Spark 性能优化高频面试题及答案
目录
- 高频面试题及答案
- 1. 如何通过调整内存管理来优化 Spark 性能?
- 2. 如何通过数据持久化优化性能?
- 3. 如何通过减少数据倾斜(Data Skew)问题来优化性能?
- 4. 如何通过优化 Shuffle 操作提升性能?
- 5. 如何通过广播变量(Broadcast Variables)优化性能?
- 6. 如何通过序列化机制优化 Spark 作业性能?
- 7. 如何通过动态资源分配优化性能?
- 8. 如何通过调整并行度来优化 Spark 作业?
- 9. 如何通过减少 DAG(Directed Acyclic Graph)上的窄依赖和宽依赖优化性能?
- 10. 如何通过本地性调度优化任务执行?
以下是关于 Spark 性能优化 的高频面试题及答案,涵盖了内存管理、数据序列化、任务调度等多个方面。
高频面试题及答案
1. 如何通过调整内存管理来优化 Spark 性能?
回答:
Spark 内存管理分为存储内存(用于缓存RDD和广播变量)和执行内存(用于存储 shuffle、join 等操作的中间数据)。合理配置内存分配可以有效提升 Spark 的整体性能。
-
spark.memory.fraction: 控制内存用于存储内存和执行内存的比例。默认值是0.6,意味着60%的堆内存分配给存储和执行内存,剩下的用于其他用途。如果任务需要更多内存用于计算,则可以增加此值。 -
spark.memory.storageFraction: 其中spark.memory.fraction中存储内存的占比。默认值为0.5。可以根据需要调整,用于缓存更多数据或者分配更多内存给计算。 -
示例:
spark.conf.set("spark.memory.fraction", "0.8")
spark.conf.set("spark.memory.storageFraction", "0.4")
2. 如何通过数据持久化优化性能?
回答:
持久化(Persist)和缓存(Cache)操作允许将中间数据存储在内存或磁盘中,避免重复计算,提高性能。
-
缓存策略:
MEMORY_ONLY: 将RDD存储在内存中,最适合内存充足的场景。MEMORY_AND_DISK: 如果内存不足,将RDD部分存储到磁盘中,以免内存溢出。DISK_ONLY: 如果内存有限,只使用磁盘存储。SERIALIZED版本: 可以通过序列化减少内存使用量。
-
选择持久化策略: 当内存有限时,选择序列化存储策略,如
MEMORY_AND_DISK_SER来节省内存。
3. 如何通过减少数据倾斜(Data Skew)问题来优化性能?
回答:
数据倾斜是 Spark 性能问题的常见原因,数据分布不均导致某些分区负载过高,影响整体作业性能。
-
优化策略:
- 使用自定义分区器: 对于操作如
groupByKey或reduceByKey,可以通过自定义Partitioner来保证数据分布均匀。 - 采样数据并进行预分区: 使用
sample方法来检查数据分布是否均匀,必要时手动重新分区。 - 避免全局操作: 如
groupByKey会将大量数据集中到单个分区,使用reduceByKey来减少数据传输量。
- 使用自定义分区器: 对于操作如
-
示例:
val partitionedRDD = rdd.partitionBy(new HashPartitioner(100))
4. 如何通过优化 Shuffle 操作提升性能?
回答:
Shuffle 操作通常是 Spark 性能瓶颈,涉及到跨节点数据传输。优化 shuffle 是提升 Spark 性能的关键。
-
使用本地性: 尽量减少 Shuffle 操作,如使用
mapPartitions代替groupByKey或reduceByKey来避免频繁的 shuffle。 -
调整并行度: 使用
spark.sql.shuffle.partitions增加 shuffle 分区数,提高并发度,避免单个分区过大:spark.conf.set("spark.sql.shuffle.partitions", "200") -
压缩 Shuffle 数据: 开启 shuffle 数据压缩减少网络传输和磁盘I/O:
spark.conf.set("spark.shuffle.compress", "true") spark.conf.set("spark.shuffle.spill.compress", "true")
5. 如何通过广播变量(Broadcast Variables)优化性能?
回答:
在 Spark 作业中,如果一个数据集被多个任务多次使用,可以使用广播变量将数据在节点间进行共享,减少重复的数据传输。
-
优化策略:
使用sparkContext.broadcast()方法将数据广播到每个 worker 节点,避免每次 task 执行时从 driver 节点读取数据。示例:
val broadcastVar = sc.broadcast(largeDataSet) val result = rdd.map(x => broadcastVar.value.contains(x))
6. 如何通过序列化机制优化 Spark 作业性能?
回答:
Spark 使用序列化将对象转换为字节流进行传输或存储,优化序列化机制可以显著提升性能,尤其是需要传输大量数据或频繁传递对象时。
-
Kryo 序列化: 默认情况下,Spark 使用 Java 序列化,但它效率较低。Kryo 序列化更快,且占用空间更少。
- 启用 Kryo 序列化:
spark.conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") spark.conf.set("spark.kryo.registrationRequired", "true") -
注册自定义类: 注册使用 Kryo 序列化的自定义类,以获得更好的性能。
val conf = new SparkConf().set("spark.kryo.classesToRegister", "com.example.MyClass")
7. 如何通过动态资源分配优化性能?
回答:
动态资源分配允许 Spark 根据当前的任务负载自动调整执行器数量,这可以提高资源的利用率和集群的整体性能。
- 启用动态资源分配:
动态资源分配根据作业负载灵活调整资源,避免资源闲置或过度分配。spark.conf.set("spark.dynamicAllocation.enabled", "true") spark.conf.set("spark.dynamicAllocation.minExecutors", "1") spark.conf.set("spark.dynamicAllocation.maxExecutors", "50")
8. 如何通过调整并行度来优化 Spark 作业?
回答:
并行度(Parallelism)决定了每个阶段有多少 task 同时运行,合适的并行度可以提高任务的吞吐量和执行效率。
- 调整并行度:
spark.default.parallelism: 调整全局并行度:spark.conf.set("spark.default.parallelism", "100")- 对于
reduceByKey等聚合操作,推荐并行度为总 CPU 核心数的 2-3 倍。
9. 如何通过减少 DAG(Directed Acyclic Graph)上的窄依赖和宽依赖优化性能?
回答:
在 Spark 中,宽依赖(Wide Dependency)需要进行 shuffle 操作,而窄依赖(Narrow Dependency)则不需要。减少宽依赖有助于减少 shuffle 代价。
- 优化策略:
- 优先使用窄依赖的算子,如
map、filter等操作,而尽量避免使用需要 shuffle 的算子,如groupByKey、join等。 - 将宽依赖的任务拆分为多个窄依赖任务,减少 shuffle 量。
- 优先使用窄依赖的算子,如
10. 如何通过本地性调度优化任务执行?
回答:
Spark 提供了本地性调度(Data Locality),即尽量将任务安排到与数据位于相同节点的执行器上,减少数据传输的开销。
- 优化方式:
- 通过
spark.locality.wait控制 Spark 等待获取本地数据的时间。较高的等待时间可以增加本地任务的调度机会:spark.conf.set("spark.locality.wait", "3s") - 数据本地性对性能提升尤为重要,尽量确保数据和计算在同一节点上进行。
- 通过
通过这些 Spark 性能优化的策略,可以帮助在大规模数据处理场景下提升任务执行效率和资源利用率,同时避免常见的性能瓶颈和问题。
相关文章:

Spark 性能优化高频面试题及答案
目录 高频面试题及答案1. 如何通过调整内存管理来优化 Spark 性能?2. 如何通过数据持久化优化性能?3. 如何通过减少数据倾斜(Data Skew)问题来优化性能?4. 如何通过优化 Shuffle 操作提升性能?5. 如何通过广…...

【洛谷】AT_abc371_e [ABC371E] I Hate Sigma Problems 的题解
【洛谷】AT_abc371_e [ABC371E] I Hate Sigma Problems 的题解 洛谷传送门 AT传送门 题解 I Hate Sigma Problems!!! 意思很简单就是求序列中每一个子区间内含有不同数字的个数之和。 暴力的话时间复杂度是 O ( n 2 ) O(n ^ 2) O(n2),是肯定不行的࿰…...

【Go】Go 环境下载与安装教程(Windows系统)
引言 Go,也被称为Golang,是一种静态类型,编译型的编程语言,由Google设计和开发。Go语言的设计目标是“解决软件开发中的一些问题”,特别是在大规模软件系统的构建和维护方面。 下载安装包 打开官网下载页面ÿ…...

毕业设计选题:基于springboot+vue+uniapp的驾校报名小程序
开发语言:Java框架:springbootuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包&#…...

网页通知设计灵感:CSS 和 JS 的 8 大创意实现
文章目录 前言正文1.霓虹灯风格的通知系统2.垂直时间轴通知3.动画徽章通知4.项目式通知5.多种状态通知:成功、错误、警告6.信息、警告、提示组件7.扁平化风格通知8.社交媒体风格弹出通知 总结 前言 网页通知如今已成为电商、社交平台等网站的常见功能,它…...

计算机毕业设计之:基于微信小程序的中药材科普系统(源码+文档+讲解)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

C++速通LeetCode中等第6题-找到字符串中所有字母异位词(滑动窗口最详细代码注释)
滑动窗口法: class Solution { public:vector<int> findAnagrams(string s, string p) {unordered_map<char,int> need,window;for(char c : p) need[c];int left 0,right 0;int valid 0;vector<int> res;//窗口数据更新while(right < s.s…...

Tcping:一款实用的端口存活检测工具
简介 tcping 是一个基于TCP协议的网络诊断工具,通过发送 TCP SYN/ACK包来检测目标主机的端口状态。 官网:tcping.exe - ping over a tcp connection 优点: (1)监听服务器端口状态:tcping 可以检测指定端口的状态,默认是80端口,也可以指定其他端口。 (2)显示ping返…...

【每日刷题】Day130
【每日刷题】Day130 🥕个人主页:开敲🍉 🔥所属专栏:每日刷题🍍 🌼文章目录🌼 1. 144. 二叉树的前序遍历 - 力扣(LeetCode) 2. 94. 二叉树的中序遍历 - 力扣…...

书生·浦语作业集合
目录: 1. Linux基础知识 2.python基础知识 3.Git基础知识 4.书生大模型全链路开源体系 1.1-Linux基础知识 配置环境后,运行 hello_word.py 在本地终端中进行端口映射 映射成功后,访问 127.0.0.1:7860 1.2-python基础知识 任务…...

得物App科技创新“再上一层楼”,荣获国家级奖项
近日,在2024中国国际服务贸易交易会(简称“服贸会”)上,得物App荣获“科技创新服务示范案例”奖项。这是国家层面对得物App以科技创新保障品质消费、提升消费体验成效的肯定。 在得物App上,90后、95后这些曾经的“新生…...

C#软键盘设计字母数字按键处理相关事件函数
应用场景:便携式设备和检测设备等小型设备经常使用触摸屏来代替键盘鼠标的使用,因此在查询和输入界面的文本或者数字输入控件中使用软件盘来代替真正键盘的输入。 软键盘界面:软键盘界面实质上就是一个普通的窗体上面摆放了很多图片按钮&…...

C++笔记---set和map
1. 序列式容器与关联式容器 前面我们已经接触过STL中的部分容器如:string、vector、list、deque、array、forward_list等,这些容器统称为序列式容器,因为逻辑结构为线性序列的数据结构,两个位置存储的值之间一般没有紧密的关联关…...
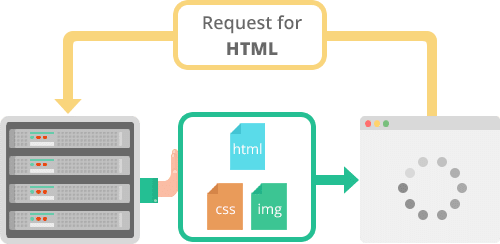
HTTP 教程
HTTP/HTTPS 简介 HTTP(Hypertext Transfer Protocol,超文本传输协议)和 HTTPS(Hypertext Transfer Protocol Secure,超文本传输安全协议)是用于在网络中传输信息的两种主要协议。它们定义了客户端和服务器…...

低代码革命:加速云原生时代的端到端产品创新
随着云计算技术的飞速发展,云原生成为了企业数字化转型的重要方向。云原生技术通过容器化、微服务、持续集成/持续部署(CI/CD)等实践,帮助企业构建和运行可扩展的应用程序。然而,云原生技术的复杂性也给开发团队带来了…...

力扣 92.反转链表Ⅱ
力扣《反转链表》系列文章目录 刷题次序,由易到难,一次刷通!!! 题目题解206. 反转链表反转链表的全部 题解192. 反转链表 II反转链表的指定段24. 两两交换链表中的节点两个一组反转链表 题解225. K 个一组翻转链表K …...
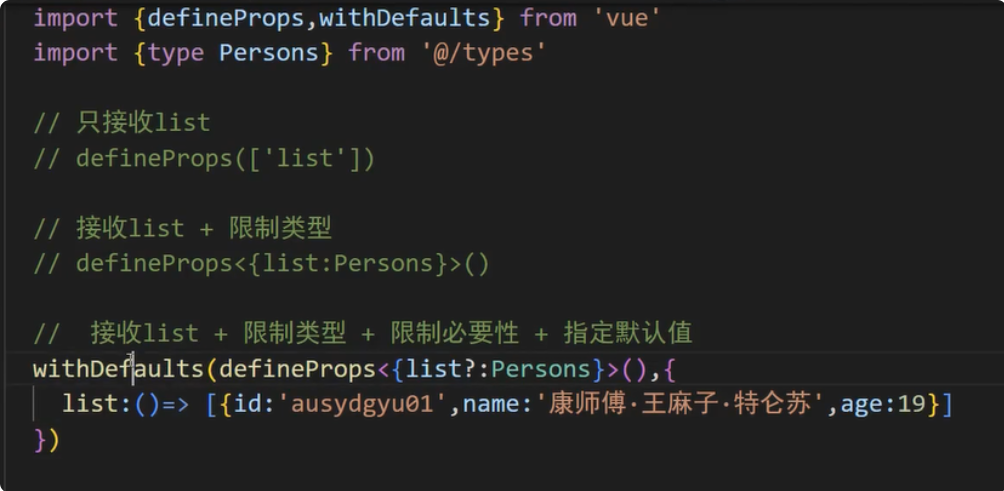
2024年最新版TypeScript学习笔记——泛型、接口、枚举、自定义类型等知识点
今天带来的是来自尚硅谷禹神2024年8月最新的TS课程的学习笔记,不得不说禹神讲的是真的超级棒! 文章目录 TS入门JS中的困扰静态类型检查编译TS命令行编译自动化编译 类型检查变量和函数类型检查字面量类型检查 类型推断类型声明声明对象类型声明函数类型…...

java项目之城镇保障性住房管理系统(源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的城镇保障性住房管理系统。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: 城镇保障性住房管…...

无人机之航线规划篇
无人机的航线规划是一个复杂但至关重要的过程,它确保了无人机在飞行过程中的安全、高效以及任务的顺利完成。以下是对无人机航线规划的详细解析: 一、定义与目的 无人机航线规划是指依据无人机任务分配,规划出符合安全条件的飞行航线。这一过…...

828 华为云征文|华为 Flexus 云服务器搭建 PicGo 图床
在这个充满非凡意义的日子里,我怀揣着满心的热忱与憧憬,毅然决然地踏上了借助华为 Flexus 云服务器搭建 PicGo 图床的精彩征程。这段旅程,注定充满了无数的挑战与意外之喜,宛如在广袤无垠的数字海洋中勇敢地探寻那神秘而珍贵的宝藏…...

【Perplexity诗词歌赋搜索黑科技】:20年NLP专家首度公开5大语义对齐技巧,让古诗检索准确率飙升至98.7%
更多请点击: https://kaifayun.com 第一章:Perplexity诗词歌赋搜索黑科技全景透视 Perplexity 并非专为古籍设计的搜索引擎,但其基于大语言模型的实时语义理解与多源交叉验证机制,意外地在诗词歌赋领域展现出颠覆性能力——它不依…...

Gregwar/Captcha图像效果详解:扭曲、线条、背景与透明度的艺术
Gregwar/Captcha图像效果详解:扭曲、线条、背景与透明度的艺术 【免费下载链接】Captcha PHP Captcha library 项目地址: https://gitcode.com/gh_mirrors/capt/Captcha 在PHP验证码开发中,Gregwar/Captcha库以其出色的图像效果和安全性能脱颖而出…...
)
手把手教你用wget和迅雷搞定nuScenes数据集下载(附完整性校验命令)
高效获取nuScenes数据集的两种技术方案与完整性验证指南 在自动驾驶与计算机视觉研究领域,nuScenes数据集因其丰富的传感器数据和精细的标注体系已成为行业基准测试的重要资源。但对于大多数研究者而言,获取这个总容量超过550GB的数据集却面临着网络不稳…...

OpenClaw 架构详解:AI Agent 的编排与执行骨架
核心定位:OpenClaw 自动化运行时(Automation Runtime),一个给 AI 套上安全、可控、可审计缰绳的框架。 它不追求 AI 的"惊喜",而是追求可预测性、可审计性和零故障。 文章目录一、设计哲学:网关…...

OBS智能跟拍插件:3分钟实现直播自动追踪的终极指南
OBS智能跟拍插件:3分钟实现直播自动追踪的终极指南 【免费下载链接】obs-face-tracker Face tracking plugin for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-face-tracker 您是否在直播时经常为手动调整摄像头而烦恼?是否希望…...

SEM教程丨如何用“场景词”突围,月揽165个询盘?
很多工业设备老板觉得SEM就是“谁出价高谁就赢”,结果往往是钱烧了一大堆,机器没卖出去几台。今天我们要复盘的是某食品安检设备公司的实操案例,看看它是如何摆脱“无效烧钱”,稳稳拿下月均165个精准咨询的 🍎。 一、 …...

2025终极指南:如何用PyGlossary打破词典格式壁垒
2025终极指南:如何用PyGlossary打破词典格式壁垒 【免费下载链接】pyglossary A tool for converting dictionary files aka glossaries. Mainly to help use our offline glossaries in any Open Source dictionary we like on any operating system / device. 项…...
)
告别集群负载:用Docker Compose在外部机器部署Prometheus+Grafana监控K8S(附完整配置文件)
轻量化监控方案:Docker Compose 部署 PrometheusGrafana 监控 Kubernetes 集群 对于资源有限的中小团队或个人开发者来说,将监控系统与业务集群分离是一个明智的选择。传统的 Kubernetes 监控方案通常将 Prometheus 和 Grafana 部署在集群内部࿰…...

Claude Code cli 以及vscode版本的各种命令参考手册
Claude Code 各种命令参考手册版本说明: 截至 2026 年 4 月,Claude Code 官方文档共收录超过 70 条内置命令与绑定技能。其中约一半为内置命令(行为由 CLI 代码实现),另一半为绑定技能(通过 Prompt 机制实现…...

Linux内核死锁实战:从原理到调试与预防策略
1. 项目概述:当内核代码“卡住”时在Linux内核开发与系统运维的深水区,有一个让所有工程师都闻之色变、却又不得不面对的“幽灵”——死锁。它不像段错误那样直接崩溃,也不像内存泄漏那样缓慢侵蚀,而是以一种近乎“优雅”的静默方…...