论文阅读笔记:Sapiens: Foundation for Human Vision Models
Sapiens: Foundation for Human Vision Models
- 1 背景
- 1.1 问题
- 1.2 目标
- 2 方法
- 3 创新点
- 4 模块
- 4.1 Humans-300M数据集
- 4.2 预训练
- 4.3 2D位姿估计
- 4.4 身体部位分割
- 4.5 深度估计
- 4.6 表面法线估计
- 5 实验
- 5.1 实现细节
- 5.2 2D位姿估计
- 5.3 身体部位分割
- 5.4 深度估计
- 5.5 表面法线估计
- 5.6 讨论
- 6 结论
论文:https://arxiv.org/abs/2408.12569
代码:https://github.com/facebookresearch/sapiens
Demo:1.https://about.meta.com/realitylabs/codecavatars/sapiens
2.https://huggingface.co/collections/facebook/sapiens-66d22047daa6402d565cb2fc
1 背景
1.1 问题
目前在2D和3D中生成具有真实感的人方面已取得重大的进展。这些方法的成功很大程度归功于对各种资产的稳健估计,例如2D关键点,细粒度人体部分分割,深度或者表面法线。
例如ControlNet。
问题1:对这些资产的稳健和准确估计仍然是一个活跃的研究领域,复杂的系统来提高单个任务的性能往往阻碍了更广泛的应用。
问题2:野生数据集的标签缺乏准确性。
1.2 目标
作者认为,这种以人为中心的模型应该满足3个标准:泛化性,广泛适用性和高保真性:
(1)泛化性保证了对未知条件的鲁棒性,使模型能够在不同的环境中一致的执行。
(2)广泛的适用性表明了该模型的通用性,使其在最少修改的情况下适用于广泛的任务。
(3)高保真性是指模型能够产生精确的、高分辨率的输出,这对于人类生成任务来说是必不可少的。
本文的目标是提供一个体现了这些属性的统一的框架和模型,称为Sapines。
2 方法
(1)依据之前的工作,利用大型数据集和可扩展的模型架构是泛化的关键。
(2)为了更广泛的适用性,采用先预训练再微调的方法,使得预训练后能够以最小的调整来适应特定的任务。
这种方法提出的一个关键问题是:哪种类型的数据对预训练最有效?在给定计算限制的情况下,应该把重点放在收集尽可能多的人类图像上,还是最好在一个较小的数据集上预训练,以更好的反应显示世界的变异性?现有的方法往往忽略了下游任务背景下的预训练数据分布。为了研究预训练数据分布对特定人类任务的影响,作者收集制作了Humans-300M数据集,该数据集包含3亿张不同的人类图像,这些未标记的图像用于从头预训练各种尺寸的VIT,参数计数范围从300M到20B。
从大型数据集中学习通用视觉特征的各种自监督方法中,作者选择了masked-autoencoder(MAE)方法。MAE相比于对比策略或多推理策略,其单便推理允许以相同的计算资源处理更大数量的图像。
Segment Anything中也是用MAE对图像编码器进行预训练的。

(3)为了更高的保真度,作者将预训练的原始输入分辨率提高到1024像素,与现有最大的视觉主干(MAWS预训练的VIT模型)相比,FLOPs增加了4倍。每个模型在1.2万亿个tokens上进行预训练。
这里的1.2万亿个tokens应该是这么计算来的:
patch_size = 16 image_size = 1024 image_num = 3E8 token_num = (image_size // patch_size)**2 * image_num
表1列出了与早期方法的比较。

为了在以人为中心的任务上进行微调,作者使用了一致的编码器-解码器架构,编码器使用预训练权重进行初始化,而解码器是一个随机初始化的轻量级的,任务特定的头。然后对这两个组件进行端到端的微调。四个基本的以人为中心的视觉任务——2D姿态估计、身体部位分割、深度估计和表面法线预测,如图1所示。

由于Benchmark往往包含噪音标签,在模型微调过程中提供不一致的监督信号,同时,利用细粒度和精准的注释也很重要。因此作者提出了一个更密集的用于姿态估计的2D全身关键点集和一个用于身体部位分割的相机类别词汇表。具体来说,作者引入了一个包含身体,手,脚和面部的308个关键点综合合集。此外将分割类扩展到28类,涵盖了头发,舌头,牙齿,上/下唇、躯干等身体部位。为了保证标注的质量和一致性以及高度的自动化,作者使用多视图捕获设置来收集位姿和分割标记。作者还利用以人为中心的合成数据进行深度和法线估计,利用RenderPeople的600次详细扫描来生成高分辨率的深度图和表面法线。
这里作者分别从模型和数据两个方面,保证子任务输出结果的准确性,即文中提出的保真度。
3 创新点
-
作者引入了Sapiens,一个在大规模人体图像数据集上预训练的VIT家族
-
本研究表明,在相同的计算预算下,简单的数据整理和大规模预训练显著提高了模型的性能
-
模型经过高质量甚至合成标签的微调,表现出了广泛的泛化性
-
本文是第一个原生支持以人为中心任务的高保真推理的1K分辨率模型,在二维姿势、身体部位分割、深度和正常估计的基准测试集上取得了最先进的性能。
4 模块
4.1 Humans-300M数据集
本文使用了一个大型的人类图像数据集对大约10亿张野生人类图像进行预训练。预处理包含丢弃有水印,文本,艺术描述或非自然元素的图像。随后,使用现成的行人边界框检测器对图像进行过滤,保留检测分数在0.9以上且边界框超过300像素的图像。图2给出了数据集中每幅图像的人数分布情况,其中超过2.48亿张图像包含多个主体。

4.2 预训练
作者遵循masked-autoencoder方法进行预训练。模型是在给定原始人体图像的部分观测值下训练的,以重构原始人体图像。与所有的自编码器一样,本文模型包含一个编码器,将可见光图像映射到一个潜在的表示,以及一个解码器,从这个潜在的表示中重建原始图像。预训练数据集有单人图像和多人图像组成,每幅图像以正方形的宽高比例缩放到固定大小,类似于VIT,将图像划分成固定大小的规则非重叠块。随机选择这些块的子集并对其进行掩膜,剩余部分可见。将掩码块占可见块的比例定义为掩膜比,在整个训练过程中保持固定不变。图3展示了本文预训练模型在未知人体图像上的重建。
本文模型表现出对各种图像特征的泛化能力,包括尺度、裁剪、主体的年龄,种族和数量。本文的模型中每个图像块token占图像面积的0.02%((16*16)/(1024*1024)≈0.02%),而标准Vits的图像块面积token占图像面积的0.4%((16*16)/(224*224)≈0.4%),减少了16倍,这为模型提供了细粒度的token推理。如图3,即使使用了95%的掩码比例,本文模型也可以在遮挡样本上实现人体解剖结构的重建。

4.3 2D位姿估计
遵循自上而下的范式,即从输入图像 I ∈ R H × W × 3 I∈R^{H×W×3} I∈RH×W×3中检测 K K K 个关键点的位置。大多数方法将这个问题归结为热力图预测, K K K 个热力图表示对应关键点处于任意空间位置的概率。作者定义了一个用于关键点检测的姿态估计transformer P P P。训练和推理时的边界框缩放为 H × W H×W H×W,并作为输入提供给P。设 y ∈ R H × W × K y∈R^{H×W×K} y∈RH×W×K 表示给定输入 I I I 对应于真值关键点的 K K K 个热力图。位姿估计器将输入 I I I 转换成为一组预测热力图 y ^ ∈ R H × W × K \hat{y}∈R^{H×W×K} y^∈RH×W×K,即 y ^ = P ( I ) \hat{y}=P(I) y^=P(I) 。 P P P 的训练目标是最小化均方差损失 L p o s e = M S E ( y , y ^ ) L_{pose}=MSE(y,\hat{y}) Lpose=MSE(y,y^)。在微调过程中, P P P的编码器用预训练的权值初始化,解码器随机初始化。长宽比 H : W H:W H:W 设置为4:3。预训练的位置嵌入相应地被插值。作者使用具有反卷积和卷积操作的轻量级解码器。
作者对 P P P 中的编码器和解码器进行了跨多个骨架的微调,包括 K = 17 K=17 K=17, K = 133 K=133 K=133 和一个新的 K = 308 K=308 K=308 高细节骨架,如图4(左)所示。与现有的最多包含68个面部关键点的格式相比,本文档 标注由243个面部关键点组成,包括眼睛,嘴唇,鼻子和耳朵周围的代表性点。这种设计是为了细致捕捉真是世界中面部表情的细微细节而量身定做。利用这些关键点,作者从一个室内拍摄装置中手动标注了100万张4K分辨率的图像。

4.4 身体部位分割
人体部位分割通常被称为人体解析,其目的是将输入图像 I I I 中的像素分为 C C C 类。大多数方法将这个问题转化为估计每个像素的类别概率,以创建一个概率图 p ^ ∈ R H × W × C \hat{p}∈R^{H×W×C} p^∈RH×W×C,即 p ^ = S ( I ) \hat{p}=S(I) p^=S(I),其中 S S S 是分割模型。如前所述,对 S S S 采用相同的编码器-解码器结构和初始化方案, S S S 被微调以最小化实际概率图 p p p 和预测概率图 p ^ \hat{p} p^, L s e g = W e i g h t e d C E ( p , p ^ ) L_{seg}=WeightedCE(p,\hat{p}) Lseg=WeightedCE(p,p^)。
作者在两个部分分割词汇表中微调 S S S:C=20的标准集和C=28的新词汇表,如图4(右)所示。
4.5 深度估计
对于深度估计,作者采用了用于分割的架构,修改后的解码器输出通道设置为1进行回归。用 d ∈ R H × W d∈R^{H×W} d∈RH×W 表示图像 I I I 的真实深度图,用D表示深度估计器,其中 d ^ = D ( I ) \hat{d}=D(I) d^=D(I),M 表示图像中人类像素的个数。对于相对深度估计,作者使用图像中的最大和最小深度将 d d d 归一化到 [0,1]。 D D D 的损失 L d e p t h L_{depth} Ldepth 定义如下:

出自论文《Depth map prediction from a single image using a multi-scale deep network》,主要是为了解决平均尺度误差占总误差很大一部分的问题,例如真值深度全是0,预测深度全1,相对深度是没有误差的,但如果直接用L1或L2就会产生误差,所以作者令:
L d e p t h = 1 M ∑ i = 1 M ( l o g ( d i ) − l o g ( d ^ i ) + α ( d , d ^ ) ) L_{depth}=\frac{1}{M}\sum_{i=1}^M(log(d_i)-log(\hat{d}_i)+\alpha(d,\hat{d})) Ldepth=M1∑i=1M(log(di)−log(d^i)+α(d,d^))
其中 α ( d , d ^ ) = 1 M ∑ i = 1 M ( l o g d ^ i − l o g ( d i ) ) \alpha(d,\hat{d})=\frac{1}{M}\sum_{i=1}^M(log{\hat{d}_i}-log(d_i)) α(d,d^)=M1∑i=1M(logd^i−log(di)),这个式子经过推导最终成为式(3)。
推导过程可见:https://zhuanlan.zhihu.com/p/29312227
同时,作者利用600张高分辨率摄影测量人体扫描数据渲染了50万张合成图像,如图5所示,以获得具有高保真度的鲁棒弹幕深度估计模型。从100张HDRI环境图集合中选择随机背景,在场景中放置一个虚拟相机,随机调整其焦距,旋转和平移,以获取4K分辨率的图像极其相关的GT真值深度图。

4.6 表面法线估计
与前面的任务类似,作者将法向量估计器 N N N 的解码器输出通道设置为3,对应于每个像素处法向量的 x y z xyz xyz 分量。生成的合成数据也被用作表面法线估计的监督。设 n n n 为图像 I I I 的真值发现图,即 n ^ = N ( I ) \hat{n}=N(I) n^=N(I)。与深度相似, 损失 L n o r m a l L_{normal} Lnormal 仅针对图像中的人体像素计算,定义如下:

总结:
综上所述,2D位姿估计,身体部位估计,深度估计和表面法线估计的网络结构基本一致,差别在于解码器的输出通道和含义不同,2D位姿估计的K个通道表示K个关键点的概率,身体部位估计的C个通道表示C个身体部位类别的概率,深度估计的1个通道表示相对深度,表面法线的3个通道表示 x y z xyz xyz 分量。
5 实验
5.1 实现细节
-
最大的模型Sapiens-2B使用Pytorch在1024个A100上预训练了18天。
-
预训练的分辨率为1024*1024,patch size为16。
-
微调的分辨率高宽比例为4:3,即1024*768。
-
不同尺寸的模型设计指标如表2。

5.2 2D位姿估计
作者使用现成的边界框检测器进行单人姿态推断。表3展示了与现有的全身姿态估计方法的比较。

尽管只使用了来自室内捕获的数据和注释,但Sapiens显示出队真实世界的强大泛化能力,如图6所示。

5.3 身体部位分割
表4展示Spaiens与其他方法的对比。

图7展示了本文模型的效果。

5.4 深度估计
表5比较了现有深度估计SOTA模型和本文提出方法的对比。

图8将本文方法的效果和DepthAnything进行了对比。

5.5 表面法线估计
表6将本文模型与现有的人体表面法线估计模型进行了对比。

图9将本文模型与PIFuHD,ECON进行了对比。

5.6 讨论
(1)预训练数据的重要性:网络提取的特征质量与预训练数据质量紧密相连。表7展示了使用Human300M进行预训练可以在所有指标上获得更好的性能,这突出了在固定的计算预算下,以人为中心的预训练的好处。

作者还研究了在预训练期间所能看到的人类图像的数量的影响。图10显示,随着预训练数据规模的增加,性能稳步提高,没有出现饱和现象。

(2)零样本泛化性:本文模型对各种情况都具有泛化性。例如在分割中,Sapiens在单人图像上微调,主体多样性有限,背景变化小,且只有第三人称视图(如图4)。但因为大规模预训练,使得模型能够再多个主体,不同年龄和视图上进行泛化,如图11所示,这些观察对其他任务也成立。

(3)缺陷:虽然模型整体很好但并不完美,在具有复杂姿态、稀有姿态、拥挤和严重遮挡的人体图像上效果欠佳。尽管激进的数据增广和裁剪策略可以缓解这一问题,但作者认为本文模型可以作为一种工具来获得大规模的,真实世界的人的标签进行监督,以开发下一代人类视觉模型。
6 结论
本文模型的性能归功于:
-
在一个专门为理解人类而定制的大型数据集上进行大规模的预训练
-
扩展的高分辨率和大容量的VIT骨干
-
真实的和合成的数据上的高质量注释
相关文章:
论文阅读笔记:Sapiens: Foundation for Human Vision Models
Sapiens: Foundation for Human Vision Models 1 背景1.1 问题1.2 目标 2 方法3 创新点4 模块4.1 Humans-300M数据集4.2 预训练4.3 2D位姿估计4.4 身体部位分割4.5 深度估计4.6 表面法线估计 5 实验5.1 实现细节5.2 2D位姿估计5.3 身体部位分割5.4 深度估计5.5 表面法线估计5.6…...

【学术会议:中国厦门,为全球的计算机科学与管理科技研究者提供一个国际交流平台】第五届计算机科学与管理科技国际学术会议(ICCSMT 2024)
您的学术研究值得被更多人看到! 在这里,我为您提供精准的会议推荐,包括计算机科学、管理科技、信息系统、人工智能、供应链管理等领域的国际会议。高效的稿件录用流程和优质的检索服务将确保您的研究成果迅速传播。关注我,寻找与…...

RK3588/RK3588s运行yolov8达到27ms
前言 Hello,小伙伴们~~我最近做了一个比较有意思的东西,想起来也好久没有写博客了,就记录一下吧。希望和大家一起学习,一起进步! 我简单介绍一下我最近做的这个东西的经过哈~上个月在B站上看到了一个博主发了一条视频关…...
思路)
2024年华为杯中国研究生数学建模竞赛E题(高速公路应急车道紧急启用模型)思路
1. 统计四个观测点的交通流参数随时间的变化规律 思路: 从视频数据中提取流量、密度、速度等交通流参数。进行时间序列统计,分析其随时间的变化规律。通过数据可视化,帮助分析流量波动、车速变化等现象。主要步骤: 读取视频数据:利用提供的Python程序读取每个视频文件。提…...

np.random.seed设完又想用随机seed怎么办
Python 设完np random seed 之后又想不设这个seed让它random,怎么办? 在Python的NumPy库中,一旦你设置了随机种子(通过numpy.random.seed()函数),所有后续的随机操作都会基于这个种子生成可预测的结果。如…...

[数据结构]动态顺序表的实现与应用
文章目录 一、引言二、动态顺序表的基本概念三、动态顺序表的实现1、结构体定义2、初始化3、销毁4、扩容5、缩容5、打印6、增删查改 四、分析动态顺序表1、存储方式2、优点3、缺点 五、总结1、练习题2、源代码 一、引言 想象一下,你有一个箱子(静态顺序…...

Invalid Private Key, Not a valid string or uint8Array
报这种错误:一般在生成private key前面添加"0x"即可解决。我就是在私钥前面添加了"0x"解决了。 在学习web3时,使用助词生成的私钥,然后由私钥导出keystore就报错: ERROR Invalid Private Key, Not a valid …...

【Text2SQL】PET-SQL:在Spider基准测试中取得了SOTA
解读:PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency 这篇论文介绍了一个名为 PET-SQL 的文本到 SQL(Text-to-SQL)框架,旨在通过增强提示(prompt)和利用不同大型语言…...
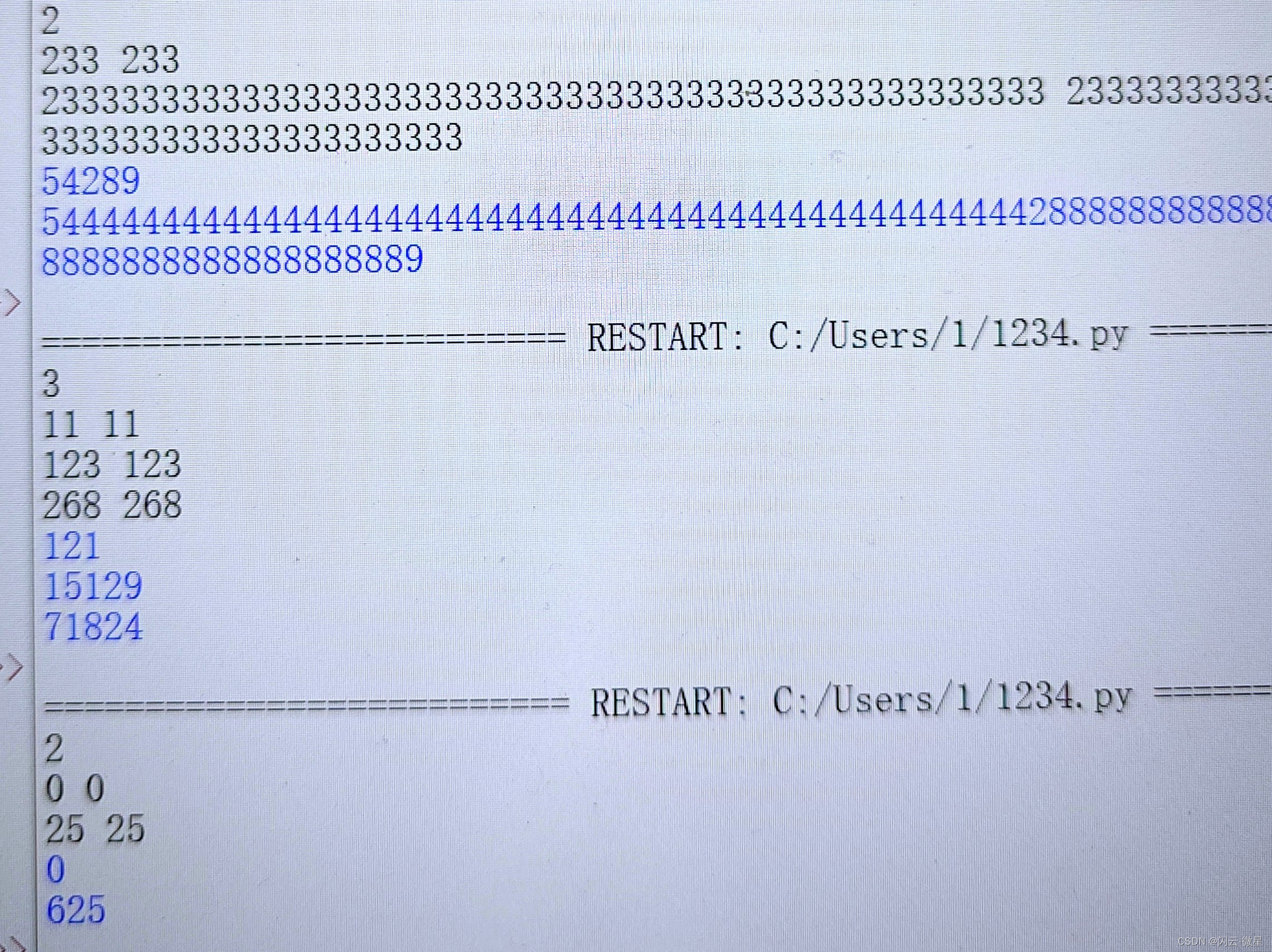
python-3n+1数链/233
一:3n1数链题目描述 在计算机科学上,有很多类问题是无法解决的,我们称之为不可解决问题。然而,在很多情况下我们并不知道哪一类问题可以解决,哪一类问题不可解决。现在我们就有这样一个问题,问题如下&#…...

vue2基础系列教程之v-model及面试高频问题
v-model是表单组件里面的核心知识点,这个指令给我们写表单业务带来了很大的方便。 元素标签上的 v-model 指令用于双向绑定数据,它是一个语法糖,可以用于代替 v-bind:value 和 input 例如:<input v-model"message" placeholder…...

【高分系列卫星简介——高分一号(GF-1)】
高分一号卫星(GF-1) 高分一号(GF-1)是中国高分辨率对地观测系统(简称“高分专项”)的第一颗卫星,具有里程碑式的意义。以下是对高分一号卫星的详细介绍: 一、基本信息 发射时间&…...

Python基于TensorFlow实现时间序列循环神经网络回归模型(LSTM时间序列回归算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 随着信息技术的发展和传感器设备的广泛应用,时间序列数据的产生量急剧增加。无论是股市价格…...

springboot实战学习(6)(用户模块的登录认证)(初识令牌)(JWT)
接着上篇博客学习。上篇博客是在基本完成用户模块的注册接口的开发以及注册时的参数合法性校验的基础上,基本完成用户模块的登录接口的主逻辑。具体往回看了解的链接如下。 springboot实战学习笔记(5)(用户登录接口的主逻辑)-CSDN博客文章浏览…...

二叉树的顺序存储和基本操作实现
写代码:定义顺序存储的二叉树(数组实现,树的结点从数组下标1开始存储) 基于上述定义,写一个函数 int findFather ( i ) ,返回结点 i 的父节点编号 基于上述定义,写一个函数 int leftChild ( i…...

python学习-10【模块】
1、认识模块 导入模块 使用 import 语句使用 from … import 语句 1、import modulename [as alias] modulename:表示要导入的模块名as alias:可选参数,为模块起的别名 2、from modulename import name modulename:模块名&#x…...

modbus调试助手/mqtt调试工具/超轻巧物联网组件/多线程实时采集/各种协议支持
一、前言说明 搞物联网开发很多年,用的最多的当属modbus协议,一个稳定好用的物联网组件是物联网平台持续运行多年的基石,所以这个物联网组件从一开始就定位于自研,为了满足各种场景的需求,当然最重要的一点就是大大提…...
数值计算 --- 平方根倒数快速算法(0x5f3759df,这是什么鬼!!!)
平方根倒数快速算法 --- 向Greg Walsh致敬! 1,牛顿拉夫逊 已知x,要计算,假设的值为a,则: ,(式1) 如果定义一个自变量为a的函数f(a): 则,令函数f(a)等于0的a就…...

迭代器和生成器的学习笔记
迭代器 Python 迭代器是一种对象,它实现了迭代协议,包括 __iter__() 和 __next__() 方法。迭代器可以让你在数据集中逐个访问元素,而无需关心数据结构的底层实现。与列表或其他集合相比,迭代器可以节省内存,因…...

ES5 在 Web 上的现状
最后一个支持 ES5 的浏览器 IE 11 在 2022 年被微软停止支持,那么今天 Web 上的 ES5 现状如何?在构建生产代码时,Web 开发者的最佳实践是什么? 本文将通过数据来回答这些问题,并基于这些数据为网站开发者和库作者提供一…...

人话学Python-循环语句
一:while语句 while语句的组成由判断条件和执行语句组成。当满足条件时会不断执行后续语句,然后再循环执行的语句结束之后再次回到条件判断,如此循环。 pos 0 ans 0 while pos < 6:ans pos * 4pos 1 print(ans)>>>84"&…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

2026年,本地精准营销高性价比服务商来袭,你还不了解一下?
在本地商业竞争日益激烈的2026年,实体店面临着诸多挑战,引流难、成本高、复购率低等问题困扰着众多商家。而中粤(广州)信息科技有限公司作为本地精准营销的高性价比服务商,正以其独特的优势和卓越的服务,为…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态
Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore LTSC-Add-MicrosoftStor…...

C语言预处理指令全解析
第六章 预处理命令在c语言中,所有# 开头的指令,被称为预处理指令。gcc 编译预处理 所有的预处理指令,都要在这步处理完汇编编译连接#include包含头文件。 全局变量的声明,函数的声明, 自定义构造类型声明, …...

OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS
OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重获新…...