在SpringBoot项目中利用Redission实现布隆过滤器(布隆过滤器的应用场景、布隆过滤器误判的情况、与位图相关的操作)
文章目录
- 1. 布隆过滤器的应用场景
- 2. 在SpringBoot项目利用Redission实现布隆过滤器
- 3. 布隆过滤器误判的情况
- 4. 与位图相关的操作
- 5. 可能遇到的问题(Redission是如何记录布隆过滤器的配置参数的)
- 5.1 问题产生的原因
- 5.2 解决方案
- 5.2.1 方案一:删除Redis中与布隆过滤器相关的key
- 5.2.2 方案二:创建一个新的布隆过滤器
对 Redission 不了解的同学,可以参考我的另一篇博文: 在SpringBoot项目中使用Redission实现分布式锁(什么是Redission、为什么要使用分布式锁、分布式锁的应用场景、Redission的读锁和写锁、可重入锁的原理
至于什么是布隆过滤器,可以参考我的另一篇博文:Redis缓存面试三兄弟:缓存穿透、缓存雪崩、缓存击穿 的 1.3.3 方案三:使用布隆过滤器 部分
1. 布隆过滤器的应用场景
布隆过滤器(Bloom Filter)是一种空间效率极高的概率数据结构,用于测试一个元素是否属于集合
布隆过滤器可能会产生误报(一个元素不属于集合,但布隆过滤器判断元素属于该集合),但绝不会漏报(一个元素属于集合,但布隆过滤器判断元素不属于该集合)
布隆过滤器适用于以下一些应用场景:
- 网络爬虫:避免爬取已经访问过的URL,减少重复工作
- 防止缓存穿透:在缓存系统中,使用布隆过滤器检查请求的数据是否可能存在,以避免对不存在的数据进行数据库查询
- 数据库索引:用于快速判断一个记录是否存在于数据库中,减少不必要的磁盘I/O操作
- 邮件系统:过滤垃圾邮件,通过布隆过滤器快速判断一个邮件地址是否在垃圾邮件发送者列表中
- 网络安全:用于检测和防御DDoS攻击,通过布隆过滤器识别和过滤恶意流量
- 分布式系统:在分布式环境中,布隆过滤器可以用来检查数据是否已经被处理,以避免重复处理
- 文件系统:在文件检索系统中,快速判断一个文件是否存在于文件系统中,减少文件系统的访问次数
- 大数据集去重:在处理大规模数据集时,使用布隆过滤器进行高效去重
- 网络服务:检查客户端请求的内容是否已经被服务器处理过,从而避免重复处理
布隆过滤器的优点在于它的空间效率和查询速度,布隆过滤器在处理大量数据时非常有用
2. 在SpringBoot项目利用Redission实现布隆过滤器
如果不知道如何在 SpringBoot 项目项目中接入 Redission,可以参考我的另一篇博文:在SpringBoot项目中使用Redission实现分布式锁(什么是Redission、为什么要使用分布式锁、分布式锁的应用场景、Redission的读锁和写锁、可重入锁的原理)
编写一个测试类,测试布隆过滤器的过滤效果
import org.junit.jupiter.api.Test;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class BloomFilterTests {@Autowiredprivate RedissonClient redissionClient;@Testpublic void testBooleanFilter() {try {String filterName = "myBloomFilter";long expectedInsertions = 100000L; // 预期元素数量double falseProbability = 0.01; // 容错率,也就是误报率// 创建布隆过滤器,参数分别为:过滤器名称,预期元素数量,误差率RBloomFilter<Object> bloomFilter = redissionClient.getBloomFilter(filterName);bloomFilter.tryInit(expectedInsertions, falseProbability);// 添加元素for (int i = 1; i <= 50; i++) {bloomFilter.add(String.format("element%02d", i));}// 检查元素是否存在System.out.println("bloomFilter.contains(\"element01\") = " + bloomFilter.contains("element01"));System.out.println("bloomFilter.contains(\"element51\") = " + bloomFilter.contains("element51"));} finally {// 关闭 Redission 客户端redissionClient.shutdown();}}}
输出结果如下

3. 布隆过滤器误判的情况
我们将预期元素数量改为 5 个,再次对布隆过滤器进行测试
import org.junit.jupiter.api.Test;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class BloomFilterTests {@Autowiredprivate RedissonClient redissionClient;@Testpublic void testBooleanFilter() {try {String filterName = "myBloomFilter";long expectedInsertions = 5L; // 预期元素数量double falseProbability = 0.01; // 容错率,也就是误报率// 创建布隆过滤器,参数分别为:过滤器名称,预期元素数量,误差率RBloomFilter<Object> bloomFilter = redissionClient.getBloomFilter(filterName);bloomFilter.tryInit(expectedInsertions, falseProbability);// 添加元素for (int i = 1; i <= 50; i++) {bloomFilter.add(String.format("element%02d", i));}// 检查元素是否存在System.out.println("bloomFilter.contains(\"element01\") = " + bloomFilter.contains("element01"));System.out.println("bloomFilter.contains(\"element51\") = " + bloomFilter.contains("element51"));} finally {// 关闭 Redission 客户端redissionClient.shutdown();}}}
运行结果如下

可以看到,布隆过滤器出现了误判的情况(element51 不在集合中,但布隆过滤器判断 element51 在集合中)
我们查看布隆过滤器的配置(布隆过滤器中各个参数的含义可参考本文的 布隆过滤器中各个参数的含义 章节)

可以发现,布隆过滤器底层的位图的大小为 47,布隆过滤器在处理每个元素时要应用的哈希函数的数量为 7,也就是说,每个元素会映射到位图的 7 个位置上
我们往布隆过滤器中插入了 50 个元素,每个元素映射到位图的 7 个位置上,非常容易发生哈希冲突的情况,从而导致布隆过滤器误判
我们删除布隆过滤器后,重写运行测试代码,查看位图中 1 的数量

redissionClient.getBitSet(filterName).cardinality()

可以发现,位图的大小为 47,位图中 1 的数量也是 47,也就是说,位图中所有位置都是 1,也就意味着此时布隆过滤器已经完全失去了过滤作用
所以说,在初始化布隆过滤器时,我们需要十分注意 预期元素数量 和 误判率 参数,否则布隆过滤器的过滤效果将会大打折扣,甚至失效
4. 与位图相关的操作
Redission 提供的 RBloomFilter 类用于布隆过滤,而 RBitSet类 用于常规的位图操作
使用 RBitSet 类可以对各种位图进行各种操作,如设置位、清除位、检查位的状态等

@Test
public void testBitmap() {try {String filterName = "myBloomFilter";RBitSet bitSet = redissionClient.getBitSet(filterName);bitSet.set(0, true); // 设置第0位为1bitSet.set(1, false); // 设置第1位为0bitSet.clear(0); // 清除第0位boolean isSet = bitSet.get(0); // 检查第0位是否为1System.out.println("isSet = " + isSet);long count = bitSet.cardinality(); // 返回位图中1的数量System.out.println("count = " + count);} finally {// 关闭 Redission 客户端redissionClient.shutdown();}
}
5. 可能遇到的问题(Redission是如何记录布隆过滤器的配置参数的)

org.redisson.client.RedisException: ERR Error running script (call to f_a7ac8cff901d5cafb8de37987dfbe1fc11f00eb4): @user_script:1: user_script:1: Bloom filter config has been changed . channel: [id: 0xe1fd1f6a, L:/127.0.0.1:3098 - R:127.0.0.1/127.0.0.1:6379] command: (EVAL), promise: java.util.concurrent.CompletableFuture@52a215fa[Not completed, 1 dependents], params: [local size = redis.call(‘hget’, KEYS[1], ‘size’);local hashIterations = redis.call(‘hget’, KEYS[1], ‘hashIterations’);assert(size == ARGV[1] and hashIterations == ARGV[2], ‘Bloom filter config has been changed’)local k = 0;local c = 0;for i = 4, #ARGV, 1 do local r = redis.call(‘setbit’, KEYS[2], ARGV[i], 1); if r == 0 then k = k + 1;end; if ((i - 4) + 1) % ARGV[3] == 0 then if k > 0 then c = c + 1;end; k = 0; end; end; return c;, 2, {myBloomFilter}:config, myBloomFilter, 47, 7, 7, 6, 14, 20, …]
5.1 问题产生的原因
之所以会报错,是因为布隆过滤器的配置参数被篡改了
那布隆过滤器的配置参数存放在哪里呢,当然是存在 Redis 里面,Redis 中会有一个与布隆过滤器配置参数相关的 key,这个 key 使用的是 Hash 结构


各个参数的含义:
- size:布隆过滤器位图的大小
- hashIterations:布隆过滤器在处理每个元素时要应用的哈希函数的数量
- falseProbability:布隆过滤器的误报率,即错误地判断一个元素存在于集合中的概率
- expectedInsertions:预期将要插入布隆过滤器的元素数量
5.2 解决方案
5.2.1 方案一:删除Redis中与布隆过滤器相关的key
直接删除 Redis 中与布隆过滤器相关的 key,下次再操作布隆过滤器时会重新创建布隆过滤器

5.2.2 方案二:创建一个新的布隆过滤器
直接更改布隆过滤器的名字,创建一个新的布隆过滤器

相关文章:
在SpringBoot项目中利用Redission实现布隆过滤器(布隆过滤器的应用场景、布隆过滤器误判的情况、与位图相关的操作)
文章目录 1. 布隆过滤器的应用场景2. 在SpringBoot项目利用Redission实现布隆过滤器3. 布隆过滤器误判的情况4. 与位图相关的操作5. 可能遇到的问题(Redission是如何记录布隆过滤器的配置参数的)5.1 问题产生的原因5.2 解决方案5.2.1 方案一:…...

【prefect】python任务调度工具 Prefect | 可视化任务工具 | Python自动化的终极武器 | 高效数据管道管理
一、产品介绍 1、官方 Github https://github.com/PrefectHQ/prefect 2、官方文档 https://docs.prefect.io/3.0/get-started/index 3、Pgsql说明 正确的python链接pgsql如下: import psycopg2 from sqlalchemy import create_enginedef connect_with_psycopg2(…...

蓝禾,汤臣倍健,三七互娱,得物,顺丰,快手,游卡,oppo,康冠科技,途游游戏,埃科光电25秋招内推
蓝禾,汤臣倍健,三七互娱,得物,顺丰,快手,游卡,oppo,康冠科技,途游游戏,埃科光电25秋招内推 ①蓝禾 【岗位】国内/国际电商运营,设计,…...

【面向对象】设计模式分类
java中设计模式共23种,根据使用场景可分为创建型模式、结构型模式、行为型模式。 创建型: 如何创建对象。 单例模式:保证一个类在一个程序中只能创建一个对象。例如windows任务管理器窗口只需要创建一个。单例模式只创建一个对象࿰…...
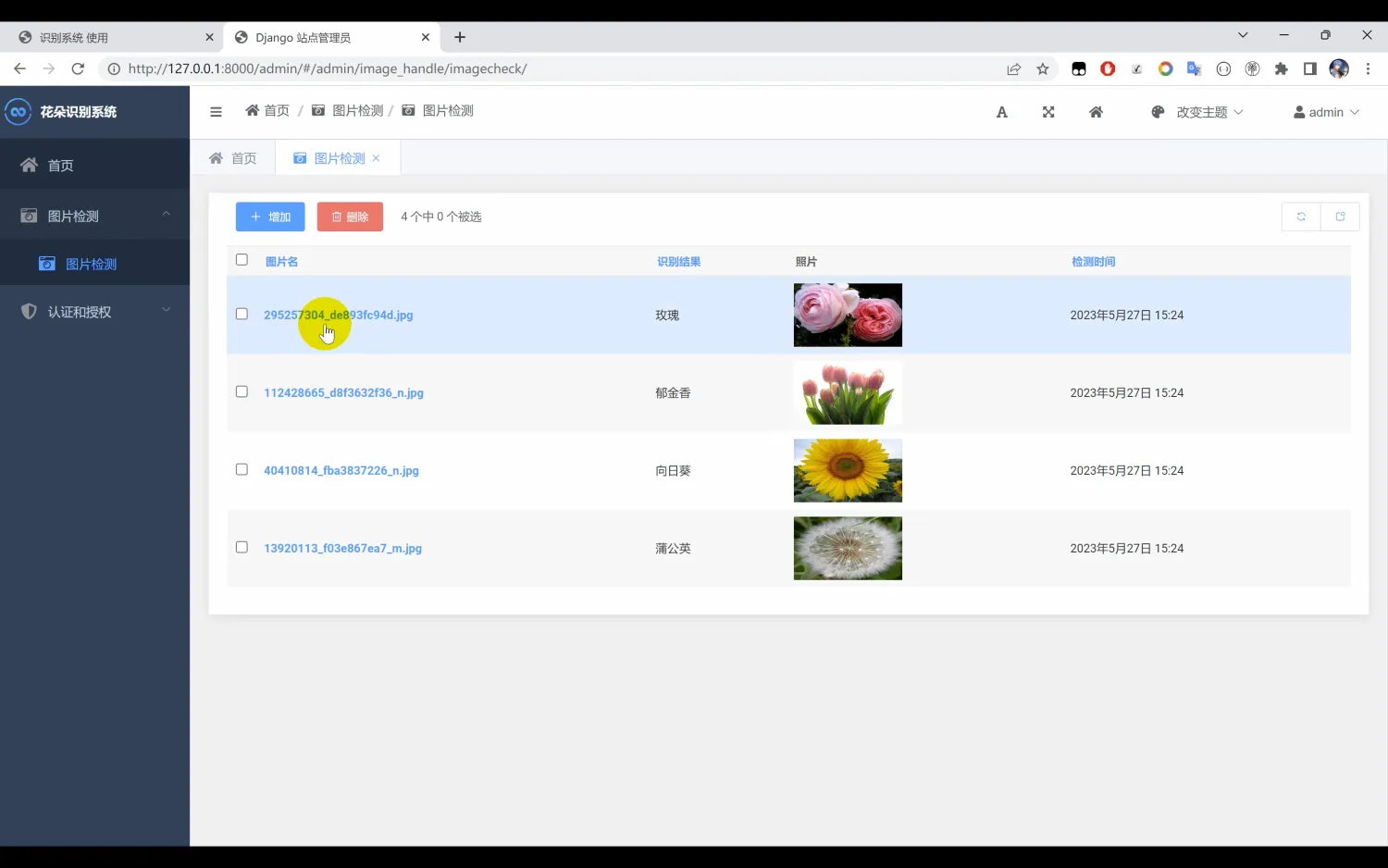
花朵识别系统Python+卷积神经网络算法+人工智能+深度学习+计算机课设项目+TensorFlow+模型训练
一、介绍 花朵识别系统。本系统采用Python作为主要编程语言,基于TensorFlow搭建ResNet50卷积神经网络算法模型,并基于前期收集到的5种常见的花朵数据集(向日葵、玫瑰、蒲公英、郁金香、菊花)进行处理后进行模型训练,最…...

中泰免签,准备去泰国旅游了吗?《泰语翻译通》app支持文本翻译和语音识别翻译,解放双手对着说话就能翻译。
泰国是很多中国游客的热门选择,现在去泰国旅游更方便了,因为泰国对中国免签了。如果你打算去泰国,那么下载一个好用的泰语翻译软件是很有必要的。 简单好用的翻译工具 《泰语翻译通》App就是为泰国旅游设计的,它翻译准确&#x…...

C++/Qt 集成 AutoHotkey
C/Qt 集成 AutoHotkey 前言AutoHotkey 介绍 方案一:子进程启动编写AutoHotkey脚本准备 AutoHotkey 运行环境编写 C/Qt 代码 方案二:显式动态链接方案探索编译动态链接库集成到C工程关于AutoHotkeyDll.dll中的函数原型 总结 前言 上一篇介绍了AutoHotkey…...
OpenMV学习第一步安装IDE_2024.09.20
用360浏览器访问星瞳科技官网,一直提示访问不了。后面换了IE浏览器就可以访问。第一个坑。...

RK3568平台(基础篇)万用表的使用
一.万用表的通断判断 万用表两个笔头的插法:黑笔头是插在COM的孔里面,红色笔头可以插在其他的三个孔里面,20A和mA分别用来测电流,另外一个孔可以用来测其他(电压 电阻)。 以下这个三角符号(像wifi一样的)可以用来测通断: 使用万用表的红笔和黑笔进行短接,这时候两端…...

more、less 命令:阅读文本
一、命令简介 more 和 less 都是用于查看文本文件内容的命令,但它们在显示方式和功能上有一些区别。 简单的说 less 是 more 的升级版:增加了搜索、跳转等功能。所以优先使用 less,可以不用 more 了。 二、命令参数 基…...

【笔记】1.3 塑性变形
一、塑性变形的方式 DDWs(Dislocation-Dipole Walls,位错偶极墙):指由两个位错构成的结构,它们以一种特定的方式排列在一起,形成一个稳定的结构单元。 DTs(Dislocation Tangles,位错…...
Java集合(三)
目录 Java集合(三) Java双列集合体系介绍 HashMap类 HashMap类介绍 HashMap类常用方法 HashMap类元素遍历 LinkedHashMap类 LinkedHashMap类介绍 LinkedHashMap类常用方法 LinkedHashMap类元素遍历 Map接口自定义类型去重的方式 Set接口和Ma…...

python:给1个整数,你怎么判断是否等于2的幂次方?
最近在csdn上刷到一个比较简单的题目,题目要求不使用循环和递归来实现检查1个整数是否等于2的幂次方,题目如下: 题目的答案如下: def isPowerofTwo(n):z bin(n)[2:]print(bin(n))if z[0] ! 1:return Falsefor i in z[1:]:if i !…...

Centos7安装gitlab-ce(rpm安装方式)
本章教程,主要介绍如何在Centos7安装gitlab-ce。 一、安装基础环境 安装gitlab-ce之前,我们需要安装一下jdk版本。 sudo yum install java-11-openjdk-devel二、下载安装包 这里我们下载的是rpm包。更多gitlab-ce版本可以在这里查看:https://…...

Flutter 获取手机连接的Wifi信息
测试版本 Flutter:3.7.6Dart:2.19.3 network_info_plus: 4.0.1 前言 我在做设备配网的时候,需要选择配网的WiFi。用下拉选择框展示WiFi列表。现在有个需求:默认展示的设备为手机连接的wifi。要实现这个需求只要能够获取到手机连接的wifi信息…...

誉龙视音频 Third/TimeSyn 远程命令执行复现
0x01 漏洞描述: 誉龙公司定位为系统级的移动视音频记录解决方案提供商,凭借其深厚的行业经验,坚持自主研发,匠心打造记录仪领域行业生态,提供开放式的记录仪APK、GB28181 SDK、国网B协议、管理平台软件OEM。誉龙视音频…...

ATMEGA328P芯片引脚介绍
1.AVCC AVCC是ATmega328P芯片的模拟电源引脚。 AVCC引脚的定义 模拟电源引脚:AVCC(Analog Voltage Common)是ATmega328P微控制器中的模拟电源引脚,用于为模拟电路部分提供稳定的电源。功能描述:AVCC通常连接到一个干…...

现代前端构建工具对比:Vue CLI、Webpack 和 Vite
一、引言🌟 在现代前端开发中,选择合适的构建工具对于提高项目的效率和可维护性至关重要。🛠️ Vue CLI、📦 Webpack 和 🚀 Vite 是目前最流行的三个构建工具,它们各自具有独特的优势和适用场景。本文将深…...

代码随想录算法训练营第三九天| 198.打家劫舍 213.打家劫舍II 337.打家劫舍 III
今日任务 198.打家劫舍 213.打家劫舍II 337.打家劫舍 III 198.打家劫舍 题目链接: . - 力扣(LeetCode) class Solution {public int rob(int[] nums) {int[] dp new int[nums.length];if (nums.length 1) return nums[0];if (nums.lengt…...
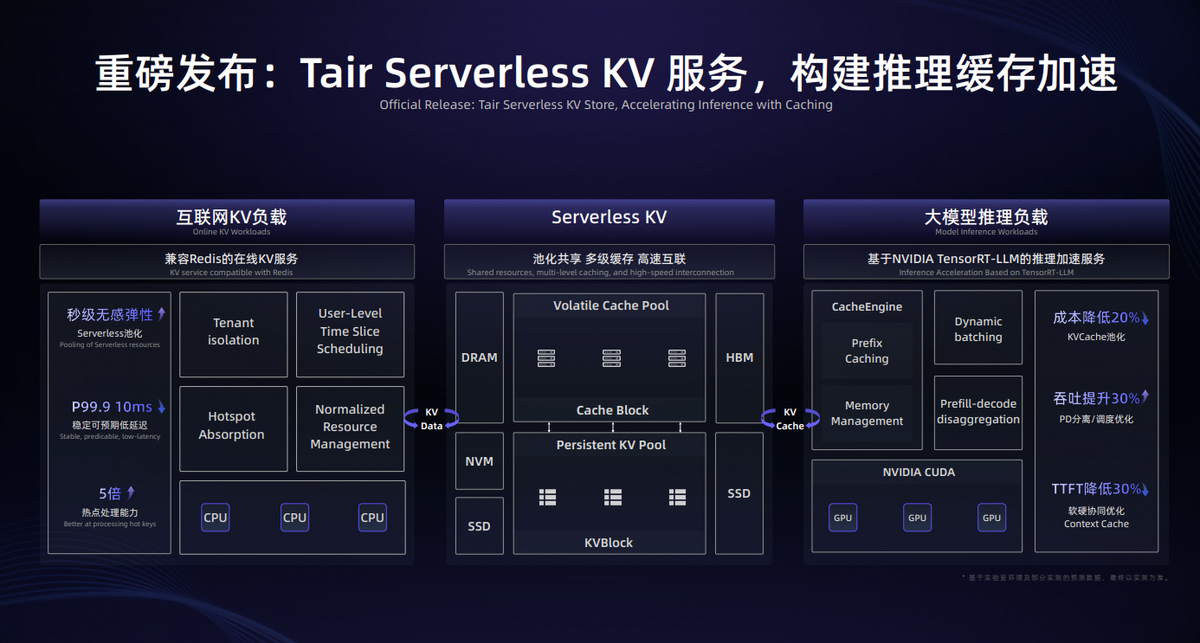
阿里云AI基础设施全面升级,模型算力利用率提升超20%
来源首席数智官 9月20日,2024云栖大会现场,阿里云全面展示了全新升级后的AI Infra系列产品及能力。通过全栈优化,阿里云打造出一套稳定和高效的AI基础设施,连续训练有效时长大于99%,模型算力利用率提升20%以上。 “AI…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

CANN-昇腾NPU-RAG推理-检索增强生成怎么部署
RAG(Retrieval-Augmented Generation)是 LLM 知识库的组合:先检索相关文档,再让 LLM 基于文档回答。昇腾NPU 上部署 RAG 需要两个组件:Embedding 模型(做向量检索)和 LLM(做生成&am…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...

AutoPentest:面向红队的渗透测试决策引擎架构解析
1. 这不是又一个“自动化扫描器”,而是一套能替你做决策的渗透测试工作流引擎AutoPentest这个名字,第一眼容易让人联想到Nmap加个for循环、或者Burp Suite里点几下Intruder——但实际用过的人很快会意识到:它根本不在同一个维度上。我第一次在…...

基于Meshtastic构建LoRa Mesh网络:从硬件自制到传感器集成实战
1. 项目概述:构建一个灵活且易用的LoRa Mesh网络 如果你对物联网、远程传感或者去中心化通信网络感兴趣,那么LoRa技术一定不会陌生。它以其超低功耗、超远距离和强大的抗干扰能力,成为了构建广域传感网络的理想选择。然而,传统的…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...