Spark部署文档
Spark Local环境部署
下载地址
https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
条件
- PYTHON 推荐3.8
- JDK 1.8
Anaconda On Linux 安装
本次课程的Python环境需要安装到Linux(虚拟机)和Windows(本机)上
参见最下方, 附: Anaconda On Linux 安装
解压
解压下载的Spark安装包
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/
环境变量
配置Spark由如下5个环境变量需要设置
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中

PYSPARK_PYTHON和 JAVA_HOME 需要同样配置在: /root/.bashrc中

上传Spark安装包
资料中提供了: spark-3.2.0-bin-hadoop3.2.tgz
上传这个文件到Linux服务器中
将其解压, 课程中将其解压(安装)到: /export/server内.
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/
由于spark目录名称很长, 给其一个软链接:
ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/spark


测试
bin/pyspark
bin/pyspark 程序, 可以提供一个 交互式的 Python解释器环境, 在这里面可以写普通python代码, 以及spark代码

如图:

在这个环境内, 可以运行spark代码
图中的: parallelize 和 map 都是spark提供的API
sc.parallelize([1,2,3,4,5]).map(lambda x: x + 1).collect()
WEB UI (4040)
Spark程序在运行的时候, 会绑定到机器的4040端口上.
如果4040端口被占用, 会顺延到4041 … 4042…

4040端口是一个WEBUI端口, 可以在浏览器内打开:
输入:服务器ip:4040 即可打开:

打开监控页面后, 可以发现 在程序内仅有一个Driver
因为我们是Local模式, Driver即管理 又 干活.
同时, 输入jps
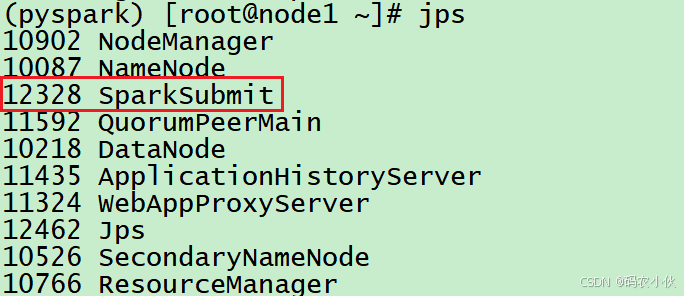
可以看到local模式下的唯一进程存在
这个进程 即是master也是worker
bin/spark-shell - 了解
同样是一个解释器环境, 和bin/pyspark不同的是, 这个解释器环境 运行的不是python代码, 而是scala程序代码
scala> sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6)
这个仅作为了解即可, 因为这个是用于scala语言的解释器环境
bin/spark-submit (PI)
作用: 提交指定的Spark代码到Spark环境中运行
使用方法:
# 语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]# 示例
bin/spark-submit /export/server/spark/examples/src/main/python/pi.py 10
# 此案例 运行Spark官方所提供的示例代码 来计算圆周率值. 后面的10 是主函数接受的参数, 数字越高, 计算圆周率越准确.
对比
| 功能 | bin/spark-submit | bin/pyspark | bin/spark-shell |
|---|---|---|---|
| 功能 | 提交java\scala\python代码到spark中运行 | 提供一个python | |
| 解释器环境用来以python代码执行spark程序 | 提供一个scala | ||
| 解释器环境用来以scala代码执行spark程序 | |||
| 特点 | 提交代码用 | 解释器环境 写一行执行一行 | 解释器环境 写一行执行一行 |
| 使用场景 | 正式场合, 正式提交spark程序运行 | 测试\学习\写一行执行一行\用来验证代码等 | 测试\学习\写一行执行一行\用来验证代码等 |
Local模式将是我们7天Spark课程的主力使用模式
Spark StandAlone环境部署
新角色 历史服务器
历史服务器不是Spark环境的必要组件, 是可选的.
回忆: 在YARN中 有一个历史服务器, 功能: 将YARN运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息.
Spark的历史服务器, 功能: 将Spark运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息.
搭建集群环境, 我们一般推荐将历史服务器也配置上, 方面以后查看历史记录
集群规划
课程中 使用三台Linux虚拟机来组成集群环境, 非别是:
node1\ node2\ node3
node1运行: Spark的Master进程 和 1个Worker进程
node2运行: spark的1个worker进程
node3运行: spark的1个worker进程
整个集群提供: 1个master进程 和 3个worker进程
安装
在所有机器安装Python(Anaconda)
参考 附1内容, 如何在Linux上安装anaconda
同时不要忘记 都创建pyspark虚拟环境 以及安装虚拟环境所需要的包pyspark jieba pyhive
在所有机器配置环境变量
参考 Local模式下 环境变量的配置内容
确保3台都配置
配置配置文件
进入到spark的配置文件目录中, cd $SPARK_HOME/conf
配置workers文件
# 改名, 去掉后面的.template后缀
mv workers.template workers# 编辑worker文件
vim workers
# 将里面的localhost删除, 追加
node1
node2
node3
到workers文件内# 功能: 这个文件就是指示了 当前SparkStandAlone环境下, 有哪些worker
配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh# 2. 编辑spark-env.sh, 在底部追加如下内容## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
注意, 上面的配置的路径 要根据你自己机器实际的路径来写
在HDFS上创建程序运行历史记录存放的文件夹:
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
配置spark-defaults.conf文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.conf# 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://node1:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
配置log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties# 2. 修改内容 参考下图
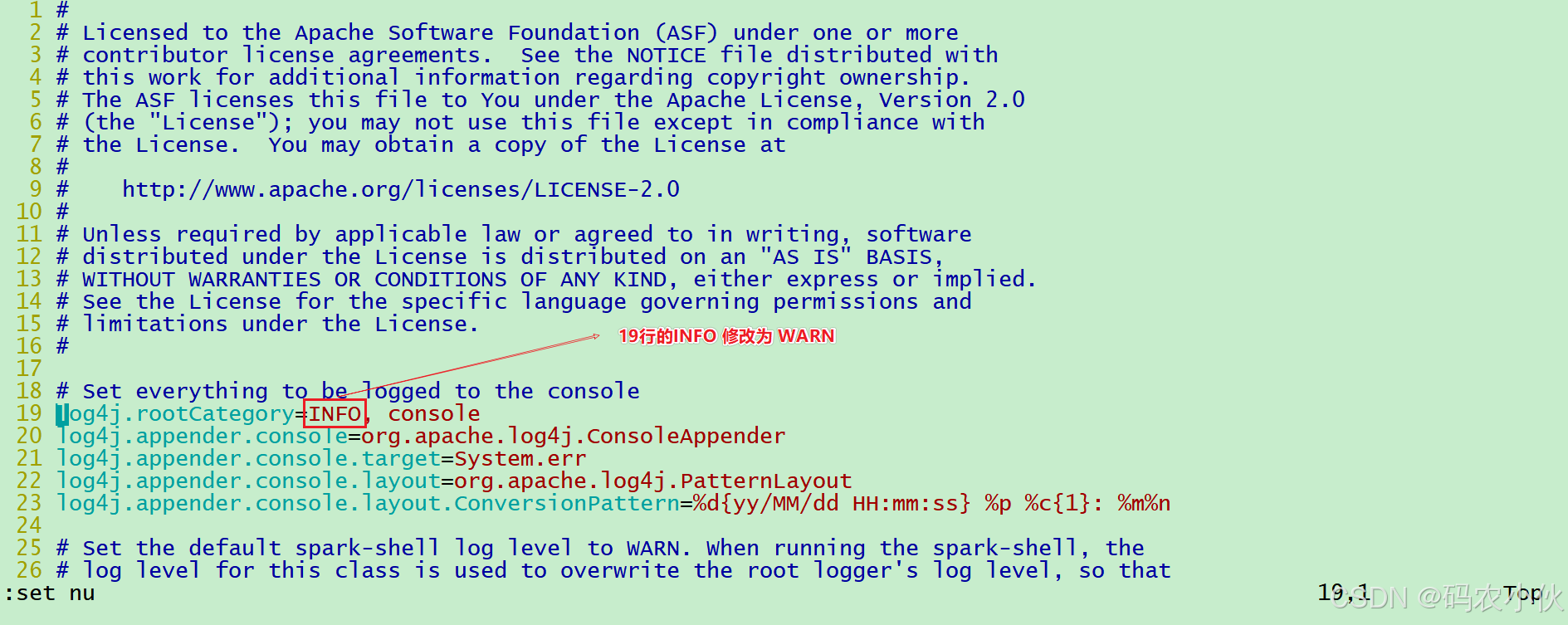
这个文件的修改不是必须的, 为什么修改为WARN. 因为Spark是个话痨
会疯狂输出日志, 设置级别为WARN 只输出警告和错误日志, 不要输出一堆废话.
将Spark安装文件夹 分发到其它的服务器上
scp -r spark-3.1.2-bin-hadoop3.2 node2:/export/server/
scp -r spark-3.1.2-bin-hadoop3.2 node3:/export/server/
不要忘记, 在node2和node3上 给spark安装目录增加软链接
ln -s /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark
检查
检查每台机器的:
JAVA_HOME
SPARK_HOME
PYSPARK_PYTHON
等等 环境变量是否正常指向正确的目录
启动历史服务器
sbin/start-history-server.sh
启动Spark的Master和Worker进程
# 启动全部master和worker
sbin/start-all.sh# 或者可以一个个启动:
# 启动当前机器的master
sbin/start-master.sh
# 启动当前机器的worker
sbin/start-worker.sh# 停止全部
sbin/stop-all.sh# 停止当前机器的master
sbin/stop-master.sh# 停止当前机器的worker
sbin/stop-worker.sh
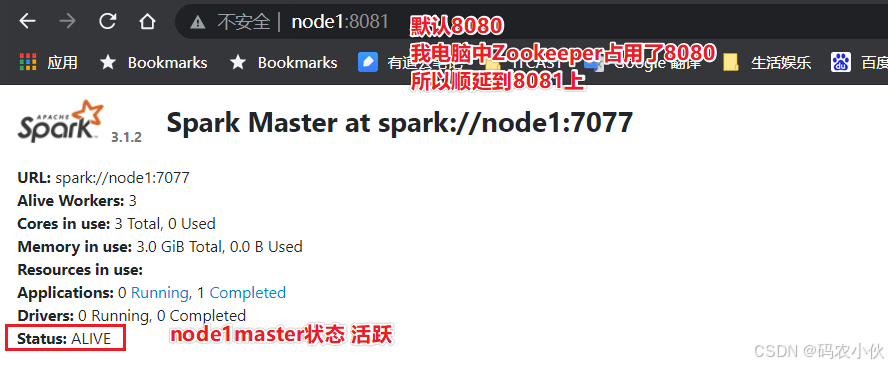
查看Master的WEB UI
默认端口master我们设置到了8080
如果端口被占用, 会顺延到8081 …;8082… 8083… 直到申请到端口为止
可以在日志中查看, 具体顺延到哪个端口上:
Service 'MasterUI' could not bind on port 8080. Attempting port 8081.

连接到StandAlone集群
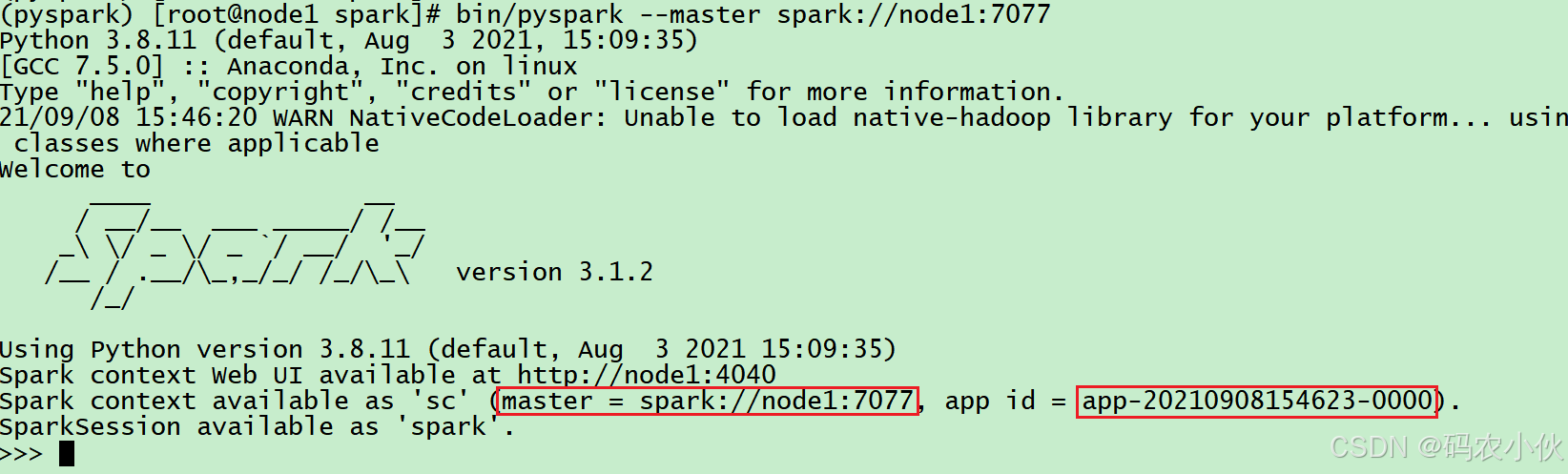
bin/pyspark
执行:
bin/pyspark --master spark://node1:7077
# 通过--master选项来连接到 StandAlone集群
# 如果不写--master选项, 默认是local模式运行
bin/spark-shell
bin/spark-shell --master spark://node1:7077
# 同样适用--master来连接到集群使用
// 测试代码
sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
bin/spark-submit (PI)
bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 100
# 同样使用--master来指定将任务提交到集群运行
查看历史服务器WEB UI
历史服务器的默认端口是: 18080
我们启动在node1上, 可以在浏览器打开:
node1:18080来进入到历史服务器的WEB UI上.

Spark StandAlone HA 环境搭建
步骤
前提: 确保Zookeeper 和 HDFS 均已经启动
先在spark-env.sh中, 删除: SPARK_MASTER_HOST=node1
原因: 配置文件中固定master是谁, 那么就无法用到zk的动态切换master功能了.
在spark-env.sh中, 增加:
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
# spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现
# 指定Zookeeper的连接地址
# 指定在Zookeeper中注册临时节点的路径
将spark-env.sh 分发到每一台服务器上
scp spark-env.sh node2:/export/server/spark/conf/
scp spark-env.sh node3:/export/server/spark/conf/
停止当前StandAlone集群
sbin/stop-all.sh
启动集群:
# 在node1上 启动一个master 和全部worker
sbin/start-all.sh# 注意, 下面命令在node2上执行
sbin/start-master.sh
# 在node2上启动一个备用的master进程
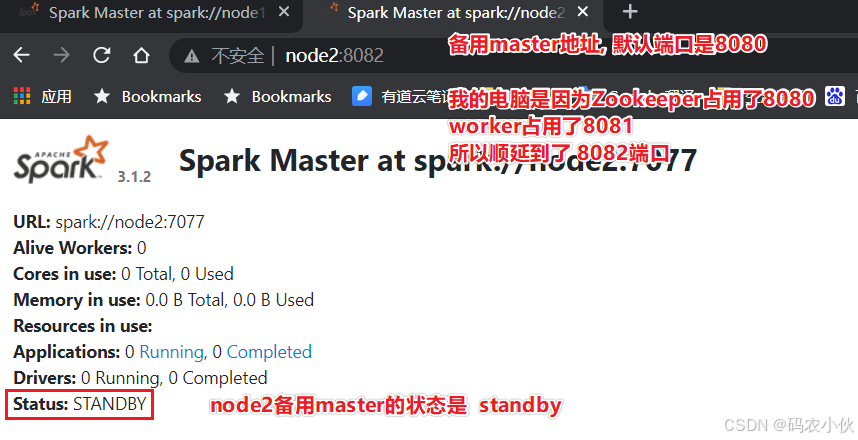
master主备切换
提交一个spark任务到当前alivemaster上:
bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 1000
在提交成功后, 将alivemaster直接kill掉
不会影响程序运行:
当新的master接收集群后, 程序继续运行, 正常得到结果.
结论 HA模式下, 主备切换 不会影响到正在运行的程序.
最大的影响是 会让它中断大约30秒左右.

Spark On YARN 环境搭建
部署
确保:
- HADOOP_CONF_DIR
- YARN_CONF_DIR
在spark-env.sh 以及 环境变量配置文件中即可
连接到YARN中
bin/pyspark
bin/pyspark --master yarn --deploy-mode client|cluster
# --deploy-mode 选项是指定部署模式, 默认是 客户端模式
# client就是客户端模式
# cluster就是集群模式
# --deploy-mode 仅可以用在YARN模式下
注意: 交互式环境 pyspark 和 spark-shell 无法运行 cluster模式
bin/spark-shell
bin/spark-shell --master yarn --deploy-mode client|cluster
注意: 交互式环境 pyspark 和 spark-shell 无法运行 cluster模式
bin/spark-submit (PI)
bin/spark-submit --master yarn --deploy-mode client|cluster /xxx/xxx/xxx.py 参数
spark-submit 和 spark-shell 和 pyspark的相关参数
参见: 附2
附1 Anaconda On Linux 安装 (单台服务器)
安装
上传安装包:
上传: 资料中提供的Anaconda3-2021.05-Linux-x86_64.sh文件到Linux服务器上
安装:
sh ./Anaconda3-2021.05-Linux-x86_64.sh





输入yes后就安装完成了.
安装完成后, 退出SecureCRT 重新进来:

看到这个Base开头表明安装好了.
base是默认的虚拟环境.
国内源
如果你安装好后, 没有出现base, 可以打开:/root/.bashrc这个文件, 追加如下内容:
channels:- defaults
show_channel_urls: true
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
附2 spark-submit和pyspark相关参数
客户端工具我们可以用的有:
- bin/pyspark: pyspark解释器spark环境
- bin/spark-shell: scala解释器spark环境
- bin/spark-submit: 提交jar包或Python文件执行的工具
- bin/spark-sql: sparksql客户端工具
这4个客户端工具的参数基本通用.
以spark-submit 为例:
bin/spark-submit --master spark://node1:7077 xxx.py
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]Options:--master MASTER_URL spark://host:port, mesos://host:port, yarn,k8s://https://host:port, or local (Default: local[*]).--deploy-mode DEPLOY_MODE 部署模式 client 或者 cluster 默认是client--class CLASS_NAME 运行java或者scala class(for Java / Scala apps).--name NAME 程序的名字--jars JARS Comma-separated list of jars to include on the driverand executor classpaths.--packages Comma-separated list of maven coordinates of jars to includeon the driver and executor classpaths. Will search the localmaven repo, then maven central and any additional remoterepositories given by --repositories. The format for thecoordinates should be groupId:artifactId:version.--exclude-packages Comma-separated list of groupId:artifactId, to exclude whileresolving the dependencies provided in --packages to avoiddependency conflicts.--repositories Comma-separated list of additional remote repositories tosearch for the maven coordinates given with --packages.--py-files PY_FILES 指定Python程序依赖的其它python文件--files FILES Comma-separated list of files to be placed in the workingdirectory of each executor. File paths of these filesin executors can be accessed via SparkFiles.get(fileName).--archives ARCHIVES Comma-separated list of archives to be extracted into theworking directory of each executor.--conf, -c PROP=VALUE 手动指定配置--properties-file FILE Path to a file from which to load extra properties. If notspecified, this will look for conf/spark-defaults.conf.--driver-memory MEM Driver的可用内存(Default: 1024M).--driver-java-options Driver的一些Java选项--driver-library-path Extra library path entries to pass to the driver.--driver-class-path Extra class path entries to pass to the driver. Note thatjars added with --jars are automatically included in theclasspath.--executor-memory MEM Executor的内存 (Default: 1G).--proxy-user NAME User to impersonate when submitting the application.This argument does not work with --principal / --keytab.--help, -h 显示帮助文件--verbose, -v Print additional debug output.--version, 打印版本Cluster deploy mode only(集群模式专属):--driver-cores NUM Driver可用的的CPU核数(Default: 1).Spark standalone or Mesos with cluster deploy mode only:--supervise 如果给定, 可以尝试重启DriverSpark standalone, Mesos or K8s with cluster deploy mode only:--kill SUBMISSION_ID 指定程序ID kill--status SUBMISSION_ID 指定程序ID 查看运行状态Spark standalone, Mesos and Kubernetes only:--total-executor-cores NUM 整个任务可以给Executor多少个CPU核心用Spark standalone, YARN and Kubernetes only:--executor-cores NUM 单个Executor能使用多少CPU核心Spark on YARN and Kubernetes only(YARN模式下):--num-executors NUM Executor应该开启几个--principal PRINCIPAL Principal to be used to login to KDC.--keytab KEYTAB The full path to the file that contains the keytab for theprincipal specified above.Spark on YARN only:--queue QUEUE_NAME 指定运行的YARN队列(Default: "default").
附3 Windows系统配置Anaconda
安装
打开资料中提供的:Anaconda3-2021.05-Windows-x86_64.exe文件,或者去官网下载:https://www.anaconda.com/products/individual#Downloads
打开后,一直点击Next下一步即可:
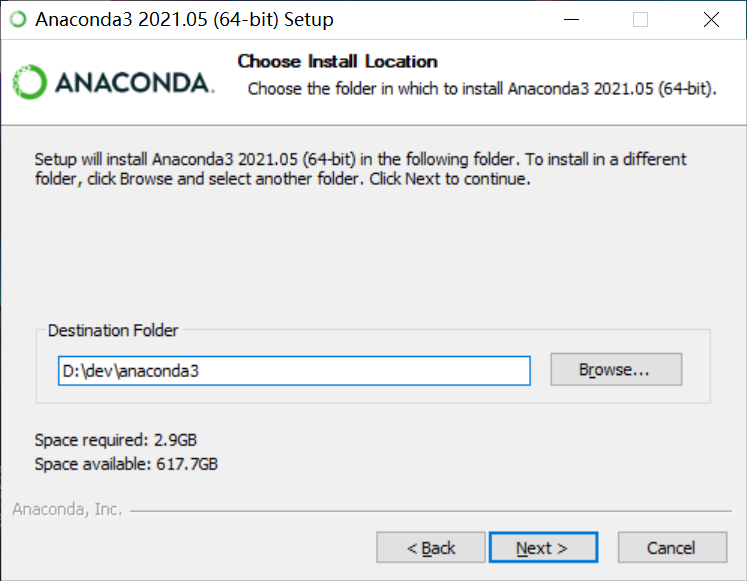
如果想要修改安装路径, 可以修改
不必勾选
最终点击Finish完成安装
打开开始菜单, 搜索Anaconda
出现如图的程序, 安装成功.
打开 Anaconda Prompt程序:

出现base说明安装正确.
配置国内源
Anaconda默认源服务器在国外, 网速比较慢, 配置国内源加速网络下载.
打开上图中的 Anaconda Prompt程序:
执行:
conda config --set show_channel_urls yes
然后用记事本打开:
C:\Users\用户名\.condarc文件, 将如下内容替换进文件内,保存即可:
channels:- defaults
show_channel_urls: true
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
创建虚拟环境
# 创建虚拟环境 pyspark, 基于Python 3.8
conda create -n pyspark python=3.8# 切换到虚拟环境内
conda activate pyspark# 在虚拟环境内安装包
pip install pyhive pyspark jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
相关文章:
Spark部署文档
Spark Local环境部署 下载地址 https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz 条件 PYTHON 推荐3.8JDK 1.8 Anaconda On Linux 安装 本次课程的Python环境需要安装到Linux(虚拟机)和Windows(本机)上 参见最下方, 附: Anaconda On Linux 安…...

Broadcast:Android中实现组件及进程间通信
目录 一,Broadcast和BroadcastReceiver 1,简介 2,广播使用 二,静态注册和动态注册 三,无序广播和有序广播 1,有序广播的使用 2,有序广播的截断 3,有序广播的信息传递 四&am…...

5分钟熟练上手ES的具体使用
5分钟上手ES的具体使用 相信有很多同学想要去学习elk时会使用docker等一些方式去下载相关程序,但提到真正去使用es的一系列操作时又会知之甚少。于是这一篇博客应运而生。 本文就以下载好elk/efk系统后应该如何去使用为例,介绍es的具体操作。 es关键字…...

lambda 自调用递归
从前序与中序遍历序列构造二叉树 官方解析实在是记不住,翻别人的题解发现了一个有意思的写法 class Solution { public:TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {auto dfs [](auto&& dfs, auto&&…...
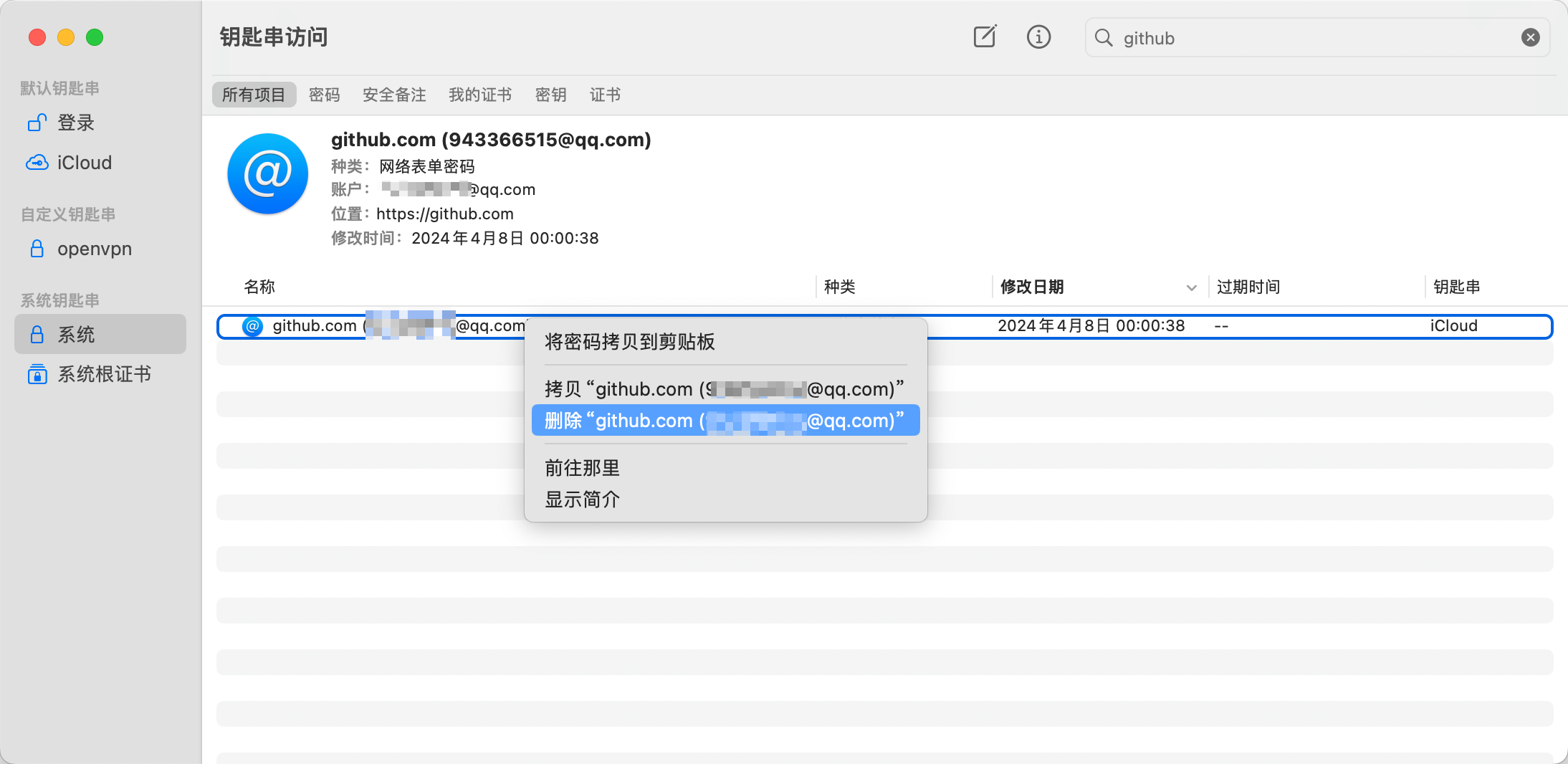
mac中git操作账号的删除
命令行玩的很溜的可以跳过 找到钥匙串访问 搜github、gitee就行了...

AI Agent的20个趋势洞察
结论整理自【QuestMobile2024 AI智能体应用洞察半年报】: AI原生应用(APP)一路高歌;豆包用户突破3000万;TOP10 APP以综合类应用为主。无论何种类型的AIGC APP都以智能体为“抓手”,专注于解决各种细分场景中的问题&am…...

Spring Boot-定时任务问题
Spring Boot 定时任务问题及其解决方案 1. 引言 在企业级应用中,定时任务是一项常见需求,通常用于自动化执行某些操作,如数据备份、日志清理、系统监控等。Spring Boot 提供了简洁易用的定时任务机制,允许开发者通过简单的配置来…...

从混乱到清晰!借助Kimi掌握螺旋型论文结构的秘诀!
AIPaperGPT,论文写作神器~ https://www.aipapergpt.com/ 写学术论文有时会让人感到头疼,特别是在组织结构和理清思路时,往往觉得无从下手。 其实,找到合适的结构不仅能帮你清晰地表达研究成果,还能让你的论文更有说…...
等级考试试卷(二级)真题)
中国电子学会202306青少年软件编程(Python)等级考试试卷(二级)真题
一、单选题(共25题,每题2分,共50分) 1、运行以下程序,如果通过键盘先后输入的数是1和3,输出的结果是?( ) a = int(input()) b = int(input()) if a < b:a = b print(a)A. 3 1 B. 1 3 C. 1 D. 3 2、运行以下程序,输出的结果是?( ) n = 10 s = 0 m = 1 while…...
样本册3D翻页电子版和印刷版同时拥有是一种什么体验
在数字化时代,样本册3D翻页电子版的兴起,让传统印刷版样本册面临着前所未有的挑战。与此同时,许多企业也开始尝试将两者相结合,以满足更多元化的市场需求。那么,拥有一份既具备数字化优势,又保留传统印刷…...

8586 括号匹配检验
### 思路 1. **初始化栈**:创建一个空栈用于存储左括号。 2. **遍历字符串**:逐个字符检查: - 如果是左括号(( 或 [),则入栈。 - 如果是右括号() 或 ]),则检查栈是…...

案例精选 | 聚铭助力河北省某市公安局筑牢网络安全防护屏障
近年来,各级公安机关积极响应信息化发展趋势,致力于提升公安工作的效能与核心战斗力。河北省某市公安局作为主管全市公安工作的市政府部门,承担着打击违法犯罪、维护社会稳定的重任。随着信息化建设的推进,局内系统数量、种类及数…...

VBS学习2:问题解决(文件中含义中文运行报错或者中文乱码)
文件中含义中文运行报错或者中文乱码 问题 msgbox"fdsfdsf大蘇打撒旦dsfsdffsdfsd发斯蒂芬斯蒂芬"解决 文件编码修改成GB2312...

首次揭秘行业内幕!范罗士、希喂、有哈、小米、安德迈宠物空气净化器实测分析
前段时间有个朋友来我家做客,看到我家三只长毛猫,家里还是干干净净的,他家一只短毛猫都猫毛满天飞。也是很细心,留意到我家猫拉完粑粑后,我立刻就去把宠物空气净化器开上了,他一点味都没闻到。 回家后立刻…...
)
1267:【例9.11】01背包问题(信奥一本通)
题目链接:信息学奥赛一本通(C版)在线评测系统 (ssoier.cn) 今天刚看完卡尔大哥讲解的01背包,今天手敲了一遍,还是很多问题,只能说自己还是刷题太少或者说是没理解到位。 代码如下 # include <iostrea…...

信息化时代下的高标准农田灌区:变革与机遇并存
在信息化时代的浪潮中,高标准农田灌区的建设与管理正经历着前所未有的变革,这既是一个挑战重重的历程,也孕育着无限的发展机遇。随着物联网、大数据、云计算以及人工智能等先进技术的飞速发展与融合应用,传统的农田灌溉模式正在被…...

【系统架构设计师-2013年真题】案例分析-答案及详解
更多内容请见: 备考系统架构设计师-核心总结索引 文章目录 【材料1】问题1问题2【材料2】问题1问题2问题3问题4【材料3】问题1问题2问题3【材料4】问题1问题2问题3【材料5】问题1问题2问题3【材料1】 阅读以下关于企业应用系统集成架构设计的说明,在答题纸上回答问题1和问题…...

git merge如何忽略部分路径
参考文章: Git - Ignore files during merge How to make git ignore a directory while merging 在进行git merge时,想忽略部分路径的回合。 如:将develop分支merge回master,但是忽略/path/to/folder路径 操作: gi…...

spring boot导入多个配置文件
1、简介 Spring Boot从2.4.x版本开始支持了导入文件的方式来加载配置参数,与spring.config.additional-location不同的是不用提前设置而且支持导入的文件类型相对来说要丰富很多。 我们只需要在application.properties/application.yml配置文件中通过spring.config.…...

硬件工程师笔试面试——无线通讯模块
目录 15、无线通讯模块 15.1 基础 无线通讯模块实物图 15.1.1 概念 15.1.2 常见的无线通讯模块及其特点 15.1.3 无线通讯模块参数 15.1.4 无线通讯模块工作原理 15.2 相关问题 15.2.1 如何根据项目需求选择合适的无线通讯模块? 15.2.2 无线通讯模块的安全性如何,如…...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...