从 HDFS 迁移到 MinIO 企业对象存储

云原生、面向 Kubernetes 、基于微服务的架构推动了对 MinIO 等网络存储的需求。在云原生环境中,对象存储的优势很多 - 它允许独立于存储硬件对计算硬件进行弹性扩展。它使应用程序无状态,因为状态是通过网络存储的,并且通过降低操作复杂性,使应用程序能够实现比以往更高的规模。从网络对象存储系统写入和读取数据的最突出标准是 S3。MinIO 是一种完全符合 S3 标准、高性能、混合和多云就绪的对象存储解决方案。与将数据引入计算的传统方法相比,通过网络存储计算工作负载数据的模式是现代分解架构的缩影。这种方法的好处是多方面的:节省成本、可扩展性和性能。我们的一个客户,一家领先的金融集团,使用 MinIO 而不是 HDFS,节省了 60%+ 的成本性能提升。这种节省绝非非凡。在可扩展性方面,Hadoop 在处理小文件方面的低效率及其对数据局部性的需求限制了其可扩展性,而 MinIO 擅长处理从 KB 到 TB 的各种对象大小。至于性能,大多数老练的 Hadoop 管理员都知道,高性能对象存储后端已成为现代实施的默认存储架构。本文详细介绍了如何通过更改存储协议、数据迁移和性能调整,将对象存储的优势引入 Hadoop。在以下部分中,我们将介绍从 HDFS 迁移到 MinIO E
hdfs:// to s3a://
默认情况下,Hadoop 生态系统中的任何大数据平台都支持与 S3 兼容的对象存储后端。这种支持可以追溯到 2006 年,当时新兴技术嵌入了 S3 客户端实现。所有 Hadoop 相关平台都使用 hadoop-aws 模块和 aws-java-sdk-bundle 来为 S3 API 提供支持。通过指定适当的协议,应用程序可以在 HDFS 和 S3 存储后端之间无缝切换。对于 S3,协议方案为 s3a://,对于 HDFS,方案为 hdfs://。
Hadoop SDK 中的 S3 客户端实现多年来不断发展,每个协议方案都有不同的协议方案名称,例如 s3://、s3n:// 和 s3a://。目前 s3:// 表示 Amazon 的 EMR 客户端。Hadoop 生态系统中可用的最突出的 S3 客户端是 s3a://,它适用于所有其他 S3 后端。
注意:s3n:// 已失效,不再受任何主要 Hadoop 供应商支持。
迁移的第一步是将 Hadoop 用于与后端存储通信的协议从 hdfs:// 更改为 s3a://。在平台的 core-site.xml 文件中,更改以下参数 Hadoop.defaultFS 以指向 s3 后端。
<property> <name>fs.default.name</name> <value>hdfs://192.168.1.2:9000/</value> </property> | <property> <name>fs.default.name</name> <value>s3a://minio:9000/</value> </property> |
有几种方法可以迁移到 MinIOAIstore。您可以将旧数据保留在 HDFS 中供 Hadoop 访问,而新数据保存在 MinIO 中,以供 Apache Spark 等云原生应用程序访问。您可以将所有内容移动到 MinIO,以便 Hadoop 和云原生应用程序访问它。或者,您可以选择执行部分迁移。您必须为您的组织选择最好的。我将在下面介绍如何进行完整迁移,并在以后的博客文章中更深入地了解如何规划迁移。
将数据从 HDFS 迁移到 S3
可以使用名为 distcp 的 Hadoop 原生工具在不同的存储后端之间迁移数据,distcp 代表分布式复制。它需要两个参数:source 和 destination。源和目标可以是 Hadoop 支持的任何存储后端。在此示例中,为了将数据从 HDFS 移动到 s3,必须将源设置为 hdfs://192.168.1.2:9000 ,目标为 s3a://minio:9000 。
>_ # configure the source and destination
>_ export src=hdfs://192.168.1.2:9000>_ export dest=s3a://minio:9000>_
>_ # perform the copy
>_ Hadoop distcp $src $dest根据数据的大小和传输速度,distcp 本身可以扩展,并且可以使用大规模并行基础设施迁移数据。映射器的数量,即复制数据的并行任务的数量,可以使用 -m 标志进行配置。一个好的经验法则是将其设置为基础设施中所有节点的可用 CPU 内核数。例如,如果您有 8 个空闲节点,每个节点有 8 个内核,则 CPU 内核的数量将为 64。
>_ # configure the number of mappers
>_ export num_cpu_cores=64>_
>_ # perform the copy with higher parallelism for large datasets
>_ Hadoop distcp -m $num_cpu_cores $src $dest注意:映射器的数量应对应于基础设施中的可用内核数量,而不是整个集群中的内核总数。这是为了确保其他工作负载具有可用于其操作的资源。
优化性能
Hadoop 和 MinIO 之间的数据访问模式大不相同。根据设计,对象存储系统不支持编辑。这在其实现数 PB 规模的能力中起着关键作用。其次,在对象存储系统中将数据从一个位置复制到另一个位置的成本很高,因为该操作会产生服务器端副本。某些对象存储系统并不严格一致,这可能会使 Hadoop 感到困惑,因为文件可能不会显示,或者如果最终一致,则已删除的文件可能会在列出操作期间显示。
注意:MinIO 没有一致性缺点,因为它是严格一致的。
考虑到这些因素,很容易调整您的应用程序以成为 Object Storage 原生应用程序。为了帮助加快这一旅程,已经付出了巨大的努力,那就是将 S3 提交程序引入 Hadoop。顾名思义,S3 提交程序承诺向 S3 提供一致、可靠和高性能的数据承诺。提交者更改 S3 中数据的读/写访问模式。首先,它们避免了服务器端副本,否则 Hadoop 应用程序会广泛使用服务器端副本,以允许多个 Hadoop 工作线程原子写入数据。一些提交者甚至使用本地驱动器作为缓存,并且只将最终输出写入 MinIO以提高性能。有三个提交程序,每个提交程序都有不同的权衡来处理各种用例。他们是:
-
目录提交者
-
分区 Committer
-
提交者
为了在应用程序中启用 committer,请在 core-site.xml 文件中设置以下配置:
<property><name>mapreduce.outputcommitter.factory.scheme.s3a</name><value>org.apache.Hadoop.fs.s3a.commit.S3ACommitterFactory</value><description>The committer factory to use when writing data to S3A filesystems.</description></property>目录提交者
此提交程序首先更改访问模式以在本地 (缓存驱动器) 写入数据,一旦收集到要写入的数据的最终版本,就会执行写入。这种编写风格更适合分布式计算和 MinIO通过快速网络连接,并通过防止服务器端副本大大提高性能。要选择此提交程序,请将以下参数 fs.s3a.committer.name 设置为 directory。
<property><name>fs.s3a.committer.name</name><value>directory</value></property>分区 Committer
此提交程序类似于目录提交程序,不同之处在于它处理冲突的方式。目录提交程序通过考虑整个目录结构来处理写入同一文件的不同 Hadoop 工作程序的冲突。对于分区的提交程序,冲突是逐个分区处理的。如果目录结构是深度嵌套的或通常非常大,则与目录提交程序相比,此提交程序提供更高的性能。仅建议将其用于 Apache Spark 工作负载。
<property><name>fs.s3a.committer.name</name><value>partitioned</value></property>Magic 提交者
这个 committer 的内部工作原理不太为人所知,因此命名为 Magic committer。它会自动选择最佳策略以实现尽可能高的性能。它仅适用于严格一致的 S3 存储。由于 MinIO 是严格一致的,因此可以安全地使用 Magic committer。建议在您的工作负载中尝试此提交程序,以将性能与其他提交程序进行比较。
<property><name>fs.s3a.committer.name</name><value>magic</value></property>
选择 Committer 的一个好的经验法则是从最简单且最可预测的目录 Committer 开始,如果您的应用程序需求不能得到满足,请尝试其他两个 Committer(如果适用)。一旦选择了合适的提交者,您的应用程序就可以接受性能和正确性的测试。
相关文章:
从 HDFS 迁移到 MinIO 企业对象存储
云原生、面向 Kubernetes 、基于微服务的架构推动了对 MinIO 等网络存储的需求。在云原生环境中,对象存储的优势很多 - 它允许独立于存储硬件对计算硬件进行弹性扩展。它使应用程序无状态,因为状态是通过网络存储的,并且通过降低操作复杂性&a…...

Rust 常见问题汇总
问题1: cargo build 一直提示Blocking waiting for file lock on package cache。 在 cargo.toml 文件中添加了依赖之后,运行 cargo build 命令时,如果卡在 blocking waiting for file lock on package cache lock 这里, 后来发…...

java泛型类与泛型方法
Java泛型类和泛型方法是Java泛型编程中的重要组成部分。它们允许开发者编写类型安全且高度复用的代码。下面详细介绍泛型类和泛型方法的概念、用法和示例。 泛型类 泛型类是在类定义中使用类型参数的类,可以指定具体的类型实例化该类。这样可以确保类型安全&#…...

Android String资源文件中,空格、换行以及特殊字符如何表示
空格: 例:<string name"test">test test</string> 换行:\n 例:<string name"test">test \n test</string> tab:\t …...

CUDA及GPU学习资源汇总
CUDA C Programming Guide 的中文翻译版GPU中的SM和warp的关系推荐几个不错的CUDA入门教程CUDA编程入门极简教程...

uniapp vue3 梯形选项卡组件
实现的效果图: 切换选项卡显示不同的内容,把这个选项卡做成了一个组件,需要的自取。 // 组件名为 trapezoidalTab <template> <view class"pd24"><view class"nav"><!-- 左侧 --><view cla…...

如何在微信小程序中实现WebSocket连接
微信小程序作为一种全新的应用形态,凭借其便捷性、易用性受到了广大用户的喜爱。在实际开发过程中,实时通信功能是很多小程序必备的需求。WebSocket作为一种在单个TCP连接上进行全双工通信的协议,能够实现客户端与服务器之间的实时通信。本文…...

二级等保测评中安全物理环境的重要性及高危项分析
当今数字化时代,信息安全至关重要。网络安全等级保护测评是确保信息系统安全稳定运行的重要手段之一,其中二级等保测评对于许多企业和组织来说是必须要达到的安全标准。 而安全物理环境作为等保测评的重要组成部分,其重要性不容忽视。 安全物…...

C++11——lambda
lambda lambda的介绍lambda的使用lambda的细节->捕捉列表 lambda的介绍 lambda是匿名函数,再适合的场景去使用可以提高代码的可读性。 场景: 假设有一个Goods类需要进行按照价格、数量排序 class Goods {string name;size_t _price;//价格int num;/…...

Dubbo3序列化安全问题
序列化安全 在 Dubbo 3.0 中,序列化协议的安全性得到了加强。 1. 序列化安全性升级 Triple 协议: 推荐使用 Triple 协议 的非 Wrapper 模式,该模式在安全性上更为严格。需要开发人员编写 IDL(接口描述语言)文件,这虽…...

秒懂Linux之共享内存
目录 共享内存概念 模拟实现共享内存 创建key阶段 编辑创建共享内存阶段 删除共享内存阶段 查看共享内存属性阶段 挂接共享内存到进程阶段 取消共享内存与进程挂接阶段 进程通信阶段 添加管道改进版 共享内存函数 shmget函数 shmat函数 shmdt函数 shmctl函数 共享内存概念 共…...

【计算机网络】网络层协议解析
网络层的两种服务IPv4分类编址划分子网无分类地址 IPv4地址应用IP数据报的发送和转发过程主机发送IP数据报路由器转发IP数据报 IPv4数据报首部格式ICMP网际控制报文协议虚拟专用网VPN与网络地址转换NAT 网络层主要任务是实现网络互连,进而实现数据包在各网络之间的传…...
)
sqlist void reverse(SqList A)
#include <stdlib.h> #include <stdio.h> #include <iostream> using namespace std; #define INIT_SIZE 5 #define INCREMENT 10 # define OK 1 # define ERROR 0/* 定义ElemType为int类型 */ typedef int ElemType; void input(ElemType &s); void out…...

聊聊Thread Local Storage
聊聊ThreadLocal 为什么需要Thread Local StorageThread Local Storage的实现PThread库实现操作系统实现GCC __thread关键字实现C11 thread_local实现JAVA ThreadLocal实现 Thread Local Storage 线程局部存储,简称TLS。 为什么需要Thread Local Storage 变量分为全…...

WEB攻防-JS项目Node.js框架安全识别审计验证绕过
知识点: 1、原生JS&开发框架-安全条件 2、常见安全问题-前端验证&未授权 详细点: 1、什么是JS渗透测试? 在JavaScript中也存在变量和函数,当存在可控变量及函数调用即可参数漏洞 2、流行的Js框架有哪些? …...

STM32——SPI
1.SPI简介 SPI,是英语Serial Peripheral Interface的缩写,顾名思义就是串行外围设备接口。SPI,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚…...

【云安全】云上资产发现与信息收集
一、云基础设施组件 1、定义 在云计算基础架构中,基础设施组件通常包括:计算、存储、网络和安全等方面的资源。例如,计算资源可以是虚拟机、容器或无服务器计算引擎;存储资源可以是对象存储或块存储;网络资源可以是虚拟…...
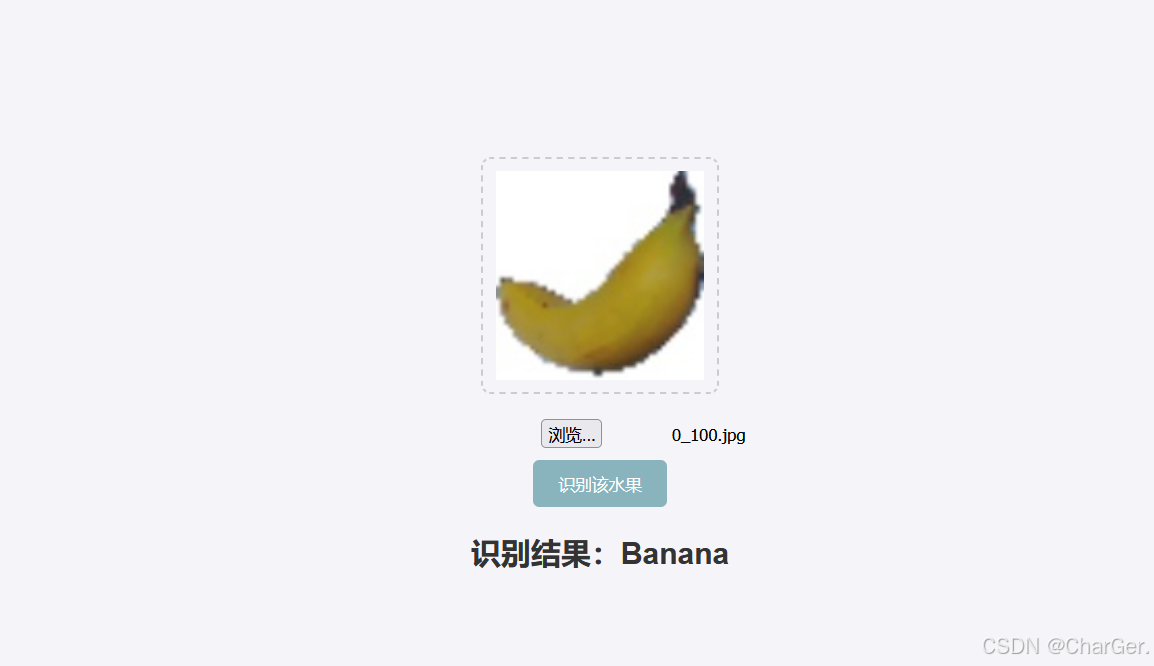
flask搭建微服务器并训练CNN水果识别模型应用于网页
一. 搭建flask环境 概念 flask:一个轻量级 Web 应用框架,被设计为简单、灵活,能够快速启动一个 Web 项目。CNN:深度学习模型,用于处理具有网格状拓扑结构的数据,如图像(2D网格)和视频(3D网格&a…...

数据篇| 关于Selenium反爬杂谈
友情提示:本章节只做相关技术讨论, 爬虫触犯法律责任与作者无关。 LLM虽然如火如荼进行着, 但是没有数据支撑, 都是纸上谈兵, 人工智能的三辆马车:算法-数据-算力,缺一不可。之前写过关于LLM微调文章《微调入门篇:大模型微调的理论学习》、《微调实操一: 增量预训练(Pretrai…...

MySQL高阶1890-2020年最后一次登录
目录 题目 准备数据 分析数据 题目 编写解决方案以获取在 2020 年登录过的所有用户的本年度 最后一次 登录时间。结果集 不 包含 2020 年没有登录过的用户。 返回的结果集可以按 任意顺序 排列。 准备数据 Create table If Not Exists Logins (user_id int, time_stamp …...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...