后可省略): 调用av_register_all()初始化编解码器。 调用avcodec_register_all()注册所有编解码器。 打开输入的音频流:…...

从黎巴嫩电子通信设备爆炸看如何防范网络电子袭击
引言: 在当今数字化时代,电子通信设备已成为我们日常生活中不可或缺的一部分。然而,近期黎巴嫩发生的电子设备爆炸事件提醒我们,这些设备也可能成为危险的武器。本文将深入探讨电子袭击的原理、防范措施,以及网络智能…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

Redis 客户端连接详解
Redis 客户端连接详解 引言 Redis 是一款高性能的内存数据结构存储系统,常用于缓存、会话管理、实时排行榜等功能。客户端连接是 Redis 生态系统中的重要组成部分,本文将详细介绍 Redis 客户端连接的相关知识,包括连接方式、连接配置、连接管理等方面。 Redis 客户端连接…...

BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能
BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否觉得网易云音乐PC版功能有限,界面单调?…...