微软开源GraphRAG的使用教程(最全,非常详细)
GraphRAG的介绍
目前微软已经开源了GraphRAG的完整项目代码。对于某一些LLM的下游任务则可以使用GraphRAG去增强自己业务的RAG的表现。项目给出了两种使用方式:
- 在打包好的项目状态下运行,可进行尝试使用。
- 在源码基础上运行,适合为了下游任务的微调时使用。
如果需要利用Ollama部署本地大模型的可以参考我的另一篇博客
以下在通过自身的实践之后的给出对这两种方式的使用教程,如果还有什么问题在评论区交流。
一、在源码基础上运行(便于后续修改)
1. 准备环境(在终端运行)
(1)创建虚拟环境(已安装好anaconda),此处建议使用python3.11:
conda create -n GraphRAG python=3.11
conda activate GraphRAG
2. 下载源码并进入目录
git clone https://github.com/microsoft/graphrag.git
cd graphrag
3. 下载依赖并初始化项目
(1)安装poetry资源包管理工具及相关依赖:
pip install poetry
poetry install
(2)初始化
poetry run poe index --init --root .
正确运行后,此处会在graphrag目录下生成output、prompts、.env、settings.yaml文件
4. 下载并将待检索的文档document放入./input/目录下
mkdir ./input
curl https://www.xxx.com/xxx.txt > ./input/book.txt #示例,可以替换为任何的txt文件
5.修改相关配置文件
(1)修改.env文件(默认是隐藏的)中的api_key
vi .env #进入.env文件,并修改为自己的api_key
修改后是全局配置,后续不需要再次修改了
(2)修改settings.yaml文件,修改其中的使用的llm模型和对应的api_base
提前说明,因为GraphRAG需要多次调用大模型和Embedding,默认使用的是openai的GPT-4,花费及其昂贵(
土豪当我没说,配置也不需要改),建议大家可以使用其他模型或国产大模型的api
我这里使用的是agicto提供的APIkey(主要是新用户注册可以免费获取到10块钱的调用额度,白嫖还是挺爽的)。我在这里主要就修改了API地址和调用模型的名称,修改完成后的settings文件完整内容如下:
(代码行后有标记的为需要修改的地方),如果用的是agicto则则不用修改settings.yaml
encoding_model: cl100k_base
skip_workflows: []
llm:api_key: ${GRAPHRAG_API_KEY}type: openai_chat # or azure_openai_chatmodel: deepseek-chat #修改model_supports_json: false # recommended if this is available for your model.api_base: https://api.agicto.cn/v1 #修改# max_tokens: 4000# request_timeout: 180.0# api_version: 2024-02-15-preview# organization: <organization_id># deployment_name: <azure_model_deployment_name># tokens_per_minute: 150_000 # set a leaky bucket throttle# requests_per_minute: 10_000 # set a leaky bucket throttle# max_retries: 10# max_retry_wait: 10.0# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times# concurrent_requests: 25 # the number of parallel inflight requests that may be madeparallelization:stagger: 0.3# num_threads: 50 # the number of threads to use for parallel processingasync_mode: threaded # or asyncioembeddings:## parallelization: override the global parallelization settings for embeddingsasync_mode: threaded # or asynciollm:api_key: ${GRAPHRAG_API_KEY}type: openai_embedding # or azure_openai_embeddingmodel: text-embedding-3-small #修改api_base: https://api.agicto.cn/v1 #修改# api_base: https://<instance>.openai.azure.com# api_version: 2024-02-15-preview# organization: <organization_id># deployment_name: <azure_model_deployment_name># tokens_per_minute: 150_000 # set a leaky bucket throttle# requests_per_minute: 10_000 # set a leaky bucket throttle# max_retries: 10# max_retry_wait: 10.0# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times# concurrent_requests: 25 # the number of parallel inflight requests that may be made# batch_size: 16 # the number of documents to send in a single request# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request# target: required # or optionalchunks:size: 300overlap: 100group_by_columns: [id] # by default, we don't allow chunks to cross documentsinput:type: file # or blobfile_type: text # or csvbase_dir: "input"file_encoding: utf-8file_pattern: ".*\\.txt$"cache:type: file # or blobbase_dir: "cache"# connection_string: <azure_blob_storage_connection_string># container_name: <azure_blob_storage_container_name>storage:type: file # or blobbase_dir: "output/${timestamp}/artifacts"# connection_string: <azure_blob_storage_connection_string># container_name: <azure_blob_storage_container_name>reporting:type: file # or console, blobbase_dir: "output/${timestamp}/reports"# connection_string: <azure_blob_storage_connection_string># container_name: <azure_blob_storage_container_name>entity_extraction:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this taskprompt: "prompts/entity_extraction.txt"entity_types: [organization,person,geo,event]max_gleanings: 0summarize_descriptions:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this taskprompt: "prompts/summarize_descriptions.txt"max_length: 500claim_extraction:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this task# enabled: trueprompt: "prompts/claim_extraction.txt"description: "Any claims or facts that could be relevant to information discovery."max_gleanings: 0community_report:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this taskprompt: "prompts/community_report.txt"max_length: 2000max_input_length: 8000cluster_graph:max_cluster_size: 10embed_graph:enabled: false # if true, will generate node2vec embeddings for nodes# num_walks: 10# walk_length: 40# window_size: 2# iterations: 3# random_seed: 597832umap:enabled: false # if true, will generate UMAP embeddings for nodessnapshots:graphml: falseraw_entities: falsetop_level_nodes: falselocal_search:# text_unit_prop: 0.5# community_prop: 0.1# conversation_history_max_turns: 5# top_k_mapped_entities: 10# top_k_relationships: 10# max_tokens: 12000global_search:# max_tokens: 12000# data_max_tokens: 12000# map_max_tokens: 1000# reduce_max_tokens: 2000# concurrency: 32
6.构建GraphRAG的索引(耗时较长,取决于document的长度)
poetry run poe index --root .
成功后如下:
⠋ GraphRAG Indexer
├── Loading Input (InputFileType.text) - 1 files loaded (0 filtered) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_base_text_units
├── create_base_extracted_entities
├── create_summarized_entities
├── create_base_entity_graph
├── create_final_entities
├── create_final_nodes
├── create_final_communities
├── join_text_units_to_entity_ids
├── create_final_relationships
├── join_text_units_to_relationship_ids
├── create_final_community_reports
├── create_final_text_units
├── create_base_documents
└── create_final_documents
🚀 All workflows completed successfully.
7.进行查询
此处GraphRAG提供了两种查询方式
1)全局查询 :更侧重全文理解
poetry run poe query --root . --method global "本文主要讲了什么"
运行成功后可以看到输出结果
2)局部查询:更侧重细节
poetry run poe query --root . --method local "本文主要讲了什么"
运行成功后可以看到输出结果
8. 总结
上述过程为已经验证过的,如果报错可以检查是否正确配置api_key及api_base
二、在python包的基础上进行(快速尝试)
1. 环境安装
pip install graphrag
2. 初始化项目
创建一个临时的文件夹graphrag,用于存在运行时数据
mkdir ./graphrag/input
curl https://www.xxx.com/xxx.txt > ./myTest/input/book.txt // 这里是示例代码,根据实际情况放入自己要测试的txt文本即可。
cd ./graphrag
python -m graphrag.index --init
3. 配置相关文件(可参考上述的配置文件过程)
4. 执行并构建图索引
python -m graphrag.index
5.进行查询
1)全局查询
python -m graphrag.query --root ../myTest --method global "这篇文章主要讲述了什么内容?"
2)局部查询
python -m graphrag.query --root ../myTest --method local "这篇文章主要讲述了什么内容?"
总结
通过以上两种方式,我们已经尝试了利用源码和python资源包进行配置GraphRAG的方式。大家可以按照自己的需求尝试以上两种方法。如果还有问题,欢迎在评论区讨论!
相关文章:
)
微软开源GraphRAG的使用教程(最全,非常详细)
GraphRAG的介绍 目前微软已经开源了GraphRAG的完整项目代码。对于某一些LLM的下游任务则可以使用GraphRAG去增强自己业务的RAG的表现。项目给出了两种使用方式: 在打包好的项目状态下运行,可进行尝试使用。在源码基础上运行,适合为了下游任…...
初始化项目)
使用Refine构建项目(1)初始化项目
要初始化一个空的Refine项目,你可以使用Refine提供的CLI工具create-refine-app。以下是初始化步骤: 使用npx命令: 在命令行中运行以下命令来创建一个新的Refine项目: npx create-refine-applatest my-refine-project这将引导你通过…...

【Docker】安装及使用
1. 安装Docker Desktop Docker Desktop是官方提供的桌面版Docker客户端,在Mac上使用Docker需要安装这个工具。 访问 Docker官方页面 并下载Docker Desktop for Mac。打开下载的.dmg文件,并拖动Docker图标到应用程序文件夹。安装完成后,打开…...

[大语言模型-论文精读] 以《黑神话:悟空》为研究案例探讨VLMs能否玩动作角色扮演游戏?
1. 论文简介 论文《Can VLMs Play Action Role-Playing Games? Take Black Myth Wukong as a Study Case》是阿里巴巴集团的Peng Chen、Pi Bu、Jun Song和Yuan Gao,在2024.09.19提交到arXiv上的研究论文。 论文: https://arxiv.org/abs/2409.12889代码和数据: h…...

提升动态数据查询效率:应对数据库成为性能瓶颈的优化方案
引言 在现代软件系统中,数据库性能是决定整个系统响应速度和处理能力的关键因素之一。然而,当系统负载增加,特别是在高并发、大数据量场景下,数据库性能往往会成为瓶颈,导致查询响应时间延长,影响用户体验…...

Prometheus+grafana+kafka_exporter监控kafka运行情况
使用Prometheus、Grafana和kafka_exporter来监控Kafka的运行情况是一种常见且有效的方案。以下是详细的步骤和说明: 1. 部署kafka_exporter 步骤: 从GitHub下载kafka_exporter的最新版本:kafka_exporter项目地址(注意ÿ…...

在vue中:style 的几种使用方式
在日常开发中:style的使用也是比较常见的: 亲测有效 1.最通用的写法 <p :style"{fontFamily:arr.conFontFamily,color:arr.conFontColor,backgroundColor:arr.conBgColor}">{{con.title}}</p> 2.三元表达式 <a :style"{height:…...

商城小程序后端开发实践中出现的问题及其解决方法
前言 商城小程序后端开发中,开发者可能会面临多种问题。以下是一些常见的问题及其解决方法: 一、性能优化 问题:随着用户量的增加和功能的扩展,商城小程序可能会出现响应速度慢、处理效率低的问题。 解决方法: 对数…...

阿里Arthas-Java诊断工具,基本操作和命令使用
Arthas 是阿里巴巴开源的一款Java诊断工具,深受开发者喜爱。它可以帮助开发者在不需要修改代码的情况下,对运行中的Java程序进行问题诊断和性能分析。 软件具体使用方法 1 启动 Arthas,此时可能会出现好几个jvm的进程号,输入序号…...

Go 1.19.4 路径和目录-Day 15
1. 路径介绍 存储设备保存着数据,但是得有一种方便的模式让用户可以定位资源位置,操作系统采用一种路径字符 串的表达方式,这是一棵倒置的层级目录树,从根开始。 相对路径:不是以根目录开始的路径,例如 a/b…...

jEasyUI 创建标签页
jEasyUI 创建标签页 jEasyUI(jQuery EasyUI)是一个基于jQuery的框架,它为Web应用程序提供了丰富的用户界面组件。标签页(Tabs)是jEasyUI中的一个常用组件,用于在一个页面内组织多个面板,用户可…...

鸿蒙HarmonyOS开发:一次开发,多端部署(界面级)天气应用案例
文章目录 一、布局简介二、典型布局场景三、侧边栏 SideBarContainer1、子组件2、属性3、事件 四、案例 天气应用1、UX设计2、实现分析3、主页整体实现4、具体代码 五、运行效果 一、布局简介 布局可以分为自适应布局和响应式布局,二者的介绍如下表所示。 名称简介…...

使用 Python 模拟光的折射,反射,和全反射
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

大厂太卷了!又一款国产AI视频工具上线了,免费无限使用!(附提示词宝典)
大家好,我是程序员X小鹿,前互联网大厂程序员,自由职业2年,也一名 AIGC 爱好者,持续分享更多前沿的「AI 工具」和「AI副业玩法」,欢迎一起交流~ 记得去年刚开始分享 AI 视频工具的时候,介绍的大多…...

vue3扩展echart封装为组件库-快速复用
ECharts ECharts,全称Enterprise Charts,是一款由百度团队开发并开源,后捐赠给Apache基金会的纯JavaScript图表库。它提供了直观、生动、可交互、可个性化定制的数据可视化图表,广泛应用于数据分析、商业智能、网页开发等领域。以…...

随机掉落的项目足迹:Vue3 + wangEditor5富文本编辑器——toolbar.getConfig() 查看工具栏的默认配置
问题引入 小提示:问题引入是一个讲故事的废话环节,各位小伙伴可以直接跳到第二大点:问题解决 我的项目不需要在富文本编辑器中引入添加代码块的功能,于是我寻思在工具栏上把操作代码的菜单删一删 于是我来到官网文档工具栏配置 …...

更新 Git 软件
更新 Git 软件本身是指将你当前安装的 Git 版本升级到最新版本。不同的操作系统有不同的更新方法。以下是针对 Windows、macOS 和 Linux 的 Git 更新步骤: Windows 检查当前版本: git --version访问官网下载最新版本: 访问 Git 官方网站 (ht…...
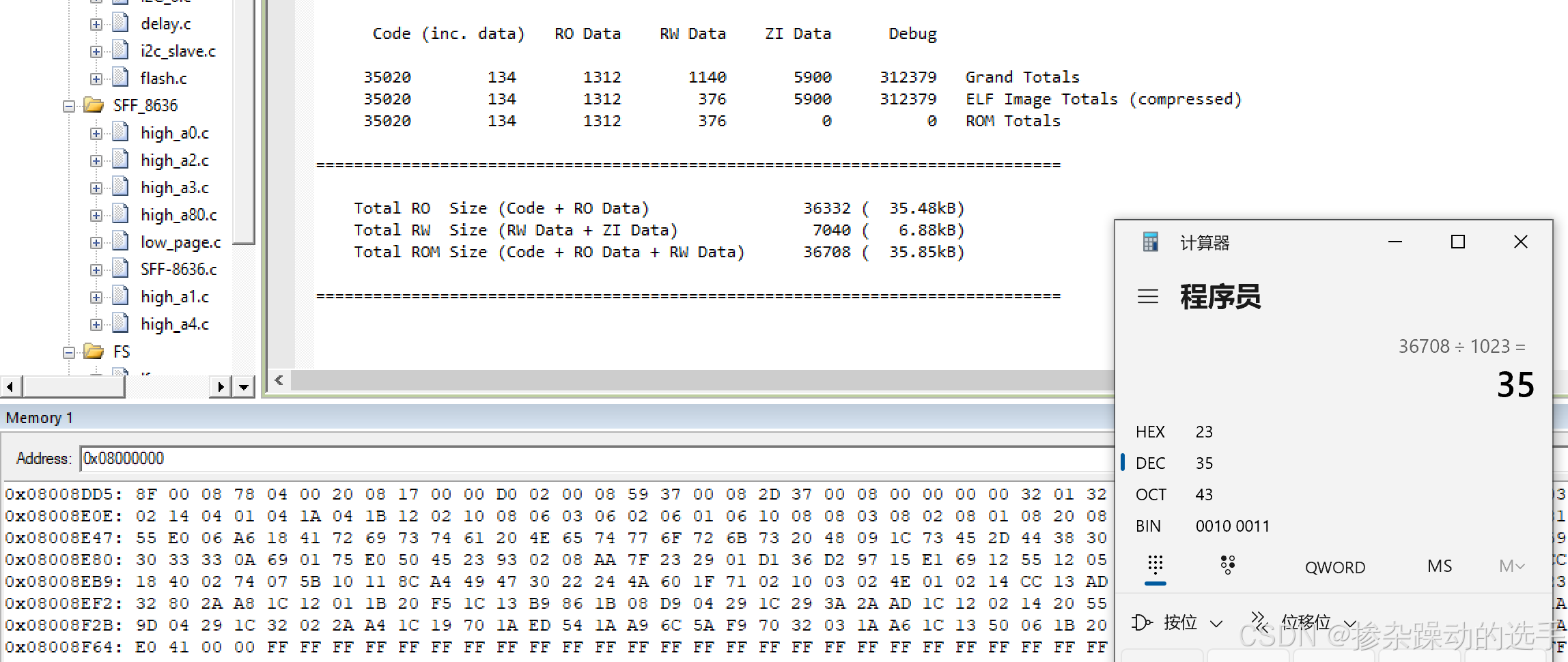
Keil根据map文件确定单片机代码存储占用flash情况
可以从map文件中查看得知,代码占用内存情况大概为35KB,而在在线仿真时,可以看到在flash的0x8008F64地址前均有数据,是代码数据,8F64(HEX)36708(DEC),36708/102335,刚好35。因此,要想操作读写flash,必须在不…...

ByteTrack多目标跟踪流程图
ByteTrack多目标跟踪流程图 点个赞吧,谢谢。...

什么是L2范数
定义: 在数学和计算中,L2 范数是一种用于测量向量长度或大小的方法,也被称为欧几里得范数。对于一个 n 维向量 x ( x 1 , x 2 , … , x n ) \mathbf{x} (x_1, x_2, \dots, x_n) x(x1,x2,…,xn),其 L2 范数定义为&#x…...

短剧进军韩国:外卡收单+本地钱包,Antom助你打通“付费最后一公里”
韩国短剧市场正以惊人的速度崛起。2024年,韩国短剧市场规模已达4.9亿美元,全球排名第4,预计未来将突破15亿美元。中国出海平台如DramaBox、ShortMax、ReelShort等早已抢先布局,在下载榜和收入榜上占据大半江山。然而,流…...
和内存映射(mmap)到底有啥区别?)
别再傻傻分不清了!Linux下共享内存(shm)和内存映射(mmap)到底有啥区别?
Linux下共享内存(shm)与内存映射(mmap)的本质区别与工程实践 在Linux系统编程中,当我们需要在进程间高效传递数据时,共享内存(shm)和内存映射(mmap)这两个概念常常让开发者感到困惑。它们看似都能实现内存共…...

ARM SVE架构LD1H指令详解与性能优化
1. ARM SVE架构与LD1H指令概述在Armv8.2架构引入的可扩展向量扩展(Scalable Vector Extension, SVE)彻底改变了传统SIMD指令集的设计理念。与固定128位或256位宽度的NEON指令不同,SVE采用向量长度不可知(Vector Length Agnostic, VLA)编程模型,允许同一套…...

3个步骤快速定位Windows热键占用者:Hotkey Detective完整实战指南
3个步骤快速定位Windows热键占用者:Hotkey Detective完整实战指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

用FPGA的DDS IP核做个信号发生器:从Vivado配置到ILA抓波形实战
基于FPGA的DDS信号发生器实战:从IP核配置到硬件调试全解析 在数字信号处理领域,直接数字频率合成(DDS)技术因其频率分辨率高、切换速度快和相位连续可调等优势,已成为现代电子系统中不可或缺的核心技术。本文将带领读者完成一个完整的FPGA-ba…...

PS4模拟器完整指南:shadPS4免费畅玩主机游戏教程
PS4模拟器完整指南:shadPS4免费畅玩主机游戏教程 【免费下载链接】shadPS4 PS4 emulator for Windows,Linux,MacOS 项目地址: https://gitcode.com/gh_mirrors/shad/shadPS4 还在寻找在电脑上体验PS4独占游戏的方法吗?shadPS4是一款免费开源的PS4…...

Vibe Coding 灾难的爆发
AI 编程工具确实正在颠覆软件行业,但几乎比我所见过的任何事物都更属于那个"如果没有丰富的前期经验,你不应该在家尝试"的类别: Reddit 上 vibe coding 灾难故事堆积如山。除非你介入并为 AI 建立结构,否则它就会推送垃…...

HsMod终极指南:55项功能打造你的个性化炉石传说体验
HsMod终极指南:55项功能打造你的个性化炉石传说体验 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说多功能插件,为玩家提…...

为什么你的无锁队列在压测中崩了——从 ABA 问题到 Hazard Pointer,追踪 lock-free 内存回收的生死时序
你的 lock-free queue 通过了所有单元测试,在 4 线程环境下稳定跑了整整一周,性能数据漂亮,直到你把压测线程数拉到 64,跑了 17 分钟后收到 SIGSEGV,打开 coredump 一看,崩溃地址指向的那块内存已经被 free 掉又被另一次 enqueue 重新 allocate 成了一个全新的节点,而 d…...

AI Agent 艺术创作能力探索
AI Agent 艺术创作能力探索:从生成式工具到自主创作主体的范式跃迁 关键词 AI Agent、生成式艺术、多模态创作、自主创作系统、计算美学、大模型推理、人机协同创作 摘要 本文从第一性原理出发,系统拆解AI Agent艺术创作的底层逻辑、技术架构、实现机制与产业价值。我们将…...