DeepCross模型实现推荐算法
1. 项目简介
A032-DeepCross项目是一个基于深度学习的推荐算法实现,旨在解决个性化推荐问题。随着互联网平台上信息和内容的爆炸式增长,用户面临着信息过载的困境,如何为用户提供高效、精准的推荐成为了关键。该项目背景基于现代推荐系统的发展,利用用户行为数据和内容特征,来生成符合用户偏好的推荐结果。项目使用的核心模型是DeepCross模型,这是一种结合了深度神经网络(DNN)和交叉特征结构的混合模型。DeepCross模型通过对用户和物品的特征进行嵌入,并应用交叉特征层来捕捉不同特征之间的高阶交互,进而提升推荐精度。与传统的矩阵分解模型相比,DeepCross模型能够更好地处理非线性关系,适用于处理大量的稀疏数据,广泛应用于电商、社交平台、内容推荐等场景。通过该项目的实现,目标是优化现有推荐算法的效果,并为用户提供更精准的个性化内容推荐体验。

2.技术创新点摘要
混合架构: DeepCross模型结合了两种架构的优势:深度神经网络(DNN)和交叉网络。DNN用于捕捉特征之间的高阶非线性交互,而交叉网络则高效地建模不同层次的特征交叉,避免了手动特征工程的复杂性。这种模型的融合能够更好地表示特征交互,提升推荐系统捕捉数据中低阶和高阶模式的能力。
高效的特征交叉层: 交叉网络引入了一种独特的特征交互机制,通过在每一层计算输入特征的交叉积来实现。这一过程允许模型在保持计算效率的同时,明确地建模原始特征之间的交互关系。与传统的基于多项式的模型不同,交叉网络能够建模高阶交互,而不会导致参数数量的指数级增加。
StepRunner和EpochRunner类的模块化训练: 代码中实现的StepRunner和EpochRunner类将训练过程模块化,使得管理单个步骤和基于epoch的更新变得更加简便。这种结构为集成优化技术(如学习率调度器和训练过程中的评估指标)提供了灵活性,使得该模型能够更好地适应不同的数据集和训练需求。
正则化与性能监控: 在整个训练过程中,模型有效地集成了正则化策略,并监控关键性能指标。例如,模型通过AUC(曲线下面积)等指标来跟踪性能,确保模型在训练过程中持续优化,减少过拟合的风险,并确保模型在处理未见数据时具备良好的泛化能力。
3. 数据集与预处理
在DeepCross模型项目中,数据集来源于某个推荐系统领域,包含用户行为数据和物品特征数据。该数据集的特点包括:高维、稀疏性较强,且包含大量的类别型特征(如用户ID、物品ID、性别、地区等)。这种类型的数据集通常具有大量离散化的特征,需要有效的预处理和特征工程,以提高模型的性能。
数据预处理流程主要包括以下几个步骤:
- 缺失值处理:首先,对数据中的缺失值进行处理。某些数值型特征的缺失值可以用均值、中位数或其他统计值进行填充,而类别型特征可以用特殊的“未知”类别进行标记。
- 特征编码:由于类别型特征不能直接输入到模型中,需要将其转换为数值形式。常用的编码方式包括独热编码(One-Hot Encoding)和嵌入表示(Embedding) 。对于高维类别型特征,模型采用嵌入方式,将每个类别映射到一个低维的向量空间中,从而减少计算量并保留更多的特征信息。
- 归一化:数值型特征通常需要进行归一化处理,将不同量级的特征值缩放到同一范围,以避免某些特征对模型的影响过大。常用的归一化方法包括最小-最大缩放和标准化。
- 特征交叉:特征工程的重要环节是进行特征交叉,通过组合不同的特征来生成新的交叉特征。这一过程能够捕捉不同特征之间的潜在关系,有助于提高模型的预测性能。DeepCross模型利用其特有的交叉网络结构,自动完成特征交叉的过程,避免了手动设计交叉特征的复杂性。
- 数据拆分:为了评估模型的性能,数据集通常会按照一定比例拆分为训练集、验证集和测试集。在本项目中,使用了标准的80/20的拆分比例,将大部分数据用于训练模型,其余用于验证和测试模型的泛化能力。
4. 模型架构
从代码中可以看出,模型是基于DeepCross模型的实现,具体使用了CrossNetMatrix模块来构建Deep Cross V2(DCNV2)模型。下面是关于模型架构的详细解释:
1. 模型结构的逻辑
该模型的结构包括两大部分:交叉网络(Cross Network) 和 多层感知机(MLP,Multi-Layer Perceptron) 。具体架构如下:
-
输入层:
- 输入包括两类特征:数值型特征和类别型特征。
- 对数值型特征,直接输入至网络中,记为 Xnum。
- 对类别型特征,采用嵌入表示(Embedding),将类别型特征映射为低维稠密向量,记为 Xcat。这些嵌入向量的维度为 dembed。
-
交叉网络(Cross Network) :
- 交叉网络的主要作用是捕捉特征之间的高阶交互,避免手动特征工程。
- 模型使用的是CrossNetMatrix,其中每一层的计算公式为:
- x l + 1 = x 0 x l T W l + b l + x l \mathbf{x}_{l+1} = \mathbf{x}_0 \mathbf{x}_l^T \mathbf{W}_l + \mathbf{b}_l + \mathbf{x}_l xl+1=x0xlTWl+bl+xl
- 其中,xl\mathbf{x}_lxl 是第 lll 层的输入特征,Wl\mathbf{W}_lWl 是该层的权重矩阵,bl\mathbf{b}_lbl 是偏置项,x0\mathbf{x}_0x0 是初始输入特征。通过这一操作,模型在不同层次上交叉输入特征,捕捉特征间的多阶交互。
-
多层感知机(MLP) :
- 交叉网络输出的特征被传入多层感知机(MLP),用于进一步捕捉特征的非线性关系。
- MLP的结构为多层全连接层,使用ReLU激活函数,层与层之间加入了Dropout以防止过拟合。
-
- h i + 1 = ReLU ( W i h i + b i ) \mathbf{h}_{i+1} = \text{ReLU}(\mathbf{W}_i \mathbf{h}_i + \mathbf{b}_i) hi+1=ReLU(Wihi+bi)
- 其中 Wi\mathbf{W}_iWi 和 bi\mathbf{b}_ibi 分别是第 iii 层的权重矩阵和偏置项,hi\mathbf{h}_ihi 是第 iii 层的输出。
-
输出层:
- 最终输出层使用Sigmoid激活函数,输出为一个概率值,表示样本属于某个类别的概率: y ^ = σ ( W out h + b out ) \hat{y} = \sigma(\mathbf{W}_{\text{out}} \mathbf{h} + \mathbf{b}_{\text{out}}) y^=σ(Wouth+bout)
- 其中 σ是Sigmoid函数,Wout是输出层的权重矩阵。
2. 模型的整体训练流程
- 损失函数: 模型使用二元交叉熵损失(Binary Cross-Entropy Loss)来衡量预测结果与真实标签之间的差距。其公式为:
- L = − 1 N ∑ i = 1 N [ y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ] \mathcal{L} = -\frac{1}{N} \sum_{i=1}^N [y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i)] L=−N1i=1∑N[yilog(y^i)+(1−yi)log(1−y^i)]
- 其中,NNN 是样本数量,yiy_iyi 是真实标签,yi\hat{y}_iyi 是模型预测的概率值。
- 优化器: 模型使用Adam优化器进行训练,自动调整学习率以加快收敛速度。
- 评估指标: 模型主要使用AUC(ROC曲线下面积)作为评估指标。AUC衡量了模型区分正负样本的能力,AUC值越高,说明模型性能越好。
5. 核心代码详细讲解
1. 数据预处理和特征工程
from sklearn.preprocessing import LabelEncoder, QuantileTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
dfdata = pd.read_csv("/home/mw/input/eat_pytorch_datasets3807/eat_pytorch_datasets/eat_pytorch_datasets/criteo_small.zip",sep="\t",header=None)
dfdata.columns = ["label"] + ["I"+str(x) for x in range(1,14)] + ["C"+str(x) for x in range(14,40)]
cat_cols = [x for x in dfdata.columns if x.startswith('C')]
num_cols = [x for x in dfdata.columns if x.startswith('I')]
num_pipe = Pipeline(steps = [('impute', SimpleImputer()), ('quantile', QuantileTransformer())])for col in cat_cols:dfdata[col] = LabelEncoder().fit_transform(dfdata[col])
dfdata[num_cols] = num_pipe.fit_transform(dfdata[num_cols])
categories = [dfdata[col].max() + 1 for col in cat_cols]
- LabelEncoder: 将类别型特征编码为整数,便于模型处理。
- SimpleImputer: 用于填充数值型特征中的缺失值。
- QuantileTransformer: 将数值型特征进行分位数归一化处理,将数据转换为均匀分布。
- Pipeline: 将缺失值填充和归一化操作结合在一起,应用于数值型特征。
- LabelEncoder应用于每个类别型特征,将其转换为数值。
- 最后计算categories: 通过统计每个类别型特征的最大值,生成类别数量列表,用于嵌入层的初始化。
2. 模型架构构建
def create_net():net = DeepCross(d_numerical= ds_train.X_num.shape[1],categories= ds_train.get_categories(),d_embed_max = 8,n_cross = 2, cross_type = "matrix",mlp_layers = [128,64,32], mlp_dropout=0.25,stacked = True,n_classes = 1)return net
- DeepCross模型: 该模型由交叉网络和多层感知机(MLP)构成。
- d_numerical: 数值特征的维度,输入到网络中的数值特征数量。
- categories: 类别型特征的嵌入层信息,包含每个类别的类别数。
- d_embed_max: 设置嵌入层的最大维度(8维),用于类别型特征嵌入。
- n_cross: 设置交叉网络的层数(2层交叉层),用于高阶特征交叉。
- cross_type: 使用的是交叉网络的"matrix"方式,即CrossNetMatrix。
- mlp_layers: 设置MLP的层数及每层的节点数,分别为128, 64, 32。
- mlp_dropout: 设置每层MLP的Dropout比例,防止过拟合。
- stacked: 是否使用堆叠式的MLP结构。
- n_classes: 设置模型的输出节点数,这里是二分类问题,因此输出节点为1。
3. 模型训练与评估
model = KerasModel(net,loss_fn = nn.BCEWithLogitsLoss(),metrics_dict = {"auc": AUC()},optimizer = torch.optim.Adam(net.parameters(), lr=0.002, weight_decay=0.001))
dfhistory = model.fit(train_data=dl_train, val_data=dl_val, epochs=20, patience=5,monitor = "val_auc", mode="max", ckpt_path='checkpoint.pt')
val_auc = roc_auc_score(labels.cpu().numpy(), preds.cpu().numpy())
- KerasModel: 定义了深度学习模型的训练与评估流程,封装了模型、损失函数、评估指标、优化器等。
- loss_fn: 使用二元交叉熵损失(
BCEWithLogitsLoss),适合二分类任务。 - metrics_dict: 设置AUC作为模型的评估指标。
- optimizer: 使用Adam优化器,并且设置学习率为0.002,权重衰减参数为0.001。
- model.fit: 开始训练模型,设置了训练和验证数据、训练轮次(20轮)、早停机制(5轮无提升则停止)和监控的指标(AUC)。
- roc_auc_score: 计算模型在验证集上的AUC值,用于评估模型的性能。
6. 模型优缺点评价
优点:
- 高效的特征交叉:DeepCross模型通过交叉网络自动捕捉特征之间的高阶交互,避免了手动特征工程的复杂性。通过这种方式,模型能够有效处理类别型和数值型特征之间的关系,并在推荐任务中表现出色。
- 灵活的嵌入表示:模型对类别型特征使用了嵌入层,将高维的离散特征转换为低维的稠密表示,降低了模型的计算复杂度,同时保留了特征的语义信息。
- 多层感知机(MLP)的非线性建模能力:MLP能够进一步提取非线性特征,增强模型对复杂数据的表达能力,从而提升预测精度。
- AUC评估指标:使用AUC作为模型性能的评估指标,适合二分类任务,能够较好地衡量模型的区分能力。
缺点:
- 过拟合的潜在风险:虽然模型使用了Dropout等正则化技术,但在处理小数据集时,仍然存在过拟合的风险。特别是当MLP层数较多时,模型容易拟合训练数据,但在测试数据上的表现可能不理想。
- 对类别型特征处理的局限性:尽管嵌入层能够有效处理类别型特征,但对于类别数量过多或过少的特征,嵌入维度的选择可能不够灵活,导致信息丢失或计算资源浪费。
- 模型复杂性高:由于模型结合了交叉网络和MLP,计算复杂度较高,尤其是当数据量大时,训练时间和资源需求较大。
改进方向:
- 模型结构优化:可以尝试增加更多层次的交叉网络,以捕捉更复杂的特征交互。同时,可以引入注意力机制,使模型能够更好地聚焦于重要特征。
- 超参数调整:进一步优化嵌入层维度、交叉层数、MLP节点数等超参数,提升模型的整体性能。
- 更多的数据增强方法:可以在数据预处理阶段引入更多的数据增强方法,如SMOTE或类别平衡技术,以应对类别不平衡问题,提高模型的泛化能力。
↓↓↓更多热门推荐:
DeepFM模型预测高潜购买用户
CNN-LSTM住宅用电量预测
点赞收藏关注,免费获取本项目代码和数据集,点下方名片↓↓↓
相关文章:
DeepCross模型实现推荐算法
1. 项目简介 A032-DeepCross项目是一个基于深度学习的推荐算法实现,旨在解决个性化推荐问题。随着互联网平台上信息和内容的爆炸式增长,用户面临着信息过载的困境,如何为用户提供高效、精准的推荐成为了关键。该项目背景基于现代推荐系统的发…...

【力扣】2376. 统计特殊整数
如果一个正整数每一个数位都是 互不相同 的,我们称它是 特殊整数 。 给你一个 正 整数 n ,请你返回区间 [1, n] 之间特殊整数的数目。 示例 1: 输入:n 20 输出:19 解释:1 到 20 之间所有整数除了 11 以外都…...

MySQL面试题——第一篇
1. 一张自增表里面总共有7条数据,删除了最后2条数据,重启数据库后又插入了一条数据,此时ID是几 表类型如果是MyISAM,那么id就是8 如果是InnoDB,那就是6 InnoDB表只会把自增主键的最大id记录在内存中,所以重…...
零停机部署的“秘密武器”:为什么 Kamal Proxy 能成为你架构中的不二之选?
你是不是也遇到过这种场景:网站正在升级,用户却被迫刷新无数次页面?服务器切换时瞬间掉线,客户体验差得没话说。更糟糕的是,流量高峰期来临时,正是业务最重要的时刻,结果因为停机而损失惨重。这个时候你一定会想:难道没有一种方式,能在不打断服务的情况下,平滑地进行…...
轻量级RSS阅读器Fusion
什么是 Fusion ? Fusion 是一款轻量级、自托管的 RSS 聚合器和阅读器。 软件主要特点: 自动分组、书签、搜索、嗅探信息导入/导出 OPML 文件支持 RSS、Atom、JSON 类型的 feed响应式、明/暗模式、PWA轻量级,自托管友好 使用 Golang 和 SQLit…...

Kubernetes从零到精通(11-CNI网络插件)
Kubernetes网络模型 Kubernetes的网络模型(Kubernetes Networking Model)旨在提供跨所有节点、Pod和服务的统一网络连接。它的核心理念是通过统一的网络通信规则,保证集群中的所有组件能够顺畅地相互通信。Kubernetes网络模型主要有以下几个关…...

【手机马达共振导致后主摄马达声音异常】
手机马达共振导致后主摄马达声音异常 问题根因解决方案其他易混淆 问题根因 当手机马达的震动频率和摄像头AF马达的一二阶震动频率处于共振频段的时候,手机马达震动时候有很大概率会干扰到后置摄像头的对焦马达正常工作,可能出现的影响有出现滋滋杂音&a…...

AUTOSAR UDS NRC
UDS NRC NRC 含义如表格所示 NRC代码描述含义0x00Ok没有错误,请求已成功执行0x01~0x0FISOSAEReservedISO 保留,暂时未定义0x10General reject服务请求被拒绝,原因不明确0x11Service not supported请求的服务不被支持0x12Sub-function not supported请求的子功能不被支持0x13…...

[数据结构]无头单向非循环链表的实现与应用
文章目录 一、引言二、线性表的基本概念1、线性表是什么2、链表与顺序表的区别3、无头单向非循环链表 三、无头单向非循环链表的实现1、结构体定义2、初始化3、销毁4、显示5、增删查改 四、分析无头单向非循环链表1、存储方式2、优点3、缺点 五、总结1、练习题2、源代码 一、引…...

认识结构体
目录 一.结构体类型的声明 1.结构的声明 2.定义结构体变量 3.结构体变量初始化 4.结构体的特殊声明 二.结构体对齐(重点难点) 1.结构体对齐规则 2.结构体对齐练习 (一)简单结构体对齐 (二)嵌套结构体对齐 3.为什么存在内存对齐 4.修改默认对齐数 三.结构体传参 1…...
)
Linux驱动.之MT7601,USB-WiFi网卡移植到X210开发板,wpa_supplicant配置工具的使用(一)
一、移植前 1、下载与解压无线网卡MT7601U驱动源码压缩包 DPO_MT7601U_LinuxSTA_3.0.0.4_20130913.tar.bz2 解压后有如下文件 ate common iwpriv_usage.txt Makefile mgmt phy README_STA_usb RT2870STA.dat sta_ate_iwpriv_usage.txt chips include m…...
ChatGPT 在国内使用的方法
AI如今很强大,聊聊天、写论文、搞翻译、写代码、写文案、审合同等等,ChatGPT 真是无所不能~ 作为一款出色的大语言模型,ChatGPT 实现了人类般的对话交流,最主要是能根据上下文进行互动。 接下来,我将介绍 ChatGPT 在国…...
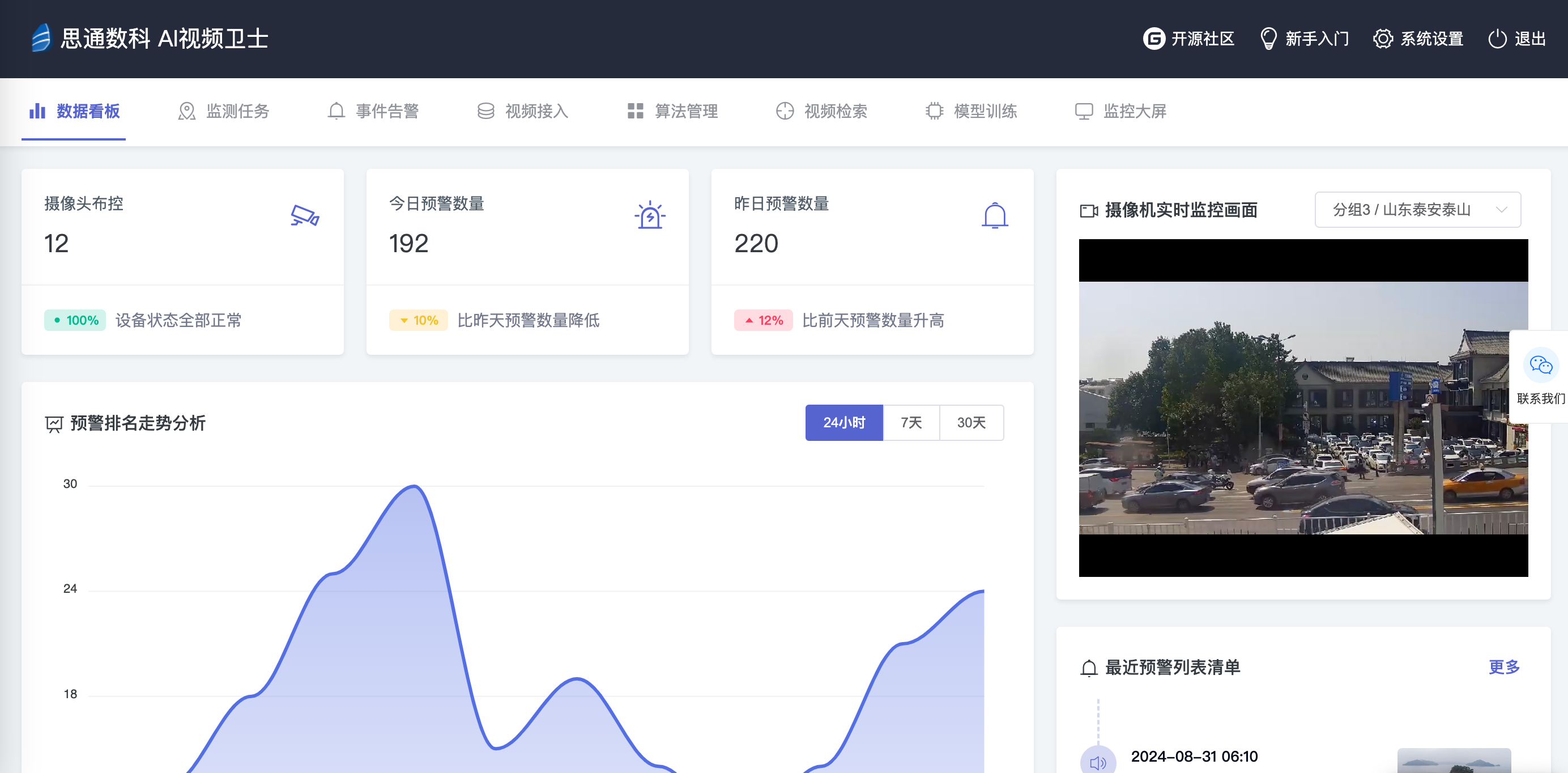
思通数科开源产品:免费的AI视频监控卫士安装指南
准备运行环境: 确保您的服务器或计算机安装了Ubuntu 18.04 LTS操作系统。 按照产品要求,安装以下软件: - Python 3.9 - Java JDK 1.8 - MySQL 5.5 - Redis 2.7 - Elasticsearch 8.14 - FFmpeg 4.1.1 - RabbitMQ 3.13.2 - Minio (…...

阿里HPN-用于大型语言模型训练的数据中心网络
阿里巴巴HPN:用于大型语言模型训练的数据中心网络 探索大规模语言模型训练新方法:阿里巴巴HPN数据中心网络论文。 摘要 本文介绍了阿里云用于大型语言模型(LLM)训练的数据中心网络HPN。由于LLM和一般云计算之间的差异(例如,在流量模式和容错性方面)&…...

re题(27)BUUFCTF-[MRCTF2020]Transform
BUUCTF在线评测 (buuoj.cn) 先到ida,先看一下字符串 找到主函数 int __cdecl main(int argc, const char **argv, const char **envp) {char Str[104]; // [rsp20h] [rbp-70h] BYREFint j; // [rsp88h] [rbp-8h]int i; // [rsp8Ch] [rbp-4h]sub_402230(argc, argv…...

偶数、奇数、整数与指数
引言 在前面的课程中,我们已经学习了 Python 的基本输入输出、数据类型及其转换、顺序结构、分支结构、循环结构、循环控制语句、字符串类型、列表类型、元组类型、字典类型、集合类型、函数的定义与使用、函数调用与作用域、函数的高级应用、质数、倍数与余数。本课…...

关于c#中异步async和await的理解
之前给大家介绍了所谓异步编程的用法,但是没有细致的理解到,今天想和大家一起探讨一下; 前文: C#笔记14 异步编程Async,await,task类-CSDN博客 异步的起初 应用程序会启动一个进程,一个进程可以有很多…...

mysql等保数据库命令
mysql数据库命令 默认安装位置:C:\Program Files\MySQL\MySQL Server 8.0\bin select version() from dual; desc mysql.user; 查看表中有哪些列 1、SELECT user, host, authentication_string, account_locked ,password_lifetime FROM mysql.user; 查询用户表…...

云平台在大规模设备管理和数据分析中的作用
在当代数字化转型的浪潮中,云平台作为信息技术基础设施的核心组件,扮演着无可替代的角色,尤其在大规模设备管理和数据分析领域,其重要性和影响力日益凸显。本文旨在深入探讨云平台如何通过其独特的优势,促进数据的高效…...

数据结构-树和二叉树
树 和 二叉树 1.树的概念 树 tree 是n(n>0)个节点的有限集 在任意的一个非空树中 (1)有且仅有一个特定的被称为 根(root) 的节点 (2)当n>1时, 其余的节点可分为m(m>0)个互不相交的有限集T1, T2, T3, .... …...

如何快速掌握串口数据可视化:SerialPlot终极完整教程
如何快速掌握串口数据可视化:SerialPlot终极完整教程 【免费下载链接】serialplot Small and simple software for plotting data from serial port in realtime. 项目地址: https://gitcode.com/gh_mirrors/se/serialplot 想象一下,你正在调试一…...

安装 KubeSphere
安装 KubeSphere KubeSphere Core (ks-core) 是 KubeSphere 的核心组件,为扩展组件提供基础的运行环境。KubeSphere Core 安装完成后,即可访问 KubeSphere Web 控制台。 1. 安装 KubeSphere Core 在集群节点上,执行以下命令安装 KubeSpher…...

Chrome二维码插件:跨设备链接传输的智能解决方案
Chrome二维码插件:跨设备链接传输的智能解决方案 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码,同…...

Fusion360新手必看:这10个隐藏快捷键和技巧,让你建模效率翻倍
Fusion360效率革命:10个被低估的实战技巧与深度应用 第一次打开Fusion360时,我被它复杂的界面吓到了——工具栏密密麻麻的图标,嵌套多层的右键菜单,还有那些隐藏在角落里的功能选项。直到一位资深用户向我演示了如何用长按左键快…...

KMS_VL_ALL_AIO:智能激活脚本的完整使用指南
KMS_VL_ALL_AIO:智能激活脚本的完整使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO KMS_VL_ALL_AIO是一款基于微软官方KMS协议开发的智能激活脚本,为Windows系统…...

Borderless Gaming终极指南:三步搞定无缝游戏窗口切换的魔法
Borderless Gaming终极指南:三步搞定无缝游戏窗口切换的魔法 【免费下载链接】Borderless-Gaming Play your favorite games in a borderless window; no more time consuming alt-tabs. 项目地址: https://gitcode.com/gh_mirrors/bo/Borderless-Gaming 你…...

技术人的时间管理:高效利用每一天
技术人的时间管理:高效利用每一天 引言 作为一名技术人,我们每天都面临着大量的工作任务和学习需求。如何在有限的时间内高效完成工作、持续学习提升,同时保持良好的生活质量,是每个技术人都需要面对的挑战。 在过去的几年里&…...

智能数据上下文层:让AI代理真正理解您的企业数据价值
智能数据上下文层:让AI代理真正理解您的企业数据价值 【免费下载链接】WrenAI Turn any AI Agents into world-class data analysts through the open context layer that gives AI agents grounded, governed memory, context, SQL across 20 data sources, that h…...

免费文档下载终极指南:一键获取百度文库、豆丁网等30+平台资源
免费文档下载终极指南:一键获取百度文库、豆丁网等30平台资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就…...

Python爬虫实战:从零编写一个健壮的静态页面抓取器!
㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~ ㊙️本期爬虫难度指数:⭐⭐⭐ (进阶) 🉐福利: 一次订阅后,专栏内的所有文…...