【MySQ】在MySQL里with 的用法
在MySQL中,WITH语句通常与公用表表达式(Common Table Expressions,简称CTE)一起使用。CTE是一种临时的结果集,类似于视图或子查询,它们在查询中被定义并且可以在一个或多个SELECT、INSERT、UPDATE或DELETE语句中被引用。CTE通常用于简化复杂的查询,特别是那些包含多个子查询的查询。它们可以帮助提高查询的可读性和维护性。在MySQL数据库中,WITH语句是一种用于在查询中临时定义一个可见的命名结果集的语法。它通常与SELECT语句一起使用,可以简化复杂查询,提高查询性能,以及提高查询语句的可读性。
1.with 语句的语法
在MySQL中,WITH语句的语法如下所示:
WITHcte_name1 (column_name1, column_name2, ...) AS (SELECT column_name1, column_name2, ...FROM table_nameWHERE condition),cte_name2 (column_name1, column_name2, ...) AS (SELECT column_name1, column_name2, ...FROM table_nameWHERE condition)
SELECT column_name1, column_name2, ...
FROM cte_name1
JOIN cte_name2
WHERE condition;
SQL
其中,WITH关键字后的部分定义了一个或多个通用表表达式(CTE)。
每个CTE由一个名称(cte_name)
和一个查询(SELECT语句)组成。查询可以包含任意数目的列,也可以包含表连接、聚合函数等。CTE定义后,可以在接下来的SELECT语句中引用它们的名称,并进行其他查询操作,如JOIN、WHERE等。
2.with 语句的应用场景
with 语句的主要优势在于可以避免多次编写相同的子查询,提高查询性能和可读性。通过使用with语句,可以将复杂的查询逻辑分解为多个可见的命名结果集,使查询更加直观清晰。下面是一些with语句的常见应用场景:
2.1 递归查询
with语句非常适合处理递归查询。递归查询是指查询结果集包含对同一表的多次查询,每次查询都基于上一次查询的结果。在with语句中,可以使用递归的方式定义一个CTE,并在接下来的查询中引用它。
示例代码:
WITH RECURSIVE cte_name (column_name1, column_name2, ...) AS (-- 初始查询SELECT column_name1, column_name2, ...FROM table_nameWHERE conditionUNION ALL-- 递归查询SELECT column_name1, column_name2, ...FROM cte_nameWHERE condition
)
SELECT * FROM cte_name;
2.2 数据转换和处理
使用with语句,可以在查询中先对数据进行转换和处理,然后再进行其他操作。这样可以提高查询的可读性和性能。
示例代码:
WITH cte_name (column_name1, column_name2, ...) AS (SELECT column_name1 * 2, column_name2, ...FROM table_nameWHERE condition
)
SELECT SUM(column_name1), column_name2
FROM cte_name
GROUP BY column_name2;
2.3 复杂查询简化
当查询逻辑较为复杂时,使用with语句可以将查询分解为多个可见的结果集,使查询逻辑更加清晰。这样可以提高查询的可读性和维护性。
示例代码:
WITHsales_total (product_name, total_quantity) AS (SELECT product_name, SUM(quantity)FROM salesGROUP BY product_name),sales_average (product_name, avg_quantity) AS (SELECT product_name, AVG(quantity)FROM salesGROUP BY product_name)
SELECT *
FROM sales_total
JOIN sales_average USING (product_name);
3. 注意事项和限制
在使用with语句时,需要注意以下几个方面:
* WITH语句中的每个CTE都只能在接下来的查询中使用一次,并且必须通过SELECT语句引用。
* CTE的名称在查询中是可见的,但不能在查询外部使用。
* WITH语句中的查询可以包含多个CTE,它们之间可以相互引用。
* WITH语句必须使用逗号进行分隔,最后一个CTE后不需要逗号。
* WITH语句中的CTE可以使用常规的查询语法,包括JOIN 、WHERE、GROUP BY等。
* MySQL对于WITH语句的支持并不是很完善,一些高级特性可能无法使用。
4.with语句的示例
为了更好地理解和演示WITH语句的用法,下面给出一个简单的示例。假设有一个员工表employees,包含员工的ID、姓名、部门ID和工资等信息。同时还有一个部门表
departments,包含部门的ID和名称等信息。现在需要查询每个部门的平均工资和总工资,并按部门ID进行排序。
示例代码:
WITHavg_salary (department_id, average_salary) AS (SELECT department_id, AVG(salary)FROM employeesGROUP BY department_id),total_salary (department_id, total_salary) AS (SELECT department_id, SUM(salary)FROM employeesGROUP BY department_id)
SELECT d.department_id, d.department_name, avg_salary.average_salary, total_salary.total_salary
FROM departments d
JOIN avg_salary ON d.department_id = avg_salary.department_id
JOIN total_salary ON d.department_id = total_salary.department_id
ORDER BY d.department_id;
以上示例中,首先通过两个CTE分别计算了每个部门的平均工资和总工资。然后使用
JOIN语句将部门表和这两个CTE进行连接,并按部门ID进行排序。
5. 总结
本文详细介绍了MySQL中WITH语句的语法、应用场景、注意事项和限制。WITH语句可以提高查询的可读性和性能,尤其适用于处理递归查询、数据转换和处理以及简化复杂查询等情况。在使用WITH语句时,需要注意每个CTE的命名和查询的语法,并理解其局限性。
6. with 语句示例
在MySQL中,`WITH`语句通常与公用表表达式(Common Table Expressions,简称CTE)一起使用。CTE是一种临时的结果集,类似于视图或子查询,它们在查询中被定义并且可以在一个或多个SELECT、INSERT、UPDATE或DELETE语句中被引用。CTE通常用于简化复杂的查询,特别是那些包含多个子查询的查询。它们可以帮助提高查询的可读性和维护性。
以下是WITH语句的基本语法:
WITH cte_name (column1, column2, ...)
AS
(-- CTE的定义,可以是任何SELECT语句SELECT column1, column2, ...FROM ...
)
SELECT *
FROM cte_name;
例子1:简单的CTE
WITH EmployeeSalaries AS (SELECTemployee_id,salary,department_idFROMemployees
)
SELECTemployee_id,salary
FROMEmployeeSalaries
WHEREdepartment_id = 10;
在这个例子中,`EmployeeSalaries`是一个CTE,它从`employees`表中选择了员工ID、薪水和部门ID。然后,可以在随后的`SELECT`语句中引用这个CTE来获取特定部门的员工薪水信息。
例子2:使用CTE进行分区查询
WITH RankedEmployees AS (SELECTemployee_id,salary,DEPARTMENT_ID,RANK() OVER (PARTITION BY DEPARTMENT_ID ORDER BY salary DESC) AS salary_rankFROMemployees
)
SELECTemployee_id,salary,salary_rank
FROMRankedEmployees
WHEREsalary_rank <= 3;
在这个例子中,`RankedEmployees`是一个CTE,它使用窗口函数`RANK()`来为每个部门的员工薪水进行排名。然后,可以从这个CTE中选择每个部门薪水排名前三的员工。
例子3:递归CTE
CTE也可以是递归的,这意味着CTE可以引用自身。这在处理层次或递归数据结构时非常有用,比如组织架构、物料清单等。
WITH RECURSIVE EmployeeHierarchy AS (SELECTemployee_id,manager_id,employee_nameFROMemployeesWHEREmanager_id IS NULLUNION ALLSELECTe.employee_id,e.manager_id,e.employee_nameFROMemployees eINNER JOIN EmployeeHierarchy eh ON eh.employee_id = e.manager_id
)
SELECTemployee_id,manager_id,employee_name
FROMEmployeeHierarchy;
在这个递归CTE的例子中,`EmployeeHierarchy`首先选择了所有没有经理的员工(即顶级经理),然后递归地联接`employees`表,将每个员工与他们的直接下属相连接。CTE可以在一个查询中被定义一次,并且在查询的多个部分中被引用多次,这样可以避免复杂的子查询并且提高性能。
7.如何使用CTE进行数据的分组和聚合操作?
公用表表达式(CTE)可以与数据的分组和聚合操作一起使用,以简化复杂的查询。CTE允许你在查询的顶部定义一个临时的结果集,这个结果集可以包含分组和聚合操作,然后在主查询中引用这个结果集。
以下是一个使用CTE进行数据分组和聚合操作的例子:
假设我们有一个名为`sales`的表,包含以下列:`sale_id`(销售ID)、`product_id`(产品ID)、`quantity`(数量)和`sale_date`(销售日期)。我们想要计算每个产品每月的销售总量。首先,我们可以创建一个CTE来提取每个月的销售记录:
WITH MonthlySales AS (SELECTproduct_id,SUM(quantity) AS total_quantity,YEAR(sale_date) AS sale_year,MONTH(sale_date) AS sale_monthFROMsalesGROUP BYproduct_id,sale_year,sale_month
)
SELECTproduct_id,sale_year,sale_month,total_quantity
FROMMonthlySales
ORDER BYproduct_id,sale_year,sale_month;
在这个例子中,`MonthlySales` CTE使用了`GROUP BY`子句来按`product_id`、`sale_year`和`sale_month`进行分组,并计算每个分组的总销售数量。然后,我们可以在主查询中选择这些分组的结果,并按产品ID、销售年份和月份排序。
如果你想在一个查询中获取所有产品的销售总量,你可以在CTE中包含一个总计分组:
WITH TotalSales AS (SELECTproduct_id,YEAR(sale_date) AS sale_year,MONTH(sale_date) AS sale_month,SUM(quantity) AS total_quantityFROMsalesGROUP BYproduct_id,sale_year,sale_month
),
OverallTotalSales AS (SELECTYEAR(sale_date) AS sale_year,MONTH(sale_date) AS sale_month,SUM(total_quantity) AS overall_total_quantityFROMTotalSalesGROUP BYsale_year,sale_month
)
SELECTproduct_id,sale_year,sale_month,total_quantity
FROMTotalSales
UNION ALL
SELECTNULL AS product_id,sale_year,sale_month,overall_total_quantity
FROMOverallTotalSales
ORDER BYsale_year,sale_month,product_id;
在这个例子中,`TotalSales` CTE计算了每个产品的每月销售总量,而`OverallTotalSales` CTE进一步计算了所有产品的每月销售总量。然后,我们使用`UNION ALL`将这两个结果集合并在一起,并按年份和月份排序。CTE可以包含多个层次,每个层次都可以包含分组和聚合操作,这使得它们非常适合于复杂的数据分析任务。
8. 如何使用CTE进行更复杂的数据聚合,比如计算不同时间段的总销售额?
使用CTE(公用表表达式)进行复杂数据聚合的一个常见场景是计算不同时间段的总销售额。这可能涉及到多个表的联接、多级分组、条件过滤以及聚合函数的使用。以下是一个示例,展示了如何使用CTE来计算每个销售员在不同时间段(如每月)的总销售额。
假设我们有两个表:`sales`和`employees`。`sales`表包含销售记录,包括`sale_id`(销售ID)、`employee_id`(销售员ID)、`sale_amount`(销售金额)和`sale_date`(销售日期)。`employees`表包含销售员的信息,包括`employee_id`(销售员ID)和`employee_name`(销售员姓名)。我们的目标是计算每个销售员每月的总销售额。
WITH SalesDetails AS (SELECTe.employee_id,e.employee_name,YEAR(s.sale_date) AS sale_year,MONTH(s.sale_date) AS sale_month,s.sale_amountFROMsales sJOIN employees e ON s.employee_id = e.employee_id
),
MonthlySales AS (SELECTemployee_id,employee_name,sale_year,sale_month,SUM(sale_amount) AS total_salesFROMSalesDetailsGROUP BYemployee_id,sale_year,sale_month
)
SELECTemployee_id,employee_name,sale_year,sale_month,total_sales
FROMMonthlySales
ORDER BYemployee_id,sale_year,sale_month;
在这个示例中:
-
SalesDetails CTE:首先,我们创建了一个
SalesDetailsCTE,它通过联接sales和employees表来获取每个销售记录的销售员ID、销售员姓名、销售日期和销售金额。同时,我们使用YEAR()和MONTH()函数来提取销售日期的年份和月份。 -
MonthlySales CTE:接下来,我们创建了一个
MonthlySalesCTE,它对SalesDetails的结果按销售员ID、年份和月份进行分组,并使用SUM()聚合函数来计算每个分组的总销售额。 -
主查询:最后,我们从
MonthlySalesCTE中选择数据,并按销售员ID、年份和月份排序,以展示每个销售员每月的总销售额。
这个示例展示了如何使用CTE进行多级聚合操作,以及如何结合联接、分组和聚合函数来解决复杂的数据分析问题。通过将复杂的查询逻辑分解到多个CTE中,我们可以提高查询的可读性和可维护性。
9. 如何使用CTE进行数据清洗,比如去除重复的销售记录?
使用CTE(公用表表达式)进行数据清洗,比如去除重复的销售记录,可以帮助你组织和简化查询。以下是一个示例,展示了如何使用CTE来去除重复的销售记录。
假设我们有一个名为sales的表,包含以下列:sale_id(销售ID)、employee_id(销售员ID)、customer_id(客户ID)、sale_amount(销售金额)和sale_date(销售日期)。有时,由于数据导入错误或其他原因,表中可能包含重复的销售记录。
我们的目标是去除重复的销售记录,并保留一个唯一的销售记录。
WITH RankedSales AS (SELECTsale_id,employee_id,customer_id,sale_amount,sale_date,ROW_NUMBER() OVER (PARTITION BY employee_id, customer_id, sale_date ORDER BY sale_id) AS rnFROMsales
)
SELECTsale_id,employee_id,customer_id,sale_amount,sale_date
FROMRankedSales
WHERErn = 1;
在这个示例中:
-
RankedSales CTE:首先,我们创建了一个
RankedSalesCTE,它使用ROW_NUMBER()窗口函数为每个销售记录分配一个唯一的行号。PARTITION BY子句用于指定要检查重复记录的列(在这个例子中是employee_id、customer_id和sale_date)。ORDER BY子句用于确定记录的排序,以便为每个分组的第一个记录分配行号1。 -
主查询:然后,在主查询中,我们从
RankedSalesCTE中选择行号为1的记录,即每个分组的第一个记录。这样,我们就可以去除重复的销售记录,只保留每个分组中的第一个记录。
这种方法的优点是它允许你保留每个重复组中的一个记录,同时去除其他重复的记录。此外,通过调整ROW_NUMBER()函数中的ORDER BY子句,你可以控制哪个记录被视为“第一个”并被保留。
请注意,如果你想要保留每个重复组中的最后一个记录,你可以使用ROW_NUMBER()函数并更改ORDER BY子句,或者使用RANK()或DENSE_RANK()函数来处理并列情况。如果你想要删除所有重复的记录,可以使用DISTINCT关键字或GROUP BY子句来聚合数据。
10. 如何使用CTE来处理数据中的异常值?
使用CTE(公用表表达式)处理数据中的异常值是一种有效的策略,可以帮助你在执行聚合或分析之前清理数据集。异常值可以是错误数据、意外噪声或不符合数据模式的值。以下是使用CTE来识别和处理异常值的一些常见方法:
- 定义异常值的标准
首先,你需要定义什么是异常值。这可能基于业务逻辑、统计分析(如标准差、四分位数)或其他规则。
- 创建CTE以识别异常值
你可以在CTE中使用条件语句或比较操作来标识异常值。
示例: 假设你有一个销售数据表sales,包含sale_amount(销售金额)和sale_date(销售日期)。如果销售金额超过某个阈值(比如平均销售额的3倍标准差),则认为该记录是异常的。
WITH SalesStats AS (SELECTAVG(sale_amount) AS avg_sale,STDDEV(sale_amount) AS std_deviationFROMsales
),
AnomalousSales AS (SELECTs.*,(s.sale_amount > (SELECT avg_sale FROM SalesStats) * 3 OR s.sale_amount < (SELECT avg_sale FROM SalesStats) / 3) AS is_anomalousFROMsales s
)
SELECT*
FROMAnomalousSales
WHEREis_anomalous = 1;
在这个例子中,SalesStats CTE 计算了所有销售金额的平均值和标准差。AnomalousSales CTE 则标记了那些销售金额超过平均值的3倍标准差的记录为异常。
- 过滤异常值
在主查询中,你可以使用CTE的结果来过滤掉异常值,只处理正常数据。
SELECTsale_amount,sale_date
FROMAnomalousSales
WHEREis_anomalous = 0;
- 使用窗口函数进行比较
如果你需要基于相对标准(如与同一组内的其他值比较)来识别异常值,可以使用窗口函数。
示例: 识别每个销售员销售额中的异常值。
WITH SalesPerEmployee AS (SELECTemployee_id,sale_amount,RANK() OVER (PARTITION BY employee_id ORDER BY sale_amount DESC) AS sale_rankFROMsales
)
SELECTemployee_id,sale_amount
FROMSalesPerEmployee
WHEREsale_rank = 1 OR sale_rank = 2; -- 假设前两个最高销售额为异常
- 多级CTE处理
对于更复杂的异常检测逻辑,可能需要多级CTE,每级处理不同的方面,最终组合结果。
示例: 组合使用多个CTE来处理和分析异常。
WITH RawSales AS (SELECTemployee_id,customer_id,sale_amount,sale_dateFROMsales
),
FilteredSales AS (SELECTemployee_id,customer_id,sale_amount,sale_dateFROMRawSalesWHEREsale_amount BETWEEN 100 AND 10000 -- 基于业务规则过滤
),
AnalyzedSales AS (SELECTemployee_id,customer_id,sale_amount,sale_date,(s.sale_amount > (SELECT AVG(sale_amount) * 3 FROM FilteredSales WHERE employee_id = s.employee_id)) AS is_anomalousFROMFilteredSales s
)
SELECTemployee_id,customer_id,sale_amount,sale_date
FROMAnalyzedSales
WHEREis_anomalous = 0;
在这个例子中,我们首先过滤掉明显不合理的数据,然后进一步分析每个销售员的销售额,以识别异常值。
使用CTE处理异常值可以提高查询的可读性和组织性,使得数据处理步骤更加清晰。
相关文章:

【MySQ】在MySQL里with 的用法
在MySQL中,WITH语句通常与公用表表达式(Common Table Expressions,简称CTE)一起使用。CTE是一种临时的结果集,类似于视图或子查询,它们在查询中被定义并且可以在一个或多个SELECT、INSERT、UPDATE或DELETE语…...

多源最短路径
文章目录 1. 01 矩阵(542)2. 飞地的数量(1020)3. 地图分析(1162)4. 地图中的最高点(1765) 1. 01 矩阵(542) 题目描述: 算法原理: 这…...

在 Mac 中设置环境变量
目录 什么是环境变量,为什么它们重要?什么是环境变量?举个例子 如何查看环境变量如何设置和修改环境变量1. 临时设置环境变量2. 永久设置环境变量3. 修改现有环境变量 环境变量在开发中的应用在 Node.js 项目中使用环境变量在 Python 项目中使…...

记录一次ubuntu /mysql/redis/nginx等 系统安装
没想到还会做一次系统安装配置类的工作,没办法,碰到问题了,总得解决。 安装 &网络配置 从网上下载了ubuntu 18.04.6的安装包,用UltraISO做安装盘,到服务器上修改了下启动顺序,ubuntu的安装非常简单&a…...
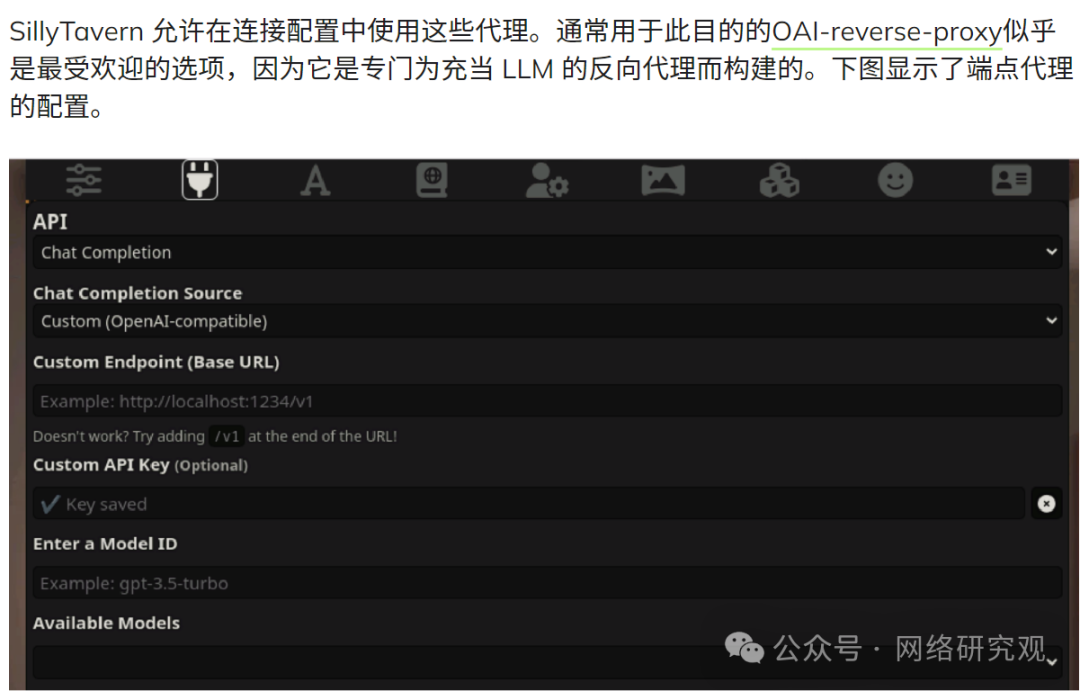
大型语言模型 (LLM) 劫持攻击不断升级,导致每天损失超过 100,000 美元
Sysdig 威胁研究团队 (TRT) 报告称,LLMjacking(大型语言模型劫持)事件急剧增加,攻击者通过窃取的云凭证非法访问大型语言模型 (LLM)。 这一趋势反映了 LLM 访问黑市的不断增长,攻击者的动机包括个人使用和规避禁令和制…...

Java 入门指南:JVM(Java虚拟机)垃圾回收机制 —— 垃圾收集器
文章目录 垃圾回收机制Stop-the-World垃圾收集器垃圾收集器分类Serial 收集器Serial Old 收集器ParNew 收集器Parallel Scavenge 收集器Parallel Old 收集器CMS 收集器CMS 收集器缺点 G1 收集器G1 收集器特点G1 收集器的分代理念G1 收集器运作过程 垃圾回收机制 垃圾回收&…...
nano 命令:文本编辑器
一、命令简介 nano 是一个简单易用的文本编辑器,适合初学者和那些不需要复杂功能的用户。 相关命令(不同难度的编辑器): 初级难度:nano中级难度:vim终极难度:Emacs 二、命…...

【2020工业图像异常检测文献】SPADE
Sub-Image Anomaly Detection with Deep Pyramid Correspondences 1、Background 利用深度预训练特征的最近邻( kNN )方法在应用于整个图像时表现出非常强的异常检测性能。kNN 方法的一个局限性是缺乏描述图像中异常位置的分割图。 为了解决这一问题&a…...

C++QT医院专家门诊预约管理系统
目录 一、项目介绍 二、项目展示 三、源码获取 一、项目介绍 医院专家门诊预约管理系统 [要求] 该系统需创建和管理以下信息:1、门诊专家信息:专家姓名、编号、性别、年龄、职称、门诊科目、服务时间、门诊预约数据集等;2、门诊预约信息…...

在SpringBoot项目中利用Redission实现布隆过滤器(布隆过滤器的应用场景、布隆过滤器误判的情况、与位图相关的操作)
文章目录 1. 布隆过滤器的应用场景2. 在SpringBoot项目利用Redission实现布隆过滤器3. 布隆过滤器误判的情况4. 与位图相关的操作5. 可能遇到的问题(Redission是如何记录布隆过滤器的配置参数的)5.1 问题产生的原因5.2 解决方案5.2.1 方案一:…...

【prefect】python任务调度工具 Prefect | 可视化任务工具 | Python自动化的终极武器 | 高效数据管道管理
一、产品介绍 1、官方 Github https://github.com/PrefectHQ/prefect 2、官方文档 https://docs.prefect.io/3.0/get-started/index 3、Pgsql说明 正确的python链接pgsql如下: import psycopg2 from sqlalchemy import create_enginedef connect_with_psycopg2(…...

蓝禾,汤臣倍健,三七互娱,得物,顺丰,快手,游卡,oppo,康冠科技,途游游戏,埃科光电25秋招内推
蓝禾,汤臣倍健,三七互娱,得物,顺丰,快手,游卡,oppo,康冠科技,途游游戏,埃科光电25秋招内推 ①蓝禾 【岗位】国内/国际电商运营,设计,…...

【面向对象】设计模式分类
java中设计模式共23种,根据使用场景可分为创建型模式、结构型模式、行为型模式。 创建型: 如何创建对象。 单例模式:保证一个类在一个程序中只能创建一个对象。例如windows任务管理器窗口只需要创建一个。单例模式只创建一个对象࿰…...
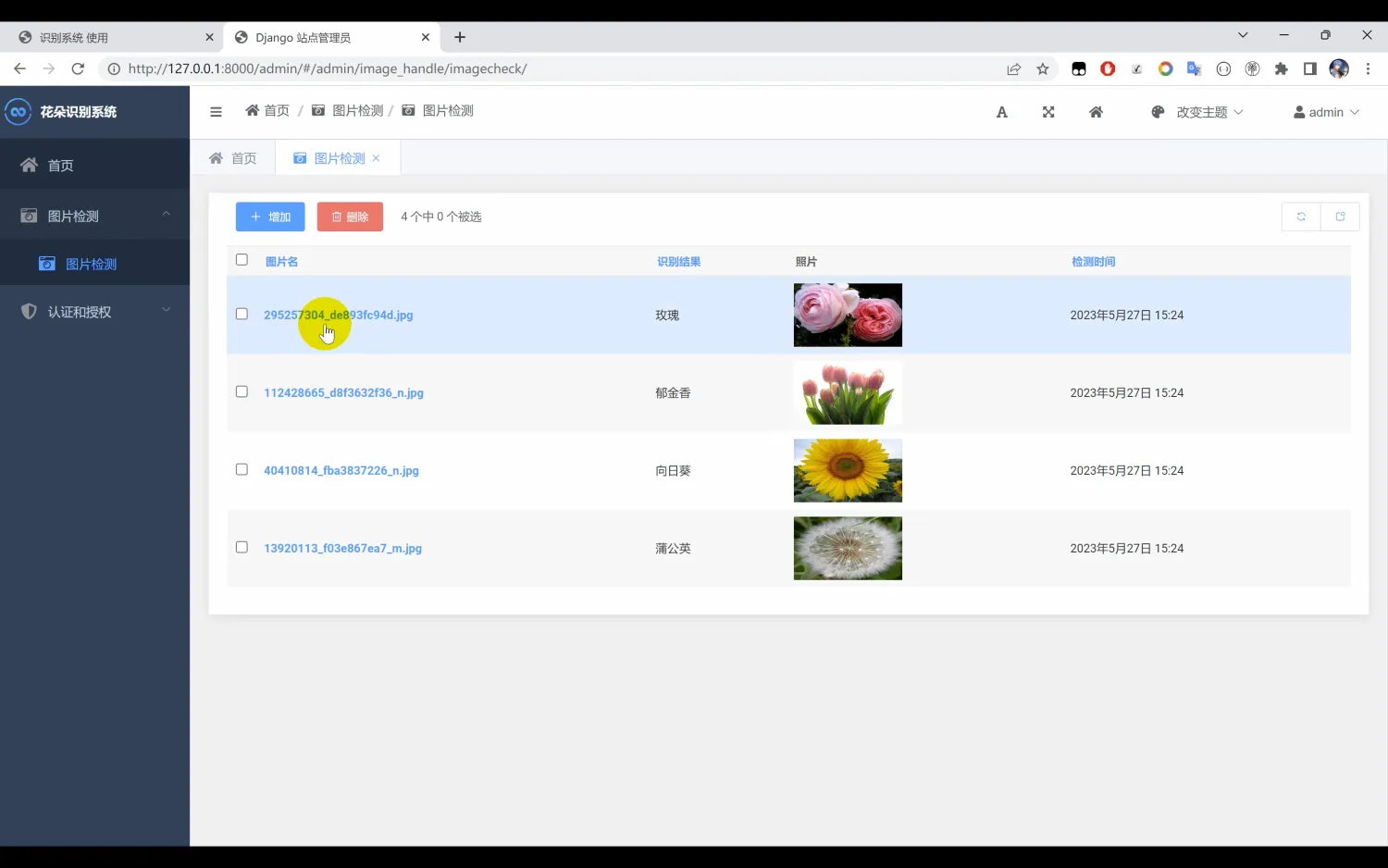
花朵识别系统Python+卷积神经网络算法+人工智能+深度学习+计算机课设项目+TensorFlow+模型训练
一、介绍 花朵识别系统。本系统采用Python作为主要编程语言,基于TensorFlow搭建ResNet50卷积神经网络算法模型,并基于前期收集到的5种常见的花朵数据集(向日葵、玫瑰、蒲公英、郁金香、菊花)进行处理后进行模型训练,最…...

中泰免签,准备去泰国旅游了吗?《泰语翻译通》app支持文本翻译和语音识别翻译,解放双手对着说话就能翻译。
泰国是很多中国游客的热门选择,现在去泰国旅游更方便了,因为泰国对中国免签了。如果你打算去泰国,那么下载一个好用的泰语翻译软件是很有必要的。 简单好用的翻译工具 《泰语翻译通》App就是为泰国旅游设计的,它翻译准确&#x…...

C++/Qt 集成 AutoHotkey
C/Qt 集成 AutoHotkey 前言AutoHotkey 介绍 方案一:子进程启动编写AutoHotkey脚本准备 AutoHotkey 运行环境编写 C/Qt 代码 方案二:显式动态链接方案探索编译动态链接库集成到C工程关于AutoHotkeyDll.dll中的函数原型 总结 前言 上一篇介绍了AutoHotkey…...
OpenMV学习第一步安装IDE_2024.09.20
用360浏览器访问星瞳科技官网,一直提示访问不了。后面换了IE浏览器就可以访问。第一个坑。...

RK3568平台(基础篇)万用表的使用
一.万用表的通断判断 万用表两个笔头的插法:黑笔头是插在COM的孔里面,红色笔头可以插在其他的三个孔里面,20A和mA分别用来测电流,另外一个孔可以用来测其他(电压 电阻)。 以下这个三角符号(像wifi一样的)可以用来测通断: 使用万用表的红笔和黑笔进行短接,这时候两端…...

more、less 命令:阅读文本
一、命令简介 more 和 less 都是用于查看文本文件内容的命令,但它们在显示方式和功能上有一些区别。 简单的说 less 是 more 的升级版:增加了搜索、跳转等功能。所以优先使用 less,可以不用 more 了。 二、命令参数 基…...

【笔记】1.3 塑性变形
一、塑性变形的方式 DDWs(Dislocation-Dipole Walls,位错偶极墙):指由两个位错构成的结构,它们以一种特定的方式排列在一起,形成一个稳定的结构单元。 DTs(Dislocation Tangles,位错…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...