descrTable常用方法
descrTable 为 R 包 compareGroups 的重要函数,有关该函数以及 compareGroups 包的详细内容见:R包compareGroups详细用法
加载包和数据
library(compareGroups)# 加载 REGICOR 数据(横断面,从不同年份纳入,每个变量有个label)
data(regicor)# 保留部分变量
regicor <- regicor[,c('id','age','sex','smoker','height','weight')]
1. formula、data、show.all、digits、show.p.overall、show.p.trend、show.n、digits.p、all.last
-
formula: 一个 “公式” 类的对象(或可以转换为该类的对象)。
~的右侧必须以加减法方式纳入包含项,或为.纳入所有变量。左侧必须包含分组变量的名称,或者可以留空(在这种情况下,将为整个样本提供描述性统计数据,并且不进行测试)。 -
data: 一个可选的数据框、列表或环境(或可通过
as.data.frame强制转换为数据框的对象),包含模型中的变量。如果在data中找不到变量,则这些变量会从environment(formula)中获取。 -
show.all: 逻辑值,指示是否显示 ‘[ALL]’ 列(未按组分层的所有数据)。如果定义了分组变量,则默认值为 FALSE;如果没有组,则为 FALSE。
-
digits: 一个整数向量,其组件数量与变量相同。设置每个变量的保留小数位数。如果其长度为 1,则对所有变量进行设置。每个组件指定要显示的有效小数位数。或者是一个命名向量,指定 ‘digits’ 应用于哪些变量(一个保留名称是 ‘.else’,定义其余变量的 ‘digits’);如果没有定义 ‘.else’ 变量,则对其余变量应用默认值。默认值为 NA,表示使用"适当"的小数位数(详细信息请参见说明文档)。
-
show.p.overall: 逻辑值,指示是否显示整体组显著性(‘p.overall’ 列)的 p 值。默认值为 TRUE。
-
show.p.trend: 逻辑值,指示是否显示 p-trend。如果组少于 3,则始终为 FALSE。如果缺少此参数且组数超过 2 且分组变量为有序因子,则显示 p-trend。默认情况下,p-trend 不显示;当组数超过 2 且分组变量为有序因子类时显示。
-
show.n: 逻辑值,指示是否在 ‘descr’ 表中显示每个变量分析的个体数量。默认值为 FALSE,当没有组时为 TRUE。
-
digits.p: 整数,指示所有 p 值显示的小数位数。默认值为 3。
-
all.last: 逻辑值。整个样本的描述性统计放在按组描述性统计之后。默认值为 FALSE,表示整体队列的描述性统计放在第一位。
descrTable( smoker ~ . -id, data = regicor, show.all = TRUE, digits = c(2,2,3,4), # 为不同变量设置保留位数show.p.trend = TRUE,show.p.overall = TRUE,show.n = TRUE,digits.p = 4)

descrTable( smoker ~ . -id, data = regicor, show.all = TRUE, all.last = TRUE # 最后一列显示 ALL)

2. subset、select
- selec: 一个包含与列变量相同数量组件的列表。如果列表长度为 1,则它会为所有变量重复。
selec的每个组件是一个表达式,该表达式将被评估以选择每个变量分析的个体。否则,将应用一个指定了变量的命名列表。.else是一个保留名称,用于定义其他变量的选择。如果没有定义.else变量,则对其他变量应用默认值。默认值为NA,即分析所有个体(不进行子集化)
descrTable( smoker ~ . - id,show.all = TRUE,show.n = TRUE,data = regicor,selec = list(sex = sex == "Male", # 只分析男性height = weight >70) # 只分析体重大于 70 人的身高)
# 可以看到 age、weight 的 N 还是不变,为 2233,2209
# sex 只分析了男性,身高只分析体重大于 70 人的

- subset: 可选的向量,指定用于计算过程的个体子集。它会应用于所有变量。
subset和selec在每个变量中以&的形式添加。
descrTable( smoker ~ . - id, show.all = TRUE,show.n = TRUE,data = regicor,subset = (sex == "Male" & weight > 70)) # 只分析同时满足的个体的,N只剩837

3. na.action
na.action: 一个函数,指示当数据包含 NA 时应该发生什么。默认值为 NULL,相当于 na.pass,即不采取任何行动。na.exclude 可以在希望移除所有在任何变量中有 NA 的个体时很有用。
descrTable( smoker ~ . - id, show.all = TRUE,show.n = TRUE,data = regicor,na.action = na.exclude)

4. method
method: 整数向量,包含与变量数量相同的组件。仅适用于连续变量(对于因子变量则被忽略)。默认值为1,可能的值为:
1- 强制分析为 “正态分布”;
2- 强制分析为 “连续非正态”;
3- 强制分析为 “分类”;
4- NA,进行 Shapiro-Wilks 正态性检验以决定正态或非正态。
descrTable( smoker ~ . - id, show.all = TRUE,show.n = TRUE,data = regicor,method = c(height = 2, weight =2))

descrTable( smoker ~ . - id, show.all = TRUE,show.n = TRUE,data = regicor,method = c(1,2,2,1))

5. hide
hide: 一个向量(或列表),包含与变量数量相同的整数或字符, 隐藏分类变量的第几类别。如果其长度为 1,则对所有变量进行回收。每个组件指定必须隐藏且不显示的类别(如果是字符,则为类别的文字名称;如果是整数,则为位置)。此参数仅适用于分类变量,对于连续变量将被忽略。如果为 NA,则显示所有类别。或者是一个命名向量(或命名列表),指定应用于哪些变量的 ‘hide’,其余变量应用默认值。默认值为 NA。
descrTable( smoker ~ . - id, show.all = TRUE,show.n = TRUE,data = regicor,hide = 2) # 隐藏第二类别

6. sd.type、q.type、extra.labels
-
sd.type: 一个整数,指示标准偏差的显示方式:1 - mean(SD),2 - mean ± SD。
-
q.type: 一个包含两个整数的向量。第一个组件指非正态变量显示的括号类型(1 - 方形,2 - 圆形),第二个组件指百分位数分隔符(1 - ‘;’,2 - ‘,’,3 - ‘-’)。默认值为 c(1, 1)。
-
extra.labels: 字符向量,包含 4 个组件,对应于附加到正常、非正态、分类或生存变量标签的关键标签。默认值为 NA,不附加任何额外关键字。如果设置为 c(“”,“”,“”,“”),则附加"Mean (SD)"、“Median [25th; 75th]”、“N (%)” 和 “Incidence at time=timemax”(请参阅 compareGroups 函数中的 timemax 参数)。
descrTable( smoker ~ . - id, show.all = TRUE,show.n = TRUE,data = regicor,sd.type = 2, # 更改描述 sd 的方式q.type = c(2,2), # 更改描述 quantile 的方式extra.labels = c("","","",""))
7. 修改变量的 label
修改变量的 label 以在表格中直接显示
attr(regicor$tcv,"label")<-"Cardiovascular"
8. 修改源代码,提升客制化能力
在R脚本中输入createTable(), 然后鼠标对着函数名,按下 ctrl和鼠标左键,可以看到这个函数的源代码。但可以发现源代码为只读模式,因为在安装R包时,R源代码就被编译为了二进制文件以提升代码运行速度。因此通常可以通过下载源代码并修改后重新编译安装或者新建同名函数覆盖
1、下载源代码修改后编译安装
# 下载 compareGroups 包的源代码
download.packages("compareGroups", destdir = ".", type = "source")# 解压源代码
# tar -xzf compareGroups_x.x.x.tar.gz# 修改源代码
# 找到原函数并修改# 重新安装
# 进入解压后的包目录
setwd("compareGroups")# 编译并安装修改后的包
system("R CMD build .")
install.packages("compareGroups_x.x.x.tar.gz", repos = NULL, type = "source")
github上createTable()函数在如图文件中

2、创建同名 function 覆盖源代码
# 获取 creaTable 函数的源代码
getAnywhere(createTable)
# 或
edit(compareGroups::createTable)# 将函数源代码复制出来
createTable <- function(...) {# 这里是函数的原始源代码# 修改你需要更改的部分
}
9. 修改结果tab
修改源代码可以一劳永逸,但如果不会也可以用代码修改结果
tab$descr <- apply(tab$descr, c(1, 2), function(x) gsub("±", "+-", x))
tab$descr <- apply(tab$descr, c(1, 2), function(x) gsub("\\[", "(", x))
相关文章:
descrTable常用方法
descrTable 为 R 包 compareGroups 的重要函数,有关该函数以及 compareGroups 包的详细内容见:R包compareGroups详细用法 加载包和数据 library(compareGroups)# 加载 REGICOR 数据(横断面,从不同年份纳入,每个变量有…...

回归预测 | Matlab实现ReliefF-XGBoost多变量回归预测
回归预测 | Matlab实现ReliefF-XGBoost多变量回归预测 目录 回归预测 | Matlab实现ReliefF-XGBoost多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.ReliefF-xgboost回归预测代码,对序列数据预测性能相对较高。首先通过ReleifF对输入特征计算权…...

年度最强悬疑美剧重磅回归,一集比一集上头
纽约的夜晚,平静被一声枪响打破,一场离奇的谋杀案悄然上演。《大楼里只有谋杀》正是围绕这样一桩扑朔迷离的案件展开的。三位主角,赛琳娜戈麦斯饰演的梅宝、史蒂夫马丁饰演的查尔斯、马丁肖特饰演的奥利弗,这些性格迥异的邻居因为…...

AI一点通: 简化大数据与深度学习工作流程, Apache Spark、PyTorch 和 Mosaic Streaming
在大数据和机器学习飞速发展的领域中,数据科学家和机器学习工程师经常面临的一个挑战是如何桥接像 Apache Spark 这样的强大数据处理引擎与 PyTorch 等深度学习框架。由于它们在架构上的固有差异,利用这两个系统的优势可能令人望而生畏。本博客介绍了 Mo…...

Python知识点:深入理解Python的模块与包管理
开篇,先说一个好消息,截止到2025年1月1日前,翻到文末找到我,赠送定制版的开题报告和任务书,先到先得!过期不候! 深入理解Python的模块与包管理 Python的模块和包是代码组织、复用和分发的基本…...

倒排索引(反向索引)
倒排索引(Inverted Index)是搜索引擎和数据库管理系统中常用的一种数据结构,用于快速检索文档集合中的文档。在全文搜索场景中,倒排索引是一种非常高效的手段,因为它能够快速定位到包含特定关键词的所有文档。 1、基本…...

openCV的python频率域滤波
在OpenCV中实现频率域滤波通常涉及到傅里叶变换(Fourier Transform)和其逆变换(Inverse Fourier Transform)。傅里叶变换是一种将图像从空间域转换到频率域的数学工具,这使得我们可以更容易地在图像的频域内进行操作,如高通滤波、低通滤波等。 下面,我将提供一个使用Py…...

探索视频美颜SDK与直播美颜工具的开发实践方案
直播平台的不断发展,让开发出性能优异、效果自然的美颜技术,成为了技术团队必须面对的重要挑战。本篇文章,小编将深入讲解视频美颜SDK与直播美颜工具的开发实践方案。 一、视频美颜SDK的核心功能 视频美颜SDK是视频处理中的核心组件…...
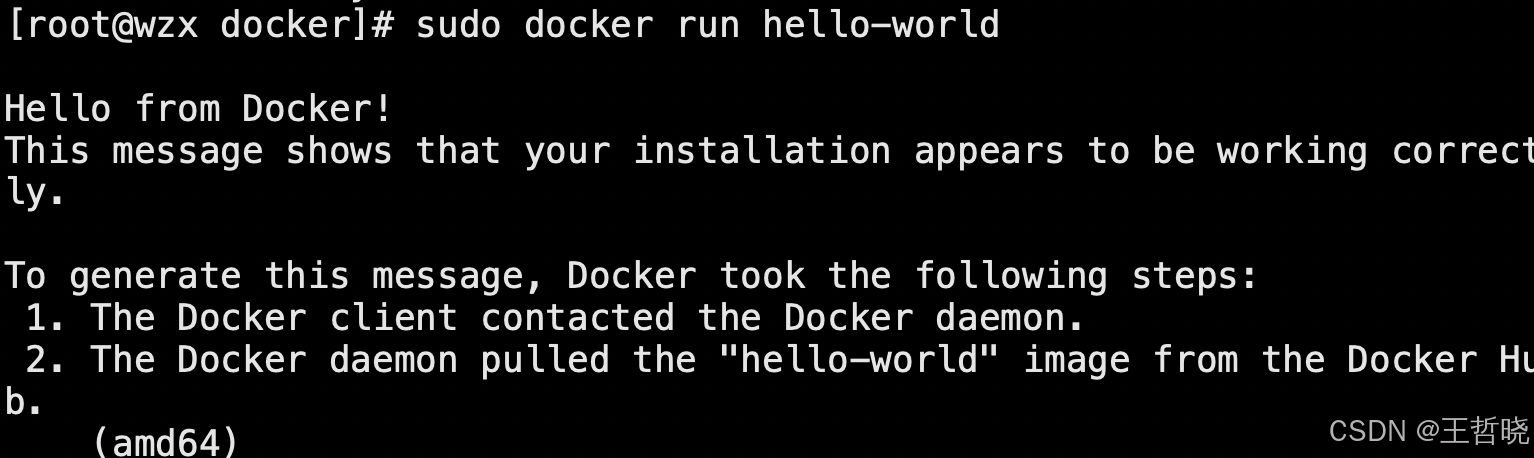
Linux通过yum安装Docker
目录 一、安装环境 1.1. 旧的docker包卸载 1.2. 安装常规环境包 1.3. 设置存储库 二、安装Docker社区版 三、解决拉取镜像失败 3.1. 创建文件目录/etc/docker 3.2. 写入镜像配置 https://docs.docker.com/engine/install/centos/ 检测操作系统版本,我操作的…...

面部表情数据集合集——需要的点进来
文章目录 1、基本介绍2、每个数据集介绍2.1、FER2013(已预处理)2.2、FERPLUS(已预处理)2.3、RAF2.4、CK2.5、AffectNet2.6、MMAFEDB 3、获取方式 1、基本介绍 收集并整理了面部表情识别(Facial Emotion Recognition&am…...

AI学习指南深度学习篇-Adagrad的Python实践
AI学习指南深度学习篇-Adagrad的Python实践 在深度学习领域,优化算法是模型训练过程中至关重要的一环。Adagrad作为一种自适应学习率优化算法,在处理稀疏梯度和非凸优化问题时表现优异。本篇博客将使用Python中的深度学习库TensorFlow演示如何使用Adagr…...

vue2使用npm引入依赖(例如axios),报错Module parse failed: Unexpected token解决方案
报错情况 Module parse failed: Unexpected token (5:2) You may need an appropriate loader to handle this file type. 原因 因为我们npm install时默认都是下载最新版本,然后个别依赖的版本太新,vue2他受不起这个福分。 解决方法 先去package.js…...
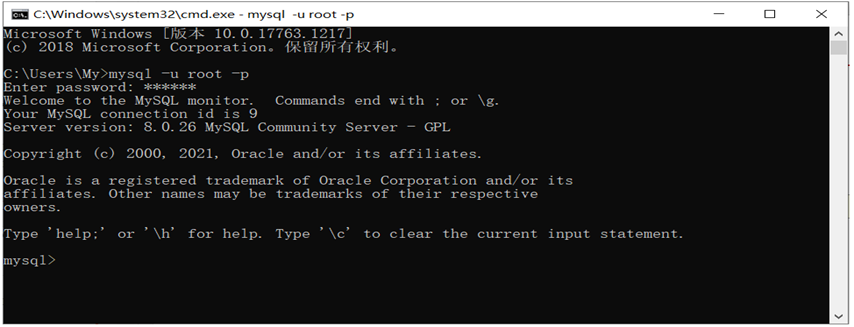
MySQl篇(基本介绍)(持续更新迭代)
目录 一、为什么要使用数据库 1. 以前存储数据的方式 2. 什么是数据库 3. 采用的数据库的好处 4. 如何理解数据库、数据库管理系统、SQL 5. 如何理解数据是有组织的存储 6. 现在的数据库 二、关系型数据系统 1. 什么是关系型数据库 2. 关系型数据库特点 3. 关系型数据…...

Java开发与实现教学管理系统动态网站
博主介绍:专注于Java .net php phython 小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不然下次找不到哟 我的博客空间发布了1000毕设题目 方便大家学习使用 感兴趣的可以…...

麒麟操作系统 MySQL 主从搭建
MySQL rpm64 架构搭建主从 文章目录 1.检查操作系统2.配置基础环境3.下载软件并安装4. 服务初始化5 主从搭建5.1 主节点配置(192.168.31.82)5.2 从节点配置(192.168.31.83)5.3 从节点配置(192.168.31.84)5.4 节点都重启5.5 在主机上建立帐户并授权slave5.6 salve 来同步master…...

OSSEC搭建与环境配置Ubuntu
尝试使用Ubuntu配置了OSSEC,碰见很多问题并解决了,发表博客让后来者不要踩那么多坑 环境 : server :Ubuntu22.04 64位 内存4GB 处理器4 硬盘60G agent: 1.Windows11 64位 2.Ubuntu22.04 64位 服务端配置 一、配置安装依赖项&…...

【RabbitMQ】消息分发、事务
消息分发 概念 RabbitMQ队列拥有多个消费者时,队列会把收到的消息分派给不同的消费者。每条消息只会发送给订阅该队列订阅列表里的一个消费者。这种方式非常适合扩展,如果现在负载加重,那么只需要创建更多的消费者来消费处理消息即可。 默…...

mysql mha高可用集群搭建
文章目录 mha集群搭建主从从部署基本环境准备安装mysql主从配置 mha部署故障修复 搭建完成 mha集群搭建 在 MySQL 高可用架构中,MHA(Master High Availability)通常采用一主多从的架构。 MHA 可以提供主从复制架构的自动 master failover 功…...

如何解决“json schema validation error ”错误? -- HarmonyOS自学6
一. 问题描述 DevEco Studio工程关闭后,再重新打开时,出现了如下错误提示: json schema validation error 原因: index.visual或其他visual文件中的left等字段的值为负数时,不能以”-0.x“开头,否则就会…...

基于Jeecg-boot开发系统--后端篇
背景 Jeecg-boot是一个后台管理系统,其提供能很多基础的功能,我希望在不修改jeecg-boot代码的前提下增加自己的功能。经过几天的折腾终于搞定了。 首先是基于jeecg-boot微服务的方式来扩展的,jeecg-boot微服务本身的搭建过程就不讲了&#x…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...